Figure 1: GQM hierarchy for the deployment of SCOOP
MASAHIRO HORI
Tokyo Research Laboratory, IBM Japan Ltd.
1623-14 Shimo-tsuruma, Yamato-shi
Kanagawa-ken 242-8502, Japan
hori@trl.ibm.co.jp
This paper presents an empirical study to assess a process for the real-life deployment of a library of problem-solving methods dedicated to production-scheduling problems. First, the context of the study is elucidated on the basis of the goal-based framework for software measurement. The organization of the library is briefly explained, and the results of measuring the library's evolution during its deployment are then given. Finally, the context of this study is further refined not only to allow its continuation with clear goals, but also to make the preliminary quantitative results obtained from a real-life setting available for use in other studies of the reuse of problem-solving knowledge.
One of the primary issues in developing knowledge systems is how to improve their extensibility and productivity by using software and knowledge reuse technologies. Libraries of problem-solving methods have been proposed to facilitate the reuse of problem-solving knowledge. The ultimate goal of knowledge reuse is to demonstrate that qualified knowledge libraries facilitate the development of knowledge systems in real life, not only for the prototype and first release, but also for the further enhancement and maintenance of the systems. However, libraries of problem-solving knowledge evolve according to the clarification of implicit ontological commitments. This kind of volatility is partly due to the interaction problem, namely, the dependence of knowledge on its use [Bylander and Chandrasekaran, 1987], because reusable libraries cannot exist independently of the assumptions about how they will be (re)used in a real-life context [Clancey, 1993, Brown and Duguid, 1994].
Since the benefits of knowledge reuse cannot be properly evaluated by developing a single, prototype knowledge system, it is important to take account of questions related to sample population, reality of environments, and time range of studies. A series of Sisyphus efforts have moved from a single, prototype system for room assignment [Linster, 1993] toward a more realistic example of elevator design [Schreiber and Birmingham, 1996], and are now ready for quantitative measurement of the knowledge-engineering performance [Shadbolt, 1995]. At the same time, many groups are pursuing their own approaches to a variety of sample problems [Marques, Dallemagne, Klinker, McDermott, and Tung, 1992, Runkel, Birmingham, and Balkany, 1994, Eriksson, Shahar, Tu, Puerta, and Musen, 1995]. Although long-term studies that follow the evolution of knowledge systems in real life are extremely rare, experiences over a ten-year period have been reported in the case of XCON [Barker and O'Connor, 1989].
Every effort deals with some of the issues mentioned above, but it is almost impossible to conduct a long-term empirical study for a number of real-life tasks. Thus, the real challenge for the whole research community is to make the empirical results cumulative [Simon, 1995]. The difficulties will then be twofold. One is that all empirical results are open to interpretation, and the other is that even if the interpretations of results are generally agreed on, the results are invariably tied to an experimental setup [Hanks, Pollack and Cohen, 1993]. Therefore, it is necessary in reporting empirical results with careful characterization of the context of the study. Without knowing the context, readers cannot determine whether the results are comparable and, what is worse, they may reach an inadequate understanding of the results. Ways of presenting results should allow readers to more or less reconstruct the empirical study.
We have worked on a component-oriented methodology for developing knowledge systems, and on elicitation of reusable problem-solving knowledge from existing scheduling expert systems [Hori, Nakamura, Satoh, Maruyama, Hama, Honda, Takenaka, and Sekine, 1995]. On the basis of our experiences in scheduling problems, we have designed and implemented a component library for production scheduling systems, SCOOP (Scheduling COmponents fOr Production control systems) [Hori and Yoshida, 1996]. After developing two prototype systems, we made SCOOP available in July 1995 for the development of real-life production-scheduling systems. Scheduling systems developed with SCOOP are now running at IBM's hard-disk manufacturing plants in Thailand and Hungary. In developing and deploying SCOOP, we collected empirical data that may characterize the library and its reuse process.
The results presented in this article are inextricably associated with a particular problem type and the situation at hand. Therefore, we are not attempting to claim that these results can be generalized to all kinds of knowledge library. We know that our sample sizes are too small to have statistical validity. The empirical study here is regarded as an assessment study to establish baselines, ranges, and other aspects of the behaviors of a system or its environment [Cohen, 1995, p. 7,]. Two complementary aspects of empirical studies are distinguished in [Cohen, 1995]: an exploratory phase for summarization and modeling, and an experimental (confirmatory) phase for testing hypotheses and predictions. At this moment, our work stays in the exploratory phase by itself. From a practical point of view, however, exploratory studies in industrial settings and experimental research in laboratory settings must be linked, so that hypotheses suggested by the former can be tested and confirmed by the latter.
The objective of this article is to clarify the context of our empirical study, so that insights obtained from this study in an industrial setting can be transferred to other exploratory or experimental studies. Although our study deals with only a single project for the deployment of SCOOP, a salient feature is that it focuses on the evolution of the library in real life. In the next section, a goal-based framework for software measurement [Basili and Rombach, 1988] is introduced, and the context of our study is constructed on the basis of the framework. Section 3 describes the organization and application of SCOOP, and empirical data collected during the deployment are given in Section 4. Finally, the context of this study is further refined, not only to allow this study to be continued with clear goals, but also to make our preliminary results available for use in other studies of the reuse of problem-solving knowledge.
Measurement is the process of assigning symbols (usually numbers) to attributes of entities in the real world. There are three classes of entities in software measurement [Fenton, 1994]:
Furthermore, internal and external attributes are distinguished within each class of entity [Fenton, 1994]:
- Processes
- are any software-related activities that take place over time.
- Products
- are any artifacts, deliverables, or documents that result from processes.
- Resources
- are items required by processes
For example, the size of program code is an internal attribute of a product, which can be measured in isolation. In contrast, productivity is an external attribute of a resource (i.e., personnel, either as individuals or groups), because it depends on the personnel's skills and the quality of products to be delivered. Maintainability is an external attribute of a product, which also depends on the skills of the maintainers and the tools available to them.
- An internal attribute
- is one that can be measured by examining the product, process, or resource itself, and can be separated from its behavior.
- An external attribute
- is one that can be measured only with respect to other entities in its environment.
It must be noted here that we cannot measure the external attributes directly without reference to internal attributes. It is important to keep this distinction in mind when conducting an empirical study with measurements. Internal attributes may suggest what we are likely to find as external attributes. However, the relationship between internal attribute values and the resulting external attribute values has rarely been established, because it is sometimes difficult to perform the controlled experiments necessary to confirm the relationship [Fenton and Pfleeger, 1997, p. 80,]. In addition, it has also been pointed out that current research on software measurement should try to find good measures, so that indirect measures can be derived from those original measures and predictive theories can then be constructed once the cause-and-effect relationships have been identified [Henderson-Sellers, 1996, p. 66,].
Our goal is to create a qualified library of problem-solving knowledge. However, software is created by development, not by production as in the manufacture of consumer products, because software artifacts may not necessarily be reproduced in the same form. This means that we do not have a lot of data collection points to construct reasonably accurate models for a statistical quality model [Basili, 1996]. This situation parallels the difficulty in coping with the interaction problem mentioned earlier. The dependence of knowledge on its use is manifested when we consider issues related to the external attributes. Therefore, it is useful to think about internal attributes of knowledge, either as product, process, or resource, before we investigate the interaction problem.
A typical problem in the application of software measurement is an absence of any coherent goals. Metrics are used for measuring some aspects of quality factors such as efficiency, usability, and maintainability. Interpretations of a quality factor usually depend on the perspectives of the observers, who may include software engineers, domain experts, and end users. Furthermore, trade-offs may exist between such perspectives.
In the literature of software engineering, a methodology called the goal/question/metrics (GQM) paradigm [Basili and Rombach, 1988] was proposed to guide the integration of measurement into the software development process, and is now widely used for software measurement. This methodology is characterized by two measurement principles. First, measurement must be top-down, clarifying what measures should be collected. Second, the collected data must be interpreted in the context of a goal and objective. The GQM approach provides a framework involving three steps:
In terms of the goal definition templates provided in [Basili and Rombach, 1988],
a major goal of our study can be defined as follows. Italicized words
below are selected from terms in the templates.
Goal definition
The goal definition is then refined into one or more questions, and finally metrics are derived so that the questions can be answered to meet the top-level goal. However, it is generally accepted that progressing from goal to question is the most difficult part of the GQM approach, which provides little guidance for identifying useful questions [Shepperd, 1995, p. 146,].
Figure 1: GQM hierarchy for the deployment of SCOOP
When we started to design SCOOP at the beginning of 1994, we had some questions about the organization of reusable libraries of problem-solving methods. These questions resulted not only from our experiences in applying a component-oriented approach to scheduling problems [Hori, Nakamura, and Hama, 1994], but also from informal interviews with software engineers who have worked on a commercial software package for production-scheduling systems.
The first point is that knowledge systems cannot live by problem-solving methods alone in real life. Real-life knowledge systems consist of high-level modules or subsystems not only for problem-solving methods, but also for an application domain model and user interfaces. For instance, the required characteristics of scheduling systems are diverse, and are not necessarily limited to the features of scheduling algorithms [Liebowitz and Potter, 1993]. Practical systems in real environments must meet certain requirements as regards interactivity with end users, in addition to requirements as regards interoperability with peripheral information systems [Mitev, 1994].
This observation leads to a high-level module structure of knowledge
systems, which consist of three subsystems: a domain model, problem-solving methods, and graphical user
interfaces. In particular, these subsystems should be designed, so
that mutual dependency between subsystems can be eliminated.
Otherwise, mutually dependent subsystems require monolithic treatment
that hinders reuse of the library.
a domain model, problem-solving methods, and graphical user
interfaces. In particular, these subsystems should be designed, so
that mutual dependency between subsystems can be eliminated.
Otherwise, mutually dependent subsystems require monolithic treatment
that hinders reuse of the library.
The second point is that successful knowledge systems evolve continually in their context of use. Thus it is also necessary for a library of problem-solving methods to be enhanced, when a novel function is realized in a knowledge system and can be generalized for inclusion in the library. A pitfall then is that over-commitment to an individual problem may spoil the reusability of the library. This might not be so serious initially, even if some project-specific functions are added to the library. But the overhead will become apparent as the whole library is upgraded consistently, with the addition of bells and whistles that may not be crucial in the intended scope of reuse.
The above observations raise two questions as follows under the top-level goal. The first question is to what extent the high-level module structure is altered throughout the project cycles. Once this question is posed, it is necessary to measure the code size of each high-level module. In this study, we focus particularly on the project-independent portion of a knowledge system, which will be reused as a library in different projects. Therefore, the size should be measured by determining whether a portion of the module depends on a particular project at hand.
The second question is whether productivity is significantly affected by dependence of a high-level module in each project cycle. This question refers to productivity, which is an external attribute that cannot be measured directly. Measures related to this question will be the increase in code size during a project cycle and the person-hours spent on the process. As in the case of the measures derived from the first question, the code size and person-hours here should also be measured by taking account of the dependence on the project at hand.
A summary of the GQM hierarchy in our study is given in Figure 1, where the two of the measures (M1 and M2) are internal product attributes, while the other two (M3 and M4) are external process attributes. Although this hierarchy comes out in a retrospective manner, the GQM provides a framework for structuring and documenting measurement work.
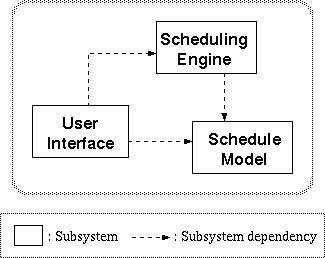
SCOOP is implemented in an object-oriented language (C++) and currently includes about 40 classes. SCOOP consists of three subsystems: a schedule model, a scheduling engine, and a graphical user interface (Figure 2). The schedule model provides core concepts for the manufacturing domain such as product, lot, and resource. The graphical user interface subsystem consists of facilities for visualizing and modifying the internal status of a schedule model. The scheduling engine provides a hierarchy of problem-solving methods. The scheduling engine subsystem is explained later in this section, while further details of the other subsystems are found in [Hori and Yoshida, 1997].
The scheduling engine subsystem comprises two scheduling methods: an
assignment method and a dispatching method.
As shown in Figure 3, every lot (ScLot) is
indirectly associated with operations (ScUnit) via a production
sequence (ScJob). This whole-part relation between a lot and
units articulates the roles of the two scheduling methods. That is to
say, the dispatching method, which deals with lot priorities,
determines the global manufacturing status. In contrast, the
assignment method is concerned with the status on a more detailed
level, since this method deals with the starting and finishing times
of each operation in relation to the manufacturing equipment (ScRsc).
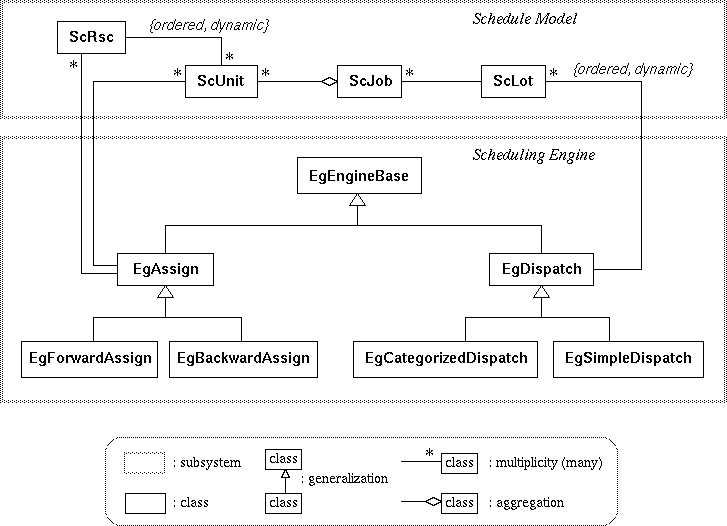
Figure 3: Scheduling engine subsystem
The assignment method (EgAssign) assigns units (ScUnit) to resources (ScRsc), fixing the starting and finishing time of each unit. EgAssign provides primitive inferences common to two assignment methods: a forward and a backward assignment method. The former tries to assign each unit to an appropriate resource as early as possible, up to the earliest starting time, while the latter does the same as late as possible, down to the due date.
The forward and backward assignment methods are fully operationalized in EgForwardAssign and EgBackwardAssign respectively, which are defined as subclasses of EgAssign. Scheduling methods can be customized by overriding the operationalized classes for assignment. For example, the loads of alternative resources can be balanced by redefining an inference for resource selection in a subclass of EgForwardAssign and/or EgBackwardAssign.
The dispatching method (EgDispatch) determines the priority of each lot (ScLot) without regard to actual assignments between units and resources. The most important inference for dispatching is to compare two lots and determine the one with higher priority. Since the comparison employs attributes defined in the schedule model or its project-specific extension, the comparing inference is defined in the schedule model as a member function of ScLot or its project-specific subclass, and is not given within EgDispatch or any of its subclasses in the scheduling engine subsystem.
After the development of two prototype systems with SCOOP, a real-life scheduling system was developed for use in a production line for low-end hard disk drives (2.5 and 3.5-inch HDDs). The plant floor consists of three areas, for assembly, testing, and packing. The difficulty in the production control stems from the uncertainty in the test processes, which is primarily caused by the fluctuating yield, the high-volume outputs, and the variety of product types. The plant is thus continually faced with the tasks of reducing the manufacturing cycle time and achieving punctual delivery to customers. In the spring of 1994, the operation system department started reengineering the manufacturing processes by developing three software systems: a scheduling system for the test area, a shipment control system for the packing area, and a system for tracking work in process (WIP) inventory.
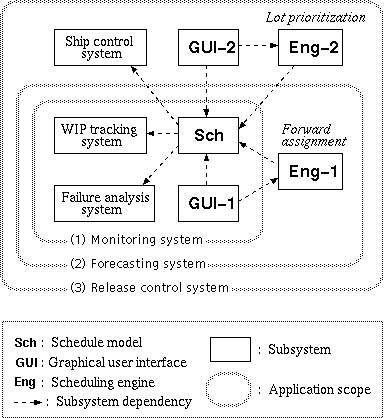
Figure 4: Evolution of a real-life scheduling system
The scheduling system is required to be flexible in controlling
production in response to new demands and variable manufacturing
conditions, and extensible so that it can be installed on the plant
floor incrementally.
However, the plant is already in operation, producing high-volume
daily output. Therefore, it is critical to introduce the new
production operations incrementally, so that floor workers are not
forced to make drastic changes in their daily operations. SCOOP's
extensibility has allowed it to be deployed incrementally in the plant
in Thailand since August 1995, and in another manufacturing plant in
Hungary since July 1996.
The scheduling system has evolved in the manufacturing context,
incorporating additional production data from other information
systems in the plant. Furthermore, collaboration is being tightened
not only with the manufacturing department, which is responsible for
resource utilization, but also with the production department, which
is responsible for meeting customers' deadlines.
The system was extended from a simple configuration without any scheduling method to a configuration with two types of method. From the perspective of the high-level system structure, the configuration of the scheduling system has grown according to the three project cycles, as shown in Figure 4.
The configuration shown in Figure 4(1) realizes a monitoring system that visualizes the actual manufacturing status received from the WIP-tracking system. The role of this progress monitor is to check for and regulate incorrect operations by the floor workers, who manually transport vehicles that carry products from one process to the next. A forecasting system is then realized by integrating a forward assignment method (Eng-1 in Figure 4(2)), in order to forecast the completion time of products in the test area. The forecasting system is invoked automatically every twenty minutes, and the results obtained are reported online to the workers in the packing area.
A release control system is realized by extending the forecasting system with a dispatching method (Eng-2 in Figure 4(3)). The dispatching method dynamically prioritizes the manufacturing lots to be released next to the test area, so that the requests from the production department can be answered on the fly. In contrast to conventional scheduling systems, which create a static schedule for the next day or week, this scheduling system responds to the up-to-date manufacturing progress iteratively in the shorter cycle time. This avoids relying on inaccurate assumptions made in advance, and allows punctual delivery by monitoring the real-time manufacturing performance and packing status.
This section describes the empirical results obtained during the development of the scheduling system for HDD manufacturing. In order to collect empirical data, a complete set of source code is saved when either a major enhancement is made without any application development, or when an application system is released. In addition, a software developer fills in a form listing the coding hours and the type of changes made, which can be either creation, modification, or deletion of code. The models for measuring the size and effort are as follows:
The scheduling system has been developed by a single software developer up to the end of the third cycle. At the beginning of the first cycle, the developer had 9 years of programming experience in Lisp and 3 years of experience in C++. SCOOP was also designed and developed by the same person. Thus, the case presented in this paper is not usual in the sense that the library is reused by the library developer by himself. However, the advantage here is that the collected data are placed in the same context, allowing proper comparison of data collected from different project cycles.
Figure 5 shows the code size of a subsystem as a percentage of the code sizes of all subsystems. In particular, Figure 5(a) shows the proportion in the project-independent portion of the system, which corresponds to the library provided as SCOOP. Figure 5(b), on the other hand, shows the proportion in the project-specific portion of the system, which will not be reused in other projects.
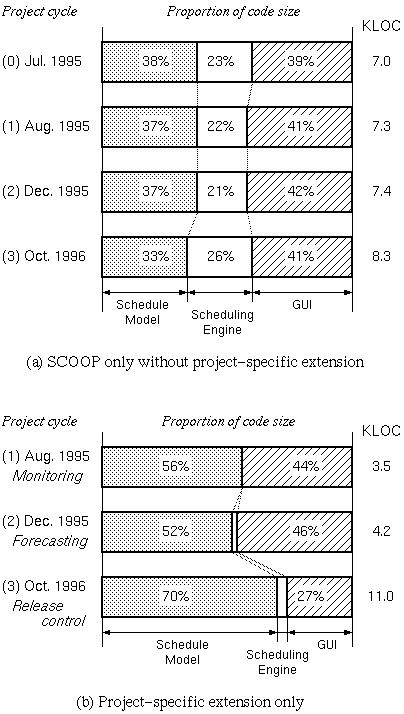
Figure 5: Proportion of code in each subsystem
Figure 5(a) tells us that the relative proportions of the three subsystems were rather stable, except for the growth of the scheduling engine subsystem in the third project cycle. This growth resulted from the addition of a dispatching method, or EgDispatch, and its two subclasses (Figure 3). On the other hand, in the project-specific portion, the subsystem ratio and the total size changed substantially through all the project cycles. This can be further investigated by taking account of the actual code size growth and person-hours spent on the coding (Table 1).
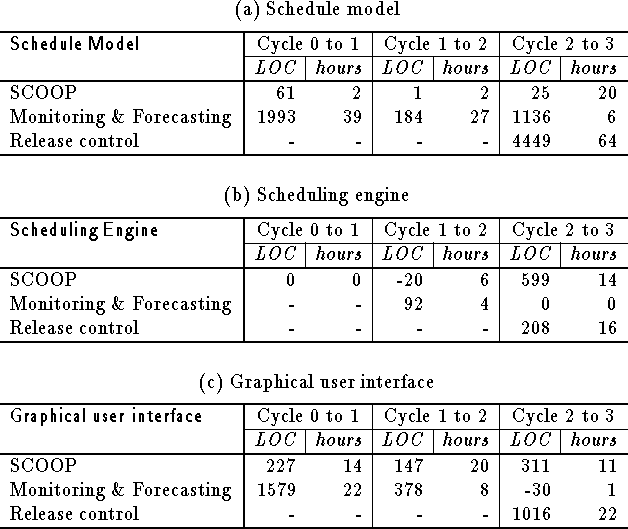
Table 1: Increases in LOC and person-hours between project cycles
After the end of the first project cycle, the project-specific proportion of C++ source code constituted 29% of the entire scheduling system. The proportion further increased to 32% during the second cycle, and reached 48% at the end of the third cycle. The tough question here is to what extent the reused/reusable part of the evolving system should be kept, taking into account not only the maintainability and extensibility of the system at hand, but also the reusability of the library for the development of prospective systems. In the present case, it is possible to further investigate the code size growth in each subsystem.
The code size of the scheduling engine subsystem grew by 37% (599 LOC) after the second cycle (Table 1(b)). This extension, however, has not required any change in the design of the other subsystems. In the scheduling engine subsystem of the final system, the total amount of project-specific code is 300 lines, of which 92 LOC are for the forecasting function and 208 LOC are for the release control function. The assignment method (Eng-1 in Figure 4(2)) was extended to take account of the test failure ratio, by incorporating yield values obtained from the failure analysis system. The dispatching method (Eng-2 in Figure 4(3)) was extended to deal with the project-specific attributes, which are used to prioritize available lots to be released in the test area. Since the code for the project-specific scheduling methods constitutes only 12% of the code for all the scheduling methods in the final system, it is possible to say that the development workload is reduced by reusing methods in the scheduling engine subsystem.
The requirements of the graphical user interface are diverse,
especially when customization for end users is needed.
Although the user interface subsystem was developed by using an
existing library of conventional visual components
such as push buttons, list boxes, and pull-down menus, it is almost
impossible to provide a comprehensive set of components tailored to a
variety of end-users' requirements.
The project-independent portion of the user interface subsystem has
grown by 25% (685 LOC) in code size through all the project
cycles (Table 1(c)). This subsystem is not stabilized
yet, and is likely to be extended by further deployment of SCOOP.
In contrast, the code size of the schedule model has grown by only 3% (87 LOC) through all the project cycles (Table 1(a)). Therefore, it is possible to say that the schedule model is rather stable as compared with the scheduling engine and the user interface subsystems. The schedule model, however, includes a large extension in the project-specific portion, which has grown radically due to the enhancement of the system on the plant floor. The main part of the project-specific extension is for incorporating external data from other information systems such as the shipment control system and failure analysis system (Figure 4). The other extension is to elaborate the concepts in the schedule model, so that project-specific attributes and their access procedures can be provided to deal with external data.
Since we have collected data on the person-hours spent on coding, as well as the code size growth, it is possible to investigate issues related to productivity. Productivity is generally defined as the rate of output per unit of input. Intuitively, the notion of productivity includes the contrast between the inputs and outputs of a process. However, measuring the productivity of a software engineer or a software engineering process is more elusive. We must carefully define what constitutes a set of inputs, how a process affects the inputs, and what a suitable unit of output is [Shepperd, 1995, Fenton and Pfleeger, 1997].
The most common productivity measure is defined as size divided by effort. In the case at hand, we measured the size in lines of code, and the effort in person-hours spent on coding. Therefore, it is possible to calculate the productivity of the software developer by dividing the LOC by the person-hours. Since the number of data in Table 2 is rather small, it is hard to generalize the results at present. But it can be observed from the table that the LOC/hours ratios in the project-independent portion of the subsystems for the schedule model and the graphical user interface are relatively low. One possible reason for this result is that the modification of the project-independent, or reusable, portion of knowledge systems includes frequent insertion and deletion of small fragments of code, and that such an exploratory process rarely results in a substantial growth in code size. Another reason is that such modifications require more time to test before release, not only for the system at hand but also for other prototype systems used as test cases.
As for the scheduling engine subsystem, a dispatching method is added to the subsystem during the third project cycle, and the fundamental problem-solving steps are completely different from those for the assignment method. Therefore, a possible interpretation is that the productivity was relatively low (13.0) in comparison with other modifications for the scheduling engine subsystem.
The person-hours spent on realizing the project-specific portion of the scheduling methods accounted for only about 10%, or 20 hours (4 hours for the forecasting function and 16 hours for the release control function) of the total coding hours (209 hours) for the project-specific portion throughout the three project cycles. The scheduling methods in the library thus reduced the workload involved in developing the scheduling system. However, another 20 hours were spent on modifying the project-independent portion of the scheduling engine subsystem in parallel with the SCOOP-based development of an application system.
It must be noted here that the scheduling system reported here has been developed by a single software developer, who also designed and realized SCOOP. Needless to say, it will take more time to maintain SCOOP the application programmer is different from the library designer, because it is usually very difficult for the application programmer to refine the library due to the unavailability of the relevant documents and specifications.
Besides the scheduling engine subsystem, the rest of the coding hours was spent on specializing the schedule model (136 hours) and developing the graphical user interface (53 hours). Specialization of the schedule model took up about 65% of the total coding hours for the project-specific portion (209 hours). The specialization consisted mainly of incorporating information from external data servers. This exactly reflects the observation by van Heijst et al., that the world is filled with knowledge bases and databases which are not developed with that purpose in mind [van Heijst, Schreiber, and Wielinga, 1997, p. 287,].

Table 2: Ratios of LOC/hours through all the project cycles
Moderate stability is an essential feature of reusable knowledge, but empirical studies are needed to draw up practical guidelines for designing reusable libraries. In our experience, 30% (89/298) of the total coding hours were spent on modifying the library. Although an in-depth discussion is beyond the scope of this article, it is probable that modification of a reusable library will occur in parallel with development of a knowledge system. Furthermore, such modification could happen repeatedly in the maintenance of the system.
Finally, we must be very careful in dealing with the productivity measure used here, because it takes account only of lines of code divided by coding hours, without regard to the quality or creativity of the development process. It is as if we were to measure the productivity of poets by computing the number of words or lines they produced and dividing by the number of hours they spend writing [Fenton and Pfleeger, 1997, pp. 409-410,].
Research efforts in knowledge engineering have been more or less directed by the knowledge-level hypothesis that advocates the behavior of a rational agent independently of particular implementational formalism [Newell, 1982]. As a result, a variety of knowledge-level models have been proposed in the research community. This demonstrates that the constituents of problem-solving knowledge can be common to a variety of knowledge systems at the conceptual level, regardless of their implementational details. However, it does not necessarily mean that such knowledge can be actually reused with operational extension in real life. An assumption shared with that approach is the notion of the structure-preserving design [Schreiber, 1993], in which the information content and structure of the knowledge model are preserved in the final artifact. In terms of software measurement, this is related to structure measures rather than code measures. The structure measures view a product as a component of a larger system and focus on the interconnection between software components, while the code measures have no concern with interconnection.
It is pointed out that a qualitative conceptual model may fail to keep desirable properties such as testability and maintainability, as results of investigation of search-space tractability from a graph-theoretic perspective [Menzies, Cohen, and Waugh, 1998]. Besides the search space structure, however, there are other possibilities of conceptual structures that can be preserved without serious impediments in an implementational structure. Structuredness is an issue to be further elaborated considering different granularity of constructs, such as at the levels of subsystems, individual concepts, and primitive operations. We are going to further investigate the structuredness of SCOOP by using coupling and cohesion measures [Hori, 1998], which are defined on the basis of a model of modular system [Briand, 1996], and measurement viewpoints advocated in [Chidamber and Kemerer, 1994]. These measures are to be put under the first question in Figure 1.
The design process can be subdivided into two design steps: architectural or high-level design, which involves identifying software components and their interconnections, and algorithmic design, which involves identifying the control flow and data structures within architectural components [Rombach, 1990]. One of the limitations of design measures is that possible dynamic behaviors of a system cannot be captured. However, the potential benefit is that they can be measured independent of any particular implementation, especially before the start of coding. In order to characterize a library of problem-solving knowledge, it is necessary to think about an additional question in the GQM hierarchy; namely, whether architectural design information has more influence on the applicability of a knowledge library than algorithmic design information.