
INRIA Rhône-Alpes, 655 avenue de l'Europe, 38330 Montbonnot Saint-Martin, France Jerome.Euzenat@inrialpes.fr
ABSTRACT: The Co4 system is dedicated to the representation of formal knowledge in an object and task based manner. It is fully interleaved with hyper-documents and thus provides integration of formal and informal knowledge. Moreover, consensus about the content of the knowledge bases is enforced with the help of a protocol for integrating knowledge through several levels of consensual knowledge bases. Co4 is presented here as addressing three claims about corporate memory: (1) it must be formalised to the greatest possible extent so that its semantics is clear and its manipulation can be automated; (2) it cannot be totally formalised and thus formal and informal knowledge must be organised such that they refer to each other; (3) in order to be useful, it must be accepted by the people involved (providers and users) and thus must be non contradictory and consensual.
This "computer as medium" idea could be strengthened by extending it towards the knowledge itself. However, stating knowledge on computer medium is not enough for several reasons: it does not promote communication among individuals nor confrontation against standard or analysis tools. For that purpose, a computer environment called Co4 (for collaborative construction of consensual knowledge) is presented in (Rechenmann, 1993; Euzenat, 1995a). Three axioms about corporate memories are provided here for justifying the Co4 approach.
The first axiom of the approach is that knowledge must be stated as formally as possible. This has clear advantages since the knowledge can be given a semantics, can be manipulated by computers according to that semantics and properties of the repository (among which consistency and completeness but also subsumption) can be checked. However, not everything can and must be formalised and even if it were, the formal systems could suffer from serious limitations (complexity or incompleteness).
The second axiom states that it must be possible to wrap up a skeleton of formal knowledge with informal flesh made of text, pictures, animation... Thus, knowledge which has not yet reached a formal state, comments about the production of knowledge or informal explanations can be tied to the formal corpora.
The third and stronger axiom is that people must be supported in discussing about the knowledge introduced in the knowledge base. In this perspective, re-using, diffusing and maintaining knowledge should be a participatory activity of all the involved people (providers and users). Users will use the knowledge only if they understand it and they are assured that it is coherent. The point is to enforce discussion and consensus while the actors are still at hand rather than hurrying the storage of raw data and discovering far latter that it is of no help. The presented work is really cooperative: it is not restricted to give good or bad marks, but it tries to involve and commit each participant in the process. The objective is not to build a corporate record but to build a coherent corporate memory.
The Co4 (Euzenat, 1995a) system, which is presented here, is dedicated to the incremental and concurrent building of a knowledge base organising, around formalised knowledge, a set of various annotations (text, bibliography, image, experimental data, etc.). It should provide collaborators with support for, on one hand, expressing, annotating and manipulating their knowledge, and on the other hand, submitting it to other people.
To that extent we propose a protocol based on the agreement of every participant. It is based on formal rules inspired from the peer review process of scientific journals. Hence, instead of merely reproducing the paper journals in computers, the principles of scientific journals are applied to the knowledge formally expressed in a computer. The result should be a consensual knowledge base, i.e. which everybody in a group agrees to be a reasonable state of the art. It can be used for confronting new results and for learning new knowledge.
The knowledge expression formalisms and facilities are first presented (§1) before turning to consultation and modification of knowledge bases on the World-Wide Web (§2). Then the principles of the protocol for building knowledge bases and the way knowledge bases are related are given (§3). Afterwards, the definition of the protocol is briefly sketched (§4). The presentation aims at giving a global view of the system and how it addresses the problems raised above. More precise presentation of the tools can be found elsewhere -- Tropes (Sherpa, 1995), HyTropes (Euzenat, 1996) and the Co4 protocol (Euzenat, 1995b).
The design of these knowledge bases has led to the identification of four types of knowledge to be represented:
Descriptive knowledge on the biological entities involved is represented in an object-based knowledge representation system. This enables the representation of classes of objects (e.g. genes), subclasses (e.g. protein genes) and the identification of an object as belonging to such a class. In Co4, the descriptive knowledge is available in the Tropes system (Sherpa, 1995). The semantics of the system is given in set-theoretic terms and the operations (e.g. filtering, classification) respect it. Tropes is able to organise objects into multiple independent taxonomies and allows the user to work on a subset of these taxonomies. It thus satisfies the need to express several viewpoints on object classifications (Overton, Koile, and Pastor, 1990; Karp and Mavrovouniotis, 1994).
Methodological knowledge specifies the ways to select and link up methods for a given task. It is represented through a task management system able to integrate, represent, process and monitor the many computer programs for analysing the results of experiments. These tasks can be understood as executable KADS tasks (Schreiber, Wielinga, and Breuker, 1993) and are given a semantics in terms of problems and methods. They are organised along a specialisation (more abstract/more specific) link and a composition (task/sub-task) link. The composition can be expressed through various operators (e.g. parallelism, sequence, alternative). The methodological system is available through the Control system and will be integrated with Tropes under the name of TnT ("Task in Tropes").
Behavioural knowledge, which has not been introduced in the two knowledge bases above, concerns the modelling of dynamic phenomena, such as the dynamics of gene inhibition or activation, through a qualitative modelling system. Such kind of knowledge has already been used for representing metabolism (Karp and Mavrovouniotis, 1994). Behavioural knowledge is under study in the context of a knowledge base on the genetic regulation in the early development of the fruit fly egg.
Non formal annotations on the various objects and tasks involved are achieved through a hypertext system which connects hypertext nodes with the components of the descriptive and methodological knowledge. It allows browsing among texts, objects and tasks. The non formal (and especially hyper-textual) annotations are the subject of the next section (§2).
Some authors (Conklin, 1996) call formal knowledge the knowledge expressed in reports or recorded communication and informal knowledge the processes in a firm. As it can be understood from above, the process knowledge (as it seems better to call it) can be recorded and formalised as methodological knowledge.
As an example, change (for instance the destruction or addition of some objects in the base) is the most critical operation. It can seem obvious that the user may query and modify the base and that modifications must leave the base in a consistent state. However, the way this is achieved in Co4 is particular since it must work when the researchers want to communicate a part of their bases to another base. For instance, imagine that some user wants to add a particular task (a specialisation of the filter-network task called extract-paths which has as input a network of interactions and two genes and as output another network: the one which contains only interactions in paths from one of the genes to the other).
If the proposal is consistent with the base, the change is committed and the knowledge base is simply modified. But this can be otherwise, for instance because the user typed fiter-network instead of filter-network or because filter-network has a contextual-network as output while the user specified the more general Tropes class network for the new task. In such a case, the system is able to detect the problem: this is a first contribution for delivering trustful corporate knowledge.
However, the system is also able to reason on the knowledge and to help the user to repair some of these mistakes. For the first problem, a lexicographic corrector is sufficient for deciding that the closest task name is filter-network while for the second one a revision algorithm is necessary (Crampé and Euzenat, 1996). Such a module is able to propose several repairs to the user (e.g. restricting the type of output in extract-paths, expanding it in filter-network, making extract-paths a specialisation of a more generic task).
This ability to process formal manipulation of knowledge base is precious to the users of simple knowledge bases, however, it is invaluable to users who are not the authors of some pieces of knowledge (e.g. filter-network) involved in the problem.
Figure 1. The software architecture. Each box represents a software module, each circled unit is a data/knowledge repository and each arrow represents the call of a program functionality. The complete description is given here for being compatible with other pictures.
Having sketched a representation enabling the expression of formal knowledge, the connection with informal knowledge must be considered.
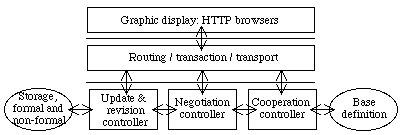
Figure 2. The base is accessed locally and remotely (through networks) via a HTML browser. This is achieved by the negotiation controller which handles HTML queries.
Knowledge bases can be used as WWW servers whose skeleton is the structure of formal knowledge (mainly in the object-based formalism) and whose flesh consists of pieces of texts, images, sounds and videos tied to the objects. Turning a knowledge base system into a WWW server is easily achieved by connecting it to a port and transforming each object reference into a URL. If the knowledge base is already documented by WWW pages, the latter remain linked to or integrated into the pages corresponding to these objects. Our old SHIRKA system was already able to link formal knowledge with pictures and texts through a proprietary hypermedia system; Tropes is provided with its HTTP server counterpart HyTropes (Euzenat, 1996). The link in term of Co4 is presented in figure 2.
The advantages of such an approach with regard to the previous proprietary hypertext systems are chiefly the availability of the knowledge base content to a wide and untrained audience. HyTropes has access to the internet, the internet has access to HyTropes but access can also be easily restricted to the so-called "intranet". However, other advantages are found in the consistency of the base (for instance, there is no dangling link since the skeleton is generated automatically and formal information is maintained sound).

Figure 3. Presentation of a viewpoint and the gene class from a Tropes version of the ColiGene knowledge base (Perrière and Gautier, 1993).

Figure 4. Filter and instance WWW page from a sample real estate knowledge base.
HyTropes makes filtering and classification queries available. Actually the whole Tropes API is subject to "URLising". So the next step will consist in publishing the URL rules (far simpler than the URL generated by the FORM tag) in order to enable any other application to:
Some independent knowledge bases can subscribe to group bases as observers: these bases are sent by the group base whatever is introduced in the knowledge base but cannot modify it. Observers are not considered further in this presentation.

Figure 5. Hierarchical architecture and message flow (dark arrows). Bases are organised in a tree whose leaves are individual bases and nodes represent consensus between the connected individual bases.
Group bases have the same structure as individual ones: they are made of the same pieces of software. The main difference between group bases and individual workstations is that the former are completely automated and only respond to stimuli from other bases: they do not require human assistance.
Bases are linked together in such a way that a particular base knows its subscribers and its group base. These links are in fact virtual and are implemented by the flow of messages from one base to another. To its subscribers a group base mainly sends messages for broadcasting a change accepted by everyone and calls for comments in order to establish whether a change must be committed or not. The other way, a (group or individual) base sends to its group base changes which it wants the group base to integrate. Of course, any base, as a group base, also receives changes to commit and as an individual base also receives calls for comments and change broadcast.
Consistency and formality require more strictness in the protocol than pure peer-reviewing; this leads to the consensus requirement (i.e. in which, a modification, for being accepted, must have been agreed by all other members -- for instance, in the context of genome sequencing, a consensus map is a map that people involved in the research field think correct). Integrating knowledge goes through the process of submitting knowledge to the base, of letting it be reviewed by the other participants and of accepting or amending it according to their reactions. Informal knowledge is also subject to submissions, reviewing and so on. This protocol works at several levels: the group bases can be grouped together into a more important group base and so on. However, the behaviour of such a group base is still subject to the consensual approbation of its subscribers. Thus, for instance, a consensual representation could be achieved inside a particular firm before being submitted to the inter-institution base.

Figure 6. The base definition contains the situation of a base inside the tree of bases. It thus stores the addresses of group and subscriber bases. When a problem occurs, the negotiation controller has the choice between displaying it on a HTML browser (individual base) or passing it to the cooperation controller which sends it to the subscriber bases (group base).
In a first version of Co4, the group base applies non destructive modifications without discussion. These modifications are always possible in the group base, since they are in the subscriber base which contains it. In the case of destructive modifications, a call for comments, identified by a unique number, is issued to every subscriber. Among the answers provided by the subscribers, three cases may happen:
So let briefly see how to connect a base and submit knowledge.
As soon as the base is part of a group base, it receives the complete contents of that base (to which it is supposed to subscribe), it is entitled to give its opinion on all submissions currently under examination and is allowed to submit knowledge. The interesting point is the submission of knowledge which is described right below.
The consultation or modification is initiated through the graphic interface and directly processed by the revision controller. However, in the usual mode, the modification is prepared by a confrontation query which asks for a comparison of a new piece of knowledge (made of objects, tasks, hypertext nodes and qualitative equations) and the knowledge base. The comparison of a corpus of knowledge with another results in a report about what is different, what is the same and what is contradictory. If the piece of knowledge does not contradict the knowledge base, it can be submitted for integration. If it contradicts it, the researcher can modify it in order to fit the group base. Concerning the informal documentation, if, for instance, the user wants to create a hypertext node it is possible to detect if a node with the same name already exists and to negotiate its modification.
When the subscribers are confident enough with some pieces of knowledge, they can submit them to the group knowledge base to which they subscribe. This is achieved by circumscribing the submitted part (which can include hypertext annotations justifying them) and calling the submission procedure of the negotiation controller. In order to complete the submission message, the negotiation controller collects the sets of differences between the consensual group base connected and the selected changes (they are logged in by the revision controller) and sends them to the group base. Usually, the group base, through its own revision and negotiation controllers, issues a report describing how the submitted knowledge can be added to the group base. Thus, as usual, the user can choose a better (and consistent) way to achieve the submission. This proposal will be submitted to the other subscribers and committed if it reaches consensus.
As a subscriber of the group base, the user also receives the call for comments issued by the group base in response to the submission of some material. Users can read the submission or apply it in their own knowledge base by submitting it to the revited when they consider that the knowledge must be integrated in the consensual knowledge base, rejected when they do not, and alternate when they propose another change.
When the group base has gathered enough comments, it integrates, or not, the change in the base. The change being now consensual, it is broadcast to all subscribers. It may happen, however, that the research they are currently involved in contradicts what is in the group base. So users can refuse the new piece of knowledge (just as they can modify parts of the group base knowledge in their local base) which is then stored in a change logbook for further change submission.
The fact that anyone can maintain a knowledge base different from the consensus obviously allows the exploration of alternative paths. On a more basic ground, it enables communication, negotiation and acceptation to be asynchronous. This reproduces the way papers are submitted, discussed and accepted or rejected in a scientific journal: reviewers can take time for carefully examining a proposal since it will not stop the work of the base which issued it.
The messages sent from one base to another are expressed through a speech act (loosely inspired from "speech act theory"). Speech acts are used here for building a set of relevant "artificial" acts rather than trying to understand the "natural" speech acts occurring in ordinary conversation (in the same way that grammars have been borrowed by computer science from linguistics). Each particular act carries a precise semantics (taken as the goal of the sender). The notion of a speech act has several advantages for the particular architecture presented here:
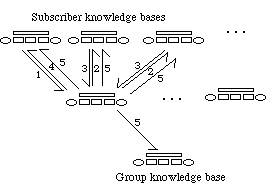
Figure 7. Downward policy: how a group base processes an initiative from a subscriber.
A policy can be schematised by a picture and a table. In the picture (see figure 7), arrows represent messages; numbers labelling them are a stratification of their occurrence order. All the messages carrying the same number must have been sent before the arrows carrying the successor can be instanciated. The table (see table 1) provides the name of the performative of each message in each instance of the policy (e.g. for subscribing or submitting a piece of knowledge the performative initiating the conversation is not the same). The arrows may or may not be instanciated. Moreover, additional communication may happen between two stages (for instance a group base which receives a call for comments, initiates its own call, and replies to the former only when the latter reaches completion).
| downward policy | subscribe | submit | forward |
| 1: query | register | achieve | forward(P) |
| 2: call | ask-all | ask-all | ask-all |
| 3: vote | reply | reply | reply |
| 4: report | notify | notify | notify |
| 5: commit | tell | tell | P |
For downward policy, there are 5 stages which can be instanciated in three distinct processes. For instance, the submission is achieved through (1) a base sending an achieve message to its group base, (2) a call for comments emitted with the ask-all message from the group base to its subscribers, (3) a reply from the subscribers to the group base accepting or rejecting the proposal (which corresponds to their vote for or against the proposal), (4) a notification of the issue to the initial sender and (5) the introduction in the group base of the proposal and a broadcast of this to all the subscribers with the tell performative.
The same stages are found in the upward policy (see figure 8 and table 2) but they do not correspond to the same set of arrows. For instance, a broadcast is achieved through (1) the tell message considered above, (2) a call for comments to all the subscribers (for group base), (3) the same reply as above from the subscribers, (4) nothing in that case and (5) the introduction or not in the base of the content of the message and its broadcast to the subscribers (through a new tell).
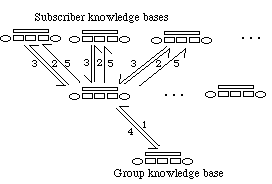
Figure 8. Upward policy: how a group base processes an initiative from its own group base.
| upward policy | call | broadcast | retract |
| 1: query | ask-all | tell | deny |
| 2: call | ask-all | ask-all | deny(ask-all) |
| 3: vote | reply | reply | |
| 4: report | reply | ||
| 5: commit | tell |
An additional policy is used for the deny performative which depends on the wrapped performative and exactly undoes what the performative does and the usual policy for evaluate/reply is used.
The consensus aspect is dealt with through the acceptation of proposals which achieve acceptance from every subscriber and the rejection of other proposals. Consensus could be replaced by some other definitions (like majority or intersection, see §4.1), but it has been retained for two reasons: (1) it enjoys interesting formal properties (if a consensual base contains only knowledge which is accepted by all the subscribers, this remains true if subscribers are added or retracted), and (2) it should lead to the discussion of proposals -- not only conflicts -- and thus the collaboration of the researchers. However, this does not mean that there is no conflict: the conflicts are to be treated by negotiation between the providers and the users of the knowledge (note that the hierarchy of bases allows to structure the discussion by circles).
So the knowledge stored in group knowledge bases is correct, consistent and consensual. This is in great contrast with what is currently developed over the networks: databases available through WAIS, Gopher or WWW do not have to be consensual nor consistent. Data are provided as such, without any warranty of consistency from the provider, and the retrievers have to make it consistent before introducing it into their own databases. Other frameworks are also different in this respect: neither the knowledge sharing (when the opportunity to modify the shared knowledge is considered) nor the software agents provide any warranty about the consistency of the knowledge they provide.
Difficulties with the cooperation protocol can arise from the fact that it must be closely suited to the needs of cooperative knowledge base building. Otherwise, subscribers would work around it. The ideal protocol should be mechanically interpretable (at least at the performative level) and rich enough for covering adequately all of the needs. The first requirement has been successfully achieved through the design of an automatic group base protocol. However, our present protocol is very simple (only 35 rules). It must be enhanced through experience and some assumptions may have to be relaxed. For instance, it does not take into account the demand from a reviewer to clarify some point.
The Co4 protocol has some limitations since the communication protocol is very restrictive. These limitations are usually found in the manual peer review process (however, the same protocol does not prevent people from submitting to, reviewing for and reading scientific journals). There is still debate for knowing if peer review for scholar literature is the correct behaviour in the electronic age (Peters, 1995) and the answer will not be given here. The issue of authentication of the contributions could be ensured by the obligation of citing the sources in the hypertext annotations; this should be facilitated by the availability of a citation editor in Co4 and a contribution tracing mechanism (authentication of who proposed a modification and who issued an alternative proposal). Other enhancements are deadlines -- for returning answers, etc. (Winograd, 1987) -- penalties -- for these reviewers who take a very long time for reviewing (for instance, suspension of their submissions) -- and an anonymity management system which provides both independence and recognition to reviewers (Stodolsky, 1990).
The knowledge base architecture presented above includes two particularly interesting design choices: it is the same for all of the bases, so they can be made out of the same software packages, and it is described in a modular fashion, so that it can be used with a very raw system or a very complex one. This leaves the door open for a trade-off between the complexity and power of each algorithm used. The Co4 protocol development should take advantage of this since it allows to start with very simple components and to enhance them progressively.
For instance, the knowledge repository can be a simple hypertext system which identifies nodes by a reference and raises an error when two nodes have the same reference (the simplest system is a text repository with the UNIX "diff" and "patch" utilities). The degré zéro of change control consists in routing error messages to the user, in order to have the error corrected.
Nonetheless, the protocol can be easily replaced by another one, based for instance on a vote of the majority of the subscribers, on the intersection of all of the knowledge bases or on economic decision making (for determining the introduction or not of knowledge into the base). The protocol is also designed independently of the content and language of the knowledge base. This enables to use it for different pieces of knowledge (hypertext or classes as well as tasks or equations). One could imagine to refine the protocol for dealing specifically with these expressions. However, the specific aspect is actually assigned to the revision module which issues the reports.
As a summary, the architecture and the protocol provided above are independent of the knowledge repository and the modules which manage it.
Corporate memory is not a clearly defined word. For some people, it consists in integrating the information system of an enterprise. This is usually carried out with the help of software which allow to publish the databases and software for accessing these publications (Huhns, Jacobs, Ksiezyk, Shen, Singh, and Cannata, 1993; Collabra, 1996). The knowledge is usually modified by a unique authorised person and consistency is not ensured. However, there is no acknowledged conflict in such systems. For others, corporate memory essentially contains the memory of how the enterprise works (Durstewitz, 1994; Conklin, 1996). This includes structure, work flow, information pathways and interaction protocols.
These approaches are clearly useful. The former allows the wide dissemination of the information -- as does the HyTropes system -- but it is not sufficient for ensuring the cohesion of the knowledge and its acceptance by other people. The latter has the advantage of considering the context of knowledge production and use. This is clearly a very important topic complementary to the present work. Paying attention to the socio-psychological effects of such a memory should greatly facilitate its acceptance. However, we did not focus on that particular aspect.
The present work is concerned with a third approach which considers that the corporate memory must contain the knowledge which underlies the behaviour and work of individual people. This knowledge must be the common understanding of the people in a corporation. It is thus more related with the acquisition of a shared ontology (instead of a system for sharing an ontology otherwise built).
The Co4 principle is similar to that of the Shade project (Gruber, Tenenbaum, and Weber, 1992) which builds a knowledge medium to support the collaborative design of an artefact; in Co4 the artefact is the knowledge base. Such a system must enforce both the consistency and the agreement of everyone (human or software agent) involved into the design process. However, there are several technical differences between both systems:
ICM (Fruchter, Clayton, Krawinkler, Kunz, and Teicholz, 1993) is another related system which uses the cycle "propose-interpret-criticise-explain" for the same purpose: confronting knowledge. The system is dedicated to architectural design and tries to make people of different professions communicate through graphic layout. The system aims at filling the gap between very expressive CAD drawing tools lacking semantics and formal knowledge base systems lacking intelligible drawing capabilities. So, the drawings are translated into symbolic representations that the system can manipulate. It can also elaborate critics (when confronting two viewpoints) and report these critics on the display. It thus differs from Co4 since (1) it considers that the drawings can be translated to a symbolic level and back and (2) it provides the critics by itself while Co4 lets the users generate an important part of them. The two points are related since a critic can only be developed on formal requirements while Co4 accepts totally informal knowledge. In summary, ICM focuses on informal communication of formal knowledge.
At another extremity (formal protocol for informal knowledge communication) Co4 shares some features with the coordinator (Winograd, 1987). The coordinator is a system which allows people to submit requests and offers to others who can answer by declining, accepting or proposing an alternative. The system is able to store these proposals and to manage the state of each proposal. The main differences lie in the goal of building a consensual knowledge base (common to each individual), the formal treatment that Co4 can apply to knowledge and the hierarchical construction of knowledge bases (and hence of the communication) instead of peer-to-peer communication. The Co4 protocol also resembles argumentation protocols like IBIS (Kuntz and Rittel, 1970). However, two important differences must be noted: the proposals are not questions but answers that someone wants to integrate in a base and Co4 does not primarily aim at recording the argumentation process but the result of the process. Meanwhile, the IBIS framework could be used for structuring the discussion between subscribers and recording the decision rational.
Another system has been set up for supporting the peer review process (Mathews and Jacob, 1996). It supports the material aspects of the process and corresponds to the base protocol here. In fact, it sticks closely to the real process in which the peers are not so preoccupied by constructing a common memory (or artefact).
The originality of the system are mainly:
The system presented here is either implemented in separate parts (Tropes and HyTropes are separated from the task system) or under implementation (behavioural knowledge or the Co4 protocol). The implemented parts have been used in molecular biology projects (representation of genetic regulation in D. melanogaster for HyTropes and sequencing projects for the task system). Achieving a working Co4 system requires more investigation on the aspect of formal revision and the full and modular implementation of the Co4 protocol. However, such a system is not an end and it will have to prove its usefulness through real-life experiments. Beside pursuing work on molecular biology, the construction of a corporate memory from actual design processes is under way and the Co4 protocol will be tested on collaborative paper writing.
The technical aspects of the available Tropes server are presented in the HyTropes home page together with demonstrations of the program and the sources.
Conklin, J. (1996). Designing organisational memory: preserving intellectual assets in knowledge economy, White paper, Corporate memory systems, Austin (TX US), 1996 http://www.cmsi.com/business/info/pubs/desom/index.htm
Crampé, I., and Euzenat, J. (1996). Révision interactive dans une base de connaissance à objets, Proc. 10th RFIA, Rennes (FR), pp615-623 ftp://ftp.inrialpes.fr/pub/sherpa/publications/crampe96a.ps.gz
Durstewitz, M. (1994). Newsletter on corporate memory, Internal memo, Eurisko, Toulouse (FR) http://www.delab.sintef.no/MNEMOS/external-info/cm-eurisko.txt
Euzenat, J. (1995a). Building consensual knowledge bases: context and architecture, in Mars, N. (Ed.), Building and sharing large knowledge bases, pp143-155, Amsterdam (NL): IOS press ftp://ftp.inrialpes.fr/pub/sherpa/publications/euzenat95a.ps.gz
Euzenat, J. (1996). Knowledge bases as Web page backbones, Proc. 5th WWW workshop on <<artificial intelligence-based tools to help W3 users>>, Paris (FR) http://www.inrialpes.fr/sherpa/papers/euzenat96a.html
Farquhar, A., Fikes, R., Pratt, W., and Rice, J. (1995). Collaborative ontology construction for information integration, Research report 63, Knowledge system laboratory, Stanford university, Stanford (CA US) ftp://ksl.stanford.edu/pub/KSL_Reports/KSL-95-63.ps
Finin, T., Fritzson, R., MacKay, D., and MacEntire, R. (1994). KQML as an agent communication language, Technical report CS-94-02, University of Maryland, Baltimore (MD US) (rep. in proc. 3rd CIKM, Gaithersburg (ML US), 1994) http://www.cs.umbc.edu/kqml/papers/kqml-acl.ps
Fruchter, R., Clayton, M., Krawinkler, H., Kunz, J., and Teicholz, P. (1993). Interdisciplinary communication medium for collaborative conceptual building design, Proc. 2nd conference on the application of artificial intelligence techniques to civil engineering, Edinburgh (GB), pp7-16 ftp://cdr.stanford.edu/pub/CDR/Publications/Reports/ICM.ps
Gaines, B. (1990). Knowledge-support systems, Knowledge based systems 3(4):192-203
Gaines, B., and Shaw, M. (1995). WebMap: Concept Mapping on the Web, Proc. 4th WWW conference, Boston (MA US)
http://ksi.cpsc.ucalgary.ca/articles/WWW/WWW4WM/
Gruber, T., Tenenbaum, J., and Weber, J. (1992). Toward a knowledge medium for collaborative product development, in Gero, J. (Ed.). Proc. 2nd. international conference on artificial intelligence in design, Pittsburg (PA US), pp413-432
ftp://ksl.stanford.edu/pub/knowledge-sharing/papers/shade.ps
Huhns, M., Jacobs, N., Ksiezyk, T., Shen, M.-W., Singh, M., and Cannata, P. (1993). Integrating enterprise information models in CARNOT, Proc. 1st international conference on intelligent and cooperative information systems, Rotterdam (NL), pp32-42
Karp, P., and Mavrovouniotis, M. (1994). Representing, analyzing and synthesizing biochemical pathways, IEEE Expert 9(2):11-22">
http://www.ai.sri.com/pubs/papers/Karp94-11:Representing/document.ps.Z
Médigue, C., Vermat, T., Bisson, G., Viari, A., and Danchin, A. (1995). Cooperative computer system for genome sequence analysis, Proc. 3rd ISMB, Cambridge (GB), pp249-258">
ftp://ftp.inrialpes.fr/pub/sherpa/publications/medigue95a.ps.gz
Peters, J. (1995). The hundred years war started today: an exploration of electronic peer review
http://www.mcb.co.uk/literati/articles/hundred.htm
Rechenmann, F. (1993). Building and sharing large knowledge bases in molecular genetics, in Mars, N. (Ed.), Building and sharing large knowledge bases, pp291-301, Amsterdam (NL): IOS press
ftp://ftp.inrialpes.fr/pub/sherpa/publications/rechenmann93.ps.gz
Rees, O., Edwards, N., Madsen, M., Beasley, M., and McClenaghan, A. (1995). A Web of Distributed Objects, Proc. 4th WWW conference, Boston (MA US), pp75-87
http://www.ansa.co.uk/ANSA/ISF/wdistobj/Overview.html
Sherpa project (1995). Tropes 1.0 reference manual, Internal report, INRIA Rhône-Alpes, Grenoble (FR)
ftp://ftp.inrialpes.fr/pub/sherpa/rapports/tropes-manual.ps.gz
Stefik, M. (1986). The next knowledge medium, AI magazine 7(1):34-46