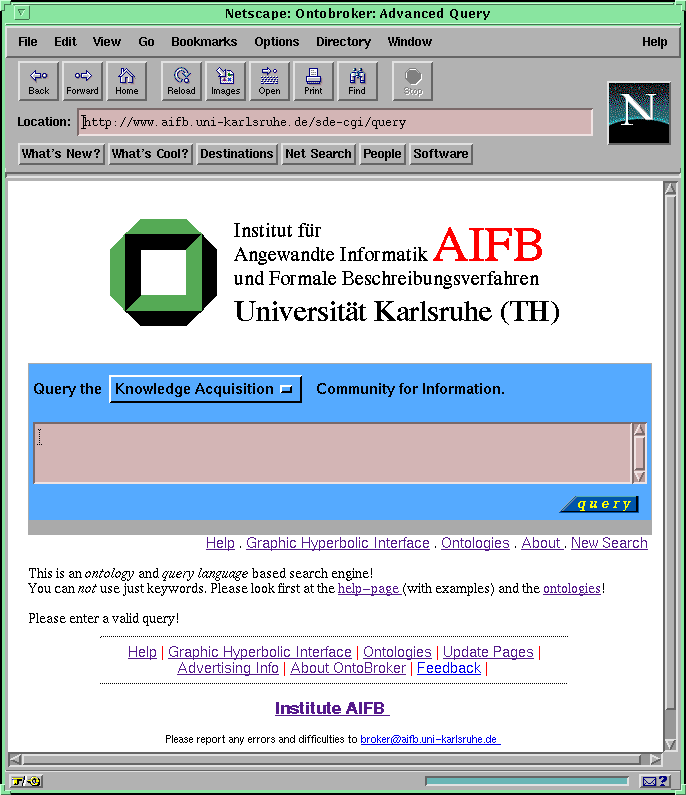
Fig.1: The Start Page (larger image)
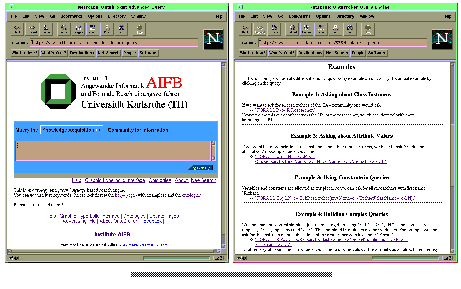
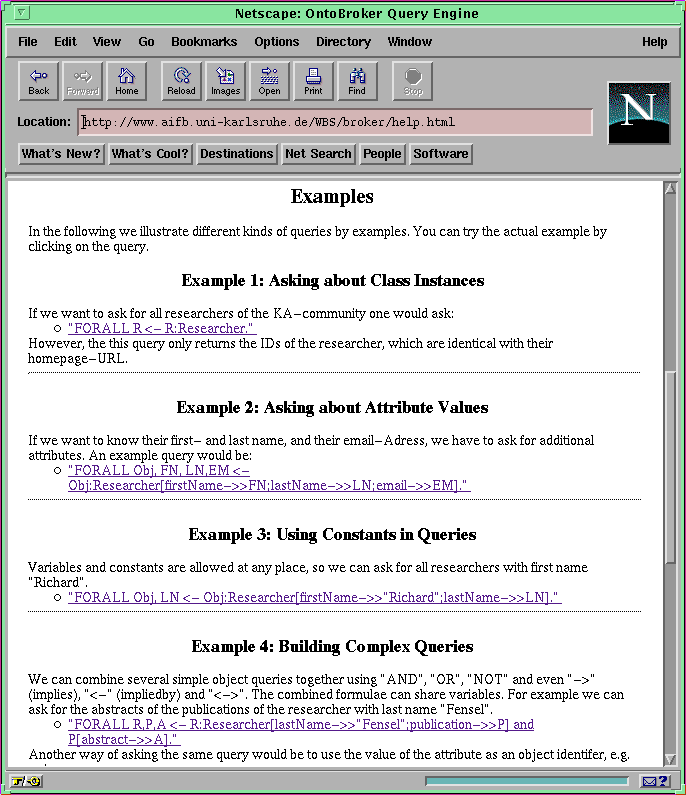
Fig.2:The Query Page (a) (larger image) and the Help Page (b) (larger image).
Stefan Decker, Michael Erdmann, Dieter Fensel, Rudi
Studer
University of Karlsruhe, Institute AIFB, 76128
Karlsruhe, Germany
Email: {decker, erdmann, fensel,
studer}@aifb.uni-karlsruhe.de,
http://www.aifb.uni-karlsruhe
.de/WBS/broker
Abstract. The World Wide Web (WWW) is currently one of the most important electronic information sources. However, its information retrieval mechanisms and the provided reasoning services are rather limited. Ontobroker consists of a number of languages and tools that enhance query access and inference service in the WWW. The paper provides a detailed description of how to use Ontobroker .
The World Wide Web (WWW) contains huge amounts of knowledge about almost all subjects you can think of. However, the capabilities for automated inferencing are rather limited, so we designed and implemented some tools necessary to enable the use of ontologies for enhancing the web. The broker architecture called Ontobroker [Ontobroker] consists of three core elements: a query interface for formulating queries, an inference engine used to derive answers, and a webcrawler used to collect the required knowledge from the web. This paper provides a manual for using Ontobroker . More details of the whole approach can be found in. [Fensel et al, 1998a] [Fensel et al, 1998b] .
This paper is organised as follows. In section 2 , we demonstrate the client side of Ontobroker and show, how to pose queries with three different approaches: using predefined query schemes, the textual interface and a graphical interface. Section 3 shows the provider side: how to become a knowledge provider, and how to annotate HTML-pages. Section 4 ends with some conclusions and future work.
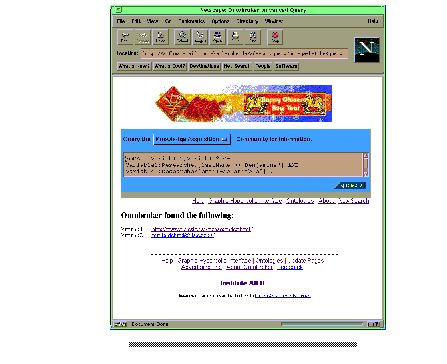
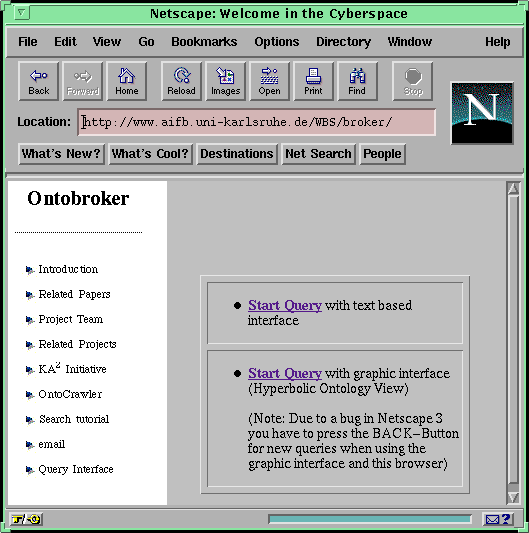
The Ontobroker query interface is attached to the WWW as a web page. For posing queries one has to go to the start page provided by the URL http://www.aifb.uni-karlsruhe.de/WBS/broker (see Figure 1 ). The page provides several possibilities, e.g. more information and papers about the project, two different modes for accessing the query-forms, or to use Ontocrawler to update the factual knowledge base. At first we describe the textual query interface, which can be reached through the first "Start Query" button on the right side. This directly leads to another page presenting the main query interface of Ontobroker (see Figure 2 ). The interface provides the main interaction component of Ontobroker . Queries can be posed in three ways:
Fig.1: The Start Page (larger image)
Fig.2:The Query Page (a) (larger image) and the Help Page (b) (larger image).
The first approach is the most powerful, but also the most difficult possibility of posing queries, because the user has to know the syntax and semantics of the query language and he has to know the content (and exact spelling) of the concepts available in the ontology. People, who are non specialists, and who are only occasionally using such a system are not willing to learn an abstract syntax for using the query engine.
So we focus on the latter two approaches, that define some support for posing queries. In either way, the user has to choose the ontology he wants to use for his queries, and he has to provide some information that is used to build the query in a textual from. The ontologies available for Ontobroker can be viewed by choosing the "Ontologies"-link at the main query page ( Figure 2 a).
The help page is available through the Help link below the text input form. This help page provides several examples of queries that can be directly processed by Ontobroker (see Figure 2 ). Some provided examples are e.g.:
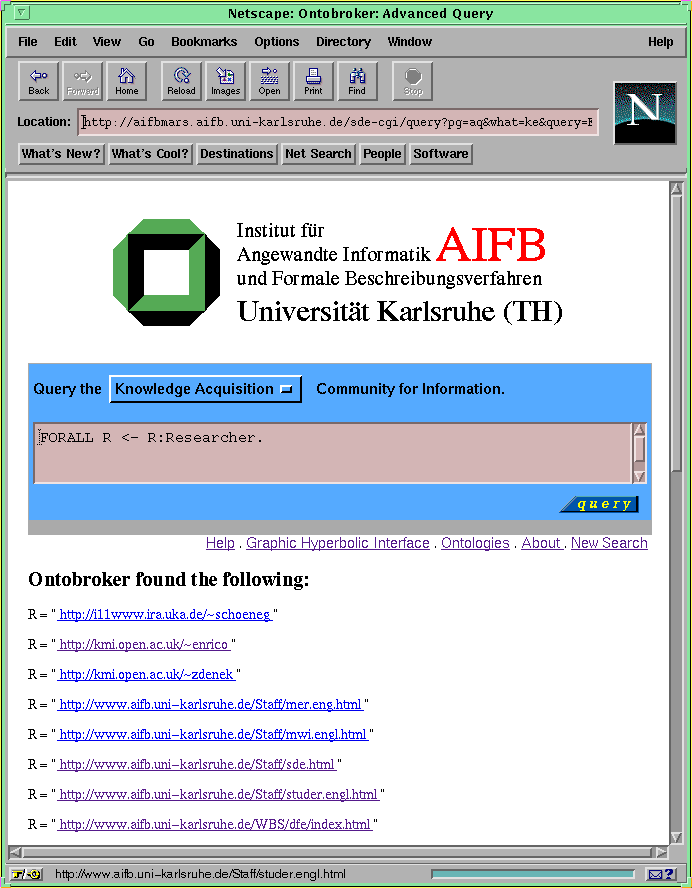
By clicking on these queries the main query window shows up again, providing now the query in the main input form of the window. This provides one kind of access for using Ontobroker : instead of typing individual queries, query templates can be selected and changed accordingly to the actual needs. By clicking on the "query" field below the input form, the query is sentto and processed by the inference engine of Ontobroker . After a few seconds a new page is returned containing the query and the inference results. If the search results are URLs, they are directly clickable, i.e. the object IDs are represented by URLs and can be used for locating the homepages of the researchers. The first query shown above and part of the inference results are depicted in Figure 3 .
However, even when using templates the direct formulation of the query has two drawbacks:
Fig3: Query Page with Inference Results (larger image)
To remedy these drawbacks Ontobroker provides an additional interface.
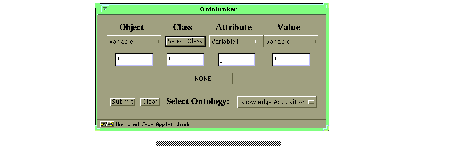
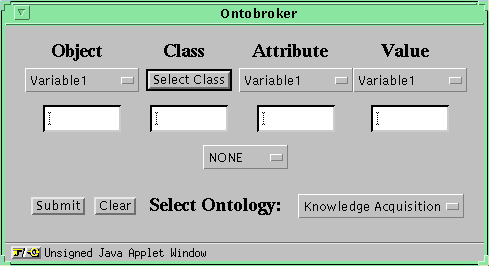
Ontobroker provides a second query interfaces, which is Java based and therefore allows for a better support than the HTML based query interface while it is still executable on all major platforms where a Web-browser with Java support exists. Based on these interfaces Ontobroker automatically derives the query in textual form and presents the result of the query. To start the Java-Applet the user has to select the second "Start Query"-link on the introduction page (see Figure 1 ) or, alternatively, the "Graphic Hyperbolic Interface" link on the main query page (see Figure 2 ). After a few seconds the applet window shows up. In this interface the structure of the query language can be exploited to remedy the first drawback: in a Query-By-Example like interface the user only provides the information he already knows and from that the query is generated (see Figure 4 ).
Fig.4: Applet Query Window (larger image)
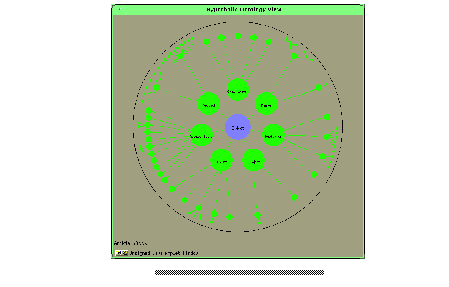
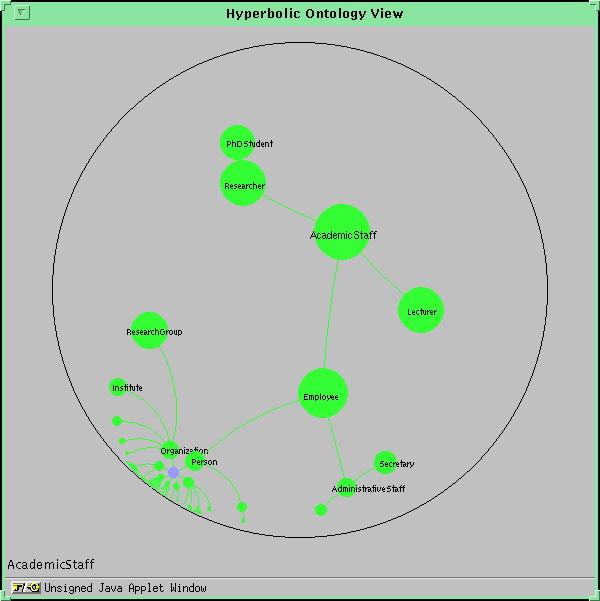
But this does not resolve the second drawback: also support for selecting classes and attributes from the ontology is needed, because nobody can be expected to know the hole ontology. So, to allow for the selection of classes, the ontology has to be presented in an appropriate manner. Usually an ontology can be represented as a large hierarchy of concepts. In regard to the handling of this hierarchy a user has at least two requirements: first he wants to scan the vicinity of a certain class looking for classes better suited to formulate a certain query. Second a user needs an overview over the whole hierarchy to allow a quick and easy navigation from one class in the hierarchy to another class (and at best this navigation should be continuous, so that there is no rapid change in the presentation). These requirements are met by a presentation scheme based on Hyperbolic Geometry 1(see Figure 5 ): classes in the center are depicted with a large circle, whereas classes at the border of the surrounding circle are only marked with a small circle. The visualisation techniques allows a quick navigation to classes far away from the center as well as a closer examination of classes and their vicinity. When a user selects a class from the hyperbolic ontology view, the class name appears in the class field and the user can select one of the attributes from the attribute choice menu because the pre-selected class determines the possible attributes. The window that presents the ontology in the described way pops up at the same time as the applet main windows.
Fig.5: Initial Hyperbolic Ontology View (larger image)
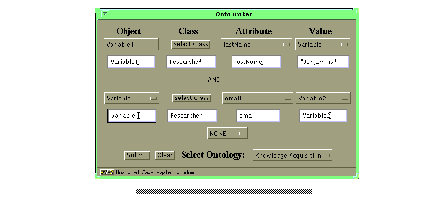
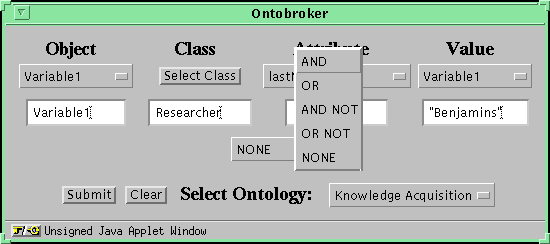
To formulate a query we have to perform several steps. Lets say we want to pose the following query:
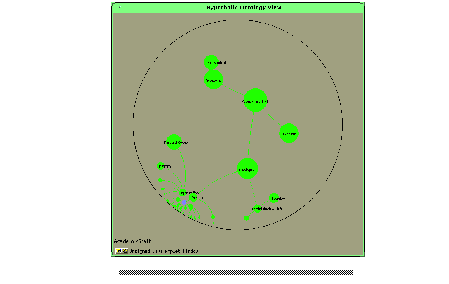
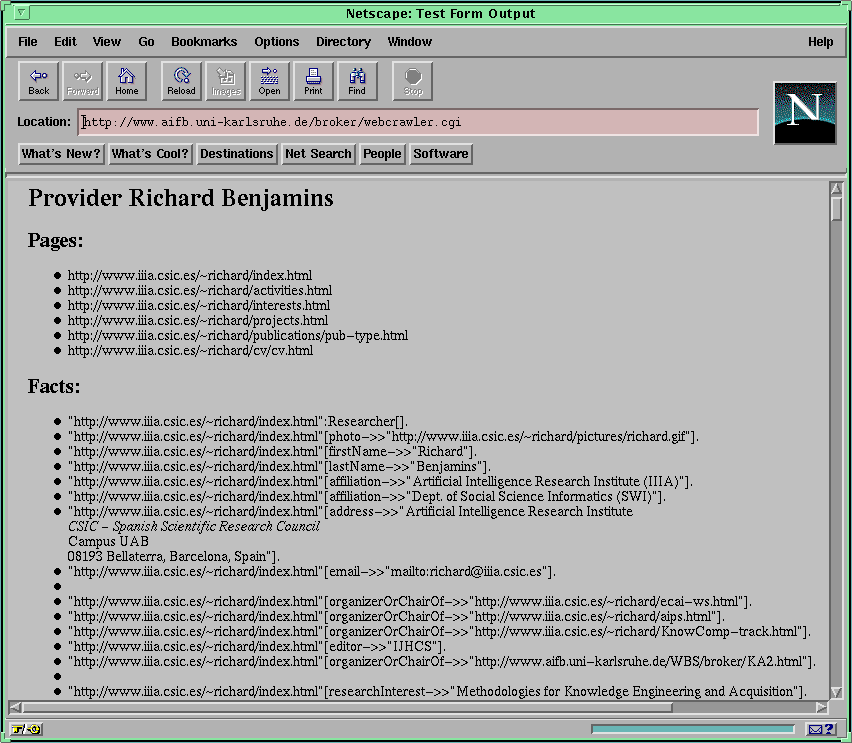
We have to do the following: at first, we have to select a variable from the choice menu directly below the label "Object". This is a place marker for the ObjectID. The next step is to select an appropriate class from the hyperbolic ontology view ( Figure 5 ). Because the user ideally selects the most specific class describing the real world person "Benjamins" (because this allows using more attributes) we navigate through the ontology part describing persons. This is done by simply clicking on one concept and dragging it to another location inside the surrounding circle. The rest of the hierarchy is drawn according to the new position of the dragged node (see Figure 6 ).The most specific class describing Richard Benjamins is "Researcher". Therefore we just click on the circle containing the string "Researcher". In the query window the string "Researcher" appears in the class section and all its attributes are available for selecting in the attribute choice menu.
Fig.6: Hyperbolic Ontology View after some Navigation (larger image)
For determination of the object id of the Researcher with last name "Benjamins" the user has to select the attribute "lastName"
Fig.:7 Main Applet Window with Attribute Menu (larger image)
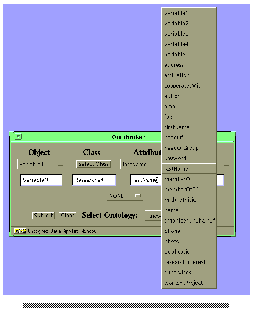
out of the list of all available attributes, which are determined through the selected class. The last action he has to do is just to fill in the name "Benjamins" to the field value, because this is the value of the attribute "lastName" of the object we are interested in. Furthermore the user wants to ask for the email-address of this researcher, that means he wants to ask for another attribute value. Because the current interface supports only one attribute-value pair of objects, we need to enlarge the query. This is done by selecting an operator from the choice menu in the center of the applet window (with the label "NONE"). I
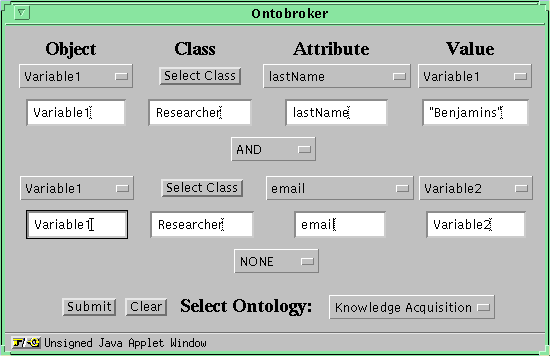
We select "AND" because we are looking for the email address of the same researcher. After selecting the appropriate connector the window is enlarged and provides an additional row. In this row the information has to be provided. That is, at first for the contents of the "Object" column of the second row the same variable as for the first row has to be selected, because we are querying the same object. Furthermore, to have the attributes available in a way that we can select an appropriate attribute, we also select the class "Researcher" in the Hyperbolic Ontology View. Because we want to know the value of the attribute "email" we select this attribute in the attributes choice menu. And at last we have to select a new variable for the value slot of the second row.
Fig.8: Main Applet Window with Connector Menu (larger image)
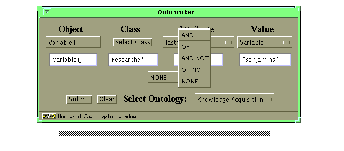
After providing the necessary information the interface should look like Figure 9 .
Fig.9: Main Window with complete query (larger image)
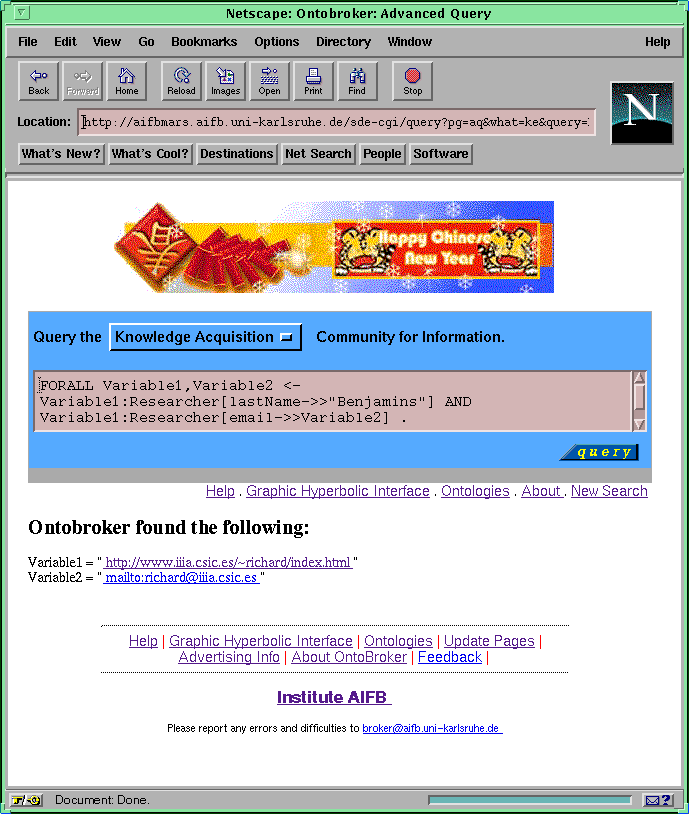
By pressing the "Submit"-button a textual query is generated and submitted to the query engine, which shows the textual version of the query and the computed answer (see Figure 10 ).
Fig.10: Text interface with generated query and answer(larger image)
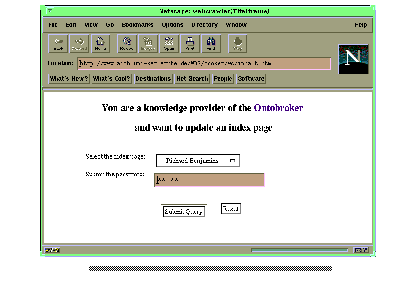
The information that can be queried with the techniques described above has to be provided to the system somehow. To become a knowledge provider one first has to perform the following steps.
Fig 11 Example of an index file
Fig.12:WWW interface for updating provided information (larger image)
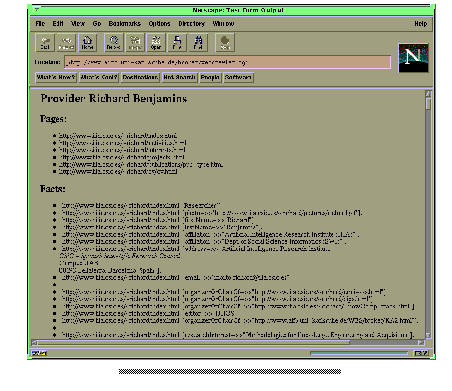
Fig.13:Facts extracted by Ontobroker`s web crawler (larger image)
Knowledge contained in the WWW is generally formulated using the Hyper-Text Mark-up Language (HTML). Therefore, we developed an extension of the HTML syntax to enable the ontological annotation of web pages. We will only provide the general idea here (see [Ontobroker] for more details).
The idea behind our approach is to take HTML as a starting point and to add only few ontologically relevant tags. With these minor changes to the original HTML pages the knowledge contained in the page is annotated and made accessible as facts to the Ontobroker . This approach allows the knowledge providers to annotate their web pages gradually, i.e. they do not have to completely formalize the knowledge contained therein. Further, the pages remain readable by standard browsers like Netscape Navigator or MS Explorer. Thus there is no need to keep several different sources up-to-date and consistent, reducing development as well as maintenance efforts considerably. All factual ontological information is contained in the HTML page itself.
The annotation should follow a given ontology (cf. Figure 14 ). The ontology contains classes, their attributes and relationships between different classes. The ontology also contains rules to deduce new knowledge based on the given input.
Fig.14:Subset of Ontobroker`s underlying ontology
According to the ontology, the web pages can be annotated with three different epistemological primitives:
All three kinds are expressed using an extended version of the frequent HTML anchor tag:
To
demonstrate the annotation of an HTML page we will take the
real home page of a person and add ontological
information to
it. The top of the page is depicted in Figure 16 . The HTML code of this portion of
the page is listed below (cf.
Figure 17 ).
The first thing we will annotate is the instance
relationship
between the page and the class Researcher . This is achieved by stating
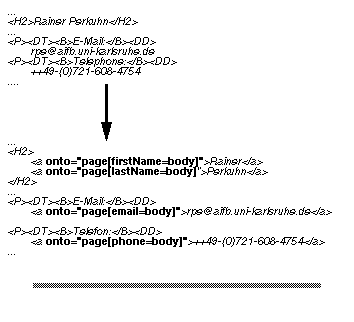
Fig.15:Annotation of the researcher`s name, email and phone number
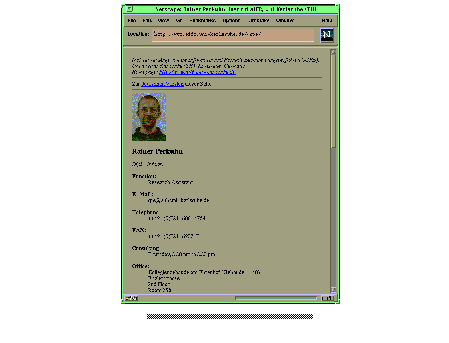
Fig.16:Top of a researcher`s homepage (original homepage)
Fig.17: Original HTML code of a researcher`s home page
<a onto="page:Researcher"> </a>
on the page. Doing so, we create a new object of type Researcher . The object is accessible via its URL, thus the URL of the homepage is of type Researcher . Since all classes and objects can be characterized with attributes we can define values for attributes of the newly defined object. The attributes that can be used should be taken from the ontology. Because Researcher is a sub-sub-sub-class of Person each Researcher has the attributes firstName and lastName . The values of these attributes occur on the home page and can be used to define a part of the formal knowledge base. We alter the HTML code by adding a few keywords that let the parser locate the annotated information. In the same way information like email, phone number etc. can be defined (cf. Figure 15 ). The keyword body instructs the parser to get the values from the HTML text occurring between the <a ...> and </a> tags .
The given examples related an object with atomic values, i.e. a character string occurring on a web page. But other objects are also allowed as attribute values. The following annotation defines the affiliation attribute of the object denoted by the URL of the current page and takes the value from the anchor-tag`s href -attribute, that refers to another object, namely the institute where the researcher works.
<A onto="page[affiliation=href]" href="http://www.aifb.uni-karlsruhe.de/">http://www.aifb.uni-karlsruhe.de
If the institute`s home page is not annotated with ontological information Ontobroker normally has no information about this object. Due to rules specified in the ontology the inference engine of Ontobroker nevertheless deduces that this newly introduced object ( "http://www.aifb.uni-karlsruhe.de/" ) must be of class Organization (cf. last rule in Figure 14 ) and thus creates new knowledge not explicitly mentioned before.
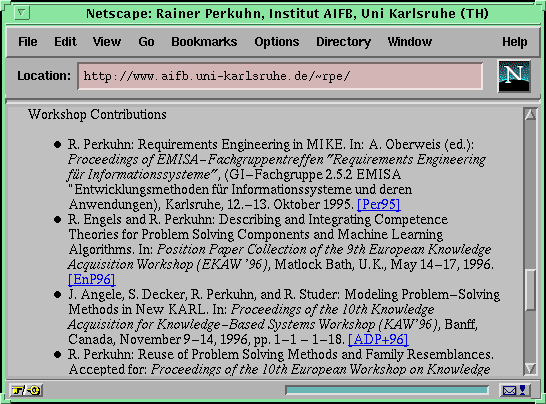
Up to now all information was related to an object depicted by a complete web page. Additionally, the annotation formalism of Ontobroker allows to define namedportions of web pages as objects, or to define any entity that can be addressed via an URL as an object. An example for the former case are publications that are normally listed on a person`s home page or collected on a special publication page, that contains several individual publications. Our colleague also lists some publications on his home page (cf. Figure 18 ). The HTML code that is used to describe the publication together with necessary ontological annotations is given in Figure 19 .
Fig.18:List of publications on a researcher`s homepage (larger image)
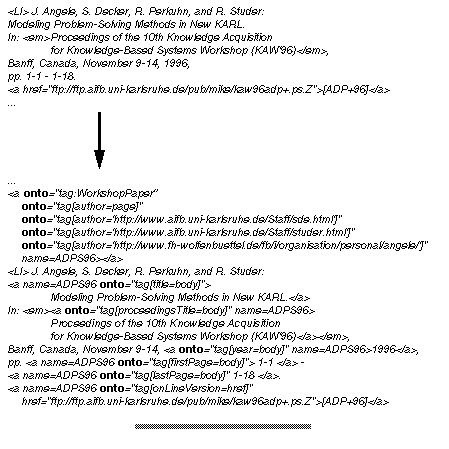
Fig.19:Annotation of a publication objec
As we can see in Figure 19 we create a new object with the statement
<a onto="tag:WorkshopPaper" ... name = ADPS96 >
This statement tells the parser to create an instance of class WorkshopPaper . The keyword tag tells him to use as object identifier the URL of the currently processed web page with a "#" character and the name of the current tag (i.e. ADPS96 ) appended. Thus the defined objects is accessible by a unique identifier. The following onto-statement defines attribute values for this newly created object of class WorkshopPaper , a sub-sub-class of Publication . In this example the tight integration of ontological annotations and actual HTML text can be seen. Because the relevant information is already present on the web page the annotations only have to define the semantics of the texts according to the ontology, e.g. that "Modeling Problem-Solving Methods in New KARL" is the title of the Paper . This semantical annotations allow for concrete queries as demonstrated in earlier sections.
We presented a couple of tools and techniques that enhance query and inference services of the WWW. An ontology is used to define the semantics of information that is presented in natural language structured by HTML and enriched by graphics, movies and further audiovisual information. Therefore, information can be annotated by semantical information that enables informed query answering support. In addition, Ontobroker can derive new facts from the ontology and the available facts. There are recent trends like Resource Description Framework (RDF) [RDF] to enrich web documents by meta information to provide better access for automatic search agents and human users. We will provide a translation service into RDF as soon as it will be established as a standard by the W3C. More details and comparisons with other approaches can be found in [Fensel et al, 1998a] and [Fensel et al, 1998b] .
Acknowledgements. We thank Richard Benjamins and Rainer Perkuhn for their annotated and raw HTML pages that served as illustrative examples. Special thanks to Jürgen Angele who co-developed the evaluation engine that is used by Ontobroker .
[Fensel et al, 1998a] Dieter Fensel, Stefan Decker, Michael Erdmann, and Rudi Studer: Ontobroker: How to make the WWW Intelligent, research report, Institute AIFB. In: Proceedings of the 11th Banff Knowledge Acquisition for Knowledge-Based System Workshop (KAW98), Banff, Canada, April 1998. A short version is available in HTML through [Ontobroker].
[Fensel et al, 1998b] Dieter Fensel, Stefan Decker, Michael Erdmann, and Rudi Studer: Ontobroker: The Very High Idea. In Proceedings of the 11th International Flairs Conference (FLAIRS-98) , Sanibal Island, Florida, May 1998. Available through: [Ontobroker]
[Ontobroker] http://www.aifb.uni-karlsruhe .de/WBS/broker
[RDF] Resource Description Framework, http://www.w3.org/TR/WD-rdf-syntax .
1.The hyperbolic ontology view is based on a Java-profiler written by Vladimir Bulatov and available on http://www.physics.or st.edu/~bulatov/HyperProf/index.html.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}