School of Computer Science and Engineering,
University of New South Wales, Sydney 2052 Australia
email compton@cse.unsw.edu.au
+Western Diagnostic Pathology, Perth, Australia
glenn@cse.unsw.edu.au
++Dept. of Computer Science, Hoseo University, Korea
Ripple Down Rules (RDR) is a simple and effective knowledge acquisition and knowledge maintenance tool. The original version of RDR provided only a single classification for a particular set of data. A later refinement to the method was Multiple Classification Ripple Down Rules (MCRDR). This paper describes an MCRDR tool, using a simple artificial domain based on weather as an example problem. It aims to describe the main features that should be addressed in any real application of an MCRDR system.
BACKGROUND
Ripple Down Rules is a knowledge acquisition methodology where an expert creates and maintains his or her own KBS. Maintenance is very simple thereby allowing a system to be built while it is in routine use by fixing errors as they occur. The original motivation for RDR was to attempt to deal with the situated nature of the knowledge provided by experts, as observed during maintenance (Compton & Jansen 1990). A rule is only added to the system when a case has been given a wrong conclusion. A key feature of RDR is that the knowledge being added is validated. Any cases that have prompted knowledge acquisition are stored along with the knowledge base and the method does not allow the expert to add any rules which would result in any of these stored cases being given a different conclusion from that stored. The expert is required to select features for a rule that distinguish between the case for which the rule is being added and the other stored cases already correctly handled. The validation that this provides is not total validation, but ensures that as the system is incrementally developed, the previous performance of the system is maintained, at least with respect to the stored, or 'cornerstone' cases. The focus on distinguishing between cases is in common with methods based on personal construct psychology (Gaines & Shaw 1990).
Initial studies focussed on tasks where only a single classification per case is required. For this task rules were linked in a binary tree structure and a single case was stored with each rule. When a conclusion had to be corrected a new rule was added at the end of the inference path through the tree giving the wrong conclusion. The rule had to then distinguish between the new case and the case associated with the rule that gave the wrong conclusion (Compton & Jansen 1990). The major success for this approach has been the PEIRS system, a large medical expert system for pathology laboratory report interpretation built by experts without the support of a knowledge engineering (Edwards, et al. 1993). It was also built whilst in routine use. Despite the fact that knowledge is added in random order, simulation studies have shown that knowledge bases produced by correcting errors as they occur are at least as compact and accurate as those produced by induction(Compton, et al. 1995; Compton, et al. 1994).
More recently we have developed RDR to deal with tasks where multiple independent classifications are required (Kang 1996; Kang, et al. 1995). This approach allows for n-ary trees, but is most simply understood in terms of a flat rule structure, where all rules are evaluated against the data. When a new rule is added, all cases associated with the KBS could reach this rule, so that the rule must distinguish between the present case and all the stored cases. In the approach developed, the expert is required firstly to construct a rule which distinguishs between the new case and one of the stored cases. If other stored cases satisfy the rule, further conditions are required to be added to exclude a further case and so on until no stored cases satisfy the rule. Surprisingly the expert provides a sufficiently precise rule after two or three cases have been seen (Kang, et al. 1995). Rules which prevent an incorrect conclusion by providing a null conclusion are added in the same way. The MCRDR system produces somewhat better knowledge bases than RDR even for single classification domains, probably because more use is made of expertise rather than depending on the KB structure (Kang 1996).
Some more detailed features of the MCRDR implementation below should be noted. An n-ary tree structure is allowed, so that when a new rule is added to deal with a case, the rule must distinguish between this case, the cases stored with the parent rule (giving a the wrong conclusions), any sibling rules and the children of any siblings rules as all of these may cause the new rule to fire. Further if a case requires a new conclusion, the case is stored not only with the rule giving the new conclusion but with any other rules that gave correct conclusions during the process, as these rules must continue to handle the case in the same way as knowledge develops. In this way rules may end up with multiple cornerstone cases. Also, at the discretion of an expert, when a rule makes a wrong conclusion, a refinement rule may be added to correct the conclusion, or alternately a 'stopping' refinement rule may be added which simply means no conclusion is produced from this rule path and a new rule added elsewhere. For both the new rule and the stopping rule, the rule must distinguish between the case and any cornerstone cases that reach the rule. In deciding to have a refinement, or a stopping rule and new rule, the expert is deciding whether the new rule is probably of wide application or a fairly specific refinement. Experience suggests it is adequate for a rule to be a refinement or to go at the top of the tree. The decision does not affect the validation of the rule addition, and in practice is of little importance. If a rule is inappropriately selected as a refinement then fairly quickly a new case of this type will occur which does not reach the refinement and so a new rule will be added at the top. On the other hand the studies showing that differentiation between cornerstone cases is rapidly complete were based on all rules being added at the top so that the differentiation task was maximised.
It should be noted that although MCRDR does not require a knowledge engineer for rule addition and rule organisation, it does require the development of an appropriate data model and an appropriate interface for the data model in the normal software engineering fashion. This also includes some simple data abstraction as required. It of course also requires an assessment that the task can be handled by MCRDR. Tools for RDR for construction tasks are under development.
The following sections outline an MCRDR demonstration system. A data model and interface has already been developed for the domain. However the interface is a Hypercard stack and so is fairly readily modified.
BASICS
This demonstration program runs on a Macintosh computer, and consists of a HyperCard stack and support components as follows:
MC RDR Interface The interface for the application. This icon starts the application.
RDR_Engine This is the server that does most of the processing. It has no interface.
Weather A set indexed data files for processing
*Weather A small knowledgebase
The Interface and the Engine together form the application. They exist in a simple client server relationship. The Manual is this document.
Installation of the demonstration program on a Macintosh should be very simple - simply copy everything to the local hard disk. Either HyperCard or the HyperCard Player should be present.. The HyperCard Player is distributed as standard with all Macintosh computers.
Getting started with the application is very easy; simply double click on the MCRDR Interface icon and the application will start up. On the first screen are some credits and a large START button. This will load the knowledge base and take you to the start of processing.
The aim of this demonstration program is to maintain a small expert system that is trying to classify some data called 'weather' and that covers several different perspectives areas to demonstrate the features of multiple classification RDR. The starter system covers the following areas:
Topic Conclusion codesNo conclusions %NCxxx
Flooding %FLDxx
Kite flying %KITEx
Wearing of Raincoats %RANxx
Wearing of shorts %SRTSx
Likelihood of sun %SUNxx
however any other topics can by whom ever is building the system.
PROCESSING CASES
For the demonstration, the application is set up to process cases stored in the 'Weather' data file. This is an indexed set of cases which can be accessed either sequentially or randomly. This file holds 200 cases of varying sizes, with varying amounts of time course data available. Note that since we are not meteorologists, the data may be pretty strange.
In the screen snap below can be seen the result for processing case number #10 against the knowledge base. The knowledge base is not expected to be complete or correct.
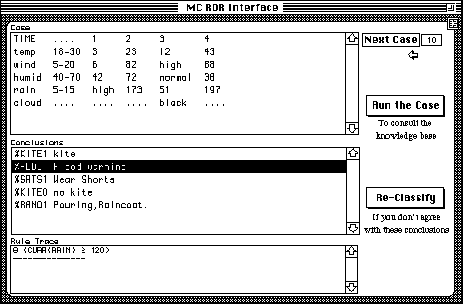
A number of important features can be seen here. Firstly, the data itself is time course data. The data can have up to five columns of values for any particular attribute measured at different times. In the randomly generated data used in this demonstration there will be a maximum of five columns of data, which can have a mixture of strings, real values or missing values (indicated by '....').
The second column is special - it indicates the normal range for the attribute. For the case shown above, the attribute 'rain' has a normal range of 5 to 15 while 'cloud' has no normal range. The existence of normal range leads to the concepts of high and low values. More on this later in the discussion on functions. Although this demonstration is concerned with weather this data format is essentially the same to that used in the PEIRS expert system. The aim is to show the potential real domains beyond the toy weather domain.
When this case was processed, the expert system reported five conclusions. A summary of the conclusion text is displayed, since it is inappropriate to display to display the full conclusion information here. In full, a conclusion consists of a six character conclusion code, a unique id number, a single line of text (the header), and an arbitrary amount of free text. Note that mixture of conclusions indicate that this particular KB is at a very early stage of development with plenty of errors.
KNOWLEDGE ACQUISITION AND MAINTENANCE
All knowledge acquisition is maintenance in that knowledge acquisition is prompted by the system making a wrong conclusion or a case or failing to make a conclusions when one is required. The following case and conclusion combination are a good example to illustrate knowledge acquisition. In this instance, the expert system has suggested wearing a raincoat because HIGH(RAIN) was TRUE.
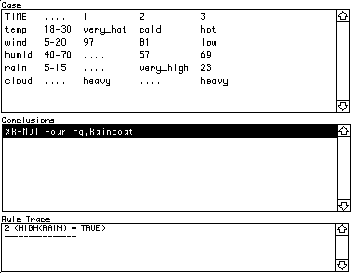
However, one might disagree with this conclusion. Rather, considering the low wind and the hot weather, it might be better to leave the rain coat at home and take shorts and an umbrella. To correct the knowledge base one needs to do several things:
* stop the KB from producing the %RAN01 conclusion
* select two new conclusions - shorts and umbrella
This process is called in general called 'reclassifying'.
After reclassifying the case one needs to make new rules to produce the new classifications and a new rule to stop the inappropriate classification and install all three in the knowledge base.
To begin this process, click on the Re-Classify button, to go to the Reclassify screen.
A good first step, is to move any conclusions that are inappropriate for the current case to the 'Deleted Conclusions' field, which can be done by double-clicking. You can move them back by click-holding in the 'Deleted Conclusions' field and choosing 'the "Delete' option (deleting a delete as it were)
To choose some new Conclusions, use the Add New Conclusions button. This will take you to the Conclusions screen where you can browse the conclusion database and choose the conclusions you need. See the section on the conclusion maintenance for more details on this.
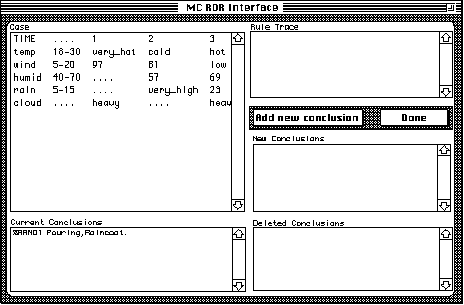
After the relevant conclusion slection, the reclassification screen should(in part at least) look something like this:
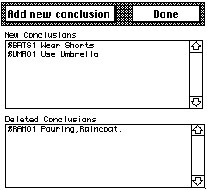
When everything has been reclassified. it is time to make rules and install them in the knowledge base.
MAKING NEW RULES
This is the way the Make Rule screen should appear when you arrive. There are places to view the current case, and the previous cornerstone cases, places to see the conclusions that have to be asserted and conclusions that have to be stopped and a field the display the rule conditions as they are assembled.
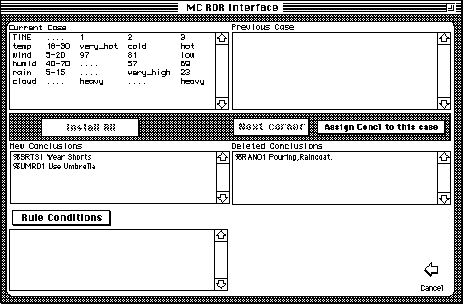
The basic procedure here is to select a conclusion, and to process all the cornserstone cases that have been associated with it by the program until you have distinguished the current case from all the cornerstone cases or have assigned the selected conclusion to cornerstone cases.
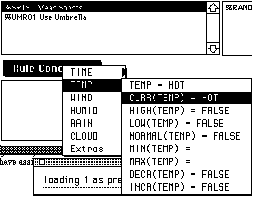
Begin by selecting the first new conclusion - %SRTS1. The program will begin processing relevant cornerstone cases (indicating by the rotating beach ball cursor) and when finished hilite the conclusion. At this stage, a number of valid rule conditions are available for election by click-holding on the Rule Condition button. The following image shows the hierarchical menu that results when you use this button.
For each of the attributes in the case, a range of potential rule conditions are displayed. The system understands time course data so concepts like maximum and minimum are available. See the discussion of functions below.
After having chosen some rule conditions, use the Next Corner button, the system will process cornerstone cases to see which (if any) have to be checked by you for further consideration. In this instance nothing further need be done. Otherwise a cornerstone case which the rule did not distinguish from the new case would be displayed and further rule conditions added to the rule.
Choose the next conclusion of %UMR01 and then choose a rule condition of WIND = LOW for a rule condition and then use the Next Corner button as above.
A very similar procedure applies for the deleted conclusion of %RAN01 - where we choose a rule condition of TEMP = HOT. Again, we must consider any of the possible cornerstone case that may be involved, so se of the Next Corner button is needed.
Note
All corners for all conclusions have to be considered before the INSTALL ALL rules button will become active. This is the most difficult stage for the expert and probably the most difficult in this outline. However, it is not that any of the task is difficult, but that a sequence is involved. If the INSTALL ALL button is not active, the expert may have missed a cornerstone case for one of the conclusions and a quick recheck is required.
When Ready to Install
When you have finished installing, assuming that all has gone correctly and the system has not complained about something you should return to the processing screen and the case will be processed again and the new conclusions will appear as below:

MANAGING CONCLUSIONS
Note that the way in which conclusions are managed is not intrinsic to MCRDR and there may be many better alternatives which could be plugged in. In fact, conclusion management could be achieved by simply allow the expert to add any free text conclusion required. However in practice, most organisations prefer to keep some consistency in conclusions bey re-using them and consistent use of conclusions provides more possibility for re-using the knowledge for other purposes, if only for browsing.
The Conclusions screen is an interface to a small database for the creation and selection of conclusions codes. This screen serves two purposes, firstly you can maintain the conclusions, and secondly, you select conclusions when making new rules.
A conclusions consists of several parts:
a six character conclusions code
a unique id number
a single line of text - the header a shorthand description for the system maintainer
the conclusion text - an arbitrary amount of free text
The conclusions are indexed by the six character code, by the ID and keyword. However, for the purposes of this demonstration only conclusions codes are supported.
To display the full set of known code use the Known Codes button. Selecting one of the codes from the list displays all its details. In the screen snap the code %UMR01 has been selected.
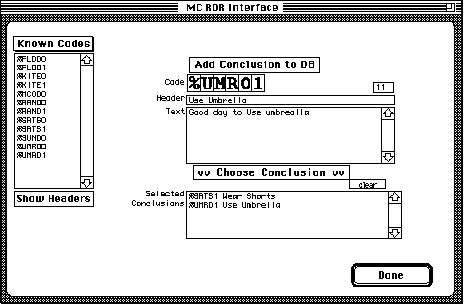
BROWSING
Browsing is normally essential in a KBS, because the expert and knowledge engineer need to explore the system to understand how it has handled a case and how it may handle it better before making a change. This is not required with MCRDR. Here browsing is included, simply so the knowledge can be explored and to satisfy the curious as to what happens internally with MCRDR. We found with PEIRS that the expert tended to be interested in seeing why a particular mistake was made even though this was not necessary for adding a new rule.
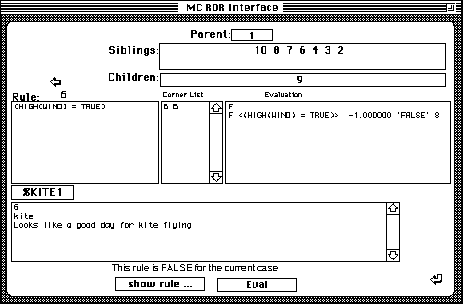
There are two methods to browse in this demonstration program. Which one to use is a matter of need and personal preference. The first method, the one providing the most information is shown in the following diagram. Selecting any rule number from Parent, Sibling or Children will take you to that individual rule, displaying the relevant information. The Corner List field shows all the cornerstone cases associated with this rule, with the first number in the cornerstone list, the case that caused the creation of the rule. The subsequent numbers are all cornerstone cases that are associated with this rule because the rule was used by a case which required the addition of a rule somewhere. This means that the initial conerstone case number occurs again, but the repetition is not an error.
The Evaluation field consists of several lines. The first line is a single letter , either a T for true or an F for false, the state of the rule for the current case, followed by a single line for each rule condition, showing how it was evaluated.
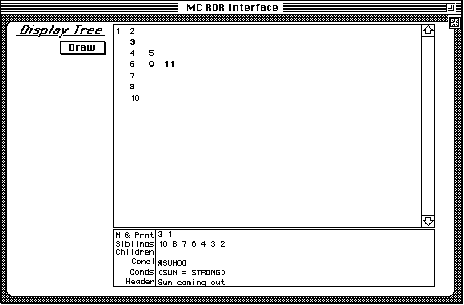
The second browsing method implemented in the demonstration program is a more graphical style, showing the actual layout of the n-ary structure of the MCRDR tree. You can draw the structure by use the Draw button at any time. and selecting any of the rule numbers will display its essential information below.
FUNCTIONS
Heuristic classification includes the idea of constructing rules using abstractions of data. This is invariably essential with numerical data and useful in general. A problem with such abstractions is that they are rarely as crisp as expressed by experts, leading to maintenance problems and attempts at solutions with techniques such as probabilistic reasoning and fuzzy set membership. RDR avoids such problems since an abstraction can be refined in a particular context by reference back the raw data. E.g. TSH (HIGH) may be defined as TSH >6 (TSH is measurement of pituitary function in pathology). A rule may then use TSH = HIGH but be impropriate for a borderline result of TSH = 6.5 when other data are also borderline. The expert can then identify the differences between the case by a refinement rule using for example TSH >8. The nett effect is that the rule pathway to this refinement rule applies to the region 6 < TSH < 8. PEIRS showed that this approach allowed for quite simple abstractions which were then patched where necessary. We believe it also corresponds to normal expert explanations where experts prefer to change and re-define abstractions to deal with particular contexts, but where the various definitions are each crisp, rather than give a more comprehensive and formal abstraction. The section below describes a simple function interpreter to allow the expert to define abstractions. Of course new functions can be added at any stage, because they will only be used in rules added after this stage of development. Other on-going research is looking at RDR maintenance of functions to deal with the situation when the expert wishes to change the actual function definition. However, this seems to be an interesting challenge rather than a pressing practical requriment.
The following screen snap shows the standard functions.
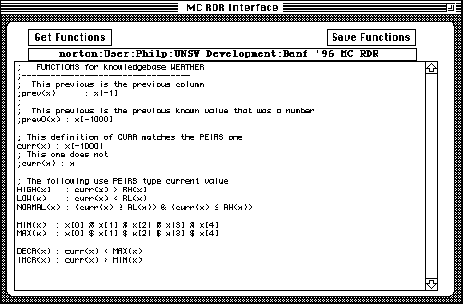
Rules and functions use low level references to data. Functions are references to data that have some defined name that can themselves be referred to, either in rules or in other functions. As well as the basic references to data several predefined functions exist.
Data References
When referring to case data, an indexing notation is used. Consider the following line of data
ATT R1-R2 Va Vb Vc .... Vd
The string ATT refers to Vd
The string Rl(att) refers to R1
The string Rh(att) refers to R2
The string ATT[0] refers to Va
The string ATT[1] refers to Vb
The string ATT[2] refers to Vc
The string ATT[3] refers to '....'
The string ATT[4] refers to Vd
The string ATT[-1] refers to the column before the last column
which is '....'
The string ATT[-2] refers to the column before the column before the last column
which is Vc
The string ATT[-1000] refers to the column before the last column that was not '....'
which is Vc
The string ATT[-1001] refers to the col before the col before the last col not a '....'
which is Vb
Predefined Values
RH(x) The range high value
RL(x) The range low value
TRUE Logical TRUE
FALSE Logical FALSE
UNKNOWN Logical UNKNOW (As in the function result is unknown)
Operators
case '+' Numeric operator
case '-' Numeric operator
case '*' Numeric operator
case '/' Numeric operator
case '>' Numeric operator
case '<' Numeric operator
case '>=' Numeric operator
case '<=' Numeric operator
case '=' Numeric operator and string operator
case '!= Numeric operator and string operator ( use option-'=' )
case '!' Numeric operator and string operator
case '&' Logical AND operator - operates on the results of a rule condition
case '|' Logical OR operator - operates on the results of a rule condition
case '$' Numeric maximum operator - returns the maximum of the two numbers
case '%' Numeric minimum operator - returns the minimum of the two numbers
case '#' Exists operator - evaluates truw when a test exists (or a function calculated)
case '@' Index operator - returns column index for specified attribute
Creating Rule Conditions
When creating rule conditions a number of things should be considered. A condition can be one of a number of different types, in the pathology example below:
* a direct reference to a test, eg TSH > 34, or TSH :> TSH[1]
* a reference to a specific function, eg TSH_HIGH
* a reference to a global function, eg HIGH(TSH)
* a combination of the above, eg TSH > 34 & TSH_HIGH & HIGH(TSH)
In the Making Rules screen, you have quite a bit of leeway in manipulating rule construction. You can alter rule operators or values using a popup menu as shown below. Note that a general guideline holds that the rule must at all times be true for the current case but false for the previous. If you inadvertently create a rule that breaks this guideline you will be advised and the rule will revert to the valid format.
SUMMARY
This paper has described an MCRDR implementation to give advice about the weather. It ennobles the key features of MCRDR to be explored. It also includes secondary but important features such as conclusion management, browsing and functions for pre-processing data.
ACKNOWLEDGMENTS
This research has been supported by the Australian Research Council. This implementation was developed by the first author.
REFERENCES
Clancey, W.J. (1985). Heuristic classification, Artificial Intelligence 27: 289-350.
Compton, P., Preston, P. and Kang, B. (1995). The Use of Simulated Experts in Evaluating Knowledge Acquisition in B Gaines & M Musen, Proceedings of the 9th AAAI-Sponsored Banff Knowledge Acquisition for Knowledge-Based Systems Workshop, Banff, Canada, University of Calgary, 12.1-12.18.
Compton, P., Preston, P., Kang, B. and Yip, T. (1994). Local patching produces compact knowledge bases in L Steels, G Schreiber & W Van de Velde, A Future for Knowledge Acqusition: Proceedings of EKAW'94, Berlin, Springer Verlag, 104-117.
Compton, P.J. and Jansen, R. (1990). A philosophical basis for knowledge acquisition, Knowledge Acquisition 2: 241-257.
Edwards, G., Compton, P., Malor, R., Srinivasan, A. and Lazarus, L. (1993). PEIRS: a pathologist maintained expert system for the interpretation of chemical pathology reports, Pathology 25: 27-34.
Gaines, B. and Shaw, M. (1990). Cognitive and Logical Foundations of Knowledge Acquisition in 5th AAAI Knowledge Acquisition for Knowledge Based Systems Workshop, Bannf, 9.1-9.25.
Kang, B. (1996). Multiple Classification Ripple Down Rules. PhD thesis, University of New South Wales.
Kang, B., Compton, P. and Preston, P. (1995). Multiple Classification Ripple Down Rules : Evaluation and Possibilities in B Gaines & M Musen, Proceedings of the 9th AAAI-Sponsored Banff Knowledge Acquisition for Knowledge-Based Systems Workshop, Banff, Canada, University of Calgary, 17.1-17.20.