Juergen Angele, Stefan Decker, Rainer Perkuhn, and Rudi Studer
Institute AIFB
University of Karlsruhe (TH)
D-76128 Karlsruhe, Germany
e-mail: { angele | decker | perkuhn | studer }@aifb.uni-karlsruhe.de
Abstract
New KARL (Knowledge Acquisition and Representation Language) allows to specify all parts of a problem-solving method (PSM). It is a formal language with a well-defined semantics and thus allows to represent PSMs precisely and unambiguously yet abstracting from implementation detail. In this paper it is shown how the language KARL has been modified and extended to New KARL to better meet the needs for the representation of PSMs. Based on a conceptual structure of PSMs new language primitives are introduced for KARL to specify such a conceptual structure and to support the configuration of methods. An important goal for this extension was to preserve three important properties of KARL: to be (i) a conceptual, (ii) a formal, and (iii) an executable language.1 INTRODUCTION
The specification language KARL ([Fensel, 1995a], [Fensel, Angele, and Studer 1997]) is part of the MIKE-approach (Model-based and Incremental Knowledge Engineering) [Angele, Fensel, and Studer, 1996]. The overall goal of the MIKE project is the definition of a development method for knowledge-based systems (KBS) covering all steps from initial knowledge acquisition to design and implementation. The central model within the development process in MIKE is the KARL model of expertise which resembles the KADS model of expertise [Schreiber, Wielinga, and Breuker, 1993]. This model describes all functional requirements for the knowledge-based system under development. The language KARL has been developed for building and representing this model of expertise:
It is now two years ago that the current version of KARL has been defined. In the meantime several models of expertise have been specified in KARL. Using KARL it has been started to build up a library of formally specified problem-solving methods: Hill Climbing, Chronological Backtracking, Beam Search, Cover-and-Differentiate, Board-Game Method, Propose-and-Exchange, and Propose-and-Revise.
2 THE CONCEPTUAL MODEL OF A PSM
The development of a KBS begins with analyzing the organizational circumstances. If it seems reasonable to integrate a KBS in the (business) process the next step is to figure out what part of the process might be performed by a KBS [Decker, Erdmann, and Studer, 1996]. From the knowledge engineering point of view this part is called a task and it can be described by the goals it is intended to achieve.
This section presents the notion of a PSM in the context of the method-to-task paradigm that emerged from Components of Expertise [Steels, 1990], Task Structure Analysis [Chandrasekaran, Johnson, and Smith, 1992], PROTÉGÉ-II [Puerta et al., 1992], and CommonKADS [Schreiber et al., 1994a]. We do not want to go into details about the distinction of generic (problem solving) and domain specific (ontology) knowledge. We do neither mention explicitly the mappings between these two different kinds of knowledge since these can be treated as a special case of any mapping of a PSM to its environment.
2.1 Representing PSMs
Given a task that a system should accomplish a PSM is the specification of the functionality of the problem solving behaviour of the system to be built. It is a description of how the functionality can be achieved and how the requirements can be met without taking non-functional requirements (1) and implementation aspects into account. In MIKE, the latter features are handled in a separate design and a separate implementation phase (cf. [Landes and Studer, 1995]).
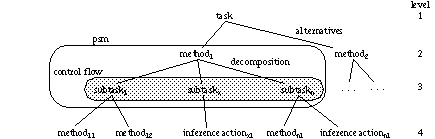
Figure 1: Embedding the notion of PSM into the method-to-task paradigm
A PSM decomposes a task into new subtasks. According to the divide-and-conquer principle this is done repeatedly downto a level of subtasks for which the solution is obvious and can be written down in a straightforward manner as an elementary inference action. In addition to the decomposition the PSM has to specify the control flow of the subtasks, i.e. the ordering in which the subtasks can be accomplished. Or, to put it the other way around, as long as one is interested in specifying the control flow one has to decompose the task further.
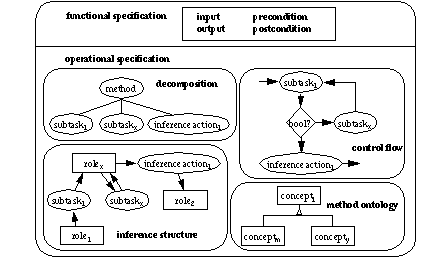
Figure 2: (Parts of the) Description of a PSM
To date, KARL focuses on capturing the description of the operational specification, but it lacks the capability to describe the functional specification of a PSM. The extension of the language KARL aims at specifying the operational part of a PSM exactly as it is shown in figure 2, that is only partially covered in the current version of KARL. New KARL provides primitives to distinguish clearly between the decomposition, the inference structure, the control flow, and the method ontology of a PSM. By this, there is no explicit representation of a single task and a single inference layer as in current KARL. But it is easy to derive this task or inference layer view from the method-to-task decomposition tree of figure 1 by extracting views solely on the odd rsp. the even levels.
2.2 The Notion of Method and Task Ontologies
A PSM comes with a method ontology defining the generic concepts and relationships the problem-solving behaviour of the PSM is based on [Gennari et al., 1994]. This method ontology includes all concepts and relationships which are used for specifying the functionality of the PSM (see figure 3). In addition, constraints can be specified for further restricting the defined terminology. It should be clear that the method ontology defines exactly the ontological assumptions that must be met for applying the PSM.
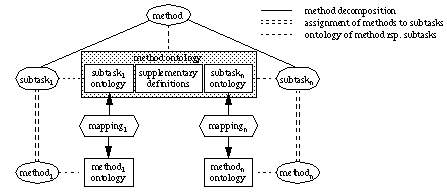
Figure 3: Ontologies within the method-to-task paradigm
Assuming that a PSM is decomposed into subtasks the problem arises of how to make the method ontology independent of the selection of more elementary methods for solving the subtasks of the PSM. In order to get rid of that problem the notion of a subtask ontology is introduced [Studer et al., 1996]. The subtask ontology defines all the concepts and relationships which are used for specifying the functional behaviour of the subtask. In essence, the method ontology is then derived from the various subtask ontologies by combining them and by introducing additional concepts and constraints. As a consequence, the subtask ontologies provide a context for mapping the (global) method ontology to the ontologies of the submethods which are used for solving the subtasks.
Of course, in general there are some differences between a subtask ontology and the ontology of the method used to accomplish the subtask. Therefore, one has to define mappings between these ontologies (compare e.g. [Gennari et al., 1994]) in order to transform the structure of the subtask ontology into the structure of the method ontology and vice versa.
It is obvious that these mappings can be specified in the same way as the mappings which are used to map the generic PSM terminology to the domain specific terminology as defined by the domain layer of the model of expertise. I.e. within our framework of tasks and methods we use the same kind of mappings for handling ontology transformations within a method as well as between the generic method ontology and the domain ontology.
3 REPRESENTING PSM`S IN NEW KARL
In the following section we show how KARL has been extended to New KARL in order to specify the conceptual model of PSMs and to support the way PSMs are configured from more elementary components. In section 3.1 and section 3.2 we discuss the conceptual extensions of KARL which support the concepts introduced in section 2. In section 3.3 we present some of the extensions we have introduced on the language level of KARL. Section 3.4 then sketches the changes at the semantics of KARL which are necessary to integrate the new constructs.
KARL has been evaluated the last years in a number of case studies. One of the largest one was the Sisyphus II project which has been used to compare different knowledge engineering approaches. In this project an elevator configuration task has been posed [Schreiber and Birmingham, 1996]. For configuring an elevator values have to be assigned to a predefined set of parameters. These assignments have to fulfil a number of domain-specific contraints. To accomplish this task we used a variant of the PSM Propose-and-Revise ([Poeck et al., 1996], [Angele, 1996]). Because we gained many insights during this project we use this model for our examples in the following.
3.1 Ontologies
Every PSM comes with its own domain independent terminology, i.e. its method ontology [Puerta et al., 1992]. Additionally the domain layer is expressed in its own domain specific terminology. These different ontologies have to be distinguished within the model of expertise and transformations between them have to be defined.
3.1.1 Method ontology
In the current version of KARL the concepts and relationships defining the PSM ontology are spread over the different roles, i.e. stores, views, terminators, and inference actions at the inference layer. These concepts and relationships are represented in KARL using classes and predicates. Classes and predicates represent the structure of the objects and relationships (via attributes) as well as the extension, i.e. the set of class elements and the set of relations. In order to improve readability and to avoid redundant definitions this method ontology is centralized for a PSM in New KARL. Furthermore in New KARL the representation of the structure information (types) is separated from the extensions. The types are defined at one place within a PSM. Within roles and inference actions extensions (sets of objects or sets of relations) of the different types may be defined. This allows to define several independent sets of objects and relations of the same structure.
par-name: {};
par-value: {};
END;3.1.2 Mapping Ontologies
There exist different places within the model of expertise where formulae expressed in one ontology have to be transformed to formulae expressed in another ontology:
The unary mapping operator map performs the second and third item. The parameter of map may contain variables for function symbols, predicate symbols, elements, values, classes, attributes, rule names and entire sub-formulae which allows to transform several formulae by one mapping expression.
For instance the PSM Propose-and-Revise uses domain specific derivation rules (propose rules) which derive the values of parameters from the values of either input parameters or parameters which have already been tackled. To apply these derivation rules correctly the PSM must know which parameter depends on which other parameters. This information is implicitly available within the derivation rules. For instance the derivation rule (2):
par(selected_platform_model, "2.5B") <- par(platform_depth, 60).
IN DOMAIN-LAYER;
OUT Parameters;
map(par(X,Y) <- par(U,V)) |-> (depends_on(map(X), map(U))).
/* Maps all propose rules which fit to this form to a set of dependency facts.
Our example rule is mapped to the fact depends_on(selected_platform_model,
platform_depth). If not stated otherwise map(X) = X' holds.*/
depends_on(X,Z) <- depends_on(X,Y) /\ depends_on(Y,Z).
/* this rule models transitive dependencies */
END;3.2 Tasks and Methods
In order to support the method-to-task approach, tasks and methods have to be distinguished. In New KARL primitives to describe tasks and PSMs have been introduced.
TASK < task name >
A method is defined by its functional specification and by an operational specification which establishes subtasks, specifies elementary inference actions and describes the control flow between those parts. Mappings are necessary to map the ontology of the task to the method (which accomplishes the task):
METHOD < method name >
The control part of a method describes the control flow between different subtasks and elementary inference actions. The data flow part describes the subtasks, specifies elementary inference actions, describes the roles, and defines the data flow between them. Thus the data flow together with the control flow may be seen as an operational specification of the functional specification given by the pre- and postconditions of the method. As a consequence of this structure there is no longer a common inference and control layer of a model of expertise. Instead every method describes its own part of the inference layer and of the control layer.
An example for a precondition of a method is given for the problem-solving method Propose-and-Revise: the propose-rules have to be acyclic. A propose-rule determines a value for a parameter dependent on the values of other parameters. Acyclic means that no value may depend transitively on itself.
Using the above mentioned relationship depends_on (see section 3.1.2) a precondition for the PSM Propose-and-Revise may be defined which assures that the parameter dependencies are acyclic (relationship p of role r is named r.p):
METHOD Propose-and-Revise
IN Parameters;
...
PRE
! Parameters.depends_on(A1, A2) -> ¬ Parameters.depends_on(A2, A1).
/* If A1 depends on A2 then A2 must not depend on A1
(the ! sign indicates a constraint) */
POST
...
END;3.3 Technical Details
The language L-KARL is used to describe the knowledge at the domain layer, to specify elementary inference steps at the inference layer, it is used within the mappings between inference and domain layer and between tasks and methods at the inference layer, and it is used to express constraints, pre- and postconditions and conditions within the control flow. 3.3.1 Surmounting Horn logic
L-KARL is restricted to Horn logic extended by negation (normal programs) to enable an efficient operationalization of the model of expertise. There is a tradeoff between expressibility and executability, because on the one hand Horn logic is a subset of first order logic which may be operationalized with reasonable efficiency and on the other hand this results in some severe deficiencies: describing inference actions or logical dependencies using Horn rules looks sometimes more like programming than like specifying.
To drop partially the restriction to Horn logic (at least syntactically) New KARL-rules are extended to the following form:
In [Lloyd and Topor, 1984] a simple Horn axiomatization is described for this extension and thus it can be easily integrated into the constructive semantics of KARL and based on that into the interpreter of KARL.
Let us give an example. In our class hierarchy we want to find the leaves of this hierarchy. In the current version of KARL this must be expressed using the following rules:
leaf(X) <- X <= Y /\ ¬ not_leaf(X).3.3.2 Access to the domain ontology
In order to make statements about the domain ontology (4) itself classes, their attributes, their interrelationships (generalization, part-of relation), and the relationships should be accessible within rules. For this purpose signature-atoms, i.e. atoms which allow to access the attributes of classes and their range restrictions (cf. [Kifer, Lausen, and Wu, 1995]), are introduced.
For instance given the following class definition:
car-capacity-range: {REAL};
speed:{REAL};
...
END;
/* the signature atom is subscribed by an s */3.3.3 Rules as objects
Propose-and-Revise uses domain specific fix rules to modify the parameter values if a constraint violation occurs. A fix rule may for instance increment the value of a parameter. Fix rules may contradict each other, for instance one fix rule increments a parameter value and another one decrements the value of the same parameter. So it must be possible to apply fix rules selectively. In KARL we solved this problem by an additional flag in the fix rule bodies which has been set by the problem-solving process at the inference layer if the fix rule should fire. The following constructs in New KARL allow to handle domain rules similar to objects, i.e. they may be mapped to the inference layer, selected by corresponding inference actions and selectively evaluated.
/* fix 1 fixes a violation of constraint 2 */3.3.4 Rules and States
Up to now in KARL the state change caused by an elementary inference action is not directly recognizable. An elementary inference action computes a set of facts depending on its input facts and the rules which describe the elementary inference action (the perfect Herbrand model). The content of every output role is determined by the subset that fits to the class and relationship definitions of the role (cf. [Fensel, 1995a]). For a store which is input and output store of an inference action this has for instance the following consequence: the content of the store before the execution of the inference action is a subset of the content of the store after the execution. For instance the PSM Propose-and-Revise uses fix-rules, that change attribute values of objects in KARL. Attributes have a functional dependency on their objects, i.e. there may be only one value for an attribute. So it is not possible to change such a value in one step by a fix rule, because a fix rule computes a new value and then both values, the old and the new one are available. Instead, a complicated construction has to be used, where a first inference action evaluates the selected fixes:
newvalue(Parname,V + 2) <- par(Parname, V).
We model the transition from one state to another state with the operators first and next (O). The operator first describes what is valid in the initial state and next describes the following states. For our purposes it is sufficient to allow only two kinds of clauses: computation clauses und output clauses. In a computation clause all literals are (implicitly) annotated with the first operator. The head of an output clause is annotated with a next operator, meaning that if the head can be derived it is included in the output stores. The input from the input stores is implicitly annotated with a first.
3.3.5 Evaluation of rule objects
Rule objects which are mapped to the inference layer should be selectively evaluable at the inference layer. Every ontology at the inference layer contains the predefined type RULE'. Every rule object at the inference layer must be an element of a class of type RULE' or of a class of a subtype of it. Rule objects which are elements of such a class c within a store s may be evaluated within an inference action by the expression:
CLASS fix-rules: RULE';
END;
INFERENCE ACTION apply-fix-combination
IN fix-combination, old-pairs;
OUT new-pairs;
EVAL(fix-combination, fix-rules);
/* this evaluates the rules stored in class fix-rules in store fix-combination */
END;3.3.6 Further improvements
Besides all the mentioned extensions a number of minor extensions and improvements have been integrated in New KARL: lists have been introduced as further data structure, the handling of sets has been improved, the expressions in tests to control loops and alternatives have been generalized, and some syntactical modifications have been done as well. 3.4 Semantics of New KARL
There are three modifications of New KARL with respect to KARL which led to larger modifications of the original semantics of KARL [Fensel, 1995a]: (i) the explicit modeling of the state transitions within inference actions, (ii) the dynamic evaluation of rule objects within inference actions, and (iii) the extended mapping construct.
The mapping operator in New KARL performs an extended matching. Be map(F1) |-> F2 the definition of a mapping operation, where F1 and F2 are formulae containing mapping variables for functions, predicates, objects, attributes, and formulae. A substitution s of the mapping variables in F1 with corresponding symbols and formulae to the formula s (F1) which matches a given fact or rule determines the output s (F2) of the mapping operator.
4 RELATED WORK
Within the KADS framework [Schreiber, Wielinga, and Breuker, 1993] two different languages have been developed: the language CML [Schreiber et al., 1994a] to describe models of expertise semi-formally on a conceptual level and the language ML2 [van Harmelen and Balder, 1992] to describe models of expertise formally. Guidelines and tool support are available to semi-automatically transform a CML-description into an ML2-description [van Harmelen and Aben, 1996]. A subset of ML2 is executable by a simulator [Teije, van Harmelen, and Reinders, 1991] in order to support the validation by testing. In contrast to that, KARL already combines these three different aspects in one language: specification on a conceptual level, formal specification, and operational specification. Thus the knowledge engineer has to learn only one language and there are no consistency problems between different representations of the same knowledge. New KARL which extends KARL especially on the conceptual level by integrating the concepts method and task preserves these properties of KARL.
CML is a semi-formal language and offers a set of primitives to describe the CommonKADS model of expertise [Schreiber et al., 1994b]. On an abstract level the structure of a CML and a New KARL specification are very similar. But CML has no formally defined semantics and according to the CML grammar every part of the specification besides the names, the roles, and the decomposition is rewritten as free text. In contrast to this, New KARL pursues the idea that the complete model has a formally defined semantics, especially the parts that are only natural language descriptions in CML, e.g. the control flow and the competence. The same holds already for (old) KARL but in addition New KARL considers also the notion of PSMs and tasks as well as method and (sub-)task ontologies. [Schreiber et al., 1994b] sketches already the necessity of ontology mappings and offers a preliminary version - with the disclaimer that this has to be refined in the near future.
The newly introduced language primitives relate to corresponding primitives in ML2 in the following way. The integration of the concept of PSMs into the language New KARL allows to describe all aspects of PSMs formally. This allows to describe PSMs precisely and unambiguously and opens them for discussion and for further analysis. Up to now no corresponding primitives are available in ML2. Domain layer and inference layer are related in ML2 via a classical object-meta relationship. In contrast to that in New KARL two different languages for each layer using different signatures are related by the mappings which transform expressions of one language into expressions of the other language. Together with the handling of rules as objects this allows to evaluate rules in an environment which may be dynamically configured during the problem-solving process. In ML2 domain formulae are mapped to variable-free terms at the inference layer. Their truth may be evaluated within the domain layer using reflection rules. So the environment in which such formulae are evaluated is fixed in advance. In New KARL all elements of the domain ontology are now accessible in formulae. This supports the reuse of both the domain layer for another task and the PSM within another domain. In ML2 there is no possibility to access the sorts and the orderings of the order sorted logic at the domain layer. The extended rules in L-KARL reduce the gap between Horn logic and full first-order logic and allow to express things more adequately. Still all parts of L-KARL may be axiomatized in Horn logic which allows to execute the model with reasonable efficiency. The price which had to be paid for this possibility is a compromise between executability and expressiveness: L-KARL is restricted to Horn logic in order to provide efficient executability whereas ML2 uses full first-order logic. On the other hand in ML2 only the Horn logic subset can be validated by the simulator. A detailed comparison between ML2 and (old) KARL may be found in [Fensel and van Harmelen, 1994].
The conceptual method-to-task framework as introduced for New KARL is also similar to the notion of task and methods in PROTÉGÉ-II ([Eriksson et al., 1995], [Gennari et al., 1994]). Especially the notion of a method ontology is taken from the PROTÉGÉ-II approach. Within PROTÉGÉ-II an ontology of mapping relations is defined for connecting methods and domains [Gennari et al., 1994]. Gennari et al. define for instance renaming mappings, filtering mappings, and class mappings. All these types of mappings may be described by the mapping operator map of New KARL. Thus New KARL provides means for formalizing the types of mappings which are used to relate a method ontology to an application ontology within the PROTÉGÉ-II framework.
The TASK approach [Pierret-Goldbreich, 1994] claims to be different from KADS approaches in dealing with flexible problem-solving and dynamic behaviour specification. TASK proposes three different languages for the conceptual, the formal and the implementation level respectively [Talon and Pierret-Goldbreich, 1996] - and by this suffers from the same disadvantages as described above. The strongest affinity between TASK and MIKE is on the formal level, i.e. between New KARL and the formal language TFL that is based upon abstract data types (ADT) [Pierret-Goldbreich and Talon, 1995]. ADTs are well-suited to specify the functional description of a PSM but they are insufficient to specify the operational part. This aspect, to treat the different parts of a PSM specification as one unit, is emphasized in New KARL. TASK ignores the specification of the operational part of a PSM - especially the control flow - because it considers methods as pre-built components that are configured during runtime via oppurtunistic reasoning. Similar to our approach TASK postulates the necessity to specify goals. This is also done in the framework of ADTs [Pierret-Goldbreich, 1996] but since goals are treated as separate entities that are linked neither to processes nor tasks it remains unclear how they can be exploited for reuse rsp. oppurtunistic configuration.
DESIRE ([Treur, 1994], [van Langevelden, Philipsen, and Treur, 1993], [van Langevelden, Philipsen, and Treur, 1992]) is a formal KBS specification language that also does not rely on the KADS model of expertise. DESIRE uses linear temporal logic with partial models to define the semantics of a reasoning process, whereas New KARL uses temporal logic to specify the input/output behaviour of an inference action. It is therefore not only directly possible to define the notion of a state change in New KARL, e.g. what should be true in the next reasoning step, but it is also possible to describe the semantics of the whole inference process in terms of a temporal Herbrand model. In DESIRE the specification of the input/output of a reasoning module is done by defining an input/output signature. New KARL has a more general approach: signatures are translated, but also entire formulae.
5 CONCLUSION
In this paper we presented New KARL, an extension to the language KARL. This extension provides the following advantages.
After having defined a new version of KARL, namely New KARL, current work is in progress to (i) define a complete formal semantics for New KARL which also allows to reason over the specification itself and to (ii) implement an interpreter for New KARL.
Acknowledgement
We thank Dieter Fensel and our anonymous referees for many useful comments and hints to earlier versions of this paper.