


We now discuss the application of the two cooperation modes introduced above in a system that recommends chromatography techniques to purify proteins from tissues and cultures. There are a number of proteins and associated chromatography techniques currently in use in a larger number of industrial chemical labs. Each of these labs may face its own subset of problems that it routinely solves and in the process it develops expertise for handling them. It may also face problems that seldom occur at its location but occur frequently at other locations - leading to the developemnt of expertise at those locations. Different locations may thus have different methods for case-based reasoning that rely on knowledge modeling analysis of their particular problems and local expertise and biases. This gives rise to the need for cooperation to exploit peer expertise.
Our multi-agent CBR system consists of a number of CHROMA agents that can recommend chromatography techniques for protein purification. Each CHROMA agent can be configured using Noos. It allows the configuration of a CBR system through a knowledge model analysis of the domain[Arcos &Plaza1996][Arcos &Plaza1994]. Such a configuration is done with the component blocks provided by Noos - like generic retrieval methods - that are refined (or biased) in order to incorporate the domain knowledge that has been modeled. In CHROMA, the domain knowledge is used to characterize which features are more important for judging the similarity between a current problem and a precedent case. Noos allows the expression of such knowledge by means of retrieval methods and preference methods. Such an abstraction permits one to ignore implementation details like the indexing algorithms and, most importantly, permits the communication of such methods among CBR agents[Arcos &Plaza1996][Arcos &Plaza1994]. This allows a CBR agent to not only exploit the cases in its own case-base but also those cases known by other agents.
Learning in CBR is lazy: a CBR system imposes a partial order among (a relevant subset of) the past examples based on the current problem. The solution of a problem is determined by the solution of the case(s) that is maximal in the partial ordering established by preferences. Thus, solutions proposed by the system are a function of the individual experience of the CBR system plus the domain knowledge given by the system designers during the knowledge modeling stage. The CBR method in a CHROMA agent is configured as follows:
In the multi-agent extension of CHROMA, each laboratory has a specific agent that can support this CBR method or a similar one. Different CBR methods can be derived by supplementing or substituting the general preference criteria with specific ones arising out of the kinds of problems an agent regularly solves. For instance, for a given tissue, the species criterion could be more relevant than the source criterion. Thus, each CBR agent possesses selection criteria adapted to its own experience.
We have seen that CBR methods are decomposed into three main tasks:
retrieval, selection and reuse.
The multiagent CHROMA application specifies the reuse task to
be local to the agent involved in solving a problem, while retrieval
and selection tasks can be delegated to other agents. In DistCBR an
agent  has a new method
encompassing the retrieval and
selection tasks; this retrieve&select method is declared
public. Another agent
has a new method
encompassing the retrieval and
selection tasks; this retrieve&select method is declared
public. Another agent 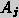 can
specify to the agent
to apply that method to a current problem and
will receive as
result, the network reference of the best precedent
case
can
specify to the agent
to apply that method to a current problem and
will receive as
result, the network reference of the best precedent
case 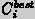 in memory. Then can access the information
of in (essentially the solution)
and reuse or adapt
that information to the current problem.
in memory. Then can access the information
of in (essentially the solution)
and reuse or adapt
that information to the current problem.
In Dist CBR, the precedent case was selected using the
criteria embodied in
retrieve&select method. On the
other hand, in ColCBR an agent uses its own CBR method on any
federated agent-in essence accessing and using the memory of the
another agent as if it was its own, and hence the name of collective
memory. In ColCBR an originating agent can
transmit its retrieve&select method to another agent
who is responsible for using it on its own memory and experience and
sending back the best precedent case to . Here
is the best according
to the criteria of and
the
experience of .
In fact, the way ColCBR is performed is slightly more complex. In ColCBR we want to find the best precedent case in the collective memory of all the peer agents, but each agent may respond with the best case from its case base. The agent can not give any assurances about the goodness of the case with respect to the entire collective memory of all the agents. So, the following ColCBR method is used to select the the best precedent case:
.
in order to
select the globally best one(s).