Unilever Research Laboratory Vlaardingen
P.O.Box 114, 3130 AC Vlaardingen, the Netherlands
Piet-Hein.Speel@Unilever.com & Manfred.Aben@Unilever.com
This paper describes the application of a library of Problem Solving Methods (PSMs) for model-based diagnosis (Benjamins, 1993) on a real-life task. PSMs have been proposed as a comprehensive and feasible approach to the construction of conceptual models for knowledge-based systems (KBSs). A number of evaluations of this approach have been reported in the literature. Most of these evaluations have involved toy problems, or reverse engineering of existing KBSs. In this paper we have applied Benjamins' library to a real-life task.
In this paper we discuss how we have applied the PSMs during conceptual knowledge modeling, and how we had to adapt them to suit our task. We have found that the library of PSMs was extremely helpful in our project. Thanks to this reuse, the complete scope and quality of the "prime diagnostic method" was incorporated in our application, ambiguities in the task and domain were brought to light, and the functional specifications of the target system were structured transparently. Since the reuse of library components in our real-life application was not trivial, we emphasize on the need for guidelines that support knowledge engineers to apply libraries of PSMs during the development of real-life KBSs.
1. INTRODUCTION
The development of Knowledge-Based Systems (KBSs) is widely viewed as a modeling activity. The main arguments for developing structured models of knowledge and of reasoning are:
* Manageability -- divide and conquer
* Reuse -- in all phases to support rapid application development and coherence between applications.
* Communication -- among all knowledge profiles
To support these arguments, libraries have been proposed that contain reusable models or reusable model fragments (Chandrasekaran, 1990; Chandrasekaran, Johnson & Smith, 1992; Steels, 1990; Steels, 1993). Benjamins' library of problem solving methods (PSMs) for diagnosis (Benjamins, 1993; Benjamins & Jansweijer, 1994) is the most comprehensive library of knowledge models. In this paper we have applied this library to a real-life task in Unilever Research: the diagnosis and subsequent redesign of chemical experiments. In this paper we focus on the diagnosis task that is aimed at finding plausible explanations for unexpected experimental results.
The main contribution of this paper is a validation in practice of a theoretically developed framework. Benjamins' framework has moreover been developed mainly by reverse engineering of existing diagnostic algorithms. Also, Benjamins' conceptual framework has been combined with a formal model in order to guarantee that system specifications such as safety issues are met (Aben, 1995; Benjamins & Aben, 1996). Another important evaluation of Benjamins' framework, done by Orsvärn (Orsvärn, 1996), focused on the reverse engineering of an existing diagnostic KBS. We have applied the framework from scratch in the (still ongoing) development of a KBS.
This paper is structured as follows. Section 2 discusses the Unilever approach to KBS development using the CommonKADS methodology. Next, it outlines the knowledge intensive problem that we want to support with a KBS and it presents a first task analysis. In section 3 we describe Benjamins' library of PSMs for diagnosis. Sections 4 - 8 will form the bulk of our paper, as it describes in detail how Benjamins' library was used, and where we adapted his PSMs to the task at hand. Sections 9 - 10 discuss our experiences with the framework, and suggestions for improvement.
In this paper we focus on task knowledge and for reasons of sensitivity, we have abstracted from the particular Unilever domain knowledge.
2. KBS DEVELOPMENT WITHIN UNILEVER PRACTICE
Unilever is one of the world's largest fast-moving consumer goods manufacturers, with products ranging from foods and beverages to detergents and cosmetics. Unilever produces a large number of so-called "A"-brands, i.e., well-known brands of high quality products. Like many multinational corporations, Unilever is a highly knowledge-intensive company, especially since it aims to compete on quality rather than on price with the cheaper "house-brands." This aspect requires that Unilever's knowledge is well-managed and applied. Current trends in the labor-market result in reduced staff, and centralized expertise. As a consequence, it is vital to make sure that important knowledge is maintained and developed further, and can be put to immediate use when required.
As new products and processes are developed in Research, it is crucial that the application and development of knowledge are supported optimally. One way of ensuring the optimal use of available knowledge is to encode this knowledge in a KBS that supports the researcher in his tasks.
To ensure that the knowledge is captured effectively and efficiently, a well-structured methodology is crucial. In Unilever, we have selected the CommonKADS methodology for developing KBSs. We apply all models of the CommonKADS model set (i.e., the Organisation, Task, Agent, Communication, Expertise and Design Models). We are continually drawing up and refining guidelines for the application of the methodology, to ensure that our practical experience in applying CommonKADS can be shared by others in Unilever. We will not describe CommonKADS in full detail here, but refer to the standard documentation (Wielinga, Schreiber & Breuker, 1992; Schreiber, Wielinga & Breuker, 1993). (For additional CommonKADS references, we also refer to http://www.swi.psy.uva.nl/projects/CommonKADS/home.html.)
In the project that we discuss here, we first made an Organizational Model (Subsection 2.1). This model charted the present organisation of the research department that we aim to support, and the knowledge intensive problems that they have encountered. In addition, we have made a task model, describing in some detail the tasks performed by the researchers, the knowledge that is applied in these tasks and various other characteristics. Actually, in our applications so far, we have combined the Organisation, Task and Agent Model into a single feasibility and problem assessment.
Next, we have constructed an Expertise Model (Subsection 2.2). In this model, both task knowledge, inference knowledge and domain knowledge have been analysed in detail. In addition, a Communication Model has been constructed which includes the user interface in terms of computer screens. Due to this interface, the functionality of the KBS is specified. At the moment, we are constructing a Design Model which will result in the realisation of a prototype KBS.
2.1 The Client and His Knowledge Intensive Problems
We have applied the CommonKADS Organization Model in order to charter the client's organisation and to identify frequently occurring, knowledge intensive tasks that may be supported by a KBS. Our client's department focuses its research on the development of improved production processes. Their goal is to find optimal process parameters for a given input product (stock feed) and equipment, such that the output product has some desired quality characteristics.
In a large research laboratory such as those of Unilever, a huge number of experiments are performed every day, both on lab scale, on pilot plant scale and on factory scale. These experiments range from the development of new or improved product formulations to the development of new or improved processes to produce new products. Within these huge number of experiments, three frequently occurring patterns or generic tasks have been distinguished, namely "design a particular process," "optimise a particular process," and "scale up a particular process."
Unilever possesses a large amount of heuristic knowledge that is relevant for effective and efficient performance of these generic tasks. However, this knowledge in not managed optimally. First, knowledge is lost when experts leave. Fortunately, not all knowledge is lost, since many reports have been produced. This, however, leads to the second knowledge bottleneck: since knowledge is distributed over many reports, relevant knowledge is difficult to access. These knowledge bottlenecks cause delays in the research process and probably loss of quality.
Focusing on the CommonKADS Communication Model, we have built a mock-up system that mimics the prospective KBS. A mock-up is a piece of software with a deceptive user interface that suggests functionality that is actually not included internally. This mock-up system helped us refine and clarify the functional specifications.
As a result of this feasibility study, we are not aiming at a KBS that replaces the process developers. Rather, we want a system that supports them in their task such that they can make better decisions. This implies that the KBS should be transparent in the tasks that it automates, and provide choice points in the reasoning process. Such a KBS would function as a process developer's intelligent workbench.
2.2 Knowledge Modeling and Task Analysis
A CommonKADS Expertise Model has been constructed which focuses on the kernel of the KBS. This Expertise Model includes the heuristic knowledge that is relevant for the support of the three generic tasks. This heuristic knowledge has been classified as follows:
1. Task knowledge consists of knowledge of the tasks "design a particular process," "optimise a particular process," and "scale up a particular process". In particular, this knowledge consists of (1) decompositions of these tasks in sub-tasks, (2) descriptions of the goals of the tasks, and (3) descriptions of the order in which the sub-tasks are to be executed.
2. Domain knowledge consists of the knowledge of materials, equipment, processes, and measurement methods that are relevant for the tasks. In addition, a significant amount of causal knowledge is included.
3. Inference knowledge describes how domain knowledge is used in primitive tasks (or inferences).
In addition, attention has been paid to the interface of the KBS with its users (i.e., the CommonKADS Communication Model). This interface consists of sequences of computer screens. The presentation of the scenarios of screens helps to understand the functionality of the KBS on a rather detailed level. In this paper, we mainly focus on the task knowledge described above.
In particular, we focus on the "optimise a particular process" task. We start by presenting a decomposition of the task "optimise a particular process" into a sequence of subtasks. When a new process needs to be delivered satisfying a particular project brief (a formal description of the desired experimental outcome), initial information of diverse nature is collected from knowledge bases, databases, theoretical models and the literature. For example, physical and other properties of the feedstock and results of relevant, past experiments need to be gathered. In addition, initial experiments are executed to collect some additional relevant information. Based on the initial information, a sequence of experiments is designed and executed in order to obtain optimal process conditions which satisfy the specifications of the project brief. If a satisfactory experiment has been executed, the reproducibility issue raises. The question is whether the designed process is batch-stable. Therefore, additional experiments with other batches need to be executed. If satisfactory results are obtained, the main task "optimise a particular process" has been achieved. Otherwise the process is not reproducible and a new optimisation effort needs to be performed.
Thus, in order to deliver an optimal process,
* initial information is collected,
* process conditions are optimised for one batch, and
* reproducibility is tested.
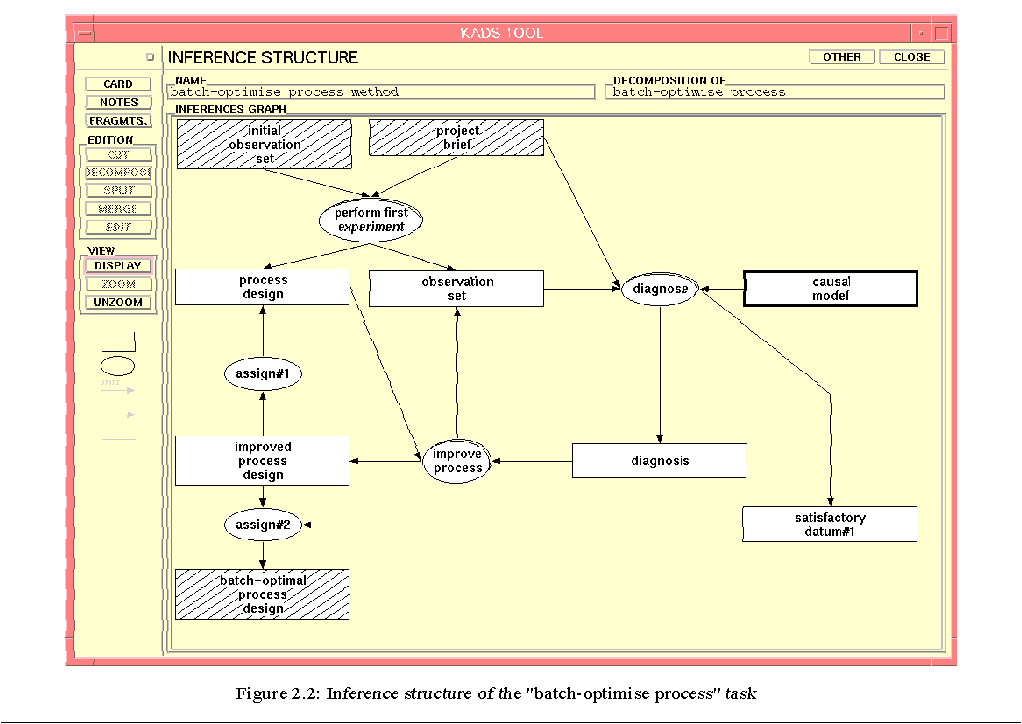
The corresponding inference structure is presented in a KADSTool© chart in Figure 2.1.
Before focusing on a diagnosis task, the subtask "batch-optimise process" needs to be analysed in more detail.
Based on the initial information collected during the first subtask, a first experiment is designed that should meet the specifications of the project brief. This experiment is executed and the empirical data are collected. The experimental data are interpreted and compared with the project brief. This comparison may result in the identification of certain problems. If problems are identified, phenomena which could cause these problems are selected. A new experiment is then formulated in order to eliminate or decrease these phenomena. Again, empirical data are collected and interpreted. The results are again compared with the project brief, and if the specifications are still not satisfactory, again problems and problem-causing phenomena are identified and again new experiments are formulated and executed. This process is repeated until either (1) the empirical results satisfy the specifications of the project brief, or (2) it is clear that the project brief cannot be satisfied. In the first case, a satisfactory process has been designed for one batch.
When reconsidering this task, a sequence of (1) problem identification and (2) selection of problem-causing phenomena, appears repeatedly. These are the main building blocks of the diagnosis task. In addition, when possible causes have been selected, a new experiment is constructed. In fact, this is a design task. Thus, in order to perform the task "batch-optimise process," the following subtasks needs to be performed:
perform first experiment
design a first process and test it empirically.
diagnose
compare the project brief with the observation set and, if a problem occurs, identify the cause of this problem,
improve process
redesign the process such that problem causes are avoided or reduced, and test the redesigned process empirically.
In Figure 2.2, the corresponding inference structure of the "batch-optimise process" task is presented. The "diagnose" task will be discussed in detail in Sections 4 - 8.
3 A LIBRARY OF PROBLEM-SOLVING METHODS FOR DIAGNOSIS
Having identified a diagnosis task that we want to support, we tried to reuse available knowledge models for diagnosis in our detailed expertise analysis. Benjamins has defined the most comprehensive library of PSMs for diagnosis that is available (Benjamins, 1993; Benjamins & Jansweijer, 1994). In this section we briefly describe the structure of this library and how to apply it in developing a detailed knowledge model.
Benjamins' library is in fact a task decomposition of diagnosis. The method of task decomposition is identical to that proposed in the CommonKADS methodology. The main ingredients of the library are (this description is copied from (Benjamins & Aben, 1996)):
* A task has a goal and is characterized by the type of input it receives and the type of output that it produces. A task goal is a specification of what needs to be achieved. For example, the goal of diagnosis is to find a diagnosis that explains all observations. A task can be decomposed into subtasks (by a PSM).
* A problem-solving method (PSM) describes how the goal of a task can be achieved. It has inputs and outputs and decomposes a task into subtasks and/or primitive tasks (called inferences). In addition, a PSM specifies the dataflow between its constituents and the control flow that determines the execution order and iterations of the subtasks and inferences.
* An inference defines a reasoning step, with its inputs and outputs, that can be carried out using domain knowledge to achieve a goal. Inferences form the actual building blocks of a problem solver. An inference is primitive, as we are not interested in detailed control within the inference.
* When all tasks are decomposed, through PSMs, into inferences, the inferences can be connected based on shared inputs and outputs (called knowledge roles). The corresponding data-flow structure formsan inference structure. An inference structure represents all possible reasoning paths of the problem solver, and does not commit to a particular problem solving strategy. Control knowledge does impose a specific problem solving strategy.
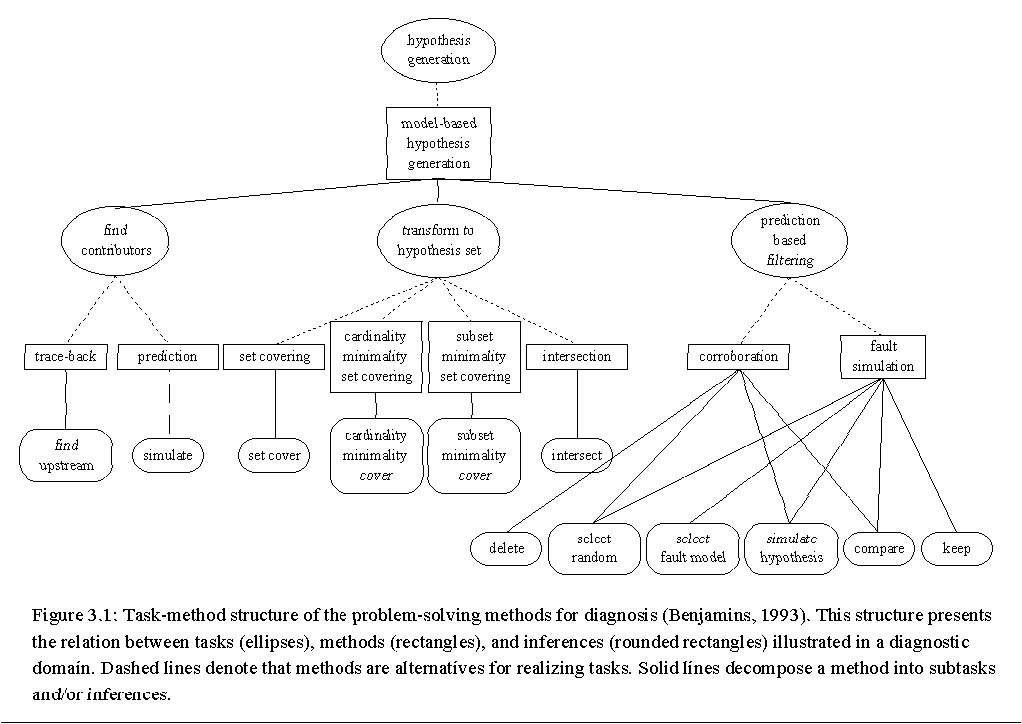
* The relations between tasks, PSMs and inferences can be depicted in a task-method structure (see Figure 3.1). The figure represents part of Benjamins' library of PSMs for diagnosis. A task may be realized by several methods, each of which propose subtasks and/or inferences. Figure 3.1 is a tangled hierarchy, since methods can be applicable to several tasks, and tasks and inferences can occur as subtasks in several places. In other words, the methods and inferences are reusable.
* To be able to actually apply a resulting problem solver, domain knowledge is required. Domain knowledge describes the declarative, domain specific knowledge of an application, independently of its use in problem solving. In our case, the domain knowledge refers to specific process steps, process parameters, product ingredients and causal knowledge.
* The domain knowledge is also used during modeling of task knowledge. PSMs have specific suitability criteria that determine whether a particular PSM can be applied to decompose a given task. These criteria can refer to the availability of domain knowledge.
In order to model the "diagnose" task in our application, we have used the following approach:
1. From Benjamins' library, we have selected the task structures and inference structures which correspond to the "diagnose" task in the application.
2. We have reused the selected task structures and inference structures. This means that we have copied the selected structures and slightly adapted them to meet the application-specific requirements. In particular, we have focused on
* decompositions of tasks and PSMs,
* inference structures (i.e., data flow) for each task,
* knowledge role mappings onto domain knowledge.
The result is a tailored PSM for diagnosis in the application.
3. We have presented the tailored PSM in KADSTool© using the available implemented KADSTool© structures of the selected task structures and inference structures.
4. THE "DIAGNOSE" TASK AND THE "PRIME DIAGNOSTIC METHOD"
Diagnosis is the task of identifying the cause of a problem. In the application, a problem is defined as unsatisfactory observed experimental data in comparison with expectations that are stated in a project brief. If a problem occurs, heuristic knowledge is used to generate a diagnosis. The heuristic knowledge consists of causal relations.
The general PSM for performing diagnoses is called the "prime diagnostic method" and is reused in the application. This diagnostic PSM is decomposed into a sequence of three subtasks:
detect symptoms
determine which of the initial observations (experimental data) are considered abnormal and which are considered normal,
generate hypotheses
generate possible causes that take into account the initial observations,
discriminate hypotheses
discriminate between the generated hypotheses based on additional observations.
Knowledge role mappings onto domain knowledge
The knowledge role "expectation set" is mapped onto parameters of the project brief in the domain layer.
The knowledge role "observation set" is mapped onto experiment parameters in the domain layer. The parameters of the project brief are also used for experiment. The knowledge role "causal model" is discussed in detail in Section 6.
Reuse considerations:
In general, the "prime diagnostic method" can be reused very well. However, two modifications have been made:
1. The input of the "diagnose" task is formed by only observations (Section 5.1 of (Benjamins, 1993)). In the application, expectations in the form of specifications of a project brief are added.
2. The control knowledge of the "detect symptoms" subtask has changed. These differences are described in Section 5.
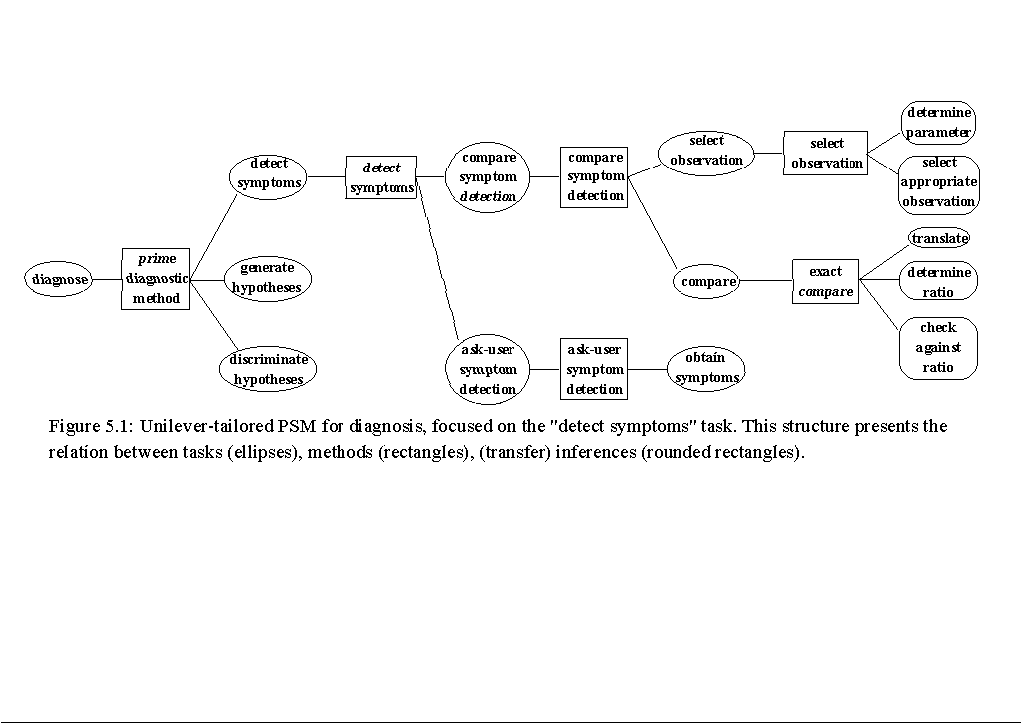
5 THE "DETECT SYMPTOMS" TASK
For an overview of this section see Figure 5.1.
The input of the "detect symptoms" task is a set of expectations and a set of initial observations. This task decides whether observations satisfactorily correspond to the expectations. Observations that do not correspond to the expectations are called "abnormality observations" or "symptoms." In the application, abnormality observations are defined as results of an experiment that are deviant according to the project brief. The collection of all symptoms that results from comparisons between the project brief and the experimental data are the input for the "generate hypotheses" task.
In (Benjamins, 1993), three alternative PSMs to perform the "detect symptoms" task are presented. Two of them are relevant for the application:
compare symptom detection
An expected value that is stated in the project brief is mechanically compared with the corresponding observed value.
ask-user symptoms detection
The user is asked to provide the symptoms.
Since project briefs are currently not stated explicitly, a mechanical comparison is not possible. Therefore, the "ask-user symptoms detection" PSM is the only way to collect symptoms. As soon as project briefs and experimental data are available electronically, a mechanical comparison is possible, using the "compare symptom detection" PSM. Since it is always preferred not to bother the user with questions, the "compare symptom detection" PSM is preferred above the "ask-user symptoms detection" PSM. The PSMs "compare symptom detection" and "ask-user symptoms detection" are discussed in Subsections 5.1 and 5.2.
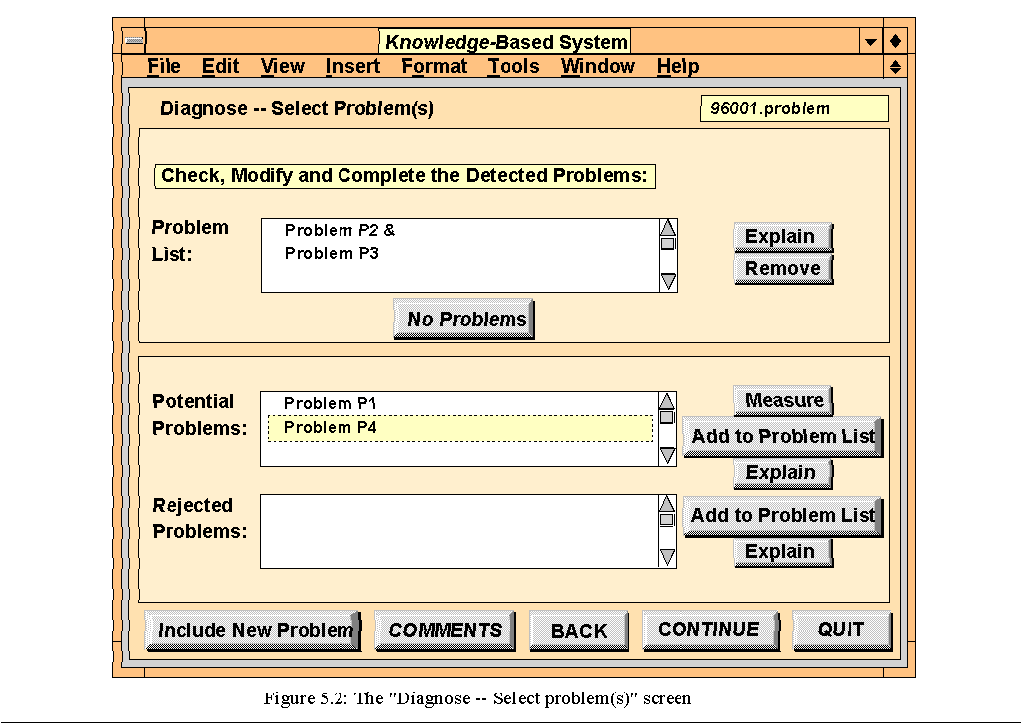
The output of this task is presented in the computer screen in Figure 5.2. The screen is divided into two parts. The top part presents the list of detected problems. Initially, only the problems detected by the "compare symptom detection" task are presented. The user is able to modify this initial problem list during the "ask-user symptoms detection" task. Three user actions are distinguished:
1. If the user decides that no problems have been occurred (i.e., the comparison of the project brief with the observation set is satisfactory), the user can select the "No Problems" button.
(If the "compare symptom detection" task has not detected any problems, then the message "No problems detected with the information available" is presented in the "Problem List.")
2. If the user wants to add a problem, the bottom part of the screen becomes important. Two classes of problems have been distinguished, namely potential problems and rejected problems.
A. Potential problems are optional problems that are not confirmed by the KBS due to lack of information (either from the project brief or the observation set). The user is able to measure the parameter corresponding to the potential problem and enter its value due to the selection of the "Measure" button. If a comparison can be made due to this additional observation, the "compare symptom detection" task will replace the potential problem to either the "Problem List" or classify it under the "Rejected Problems."
B. Rejected problems are problems that are rejected by the "compare symptom detection" task since the particular observations of the tested process satisfy the corresponding requirement of the project brief.
Using the "Add to Problem List" button, the user is able to add potential and rejected problems to the "Problem List." (In case a rejected problem is added to the "Problem List," the user overrules the KBS.)
3. If the user wants to remove a problem from the "Problem List," the problem should be selected, and in addition, the "Remove" button should be pressed (in this case, the user also overrules the KBS).
Reuse considerations:
In general, the two PSMs of the "detect symptoms" task can be reused very well. However, three modifications have been made:
1. Since two PSMs for the "detect symptoms" task have been selected and since control over these PSMs is explicitly stated, an intermediary PSM-task level has been included for the application. This means that an additional "detect symptoms" PSM has been introduced which dynamically controls the application of either a "compare symptom detection" task or an "ask-user symptoms detection" task. These tasks are performed using the corresponding "compare symptom detection" and "ask-user symptoms detection" PSMs, respectively.
2. Whereas the PSMs described in (Benjamins, 1993) focus on the detection of a single symptom (stated in the control regimes of the corresponding PSMs, pages 49, 51 and 53 of (Benjamins, 1993)), in the application, for each experiment a set of one or more symptoms needs to be detected. In particular, the "ask-user symptoms detection" PSM results in a set of symptoms.
3. In our application, expectations in the form of specifications of a project brief have been added. In (Benjamins, 1993), page 49, the control of symptom detection is based on observations (FORALL o ELEMENT-OF Oinit DO ...). In contrast, expectations lead the control of symptom detection in our application (FORALL e ELEMENT-OF "Project Brief" DO ...). This means that a symptom is detected as soon as an expectation is not accompanied with a satisfactory observation.
5.1 The "Compare Symptom Detection" Task
The goal of the "compare symptom detection" task is to mechanically detect a symptom by comparing an expected value (a specification of the project brief) with the corresponding observed value (a measure of an experiment). The PSM of the "compare symptom detection" task consists of two subsequent subtasks:
select observation
The observation that corresponds to the expectation in consideration is selected from the set of observations.
compare
Each expectation is compared with the corresponding observation. Two kinds of results are possible, namely "satisfactory" or "not satisfactory," which correspond to either normality or abnormality observations.
The subtasks "select observation" and "compare" are discussed in Subsections 5.1.1 and 5.1.2.
Reuse considerations:
The "compare symptom detection" PSM has been modified considerably for the application. The main differences are discussed in the following subsections.
5.1.1 The "Select Observation" Task
Focusing on the "select observation" task, an observation needs to be selected from the observation set which corresponds to the expectation considered. Two subtasks need to be performed to select the desired observation:
determine parameter
The parameter of the expectation is determined in order to be able to select the corresponding observation.
select appropriate observation
From the observation set, the observation with a corresponding parameter is selected.
"Determine parameter" and "select appropriate observation" are primitive tasks or inferences which will not be discussed in this paper.
Reuse considerations:
The "select observation" PSM does not occur in (Benjamins, 1993), neither do the subtasks "determine parameter" and "select appropriate observation."
5.1.2 The "Compare" Task
Focusing on the "compare" task, six PSMs are described in (Benjamins, 1993). Since an expectation can exactly be compared with its corresponding observation in the application, the "exact compare" PSM was first considered. The inference used in the "exact compare" PSM is the "equal check," which checks whether two values are equal (using the '=' symbol). In addition to equality, inclusion can occur as well in the application. For example, a particular parameter's value could be in a particular value range. Therefore, instead of the "equal check," the inferences used in the "treshold compare" PSM have been reused for inclusion in a value range.The "equal check" can be included in the "treshold compare" PSM.
Besides these straightforward comparisons, more complex comparisons need to be considered too. For example, an expectation might be a "satisfactory yield." Here the "yield" has a qualitative value. However, the corresponding observed value is usually of a quantitative nature, such as "yield is 30 %." In order to compare qualitative and quantitative values, Qualitative Abstraction Knowledge is used in a "translate" inference.
Knowledge role mappings onto domain knowledge
The knowledge role "qualitative abstraction knowledge" is mapped onto parameter value qualitative abstraction knowledge in the domain layer.
Reuse considerations:
The "threshold compare" PSM has been extended for the application. A "translate" inference has been included which realises the possibility to compare qualitative values with quantitative values.
5.2 The "Ask-User Symptoms Detection" Task
The goal of the "ask-user symptoms detection" task is to ask the user to provide the symptoms. The PSM for this task consists of a single "obtain symptoms" task, during which information is obtained from outside the system, namely from the user. Therefore, this primitive task is also called a "transfer inference."
Reuse considerations:
The PSM for the "ask-user symptoms detection" task is closely related to the PSM described in Subsection 5.2.3 in (Benjamins, 1993). The difference is that in the application, observations might not be available in the system (which is required in (Benjamins, 1993)). Therefore, the user is directly asked to provide symptoms.
6 A CAUSAL DEVICE MODEL FOR THE APPLICATION
After discussing the "detect symptoms" subtask in Section 5, the following subtask to be performed in the "prime diagnostic method" is the "generate hypotheses" subtask (which will be discussed in detail in Section 7). (Benjamins, 1993) presents two PSMs to perform the "generate hypotheses" task, namely:
empirical hypothesis generation method
This PSM employs associations between observations and hypotheses (there is no underlying device model) which yield a provisional hypothesis set.
model-based hypothesis generation method
Based on a device model, a set of device model entities that contribute to an abnormality observation is determined first. Then, the contributor set is transferred to a hypothesis set. In addition, a testing process is used to reduce the hypothesis set, taking into account only the initial observations.
In order to choose one of these PSMs, the following question needs to be answered:
Does a "device model" for processes exist?
To answer this question, a closer look is taken at the available knowledge.
As a result of a series of brainstorm sessions with experts, a set of problems P1, . . . , P4 and a set of causes C1, . . . , C11 have been identified, together with a number of causal dependencies.
The causal relations represent particular experiences of the experts. Therefore, these relations form heuristic knowledge.
In Section 2.2 of (Benjamins, 1993), three types of device models are discussed, namely "component centered device models," "causal device models," and "functional device models." Since the knowledge discussed above consists of causal relations, this knowledge might be collected in a causal device model which is discussed in more detail.
"Causal device models describe a device in terms of states that have a cause-effect. Nodes in a causal model represent particular states in a system (e.g., "temperature of the engine is high"). [...] Instead of representing the local behavior of each device component separately, a causal model represents the (causal) relations between specific component output values (states)." (Quote from (Benjamins, 1993), page 8.)
From this description, we conclude that a causal device model can be used for the application. Three additional characteristics of a device model need to be discussed. First, the model could be focused on correct (intended) behaviour or fault behaviour. Since the application knowledge describes problem causes, only fault behaviour is contained in the causal model. Second, a device model can be of qualitative or quantitative nature. Quantitative models are precise models, where the behavior of the model entities is usually mathematically described. Qualitative models describe the important concepts in qualitative terms. The following relations are used in the application:
"A possible cause of a yield which is too low is that the particles of the feedstock are too small."
Therefore, the causal model is of a qualitative nature. Third, it is important to know whether the device model is complete. In the causal model, we strive for completeness.
Knowledge role mappings onto domain knowledge
The knowledge role "causal model" is mapped onto causal knowledge in the domain layer. Thus, the causal model is not part of the task or inference knowledge.
7 THE "GENERATE HYPOTHESES" TASK
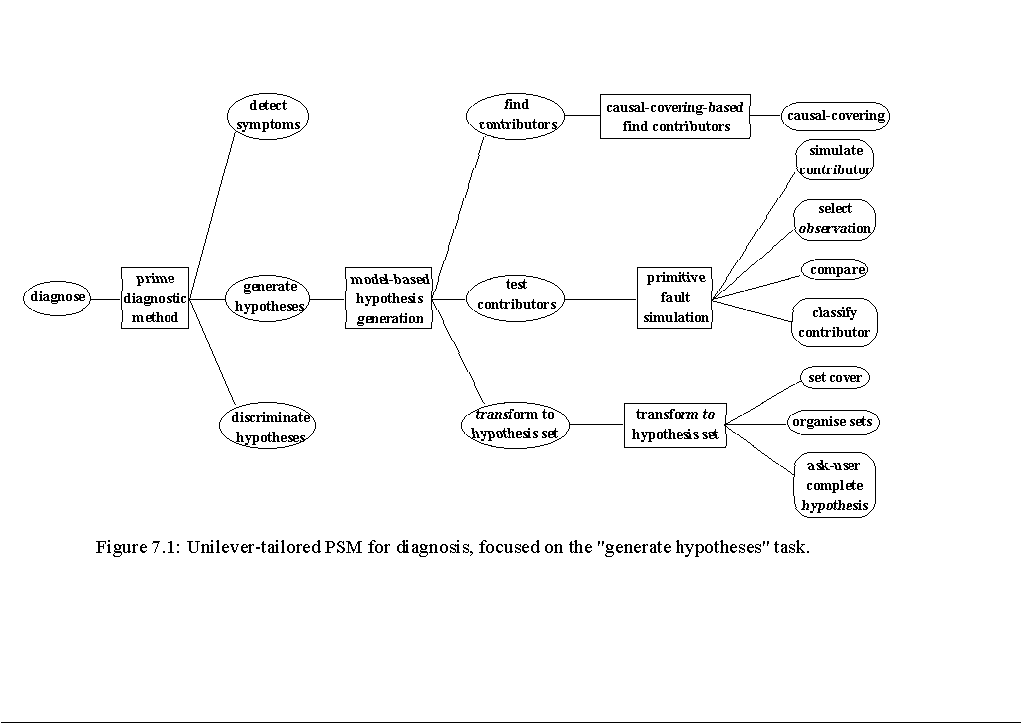
For an overview of this section see Figure 7.1.
The input for the "generate hypotheses" task is a set of symptoms. The task generates hypotheses that take into account the initial observations and collects them in a hypothesis set, which is the input for the "discriminate hypotheses" task. A hypothesis is defined as a possible explanation for the observations.
In the application, the "model-based hypothesis generation" PSM is used to perform the "generate hypotheses" task. Based on the causal device model discussed in Section 6, a set of contributors of an abnormality observation is determined first. Then, a testing process is used to classify contributors as "explanatory," "potential," or "rejectable," using only initial observations. Finally, the classified contributor set is transferred to a hypothesis set. Thus, the model-based PSM for hypotheses generation consists of three subtasks:
find contributors
For each symptom, find a set of causal model entities (i.e., particular states in an experiment) that contribute to this abnormality observation.
test contributors
Classify the contributors as "explanatory," "potential," or "rejectable," considering only initial observations.
transform to hypothesis set
Transform the contributor set to a hypothesis set. The definition of a hypothesis set is that every element is a possible explanation for all observations.
Reuse considerations:
The "generate hypotheses" task together with its model-based PSM (Subsection 5.5.2 of (Benjamins, 1993)) can be reused for the application. However, instead of testing hypotheses in the "prediction-based filtering" task (described in Section 5.8 of (Benjamins, 1993)), contributors are tested in the application. The reason for testing contributors instead of hypotheses is that initial observations directly correspond to contributors (both focusing on parameters in the domain).
7.1 The "Find Contributors" Task
The input of the "find contributors" task is a set of symptoms. The goal is to find a set of contributors for each symptom. A contributor is a particular fault state in an experiment. The output of the "find contributors" is a set of contributor sets.
For the "find contributors" task, three PSMs are described in (Benjamins, 1993). Only the "causal-covering-based find contributors" PSM is based on a causal device model. Therefore, this PSM is used in the application. The PSM is based on the following task:
causal covering
For each symptom of the symptom set, contributors for this symptom are collected. For this purpose, the causal relations in the causal device model are used.
The "causal covering" task is considered to be a primitive task or an inference. Within the causal device model, first a symptom is located, then, following the causal relations in the model, contributors are identified, which finally are collected in a symptom contributor set.
Reuse considerations:
The "causal-covering-based find contributors" PSM for the "find contributors" task (Subsection 5.6.2 in (Benjamins, 1993)) is successfully reused for the application.
7.2 The "Test Contributors" Task
The input of the "test contributors" task is a set of contributor sets. The goal is to discard as many contributors as possible, considering only initial observations. In Section 5.8 of (Benjamins, 1993), three PSMs to perform this task are presented. Since only a (primitive) fault model is available in the application, the "fault simulation" PSM is reused.
The "fault simulation" PSM exploits a fault model. A contributor is selected from the contributor set and is instantiated with the fault model that describes its fault behavior. Subsequently, a simulation is done which yields a set of expectations of what observations need to be seen given that the contributor is the case.
The next comparison step considers the set of expectations and the set of initial observations. For each expectation, the corresponding initial observation is selected (if available) and a comparison is made. For this purpose, the "select observation" and the "compare" tasks (Subsections 5.1.1 and 5.1.2) are reused. Note that at this stage no interaction with the user is considered. Only the initial observations are taken into account.
Based on the results of the comparison step, the contributors are classified. Three classes are distinguished:
1. Explanatory contributors, namely, contributors explaining initial observations. Contributors are "explanatory" if the corresponding "compare" task yields a "satisfactory" datum.
2. Rejectable contributors, namely, contributors in conflict with initial observations. Contributors are "rejectable" if the corresponding "compare" task yields an "unsatisfactory" datum.
3. Potential contributors, namely, contributors that are neither explaining nor in conflict with initial observations. Contributors are "potential" if the corresponding "compare" task yields neither a "satisfactory" nor an "unsatisfactory" datum.
In the "transform to hypothesis set" task (Section 7.3), this information is used to transform the contributors in a hypothesis set and to provide the user relevant information about hypotheses.
Thus, the "primitive fault simulation" PSM consists of the following subtasks:
simulate contributor
Do a simulation that yields a set of expectations of what observations need to be seen given that the contributor is the case.
select observation
The observation that corresponds to the contributor in consideration is selected from the set of observations (Subsection 5.1.1).
compare
Each expectation is compared with the corresponding observation (Subsection 5.1.2).
classify contributor
Classify a contributor as "explanatory" or "rejectable" in the set of contributor sets. The classified contributor set is the resulting set of contributor sets, where each contributor has one of the predicates "explanatory," "rejectable," or "potential" (a contributor is "potential" if it is not "explanatory" and not "rejectable").
Knowledge role mappings onto domain knowledge
The knowledge role "fault model" is mapped onto malfunction knowledge in the domain layer and the knowledge role "qualitative abstraction knowledge" is mapped onto parameter value qualitative abstraction knowledge.
Reuse considerations:
The "fault simulation" PSM for the "test contributors" task (described in Subsection 5.8.3 of (Benjamins, 1993)) is successfully reused for the application. However, the PSM is applied to contributors here, whereas it is applied to hypotheses in (Benjamins, 1993). In addition, the result is not a reduced set where "rejectable" elements have been discarded, but a classified set including "explanatory," "rejectable," and "potential" elements, to use all obtained information in the "transform to hypothesis set" task.
7.3 The "Transform to Hypothesis Set" Task
The input of the "transform to hypothesis set" task is a classified contributor set. This contributor set contains a set of contributors for each symptom. However, a contributor for one symptom does not have to be a contributor for another symptom. Therefore, the contributor set needs to be transformed into a hypothesis set. Each hypothesis in this set explains all initial observations (including all detected symptoms). Thus, a hypothesis consists of one or more fault states in an experiment that together explain all initial abnormality and normality observations.
7.3.1 The "Set Cover" PSM
One way for transforming the contributor sets into a hypothesis set is to apply the "set cover" PSM (Subsection 5.7.1 of (Benjamins, 1993)). The PSM operates on sets and the goal states that a hypothesis should have a nonempty intersection with any of the contributor sets (guaranteeing an explanation for each symptom). Therefore, a hypothesis "covers" all contributor sets. Note that only "explanatory" and "potential" contributors are considered in this PSM.
For example, consider the following causal device model. If both symptoms P2 and P3 have been detected, then, two corresponding contributor sets are determined during the "find contributors" task; say
{C2, C4, C5, C6, C8, C11} for symptom P2 and {C6, C7, C8, C9, C11} for P3.
{C6} is a hypothesis since C6 explains both symptoms P2 and P3. Another hypothesis is {C2, C7}, where C2 explains P2 and C7 explains P3. The hypothesis set is generated by the "set cover" PSM and becomes very large. An incomplete description of this hypothesis set is the following:
{{C6}, {C8}, {C11}, {C2, C6}, {C2, C7}, {C2, C8}, {C2, C9}, {C2, C11}, . . . , {C9, C11}, {C2, C4, C6}, {C2, C4, C7}, . . . {C8, C9, C11}, . . . , {C2, C4, C5, C6, C7, C8, C9, C11}}
7.3.2 Why Parsimony Optimisation PSMs Cannot be Applied
Since the "set cover" PSM usually generates many hypotheses, all kinds of parsimony optimisations have been proposed (Subsection 5.7.2-5.7.4 of (Benjamins, 1993)). For example, one could consider only "single fault hypotheses." However, in our application, symptoms are occasionally explained by more than one fault state. Thus, "multi faults hypotheses" should be considered as well. In addition, subset minimality could be applied as the parsimony criterion. This means that valid hypotheses have to be subset minimal. A hypothesis h is subset minimal if it has no proper subset h' which is also a valid hypothesis. Considering the example hypothesis set above, the hypothesis {C2, C6} is not subset minimal since hypothesis {C6} is a proper subset that is also a valid hypothesis. However, in our application, this "subsetminimality" assumption does not hold. Both C2 and C6 could be causes for problems P2 and P3.
The "cardinality minimality" PSM could neither be applied since the "cardinality minimality" assumption does not hold. The previous example also illustrates the inadequacy of this PSM. Therefore, we conclude that none of the parsimony optimisation approaches can be reused.
7.3.3 Presenting Classified Contributors Instead of Hypotheses
Due to the large set of hypotheses, we do not want to present all these hypotheses on a computer screen. Instead, we have chosen to present the contributor classes explanatory contributors, potential contributors, and rejectable contributors to the user (corresponding to "Diagnosis," "Potential Causes," and "Rejected Causes" in Figure 7.2, respectively). The reasons for this decision are that
1. the presentation of a possibly large set of hypotheses to the user does not seem informative,
2. users are focused on contributors (problematic parameters) rather than hypotheses (such as the combination of parameters C5 and C11, or the combination of C2, C5 and C11, or the combination C2, C4, C5, C7, C8, C9 and C11, etc.), and
3. users should be able to overrule the conclusions derived by the Knowledge-Based System.
For example, consider the following classified contributors for problems P2 and P3: C5 is an explanatory contributor, C2, C4, C7, C8, C9 and C11 are potential contributors, and C6 is a rejectable contributor. Instead of the hypotheses presentation:
{{C5, C7}, {C5, C8}, {C5, C9}, {C5, C11}, {C2, C5, C7}, {C2, C5, C8}, {C2, C5, C9}, {C2, C5, C11}, {C4, C5, C7}, {C4, C5, C8}, {C4, C5, C9}, {C4, C5, C11}, . . . , {C5, C9, C11}, {C2, C4, C5, C7}, . . . {C5, C8, C9, C11}, . . . , {C2, C4, C5, C7, C8, C9, C11}}
the following presentation of classified contributors is shown (Figure 7.2):
* an explanatory contributor: C5,
* potential contributors: C8, C11, C2, C4, C7, C9, and
* a rejectable contributor: C6.
Note that the contributors of the contributor "potential contributors" class are ranked according to the number of contributors in each hypothesis. For example, contributor C8 is placed before contributors C4 and C7, since C8 is included in hypothesis {C8} with cardinality one, and C4 and C7 are included in hypothesis {C4, C7} with cardinality two. For a more detailed ranking, domain knowledge (for example, with respect to costs) might be added later.
7.3.4 Decomposition of the "Transform to Hypothesis" Task
We want to reduce the set of contributors (and thus, the set of hypotheses) and we want the user to decide which contributors are relevant. Therefore, the user is asked to augment the class of explanatory contributors with potential contributors. Note that since we do not want to restrict the user, he/she is also able to overrule the suggestions made by the Knowledge-Based System and add or remove every contributor he/she wants. The result is a set of contributors that represents a set of hypotheses (namely all subsets of this set computed by the "set cover" PSM). The set of hypotheses, represented by this contributor set, is the output of the "transform to hypothesis set" task.
Thus, the "transform to hypothesis set" PSM consists of three subtasks:
set cover
Compute hypotheses due to the generation of non-empty intersections with any of the contributor sets included in the classified contributor set, not considering rejectable contributors.
organise sets
Collect explanatory contributors, potential contributors and rejectable contributors and rank them using information obtained from the cardinality of contributor sets computed by the "set cover" task. Note that this primitive task in fact does not produce any new knowledge.
ask-user complete hypothesis
Ask the user to augment the class of explanatory contributors with potential contributors to obtain a set of contributors that represents a set of hypotheses.
Consider the computer screen in Figure 7.2, which is produced by the "organise sets" task. The"Diagnosis" part should present the list of contributors that explains the list of detected problems. Initially, only the explanatory contributors determined by the "find contributors" and "test contributors" tasks are included. The user is able to modify this initial list of contributors and complete it to a diagnosis. Two user actions are distinguished:
1. If the user wants to add a contributor, the bottom part of the screen becomes important. Two classes of contributors have been distinguished, namely potential contributors and rejected contributors.
A. Potential contributors are optional contributors that are not confirmed by the KBS due to lack of information (from the observation set). The user is able to measure the parameter corresponding to the optional problem and enter its value due to the selection of the "Measure" button. Using this additional observation, the KBS will replace the potential contributor to either the "Diagnosis" or classify it under the "Rejected Contributors." The measuring activity and the classification activity form part of the "discriminate hyportheses" task which will be discussed in Section 8.
B. Rejected problems are problems that are rejected by the KBS since the particular observations of the tested process are not considered to be problematic.
Using the "Add to Diagnosis" button, the user is able to add potential and rejected contributors to the "Diagnosis." (In case a rejected contributor is added to the "Diagnosis," the user overrules the KBS.)
2. If the user wants to remove a contributor from the "Diagnosis," the contributor should be selected, and in addition, the "Remove" button should be pressed (in this case, the user also overrules the KBS).
Reuse considerations:
For the "transform to hypothesis set" task, only the "set-cover" subtask (described in Subsection 5.7.1 of (Benjamins, 1993)) is reused in the application. In addition, an application-specific, user-interactive approach is applied.
8 THE "DISCRIMINATE HYPOTHESES" TASK
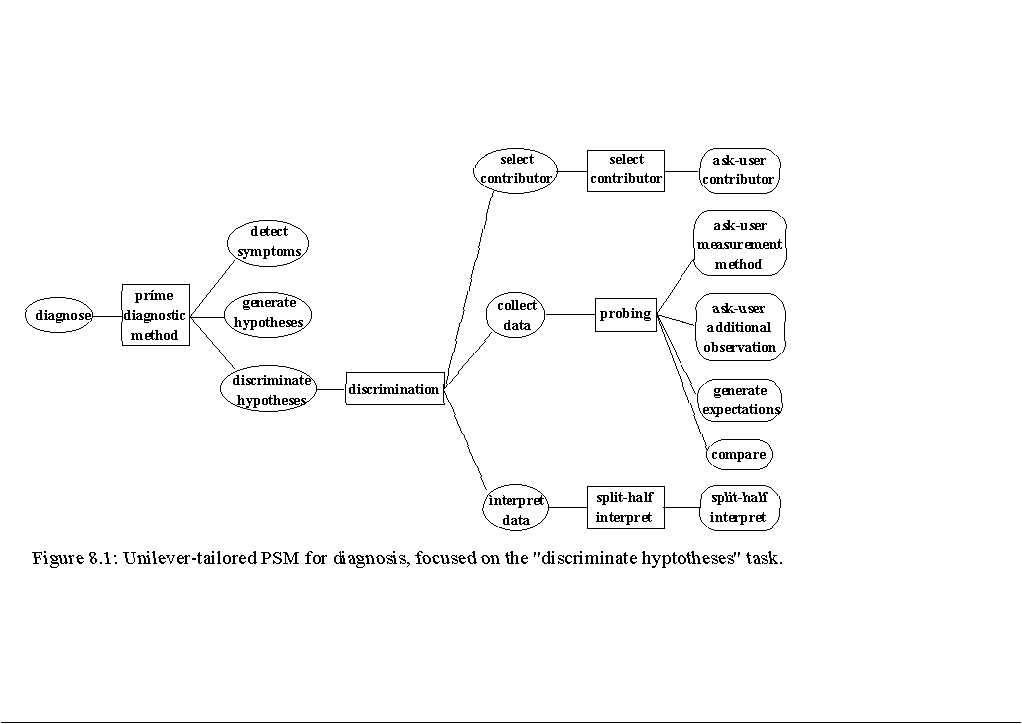
For an overview of this section see Figure 8.1.
The input of the "discriminate hypotheses" task is a hypothesis set, which is represented by a set of contributors. During the "discriminate hypotheses" task, additional observations are taken into account to discriminate between hypotheses and to deliver a diagnosis that explains both the initial and additional observations. For this purpose, the user can select the "Measure" button on the screen in Figure 7.2. The "discriminate hypotheses" task is realised by the "discrimination" PSM that consists of three subtasks:
select contributor
Select a contributor about which additional data are required to prune the hypothesis set.
collect data
Collect additional observations and determine whether the nature of the corresponding parameter is problematic.
interpret data
Process the impact of the additional observations with respect to the hypothesis set.
Reuse considerations:
The "discriminate hypotheses" task and the "discrimination" PSM have been reused (see (Benjamins, 1993), Section 5.9 for a detailed description). Two differences are distinguished:
1. The focus is on contributors rather than hypotheses.
2. The control of the PSM is directed by the users in the application.
8.1 The "Select Contributor" Task
The first subtask of the "discrimination" PSM is to select a contributor about which additional data are required to prune the hypothesis set. The task input is the hypothesis set and the output is a contributor.
In (Benjamins, 1993), Subsections 5.10.1 and 5.10.2, two PSMs are described. In the "random hypothesis selection" PSM, a hypothesis is randomly picked from the hypothesis set. In the "smart hypothesis selection" PSM, a hypothesis is selected according to some domain-dependent criterion, such as the cost of measuring, or to reduce the number of expected measurements.
In the application, users can make the choice (if they want to do an additional measurement). For each contributor, the user is supported with information about "what to measure" and "how to measure" to be able to discard the contributor of interest from the hypothesis set (hidden under the "Measure" button on the screen in Figure 7.2).
The PSM for this task consists of a single "ask-user contributor" task, during which information is obtained from the user.
Reuse considerations:
The two PSMs for the "select hypothesis" task described in Subsections 5.10.1 and 5.10.2 of (Benjamins, 1993) are not used in the application (on the short term). An "ask-user contributor" task is used instead, with similarities to the "ask-user symptoms detection" task (Section 5.2). Note again, that the focus is on contributors rather than hypotheses.
8.2 The "Collect Data" Task
The "collect data" task is concerned with collecting additional data to discard hypotheses from the hypothesis set. In (Benjamins, 1993), Section 5.12, four PSMs for data collection are discussed. Three PSMs are based on doing additional experiments. Since the execution of an additional experiment within the Unilever environment is expensive (in fact, we strive for a reduction of experiments), these PSMs will not be applied in our application. Instead, the "probing" PSM is used.
The "probing" PSM collects additional data by taking measurements at the device. For each contributor, a list of measurement methods is available ("measurement knowledge"). The user is asked to first select a feasible one and then to carry out the measurement. This user-activity results in one or more additional observations.
Then, for the parameter in consideration, corresponding expectations are collected using the "fault model." These expectations are used to decide whether the nature of the observed parameter is problematic.
Finally, the additional observations are compared with the expectations. This results in a particular datum called "parameter nature." To make comparisons possible between quantitative parameter values and qualitative parameter values, again "qualitative abstraction knowledge" is used.
Thus, the "probing" PSM is decomposed into the following subtasks:
ask-user measurement method
A collection of measurement methods is presented to the user, and the user is asked to select one or more feasible methods.
ask-user additional observation
The user is asked to carry out the actual measurement resulting in one or more additional observations.
generate expectations
Derive the expectations related to the additional observations.
compare
The additional observations are compared with the corresponding expectations. This results in a particular datum expressing the nature of the parameter in consideration (see also Subsection 5.1.2).
Knowledge role mappings onto domain knowledge
The knowledge role "measurement knowledge" is mapped onto measurement method knowledge in the domain layer, the knowledge role "fault model" is mapped onto malfunction knowledge and the knowledge role "qualitative abstraction knowledge" is mapped onto parameter value qualitative abstraction knowledge.
Reuse considerations:
The "probing" PSM for the "collect data" task (described in Subsection 5.12.2 of (Benjamins, 1993)) is successfully reused for the application. However, instead of focusing on findings in a "select-finding" task (Benjamins, 1993), Subsection 5.12.2, measurement methods are considered in the "ask-user measurement method" task. In addition, the "compare" task described in Subsection 5.1.2 is reused for the second time.
8.3 The "Interpret Data" Task
Based on the data collected in the previous task, the purpose of the "interpret data" task is to decide whether contributors can be discarded from the hypothesis set. The output of the task is a diagnosis, in the form of a contributor set, which explains both the initial and the additional observations.
Three PSMs of increasing complexity are described in Section 4.15 of (Benjamins, 1993). The first one only considers the possible removal of the contributor selected during the "select contributor" task. The drawback is that possible implications are missed. The third PSM adds the new observations to the initial observations and re-applies the "generate hypotheses" task. The disadvantage of this PSM is that the "generate hypotheses" task is time-consuming. Therefore, the second PSM is used in the application.
The "split-half interpret" PSM splits a contributor set, based on the result of testing a contributor, in two sets: a 'reject' set and a 'verified' set. After the contributor set has been verified, the 'verified' set becomes the updated contributor set.
A straightforward way to test whether a contributor should be discarded from the contributor set is to check whether the observed nature of the parameter violates the contributor; where each contributor assumes the existence of a parameter with problematic nature (which causes one or more symptoms to arise). For example, the contributor "problematic particle size" assumes the parameter "particle size"has a problematic small size. However, if the "particle size" is reasonably large, then this parameter is determined to be "not problematic." Therefore, the contributor "problematic particle size" can be discarded from the contributor set (and classified as a "rejectable contributor").
In addition, the dependencies between the contributors in the contributor set could be exploited. If contributors in the set are related, a test result of one has implications for the others. If a particular contributor is falsified, all contributors that participate to the output of the tested contributor, can be discarded from the set as well. If the contributor is verified, all participating contributors to the verified contributor make up the updated contributor set.
At the moment, dependencies between contributors are not determined in the application. Nevertheless, dependencies may arise in the future, therefore, this strategy may become relevant. The dependencies will then be stored in the causal model.
Reuse considerations:
The PSM for the "interpret data" task described in this subsection is based on the "interpret in isolation" PSM and the "split-half interpret" PSM (Subsections 5.14.1 and 5.14.2 of (Benjamins, 1993)). Note again, that the focus is on contributors rather than hypotheses.
9. DISCUSSION
In the previous sections, we have reported how Benjamins' library of problem solving methods (PSMs) for diagnosis has been reused in a real-life application. We have included specific "reuse considerations" for each library component. In this section, we try to abstract from these specific reuse considerations and pay attention to some general findings.
From the application discussed in this paper, we have learned that due to application-specific requirements, tasks and PSMs from a library need to be modified to suit the application. A library of tasks and PSMs provides the "what to reuse" but not the "how to reuse." Consequently, a knowledge engineer needs to make the following decisions for the reuse of library components:
1. How to reuse as many library components as possible?
2. How to select the most adequate library components?
3. How to best modify the selected library components?
The development of guidelines that support the knowledge engineer in using PSM libraries is required. To initiate this development, we discuss some issues that are relevant for the decision types mentioned above. In addition, we include examples from our application for illustrative purposes. Additional case studies are needed in order to derive actual guidelines that are useful for the development of real-life KBSs.
In order to reuse as many PSMs as possible, a knowledge engineer needs to know whether a PSM that does not exactly fit the conceptualisation of the application can be reused. Two approaches can be applied in order to reuse the candidate PSMs:
1. The knowledge engineer can modify the PSM in order to meet the application-specific requirements.
2. The knowledge engineer can include a subtask preceding the PSM that reconceptualises the application such that the PSM can be reused without (significant) modifications.
A tradeoff exists between the complexity of the subtask preceding the PSM and the complexity of the PSM modification: If the subtask becomes too complex, then the PSM should be modified and if the modifications of the PSM become too complex, then the introduction of a subtask should be considered. If both the preceding subtask and the PSM modification are too complex, then the PSM is not reusable.
We illustrate the two approaches with an example focused on the control knowledge for the "detect symptoms" task (Subsection 5.1). In (Benjamins, 1993), page 49, the control of symptom detection is based on observations (FORALL o ELEMENT-OF Oinit DO ...). In our application (Subsection 5.1.1), we chose to modify the PSM. As a result, expectations lead the control of symptom detection (FORALL e ELEMENT-OF "Project Brief" DO ...). Due to this design decision, the control of the "prime diagnostic method" was changed considerably.
Alternatively, a subtask preceding the "prime diagnostic method" could be designed in which key parameters were extracted from the expectations of the project brief. Using these key parameters, it should be possible to adopt the control based on observations from the library (only a selection of observations based on these key parameters needs to be included). Since this extraction subtask preceding the PSM does not seem to be very complex, we prefer this approach in this case. This preferred alternative will be incorporated in the task layer in the near future.
Guidelines supporting the knowledge engineer in choosing between the two approaches would have helped us to select the second approach immediately.
In order to select appropriate PSMs, various selection criteria have been introduced in the literature (Chandrasekaran, 1990; Steels, 1990; Benjamins, 1993; Orsvärn, 1996). These selection criteria indeed helped us in our application to select adequate PSMs. For example, the first sub-task of the "generate hypothesis" task is the "find contributors" task (Section 7). For this "find contributors" task, three PSMs are available (Section 5.6 of (Benjamins, 1993)). We used the epistemological criterion (focusing on the type of domain knowledge) to make an adequate selection. Since only causal knowledge is available in our application (Section 6), we were able to straightforwardly select the "causal covering" PSM.
However, more attention should be paid to the selection of appropriate PSMs. We try to illustrate this in the following example focused on the PSMs of the "transform to hypothesis set" task (Subsection 7.3). The goal of this task is to transform a contributor set into a hypothesis set. The different PSMs for realising this task range from performing a complete set cover, where no information is lost, to applying various criteria of parsimony (minimality), that reduce the hypothesis set. The first PSM (the "set cover" PSM) realises the task goal without refinement whereas the other three PSMs realise a "refined" goal in which a reduced hypothesis set is considered. The rationale of using a minimality criterion is that hypothesis sets covering all possible contributors are usually quit large. Since this rationale does not hold in our application, the parsimony PSMs are not applicable and therefore the "set cover" PSM has been reused. Thus, we conclude that both the goals of tasks and PSMs and the rationale behind PSMs are relevant when selecting PSMs.
Many approaches for modifying library components can be constructed. We focus on the case that for a particular task, there is more than one applicable PSM, and the choice between them need to be done at run-time. Two approaches can be applied to realise the goal of the task:
1. The knowledge engineer can combine the PSMs into a new one.
2. The knowledge engineer can introduce an intermediate level with a new PSM in which the PSMs together with their applicability conditions are organised, for example, in one or more IF-THEN-ELSE constructions.
For example, two PSMs are relevant for the "detect symptoms" task (Section 5) in our application, namely the "compare symptom detection" (for mechanical comparisons) and "ask-user symptoms detection" (for manual comparisons) PSMs. In order to make dynamic selection of the appropriate PSM possible, selection criteria were determined (are the required data available in order to carry out a mechanical comparison). In addition, an intermediary PSM-task level was included. This means that an additional "detect symptoms" PSM was introduced which includes the following control:
IF `expected-values-obtainable' AND `observed-values-obtainable'
THEN `mechanically-compare-observations-with-expectations'
ELSE ask-user-symptoms-detection
Guidelines supporting the knowledge engineer in choosing between these two modification approaches (and possible others) will help the knowledge engineer applying the library of PSMs during the development of real-life KBSs.
10. CONCLUSIONS
The CommonKADS method for KBS development includes a library of tasks and problem solving methods (PSMs). In our application we considered Benjamins' library of PSMs for diagnosis (Benjamins, 1993) as part of the CommonKADS library. The PSMs for diagnosis capture many years of research in various domains including medical and technical domains. Reusing these PSMs means the adoption of knowledge from years of experience.
In this paper, the PSMs for diagnosis have been reused in our application, which has resulted in a tailored PSM for diagnosis of Unilever experiments. From this experience we conclude that Benjamins' library is extremely helpful during conceptual knowledge modeling.
Thanks to this reuse, the complete scope and quality of the "prime diagnostic method" was incorporated in our application, ambiguities in the task and domain were brought to light, and the functional specifications of the target system were structured transparently. In addition, Benjamins' library together with our Unilever-tailored PSM was reused in another Unilever application.
The development of the tailored PSM for our application took a bit more than one month. Note, that this period includes a learning curve. Having the skills of reusing diagnosis knowledge available, we expect that future efforts to reuse PSMs for diagnosis can be done in a shorter period.
Finally, we learned from this real-life application that due to application-specific requirements, tasks and PSMs from a library need to be modified to suit the application. Consequently, a knowledge engineer needs to make various sorts of decisions in order to adequately reuse library components. Guidelines will help knowledge engineers to take optimal decisions.
11. REFERENCES
Aben, M. (1995). Formal Methods in Knowledge Engineering. Ph.D. Thesis, University of Amsterdam, Amsterdam, The Netherlands
Benjamins, V.R. (1993). Problem Solving Methods for Diagnosis. Ph.D. Thesis, University of Amsterdam, Amsterdam, The Netherlands.
Benjamins, V.R. & Aben, M. (1996). A Conceptual and Formal Model of a Diagnostic Reasoner. In Nigel Shadbolt, Kieron O'Hara & Guus Schreiber, editors, Advances in Knowledge Acquisition, pages 82--97. Springer-Verlag, Berlin Heidelberg, Germany.
Benjamins, V.R. & Jansweijer, W. (1994). Towards a Competence Theory of Diagnosis. IEEE Expert, 9(5).
Chandrasekaran, B. (1990). Design Problem Solving: A Task Analysis. AI Magazine, 11: 59--71.
Chandrasekaran, B., Johnson, T.R. & Smith, J.W. (1992). Task-Structure Analysis for Knowledge Modelling. Communications of the ACM, 35(9): 124--137.
Orsvärn, K. (1996). Principles for Libraries of Task Decomposition Methods -- Conclusions from a Case-Study. In Nigel Shadbolt, Kieron O'Hara & Guus Schreiber, editors, Advances in Knowledge Acquisition, pages 48--65. Springer-Verlag, Berlin Heidelberg, Germany.
Schreiber, A.Th., Wielinga, B.J. & Breuker, J.A. (1993). KADS: A Principled Approach toKnowledge-Based System Development. Academic Press, London.
Steels, L. (1990). Components of Expertise. AI Magazine, 11(2): 29--49.
Steels, L. (1993). The Componential Framework and its Role in Reusability. In Jean-Marc David, Jean-Paul Krivine & Reid Simmons, editors, Second Generation Expert Systems, pages 273--298. Springer-Verlag, Berlin Heidelberg, Germany.
Wielinga, B.J., Schreiber, A.Th. & Breuker, J.A. (1992). KADS: a modelling approach to knowledge engineering. Knowledge acquisition, 4(1): 5--53.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}