|
|
Classification is one of the best understood problem classes of
expert systems and there are a variety of problem solving methods
as well as high level tools (Puppe 1993; Breuker & van de
Velde, 1994; Benjamins, 1995). The major problem for building
classification systems is therefore not usually the creation of
a new method, but the acquisition and formalisation of the domain
knowledge and the verification of the knowledge base. This paper
reports on our experiences in the process of knowledge engineering,
on the resulting knowledge based system, and the problems encountered
while taking part in the Sisyphus III experiment. Sisyphus III
is a knowledge engineering experiment designed for the domain
of igneous rock classification with a given set of knowledge sources
made available through the World Wide Web (Shadbolt et al., 1996).
The knowledge bases were constructed using the classification
shell kit D3 (Puppe et al., 1996; Puppe, 1998) for coding. While
the formalisation of relational knowledge was straightforward
with the graphical knowledge acquisition tool CLASSIKA (Gappa,
1993; Gappa, 1995), the major difficulties in knowledge engineering
were the suboptimal knowledge material, problems with feature
recognition as well as the lack of applicable cases and evaluation
facilities.
The Sisyphus experiments of the knowledge acquisition community are an attempt at comparing and contrasting different methods and techniques used in the construction of knowledge-based systems. They are characterised by a common task that is solved by various groups of knowledge engineering scientists. Sisyphus III's task was to build a knowledge base for the identification of igneous rocks. The task description and knowledge sources were prepared and made available via the World Wide Web by Nigel Shadbolt´s group at the University of Nottingham (Shadbolt et al., 1996). The common knowledge material consisted of:
The system to be constructed was supposed to act as a tutorial
aid and diagnostic decision support system for trainee astronauts.
It should be used in conjunction with hand specimens, hand lens
and thin sections. The knowledge base should cover 16 igneous
rock types at the end of the first stage of the experiment (as
opposed to sedimentary or metamorphic ones). This paper is based
on the first phase only.
Other than in prior experiments, the main focus of the experiment
was not only the knowledge acquisition techniques and the resulting
knowledge bases, but especially the process of knowledge acquisition
and engineering. The criteria named by the organisers for comparative
evaluation are efficiency, accuracy, completeness, adaptability,
reusability and traceability. Prerequisites for process evaluation
are the recording of the individual knowledge acquisition activities
and of the intermediate results as well as the resources of time
and material spent. The economic model was based on person days
with a maximal budget of 120 days. In a second phase of the experiment
the participants are supposed to selectively order additional
knowledge material for an associated price (in person days). It
was announced, that for the third stage, the system's functionality
should be extended for a significant but as yet unknown new requirement.
The authors were interested in the experiment and curious about it because the problem seemed to fit well with their knowledge engineering and tool development background especially in classification problem solving of the past 15 years. Their problem specific tool kit D3 provides a high level graphical knowledge acquisition interface and a variety of well integrated classification methods. The expectation of the authors was that they could fully concentrate on the knowledge acquisition problem and engineering process. Since the authors claim that experts should develop knowledge bases by themselves, they were in particular interested to find out how difficult it was to build up a practicable knowledge base. The authors' main interests were: How expensive or effective is the development of knowledge bases really, what are the problems encountered, how adequate are their methods for the given task, how can the accuracy of a method be evaluated and how can the quality of the product and the process be measured and compared?
In the following we describe our procedure of solving the task
in chronological order. We use "person days" to indicate
the total time spent on the individual activities.
In the beginning, we tried to familiarise ourselves with the domain
by examining the interviews and pictures (two person days) as
we had no prior experience in rock identification. The main focus
in building a mental model of the domain was then identifying
the relevant attributes of the rocks and the relations between
particular features and particular rocks. Using the first structured
interview we listed typical features for 8 of the 16 rocks on
paper and checked them roughly against the card sorts and applicable
repertory grids (half person day). These rock profiles were the
basis for building a first prototype, which was roughly tested
by entering some typical cases (one person day). The prototype
only covered coarse grained rocks and assumed that the minerals
were identified.
Because we had no feeling for the characteristics of the rocks,
we decided to visit the mineralogy museum at the University of
Würzburg (half person day). The visit confirmed the impression
that classifying rocks depends strongly on classifying the various
minerals inside the rock, and that identifying a mineral was a
non-trivial classification problem in itself. Even in a coarse
grained rock it seemed to be difficult to recognise the minerals.
Asking direct questions about the identity of the minerals of
the rock in a knowledge base would only bypass the problem. A
key idea was therefore to solve the multi-classification problem
by building two knowledge bases; one for rock classification and
one for mineral classification. Among other things, the rock classification
knowledge base would ask the user how many different minerals
she can recognise and call the mineral classification knowledge
base for each mineral. This modularization also fits with the
overall knowledge structure as the knowledge for mineral identification
is well separated from the knowledge for rock classification.
Actually, the interviews demonstrated some dependencies, when
the expert suspects a certain rock type and looks for evidence
of expected minerals, but they seemed not strong enough to prevent
the modularization.
For building a first prototype for mineral classification we followed
the same procedure. We extracted mineral profiles from the first
interview and the two mineral repertory grids, and built the mineral
prototype (two person days). Using these prototyping approaches
we obtained good first insights into the task and what the system
was intended to do.
When trying to complete the prototypes we were confronted with
the problem of which features to take because the descriptors
used by the different experts had different levels of detail and
were highly interdependent (e.g. amount of silica vs. brightness).
We also wanted to get at least some practical experience for a
better understanding of the domain and of feature recognition.
So we took some opportunities to collect specimens from the field
and attempted to classify them (one person day). The recognition
of the theoretical features of the material was very puzzling,
however. In addition, many features, e.g. amount of silica or
type and proportions of minerals in the rock, were not easily
determined without special instruments or preparation, such as
chemical analysis and thin sections for microscopic analysis.
Therefore we visited the mineralogy museum for a second time.
Even the mineralogy specialist could not identify all the rocks
that we collected although the usual tools for specimen investigation
were available to him. We concluded that tremendous effort was
required to prepare multimedia-based material to explain to the
user how to recognise the features.
We found one feature that a layman could precisely determine and
use for recognition: the rock density. One must simply weigh the
rock and the water the rock displaces. Reference values for the
various rock types were not mentioned in the interviews, in which
only qualitative values like dense or light were used, but were
given in literature that we looked over for this purpose.
| andesite | dacite | trachyte | rhyolite | basalt | |
| general | volcanic equivalent of diorite (S1)
fine grained equivalent of syenite (S2) a type of basalt (S5) | less silica, less quartz than rhyolite (S1)
a type of granite, opposite to a basalt (S3) | more alkaline than dacite and rhyodacite (S1)
very similar to andesite (S3) a type of basalt (S5) | volcanic (S1), fine grained (S2), lava (S3) equivalent of a granite
same color (S2) a type of basalt (S5) | fine grained equivalent of gabbro (S1)
not alkaline, rather calium rich (S1) one of the commonest rocks on earth (S4) |
| minerals and chemistry | |||||
| - quartz | possibly (C1)
could have a bit (S1) < 10% (C4) no (C3) | quartz (C3)
possibly (C1) < 10% (C4) high quartz content (S3) | possibly (C1)
no (C3) 10% (>10%) (C4) | quartz (C3, S4, L2)
always (C1) 10% (>10%) (C4) | possibly (C1)
not so much (S3) no essential (C4) no (C3, L1) quartz-free (S5) no, usually (L3) |
| - feldspar | feldspars (S1, S4, C3, G1)
> 2/3 (C4) plagioclase essential (S2) | feldspars (S1, S3, C3, G1)
> 2/3 (C4) | feldspars (C3, C4, G1)
potassium rich feldspars (S1) | feldspar (C3, C4, G1, S4, S5, L2) | feldspars (C4, G1, S3)
plagioclase feldspar (S1, L1, L2) plagioclase essential (S2) |
| --- orthoclase versus plagioclase
proportion | andesine? plagioclase essential (S2)
> 2/3 plagioclase (C3) > 2/3 orthoclase (C4) color of feldspar mainly pink (C4) slightly more plagioclase (G1) high proportion of plagioclase (S4) a large percentage of calcium plagioclase (andosite?) rather than sodium plagioclase (oldite?) (L3) | plagioclase (L3) plagioclase feldspar (quite a lot) with the odd alkali feldspar
(S1) > 2/3 plagioclase (C3, C4) slightly more plagioclase (G1) color of feldspar mainly white (C4) plagioclase near 100% calcium relative to sodium (S5) | plagioclase (L3˜)
potassium rich feldspars (S1) > 2/3 orthoclase (C3, C4) slightly higher percentage of feldspar alkali (G1) | plagioclase (L3˜)
> 2/3 orthoclase (C3) > 2/3 plagioclase (C4) high percentage of feldspar alkali (G1) the two feldspars (S4) plagioclase (S5) ortho-, alkali feldspar (L2) | plagioclase (L3)
plagioclase feldspar (S1, L1, L2) plagioclase essential (S2) higher percentage of plagioclase (G1) - (C3, C4) plagioclase about 30% calcium relative to sodium (S5) in psolliodtic basalts: potassium feldspar (L3) |
| - pyroxene | pyroxene (L3)
a few (S1) very rich (G2) | odd pyroxene (might have) (S1)
pyroxene (L3) poor or none (G2) | pyroxene (L3)
poor or none (G2) | pyroxene (L3)
poor or none (G2) | proxene (C4, S4, L3)
dark green black pyroxene (S1) essential (S2) definitely (S3) poor or none (G2) clinopyroxene (L1, L2) |
| - olivine | olivine (C2)
never (C1) - (C3) unlikely (<-> likely) (C5) poor (G2) | never (C1)
no (C2) - (C3) unlikely (<-> likely) (C5) poor or none (G2) | never (C1)
no (C2) - (C3) unlikely (<-> likely) (C5) poor or none (G2) | never (C1)
no (C2) - (C3) unlikely (<-> likely) (C5) poor or none (G2) | olivine (C2, L2)
possibly (C1, S2) < 20% (C3) likely (<-> unlikely) (C5) rich (G2) bit of (L1) some basalts contain olivine (L3) |
| - mica, biotite | mica likely (<-> unlikely) (C5)
biotite medium (G2) | mica unlikely (<-> likely) (C5)
biotite poor or none (G2) | mica likely (<-> unlikely) (C5)
biotite poor or none (G2) | mica (S4)
mica unlikely (<-> likely) (C5) biotite poor or none (G2) muscovite (L2) | some micas possibly (S2)
biotite poor or none (G2) |
| - feldsparthoid | never (C2) | may have (C2) | never (C2)
the odd feldsparthoid (possibly, a few) (S1) | never (C2) | never (C2) |
| - amphibole | the odd amphibole (perhaps) (S1)
hornblende essential (S2) | perhaps a few | it´s a hydrous rock, so it would have amphibole in it (= hydrous form of a pyroxene)(S5) | amphibole possibly (S2)
hornblende (L2) | |
| - intersertial glass | intersertial glass (S1) | all volcanics? (S1) | all volcanics? (S1) | intersertial glass, a significant proportion of the rock (S1) | intersertial glass (S1)
plagioclase glass in them (S5) some glass in it, probably (L1) |
| silica | < 68% (C1)
45-52% (C2) > 70% (very high) (C5) medium (G1) | about 68% (C1)
52-65% (C2) high silica content (S3) > 70% (very high) (C5) high (G1) | < 68% (C1)
> 65% (C2) > 70% (very high) (C5) slightly higher than lower (G1) | > 68% (C1)
> 65% (C2) > 70% (very high) (C5) high (G1) | low (S1)
< 68% (C1) 45-52% (C2) 50-60% (C5) low (G1) undersaturated (L1) |
| calcium + potassium | high (8-15%) (C2)
calcium-rich (L3) | high (8-15%) (C2)
plagioclase near 100% calcium relative to sodium (S5) calcium-rich (L3) | medium (5-8%) (C2)
calcium-rich (L3) | high (8-15%) (C2)
calcium-rich (L3) | high (8-15%) (C2)
calcium-poor (L3) in psolliodtic basalts: potassium feldspar (L3) |
| iron + magnesium | 10-15% (intermediate) iron (C2) | 10-15% (intermediate) iron (C2) | 10-15% (intermediate) iron (C2) | <10% (low) iron (C2) | 10-15% (intermediate) iron (C2)
high percentage of irons and magnesiums (S3), ferro-magnesium minerals (S4) |
| acidity | intermediate (S2, S3, S4) | acidic (S3, S4) | basic (S3, S4, S5, C4, C5, L1) | ||
| appearance ... | |||||
Figure 1. Comparison of
statements from different knowledge sources (indicated in brackets;
S = Structured Interview, L = Laddered Grid, C = Card Sort, G
= Repertory Grid; C2 stands for Card Sort 2).
After the first prototypical phases we tried to follow a more
systematic approach for improving the knowledge bases. In order
to combine the information of the various knowledge sources into
a consistent domain model, it was necessary to identify the similarities
and differences between the individual expert statements. This
information was extracted from the transcripts and organised in
tables. One table type was used for rocks and another for minerals
each listing all criteria mentioned. The statements from the various
knowledge sources corresponding to each criterion were compared
to each other (see Figure 2 for an example part). Further relationships
from various sources, e.g. relationships between rock characteristics,
explanations of how rocks are formed, or summaries with definitions
were also used as intermediate representations on the way to forming
a domain model (theory).
This activity turned out to be rather tedious (five person days
without finishing) especially because we had no appropriate tool
support. A tool for marking text statements and building table
entries from them was desirable. For example, when a criterion
is divided in two it would be very helpful to be able to quickly
trace back to the original text source. Although tools using hypertext
methods for knowledge acquisition do exist (e.g. (Maurer, 1993)),
they were not available to us, and so we could not assess their
usefulness.
A common systematic or a reference point was missing for the analysis
of the material. Without it the individual statements, terminologies
and relationships could hardly be transformed into a consistent
theory. The problem probably could have been solved by using an
appropriate book. However one of the authors objected that the
experiment would be distorted, because it might have been sufficient
to simply use the classification scheme from the book for the
knowledge base. We suspected that the use of such classification
schemes, which have been optimised by experts in the field, would
be of considerably higher quality than anything which we as layman
could do, especially with our limited investment of time and the
material. On the other hand, we would not have learned very much
from it, and the situation of having a wealth of good literature
available is also rather untypical in many classification domains
(like e.g. fault finding in technical domains). So we continued
building the knowledge base based exclusively on the prepared
material. We missed the opportunity to ask the experts about differences
or contradictions between the statements and had to decide by
ourselves, what seemed most plausible.
For the completion of the rock classification prototype (two person
days) we decided to avoid using descriptors which seemed to be
too for laymen. It was restructured and adapted with respect to
feature recognition, although it was clear, that we were unable
to solve this problem in a satisfactory way.
Improving the mineral classification analysing the plain and cross-polarised
images of the minerals and correlating the images to the descriptions
of the self reports appeared to be an excessive additional activity.
Without thin sections and a microscope a text and picture analysis
could only result in theoretical features. We decided not to further
refine the mineral prototype because the mineral classification
in the interviews depended so strongly on microscopic images.
We could not evaluate the knowledge base despite our continual
desire to do so because feature recognition problems prevented
the acquisition of useful cases: If the features in the example
cases had been correctly described, it would have been quite easy
to classify a rock or at least to determine a group of similar
rocks. The overall vagueness resulted from the inherent vagueness
in describing the features. The database of rocks given in the
problem description was considered inadequate by the authors because
it was based on chemical analysis and contained a list of places,
both of which are useless for the intended application. Because
we were also not able to construct adequate test situations by
ourselves, we were not really able to evaluate our work.
We subsequently spent some time understanding the domain (about
three person days), studying self reports, perusing various books
and trying to classify features and rocks, but this did not result
in further refinements of the prototypes. So altogether we spent
about 17 person days on the Sisyphus experiment. We did not further
elaborate the work on Sisyphus III because of basic uncertainties
about the applicability of the system. Due to the unclarity in
feature recognition and the unavailability of useful cases it
was not clear how a system of reasonable quality could be built.
So we did not make any expensive investments, such as supporting
microscopic investigations or adding tutorial aids.
While the acquisition and evaluation of the knowledge was a major
problem, coding the knowledge with the shell kit D3 was very easy
due to its comfortable graphic knowledge editors. So when we built
the rock and mineral prototypes, we mostly entered the different
knowledge types in parallel and built a heuristic, set-covering
and case-based knowledge base. We did this although we preferred
the set covering approach from the beginning, because rocks can
be most natural described by a list of typical features where
typicality or frequency information can be added if available.
| Activities | Person days spent |
| reading | |
| first prototype for coarse grained rocks
(based on structured interview1, card sorts and appropriate repertory grids) | |
| visit of mineralogy museum | |
| first prototype for mineral identification
(based on structured interview1, card sorts and appropriate repertory grids) | |
| practical attempt of rock classification | |
| more systematic analysis of the knowledge sources (similarities and differences) | |
| improvement of rock prototype | |
| further activities in understanding the domain | |
| sum |
Figure 2. Activities and
time spent on Sisyphus III experiment.
In the next section we show screen shots of the knowledge bases,
so that the reader can see the aspects of the knowledge representation
of D3 relevant to our solution for the rock classification domain.
The general knowledge representation capabilities of D3 are much
more sophisticated. A detailed description of the knowledge representation
of D3 can be found in the literature (Puppe et al., 1996).
Since it is difficult to describe several knowledge bases (set-covering,
heuristic, case-based) in a few pages, we present a representative
selection of them with hardcopies or - if a hardcopy would consume
too much space - with an equivalent textual description. Figure
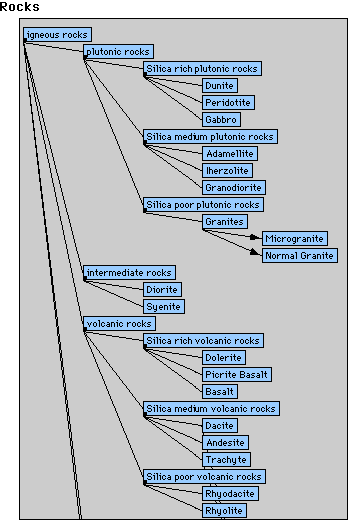
3 and Figure 4 show the complete domain ontology of the two knowledge
bases for rock and mineral classification. They cover the hierarchically
arranged diagnoses and the questionnaires with the observations
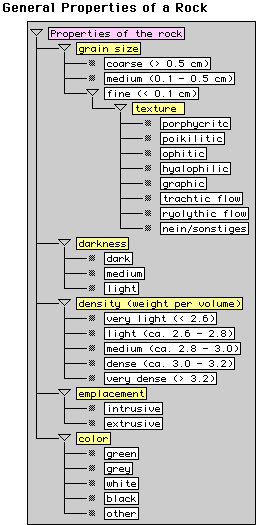
(symptoms) and their value ranges. Some questionnaires contain
follow-up questions, e.g. the questionnaire "properties of
the rock" in Figure 3 top-right contains a question "grain
size" with the value range "coarse", "medium",
and "fine", where the latter value leads to a follow-up
question about "texture" (on the screen marked with
different colours). The mineral classification knowledge base
currently does not include the analysis of thin sections. The
part of the rock classification questionnaire that concerns the
identity of minerals can automatically be answered from the results
of the mineral classification knowledge base. The rules necessary
for converting the terminology are shown in the top-right part
of Figure 4.
Examples for heuristic, set-covering and case-based knowledge
for classifying (normal) granite are shown in Figure 5. The heuristic
knowledge (upper part) consists of simple relations for how much
the presence or absence of certain features increase or decrease
the evidence for a rock. The evidence categories p1 - p7 and n1-
n7 have a simple semantics: p means positive and n negative; the
higher the number, the stronger the evidence; and the combination
of two evidence items from one category equal the evidence of
the next higher category (e.g. p3 + p3 = p4). If the total evidence
is at least p3, the diagnosis will be suspected and if it is more
than p5, the diagnosis will be probable.
The set covering knowledge (Figure 5, middle part) consists of
simple relations stating the properties of typical granites. The
typicality of a feature is rated with a p-number (higher number
denote higher typicality). This knowledge is rather easy to acquire.
However, it is more difficult to interpret: For a new case, the
problem-solver rates a diagnosis on how well it can explain (cover)
the features observed in a rock. Since usually not all features
are of equal importance, the expert can also enter different weights
for the symptoms (Figure 5, lower part, column "weight")
and for their values (not shown in Figure 5).
The case-based knowledge base (Figure 5, lower part) contains
information about the weight and partial similarity of each symptom.
The weight denotes the overall importance of the symptom compared
to other symptoms and is also used in set covering classification
(see above). Since a symptom may be of different importance for
different diagnoses, the weight can be modified for a particular
diagnosis (this mechanism has not been used in the knowledge bases).
The partial similarity describes how similar the various values
of a symptom are. The options used here are "individual",
where all values are completely different, "equidistant"
for scaled values, where the similarity of two values is proportional
to their distance on the scale and "matrix", where the
similarity between each possible pair of values is explicitly
defined by the expert. In order to find a known case that is similar
to the new case, the partial similarities of all corresponding
features are computed and summed up according to their weights.
The solution of the known case with the highest similarity is
transferred to the new case.
The last two figures (Figures 6 and 7) show how this knowledge
is applied to a new case. The upper part of Figure 6 lists the
relevant values of the chosen example case for the rock classification
knowledge and the lower part shows the results by the heuristic,
set-covering and case-based problem solvers, which were configured
to run in parallel. The justification of the results are shown
in Figure 7.
The heuristic justification of the diagnosis "granite"
is simply the list of all applicable rules concluding the diagnosis
(upper part of Figure 7). The top 10 lines say in essence that
there is considerable positive evidence (105 points) and no negative
evidence (0 points). The following list states all rules contributing
to the positive evidence (where p2 = 5 , p3 = 10, p4 = 20 and
p5 = 40 points).
The set-covering justification (middle part of Figure 7) shows
a list of symptoms and how well they are explained by the top
3 diagnoses. The first column of the table lists the symptoms,
the second the "weight" of these symptoms. The next
three columns show how well the three diagnoses can explain the
symptoms. Empty boxes indicate that the diagnosis does not cover
that symptom. If a diagnosis covers a symptom, the number in parenthesis
indicates how typical that symptom is for that diagnosis with
respect to its weight .
The case-based justification (lower part of Figure 7) compares the actual case (column "value of current case") with the most similar known case (Column "value of known case") and rates how important each attribute is and how similar the respective values are (column "similarity"). This last column has three subcolumns denoting the actual points in percentage of the maximal weight ("value = % of max"). A "-" denotes that at least one value is "unknown" and yields a small malus.
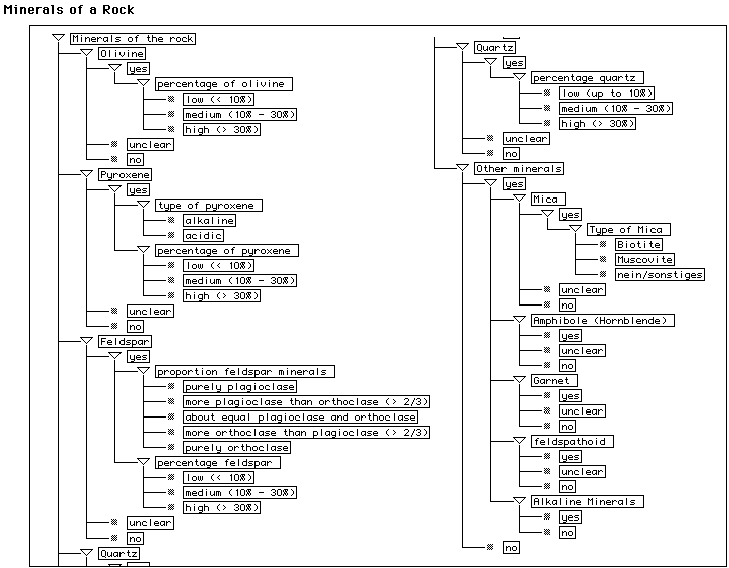
Figure 3. Rocks (top left) and questionnaires for general properties (top right) and minerals of rocks (bottom) (taken from the rock knowledge base).
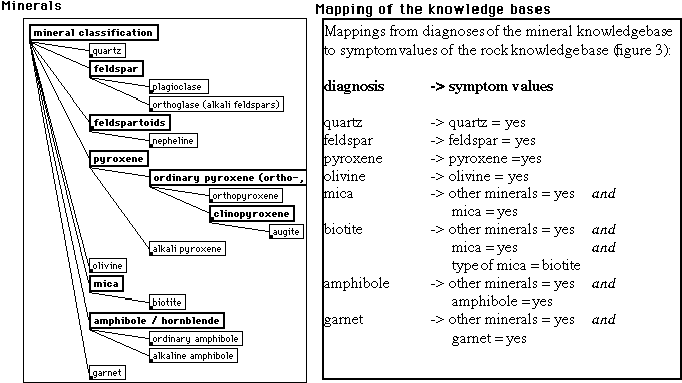
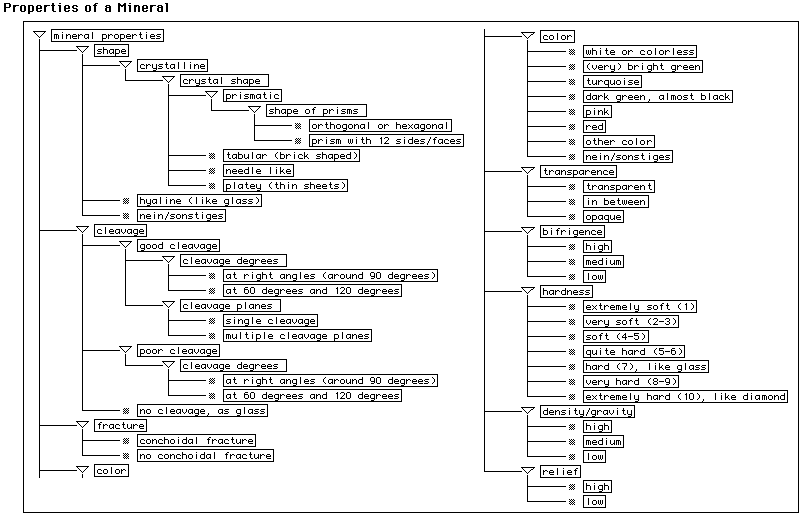
Figure 4. Minerals (top-right), mapping rules for connecting the mineral diagnoses to symptom values of the rock questionnaire (bottom-left), and questionnaire for general properties of minerals (top) (taken from the mineral knowledge base).
Heuristic rules for inferring Granites
------------------------------------------------------ then increase (p) or decrease (n) evidence of granites by
| If | darkness = light | p4 | ||
| if | density (weight per volume) = very light (< 2.6) | n3 | ||
| if | density (weight per volume) = light (2.6 - 2.8) | p4 | ||
| if | density (weight per volume) = medium (2.8 - 3.0) | n3 | ||
| if | density (weight per volume) = dense (3.0 - 3.2) | n5 | ||
| if | density (weight per volume) = very dense (> 3.2) | n6 | ||
| if | color = white | p2 | ||
| if | Olivine = no | p3 | else (yes) | n5 |
| if | Pyroxene = no | p3 | else (yes) | n3 |
| if | Feldspar = yes | p3 | else (no) | n5 |
| if | Proportion of feldspar minerals = about equal plagioclase | |||
| if | and orthoclase or more plagioclase than orthoclase | p3 | ||
| if | percentage feldspar = medium (10% - 30%) or high (> 30%) | p3 | else (low) | n5 |
| if | quartz = yes | p3 | else (no) | n5 |
| if | percentage quartz = medium (10% - 30%) or high (> 30 %) | p3 | else (low) | n5 |
| if | Mica = yes | p3 | else (no) | n5 |
if granites = probable and grain size = coarse then increase evidence of normal granites by p6
Set covering rules for inferring Granites
properties of granites with typicality values (from p7 = typical to p1 = rarely):
| darkness = light | p7 |
| density (weight per volume) = light (2.6 - 2.8) | p7 |
| color = white | p5 |
| Olivine = no | p7 |
| Pyroxene = no | p7 |
| Feldspar = yes | p6 |
| Proportion of feldspar minerals = about equal plagioclase and orthoclase | |
| or more plagioclase than orthoclase | p6 |
| percentage feldspar = medium (10% - 30%) | p5 |
| percentage feldspar = high (> 30%) | p6 |
| quartz = yes | p7 |
| percentage quartz = high (> 30%) | p6 |
| percentage quartz = medium (10% - 30%) | p5 |
| Mica = yes | p7 |
Part of general similarity knowledge
| symptom | similarity type | partial similarity | weight |
| grain size | scaled | equidistant | g5 (important) |
| texture | individual | - | g5 |
| darkness | scaled | equidistant | g3 (not so important) |
| density | scaled | equidistant | g5 |
| color | matrix | see table below | g2 (relatively unimportant) |
---------------------------- 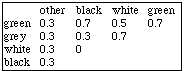
Figure 5. Parts of the
heuristic (top), set covering (middle) for inferring granites.
Part of the similarity knowledge (bottom) is also used for set
covering classification (the weights of symptoms).
Data from an example case (results below)
| Questionnaire Properties of the rock: | - |
| grain size: | coarse (> 0.5 cm) |
| darkness: | light |
| density (weight per volume): | light (ca. 2.6 - 2.8) |
| colour: | white |
| Questionnaire Minerals of the rock: | - |
| Olivine: | no |
| Pyroxene: | no |
| Feldspar: | yes |
| proportion feldspar minerals: | about equal plagioclase and orthoclase |
| percentage feldspar: | high (> 30%) |
| Quartz: | yes |
| percentage quartz: | high (> 30%) |
| other minerals: | yes |
| Mica: | yes |
| Amphibole: | no |
| Alkaline Minerals: | no |
| Garnet: | no |
| feldspathoid: | no |
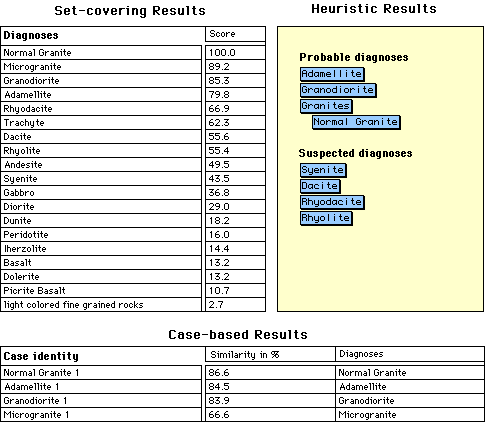
Figure 6. Results of the set-covering, heuristic, and case-based knowledge base for the case data presented above. The set-covering expert has derived one diagnosis ("Normal granite") which can explain 100% of the features, the heuristic expert has three probable diagnoses (adamellite, granodiorite and normal granite) and several suspected diagnoses and the case based expert found a very similar (86,6%) known case with the name ("case identity") "Normal granite 1" and the diagnosis "Normal granite". For explanation of the results see Figure 7.
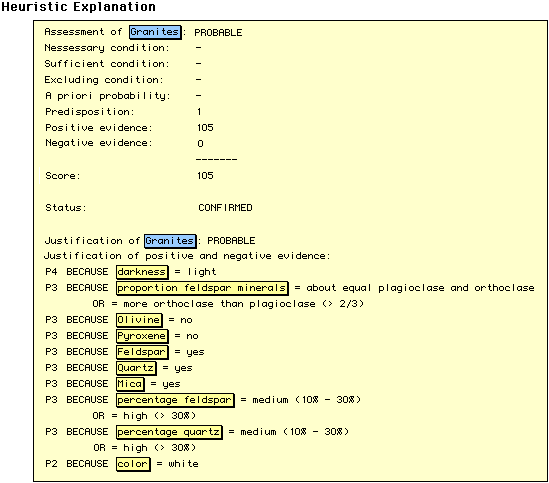
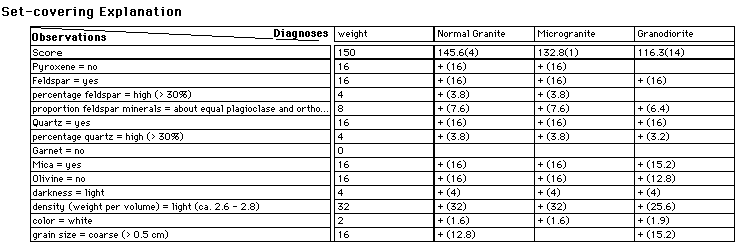

Figure 7. Explanations for heuristic (top), set-covering (middle) and case-based (bottom) results.
Some experiences and observations corresponded approximately to
the expectations of the authors. Others occurred rather unexpectedly
and can be explained by the experiment's setting. The latter are
discussed in Chapter 6.
With regard to the procedure of knowledge base construction and
of the appropriateness of the methods, techniques and tool used,
we made the following experiences.
Method and Tool Assessment. It was easy to use the implemented
models of classification problem solving in D3 and to instantiate
them with the knowledge of the domain. Having the D3 models in
mind, the authors knew very well what they were looking for in
the domain, e.g. classification objects, object properties, relations
between objects and properties, cases, etc. With the hypertext
features of D3, the rock photos and microscope images could easily
be included and linked to the corresponding entities of the formalised
part of the knowledge base. It would also be possible to draw
links to other knowledge sources in this way, such as interview
texts and repertory grids. Although it seemed obvious that the
set covering model was the most appropriate one, it was easy to
add heuristic knowledge and similarity measures for case based
classification. Due to the lack of cases, the respective strengths
and weaknesses and, in particular, possible synergy effects could
not be evaluated.
Aspect: Modularization. An interesting aspect of the problem
was the multi-classification task for a rock and each of its minerals.
The authors solved it by building two separate knowledge bases
using the new D3 component Coop-D3 (Bamberger, 1997) for their
cooperation. Coop-D3 is designed for distributed problem solving,
where different agents (knowledge bases) can call each other with
various types of requests. For the mapping of the terminologies
a knowledge-based mechanism is provided.
Aspect: Conflicting Expert Opinions. An essential knowledge
engineering problem was how to deal with the conflicting knowledge
from the different experts. The authors tried to resolve the differences
based on the consistency and frequency of the different expert
opinions into one authoritative knowledge base. Another approach
(not tried by the authors) would be to build a special knowledge
base for each expert and use the above mentioned tool Coop-D3
for the integration of the respective solutions to an overall
solution. This might be done by a majority vote or - if an assessment
about general or particular competence of the knowledge bases
is available - by a weighted majority vote. In the long run the
weights for the majority vote could be adapted automatically by
learning techniques.
Aspect: Text Analysis. An analysis tool allowing easy link
generation between the knowledge base and items of the original
hypertext documents and supporting different views would have
been very helpful. The hypertext facilities of D3 are not sufficient
for this purpose because they require a domain ontology, which
has yet to be constructed in this process.
With respect to an assessment of the product, we have to point
out that we did not find a basis for the evaluation of the knowledge-based
system. This was also one of the reasons why we did not complete
our work on the knowledge bases. As mentioned earlier, the cases
of the database were not useful for the intended task of the system.
Even worse we were unable to acquire or produce cases ourselves
due to the lack of equipment and the lack of practical experience
and expertise, e.g. in feature recognition. So we could make some
qualitative observations, but could not measure or quantify the
adequacy and quality of the system nor the efficiency of the methods
and procedure.
There were several reasons why the authors felt handicapped in the development of the knowledge base and why they think that the experiment's setting does not sufficiently reflect the knowledge engineering context of the real world. The reasons fall into the following categories:
In real world applications many of these problems are less serious
because a knowledge engineer would have the opportunity to ask
an expert to explain open questions.
The structured interviews and the rock pictures gave a good first
impression of the domain and classification task, but they were
not very helpful for building a complete knowledge base. The pre-structured
representations, i.e. the repertory grids and card sorts, were
relatively useful, mainly because they contained knowledge in
a very compact form and because they were complete although the
scope of rocks and rock characteristics was limited. But they
were contradictory and too skeletal as they contained only 5-10
descriptors. More explanations, further background knowledge and
relationships would have been necessary to make good use of these
representations. The main problem with the self reports, in which
experts think aloud while trying to classify a rock, was lack
of pictures of what an expert was currently talking about. Possible
solutions would be a movie in which an expert points at the minerals,
she is talking about, or at the coloured areas in the microscopic
images. For each rock there were two microscopic images included
in the knowledge source material, one under plain and one under
cross-polarised light, but they were not related to one of the
reports. Annotated links with explanations of these images were
also missing, which makes the reconstruction of the relations
quite laborious.
There is a wealth of literature available for domains of general
interest like rock classification, including well described procedures
for classification at different levels of detail. Especially there
are some popular books about the domain for laymen, e.g. (Schumann,
1997) and (Booth, 1997), which give a good overview and contain
detailed descriptions of each classification object (properties,
pictures) using simplified but systematic categories. For example
the Streckeisen diagram (e.g. in (Schumann, 1993), page 192-194)
is an excellent first order model for classifying igneous rocks.
They make a much better starting point than the interviews and
grids. In addition the general model provided in such a book serves
as a consistent reference point. So if we were free to choose
the material, we would select such classification schemes as starting
points and have experts comment on them.
The task was not very well suited to performance by an expert
system, because the main difficulty is the identification of the
features and less their interpretation. The classification of
rocks is mainly a task of interpreting pictures - pictures of
the rock, of its minerals and of itself under a microscope. As
today the computer technology is barely capable of recognising
for example the characteristics of minerals automatically, recognition
must be done by humans. They could better be supported by a hypermedia
system than by a knowledge-based system, however. In order to
support the intended astronaut trainee in describing rocks correctly,
it would be necessary to add drawings, pictures and texts to the
knowledge base explaining the features that are to be recognised.
This observation is confirmed by a large plant classification
system built by a biologist using D3 (Ernst, 1996). He spent at
least half of his total development time of six months in adding
such kinds of drawings, pictures and texts. In addition, he generated
a training system from the knowledge base and used hypertext documents
in order to train feature recognition (which is supported by D3).
The evaluations showed that the system correctly classified plants
when all features are described correctly, and even with 1-3 misclassified
features (from a total of ca. 40), but was of no real help for
users who were too sloppy in entering data.
Realistic cases are critical to getting feedback on the adequacy
and quality of the knowledge-base. As we mentioned earlier, we
could neither use the cases from the case base with the chemical
composition of rocks nor set up a realistic test environment by
ourselves.
In the conclusions, we speculate, whether the experiment settings
can be improved to allow for the construction of a really useful
knowledge base for helping laymen with rock classification and
how the settings could be improved. First, we make suggestions
how to deal with the three problems mentioned in the last chapter:
Problem of feature recognition: This is the most serious
problem, because it is worthless to build a knowledge base with
unrecognisable features, such as the chemical composition of rocks
from the Streckeisen diagram. The best solution is to have experts
explain how they recognise features with the opportunity to ask
them as many questions as are necessary to gain this ability to
at least a certain degree. If we remain unable to recognise some
of the features, the end-users will probably have similar problems.
In this case a better strategy for solving the task is to use
other, better recognisable features, and, consequently, a more
complex knowledge base structure. Since the experiment did not
allow direct interaction with the experts, the second best way
would be to have pictures of rocks and minerals, in which the
experts annotate what they can identify and why. As a consequence,
the rock identification activity of the self reports in the material
provided should not be based on real rocks, since they cannot
be made available through the internet, but on pictures of them
and maybe some additional parameters, for which recognition is
not the main problem (like e.g. the density of rocks). The related
material would also be a good precondition for providing the necessary
hypertext material for the end users. If it were impossible for
the experts to identify the rocks with the limited raw material
accessible via the internet, the experiment setting should strongly
recommend, for which features the Sisyphus participants need to
get a tuition on real rocks.
Suboptimal knowledge material: In domains such as rock
classification with a wealth of literature, we would recommend
that experts start by choosing their favourite classification
scheme from a book and comment on it. However, this option is
only available for domains with good literature, which is rather
uncommon for typical knowledge engineering tasks. As we know from
our experience with interviewing experts it is extremely difficult
to get experts to describe their classification knowledge clearly.
To resolve contradictions, we suspect that the interviews presented
with all their weaknesses and contradictions are quite typical
- and even of a rather good quality. Therefore, direct interaction
with the experts would be the most important improvement. Although
this is impossible in general, the experts who gave the interviews
for the Sisyphus experiment could perhaps answer email questions
from the participants (the economic model of the experiment might
allow a certain amount of resources for email contact with experts).
Lack of cases: The most obvious solution to the problem
of lack of cases is simply providing a set of useful cases. However,
in domains where feature recognition is a major problem, cases
cannot be constructed before the feature descriptors have been
defined. Therefore, we are faced with a dilemma: If cases are
provided from the beginning, they make the knowledge engineering
task rather trivial, but if there are no cases at all, we have
no opportunity for feedback and evaluation, turning the whole
experiment into a rather theoretical study. A solution might be
to make the self reports sufficiently precise to turn them into
cases. This would be more efficient, if the expert can be asked
by electronic mail, whether they agree on the participant's formal
description of cases.
These suggestions would require considerable amount of work and
expert resources for the organisers of the experiment. Given that
the suggestions were adopted, the participants might still claim
however, that the situation is artificial in comparison to real
knowledge engineering projects. Therefore, we suggest a different
scenario: The organisers of the experiment should only state the
intended goal of the knowledge systems and the evaluation scenario
precisely, and it would be up to the participants to find experts
and and decide how to interact with them. After the deadline,
the participants would send their knowledge systems to the organisers,
who organise their evaluation according to their predefined scenario
and rate the quality of the systems. Similar to the procedure
in the current experiment the overall assessment should take into
account the costs for building the knowledge base, which in turn
requires a detailed log of all activities. To motivate broad participation,
the highest rated systems should be awarded prizes.
An advantage of this scenario would be, that a direct comparison between two alternative knowledge acquisition approaches would be possible:
Most of the problems stated above might disappear in the latter
alternative: Experts have less problems with suboptimal knowledge
material as well as the lack of cases, and we believe that they
have useful strategies to deal with the problem of feature recognition.
Bamberger, S. (1997). Cooperating Diagnostic Expert Systems to
Solve Complex Diagnosis Tasks. Brewka, G., Habel, C., and Nebel,
B. (Eds.), Proceedings of the German Conference on AI, Springer,
Lecture Notes in Artificial Intelligence 1303, 325-336.
Benjamins, R. (1995). Problem-Solving Methods for Diagnosis and
their Role in Knowledge Acquisition, International Journal of
Expert Systems: Research and Application.
Booth, B. (1997). Steine und Mineralien [Rocks and Minerals].
Könemann Köln.
Breuker, J., and van de Velde, W. (eds) (1994). COMMONKADS Library
for Expertise Modelling. IOS Press.
Ernst, R. (1996). Untersuchung verschiedener Problemlösungsmethoden
in einem Experten- und Tutorsystem zur makroskopischen Bestimmung
krautiger Blütenpflanzen [Analysis of various problem solving
methods with an expert and tutoring system for the macroscopic
classification of flowers]. Master thesis in Biology, University
of Würzburg.
Gappa, U., Puppe, F., and Schewe, S. (1993). Graphical knowledge
acquisition for medical diagnostic expert systems. Artificial
Intelligence in Medicine 5, 185-211.
Gappa, U. (1995). Grafische Wissensakquisitionssysteme und ihre
Generierung [Graphical Knowledge Acquisition Systems and Their
Generation], PhD Thesis, Infix, Diski 100.
Maurer, F. (1993). Hypermediabasiertes Knowledge Engineering für
verteilte wissensbasierte Systeme [Hypermedia-based Knowledge
Engineering for Distributed Knowledge-Based Systems], PhD Thesis,
Infix, Diski 48.
Puppe, F. (1993). Systematic Introduction to Expert Systems, Springer.
Puppe, F., Gappa, U., Poeck, K., and Bamberger, S. (1996). Wissensbasierte
Diagnose- und Informationssysteme [Knowledge-based Diagnosis and
Information Systems], Springer.
Puppe, F. (1998). Knowledge Reuse among Diagnostic Problem Solving
Methods in the Shell-Kit D3, KAW-98.
Shadbolt, N., Crow, L., Tennison, J., and Cupit, J. (1996). Sisyphus
III Phase 1 Release. http://www.psyc.nott.ac.uk/aigr/research/ka/SisIII,
22nd November 1996.
Schuhmann, W. (1993). Handbook of Rocks, Minerals and Gemstones.
Houghton Mifflin Company.
Schuhmann, W. (1997). Mineralien, Gesteine - Merkmale, Vorkommen
und Verwendung [Minerals, Rocks - Characteristics, Occurrence
and Use]. München: BLV.