In a multi-agent environment like the one we envision, ontologies maintained and distributed by ontology servers act as open-ended "dictionaries of words" describing common application areas and allowing consistency among the programs that have to communicate about those areas. Modularity reasons suggest to partition large ontologies into many theories related by inclusion links (that is, a theory can include the definitions of other ontological theories thus forming a larger theory). As already mentioned, there will also be multiple ontologies, alternative or even incompatible ones, to describe the same application area, for example from a different perspective or with a different granularity [Falasconi and Stefanelli, 1994]. Thus, the ontology server will store and manage a true library of ontologies made available in a distributed fashion.
While ontology specification is best performed using a standard language, the definitions must be enforced in a system-specific way within the various agents. For example, a portion of an application ontology may be used to generate, in an automated or semi-automated way, the database view of the DMA or the graphical Knowledge Acquisition Tool needed for the construction of a RMA. Translation or mapping facilities are needed from the language used for ontology specification in the server to different knowledge/data structures or user-interface graphical forms.
The ontology server differs from a "data meta-model" agent containing meta-data about the schemata used by collaborating databases: like a conceptual schema, an ontology provides a logical description of the stored information, allowing different application agents to interoperate independently of internal representation structures; but an ontology is not meant to be complete or exhaustive. On the contrary, it should try to capture the minimal common conceptual model for a set of interoperating agents, allowing them to instantiate, specialize or extend the specified definitions. The ontology server differs also from a terminology server, in that it isn't intended as an extensive repository of standardized controlled vocabularies, or an intermediary to such vocabularies, but as a repository of special-purpose, though reusable, concept definitions. Anyway, while writing an ontology, the consultation of a standard or agreed-upon domain terminology is recommended at least for comparative purposes.
Some attempts to enable computer-assisted medical terminological modeling and automated classification were undertaken, relying on existing extensive standard medical terminologies [ICD9-CM, 1991; SNOMED, 1982; MeSH, 1994]. They often superimpose a well-defined and enforced general categorization to "flat" terms repositories. This is the case of the MED (Medical Entities Dictionary) [Cimino et al., 1994], that reuses and extends the semantic types of the UMLS [Lindberg et al., 1993] to build a hierarchical semantic network of frames with slots, and of GALEN (Generalised Architecture for Languages, Encyclopaedias and Nomenclatures in Medicine) [Rector et al, 1995], that provides a compositional formalism, GRAIL (Galen Representation and Integration Language) allowing the modeller to specify concepts and relations.
These two advanced approaches to medical terminological services show significant common features. The most evident is the already mentioned semantic foundation on a central system of formal concept definitions, explicitly referred to as ontology in the GALEN effort. The representational framework of such terminological ontologies makes direct reference to the semantic network model, and uses formalisms and control tools (e.g. consistency checkers) not tested outside clinical domains. Radical changes to the core medical ontology would probably result into unpredictable ill-functioning of the systems. A second common characteristic is the necessary distinction between the (data structure representing the) concept and the (text strings representing the) names assigned to medical terms in various nomenclatures and natural languages. Even in the context of a single tongue, typical linguistic phenomena inducing ambiguity, such as homonymy and synonymy, make it mandatory to draw a clear boundary line between these two kinds of objects, so that it becomes allowed to exploit multiple and possibly evolving classifications of terms, that is locutions in use within an "external" clinical community, into concepts, which are true "by definition" in a (modestly expressive) syntax established by system developers. A third feature is the limited amount of inference modeling and execution, mostly pertaining to some forms of "terminological reasoning" (like proper automated classification) and natural language processing (e.g. lexical analysis).
In contrast with the single conceptual model approach of the above mentioned terminology servers, a networked ontology server essentially plays the role of an ontological library manager and distributor. Besides providing means for ontology editing, refining and storing (as done in a distributed collaborative fashion by the Stanford server [Farquhar et al., 1995]), and besides being able to preserve application ontologies consistent, the ontology server should maintain even inconsistent ontological theories in the library, keeping track of their inter-relationships, also through the exploitation of the previously described categorization of ontologies.
So far, it's quite apparent that the functionalities we envision an ontology server should provide rely upon different assumptions from those underlying the terminological services described above. The idea of an ontological library not only entails the maintenance of a plurality of possibly inconsistent conceptualizations for the same domain, but also accounts for the coverage of non-clinical domains. For example, in an agent-based D-HIS the specification of some economics in an ontological theory complying with the health care administrator's view of the world becomes necessary. The already mentioned conceptualization for health care economic evaluation analyses represents a first step in this direction. The choice of Ontolingua, devised as an interlingua among multiple representational paradigms and formalisms, largely copes with the structural complexity and expressive power required for ontology specification. As a consequence, enabling the enforcement of the stated ontological commitments constitutes a main burden on the translation modules that must be carefully designed and tested. Also, being an ontology intended as a conceptual foundation for general representational terms (that is, the terms upon which the representation of data/knowledge hinges), not restricted to natural language words (though often conforming to them), the explicit representation of the distinction between concept and name is no longer mandatory. For example, many relationships found in existing knowledge bases lack a corresponding natural language term and are included for pure representation convenience.
Of course, Ontolingua offers distinct notations to designate the name (a quoted symbol like `disease) and the term denoting an object in the conceptualization (disease), but the creation of both in a theory occurs simultaneously through the same definition operator (e.g. define- class). The management of conflicts, due to homonymy, synonymy, and similar phenomena that may occur in the "artificial namespaces" resulting from the combination of the ontological views of a plurality of agents wanted to interoperate, still represents an under-tackled problem. The solution employed in the recent tools exploiting Ontolingua [Farquhar et al., 1995], treating ontological theories like symbol packages in Common Lisp, while eliminating name conflicts for concepts defined in theories, shifts the problem onto the management of theory names.
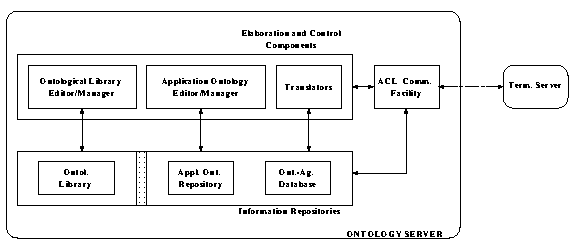
Figure 6: The architecture of an ontology server.
Agent components are specialized into functional
submodules addressing ontology creation, refinement,
storage, translation and coupling with agents.
Fig. 6 shows the main architectural components an ontology server needs to perform the activities previously identified. The schema reproduces the general software agent model (see Fig. 1) at a higher level of detail, emphasizing some functional modules and interaction paths. Among the elaboration and control agent components, specialized modules address the management of the library ontologies and of the application ontologies supported within the networked HIS, ensuring the correctness and consistency of the definitions in a theory. The repositories holding these two kinds of ontologies are placed in distinct areas of the agent's information storing submodule, as the Ontological Library will be mainly manipulated off-line, while application ontologies, once constructed from library theories with the proper editor, are destined for constant use and reference in routinary inter-agent transactions. In general, there will be at least as many application agencies supported in the HIS as the number of "active" application ontologies. Of course, different application agencies may rest upon the same physical systems (for example, the same clinical database can be accessed by a plurality of Data Management Agents), but each agency results semantically and operationally founded on a suitable ontological specification. We could consider the inclusion of a new application ontology in the on-line database (referenced as Application Ontology Repository in Fig. 6) as the "registration" of a further set of capabilities (at least in terms of an enhanced interaction vocabulary) into the distributed architecture.
The "on-line zone" of the information repositories may also provide support for another service the software agent could carry out. In a HIS characterized by a plurality of application agencies, such as the prototypical ones previously mentioned, the ontology server could keep track, in an Ontology-Agent Database, of the relations between an application ontology and the agents committing to it (that is, keep track of which portion of an application ontology is referenced or enforced by which agent). For example, it will record which agent is in charge of diagnostic reasoning activities within a physician agency: in our agency conceptualization, it will store that particular RMA is able to perform the diagnosis task. In this way, the ontology server could reply to queries involving ontology-agent pairs, and also help routing the messages along the network on the basis of a content-level message analysis. The content portion of a query message, for example, will mention the objects and relations in a conceptualization shared by asking and answering agents. Also, the organizational roles played by the running agents, according to the adopted health care organization model, included as one of the active ontologies (to which each agent commits) in the Application Ontologies Repository, are intended to be stored in the Database, so that the server is enabled to answer queries involving agents' general competence and their dependence relations. Such structural information could be of great help for performing content-independent message routing (that is, based only on the desired receiver's role) or to reduce the set of possible receivers before analyzing message content.
Thus, while the library editor manages the relationships among multiple reusable ontological axiomatizations, the application ontology editor manages the relationships between "active" ontologies and members of application agencies, allowing the ontology server to act as a mediator in the community of software agents [Takeda et al., 1994]. Unlike facilitators [Genesereth, 1992], that gather the entire message handling activity for a subset of agents, the ontology server could carry on only a partial, semantically founded mediation, as application ontologies don't necessarily constitute full conceptual models. That is, when an agent doesn't know in advance which its proper partners are and where they are exactly located on the network (as it may occur if the agent needs collaboration outside its application agency), it can seek help from the ontology server, that, once provided with a list of ontological definitions, or at least with the domain area of interest, could find out, thanks to the links relating application ontologies to original theories in the library, the possible recipients of the agent's query. These could be obtained, for example, by identifying, traversing class hierarchies, a common ancestor for definitions in two application ontologies, and then querying the database for the associated agents.
To make an example, consider the case of a physician in need to know the plausibility of the presence of rare diseases, outside his/her strict competence, given the patient's current condition. The list of suspect symptoms and findings, along with the indication that replies to its undirected (that is, with no recipients designate) request belong to the disease category and imply diagnostic abilities, can then be sent to the ontology server. Assuming that the core medical domain ontology is included by all the physician application agencies, therefore sharing the same general definitions for finding, disease and diagnosis, the server could firstly discriminate the agencies whose organizational role include the specialized physician one and whose application ontologies indicate diagnostic abilities, and then identify, traversing finding subclasses and possibly looking for instantiations corresponding to the received finding names (assuming a shared conventional finding-disease nomenclature) the set of agencies (besides the requesting one) handling such findings in a diagnostic task context. It could finally forward the original query to the set of candidate recipient agents, each one of which, after processing finding values, will give its response, a more or less meaningful one, directly back to the query originator. The latter, after evaluating the significance of the replies (for example, evaluating successful replies with respect to its own processing results), could devise the suitable recipient(s) for subsequent queries. Of course, for some phases (typically the initial and final ones) of this interaction sessions the intervention or supervision of the human users will be required.
Also, through the exploitation of this functionality, a couple of ontology servers, sharing the same ontology specification language, could act as "front-ends" for their respective HISs, mediating non- local message exchanges.
Besides the mentioned information types, the database should record, for each ontology-agent pair, the formalism into which the former must be translated in order to be enforced within the latter. As already stated, ontologies must be converted into target representation schemes (the so-called Ontolingua "implementations") to acquire actual validity in working agents. If the HIS shows a limited variability in the representational formalisms employed, as will often be the case, the translation modules can be incorporated into the ontology server, and be engaged to properly translate, exploiting information from the database, portions of an application ontology for the components of a HIS agency. Most times, they will perform only a partial conversion, due to mismatches in expressive power between Ontolingua and target languages. Of course, the outputs of the translation processes must be "wrapped" by ACL expressions (identifying e.g. the receivers) before they are sent out on the network. Obviously, such an information flow is intended as bidirectional: the reconstruction of inverse routes is conceptually straightforward.