KARATEKIT: Tools for the Knowledge-Creating Company
Andreas
Abecker*, Stuart
Aitken+, Franz
Schmalhofer*, and Bidjan
Tschaitschian*
*German Research
Center for Artificial Intelligence (DFKI),
P.O. Box 2080, D-67608 Kaiserslautern, Germany, Email: aabecker@dfki.de
+Artificial Intelligence
Applications Institute (AIAI),
University of Edinburgh, 80 South Bridge, Edinburgh EH1 1HN,
Scotland, Email: stuart@aiai.ed.ac.uk
Abstract. The companies of the future will live in an environment
where markets are continuously shifting, technology proliferating, competitors
multiplying, and products become obsolete overnight. Under such circumstances,
knowledge management (in general) and knowledge creation (in particular)  are
becoming the most decisive business factors. Knowledge creation comprises
the social sharing of vague, ambiguous and contradicting information, and
thereby discovering novel concepts (Nonaka and Takeuchi, 1997). In the
current paper, we describe how the KARAT and EKI Tools
(KARATEKIT) can be jointly applied to support the knowledge-creation process.
The KARAT system integrates techniques from knowledge acquisition, hypertext,
text analysis, and groupware to support sharing of informal and tacit knowledge
as well as its stepwise and gradual formalization. The EKI tool employs
a user-programmable marker-passing mechanism that allows to reason beyond
a fixed conceptual representation space. In this way the frame of reference
can be extended and interesting new relations or novel concepts may be
identified. The application of our system components is illustrated with
respect to the historical knowledge-creation process at Honda in 1978,
where the car concept "tall boy" was invented (i.e., a car being short
for dealing with high density of traffic and being tall for maximizing
passenger space).
are
becoming the most decisive business factors. Knowledge creation comprises
the social sharing of vague, ambiguous and contradicting information, and
thereby discovering novel concepts (Nonaka and Takeuchi, 1997). In the
current paper, we describe how the KARAT and EKI Tools
(KARATEKIT) can be jointly applied to support the knowledge-creation process.
The KARAT system integrates techniques from knowledge acquisition, hypertext,
text analysis, and groupware to support sharing of informal and tacit knowledge
as well as its stepwise and gradual formalization. The EKI tool employs
a user-programmable marker-passing mechanism that allows to reason beyond
a fixed conceptual representation space. In this way the frame of reference
can be extended and interesting new relations or novel concepts may be
identified. The application of our system components is illustrated with
respect to the historical knowledge-creation process at Honda in 1978,
where the car concept "tall boy" was invented (i.e., a car being short
for dealing with high density of traffic and being tall for maximizing
passenger space).
Keywords: organizational learning, knowledge management,
creativity
1 MOTIVATION
In the currently emerging knowledge society, knowledge is seen
as the most important success factor. Similar to the significance of technologies
and mechanical machines during the industrial revolution, knowledge creation,
knowledge management, and organizational innovations will play the pivotal
role in the future's businesses (Drucker, 1993). The creation and acquisition
of knowledge as well as its efficient utilization will be the most decisive
factors for maintaining or achieving the leading edge in successful markets.
Under these circumstances, it makes perfect sense to talk about successful
products as being the coordinated and reified knowledge of some business
enterprise.
Despite of the very substantial successes of information technology
in modern industry, this technology has not increased the productivity
of modern businesses in the expected magnitude (Landauer, 1995). The disappointment
about the overall benefits of current information technology in industry
is clearly expressed by the catchy phrase that "information systems would
show up everywhere in the world except in productivity statistics". And
it is indeed true that the very practical problems of managing knowledge
in some enterprise is not yet solved satisfactorily. Even the most innovative
approaches primarily deal with knowledge conservation, distribution,
and sharing (see, e.g., (Kühn and Abecker, 1997)), whereas
knowledge-creation is mostly neglected.
In their seminal book about the "The Knowledge-Creating Company",
Nonaka and Takeuchi (1995) have recently analyzed why the problems of knowledge
creation and organizational learning are still not mastered with the highest
possible competence in companies of the western hemisphere. More specifically,
they inspected several success cases of Japanese companies, and they showed
how these companies create the dynamics of innovation. Confronted with
an environment where markets were shifting, technology proliferating, competitors
multiplying and products becoming obsolete overnight, these companies have
realized that the only certainty is uncertainty. Nonaka & Takeuchi's
analysis was done from a management point of view without especially considering
the question of IT support.
If we want to build upon Nonaka & Takeuchi's results, and
also support knowledge-creating processes with IT, we must investigate
how knowledge-based systems and AI can take into consideration the needs
for change and innovation. Looking at the current state-of-the-art in AI,
we find mostly theories, models, and technologies which were developed
with the objective of providing computer solutions for a relatively stable
set of requirements and at least for a fixed frame of reference (see: Clancey,
1991). Model-based expert systems (Wielinga, Schreiber, and Breuker, 1992),
or formal ontologies (Gruber, 1993) are a good example for such a fixed
frame of reference, which was designed for the purpose of knowledge sharing
and reuse.
While such techniques build on stability, Nonaka & Takeuchi's results
teach us to focus on change. In this paper, we discuss how specific tools
from AI (namely our KARAT and EKI tool, resp.) can adjust their techniques
towards this requirement. In the next section, we will briefly review Nonaka
& Takeuchi's approach. We will use their suggested notion of knowledge,
their distinction between tacit and explicit knowledge, as well as their
process model for organizational knowledge creation. Our goal is to suggest
how IT can contribute to Nonaka & Takeuchi's aims. For illustrating
our ideas, in section 3, we will show how the historical example of developing
a new-concept car, as it has been documented by Nonaka could be at least
partially performed with the information technologies provided by the KARAT
and EKI systems. In section 4 and 5, the two systems are then described
in more detail. We conclude with a general discussion.
2 A PROCESS MODEL FOR KNOWLEDGE CREATION AND ORGANISATIONAL LEARNING
Recently, (Choo, 1996) concisely summarized Nonaka & Takeuchi's
comprehensive model of organizational knowledge creation:
"Knowledge creation is achieved through a recognition of the
synergistic relationship between tacit and explicit knowledge in the organization,
and through the design of social processes that create new knowledge by
converting tacit knowledge into explicit knowledge. Tacit knowledge is
personal knowledge that is hard to formalize or communicate to others.
It consists of subjective know-how, insights, and intuitions that come
to a person from having been immersed in an activity for an extended period
of time. Explicit knowledge is formal knowledge that is easy to transmit
between individuals and groups. It is frequently articulated in the form
of mathematical formulas, rules, specifications, and so on. The two categories
of knowledge are complementary. Tacit knowledge, while it remains closely
held as personal know-how, is of limited value to the organization. Explicit
knowledge does not appear spontaneously, but must be nurtured and cultivated
from the seeds of tacit knowledge. Organizations need to become skilled
at converting personal, tacit knowledge into explicit knowledge that can
push innovation and new product development. Whereas Western organizations
tend to concentrate on explicit knowledge, Japanese firms differentiate
between tacit and explicit knowledge, and recognize that tacit knowledge
is a source of competitive advantage."
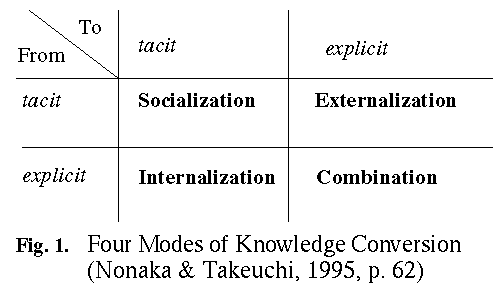
Figure 1
describes the several kinds of transformation processes between tacit
and explicit knowledge. Nonaka & Takeuchi propose to understand organizational
knowledge creation in a five-phase model which is closely related to these
transformation processes.
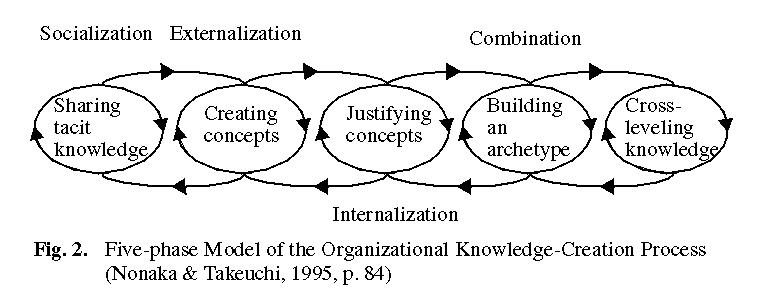
The model (see Figure 2)
comprises the following steps: (1) sharing of tacit knowledge, (2) creating
concepts, (3) justifying concepts, (4) building an archetype, and (5) cross-leveling
of knowledge. The several phases are explained as follows (Nonaka and Takeuchi,
1995):
"... The organizational knowledge-creation process starts with
the sharing of tacit knowledge, which corresponds roughly to socialization,
since the rich and untapped knowledge that resides in individuals must
first be amplified within the organization. In the second phase, tacit
knowledge shared by, for example, a self-organizing team is converted to
explicit knowledge in the form of a new concept, a process similar to externalization.
The created concept has to be justified in the third phase, in which the
organization determines if the new concept is truly worthy of pursuit.
Receiving the go-ahead, the concepts are converted in the fourth phase
into an archetype, which can take the form of a prototype in the case of
"hard" product development or an operating mechanism in the case of "soft"
innovations, such as a new corporate value, a novel managerial system,
or an innovative organizational structure. The last phase extends the knowledge
created in, for example, a division to others in the division, across to
other divisions, or even to outside constituents in what we term cross-leveling
of knowledge. ..."
In the sequel, we will use one of Nonaka & Takeuchi's success
stories in order to exemplify how IT may contribute to the successful application
of the knowledge-creation model.
3 IT SUPPORT FOR KNOWLEDGE-CREATION: THE HONDA CITY RE-INVENTED
In 1978, the Honda top management inaugurated the creation of
a new car concept with the slogan "Let's gamble, let's develop a fundamentally
different new car!" and the only requirement to invent something ,,inexpensive
but not cheap". This stimulated a creative mood in the development team
where vague information was freely exchanged and constructively elaborated.
Given our KARAT and EKI tools (to be presented in more detail in sections
4 and 5), the early phase of sharing tacit knowledge, and thus socialization
among the employees would proceed in the following way. The team members
communicate via a shared information space where arbitrary ideas or information
represented in any kind of medium can be exchanged and discussed. These
information sources may either float freely in the information space or
may be connected by (typed or untyped) links among each other or to some
categories they refer to (e.g., "inexpensive, but not cheap").
Since in a complex technical domain not each participant may be interested
in all upcoming topics, the exchanged information items can be classified
according to several organization schemes which allow to filter for manifold
criteria. Such filters must be very flexibly configurable in order to cope
with the complex and dynamically changing environment. For example, it
must be possible to define personal organization schemes which allow to
classify discussion statements wrt. to a personal view (i.e., topics related
to the personal competences). In order to ease the use of the tool, it
should be able to automatically classify the stored information items,
at least according to some standard categories. In the Honda example, there
is a "Car_Specifications" model with standard categories "Performance",
"Engine", "Driveline", "Dimensions", "Capacities", and "Chassis" (see Figure
3).
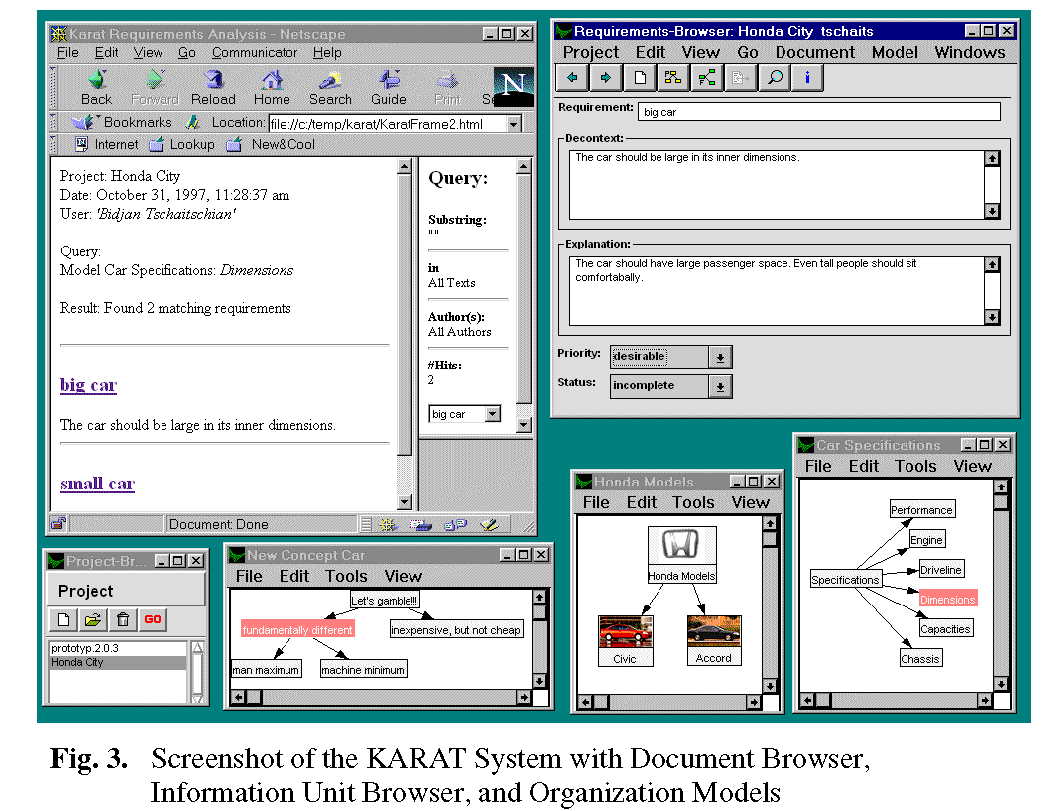
Through this exchange of arbitrarily informal or vague information,
unstated und usually intangible beliefs may become socially shared in the
group. Besides the pure exchange of information, the tool also stimulates
discussion between team members: comments, changes, or improvements can
be attached to some information item, and the extended/changed item be
put into the shared communication space, as well as directly e-mailed to
its author. For face-to-face communication, an audio or video channel to
an information item's author can also be opened. In this way, the socialization
is promoted, and the represented ideas become evolved and improved step
by step.
As discussion goes on, several new organization schemes may grow out
of the shared information items, or the given organization scheme is changed
or refined - just as in a brainstorming session using the METAPLAN method,
when the participants suddenly become aware of some structure immanent
to the topics on the whiteboard. Evolving organization structures reflect
the changing focus as well as progress of the discussion. In our Honda
example, the new discussion tracks "man maximum" and "machine minimum"
are introduced as subclasses of the "fundamentally different" category.
Introduction of new organizing structures reflects social commitment within
the group.
As the rough direction of the discussion is consolidated, the knowledge-creation
process gradually passes over to the concept-creation phase. While the
knowledge-sharing phase was characterized by ambiguity and redundancy,
now processes become more goal-directed. Once focussed on certain aspects,
an engineer's creativity may be stimulated by purposeful selection of all
discussion contributions related to these aspects. This can be done by
employing KARAT's retrieval facility which allows to extract all pieces
of information attached to the selected model concepts. A construction
engineer might be interested in all statements concerning the "Chassis"
as well as the "machine minimum" classes. The system would present all
information items which were generated within the "machine minimum" discussion
and automatically classified to the "Chassis" standard category.
Since a prototype has to meet both the "man maximum" and the "machine
minimum" ideas, now, a manager could be interested in possibly hidden relationships
between information items classified to either category. With the EKI tool,
he may search the information space by freely programmable "information
gathering agents" (marker programs) which can find connections between
information items which were not explicitly stated by the user. In the
example, the markers start at the "man maximum" and "machine minimum" categories,
respectively. From the "man maximum" category, one marker reaches an information
unit "big car", from the "machine minimum" category, the other marker reaches
a "small car" information unit. With the help of KARAT's text analysis
component, both units have been automatically classified to the "Dimensions"
category in the "Car Specifications" standard model. So, the marker passing
mechanism detects this hidden relationship, and the EKI tool produces a
summarizing statement ,,With respect to the "Dimensions" there seems
to be an interesting relationship between the ,,small car" and the ,,big
car" information units." Because of the apparent contradiction, the
manager decides to inspect both information units in more detail. Using
the KARAT information browser, the following explanations are presented:
-
"big car": the car should be large in its inner dimensions, because even
tall people should sit comfortably
-
"small car": the car should be small, because it should be possible
to park even in narrow parking lots
Now, the manager could easily resolve the inconsistency by inventing
the "tall boy" concept: a car which is large wrt. its height and "small"
wrt. its length and width.
For the sake of space, we will not go into detail about tool support
for the more conventional phases of concept justification, prototype building,
and cross-leveling of knowledge. However, one can imagine how KARAT's selective
examination of all information items relevant for some particular concepts
or contexts eases the detection of inconsistencies, redundancies, or missing
information. Similar to the scenario in concept creation, the EKI tool
allows again to establish new views which have not been explicitly prepared
in the KARAT models and contexts. This allows sophisticated procedures
for checking complex consistency constraints, e.g., concerning the business
rules within the company. Since prototype building is often characterized
by several trial-and-error cycles, using the same tool for supporting and
documenting all phases allows continuous process improvement and requirements
tracing in the case of changing conditions. In the cross-leveling phase,
KARAT provides sophisticated storage and organization mechanisms for best-practice
reports, whereas EKI provides flexible and powerful search across several
conceptual spaces.
In summary, we sketched and illustrated how IT tools could comprehensively
support Nonaka & Takeuchi's knowledge-creation process. In research
on knowledge-based systems similar processes have also been termed cooperative
knowledge evolution (Schmalhofer and Tschaitschian, 1995). In this context,
two main functionalities have been distinguished:
-
Sharing of informal, or even tacit knowledge in order to achieve
socialization among various team members. Therefore, the functionality
of a group memory and communication tool is required which can handle informal
as well as incrementally formalized knowledge.
-
At least allow and possibly support the creation of novel knowledge; in
other words, it must be possible to establish interesting relations or
creative inferences. This requires components which can bridge between
independently established representation spaces.
In the subsequent sections, we will show how our KARAT and EKI
tool, respectively, meet these requirements.
4 KARAT: GROUPWARE SUPPORT FOR COLLABORATIVE KNOWLEDGE ELICITATION,
SHARING, AND ORGANIZATION
The KARAT tool and method were originally designed and implemented
for preparing well-structured software requirements specifications from
large amounts of unstructured, redundant, and inconsistent text documents
as available from interviews with experts, minutes of meetings, e-mail
discussions, etc. (Tschaitschian, Wenzel, and John, 1997).[1]
However, in (Tschaitschian, Abecker, and Schmalhofer, 1997), we
argued that the basic principles underlying this requirements engineering
(RE) application could easily be applied to the broader problem of knowledge
management. The KARAT tool may thus be re-interpreted as a knowledge management
tool. To name the most important principles and functionalities:
-
KARAT allows to manage and organize informal knowledge, stated in
natural-language texts;
-
the informally represented information is structured, revised, and
prepared for effective utilization by annotating and categorizing them
according to some structuring models (Schmalhofer, Kühn, and Schmidt,
1991);
-
maximum user-friendliness is achieved by integrating a sophisticated
hypertext user interface with automatic text analysis for
providing suggestions for information categorization;
-
although the categorization can be seen as (or used for) a stepwise
formalization of the initial text sources, we found the trade-off between
easy use and understanding and powerful tool facilities as being crucial
for practical applications. In this trade-off, it turns out that just extremely
sparse formalization (i.e., rough, easily surveyable organization
models, not necessarily with a formally processable semantics, but merely
as a mnemonic aid for the user) promises the best effort-benefit-ratio.
Recently, we added several groupware functionalities. Moreover, we are
currently extending our information sources from pure text to arbitrary
(multi-)media. This opens new application scenarios: the means for combining
more or less informal knowledge sources and for flexible knowledge organization
together with a powerful information sharing and communication concept
allows a group to stepwise discuss and develop, formulate, and fix their
shared knowledge.
Cooperating via Shared Information Sources: The KARAT tool offers
to its users a shared information space where each participant in
the knowledge management process is free to feed in arbitrary (multimedia)
information items. Of course, tacit knowledge in general can not be
communicated using a fixed representation medium and vocabulary. Consequently,
the user should be allowed to forward text-based discussion contributions
(e.g., figuratively described ideas on new car concepts) as well as graphics
(e.g., the sketch of an innovative design detail), pictures (e.g., the
scanned advertisements of a competitor's new car model), or even video
tapes (e.g., driving studies with car prototypes or records of brainstorming
meetings), and so on.
Technically, this multimediality is achieved by KARAT's HTML user interface
(see Figure 3) which allows to handle arbitrary
information sources using the appropriate Netscape plug-ins. Conceptually,
the different knowledge media must be mapped onto some uniform meta-representation
in order to exchange, compare, and discuss them. To this end, each information
source is represented by a KARAT information unit (cf. Figure
4).
Representing Information Sources: As a first approximation, a
KARAT information unit can be compared with the knowledge-item description
frames proposed by (van Heijst, van der Spek, and Kruizinga, 1996) for
organizing Corporate Memories. There, knowledge items are described by
their classification wrt. some fixed dimensions of knowledge categorization
inspired by the KADS approach: tasks to be solved, role of the actor using
the knowledge, application domain, etc. While such an approach gives a
good idea of how a "rough organization model" (see above) could look like
in an enterprise, it is nevertheless by far too rigid for tackling with
the dynamics and unforeseeable effects in the early phases of Nonaka's
model. While a fixed classification scheme may be useful for promoting
reuse of stable and well-established procedures, i.e., knowledge conservation
and documentation, for knowledge-creation, we need much more flexible,
easily changeable, and multi-faceted descriptions. This goal is tackled
in KARAT by two basic mechanisms:
-
Information unit annotations allow for the most powerful and
flexible knowledge representation formalism: natural-language comments.
-
Information unit links connect an information unit either
with other units, or with concepts from knowledge organization models.
A KARAT knowledge organization model is just a graphical
notation of some coarse-grained overall structure which can be used for
categorizing information units.
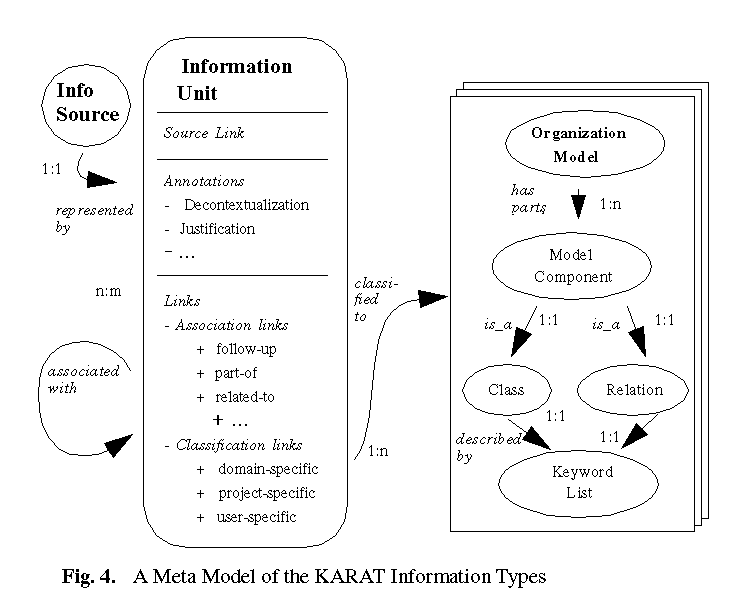
Annotating Information Units: In the annotation part,
an information unit is enriched by natural-language comments. In the RE
application, this part contains, e.g., a decontextualized form, because
single requirements extracted from larger text documents must be independently
understandable. In the case of a multimedia information source, there can
be, e.g., some short text description of the source content, because it
might be inconvenient to show a video tape to the user each time she inspects
the information repository without roughly knowing whether it is of particular
interest for her.
Relating Information Units: In the link part, hyperlinks
can be drawn from each information unit to either arbitrary other units
or arbitrary elements of knowledge organization models. We will refer to
these two types of links as association links in the first and classification
links in the latter case.
Association Links: Association links reflect the complex,
network-like nature of knowledge which is always characterized by highly
interwoven structures and close relationships between the respective information
units. Association links can either be typed (representing some
well-defined relation between information units) or untyped (giving
only a rough hint for a "has-to-do-with" relationship). Examples for a
typed association could be the "part-of" relationship between more complex
requirements specifications and their several parts, or the "follow-up"
relation between causally related discussion statements (e.g., the idea
of a large passenger cabin is caused by the requirement to realize a "man-maximum"
car). Untyped associations will be the predominant kind of links, because
our application experiences show that the semantics of such a typed information
link is hard to catch for a typical user. And, typed links are only useful
in the case that there exist specialized utilization components which are
able to exploit their semantics. So, we prefer to implement most of the
wished structuring functionality by introducing additional (maybe individually
tailorized) organization models which allow to produce specialized, small
views on exactly that part of the knowledge network which is actually of
interest.
Classification Links: Our organization models refine a certain
view on the domain of discourse in a shallow way, by a few structuring
classes (cf. Figure 3). In contrast to deep models
as they are used, e.g., for model-based inferences, we need merely what
(van Heijst, van der Spek, and Kruizinga, 1996) call "knowledge engineering
at the macro level".
Each information unit can be attached to arbitrary model components
of any model. In a company, there will exist models of general importance
as well as project-specific ones and models owned by single users or user
groups. Information can be retrieved by selecting any combination of model
components and specifying general information unit features (such as author,
creation date etc.). So, arbitrary views and multi-criteria selections
of the knowledge base can be produced. Since models can easily be extended
or changed, or new models can be added, this organization scheme offers
utmost flexibility.
The only remaining problem is that it is still some work to classify
information according to the organization models. The first remark on this
is that the user does not need to classify information units. If one does
not use any model, the tool resembles a blackboard where everyone may attach
some note pads in a completely unstructured way. However, when some user
wants to structure the gathered notes, he is supported in a twofold manner:
first, the process of classification and linking is very intuitive and
comfortable to use through our carefully designed hypertext interface;
second, the tool can provide suggestions (and can also make some classifications
automatically) by the use of text analysis techniques coming from information
retrieval. These suggestions are generated on the basis of keyword lists
describing characteristic terms of the respective classes. The keyword
lists as well as even suggestions for model classes can be generated with
sophisticated algorithms from learning text categorization. In our Honda
example, at least mapping onto some standard classes should easily be possible
automatically.
Despite their "formal" appearance (in fact, our tool offers the
graphical means for building many widely-used types of graphically denoted
models, such as KADS inference structures, ER-Diagrams, semantic nets etc.),
for the KARAT tool, most models are nothing else than flat sets of concepts.
But, this together with the graphical presentation (the interpretation
of which remains with the user) is already enough for enabling a very flexible,
yet easy to use knowledge organization. Since this kind of "shallow organization
models" is the most distinctive feature of the KARAT approach, we will
elaborate a bit more on them.
Organization Models for Knowledge Structuring: KARAT employs
the following types of organization models:
-
Problem-specific models are used in all KARAT projects within
a specific application domain. For example, in RE, there are standard classification
models for requirements (functional, non-functional, ...), in the Honda
example, we have the "Car_Specifications" model (see section 3). If KARAT
is used for distributing and reusing best practices in the cross-leveling
phase, the given enterprise-wide organization structures can be used (department
structure, business processes, ...), similar to the proposals by (van Heijst,
van der Spek, and Kruizinga, 1996), or (Hofer-Alfeis and Klabunde, 1996).
-
Project-specific models are used by all participants of a project
and often reflect the structure of the given task to be solved. In an RE
project, these are, e.g., the functional decomposition, or the data or
control-flow specification of the system to be developed. Such models usually
already exist in some formal, graphical representation like, e.g., ER-diagrams,
OMT notation, etc. In more dynamic environments, like in our Honda example,
the initial management ideas could be the starting point for a gradually
evolving brainstorming model where upcoming ideas would be attached to
some established concept, or if they are of more general interest and acceptance,
they would become new concepts in the organization model.
-
User-specific models are individual organization schemes which
allow each user to put her own personal view(s) on the knowledge repository.
The usefulness of several personal (or group) views becomes obvious if
you imagine your personal scientific paper archive, where you often might
like to organize copies of papers according to research topics, to authors,
or institutes and working groups (maybe even visualizing cooperations),
or to projects the topics are related to, and so on. KARAT offers easy
mechanisms for realizing such orthogonal, or even conflicting, organization
schemes. Moreover, your own views on these structures may considerably
differ from your colleagues' ideas about, e.g., how a research area should
be subdivided in a topical hierarchy. Individual models might also be used
for protecting private (or group) contributions from public access.
KARAT: Implementation: Figure 3 shows a screenshot
of the KARAT user interface. The KARAT tool runs on PC/Windows and on SUN/Solaris
platforms. The kernel system is implemented in Smalltalk. Two text analysis
tools implemented in C and C++ (Dengel et al., 1994) are coupled to the
KARAT kernel. MORPHIC-PLUS is a tool for the inflectional morphological
analysis of the German language (Lutzy, 1995). The INFOCLAS2 system includes
an automatic indexing component with different weighting functions as well
as a word-based text classification component (Hoch, 1994). To guarantee
user acceptance and user friendliness, an integrative working environment
has been realized through a uniform hypermedia user interface. The Hypertext
Abstract Machine (HAM) is employed for hypertext management tasks, such
as establishing and updating links between requirements and the different
models. The Netscape Navigator Internet-Browser is employed as an interface
for the HTML-represented information units and text retrieval results.
Moreover, it allows for an easy integration of arbitrary multimedia documents
into the KARAT tool. The groupware version of the tool employs the object-oriented
GemStone database.
5 EKI: TOOL SUPPORT FOR CREATIVE INFERENCES
Before describing the EKI tool in some detail, the motivation
for developing this tool will be presented. The design of the EKI tool
was inspired by a specific model of human knowledge acquisition from texts,
namely the construction-integration model (Kintsch, 1992).
5.1 A Construction-Integration Approach to Knowledge Creation &
Novel Frames of References
The construction-integration model of human learning assumes that
learning is a chaotic and globally organized process. It proposes that
there are two phases of learning. In the first phase, the so-called construction
phase, some new piece of information or idea (i.e., the learning material)
is fully elaborated in combination with the already available knowledge.
Many different kinds of associations which can be retrieved or constructed
from the knowledge net (i.e., several knowledge bases) are formed. These
knowledge construction processes may be performed under the guidance of
a processing goal. They yield pluralistic views at various levels of abstraction.
In the second phase, a constraint satisfaction process determines the
most dominant (e.g., the largest set) of knowledge units which are consistent
with one another and as complete as possible with respect to some desired
object domain. For example, it may be required that the resulting knowledge
(the so-called situation-specific circumscription) presents a complete
account of a possible design at some given level of abstraction.
As can be seen from Figure 5, the two phases
correspond to two different skills, the knowledge construction skill
and the knowledge integration skill (cf. Schmalhofer, 1998).
Both of these skills are shown as basic inference steps. For the construction
skill, three input meta-classes are assumed. A learner's prior knowledge
is organized in the form of a knowledge net (cf. Mannes and Kintsch, 1991).
The learning materials are another input meta-class. In addition, the processing
goal influences how the construction skill utilizes the information from
the knowledge net and the learning materials.
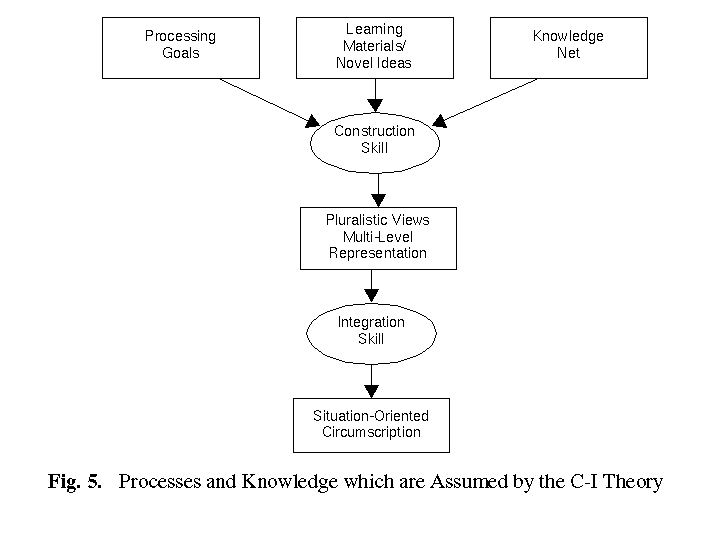
The construction skill forms a multi-level representation with
pluralistic views of the learning materials. One piece of text information
may thus be represented from different perspectives and in different ways.
These pluralistic views may furthermore contain opposite and contradictory
information.
The integration skill then evaluates how the pluralistic views
can be best fit together in a multi-level description, so that a coherent
and consistent abstract structure is obtained. Thereby, the abnormalities
(i.e., inconsistencies) that existed in the pluralistic views are eliminated
or at least substantially reduced. The product of the integration skill
is termed a situation oriented circumscription and presents the
(relatively abstract) knowledge that is acquired from the learning materials
in combination with the learners' prior knowledge.
The EKI tool was developed within the framework of this construction-integration
theory. It allows for the creation of new inference knowledge (Schmalhofer,
Franken, and Schwerdtner, 1997). EKI stands for the Evolution
of Kreative Inferences (or Initiatives).
With the EKI tool an explicit inference statement is constructed by marker
passing in a joint text- and knowledge base and a subsequent compilation
process. In addition, this tool can be used to perform knowledge integration
processes which can produce spatial, causal and other type of representations.
EKI can be applied to construct reproductive as well as creative inferences
in different kinds of knowledge bases which have become related to one
another by so called crosslinks. With this system we can describe how the
constraints that are provided from different information sources (like
for instance a novel idea that is expressed by a brief text and the givens
of an organizational structure, that is expressed by a knowledge map) may
yield a deeper understanding concerning whether or not this novel idea
can be implemented with the given organization. In the following section,
we will describe the EKI tool in some detail.
5.2 EKI: The Basic Approach
Conceptually, the EKI-System consists of two major processing
components. One component constructs creative inferences from a knowledge
net and inserts the created inferences into the knowledge net at proper
locations. Because the knowledge net consists of a conglomerate of different
knowledge segments and because the creative inference may yield additional
inconsistencies, the resulting knowledge net will usually contain many
inconsistencies and redundancies. It is therefore denoted as pluralistic
views. The other component analyzes the resulting knowledge net for coherence
and consistency and thereby selects an appropriately chosen subnet so that
some global coherence and consistency criteria are met. The resulting knowledge
net is called the situation-specific circumscription. In addition to these
major components there is a component for creating the initial knowledge
net (pluralistic views) from several well structured knowledge bases and
some text and a component for presenting the pluralistic views to the user.
The starting point for the creative inferences is a number of
separate knowledge bases, each of which is in itself well structured. For
example the THINGS knowledge base consists of hierarchically structured
object classes and respective subclass relationships. Each object is denoted
by its name and several slots may be used for its description. The ACTIONS
knowledge base similarly consists of hierarchically structured action classes.
Because each of the different knowledge bases is a complete and correct
representation of the respective segment of a domain, none of the knowledge
bases itself affords creative inferences. An affordance for creative inferences
arises by associating or linking nodes either between or within some of
the knowledge bases. These links which may introduce alternative readings
to the previously precisely defined representations are called crosslinks.
Relating the different knowledge bases by such crosslinks yields the possibility
for discovering new relationships which were not already implicitly contained
in the original knowledge bases. After such crosslinks have been inserted,
the cohering knowledge base, termed pluralistic views, is obtained.
Creative inferences may now be constructed by focusing on two
(or more) nodes, identifying relationships between these nodes and then
compiling the discovered relationship into some explicit inference statement.
This explicit statement is then called a creative inference and
is subsequently inserted into the knowledge net. The creative inferences
are in themselves additional crosslinks. The overall structure of the knowledge
net is changed by these new links and some additional arbitrariness may
thereby be introduced. In other words, the good structure of the original
knowledge bases is dissolved to a certain degree and thereby affords the
development of some new structure. The purpose of the integration process
is to find such a new structure. This new structure is determined on the
basis of some processing goal which identifies the nodes and types of links
that are of central interest. By focussing on these nodes and links, a
relatively coherent and consistent structure is then found, i.e., the situation-specific
circumscription. Thus, the situation-specific circumscription is a novel
structure which emerges form the original knowledge bases, the crosslinks
(generated by the text), and the creative inferences which yield a shift
of the focus in the knowledge net.
5.3 EKI-System Architecture
Figure 6 shows the architecture
of the EKI system. On the left side there are the various information sources
which are to be provided by the user. The knowledge base consisting of
six segments (i.e. THINGS, IDEAS, ACTIONS, THOUGHTS, EVENTS, INSIGHTS)
together with possible cross_links and the units of the TEXT_REPRESEN-TATION
which are to be processed build the input to the system. The NEW_TEXT is
entered into the system so that it corresponds unit by unit to the representational
format of the TEXT_REPRESENTATION. There are two tools, which construct
the initial Pluralistic_Views from the user's input (CreateNet) and present
the result to the user (PresentToUser).
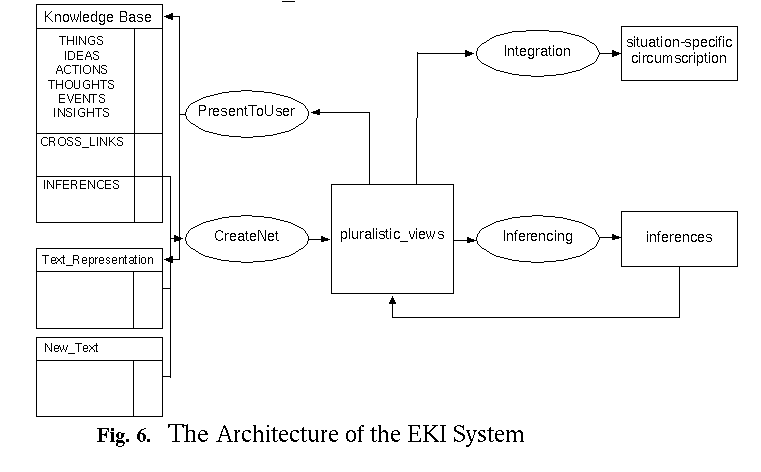
After this initial setup has been accomplished, creative inferences
may be generated and a knowledge integration may be performed on the knowledge
net (Pluralistic_Views). In order to explore creative inferences which
may emerge from this knowledge net, the user may select two (or more) nodes
of the net and provide some specification that serves as the basis for
finding relationships between these nodes. After such relationships have
been discovered by the system in terms of connecting paths between the
nodes (that satisfy the user-supplied specification), another specification
determines how some explicit statement is compiled from these paths and
inserted into the net. All of these component processes are depicted in
Figure 6 by the procedure denoted as Inferencing.
In order to generate the situation-specific circumscription by
the knowledge integration processes, the user identifies one or several
focal nodes of the net and provides a specification about which relationships
are of interest and should therefore determine the situation-specific circumscription.
The situation-specific circumscription is then calculated as that segment
of the pluralistic views which satisfies the specified relationships. More
specifically, the segment of the net consists of all the nodes that satisfy
the given relationship with each of the focal nodes. These component processes
are denoted in Figure 6 by the Integration
procedure.
Inferencing: As can be seen from Figure 7,
the inference construction is performed in two steps. Possible relationships
between two (or more) nodes are identified by a marker passing procedure
(Norvig, 1989). The resulting paths are then analyzed by a rule interpreter.
The rules which are supplied to this interpreter specify under which conditions
an inference may be constructed and how an explicit inference statement
is to be compiled out from some given path.
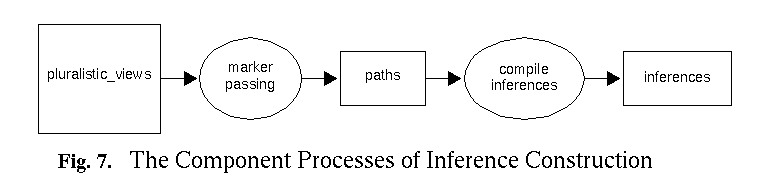
Marker passing process: The purpose of the marker passing
process is to find interesting connections and relationships between the
particular nodes of the network. In order to find appropriate connections,
the behavior of the marker can be programmed in terms of regular expressions.
These regular expressions thus provide the specifications for which types
of links can be traversed. In order to find paths between two nodes, a
marker passing process is started from each of the two nodes. For every
collision point of the two markers, a connecting path is then determined.
Depending upon the particular specification that is used, the behavior
of the markers may range from finding a very specific path over finding
a concatenation of only transitive relations (e.g., like some transitive
closure) to allowing any arbitrary connections between the nodes.
Inference compilation: After connection paths have been found,
a rule interpreter is used for compiling explicit inference statements
from a path and inserting these statements into the knowledge net. The
rules for the rule interpreter consist of condition-action pairs. The condition
part is again a regular expression which determines whether an explicit
inference statement can be generated from a particular path by the action
part of the rule. The action part then determines how the explicit inference
statement is to be generated. Such an inference statement may consist of
a single link that connects the two nodes from which the marker passing
process was started. Alternatively, the inference may consist of a new
node and two links, where the two links connect the new node to each of
the two nodes from which the marker passing process was started.
Integration Processes: For performing the integration processes,
the two or more nodes which are of focal interest must be identified by
the user. Furthermore, for each of these focal nodes, a marker program
must be supplied which determines the relations (links) that are most significant
and should therefore guide the integration process. As can be seen from
Figure 8, the integration processes are performed
in two steps. In the first step, the marker passing procedure is applied
to flag all the nodes which are reachable from each given starting point
by the respective marker program. In the second step, the integrated knowledge
net (i.e., the situation-specific circumscription) is determined by some
integration criterion. The integration criterion typically specifies that
the situation-specific circumscription should be formed on the basis of
those nodes which have been marked by all the different markers. There
may be different criteria for specifying which links should belong to the
integrated knowledge net. For instance, the situation-specific circumscription
may include only those links which have been marked from all markers. Alternatively,
it may include all the links that connect some nodes that have been marked.
Obviously, there are several other possibilities as well.

5.4 EKI: Implementation
The EKI-system was designed in an object-oriented manner. The
core components of the EKI-system are the knowledge bases, the marker passing
process, and the inference compilation process. In the knowledge bases
(knowledge net), one distinguishes nodes and links. All nodes
are instances of object classes. There is one basic class, the BasicWorldClass,
which has two subclasses, the StaticWorldClass which represents static
entities and the DynamicWorldClass representing changes. By using Java,
we programmed a user-interface, whose interaction style is very familiar
from a large number of other applications in the WorldWideWeb. A demonstrator
version of this system can be viewed over the net[2]).
Because of the existing security restrictions of Java running under Netscape,
the demonstrator cannot access any files. A regular version of the system,
which allows full file access is also available. Since Java is an object-oriented
and architecture neutral programming language, the system will be highly
portable to almost any hardware platform.
The marker-passing procedure must be specified by the user, or
an existing procedure must be selected. Figure 9
shows a screenshot of the EKI-system where the marker programs are specified
that eventually lead to the inference of developing short but tall cars.
As can be seen from this figure, the marker programs are quite short, and
as such are more readily entered by simply typing the program text than
by the direct manipulation techniques used to perform other interactions
with the EKI system. Important usability factors in the design of the marker-passing
language include the regularity of the command structure, the number of
commands a user must know and their mapping to the operations the user
wants to perform. The complexity of this task is comparable with composing
UNIX commands. The user can interactively run and re-run marker passing
programs and the results can be traced back to terms in the program in
a straightforward manner.

6 DISCUSSION
Coming from the management point of view, Nonaka & Takeuchi
recently presented their comprehensive model for understanding organizational
knowledge creation. In order to cope with the uncertainty and dynamics
of the upcoming knowledge society, the successful company must cultivate
creativity and organizational flexibility. In this paper, we discussed
how AI could adjust its techniques in order to meet these requirements.
More specifically, we presented two tools:
The EKI tool supports the generation of creative inferences from
a variety of knowledge sources. Because the separate entities of corporate
knowledge need to be related, the generation of such creative inferences
is indeed a necessary component in a learning organization. The tool is
based on the construction-integration theory about human learning processes.
The KARAT tool, based on model-based knowledge acquisition, combines techniques
from hypertext, text analysis, and groupware for sharing, evolving and
gradually formalizing informal knowledge sources within a group of knowledge
workers (Kidd, 1994).
The primary aim of this paper was not to present the tools in
technical detail (see (Tschaitschian, Wenzel, and John, 1997) or (Schmalhofer,
Franken, and Schwerdtner, 1997) for this purpose), but rather to illustrate
a scenario, to demonstrate their cooperation, and to discuss the main distinctive
features relevant to the above question of how organizational learning
could be supported. Some of the main topics to be further worked on:
Firstly, handling of informal and tacit knowledge. We suggested
that a combination of various knowledge media together with sophisticated
means for group or face-to-face discussion may contribute to this goal.
Secondly, going beyond fixed frames of references and "unfreezing"
or annealing established representation spaces. We showed how EKI may enable
the user to do so. If learning is defined as a process which leads to an
improvement in performance, and one which is intimately interconnected
with memory (or knowledge), then the parallels between the individual and
the corporate case emerge (Ayas and Foppen (1996) make a similar argument).
It has also been argued that within organizations creativity occurs through
interaction (Ayas and Foppen, 1996), and that learning occurs through discussion
(de Geus, 1996). We propose that there are strong parallels between these
social processes and the construction-integration processes of the cognitive
model upon which the EKI tool is based. Learning in a changing world demands
that contingent upon the external environment, new frames of reference
must be dynamically constructed in a social effort in which all the practitioners
of an organization are involved. These reconstructions are performed on
the basis of innovation foci, which are analogous to a discourse focus
in text comprehension (see van Elst and Schmalhofer, 1997). These innovation
foci have to be identified by the knowledge managers of an organization.
The EKI tool supports the knowledge managers in this task.
Thirdly, both tools show that in early phases of knowledge creation,
cooperative support systems and intelligent communication tools are more
useful than fully-automatic problem-solvers. However, in order to get such
tools really used in practice, AI has to care much more about psychological
and ergonomic human-computer interaction aspects. This concerns not only
the design of intuitive user interfaces, but also the conceptual design
of the tool philosophy itself. Our customer contacts suggest that this
is not only a question of how good a tool performs, but a critical success
factor which is essential for a tool to be used at all. In KARAT, this
is reflected by the thoroughly elaborated trade-off between formality (which
allows powerful inferences and services) and informality (which provides
more flexibility and makes the tool usable for a typical employee). Issue-based
information systems (cf. Shum, 1997) are a similar example where, for coordinating
and documenting group decision processes in design, the relationships between
information items are flexibly modeled by embedding them into an argumentation
structure reflecting the discussion process. It may be useful to implement
such a system with KARAT. In large, heterogeneous discussions which are
still very unstructured an issue-base may provide a useful organization,
similar to the various domain and task models in KARAT. In his EKAW-97
invited talk, Tom Gruber promoted a "minimalistic" approach to formality
in corporate memories. He envisioned a self-organizing group knowledge
creation process where useful organizing structures come "on-the-fly" as
an emergent phenomenon; they are a by-product of people doing their knowledge
work on-line from the way they name their public folders for starting and
filing group discussions. Gruber's proposal shares many similarities with
the approach of the KARATEKIT, which lies in between the two extremes of
formalization. KARAT may mimic more or less formal behaviors depending
on the defined models and typed links. A reasonable use of the tool is
typically given with a handful, shallow organizational models and just
two or three typed links, the semantics of which is easy to understand
and can be exploited by specialized reasoning algorithms.
The last, and by no means less important points concern motivational
and management considerations. In organizational knowledge creation, a
creative mood in a group must be promoted such that individual creative
acts are stimulated in relation to the body of shared group knowledge.
Further, one needs to achieve and maintain the commitment of the employees
to the socially constructed knowledge. Sensemaking and a changed explicit
reward system are topics which are discussed for ensuring these points.
If such goals are approached, a group of knowledge workers will definitely
produce better results than the sum of the knowledge creations of the individual
participants.
Acknowledgment. This work was funded by Deutsche Telekom AG and
partially supported by the German Federal Ministry for Education and Research
(bmb+f) under grant ITWM 9705 C4.
7 REFERENCES
Ayas, K. and Foppen, W. (1996). Reflections on design for learning.
http://www.orglearn.nl/Archives/RSM_Book/design.html. European Network
For Organisational Learning Development.
Boden, M. A. (1991). The Creative Mind: Myths and Mechanisms.
New York: Basic Books.
Choo, C. W. (1996). The Knowing Organization: How Organizations
Use Information to Construct Meaning, Create Knowledge, and Make Decisions.
Int. Journal of Information Management, Vol. 16, No. 5: 329-340.
Clancey, W. J. (1991). The Frame of Reference Problem in the Design
of Intelligent Machines. In K. VanLehn (Ed.), Architectures for intelligence.
The Twenty-second Carnegie Mellon symposium on cognition, pp. 357-423,
Hillsdale, NJ: Lawrence Erlbaum.
Dengel, A., Bleisinger, R., Fein, F., Hoch, R., Hönes, F.,
and Malburg, M. (1994). OfficeMAID - A System for Office Mail Analysis,
Interpretation and Delivery. In Proc. of First International Workshop
on Document Analysis Systems (DAS'94), Kaiserslautern, Germany, pp.
253-275.
Drucker, P. F. (1993). The Post-Capitalist Society. Butterworth-Heinemann
Ltd.
de Geus, A. P. (1996). Strategy and learning. http://www.orglearn.nl/Archives/RSM_Book/adgeus.html.
European Network For Organisational Learning Development.
van Elst, L., and Schmalhofer, F. (1997). Die Persistenz von Inferenzen
in einem verstehensbasierten kognitiven Modell. Kognitionswissenschaft,
Vol. 6: 86-98.
Gruber, Th. (1993). Towards Principles for the Design of Ontologies
used for Knowledge Sharing. In N. Guarino and R. Poli (Eds.), Formal
Ontologies in Conceptual Analysis and Knowledge Representation, Boston:
Kluwer Academic.
van Heijst, G., van der Spek, R., and Kruizinga, E. (1996). Organizing
Corporate Memories. In Tenth Knowledge Acquisition for Knowledge-Based
Systems Workshop KAW'96, Banff, Canada, November 9-14, pp. 42-1-42-17.
Hoch, R. (1994). Using IR Techniques for Text Classification in
Document Analysis. In Proc. of 17th International Conference on Research
and Development in Information Retrieval (SIGIR'94), pp. 31-40.
Kidd, A. (1994). The Marks are on the Knowledge Worker. In Proceedings
of CHI-94: Human Factors in Computing Systems, Boston, Mass, April
24-28, pp. 186-191, New York: ACM Press.
Kintsch, W. (1992). A Cognitive Architecture for Comprehension.
In H. Pick, P. van den Broek, and D. Knill (Eds.), The study of cognition:
Conceptual and methodological issues, pp. 143-164, Washington, DC:
APA Press.
Kühn, O., and Abecker, A. (1997). Corporate Memories for
Knowledge Management in Industrial Practice: Prospects and Challenges.
Journal of Universal Computer Science, Vol. 3, No. 8: 929-954.
Lutzy, O. (1995). Morphic-Plus: Ein morphologisches Analyseprogramm
für die deutsche Flexionsmorphologie und Komposita-Analyse (in german).
DFKI Document D-95-07.
Mannes, S., and Kintsch, W. (1991). Routine Computing Tasks: Planning
as Understanding. Cognitive Science, Vol. 15: 305-342.
Nonaka, I., and Takeuchi, H. (1995). The Knowledge-Creating
Company. Oxford: Oxford University Press.
Norvig, P. (1989). Marker Passing as a Weak Method for Text Inferencing.
Cognitive Science, Vol. 13: 569-620.
Schmalhofer, F. (1998). Constructive Knowledge Acquisition:
A Computational Model and Experimental Evaluation. Hillsdale: Lawrence
Erlbaum Associates.
Schmalhofer, F., and Tschaitschian, B. (1995). Cooperative Knowledge
Evolution for Complex Domains. In G. Tecuci and Y. Kodratoff (Eds.), Machine
Learning and Knowledge Acquisition: Integrated Approaches, pp. 145-166,
London: Academic Press.
Schmalhofer, F., Franken, L., and Schwerdtner, J. (1997). A Computer
Tool for Constructing and Integrating Inferences into Text Representations.
Behavior Research Methods, Instruments, & Computers, Vol. 29,
No. 2: 204-209.
Schmalhofer, F., Kühn, O., and Schmidt, G. (1991). Integrated
Knowledge Acquisition from Text, Previously Solved Cases and Expert Memories.
Applied Artificial Intelligence: An International Journal, Vol.
5: 311-337.
Shum, S. B. (1997). Negotiating Multidisciplinary Integration:
From Collaborative Argumentation to Organisational Memory. J. Universal
Computer Science, Vol. 3, No. 8: 929-954.
Tschaitschian, B., Abecker, A., and Schmalhofer, F. (1997). Information
Tuning with KARAT: Capitalizing on Existing Documents. In E. Plaza and
R. Benjamins (Eds.), Knowledge Acquisition, Modeling and Management,
10th European Workshop (EKAW`97), pp. 269-284, Berlin: Springer.
Tschaitschian, B., Wenzel, C., and John, I. (1997). Tuning the
Quality of Informal Software Requirements with KARAT. In E. Dubois, L.
Opdahl, and K. Pohl (Eds.), Proceedings of the Third Int. Workshop on
Requirements Engineering: Foundation for Software Quality (REFSQ'97),
pp. 81-92, Namur, Belgique: Presses Universitaires de Namur.
Wielinga, B. J., Schreiber, A. T., and Breuker, J. A. (1992).
KADS: A Modeling Approach to Knowledge Engineering. Knowledge Acquisition,
Vol. 4, No. 1: 5-53.
[1. ]KARAT:
Knowledge-based Assistant for Requirements Analysis
at Telekom.
[2.
]http://www.dfki.uni-kl.de/~schmalho/eki/eki.html