![]()
![]()
{gennari, grosso, musen}@smi.stanford.edu
Stanford Medical Informatics, Stanford University
251 Campus Dr., Stanford, CA 94305-5479
Abstract
To make cost-effective use of a library of reusable
problem-solving methods, developers must be able to quickly find and understand these
methods, so that they can match their problem and knowledge base to a method in the reuse
library. This match includes both finding the method and connecting to that executable
software module via a set of mappings or mediators. To enable this match, builders of a
reuse library must describe each method with a method-description language. We
discuss a number of general desiderata for such a language. Our work focuses on one
feature of the language: a precise specification of the input requirements of the method.
This specification allows developers to correctly match their knowledge base to a
pre-existing problem-solving method by formalizing the requirements of methods in the
library. We propose an ontology for a method-description language, and present example
specifications for two well-known problem-solving methods: propose-and-revise and cover-and-differentiate.
NOTICE: For printing, the authors would prefer that you retrieve and use the PDF format of this paper. Thank you.
For over a decade, researchers in knowledge-based systems have tried to organize, catalogue, index, and collect problem-solving methods into a library that other developers could use (Chandrasekaran, 1986; McDermott, 1988). The expected benefits of such a reuse library would be less development time for knowledge-base engineers and fewer maintenance problems.
Consider the following ideal use scenario: Judy K. Eng has a legacy knowledge base (perhaps a database) of information about some domain. Domain experts have given her a problem to solve, and she realizes that other knowledge-base developers have tackled similar problems (e.g., in diagnosis, or planning, or configuration). Therefore, she goes to the reuse library, searches for, and retrieves an appropriate problem-solving method. After reviewing the requirements of this method, she must do some additional knowledge acquisition to augment her existing knowledge base about the domain. After this step, she is able to use her augmented knowledge base with the retrieved method from the reuse library to solve her problem. Not only does she save effort in development time, but the retrieved method has been well-tested and debugged by others, and its strengths and limitations are already known.
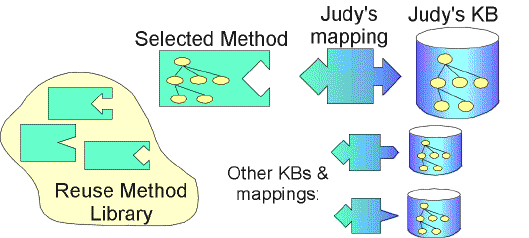
Figure 1. A view of the reuse problem. Judy K. Eng selects a particular method from the library and then needs to build a mapping from her knowledge base to the requirements of that method.
Unfortunately, building a library of methods that supports successful, cost-effective reuse has proved difficult. If we review the scenario with Judy Eng, we can see that she faces two tasks before she can reuse a problem-solving method: (1) she must find an appropriate method from the library, and (2) she must map her knowledge base to the requirements of the method. These are distinct tasks; for example, Benjamins (1995) describes the task of finding an appropriate diagnosis method, with little discussion of the mapping task, while Gennari et al. (1994) discuss mapping relationships without addressing how to index the library of methods for retrieval. We argue that objects in the reuse library be both indexed for retrieval and annotated with mapping information. In this paper, we propose a method-description language that focuses on the annotations that support the task of mapping new knowledge bases to problem-solving methods. Our language is similar in spirit to other formal problem-solving method specification languages (Fensel et al, 1996; Fensel & Groenboom, 1997; Penix & Alexander, 1997), although more modest in scope. Our language includes both informal natural language descriptions and formal axioms. The former can assist the developer to better understand the problem-solving method, while the latter is necessary as input for an engine that might prove or verify that the knowledge base has the properties required by the problem-solving method.
We assume both that a reuse library of methods exists, and that the developer has already selected an appropriate problem-solving method for the task at hand. Figure 1 presents our problem statement: Given a knowledge base, some domain-specific problem to be solved, and a selected method from a reuse library, we wish to provide information that helps the developer to construct and to verify as correct the mapping from the knowledge base to the problem-solving method. We assume that both methods and knowledge bases include ontologies (shown as trees in the figure). The knowledge base includes an ontology that describes the data, whereas the problem-solving method includes an ontology that describes the requirements of the method.
The operational definition of an ontology depends on one's knowledge model. Throughout this paper, we assume the use of a simple, frame-based knowledge representational model; in particular, the knowledge model specified by the Protķgķ environment and embodied in the Protķgķ/Win toolset (Eriksson, et al., 1995; Fergerson, Gennari & Grosso, 1997). As we show, with this view of the world, the method ontology is just one part of the method-description language specification for a particular method. In Section 2, we describe general aspects of method-description languages, as well as the more specific features of our current language. Section 3 describes this language with examples from two well-known problem-solving methods: propose-and-revise (Marcus, Stout, & McDermott, 1988) and cover-and-differentiate (Eshelman, 1988).
Our motivation for the development of a method-description language arises from the problems that occur without such a language. As an extreme case, consider the software reuse of CORBA objects (Gennari, Stein & Musen, 1996). Every CORBA method includes an Interface Definition Language (or IDL) specification of the syntactic footprint of that method: the type and structure of the inputs and outputs of the method. Therefore, an IDL specification can be viewed as a simple form of a method-description language. Although this specification is necessary for a good method-description language, we argue that it is not sufficient.
For example, suppose that a developer selects the method "cover-and-differentiate" from a CORBA-compliant library of objects, and found, according to the IDL specification, that this method's inputs were a list of "symptoms" and a "causal_net", and its outputs were a set of "diagnoses". Without further documentation, this specification says neither what the method does, nor what the meaning of these inputs are. In particular, at an implementation level, the "causal_net" is simply a graph of nodes linked together; the information that the leaves of this graph correspond to symptoms and that the roots correspond to diagnoses is conspicuously missing, and cannot be expressed in IDL. What is worse, this method actually has additional input requirements that are hidden from the IDL specification: The subtask of differentiating between two possible diagnoses usually requires interactively querying the user for additional information before proceeding. Finally, the IDL specification provides no information about the semantics of the method-it says nothing about what the method does with the inputs. For example, we should be able to state that cover-and-differentiate returns those diagnoses that "best cover" all of the symptoms reported in the input.
This example suggests some of the requirements of a method-description language, especially for the task of mapping a knowledge base to an appropriately selected problem-solving method. In this paper we focus on aspects of the language that support this mapping tasks. Although there have been many efforts to define a method-description language, most focus on the task of finding and retrieving methods from a library, rather than that of mapping knowledge bases to a selected method. In Section 2.1, we briefly review some of this research, as well as providing a set of dimensions for elements of a method-description language; in Section 2.2, we return to the more specific requirements implied by the mapping task.
2.1. Four Dimensions for a Language
We can define four dimensions along which to categorize elements of a method-description language:
Certainly, these are not absolute, partitioning dimensions: Information may be used for both finding and using a method; information can describe both what a method does and how it operates; etc. Nonetheless, it is useful to know how these dimensions are addressed by a method-description language. We characterize our own approach as follows:
We believe that this set of biases is different than that of others who are investigating ways of describing problem-solving methods. For example, the large classifications of problem-solving methods supplied by European researchers (Puppe, 1993; Breuker & Van deVelde, 1994) are designed with the goal of supporting users who are searching for a method, rather than supporting users who are mapping knowledge bases to a selected method. The EXPECT project (Gil & Melz, 1996) focuses on how rather than what: providing a language for specifying control-flow and an understanding of how sub-methods interact. Efforts at describing the capabilities and assumptions of the propose-and-revise method (Fensel, 1995a; Zdhahal & Motta, 1995) are more informal than formal, and are certainly at the knowledge level rather than at the symbol level. Although (ML)2 is a formal language for specifying methods (van Harmelen & Balder, 1992), it is not clear how to make operational its knowledge-level statements. However, this language does include "lift operations" that map information from the domain to the method, and these capture our notion of the mapping task from knowledge bases to methods.
Recent work by Fensel and Groenboom (1997) is closest to our set of biases. In this work, they describe a framework of problem-solving methods, domain models (knowledge base) and the adapters (mappings) that connect methods to domains. This work shares our goal of providing a means to formally validate (a "proof obligation") that the requirements of the problem-solving method can be matched by a particular adapter and domain model. However, their formalization of these elements focuses on a specification of how the method operates, building on earlier work known as KARL (Fensel, 1995b) and (ML)2 (vanHarmelen & Balder, 1992). In contrast, we believe that initial work at formalizing problem-solving methods should focus on the smaller task of formally defining what the method does. We expect that this focus will allow our language to be smaller and (perhaps) less expressive, but more tractable and perspicuous that these broader research efforts at formalizing methods.
Penix and Alexander (1997) describe an architecture formalism for the automatic adaptation and selection of components. This works builds on research from software engineering as well as the SpecWare (Srinivas & Jullig, 1994) approach to component-based problem solving. Although their specification language is similar to our ideas, they do not include explicit mapping components, and instead aim at automatically adapting and configuring components to match the needs of a specific task. This emphasis on automation contrasts with our bias for a more interactive system, where the developer works with a library of methods and our system simply supports the activity of method-to-domain mapping.
2.2. Our Requirements for a Method-Description Language
The task of mapping knowledge bases to methods is often overlooked. As we argue elsewhere (Gennari, et al., 1994; Park, Gennari & Musen, 1998), the construction of these mappings (or mediators) between problem-solving methods and knowledge bases is an essential and potentially expensive step in the process of applying a method from a reuse library. Thus, if the method library includes support for this process in its method-description language, this feature can make the difference between cost-effective reuse, and reuse that is more expensive than building from scratch. This is our motivation for looking primarily at the mapping task, rather than at the method-selection task.
Ultimately, we wish to provide support for automatic construction of these mappings. Short of this goal, we should provide for automatic verification that a mapping preserves the semantics in the knowledge when translating to the needs of the problem-solving method. To achieve either of these goals, we must use formal specifications that describe the inputs and outputs of a method; thus, our preference is for formality in a method-description language. However, because we are interested in automatic verification, our formalism must be simple and tractable, rather than fully expressive.
The Protķgķ project has always been biased toward grounding any knowledge-level descriptions to an executable, symbol-level implementation. Recently, our interest has been further heightened by the potential interaction between the CORBA standard (Orfali, et al., 1996) and the development of a method reuse library (Gennari, Cheng, Altman, & Musen, 1997). Our interest in the mapping task also implies an interest in the symbol level: Although selecting methods from a library can be done with knowledge-level descriptions, the mapping task necessarily involves a symbol-level specification of inputs and outputs.
Thus, our biases lead us to develop a method-description language with the following attributes:
As we show in Section 3, our method-description language does include some other features, mostly to allow for informal statements about other aspects of the method (such as control flow). However, these four elements are the ones we have made formal, and these are the elements that we expect to use when assisting developers with the task of mapping a knowledge base to a problem-solving method. Although our biases may have narrowed the scope of our method-description language, we believe that they have kept us focused on this particular task.
In this section, we present our initial definition of a method-description language, especially as motivated by the "mapping task" of a developer. We will present this language with examples from two problem-solving methods: propose-and-revise (Eshelman, 1988) and cover-and-differentiate (Marcus, Stout & McDermott, 1988). To illustrate these examples, we will show output from our Protķgķ/Win toolset (Eriksson et al., 1995; Fergerson, Gennari & Grosso, 1997).
At this point, our ontology for the method-description language is modest. We have three main classes of information: a class for listing information about the method as a whole, a class for ontological information, and a class for subtask information. For each of these, we provide a table listing and describing the slots of the class, and then an example use of the class in Protķgķ/Win with propose-and-revise. We also show our method ontologies for both propose-and-revise and cover-and-differentiate, and we briefly describe our formal language for specifying constraints.
Table 1. The slots of the problem-solving method class.
Slot |
Description |
Name |
The name of the problem-solving method (PSM) |
Author |
The point-of-contact for the author of the PSM |
Description |
A textual description of the PSM at the knowledge level. In general, this could include any information not covered by the other slots: currently we use it for information about the sources of the PSM, and about the control flow among subtasks of the PSM. We also use this slot to replicate (in natural language) some of the most important constraints specified more formally elsewhere. |
Inputs |
An ontology frame (see Table 2) |
Outputs |
An ontology frame (see Table 2) |
Subtasks |
A list of subtask frames (see Table 3) |
Competence |
Constraints across the inputs and outputs that state what the method can accomplish. |
3.1. The Problem-solving Method Class
Table 1 lists the slots of the root class in our method-description language; the method class. This class includes slots for the inputs, outputs, and subtasks of the problem-solving method. The slot "Competence" is a list of constraints across inputs and outputs; these are the constraints that are guaranteed to be true if the method executes successfully (Akkermans, et al., 1994; Fensel et al., 1996). For example, if propose-and-revise completes successfully, then all the constraints are satisfied, and all the parameters have values assigned to them (see Figure 2). This slot could be used to allow developers to verify that the method does what they want it to do; unlike an IDL specification, it communicates some notion of method semantics. This slot is not for specifying requirements among the inputs (or outputs): these constraints are specified in the ontology frame that fills the "Inputs" (or "Outputs") slot of the PSM class (see Section 3.2).
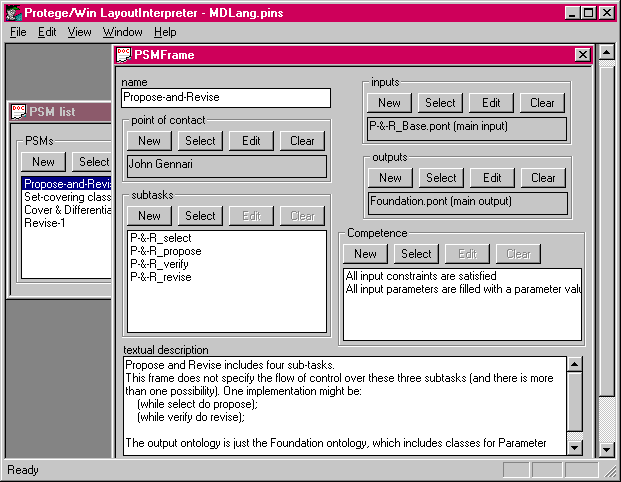
Figure 2. The PSM class filled with a specification for propose-and-revise, as seen in the Protķgķ/Win knowledge-acquisition tool.
This class could be augmented with other slots that would be used for method selection. For example, developers would presumably need to have information about the control flow among subtasks of the method. In the long run, this information could be formalized as a set of operational specifications (Fensel & Groenboom, 1997), but for our needs, the subtask slot for this class serves more as documentation, allowing developers to understand the decomposition of the problem-solving method. We might also expect information about the author of the method, and perhaps a history of successful uses of the method. However, these are informal specifications; as described in Section 2, our focus is on the formal constraints of method inputs and outputs. Figure 2 shows an example of the PSM class as filled in for the propose-and-revise problem-solving method. In the Protķgķ/Win architecture, each class in the ontology is associated with a form in the knowledge-acquisition tool, and each slot of that class is mapped to a field or graphical widget for acquiring values to fill that slot. For example, the "Description" slot in the ontology is linked to a text box in the KA-tool; in Figure 2, this box is filled with an informal description of a possible control flow among sub-methods. The slot "Inputs" is associated with a different widget that allows the user to edit the value of this slot in a second, subsidiary form (see Figure 3).
The figures with the Protķgķ toolset show our specification of the propose-and-revise problem-solving method. This is not the only possible specification for the method, but it corresponds to our implementation. For example, Figure 2 shows a breakdown of the method into four sub-tasks; other divisions are possible, but this matches our implementation. As we proceed through the description of our language, we show more and more details of our implementation and of the specification of this method in our method-description language.
Table 2. The slots of the ontology class.
Slot |
Description |
| Ontology information | A class hierarchy, following the Protķgķ knowledge model (Grosso, et al., 1998). All elements of the knowledge must be instances of these classes. |
| Constraints | A list of constraints about classes in the ontology (or about instances in the knowledge base). Simple constraints are facets on the classes in the ontology; the constraints listed in this slot are more complex and are stated using a KIF-like axiom language. |
| Key classes | A set of classes of particular importance. This is more of a nominal distinction, intended to aid the developer in constructing mediators. |
Functions |
Set of instances of a function class. Primitive function (e.g. "fix" in P-&-R) should be defined by a set of frames that ultimately bottom out in an IOR where the function can be called. This information is also in the method ontology, but sufficiently important to be duplicated here. The foundation method ontology includes a standard class for "function" with slots for IDL interfaces, etcetera, so that CORBA object can be used. |
| APIs | A description of an APIs that will be used (or must be supplied). This allows methods (and sub-methods) to query for knowledge at run-time. An example API might be "Standard GFP Queries." Note that the API could describe two directions of data flow. |
3.2. The Ontology Class
Table 2 lists the slots of the ontology class. This class specifies information about the inputs or outputs of a problem-solving method. As we describe elsewhere, our view of knowledge-based systems is constrained by the Protķgķ knowledge model (Grosso, et al., 1998). In this model, we make a strong distinction between classes and instances: The inputs to a problem-solving method are a set of instances whose defining classes reside in a method ontology. This ontology is referenced in the first slot of the Ontology Frame (in Figure 3, it is "P-&-R_Base.pont"); in Section 3.4, we discuss further method ontologies and show examples in the Protķgķ/Win toolset.
Method ontologies include information about classes, and slots of those classes, including type restrictions, and other constraints that can be expressed by a set of facets on slots. However, there are a limited number of facets available in the Protķgķ knowledge model, and in general, we need to be able to state arbitrary constraints about objects in the input ontology. This is the purpose of the "Constraints" slot of the ontology class: a list of arbitrary constraints about the objects defined in the method ontology. Figure 3 shows a number of these constraints for the input of propose-and-revise: for example, that every fix must be associated with some constraint. In Section 3.5 we show our formalization of this constraint.
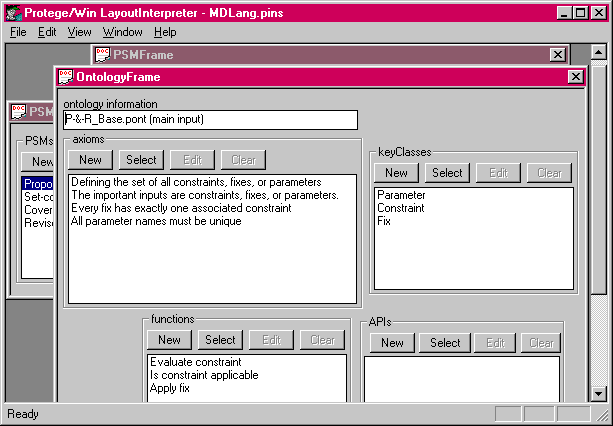
Figure 3. The ontology frame with the input constraints for propose-and-revise, as seen in the Protķgķ/Win knowledge-acquisition tool.
The "Key classes" slot is a list of those classes in the method ontology that are, in some ways, most important for the developer to map to her knowledge base. It is our hypothesis that, for large method ontologies, it will be useful to know which classes in that ontology are the primary ones, in contrast to those classes that are derived from or subsidiary to these "Key classes". In a similar fashion, we hypothesize that it will be important for the developer to know the list of functions required by a problem-solving method. This information could actually be derived from the method ontology (by searching for all slots that take a value of type "function"), but we believe that these functional requirements of the method are sufficiently important to warrant duplication of the information in the slot "Functions". Figure 3 lists the functions and key classes for our specification of the propose-and-revise problem-solving method.
The "APIs" slot contains information about ways in which the problem-solving method makes run-time queries for additional information. For a non-interactive method such as propose-and-revise, this slot is empty. However, for any method that does monitoring of data, this slot describes the types of queries the method will make. Developers that are mapping such a method onto a new knowledge base need to be aware of this requirement, and they need to be able to respond to the sorts of queries made by the method. As mentioned in the scenario at the beginning of Section 2, the cover-and-differentiate method includes an API for differentiating knowledge: asking for additional observations that distinguish among competing hypotheses. This API is specified as a required input for the subtask of "differentiate".
3.3. The Subtask Class
A subtask is a component of the problem-solving method that can be treated as a separate black box that provides some functionality to the method. Subtasks are often components that can be replaced or modified to create a variant on the original problem-solving method. As we mentioned in Section 2, subtask configuration is the focus of research by Penix and Alexander (1997). In our ontology, this class simply allows for method decomposition. Table 3 lists the slots in our specification of a subtask. Some subtasks, as indicated by the "Required" slot, are optional-they provide additional functionality, but are not an essential part of the method. A problem-solving method may include a default implementation of a subtask; in this case, the developer can rely on this default implementation, rather than building or finding externally a method to fulfill the functionality of that subtask.
Table 3. The slots of the subtask class.
Slot |
Description |
| Description | A textual description of the subtask. This will help developers understand the subtask and match particular implementations to it. |
| Required | A Boolean: Can the PSM make do without this subtask being filled? |
| Default | A Boolean: Does the PSM have a default implementation of the subtask internally? |
| Inputs | An ontology frame that specifies the inputs required by the subtask. |
| Outputs | An ontology frame that specifies the outputs of the subtask. |
| Competence | Constraints across the inputs and outputs (similar to competence for methods) |
Subtasks do not themselves have subtasks; however, they are designed to be filled by other problem-solving methods, which can have additional subtasks. For example, there is a "revise" subtask in the propose-and-revise method that takes a set of violated constraints as input, and chooses some set of fixes to apply, and applies these to modify parameter values. There are different ways of fulfilling this subtask, and we have specified one approach in a method called "Revise-1" and this problem-solving method has lower-level subtasks "choose constraint" and "apply fix".
Subtasks advertise their own inputs and outputs, using the same ontology frame defined in Section 3.2. Hopefully, these requirements are subsets of the requirements of the parent problem-solving method. Unfortunately, we cannot always guarantee this property; we would like to allow developers the freedom to fill a subtask with a method that may make some extra input demands beyond that of the parent problem-solving method. For example, different versions of the "differentiate" subtask of cover-and-differentiate may have different sorts of APIs for querying for additional knowledge.
An important issue that remains unresolved in our current draft of the method-description language is the ability to relate different ontologies to each other. This problem appears not only for relating subtask ontologies to parent method ontologies, but also for connecting the input and output ontologies for either subtasks or methods. For example, propose-and-revise returns as output only a set of parameters and parameter values-the output ontology does not care about constraints or fixes. However, the "parameter" class in the output ontology certainly needs to be the same as that specified in the input ontology.
3.4. Method Ontologies
An essential part of our method-description language is a method ontology, which includes definitions of all the objects required by the problem-solving method. For example, if a method specifies that it requires "Fixes" as inputs, it must provide a clear definition of what is meant by "Fix". With a frame-based knowledge model, such a definition includes attributes (slots) such as "fix-name" and "associated-constraint", and these slots have facets that specify type constraints, such as "string" or "Boolean".
Ideally, we would like developers of problem-solving methods to share a framework for defining inputs and outputs. For example, many methods share the idea of parameters with associated parameter values. At an even more fundamental level, many methods assume a shared understanding of basic data structures and data types, such as sets, lists, and ordered types. To capture this shared knowledge, we have begun to develop an "foundation ontology" for developers of problem-solving methods. Our hope is that the specification of any particular method ontology could include this foundation ontology, and make reference to the objects and definitions supplied therein. Figure 4 shows the class hierarchy (omitting slot information for brevity) of our foundation ontology. We used this ontology as the basis for our construction of method ontologies for both propose-and-revise and cover-and-differentiate.
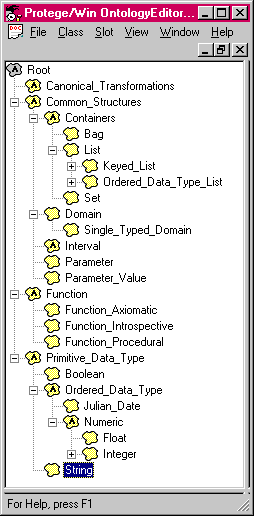
Figure 4. The Foundation ontology, to be shared by problem-solving method developers.
One purpose of the foundation ontology is to encourage developers to specify method requirements with a "normal form". If developers share meanings for standard data objects, then it will be easier for others that are building mappings to be confident that their mappings are correct. For example, the propose-and-revise problem-solving method could ask that the set of fixes be ordered by an integer-valued "preference" slot. If a developer's knowledge base contains information that is similar to, but not identical to "preference", she can use a canonical transformation that maps her knowledge base to the data type requirements of the method. Some of these transformations could be pre-enumerated and available as shared objects in the foundation ontology.
Problem-solving methods often ask for information that must be evaluated at run time. For example, a minimum specification for a constraint in propose-and-revise is something that can be evaluated at run-time to true or false. Thus, what the method requires is a function that returns a Boolean value. This function cannot be defined by the method; it is domain specific. Therefore, our foundation ontology defines classes of objects that are functions, but instances of those functions are expected from the knowledge base. These functions can be executable remote objects in the CORBA sense, and our method-description language includes slots for specifying aspects of a CORBA component, such as the IDL specification. For functions, the CORBA standard provides exactly the right level of information: a method simply publishes its IDL requirements for a function, and the knowledge base is free to implement this function call in arbitrary, domain-specific ways. As we mentioned in Section 3.2, these functions are often critical for the developer to map to her knowledge base, and thus, they appear both in the method ontology and in the ontology class in our method-description language. Figure 3 shows the functions listed for propose-and-revise.
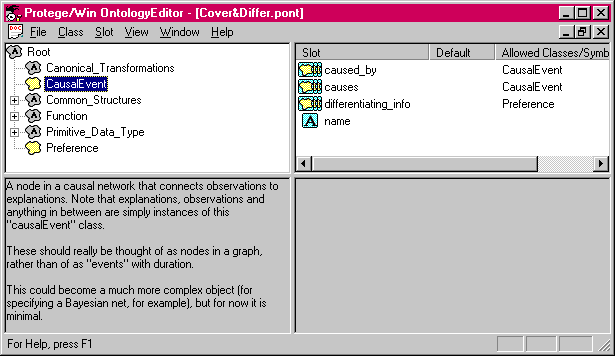
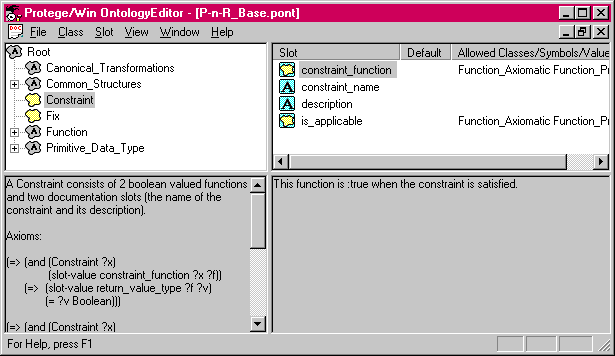
Figure 5. Two example method ontologies; the upper ontology is for cover-and-differentiate; the lower, for propose-and-revise. Both ontologies inherit from the Foundation ontology.
Figure 5 shows our method ontologies for both cover-and-differentiate (at the top) and for propose-and-revise (at the bottom). Both ontologies include the foundation ontology; in the Protķgķ/Win tool, classes from included ontologies are shown in gray. The number of method-specific classes is fairly small: constraints and fixes for propose-and-revise, and causal events and preferences for cover-and-differentiate. The right-hand pane of these tools shows the slots or attributes of the selected class. Thus, in the propose-and-revise ontology, the class "Constraint" has slots for the Boolean constraint function, the name, a description and a second Boolean function that answers the question: "is this constraint applicable?"
3.5. The Axiom Language
The lowest level of detail in our method-description language is the choice of a formal language for expressing the axioms that represent the requirements of the method. Since we need this language to express constraints, we need a formalism that is more expressive than the frame-based knowledge model that is used by Protķgķ/Win (Grosso, et al., 1998). We base our language on KIF, a familiar standard in the knowledge-bases systems world, and a language that was originally designed for knowledge reuse. (Neches, et al., 1991). However, rather than allowing arbitrary KIF sentences, we have begun work to define a set of predicates and functions that work with the constructs of the foundation ontology, and that allow developers to formally specify information about the inputs and outputs of methods. For example, the predicates "output" and "input" allow us to distinguish between elements of the input and output method ontologies. (It would be premature to publish our current list of these predicates, and we expect the list to grow over time.) Although many of these predicates could be expressed in more primitive terms with KIF, our aim is to make the axiom language smaller and more easily understood than a fully expressive formal language. In addition, these restrictions on the axiom language should allow for more tractable and well-defined verification of mapping relations.
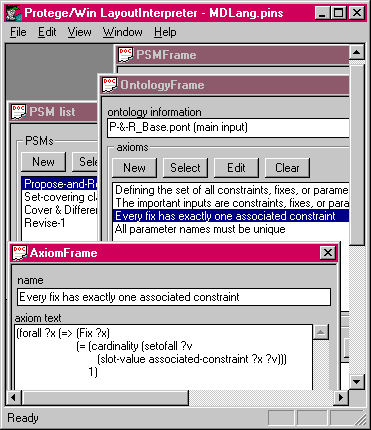
Figure 6. An AxiomFrame showing the formal specification of the constraint that every fix has exactly one constraint (for propose-and-revise).
Figure 6 shows an example of a simple axiom about the input class "Fix" for the propose-and-revise problem-solving method. Note that this axiom can only be evaluated in the context of a particular method ontology-an ontology that includes a class for "Fix" with a slot named "associated-constraint".
To demonstrate the potential value of our method-description language, let us revisit the scenario presented in Section 2: If a developer has selected "cover-and-differentiate" from a reuse library, and if that method includes a formal specification of its requirements in our method-description language, then it will be easier to construct and to validate as correct mappings to particular knowledge bases. The developer can find the data requirements from the method ontology, which uses common terms and structures from the shared foundation ontology. Comparing these requirements to the ontology of her knowledge base, she can then construct mappings to fulfill the needs of the method. The mappings could be drawn from a set of mapping types (as described in Park, et al., 1998), and these types could further simplify the task of mapping construction. The mappings could use canonical transformations from the foundation ontology for some objects, and could use simple CORBA objects to satisfy some of the functional requirements of the method. The benefit provided by the method-description language is simply that these requirements are formal and explicit, and that the method includes hooks designed for domain-specific mappings to particular knowledge bases.
A more challenging mapping task occurs when the method includes run-time queries for additional data. The default implementation for the subtask of differentiate may come with an overly simple query API-for example, an API that simply asks the user for additional information, as presented in the original MOLE system for cover-and-differentiate (Eshelman, 1998). If developers wish to use a more sophisticated approach that accounts for the cost of retrieving information, or for the possibility of querying remote database at run-time, then they could re-configure the problem-solving method by implementing the "differentiate" subtask with a more complex sub-method. Again, the advantage of a method-description language specification is that the requirements of the subtask, and the semantics of its input-output transformations (in the "Competence" slot) are made explicit and formal.
Our preference for making method requirements formal is that this can lead to the use of a theorem prover to verify that the axioms hold true. Roughly speaking, a knowledge base is a set of logical truths (the classes and axioms) and a model of them (the instances). A mediator is sound if it transforms any model of the domain ontology into a valid model of the method ontology. Thus, mappings "lift" information from the context of the domain to the context of the method, and then theorem-proving can be used to verify that the results do not contradict the axioms stated in the method-description language. The method-description language we have presented here is still work-in-progress, and it is too early to test our ideas with a "real" set of mappings, axioms, and a theorem prover. However, our bias toward a perspicuous, simple method-description language should allow for more tractable use of theorem proving.
For a method-description language to be a successful part of a method library, there needs to be a critical mass of developers and researchers that approve of the language (or are at least willing to follow its conventions). Thus, our goal is to build consensus for the general aims of our language. As we described in Section 2, we have focused on particular aspects of a method-description language: a formal description of the input and output requirements of the method, with the goal of supporting the construction of mappings, and therefore linked to a symbol-level characterization of the problem-solving method. We do not claim that this approach is the only reasonable way to build a method-description language; in fact, we hope to augment our language with elements from other languages. However, we must make it easier for developers to reuse problem-solving methods before any method reuse library can be cost-effective. This has been our motivation for our method-description language, and we hope that our language can lower this barrier to reuse.
This work has been supported in part by High Performance Knowledge Bases project of the Defense Advanced Research Projects Agency. We would like to thank our reviewers, and especially Dieter Fensel, for constructive comments on an earlier draft. We thank Ray Fergerson and all members of the Knowledge Modeling Group for their contributions to our ideas.
![]()
References
Akkermans, H., Wielinga, B., and Schreiber, G. (1994). Steps in constructing problem-solving methods. Proceedings of the Eighth Banff Knowledge Acquisition for Knowledge-Bases Systems Workshop (pp. 29.1-29.21), Banff, CA.
Benjamins, R. (1995). Problem-solving methods for diagnosis and their role in knowledge acquisition. International Journal of Expert Systems: Research & Applications, 8(2), 93-120.
Breuker, J.A., and Van de Velde, W., Eds (1994). CommonKADS Library for Expertise Modeling. Amsterdam: IOS Press.
Breuker, J. (1997). Problems in indexing problem solving methods. IJCAI Workshop on PSMs for Knowledge-based systems, Nagoya, Japan.
Chandrasekaran, B. (1986). Generic tasks for knowledge-based reasoning: High-level building blocks for expert system design, IEEE Expert, 1(3), 23-30.
Eshelman, L. (1988). MOLE: A knowledge-acquisition tool for cover-and-differentiate systems. In S. Marcus (Ed.), Automating Knowledge Acquisition for Expert Systems, Kluwer, Boston, pp. 37-80.
Eriksson, H., Shahar, Y., Tu, S.W., Puerta, A.R., and Musen, M.A. (1995). Task modeling with reusable problem-solving methods. Artificial Intelligence, 79(2), 293-326.
Fensel, D. (1995a). Assumptions and limitations of a problem solving method: A case study. Proceedings of the Ninth Banff Knowledge Acquisition for Knowledge-Bases Systems Workshop (pp. 27.1-27.19), Banff, CA.
Fensel, D. (1995b). Formal specification languages in knowledge and software engineering. The Knowledge Engineering Review, 10(4), 361 - 404.
Fensel, D., and Groenboom, R. (1997). Specifying Knowledge-Based Systems with Reusable Components. Proceedings of the 9th International Conference on Software Engineering & Knowledge Engineering (SEKE-97), Madrid, Spain.
Fergerson, R., Gennari, J., and Grosso, B. (1997). What is Protķgķ/Win? On-line documentation at http://smi-web.stanford.edu/projects/prot-nt/documentation/. Available Nov. 1997.
Gennari, J. H., Altman, R. B., and Musen, M. A. (1995). Reuse with PROT╔G╔-II: From elevators to ribosomes. Proceedings of the Symposium on Software Reuse, (pp. 72-80). Seattle, WA.
Gennari, J.H., Cheng, H., Altman, R.B., and Musen, M.A. (in press). Reuse, CORBA, and knowledge-based systems. International Journal of Human-Computer Studies.
Gennari, J. H., Stein, A. R., and Musen, M. A.(1996). Reuse for Knowledge-Based Systems and CORBA Components. Proceedings of the 10th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop (pp. 46.1 - 46.16), Banff, Canada.
Gennari, J. H., Tu, S. W., Rothenfluh, T. E., and Musen, M. A. (1994). Mapping domains to methods in support of reuse. International Journal of Human-Computer Studies, 41, 399-424.
Gil, Y., and Melz, E. (1996). Explicit representations of problem-solving strategies to support knowledge acquisition. Proceedings of the Thirteenth National Conference on Artificial Intelligence (AAAI-96), pp. 469 - 476, Portland, OR.
Grosso, W., Gennari, J., Fergerson, R., Musen, M. (1998). When Knowledge Models Collide (How it happens and what to do). Proceedings of the Eleventh Banff Workshop on Knowledge Acquisition, Modeling and Management. Banff, Canada.
van Harmelen, F. and Balder, J.R. (1992). (ML)2: A formal language for KADS models of expertise. Knowledge Acquisition 4(1), 127-161.
Marcus, S., Stout, J., and McDermott, J. (1988). VT: An expert elevator designer that uses knowledge-based backtracking. AI Magazine, 9(1), 95-112.
McDermott, J. (1988). Preliminary steps toward a taxonomy of problem-solving methods. In S. Marcus (Ed.), Automating Knowledge Acquisition for Expert Systems, Kluwer, Boston, pp. 225-255.
Neches, R., Fikes, R. E., Finin, T., Gruber, T.R., Patil, R., Senator, T., and Swartout, W. R. (1991). Enabling technology for knowledge sharing. AI Magazine, 12(3), 16-36.
Orfali, R., Harkey, D., and Edwards, J. (1996). The Essential Distributed Objects Survival Guide. John Wiley & Sons, New York.
Park, J.Y. , Gennari, J.H., and Musen, M.A. (1998). Mappings for Reuse in Knowledge-based Systems, Proceedings of the Eleventh Banff Workshop on Knowledge Acquisition, Modeling and Management. Banff, Canada.
Penix, J. and Alexander, P. (1997). Toward automated component adaptation. Proceedings of the Ninth International Conference on Software Engineering and Knowledge Engineering (pp. 535-542). Madrid, Spain.
Puppe, F., (1993). Systematic Introduction to Expert Systems. Berlin: Springer-Verlag.
Srinivas, Y.J. and Jullig R. (1994). SPECWARE: Formal Support for Composing Software. Kestrel Institute Tech Report 94.5. Available at http://www.kestrel.edu/HTML/publications.html, Nov. 1997.
Zdrahal, Z. and Motta, E. (1995). An in-depth analysis of propose-and-revise problem-solving methods. Proceedings of the Ninth Banff Knowledge Acquisition for Knowledge-Bases Systems Workshop (pp. 38.1-38.20), Banff, CA.