This paper presents IMPS, an architecture for structured knowledge acquisition and problem solving over the WWW. IMPS is a modular and extendable server-based multi-agent architecture. It carries out ontology construction and knowledge acquisition for agent-based problem solving. Both ontology construction and knowledge acquisition is informed by Problem Solving Models (PSMs). A knowledge library is available to all agents containing information about PSMs in terms of their competencies and domain knowledge requirements, and about types and locations of domain knowledge sources and how to extract different kinds of information from them. Agents use domain keywords elicited from the user to construct and instantiate a domain ontology for problem solving from a general lexical database and domain knowledge sources. IMPS uses the emerging knowledge sharing standards of KIF, KQML and Java to ensure interoperability. A vision of the future IMPS system and a working prototype are described.
"Although related information can be linked using hyperlinks, it is not the case that all necessary links for a particular problem can be foreseen in advance. Rather information has to be combined in problem-, situation- and user-specific ways, as a complement to index-based information retrieval methods. In knowledge engineering we have developed for years now the methods and techniques to do this"
(Van de Velde, 1995)
The existence of a global computer network in the future seems assured. Increasingly diverse and useful information repositories are being made available over the World Wide Web (WWW). However, along with increased usefulness come the disadvantages of overwhelming amounts of information. Additionally, the use of multiple formats and platforms makes the integration of information found on the Internet a non-trivial task. Software design for Internet information retrieval is therefore a fast-growing field. However, the information retrieved, particularly by general search engines, is often of limited use because it lacks task-relevance, structure and context. The IMPS (Internet-based Multi-agent Problem Solving) architecture proposes the idea of agents that will conduct structured on-line knowledge acquisition rather than simple information retrieval.
This leads us to ask - "What is the difference between knowledge acquisition and information retrieval?" Most definitions of knowledge acquisition are general, describing information gathering from any source. However, in practical terms, knowledge acquisition implies a higher level of structure and re-representation than mere large-scale information retrieval - resulting in a clearer and more coherent body of knowledge. The idea of re-representing existing data has already been explored in the closely related field of 'data mining' (e.g. Cupit & Shadbolt, 1994). Knowledge acquisition is also usually task relevant, done with some consideration to further use, and can be seen as the transfer and transformation of potential problem-solving expertise from some knowledge source to a program.
The practice of knowledge acquisition is somewhere between an art and a science and is based on a selection of formal and informal acquisition techniques, which place elicited information in the context of a knowledge structure for a particular task. Some of these techniques have already proved to be adaptable to the Web, for example WebGrid (Shaw & Gaines, 1995). The idea of structuring knowledge elements in a task context has been applied to information agents too.
"Ultimately, all data would reside in a "knowledge soup" where agents assemble and present small bits of information from a variety of data sources on the fly as appropriate to a given context."
(Bradshaw, 1996)
Context is provided in the IMPS architecture in two ways; firstly through reusable domain independent problem solving models (PSMs), and secondly through the creation by the agents themselves of a structured domain ontology. The PSMs provide templates that describe the types of role that knowledge might play and the inferences in which this knowledge might figure. The ontologies provide a conceptual framework for the organization of knowledge. Both of these can be used to support inter-agent communication and facilitate structured knowledge acquisition. A core concept in the IMPS architecture is the fusion of agent software technology and the problem solving theory embodied in the General Task Models (GTMs) of the KADS expert system design methodology (Schreiber et al, 1993) to create a self-configuring task-oriented KBS. We describe our KA enabled agents as being PSM aware.
When IMPS is used on the Internet, the PSM drives agent knowledge acquisition over highly implicit, heterogeneous and distributed knowledge sources. Coupled with a shared domain ontology, this produces a structured knowledge base that can be used for problem solving.
It has been widely argued (e.g. van Heijst et al, 1996) that explicit ontologies can be used to underpin the knowledge engineering process. Indeed, the idea of a library of problem solving components implies the availability of domain ontologies to instantiate these components. In the IMPS system, rather than being selected from a library, a domain ontology is constructed automatically from keywords using several knowledge sources, including an on-line general lexical database.
Recently, papers such as Fensel (1997) and Benjamins (1997) have started to discuss the implications of the Internet and the WWW for PSM reuse in particular and knowledge engineering in general. The contribution of the IMPS work is an implemented system that draws on emerging standards such as KQML, KIF and Java to produce an integrated multi-agent knowledge acquisition and problem solving expert system. The focus of this paper will be on some central principles behind the IMPS architecture. These include PSM-driven KA over the Internet, the automatic construction and use of ontologies to support mapping between domain knowledge and task structure, intentional performative-based agent communication, and the flexibility provided by the fine-grained decomposition and configuration of agent-embodied problem solving models.
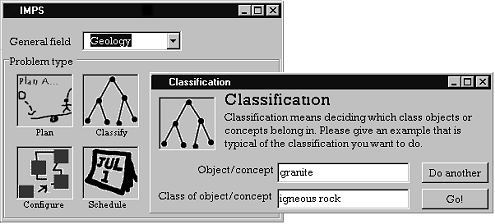
A prototype of the IMPS system has been built. This section gives a detailed view of the specification for ontology construction that informs both the prototype and the full system yet to be implemented. Suppose a user is interested in performing a heuristic classification (Clancey, 1985) task in the domain of geology. A knowledge extraction agent (KExA) interacts with the user via a simple knowledge acquisition interface (Figure 1), allowing the user to specify the kind of task they want to tackle and optionally the general domain area it is in. They then supply some priming keywords - the nature of these depends on what task has been specified. In the example used here, classification has been chosen, so the keywords given are objects or concepts and their classifications. The KExA supplies this information and details of the location of domain knowledge sources and how to extract particular kinds of knowledge from them to an Ontology Construction Agent (OCA). The OCA interacts with an on-line general lexical database [1] to obtain natural language definitions for the terms, and to start building an ontology around them. As the task structure is classification, the significant parts of the ontology will be hierarchical, and significant relations will be 'is-a' (hypernymy) and 'has-a' (meronymy) - the properties of objects are likely to distinguish between them.
Figure 1: A simple knowledge elicitation interface
The objects and relations extracted from the lexical database are presented back to the user graphically (Figure 2). This 'first pass' creates a skeletal ontology for the domain. The terms in each box on the left-hand side of the screen are synonymous (so 'batholith', 'batholite', 'pluton' and 'plutonic rock' all mean the same thing), and a natural language definition of all the terms is available when the box is clicked. The user can do correction or pruning of the ontology at this stage.

Figure 2: The first pass ontology is presented to the user
In the next stage of ontology construction, the OCA supplements the structure it has already by matching terms in that structure with terms in a domain-relevant database [2]. The implicit structure of the database can be used to infer new relationships, which can be added to the hierarchy. For example, the term 'rock, stone' has been defined and is connected to the term 'mineral' in the ontology by the relationship 'has-substance'. 'Rock' and 'mineral' are also found in the domain database, which presents records relating to rocks, with mineral being a field in those records. The OCA applies the heuristic rule that other fields in the record, such as 'essential oxides' and 'trace elements' could have similar relationship to rock, and adds the terms to the ontology.

Figure 3: A simple model of the ontology development process
The structure of the domain database is also used to add 'is_a_kind_of' subsumption links to the ontology - the OCA infers that field names and values might be held in a subsumption relationship - so if a database field is called 'mineral' and a value of the field is 'biotite', then the OCA will connect 'biotite' to 'mineral' in the ontology with an 'is_a_kind_of' relation. This kind of matching and inference can be encapsulated in a simple model (Figure 3) and occurs in an iterative process - the OCA then returns to the lexical database to try and obtain natural language definitions and new relations to attach to the terms it extracted from the domain database, and check them with the user.

Figure 4: The supplemented ontology is presented
It can be seen that this process, when repeated with different knowledge sources, creates an enriched ontology (Figure 4). As the process continues, it becomes clear that there is a thin line between this kind of ontology construction and knowledge acquisition - the same model could be used to describe the acquisition of domain knowledge from multiple sources. The real power is the amount of automated domain acquisition that has been achieved by our epistemological software agents.
It should be noted that there is a wide variety of classificatory PSMs in standard libraries. If a different PSM is used, the concepts and relationships featured in the ontology are qualitatively different. For example, if the PSM specified is model-based classification, then part of the diagnostic process is the explanation of particular features of the entity to be classified. In that case, the ontology produced (Figure 5) is structurally very different.
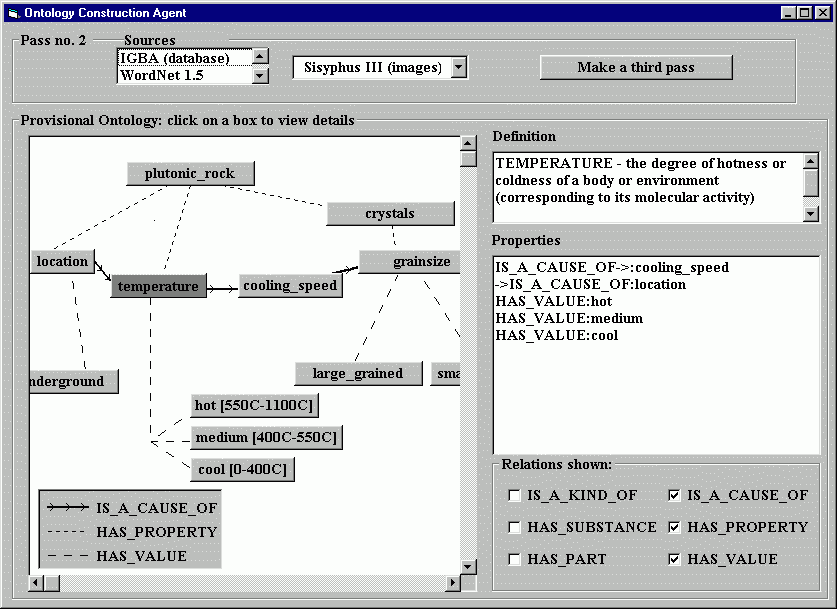
Figure 5: An ontology produced for model-based classification
Any change in the global information landscape will be significant to the knowledge engineer. The impact of the Internet on knowledge engineering (taking a long and perhaps optimistic view of the kind and magnitude of information available over the Internet) may be huge. It could be argued that 'the bottleneck of knowledge acquisition' will undergo a qualitative change. Currently knowledge engineers are faced with the problem of finding expertise from scattered, incomplete and often implicit resources. Perhaps in future there will be a far more promising accumulated wealth of electronically stored relevant legacy software and data to be mined. Whilst this will almost certainly also be unreliable and implicit, it will be much easier to access. The bottleneck will become a torrent, and the task will focus on filtering out relevant and useful morsels of knowledge.
It is a long-term aim of much of the work being done on knowledge sharing and reuse that libraries of knowledge components such as domain and task ontologies be made available over the network. With this in mind, the ideal architecture for the future would seem to be one that is network-based, modular and extendible in such a way that it will be able to use new knowledge representation formats and standards as they arise.
Internet agents are already carrying out information filtering and information retrieval in a number of applications (Bradshaw, 1996). 'Software agency' is a widely used and polysemous phrase implying characteristics of flexibility, autonomy, intelligence, adaptability and high level communication. Agents must at least maintain interaction with their environment, be able to take the initiative, be able to perform social actions, and be able to generate goals independently and act rationally to achieve them (KAW '98 Agent-oriented Approaches to Knowledge Engineering Track Description).
An agent architecture is well suited to the Internet. The distribution of agents in space and time, and their logical and semantic separation can be exploited to cope with the scale and distributed, fast-changing and unreliable nature of the Internet. There is also an advantage in terms of speed of action provided by the concurrency implicit in an agent architecture, although as Bond & Gasser (1988) point out, this must be traded off against issues of problem dependent co-ordination.
In terms of the specific task of applying knowledge engineering techniques to the Internet, one of the great advantages of the agent metaphor is that agents possess intentionality - the ability to express `attitudes' towards information. This property becomes more significant in a multi-agent architecture such as IMPS where the agents express their intentionality in knowledge-level communication. The possibility of having the agents conduct quite sophisticated interactions with regards to bits of information is an asset as it allows flexible manipulation of that information, and is also a good base for a system which will use knowledge-level models. The agents take an epistemic stance with respect to information. The goal-directed nature of the agents at the individual level also serves as an emergent flexible global planning mechanism.
Bradshaw notes that agents are expected by researchers "to help restore the lost dimension of individual perspective to the content-rich, context-poor world of the next decade". It can be seen that the simplest Internet agents, in their role as actors for an individual, are implicitly task oriented. The IMPS architecture aims to take this task-orientation much further, by using PSM-oriented knowledge acquisition to create an explicit task-relevant domain ontology which the agents can refer to in communicating and manipulating information. This ontology is then instantiated with further structured acquisition, providing a domain knowledge base which could in turn underpin agent-based problem solving guided by the same PSM structure.
The basic structure on which all the prototype IMPS agents are based is supplied by the Java Agent Template 0.3 (Frost, 1996). The JAT (Figure 6) provides a template, written in the Java language, for constructing software agents which communicate peer-to-peer with a community of other agents distributed over the Internet. The object-oriented structure of Java is ideal in terms of knowledge reuse - the use of classes, interfaces and encapsulation promote a modular, highly reusable style of programming.
Although portions of the code that define each agent are portable, JAT agents are not migratory. In contrast to many other "agent" technologies, they have a static existence on a single host. All agent messages use KQML as a top-level protocol or message wrapper.
The template provides Java classes supporting a virtual knowledge base for each agent, and includes functionality for dynamically exchanging "Resources", including Java classes such as languages (essentially protocol handlers which enable a message to be parsed and provide some high level semantics) and interpreters (content handlers, providing a procedural specification of how a message, constructed according to a specific ontology, should be interpreted), data files and information inlined into the KQML messages. The JAT enables these resources to be dynamically exchanged between agents in a "just-in-time" fashion, allowing the agent to process a message whose language and interpreter are both unknown by dynamically acquiring the necessary Language and Interpreter classes.
The architecture of the JAT is ideal for prototyping and agent development. It was specifically designed to allow for the replacement and specialization of major functional components including the user interface, low-level messaging, message interpretation and resource handling.

Figure 6: JAT 0.3 Architecture
To date, features that have been added to the JAT template to create IMPS include: new classes to describe and handle PSMs and knowledge sources and a Knowledge Interchange Format
(KIF) parsing component, generated using the Java(TM) Compiler Compiler (TM), and accessible to all agents for interpreting the information contained in KQML messages.
At a multi-agent level, IMPS uses a server architecture, in which two specialist server agents, the Knowledge Extraction Agent (KExA) and the Ontology Construction Agent (OCA) provide knowledge to Inference Agents (IAs) on demand. The Inference Agents embody KADS primitive inference types and co-ordinate to operationalise the PSM.
The KExA acts as a typical multi-agent system Agent Name Server (ANS), holding a registry of the names and locations of all active agents so that that this information can be served to other agents on request. Additionally, the KExA supervises the Knowledge Library, communicating to other agents the location and type of knowledge sources that are available to the system, and information about the problem solving model being used. It is also the interface between the system and the user during the first stages of system operation, providing the Interfaces through which knowledge is entered and translating that knowledge into KIF so all agents can store it in their knowledge bases.
The OCA uses the information that the KExA communicates to parse knowledge sources for the particular kinds of information that the PSM requires. Again, this information is translated and stored in KIF. The OCA has more ability to manipulate information in this form and can perform more sophisticated reasoning over KIF representations, in order to integrate information from different sources and present an ontology graphically for negotiation with the user.
Figure 7 illustrates how this architecture works during ontology construction. The user provides the KExA with domain keywords, and a PSM. Ideally a domain expert rather than a knowledge engineer would use the system, and a PSM would be arrived at after some interaction between the agent and the user which does not require the user to be a PSM expert. The KExA then selects and loads from the knowledge library a Java code module giving details of the PSM to be used - such as knowledge roles, and inference types. The inference types will be later used to create relevant inference agents. The knowledge roles are important for mapping domain information onto the problem solving process.
The PSM code module also contains information that will be used to structure a relevant domain ontology such as details of significant relationships - e.g. heuristic classification requires a domain ontology that is strongly hierarchical, containing many 'is-a' relations. The KExA will also match the kind of relations against information contained in the knowledge library about what information sources are available and what kind of relations they are likely to contain. This information is conveyed to the OCA, which then loads classes from the Knowledge Library that allow it to extract the relevant relations by interacting with the sources. Usually, the OCA will begin by consulting a general thesaurus to get a basic structure of terms around which it can build the ontology.

Figure 7: IMPS Knowledge Acquisition Example
The knowledge library component of IMPS is as essential to its operation as the agent component. The code modules contained within it share common interfaces, so the contents can be invisible to the agents using them.
Agent communication in IMPS can be considered at several levels. Bond & Gasser (1988) define the problem in terms of "what communication languages or protocols to use, what and when to communicate".
KIF Knowledge Interchange Format (KIF) is used for representing knowledge in the agents' knowledge bases. It is a formal language for the interchange of knowledge among disparate computer programs. KIF has declarative semantics - it is possible to understand the meaning of expressions in the language without appeal to an interpreter for manipulating those expressions. It is logically comprehensive, providing for the expression of arbitrary sentences in predicate calculus. Also, it provides for the representation of knowledge about the representation of knowledge. This meta-knowledge allows knowledge representation decisions to be made explicit and permits the introduction of new knowledge representation constructs without changing the language. KIF has been designed to maximize translatability, readability and usability as a representation language (Genesereth & Fikes, 1992).
KIF is the syntactic and semantic basis of Ontolingua (Gruber, 1992), a system for describing ontologies in a form that is compatible with multiple representation languages. Ontolingua is designed to facilitate knowledge base reuse by providing a common format for describing ontologies. The use of KIF as a representation language means that any ontologies and knowledge bases created by IMPS can be translated into other forms (such as LOOM, Epikit) by Ontolingua and will be more generally reusable. Ontolingua also provides useful sharable base ontologies such as the Frame-Ontology. The Frame Ontology allows for richer knowledge description with the addition of second-order relations to capture the common knowledge-organization conventions used in object-centered or frame-based representations (Gruber, 1993).
KQML IMPS uses the Knowledge Query and Manipulation Language (KQML) for inter-agent communication, as specified and supported by the JAT. KQML has been proposed as a standard communication language for distributed agent applications (Finin, Labrou & Mayfield, 1997), in which agents communicate via "performatives". It has a strong theoretical rooting in speech-act theory. The sender explicitly represents and reasons about communication primitives and their effects in order to try and bring about specific mental states in the hearer (Jennings, 1992). KQML is intended to be a high-level language to be used by knowledge-based systems to share knowledge rather than an internal representation language. As such, the semantics of its performatives refer specifically to agents' 'Virtual Knowledge Bases' - each agent appears to other agents to manage a knowledge base, whether or not this is true of the actual architectural implementation. In fact, in IMPS, this is the case and KIF statements are embedded in KQML. KQML supports the agent characteristic of intentionality, by allowing agents to communicate attitudes about information through performatives, such as querying, stating, believing, requiring, subscribing and offering.
Using KQML for communication means that some information about the state and beliefs of other agents can be conveyed to another agent easily, providing the basis for an architecture in which agents have some kind of model of other agents, enabling co-ordination. The use of KQML is also part of the attempt to make IMPS agents operate at the knowledge level:
"The knowledge level permits predicting and understanding behaviour without having an operational model of the processing that is actually being done by the agent"
(Newell, 1982)
This means that whatever internal knowledge representation mechanisms agents have, agent interaction is done at the knowledge level - it is as representation independent as possible. KQML is indifferent to the format of the information itself, so expressions can contain sub-expressions in other languages. So, in IMPS, KIF is used for conveying the actual information content of Virtual Knowledge Bases, whilst KQML itself is used to convey the location of knowledge sources, agents and Java code modules.
Agent Co-ordination Protocols Jennings suggests that when discussing multi-agent systems, another layer can be added above the knowledge level -
" ...a cooperation knowledge level would be concerned with those aspects of problem solving specifically related to interacting with others"
(Jennings, 1992)
A full and clear description of any multi-agent system must convey how co-operation between agents for a shared goal is achieved, in other words, how the agents interact productively with as little redundancy as possible. One way in which the IMPS architecture aims to accomplish this is specialization - in addition to the KExA and OCA server agents, each Inference Agent specializes in performing a particular process or inference step in the KADS-based PSM.
Further co-ordination is to be based on structured interaction protocols rather than global planning, using the idea of structured "conversations" as proposed by Barbuceanu & Fox (1996) (also Bradshaw, 1996). Their co-ordination language COOL relies on speech act based communication in the form of KQML, but integrates it in a structured conversation framework, modelling co-ordination activity as a conversation among two or more agents, specified by means of a finite state machine, with some basic components. These components include the states of the conversation (including an initial state and several terminating states), and a set of conversation rules specifying how an agent in a given state receives a message of specified type, does local actions (e.g. updating local data), sends out messages, and switches to another state. This language, or a similar construction based around KQML is proposed as a solution to the co-ordination problem in IMPS.
Reusable problem-solving methods focus on the idea that certain kinds of task are common (e.g. planning, classification) and can be tackled by using the same problem-solving behaviour, although they may appear superficially different because they occur in different domains with different terminology. Knowledge acquisition for expert systems using such methods focuses knowledge base construction on domain-independent problem-solving strategies.
The separation of an abstracted problem solving method from domain knowledge is in accordance with Problem Solving Models (Weilinga et al., 1991), Role-Limiting Methods (Klinker et al., 1991), Components of Expertise (Steels, 1990) and Generic Tasks (Chandrasekaran, 1986). What these approaches have in common is the use of a finite library of domain independent problem solving models, which may need some tuning to suit the domain of application.
The advantage of such methods is that they supposedly promote the reuse of knowledge. However, the larger the grainsize of these models, the more limited their reusability, therefore the approach is moving towards a smaller grainsize, with finer-grained problem-solving strategies which can be configured together to form a KBS (Puerta et al, 1992; Gil & Melz, 1996). Walther et al (1992) discuss expert system metatools which attempt to increase the flexibility of strong problem solving methods by breaking them into smaller reusable models, which can be configured according to the requirements of each application. This notion is developed in IMPS - the PSMs are not treated as the finest grain of analysis. Smaller components - the KADS primitive inference types - are embodied in agent shells. The problem-solving agents themselves can be seen as problem solving modules, each embodying a particular kind of inference. The problem solving system arises from the dynamic configuration of agents.
Additionally, Fensel (1997) points out that one reason actual reuse of PSMs doesn't occur as often as it might is that implemented PSMs make strong assumptions on software and hardware environments that limit reuse in other environments. These limitations are bypassed in an Internet-based architecture such as IMPS.
Problem solving models can also make assumptions about the nature and structure of domain knowledge to be used.
"Representing knowledge for the purpose of solving some problem is strongly affected by the nature of the problem and the inference strategy applied to the problem"
(Bylander & Chandrasekaran, 1988)
The PSMs used in IMPS are provided with task-specific domain information. The mapping between domain knowledge and reusable problem-solving components begins in ontology construction and continues through knowledge acquisition. In both stages, agents are primed by a server agent with information about distributed information sources and the kind of knowledge required for a particular task, they will select from a library the classes for extracting particular kinds of information from particular sources.
IMPS is modular and therefore extendible in the several ways; firstly, components in the library do not need to be held at the same physical location - they can be distributed across the network as long as they are registered with the Knowledge Extraction agent. Within the library, the knowledge sources are indexed by type - e.g. database, plain text file, etc., so new instances of a particular type merely need to be identified as such for them to be used by the system.
Also, the extraction classes used to obtain particular kinds of knowledge from knowledge sources are all based around a common Java interface, with standard inputs and outputs. The actual mechanisms by which the class extracts information from a source and parses it into KIF are completely hidden from the agent loading the class, according to the Object Oriented paradigm embodied by Java. New classes can be added to the library as appropriate, in a 'plug-and-play' manner, without any change to the rest of the architecture.
Knowledge sources available to the IMPS architecture do not have to be static - in anticipation of a global network in which an increasing amount of the information available is dynamically created, the classes can be written in such a way that they interact with programs available over the network, such as search engines.
Many knowledge intensive activities would clearly benefit from the existence of reusable libraries of domain ontologies. There are a growing number of efforts in this direction. However, significant obstacles need to be overcome (Van Heijst et al, 1996).
The hugeness problem concerns the enormous amount of knowledge in the world. The Internet information retrieval problem is simply a resurfacing of this wider problem as a significant fraction of the knowledge in the world is becoming available electronically. In order to provide usable ontologies for a significant range of domain areas, the library itself would have to be huge, and in order to make a system useful in areas not covered by the library, there would have to be some method for supplying ontologies to 'cover the gaps'. This being the case, and considering also the problem of interaction between PSMs and domain knowledge, it seems that more use and reuse might be obtained from a system that constructs ontologies at runtime rather than using libraries.
In a system that anticipates increasing information flow and networking, such an approach is also designed to deal with a fast changing information environment - what was an adequate ontology of domain terms two years ago may no longer be so today. A system, like IMPS, which can integrate and use knowledge from different sources (including existing ontology resources, such as Ontolingua) to construct a domain-specific, task-specific ontology could be used both to create new ontologies for domains, and also to update existing ontologies, or adapt ontologies created for different tasks.
A precedent for this work can be seen in the SENSUS project (Swartout et al., 1996) which has involved the use of a broad coverage general ontology to develop a specialized, domain specific ontology semi-automatically. Swartout argues for a conceptualization of ontologies as "living documents" whose development is integrated with that of the system they are to be used in. Additionally, progress is being made in defining mathematical methods for building ontologies - to allow the use of formal domain construction operators (Martínez-Béjar et al., 1997).
The general ontology used by IMPS is the WordNet semantically organized lexical database (Miller, 1990), which contains approx. 57,000 noun word forms organized into approximately 48,800 word meanings (synsets). WordNet has advantages over other general ontologies in terms of a strong grounding in linguistic theory, on-line status and implemented search software (Beckwith & Miller, 1990) In the long-term view, it has a Java interface suitable for agent interaction over the Internet, and several EuroWordNet projects are running. However, there are other general ontologies e.g. PENMAN Upper Model (Bateman et al., 1989), Cyc Upper Ontology (including approximately 3000 of Cyc's highest concepts with the hierarchical links between them), and, of course, Ontolingua, available to a greater or lesser extent via the Web.
Once a skeletal ontology has been created from a general ontology, IMPS supplements it with information obtained from data representations which contain explicit or implicit ontological statements, such as Ontolingua statements or relational database formats. This function could serve as a 'proof of concept' for the design of a set of protocols (implemented as Java classes) for the extraction of data from a variety of sources, such as databases, natural language text etc. that might be available to a distributed agent architecture e.g. over the Internet. A set of heuristic rules for the extraction of data from each kind of source could exploit the implicit ontologies inherent in the structure of information sources as illustrated in the `Vision' section.
Ontologies are used within the IMPS architecture to facilitate co-ordination at the PSM, inference and domain layer. The domain ontology shared by the agents is used as a basis for problem solving communication relating to the domain.
"In the context of multiple agents (including programs and knowledge bases), a common ontology can serve as a knowledge -level specification of the ontological commitments of a set of participating agents"
(Gruber, 1993)
In order to allow co-operation between agents, each agent must also have some idea of the capabilities, knowledge, input and output of the other agents. This is provided in the form of a method ontology available from each Inference Agent which describes the agent in terms of the input and output roles of their inference method. The method itself will be hidden from the view of other agents, in a Java class, or in some other form with a Java wrapper. Thus each agent represents itself at the knowledge level in terms of knowledge roles, a level of abstraction away from the actual mechanisms it uses.
The PSMs stored in the IMPS knowledge library are indexed ontologies describing each PSM in terms of input and output roles, inferences (used to spawn Inference Agents), the data flow between them, and domain requirements, such as significant relations (used for constructing a domain ontology, and during KA). PSM ontologies in IMPS are stored as Java classes using a common interface. Like Fensel et al. (1997), IMPS specifies method ontologies for indexing and reuse of PSMs in terms of competence and knowledge requirements, rather than internal mechanisms. The PSM library used by IMPS could be supplemented or even completely constructed from existing libraries of PSMs, as long as they contain enough information to write a PSM ontology for each model. Such libraries are becoming increasingly available over the WWW e.g. the diagnosis PSM library described by Benjamins (1997). This demonstrates one possible answer to the call for standardized PSM ontologies.
An IMPS prototype has been implemented, which focuses on the activity of the two server agents, the OCA and KExA, in the context of a heuristic classification task in the domain of geology. This implements the type of scenario described in the `Vision' section. It demonstrates the processes by which the agents accept domain keywords and a PSM from a user interface and
Figure 8: A process model of the prototype
arrive at a structured and instantiated ontology. This involves structured conversations between the agents in which the KExA supplies the OCA with information about the location and type of knowledge sources, and the nature and requirements of the PSM. This conversation is carried out in a series of KQML messages (Figure 8).
The interfaces used by the prototype to extract information from the user are very simple (Figure 9).

Figure 9: The KExA's user interfaces
Figure 10: The first-pass ontology is presented graphically to the user
The OCA uses the information to load and use the appropriate classes for interacting with an on-line thesaurus and domain database to extract task-relevant information. This is parsed and stored in the OCA's knowledge base in the form of KIF statements stored as Java objects, which can be viewed, queried and altered by the user via a graphical interface (Figure 10) and served to other agents on request. The basic structure and representation used in the knowledge library is covered, in terms of PSM and knowledge source ontologies and modular extraction protocols.
As yet the Inference Agents that can undertake problem solving using the extracted knowledge contained in the task-oriented ontologies have not been implemented.
The Internet will be a rich resource for knowledge engineering. In this paper we have described a system designed to exploit this resource. The IMPS multi-agent architecture performs PSM-driven ontology construction and knowledge acquisition from distributed and implicit knowledge sources, rather than simple information retrieval. This is made possible by the application of structure and context to a modular architecture.
IMPS draws on a number of existing ideas in the literature. Its novelty lies in the integration and extension of these ideas, and in the use of emerging standards for interoperability. We have described a basic interaction with IMPS, and shown how the system we describe is based in existing technologies. The elements of the system - Java, KQML, KIF and PSMs, are designed to enable knowledge sharing and reuse. They are assembled in a server-based multi-agent architecture - an arrangement which has proved successful in previous agent applications, but which now embodies PSM-focused knowledge.
InfoSleuth (Jacobs & Shea, 1996) is such architecture. It is composed of co-operating KQML-speaking agents for finding and analyzing data. Ontologies provide the collaborating agents with a common vocabulary and semantic model for interaction in a problem domain. The Java API is used to allow different ontology formats to be queried using the same operators. At the moment, InfoSleuth has a much broader range of functionality than IMPs does - agents support both general and domain specific services such as knowledge mining, fuzzy queries, brokering, query decomposition and result integration, query format conversion, and user monitoring and result sharing. However, it does not have the specific task-orientation that a PSM provides and contains no conventional KA methods.
PROTÉGÉ-II (Gennari et al., 1994) embodies some of the same ideas as IMPS, namely the reuse of components (including PSMs, ontologies and knowledge bases), and the use of ontologies at several levels to generate domain- and method-specific knowledge acquisition tools. While PROTÉGÉ-II treats the decomposition of a PSM into top-level subtasks as a 'crucial design decision', with KADS this decomposition is already guided by the primitive inference types that make up a GTM. However, the system lacks the dimension of agency, and has only recently begun the move towards a distributed environment.
The idea of agent-encapsulated KADS was explored in relation to the Quantified Integrated Logic (QIL) (Aitken & Shadbolt, 1992). This defined a formal semantics for describing and reasoning about multi-agent systems, allowing the description of KADS problem solving models within agents. It organized the agent's beliefs into three categories: domain knowledge, inference knowledge and task knowledge, taking the view that co-operative behaviour should be defined in the context of the specific problem solving methods embodied in an agent. Agent co-ordination rules have been proposed in CooperA-II (Sommaruga & Shadbolt, 1994). Taking a Gricean stance, CooperA-II implemented co-ordination rules and the small group interaction of problem solving agents in a distributed computing environment. Whilst formulating key capabilities, these projects lack integration into the knowledge-sharing framework that is now emerging.
Areas for development in the future include the detailed description of how IMPS inference agents can be configured 'on-the-fly' into a coherent problem solving model based on a PSM ontology. This question raises the indexing problem (Breuker, 1997) which states that it is hard to relate the competence and knowledge requirements of a PSM with the actual problem and the available domain knowledge. Mappings between domain knowledge and PSM roles are traditionally made by a knowledge engineer. The PROTÉGÉ project illustrates the mapping problems that we anticipate will emerge in IMPS as the project matures. Mechanisms for automating this process, such as ontology adapters, are currently being proposed (e.g. Fensel et al., 1997).
Other issues which must be dealt with for network based knowledge acquisition to be useful are how to deal with incomplete and incorrect information and disagreement between multiple knowledge sources.
"To cope with this inherent uncertainty, incompleteness and dynamicity, it is important that the collaborators have a well specified description of how to evaluate (track) their ongoing problem solving and a prescription of how to behave should it run into difficulties"
(Jennings, 1992)
However, this problem is being examined and tackled in existing agent architectures for example KAoS (Bradshaw, 1996). Like IMPS, KAoS agents share knowledge about message sequencing conventions (conversation policies), enabling agents to co-ordinate interactions. However, they also have abilities for dealing with dynamic information by using mechanisms to detect inconsistency and/or completeness in the agent's knowledge. Knowledge is represented as facts and beliefs, where facts are defined as beliefs with complete confidence. The task of gathering information from a large unreliable network has also been tackled by the Sage project (Knoblock, 1995) which provides a flexible and efficient system for integrating heterogeneous and distributed information. This flexibility with respect to imperfect information sources is not yet a feature of IMPS and some facility for dealing with this problem must be added before IMPS can be practically used on the Internet.
The treatment of information retrieval as a problem solving activity (c.f. Oates et al., 1994), encourages us to add heuristic reasoning capacities to IMPS, using the classic A.I. principle that "Applying knowledge to a problem reduces search". This would cover the issues of incompleteness and inconsistency discussed already, but also extend to other areas such as the exploitation of low-level characteristics of the Internet information environment. This approach can be seen in IFISH - The Internet Fish (LaMacchia, 1996), which is a single-agent, data-driven architecture for Internet information retrieval. Heuristic knowledge is built into IFISH via predefined rules, which contain methods for obtaining new information over the network, procedures to identify and parse particular expressions of data objects, and to look for relationships among retrieved objects. IFISH uses these rules to work in conjunction with dynamic Web entities such as search engines. This work shares with IMPS an emphasis on dynamic interaction on the WWW, but could be extended with the inclusion of a learning component to acquire new heuristics.
A second principle of classical A.I. has already been demonstrated in IMPS - "If a problem is requiring too much search, you should reformulate it". This is the essence of the architecture - a reformulation that exploits ontologies and Problem Solving Methods. These structures enable the acquisition, re-representation and re-description of relevant problem solving knowledge.
The architecture does not merely represent a `bolting together' of existing technologies - it proposes a solution to the research issue of what components are necessary to create a rational and scalable architecture, to the issue of whether significant problem solving agents can be designed and implemented, and to the issue of producing complex communication protocols that are generated and interpreted in the light of domain ontologies, problem solving models and acquisition activities.
Louise Crow is supported by a University of Nottingham Research Scholarship.
1.In this case the WordNet thesaurus was used containing over 60,000 noun entries & an extensive set of lexical relations.
2.In our example the IGBA geological database with over 19,000 igneous rock cases has been used.
Aitken, S & Shadbolt, N. R. (1992). Modelling agents at the 'Knowledge Level': a reified approach. Unpublished technical report, A.I. Group, University of Nottingham.
Barbuceanu, M. & Fox, M. S. (1996). COOL: A Language for Describing Coordination in Multi Agent Systems. In Proceedings of the First International Conference on Multi-Agent Systems (ICMAS-95), San Francisco, California, pp.17-24.
Bateman, J. A., Kasper, R. T., Moore, J. D., & Whitney, R. A. (1989). A General Organisation of Knowledge for Natural Language Processing: The Penman Upper Model. Unpublished research report, USC/Information Sciences Institute, Marina del Rey.
Beckwith, R. & Miller, G. A. (1990). Implementing a lexical network. International Journal of Lexicography, Vol. 3 (4).
Benjamins, R. (1997). Problem-Solving Methods in Cyberspace. In Proceedings of the Workshop on Problem-Solving Methods for Knowledge-based Systems at the 15th International Joint Conference on AI ( IJCAI'97), Nagoya, Japan.
Bond, A. H. & Gasser, L. (Eds.) (1988). Readings in Distributed Artificial Intelligence. San Mateo, CA: Morgan Kaufmann.
Bradshaw, J. (Eds.) (1996). Software Agents. Menlo Park, California: AAAI Press/The MIT Press.
Bradshaw, J. (1996). KAoS: An Open Agent Architecture Supporting Reuse, Interoperability, and Extensibility. In Gaines, B. & Musen, M. (Eds.) Proceedings of Tenth Knowledge Acquisition for Knowledge-Based Systems Workshop (KAW '96), Banff, Canada: SRDG Publications.
Breuker, J. (1997). Problems in indexing problem solving methods. In Proceedings of the Workshop on Problem-Solving Methods for Knowledge-based Systems at the 15th International Joint Conference on AI (IJCAI'97), Nagoya, Japan.
Bylander, T. & Chandrasekaran, B. (1988). Generic tasks in knowledge-based reasoning: the right level of abstraction for knowledge acquisition. In B. Gaines et al. (Eds.) Knowledge Acquisition for knowledge-based systems, Vol.1, pp. 65-77. London: Academic Press.
Chandrasekaran, B (1986). Generic tasks in knowledge-based reasoning: High-level building blocks for expert system design. IEEE Expert, Vol.1 (3).
Clancey, W. J. (1985). Heuristic Classification. Artificial Intelligence, Vol. 27.
Cupit, J. & Shadbolt, N. R. (1994). Representational redescription within knowledge intensive data-mining. In Proceedings of the Third Japanese Knowledge Acquisition for Knowledge-Based Systems Workshop (JKAW'94).
Fensel, D (1997). An Ontology-based Broker: Making Problem-Solving Method Reuse Work. In Proceedings of the Workshop on Problem-Solving Methods for Knowledge-based Systems at the 15th International Joint Conference on AI (IJCAI-97), Nagoya, Japan.
Fensel, D., Motta, E., Decker, S. & Zdrahal, Z. (1997). Using Ontologies for defining tasks, problem-solving methods and their mappings. In Plaza, E and Benjamins, R. (Eds.), Proceedings of the 10th European Workshop on Knowledge Acquisition, Modelling and Management (EKAW '97), pp. 113-128. Springer-Verlag.
Finin, T., Labrou, Y. & Mayfield, J. (1997). KQML as an agent communication language. In J. M. Bradshaw (ed.) Software Agents. Cambridge, MA: AAAI/MIT Press.
Frost, H. R. (1996). Documentation for the Java(tm) Agent Template, Version 0.3. Stanford University. WWW: http://cdr.stanford.edu/ABE/documentation/index.html
Genesereth, M. R. & Fikes, R. E. (1992). Knowledge Interchange Format Version 3.0 Reference Manual. Technical Report Logic-92-1, Computer Science Department, Stanford University.
Gennari, J. H., Tu, S. W., Rothenfluh, T. E. & Musen, M. A. (1994). Mapping domains to methods in support of reuse. Proceedings of 8th Knowledge Acquisition for Knowledge-Based Systems Workshop (KAW'94), Banff, Canada, 1994.
Gil & Melz (1996). Explicit Representations of Problem-Solving Strategies to Support Knowledge Acquisition. In Gaines, B. & Musen, M. (Eds.) Proceedings of 10th Knowledge Acquisition for Knowledge-Based Systems Workshop (KAW '96), Banff: SRDG Publications.
Gruber, T. R. (1992). Ontolingua: A mechanism to support portable ontologies. Technical Report KSL-91-66, Stanford University, Knowledge Systems Laboratory.
Gruber, T. R. (1993) A translation approach to portable ontology specifications. Knowledge Acquisition, Vol. 5 (2).
Jacobs, N. & Shea, R. (1996). The Role of Java in InfoSleuth: Agent-based Exploitation of Heterogeneous Information Resources, MCC Technical Report MCC-INSL-018-96.
Jennings (1992). Towards a cooperation knowledge level for collaborative problem solving. In Proceedings of the 10th European Conference on Artificial Intelligence (ECIA-92) Vienna, Austria, pp. 224-228.
Klinker, G., Bhola, C., Dallemagne, G., Marques, D., and McDermott, J. (1991). Usable and reusable programming constructs. Knowledge Acquisition, Vol. 3 (2).
Knoblock, C. A. (1995). Planning, executing, sensing, and replanning for information gathering. In Proceedings of the 14th International Joint Conference on Artificial Intelligence (IJCAI'95), Montreal, Canada.
LaMacchia, B., A. (1996). The Internet Fish Construction Kit. Proceedings of the 6th International World Wide Web Conference, http://www6.nttlabs.com/HyperNews/get/PAPER138.html
Martínez-Béjar , R, Benjamins, V. R., & Martín-Rubio (1997). Designing Operators for Constructing Domain Knowledge Ontologies. In Plaza, E and Benjamins, R. (Eds.), Proceedings of the 10th European Workshop on Knowledge Acquisition, Modelling and Management (EKAW '97), pp. 159-174, Springer-Verlag.
Miller, G. (1990). WordNet: An on-line lexical database. International Journal of Lexicography, Vol. 3 (4).
Newell, A. (1982). The Knowledge Level. Artificial Intelligence, Vol. 18.
Oates, T., Prasad, M. V. N. & Lesser, V. R. (1994). Networked Information Retrieval as Distributed Problem Solving. In Proceedings of the 3rd International Conference on Information and Knowledge Management (CIKM-94) Workshop on Intelligent Information Agents.
Puerta, A. R., Eriksson, H., Egar, J. W. & Musen, M. A. (1992). Generation of Knowledge-Acquisition Tools from Reusable Domain Ontologies. Technical Report KSL 92-81 Knowledge Systems Laboratory, Stanford University.
Schreiber, G., Weilinga, B. & Breuker, J. (Eds.) (1993). KADS, A principled approach to knowledge-based system development. London: Academic Press Ltd.
Shaw, M. & Gaines, B. (1995). Comparing Constructions through the Web. In Proceedings of Computer-Supported Cooperative Learning '95 (CSCL'95), Indiana, U.S.A., pp.300-307.
Sommaruga, L. & Shadbolt, N. R. (1994). The Cooperative Heuristics Approach for Autonomous Agents. In Proceedings of the Cooperative Knowledge Base Systems Conference (CKBS'94), pp. 49-61.
Steels, L (1990). Components of Expertise. AI Magazine, Vol. 11 (2).
Swartout, B., Patil, R, Knight, K. & Russ, T. (1996). Toward Distributed Use of Large-Scale Ontologies. In Gaines, B. & Musen, M. (Eds.) Proceedings of the 10th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop (KAW '96). Banff, Canada: SRDG Publications.
Van de Velde, W. (1995). Reuse in Cyberspace. Published as an abstract at the Dagstuhl seminar on 'Reusable Problem-Solving Methods', Dagstuhl, Germany.
van Heijst, G., Schreiber, A. Th. & Wielinga, B. J. (1996). Using Explicit Ontologies in KBS Development. International Journal of Human-Computer Studies/Knowledge Acquisition, Vol. 45.
Walther, E., Eriksson, H. & Musen, M. (1992). Plug-and-Play: Construction of task-specific expert-system shells using sharable context ontologies. Technical Report KSI-92-40, Knowledge Systems Laboratory, Stanford University.
Wielinga, B., de Velde, W. V., Schreiber, G., and Akkermans, H. (1991). Towards a unification of knowledge modelling approaches. Technical Report KADS-II/T1.1/UvA/004/2.0, Dept. of Social Science Informatics, University of Amsterdam.