2. Knowledge-Based Systems and Reuse
Beginning with the notion of reusable generic tasks (Chandrasekaran, 1983; 1986), researchers in knowledge-acquisition have worked to build knowledge-based systems from reusable components. As we will see, there are a number of different ways in which a knowledge-based system can be divided into components. At the highest level, the system contains just two components: the problem-solving method and the knowledge base. Both components should be reusable: The problem-solving method should be applicable to a set of related domains, and the knowledge base should support a number of different problem-solving methods (Gennari et al., 1994).
In addition to those who argue for the reuse of these large-scale components, a number of researchers support the idea that problem-solving methods themselves are decomposable into smaller-grained reusable components (Steels, 1990; Tu et al., 1995). For the PROTÉGÉ-II project, a decomposable problem-solving method is viewed as in
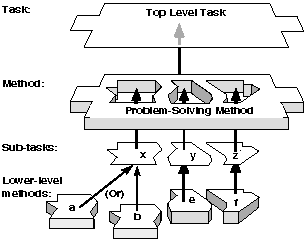
Figure 1
(Walther et al., 1992; Eriksson et al., 1995). This figure shows a top level task, or problem description, being matched by some problem-solving method. This method might be either custom-developed for this particular task, or it might adapted from an existing problem-solving method in the library. In either case, the method should be decomposable: in
Figure 1,
the method is shown as decomposable into three sub-tasks, {x,y,z}. In turn, these sub-tasks need to be matched to lower-level problem-solving methods. The degree to which a method is decomposable is dictated by the amount of reuse expected: The aim is to share the lower-level methods that solve general-use tasks, such as the methods {a,b,e,f} in
Figure 1, that implement the tasks {x, y, z}.
Figure 1
A decomposable problem-solving method. A task is matched with a problem-solving method, which can then be decomposed into subtasks {x, y, z}, which can be implemented by a variety of different lower-level problem-solving methods {a, b, e, f}.
For any type of reuse, components must be described in an abstract fashion to allow developers to find and understand components in a library; the abstractions act as indexes used to search the library of components. For knowledge-based systems, these abstractions are represented in ontologies (Gruber, 1993; Guarino & Giaretta, 1995). An ontology is a model for the component; For example, a domain ontology is a set of hierarchically organized classes that model the information in a knowledge base. A method ontology serves the same purpose for a problem-solving method, describing the inputs and outputs used by the method. Our aim is to build a large library of method and domain ontologies so that developers can access and reuse knowledge bases and problem-solving methods. As we will see, the CORBA 2.0 specification is also aimed at the construction of large libraries of components. Thus, we argue that methods and knowledge bases should be implemented as CORBA components.
3. CORBA: Reuse and Distributed Computing
Although a full description of the CORBA effort is beyond the scope of this paper (for example, see Orfali, Harkey & Edwards, 1996), we will give a brief presentation of the main ideas, highlighting those aspects that mesh tightly with ideas about reuse in the context of knowledge-based systems.
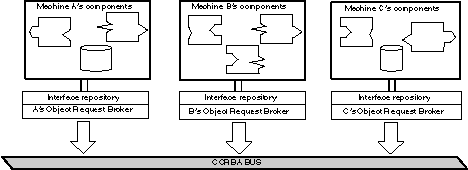
Figure 2
provides a very high-level view of a CORBA implementation of components. At the bottom of the figure is the CORBA Bus, representing the network of machines with CORBA-compliant object request brokers (ORBs). Any developer makes his or her component available for reuse by registering the component into the local interface repository. A naming convention scheme is used to ensure unique component names across the CORBA bus. As part of this registration process, the developer must describe the component with an interface definition language (IDL) specification. In Section 5, we describe IDL specifications in more detail, and contrast them to ontologies for knowledge-based systems.
Figure 2. The CORBA approach to distributed components. Any component may request services from any other component that is registered in a CORBA-compliant interface repository.
As an example of interoperation across this bus, suppose there exists a knowledge bases of medical diseases, symptoms, and literature citations that are linked to particular diseases. Developer A, a C++ programmer on machine A, wishes to build a special-purpose statistical analysis program that looks at the relationship between diseases and the citations that are linked to those diseases. As part of this program, Developer A needs to call a subroutine that does some form of cluster analysis. Developer A happens to know that Developer B (on machine B) has already built an efficient cluster analysis routine. Although this routine is written in SmallTalk, it is written in a generic fashion, and is available as a reusable CORBA component. Thus, Developer A can make remote calls to this cluster analysis routine from within the code for statistical analysis. When Developer A is done, he or she registers the statistical analysis code as another CORBA component, so that developers on machine C or elsewhere, can analyze different knowledge bases of diseases and literature citations. Note that this approach blurs the distinction between server machines and client machines: The statistical analysis component on machine A is both a server, for developers on machine C, and a client, for the cluster analysis component on machine B.
The match between this model and the ideas for decomposable problem-solving methods shown in
Figure 1
should be clear. As we will show in greater detail in Section 5, the lower-level generic methods in
Figure 1
can be implemented as CORBA components, allowing developers of knowledge-based systems to plug-and-play the components as needed for particular tasks. In addition, the CORBA infrastructure allows for distributed computing and platform independence. Thus, components to be reused need not be imported into a local environment. In some situations, distributed computing can create run-time inefficiencies due to network costs. For example, a call from a client at machine C to the statistical analysis component on machine A must go through C's ORB, across the network to A's ORB, and then likewise travel between machine A and machine B (when calling the cluster analysis subroutine), before finally returning solutions back across the network to machine C. However, these run-time costs are usually balanced by the benefit of decreased installation and maintenance costs: If a CORBA component resides on a single machine, its maintenance costs are amortized over the set of all clients that use that component.
For developers of knowledge-based systems, the primary value of CORBA is its ability to provide a standard for communication among a library of sharable, platform-independent components. In the next section, we provide three examples of knowledge-based systems reuse, where components are implemented to use the CORBA standard for interoperation and reuse.
4. KBS Reuse Scenarios with CORBA
In a large knowledge-based system, there are a number of different opportunities for the reuse of components. In this section, we present three distinct scenarios for reuse; each describes a different situation in which the development of knowledge-based systems would benefit from a CORBA implementation of reusable components. Our belief is that knowledge-based systems development would benefit from CORBA regardless of domain or task, but to demonstrate this claim, we must show examples from a variety of different domains. In the scenarios that follow, we use a set of knowledge bases and problem-solving methods that have been previously described in the literature, and have been implemented within the Protégé environment.
The scenarios proceed from simple to complex, and are organized by whether knowledge bases or problem-solving methods are the service to be reused or the client calling for a service. Although the traditional definitions of client and server do not always apply in a CORBA framework, in any given reuse scenario, there is a calling agent (client) and a service provider (server). Our experience with Protégé suggests that the following scenarios are stereotypical for the development of knowledge-based systems.
Scenario 1: A knowledge base server, with PSM clients
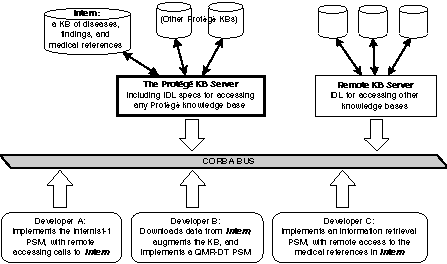
Different developers may want to apply a number of different problem-solving methods to a given knowledge base. The problem-solving methods designed by these developers are clients, making requests of a server for access to a knowledge base. For example,
Figure 3
shows three developers using the Internist-1 knowledge base implemented within the Protégé environment (Miller, Pople & Myers, 1982; Musen, Gennari & Wong, 1995). This knowledge base includes medical diseases and diagnoses, patient symptoms and findings, links between diseases and symptoms, and a large set of current medical references, including their links to particular diseases and/or symptoms. A CORBA implementation of this knowledge base would include three parts: (1) a persistent store system for the actual data
(shown in
Figure 3
at the top), (2) the server object that implements accessor functions into the knowledge base, and (3) an IDL specification of those accessor functions. Because the Protégé environment imposes a common storage format for all knowledge bases, we can build a single server that provides CORBA access to any Protégé knowledge base. This approach is generalizable beyond Protégé Any development environment or system for a common persistent store could have a single CORBA front-end that would make those knowledge bases available over the network for remote clients or users of the knowledge bases.
Figure 3. Reuse scenario 1: The knowledge base Intern is used by three developers with three different problem-solving methods.
As shown in Figure 3, the Internist-1 knowledge base may be used for different purposes by different client developers. Developer A may be interested in implementing (or re-implementing) the original Internist-1 algorithm for differential diagnosis. This is exactly what Musen et al. (1995) accomplished within the PROTÉGÉ-II environment. Although we built this system with the knowledge base and the problem-solving method as components, these were components only within PROTÉGÉ-II, and not available over networks via CORBA. We have since re-built this Internist-1 system with CORBA components.
Alternatively, rather than using Internist's algorithm for diagnosis, Developer B may be interested in developing an improved problem-solving method for differential diagnosis. For example, Shwe et al. (1991) developed QMR-DT, a decision theoretic approach to differential diagnosis that uses a Bayesian belief net to model diagnostic relationships. This approach may require augmenting the knowledge base, and thus, Developer B may want to retrieve and augment the shared Internist-1 knowledge base as a single preprocessing step, and then run the problem-solving method on the augmented, local copy of the knowledge base. Although using a local copy of the knowledge base may have greater run-time efficiency, this approach requires version maintenance: if the knowledge base changes frequently, it must be downloaded frequently, and this cost could overwhelm any savings gained in run-time efficiency. As an example where run-time, remote access to the shared knowledge base would be essential, consider Developer C, who develops a problem-solving method for accessing and analyzing the medical references portion of the Intern knowledge base. Presumably, references change at a rapid rate (at least monthly), and Developer C wants to take advantage of the work done by the Intern knowledge-base maintainers in keeping these references up-to-date.
Scenario 2: The PSM as a server, with knowledge bases as clients
A single problem-solving method, if it is designed for reuse, may be used with a number of different knowledge bases.
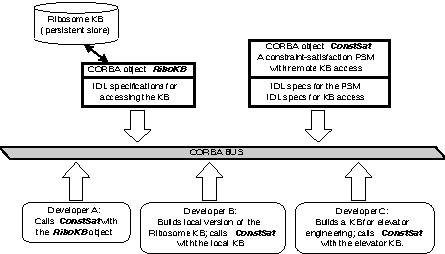
Figure 4
shows this scenario where the reusable problem-solving method is a constraint-satisfaction engine. For the knowledge-acquisition research community, a familiar use of such a problem-solving method is with the Sisyphus-2 elevator design problem (Schreiber & Birmingham, 1996). Another domain where tasks may require constraint satisfaction is molecular biology: For example, to determine the three-dimensional configuration of a ribosome, a number of atomic distance constraints between parts of the ribosome must be satisfied (Altman, Weiser & Noller, 1994).
Figure 4. Reuse scenario 2: The problem-solving method ConstSat is used by three developers with three different knowledge bases. Since ConstSat expects a remote knowledge base, it also includes an IDL description of the KB accessing functions.
Within PROTÉGÉ-II, Gennari et al. (1995) have demonstrated exactly the reuse indicated by Developers B and C in Figure 4. We used a single problem-solving method to solve both the ribosome configuration problem and the Sisyphus-2 elevator design problem. In PROTÉGÉ-II, the components were implemented as different knowledge bases and methods within the CLIPS production-system language. Because of this common base, communication problems among components were not an issue. To achieve interoperability across different development environments and platforms, we would need a component communication standard such as CORBA, and an implementation of components as outlined in
Figure 4.
This scenario provides clear motivation for designing problem-solving methods as modular CORBA components. If problem-solving methods are designed to be independent of knowledge bases, then they can be called and reused with any number of different versions of the experimental data. For example, the RiboKB knowledge base includes experimental data about ribosomal sequence information and atomic distance constraints. Developer B may question the validity of this experimental data, and may want to build a different or modified knowledge base. As long as Developer B's knowledge base follows the same form as specified by the IDL for knowledge-base access included in the shared problem-solving method, then the same constraint satisfaction problem-solving method can be applied to different versions of the knowledge base. Any developer can use the shared constraint satisfier because this CORBA component does not care where the knowledge base residesĐit simply makes accessing calls and uses the CORBA bus to find the implementation of those KB accessing calls.
It should be clear that the knowledge base for ribosomal information in
Figure 4
could be reused just as the Intern knowledge base was in scenario 1; thus, this knowledge base could be used with several different problem-solving methods, not just constraint satisfaction. Note that knowledge bases sometimes act as CORBA servers (scenario 1) and sometimes as clients (Developer B in scenario 2). This is not inconsistent: a single component can act both as a client and as a server. Thus, the IDL specifications for the constraint-satisfaction PSM component includes both methods for constraint satisfaction that are implemented as a service, and specifications for KB access that the component uses as a client and does not implement; it is assumed that these access functions are implemented by some other component on the CORBA bus.
Scenario 3: The problem-solving method as a server, with other PSMs as clients
For a number of years, the knowledge-based systems community has envisioned a library of problem-solving methods as reusable components, so that developers could build up these method components to satisfy the task at hand (Wielinga et al., 1993; Walther et al., 1992; van Heijst et al., 1995; Tu et al., 1995). However, until now, we have lacked an environment in which these ideas could be readily implemented. As described in Section 2, CORBA is designed to allow submethods to be called remotely as sharable components of a large problem-solving method.
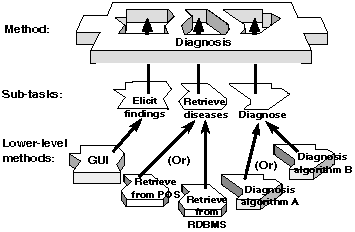
As an example,
Figure 5
shows the decomposition into components of a method to perform diagnosis using the Internist-1 knowledge base. The top-level problem-solving method is a loop that iterates through three sub-tasks: (1) elicit patient findings from the user, (2) retrieve potentially relevant diseases from the knowledge base, and (3) rank these diseases to produce a differential diagnosis based on known findings. As shown in the figure, these sub-tasks can be implemented by different sub-methods. For example, depending on needs for retrieval efficiency, the diseases may be stored in different sorts of persistent storage systems, requiring different implementations for the retrieve subtask. Similarly, different developers may prefer different algorithms for sorting and weighting the retrieved information to do the diagnose subtask.
Figure 5. A composite problem-solving method: the top-level task is broken into three subtasks, which may be implemented by different lower level problem-solving methods. In
Figure 6, these three subtasks are implemented by CORBA components.
The ability to configure the Diagnosis problem-solving method with different choices of lower-level methods can be supported by implementing each of the submethods of
Figure 5
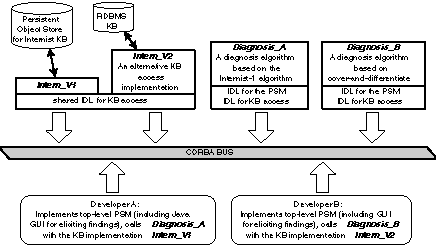
as a CORBA component. Using a commercial product for our object request broker (ORB), we have completed an implementation of these components, using the Java language for the GUI that implements the Elicit findings sub-task, and C++ for the other two sub-tasks for the Diagnosis method. A complete scenario for reusing these CORBA components is shown in
Figure 6,
where Developers A and B build two different configurations of the same top-level diagnosis problem-solving method. Our initial implementation (Developer A) uses a flat file for knowledge base storage, and a simple version of the original Internist-1 algorithm. In contrast, DeveloperB may need a relational database (RDBMS) implementation for the knowledge base access (Intern_V2), and may build a diagnosis algorithm based on cover-and-differentiate. Although we have built a Java GUI front-end for eliciting patient findings, Developer B may want a special-purpose GUI that is more suited to local platform capabilities.
Figure 6. Reuse scenario 3: Two developers build alternative versions that implement the top level problem-solving method Diagnosis (see
Figure 5), by calling CORBA components that implement various subtasks of the method.
The extent to which IDL specifications are shared dictates the ease of interoperation. Thus, if the Intern_V1 and Intern_V2 knowledge bases share the same IDL (as indicated in
Figure 6), then developers can seamlessly interchange these two components. Likewise, if a developer wants to connect Diagnosis_B with Intern_V1, then the latter component must implement those access functions called by the PSM component. Of course, the IDL need not match exactly -- presumably, the problem-solving method IDL differs between Diagnosis_A and Diagnosis_B, and this difference would be reflected in any clients.
Whereas the ability to interchange and reuse components of a knowledge-based system is not a new idea, the development of the CORBA standard for inter-component communication, and of commercial products that support this standard is new. This standard allows developers to ignore lower-level communication details, and to specify components above the level of programming languages or development environments. As more developers use this standard, it will become easier for researchers and developers to reuse components built at other sites and in other environments.
5. IDL Specifications and Ontologies
For any use of a CORBA component, both the component's author and the component's users must share an interface definition language (IDL) specification for that component. At an implementation level, this is a critical feature of the CORBA scheme for interoperation. The IDL specification allows clients to call server methods with appropriate arguments and syntax. The IDL specification must be compiled into both server and client systems, allowing a client call to make reference to stub methods, which are then transmitted by the client ORB over the network to a server machine, where the complete implementation of these methods resides. At a more abstract level, an IDL specification describes what a particular component is or doesĐas such, it is the closest match in CORBA to an ontology. Unfortunately, IDL specifications are more syntactic than semantic, and do not provide sufficient information to guarantee that components will interoperate correctly.
CORBA is an object-oriented standard for component architectures. Therefore, IDL specifications are object-centered, and allow for inheritance, polymorphism, and encapsulation. Each object in IDL includes a declaration of shared methods and static attributes; these are interfaces, since they specify the syntax of the public interface into the object.
Figure 7
shows the IDL specification for the Internist-1 problem-solving method, including the specifications for accessing an Internist-1 knowledge base. This specification includes two interfaces, KB_Loader and PSM_Session, each with attributes, methods and subsidiary data structures. Since this IDL must be compiled into components that either implement or use these interfaces, we have compiled it with each of the three components in our re-implementation of the Internist-1 system:
1) The problem-solving method component, which implements the methods listed under the PSM_Session interface, and makes client calls to the KB_Loader methods.
2) The knowledge-base server component, which implements the methods listed under the KB_Loader interface. Currently, these methods are implemented by interacting with flat files containing the Internist-1 database.
3) The Java front-end component, which makes client calls to methods in both PSM_Session and KB_Loader.
Figure 7. The IDL specification for the Internist-1 problem-solving method and for access into an Internist-1 knowledge-base.
These three components correspond exactly to the three subtasks of the Diagnosis method shown in
Figure 5
. Thus, KB_Loader is an interface to the CORBA component that implements the retrieve disease subtask of
Figure 5
. Likewise, PSM_Session specifies the interface to the component that implements the Internist-1 algorithm for performing the diagnose subtask of
Figure 5
. As specified by the IDL in Figure 7, these three components cannot be further sub-divided into subtasks or submethods. For CORBA, the granularity of components is defined by the interface construct. Thus, while the Java front-end could replace PSM_Session with an alternative implementation of the diagnose task, it cannot change any lower-level details of the Internist-1 algorithm.
The IDL specification of Figure 7 defines the exact syntax of the inputs and outputs of each component, and therefore allows us to plug-and-play components across networks and with any CORBA-compliant object request broker system. For example, we plan to replace our implementation of KB_Loader with a more generic interface for access into Protégé knowledge bases, as described in Figure 3. As long as the new component continues to support the original IDL specification for KB access, we can replace the knowledge base component with an alternative knowledge base and/or knowledge base server system, without affecting the front-end component or the problem-solving method component.
As currently specified, the KB_Loader in Figure 7 is custom-tailored for the diagnosis problem and for our Java GUI. This component is used as a service by both the problem-solving method component and by the Java front-end component. The former uses the methods getEvidence and getClassification to retrieve information about specific diseases and findings in the knowledge base. The front-end component uses the latter three methods to allow the end-user some browsing capability into the knowledge-base. For example, getEvidenceNames(Şfeverş, 30) returns 30 alphabetically sorted finding names, beginning with Şfeverş.
Unfortunately, although IDL specifies the syntax necessary for interoperation, it does not describe the semantics for what these methods do, or how they are implemented. For example, the behavior of getEvidenceNames is clear only by explanation or documentation, and therefore susceptible to misinterpretation and misunderstanding. Because the implementation of such functions is hidden, clients must (1) trust that they understand the developer's intended semantics, and (2) trust that the developer correctly implemented those semantics. CORBA provides only the syntax for interoperation; semantics are implicit and unenforced.
6. CORBA: Not a Panacea
The observation that CORBA does not provide component semantics contrasts with research in problem-solving method ontologies: An IDL specification of a component describes the syntax for the sharable elements of that component and enables interoperation, whereas ontologies for knowledge-based systems capture some of the component's semantics. In the CORBA approach, the semantics of what a component is or does is hidden in the server-side implementation. From our perspective, a significant weakness of IDL is that the specification places only syntactic constraints on how methods are implemented.
If a component is to be reused by a community of developers, the shared IDL specification should communicate something about the semantics of the methods that are available for reuse. For example, a constraint-satisfaction problem-solving method should promise, given state information and a set of constraints, to attempt to find a state where all constraints are satisfied. Unfortunately, the only constraints enforced by the IDL specification are on the type and number of arguments to the method. Thus, in the example IDL in Figure 7, there are no guarantees about what the getConclusions method does, except for the argument descriptions specified (its input is a short integer, and it returns a sequence of Conclusion structures). Therefore, the component builder and the component user must share implicit semantics about method behavior.
Unfortunately, specifying semantics for an arbitrary piece of software (or a problem-solving method) is an open research problem. The information in knowledge bases is fairly constrained, and this makes defining semantics for accessor functions (such as getEvidence) easier than arbitrary software. However, different systems might define different semantics for inheritance, default values and similar issues, and these distinctions might be hard to specify. In general, for a component to be reusable in a cost-effective manner, it must be possible for developers to quickly find and understand the component. Thus, what one needs is an abstraction of the activities of a component that can readily be understood by other developers as they browse or search through a library of CORBA components. Because IDL does not describe semantics, it is not sufficient for this abstraction.
/*----------------------------------------------------------------------------*
/* File: INTERN.IDL
/* The idl specification for access to the Internist-1 knowledge base, and
/* use of a re-implementation of the Internist-1 algorithm for diagnosis.
/*
/* Programmer: Adam Stein (w/John Gennari)
/*------------------------------------------------------------------8/28/96-*/
module internist {
enum evidence_status {POS, NEG};
typedef sequence