Ripple Down Rules with Formal Concept Analysis:
A Comparison to Personal Construct Psychology
Debbie Richards
Department of Artificial Intelligence
School of Computer Science and Engineering
University of New South Wales
Sydney, Australia
Email: {debbier}@cse.unsw.edu.au
Abstract: The acceptance that models are problematic
and the use of simple techniques for eliciting knowledge directly from
an expert without the mediation of a knowledge engineer by both Personal
Construct Psychology (PCP) and Ripple-Down Rules (RDR) means that the two
approaches share a common philosophical basis that is not shared by most
mainstream knowledge based system (KBS) research. With the recent enhancement
to multiple classification RDR which uses formal concept analysis to derive
a subsumption hierarchy of the concepts that exist implicitly in our RDR
KBS we now have a counterpart to the PCP based intensional logics and visual
language work. This paper looks in detail at both RDR and PCP comparing
and contrasting the two approaches and concludes that the two approaches
are complementary.
1 Introduction
2 An Overview of Knowledge Acquisition with Personal Construct Psychology
3 An Overview of Knowledge Acquisition with Ripple Down Rules
3.1 Formal Concept Analysis and Deriving an MCRDR Concept Lattice
4 A Comparison Between PCP and RDR
4.1 The Importance of Context and Cases
4.2 Logical Foundations, the Visual Language and Implications
4.3 Feedback and Analysis
4.4 Validation and Maintenance
4.5 The Knowledge Acquisition Process
5 Conclusion and Future Work
As humans in general and AI researchers in particular we are interested in understanding and representing conceptual models. Gaines and Shaw (1993a) describe this interest as the key difference between knowledge engineering and software engineering and is based on the stress knowledge engineering places on the use of the human expert as the source of information and the use of a knowledge representation schema for implementation. Ripple-Down Rules (RDR) research has focused on building knowledge based systems (KBS) that exhibit expert behaviour without committing to the debate on how the task is being achieved by the expert or trying to capture the conceptual model of the expert. Our main reasons for this approach are the inherently unreliable nature of models (Clancey 1991, Gaines and Shaw 1989) and the situated nature of expertise and human action (Clancey 1997, Collins 1997). Approaches based on Personal Construct Psychology (PCP) (Kelly 1955) also do not commit to how the human reasoning is being done. Gaines and Shaw only accept that elicitation allows self-modelling and the "tacit knowledge" acquired is "a theoretical construct imputed to an agent displaying intelligent behaviour by an observer" (Shaw and Gaines 1991, p.13). Gaines and Shaw point out that coming to terms with understanding and encoding the way that experts think is problematic and that we need to learn a lot more about how the mind works before such questions can be answered.
The acceptance that models are difficult and the use of simple techniques
for eliciting knowledge directly from an expert without the mediation of
a knowledge engineer (KE) by both PCP and RDR suggests that the two approaches
share a common philosophical basis that is not shared by most mainstream
KBS research. The interest in cases and the use of difference lists in
RDR and the dichotomy corollary of PCP are further similarities between
the two. More recently we have employed formal concept analysis (FCA) (Wille
1982) to allow us to develop a subsumption hierarchy of the concepts that
exist implicitly in our RDR KBS. Thus, we now have a counterpart to the
intensional logics and visual language (Gaines 1991b) supported by PCP.
The ability to derive a concept hierarchy using FCA from RDR KBS has been
important to improve the understanding of relationships between concepts
and the finding of higher level abstractions. Understanding relationships
and abstractions supports reuse of knowledge captured for one purpose such
as consultation for a different purpose such as explanation or teaching.
This paper looks in detail at RDR, including the incorporation of FCA into
RDR, and PCP comparing and contrasting the two approaches. In the next
two sections we describe knowledge acquisition (KA) with both approaches.
In Section 4 we make a comparison from a number of viewpoints. In Section
5 other related work is considered with a few remarks concerning future
work.
2 An Overview of Knowledge Acquisition with Personal Construct Psychology
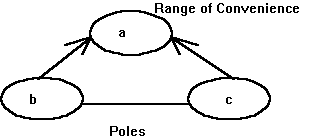
Kelly (1955) found that patients were able to describe what was different between situations or people without being able to formally describe their mental state. In the theory, people develop "personal constructs" or templets through which they anticipate (which is used to include understand, predict and control) the world (Shaw and Gaines 1992). In accordance with Kelly's geometrical perspective he sees that humans classify elements, which can be seen as examples, and place them in a psychological space. They do this using their constructs which provide a bipolar axis of reference by which people are able to differentiate between elements. The range over which a construct can be used is known as the range of convenience.
Figure 1: The Triple of Distinctions Generating a Construct (Shaw and Gaines 1991)
Gaines and Shaw have developed a logic and visual language based on
the geometry which is briefly described here and in more detail in section
4. Kelly's notion of a personal construct can be represented by the above
structure which is a triple of two disjoint distinctions that are mutually
subsumed by a third. The non-directional line between b and c
shows that b and c are disjoint and form the poles of the
construct. The arrows pointing from b and c to a indicates
that a subsumes both concepts. Since a subsumes a dichotomy
it is the range of convenience.
As a means of acquiring the relevant constructs and elements, Kelly developed
the repertory grid technique. The expert is asked simple questions that
indicate how well each construct fits each member of the solution set.
The repertory grid is a way of finding concepts, their structures and relationships
between them without directly eliciting them (Gaines and Shaw 1993a), as
shown in Figure 2. They can be more successful than attempting to directly
elicit a model because:
"The repertory grid was an instrument designed by Kelly
to bypass cognitive defences and give access to a person's underlying construction
system by asking the person to compare and contrast relevant examples"
(Gaines and Shaw 1993a, p.52).
The repertory grid in Figure 2 includes five constructs and three
elements using the contact lens prescription domain which we use in a number
of further examples to aid in comparison of the various representations
of this knowledge shown in this paper.
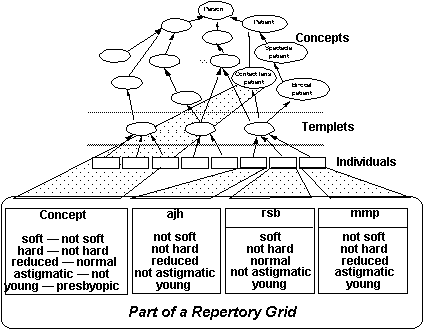
Figure 2: The repertory grid as a matrix of
concepts, individuals and constraints
(Shaw and Gaines 1992)
The repertory grid technique has found widespread success and continues
to be used both in manual and computerised form (Beail 1985) by educationalists,
clinical psychologists and managers (Shaw 1980). A number of systems have
been built based on Kelly's ideas such as Knowledge Support System Zero
(KSS0), Expertise Transfer System (ETS) and AQUINAS. Gaines and Shaw (1993a)
offer the following general framework to assist the elicitation of conceptual
structures using repertory grids. The particular supporting tool in KSS0
is given in brackets after the general description.
It is clear from the above framework that feedback and alternative views
of the conceptual models derived are integral . The range of different
ways of looking at the concepts helps to "maintain the expert's interest
and to explore his or her psychological space" (Gaines and Shaw 1993a,
p.71). The KSS0 system is non-modal so that the user can move to whatever
part of the system as they choose. In summary,
"The psychology has the advantage of taking a constructivist
position appropriate to the modelling of specialist human knowledge, but
basing this on a positivist scientific position that characterises human
conceptual structures in axiomatic terms that translate directly to computational
form" (Gaines and Shaw 1993a p. 82).
3 An Overview of Knowledge Acquisition with Ripple Down Rules
RDR was first developed to handle single classification problems and
has been successfully used in a number of applications, the most noted
one being the Pathology Expert Interpretative Reporting System (Edwards
et al 1993) that went into routine use in a large Sydney hospital with
198 rules in 1990 and grew on-line to over 2000 rules over the next four
years. It was maintained by the expert and with each rule taking about
three minutes to add represents approximately 100 hours of development
time. Much of the discussion in this paper refers to our newer implementation,
multiple classification RDR (MCRDR) (Kang, Compton and Preston 1995, Kang
1996) since the ability to provide multiple conclusions for a given case
is more appropriate for many domains and, more importantly, because the
problem of how to handle the false "if-not" branches (Richards,
Chellen and Compton 1996) does not exist. MCRDR has
also been shown to produce somewhat more compact knowledge bases with less
repetition than RDR even for single classification domains, probably because
more use is made of expertise rather than depending on the knowledge base
(KB) structure (Kang 1996). An MCRDR is defined as the triple <rule,C,S>,
where C are the children/exception rules and S are the siblings. All siblings
at the first level are evaluated and if true the list of children are evaluated
until all children from true parents have been exhausted. The last true
rule on each pathway forms the conclusion for the case. This approach allows
for n-ary trees, but as can be seen in Figure 3 an MCRDR KBS can be seen
as a flat rule structure, where all rules are evaluated against the data.
It is this flat rule structure which allows it to map into FCA so well
as described in the next subsection.
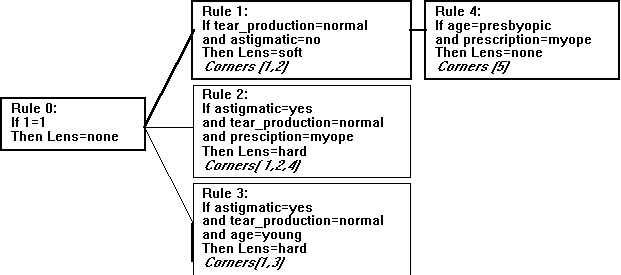
Figure 3. An MCRDR KBS for the Contact Lens Prescription Domain.
The highlighted boxes represent rules that are satisfied
for the case {age=presbyopic, prescription=myope, astigmatic=no, tear_production=normal}.
The classification given is Lens=none. As this domain only deals with mutually
exclusive conclusions we only get one conclusion, but if the domain was
extended to cover spectacles and bifocals then this case could lead to
multiple conclusions being given.
KA with MCRDR is similar to KA using single classification RDR.
As shown in Figure 4 we start with an empty KB. Knowledge is acquired by
running a case, that is the user performs an inference on a particular
case. If the user does not agree with the recommendation given they select
which conclusion/s to add or stop and then develop a rule for each of these
changes.
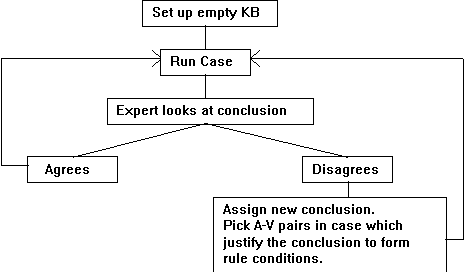
Figure 4: The KA Process in RDR.
The case that prompts one or more new rules to be added is stored in association with those rules and is referred to as the cornerstone case. When a new rule is added, all cases associated with the KBS which could reach this rule, are shown to the user and the user must develop a rule that distinguishes between the current case and all the stored cases. This is done by first constructing a rule which distinguishes between the new case and one of the stored cases. If other stored cases satisfy the rule, further conditions are required to be added to exclude a further case and so on until no stored cases satisfy the rule.
The knowledge being captured represents the operational knowledge and is equivalent to an assertional (A-box) performance system that can be executed. RDR KBS are atypical from most rule-based systems due to their exception structure and the absence of abstraction or intermediate and control rules. Each rule represents a primitive concept. We have recently developed a method for deriving a terminological KBS (T-box) from our MCRDR A-Box using FCA, which we describe next.
3.1 Formal Concept Analysis and Deriving
an MCRDR Concept Lattice
Formal Concept Analysis, first developed by Wille (1982), is a mathematically
based method of finding, ordering and displaying formal concepts (Wille
1992). A concept in FCA is comprised of a set of objects and the set of
attributes associated with those objects. The set of objects forms the
extension of the concept while the set of attributes forms the intension
of the concept. Knowledge is seen as applying in a context and can be formally
defined as a crosstable as in Figure 5 below. The rows are objects and
the columns are attributes. An X indicates that a particular object has
the corresponding attribute. This crosstable is used to find formal concepts.
We interpret an MCRDR KBS as a crosstable by treating each rule pathway
(which includes the conditions on parent nodes) as an object and the conditions
as attributes. The MCRDR KBS in Figure 4 has been converted to a crosstable
in Figure 5.
| 1=1 | astigmatic = no | tear_production= normal | age = presbyopic | prescripton = myope | astigmatic = yes | age = young | |
| 1-%LENSN | X | ||||||
| 2-%LENSS | X | X | X | ||||
| 3-%LENSN | X | X | X | X | X | ||
| 4-%LENSH | X | X | X | X | |||
| 5-%LENSH | X | X | X | X |
Figure 5: Context of "MCRDR Contact Lens Rules"
The following description of FCA follows Wille (1982) and the screen dumps shown in Figures 6 and 7 are our implementation, called MCRDR/FCA, which is an enhancement of the current MCRDR for a Windows system. A formal context (K) has a set of objects G (for Gegenstande in German) and set of attributes M (for Merkmale in German) which are linked by a binary relation I which indicates that the object g (from the set G) has the attribute m (from the set M) and is defined as: K = (G,M,I). Thus in figure 5 we have the context K of "MCRDR contact lens rules" with G = {0-%LENSN, 1-%LENSS, 2-%LENSN, 3-%LENSH, 4-%LENSH}, where the object is referred to by the rule number and its conclusion, and M = {1=1, astigmatic=no, tear_production =normal, age=presbyopic, prescription=myope, astigmatic=yes, age=young}. Note: 1=1 is the condition for the default rule with the default conclusion as was seen in Figure 3. The crosses show where the relation I exists, thus I = {(0-%LENSN,1=1), (1-%LENSS,1=1), (1-LENSS, astigmatic=no),�,(4-%LENSH, age=young)}.
A formal concept is a pair (X,Y) where X is the extent, the set of objects, and Y is the intent, the set of attributes, for the concept. The derivation operators:
X![]() X' :={m M | gIm for all
g
X' :={m M | gIm for all
g ![]() X } (1)
X } (1)
Y![]() M:
Y
M:
Y ![]() Y' :={g G | gIm for all m
Y' :={g G | gIm for all m![]() Y}
(2)
Y}
(2)
are used to construct all formal concepts of a formal context, by finding
the pairs (X'',X') and (Y',Y''). We can obtain all extents X' by determining
all row-intents {g}' with g ![]() G and then finding all their intersections using (3). Alternatively Y'
can be obtained by determining all column-extents {m}' with m
G and then finding all their intersections using (3). Alternatively Y'
can be obtained by determining all column-extents {m}' with m ![]() M
and then finding all their intersection (4). This is specified as:
M
and then finding all their intersection (4). This is specified as:
X'
= ![]() ' (3) Y'
=
' (3) Y'
= ![]() '
(4)
'
(4)
Less formally, in Figure 6 nine formal concepts have been derived for the formal context in Figure 5 by finding the intersection of sets of attributes for each object and then finding the sets of objects that have those attributes.
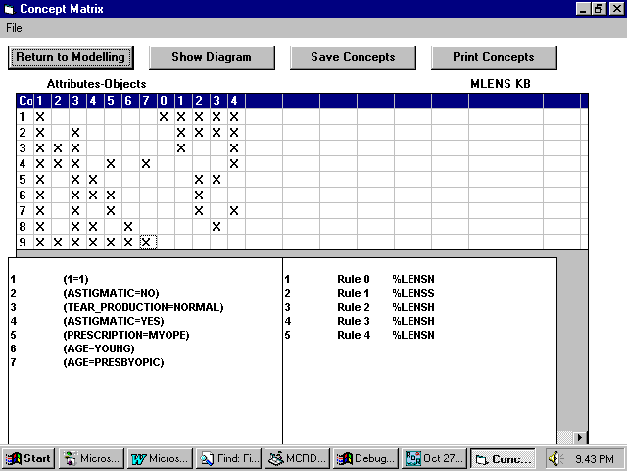
Figure 6: The concept matrix screen from MCRDR/FCA.
Nine (9) concepts have been found. Each row represents a concept. The columns show the attributes, which are listed first, followed by the objects. As was shown in the formal context in Figure 5, there are seven attributes and five objects. The attribute labels have been converted to sequential numbers and the object labels correspond to the rule number to allow the relationships between concepts and the possible patterns to be more readily seen. Full labelling can be obtained by using the pop-up windows as shown in this figure or by clicking on the attribute, object or concept number. The concepts have been ordered to show the subsumption relations that exist. The extent of the top concept, No 1, includes all objects. The intent of the bottom concept, No 9, includes all attributes.
To present a visualisation of our ordered set of concepts as a line diagram it is necessary to compute the predecessors and successors of each concept. Predecessors are found by determining the largest subconcept of the intents for each concept. Successors are found by determining the smallest superconcept of the intents. A superconcept is a set that has all of the members of another set and additional members. A subconcept is a set that has fewer members than another set but all the members it has are contained in the other set. We only concentrate on finding sub or super concepts of the intents or extents because they are inversely related and using either set will give the same result. In MCRDR/FCA the successor list was used to identify concepts higher in the diagram, the parents, and the predecessor list identified concepts lower in the diagram, the children. The number of levels of parents and children are used to layout the line diagram and an algorithm is given in Richards and Compton (1997b). However, just as users have different views of their knowledge, there is not one fixed way of drawing line diagrams and often a number of different layouts should be used (Wille 1992).
More formally, we use the subsumption relation![]() on the set of all concepts formed such that (X1,Y1)
on the set of all concepts formed such that (X1,Y1)
![]() (X2,Y2)
iff X1
(X2,Y2)
iff X1 ![]() X2. From Lattice Theory, the ordered concept set can be used
to form a complete lattice, called a concept lattice and denoted (K).
For a family (Xi,Yi) of formal concepts of K
the greatest subconcept, the join (5), and the smallest superconcept, the
meet (6), are respectively given by:
X2. From Lattice Theory, the ordered concept set can be used
to form a complete lattice, called a concept lattice and denoted (K).
For a family (Xi,Yi) of formal concepts of K
the greatest subconcept, the join (5), and the smallest superconcept, the
meet (6), are respectively given by:
![]() (Xi,Bi):=
(Xi,Bi):=
![]() (5)
(5) ![]() (Xi,Bi):=
(Xi,Bi):=
![]() (6)
(6)
In Figure 7 the concepts are shown as small circles and the sub/superconcept relations as lines. Each concept has various intents and extents associated with it. The labelling has been reduced for clarity by removing all attributes that can be reached by ascending paths and all objects that can be reached by descending paths from the concept . In MCRDR\FCA it is possible to display the concept, attribute/s or object/s belonging to each node or all three dimensions can be displayed concurrently, as in Figure 7.
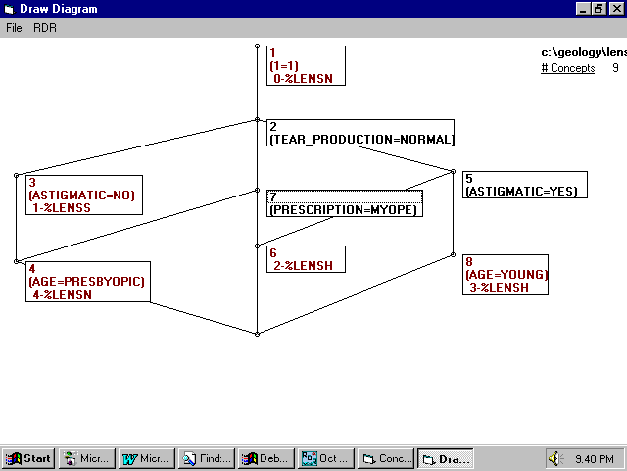
Figure 7: The Diagram Screen in MCRDR/FCA which shows the Concept Lattice for the Formal Context " MCRDR Contact Lens Rules" given in Fig. 5.
Our incorporation of FCA into RDR has provided a powerful tool for browsing the knowledge base providing explanations of the knowledge in terms of relationships between primitive concepts and higher level concepts which were previously hidden in the RDR structure. This means that RDR is able to support a wider range of activites beyond those for which it had typically been used.
4 A Comparison Between PCP and RDR
In this section we compare PCP and RDR together with some comments regarding FCA. While FCA is not the main focus of this paper its compatibility with the two approaches is interesting and confirms the suitability of combining the techniques.
PCP and RDR offer alternative simple ways of acquiring knowledge accessible to an end-user. However, the nature of the knowledge that is captured is different. As mentioned earlier, the RDR technique develops an assertional KBS or A-box. Using FCA we derive a terminological or T-box KBS using the MCRDR A-Box. PCP has a different starting point. PCP captures a conceptual model from which a terminological KBS is extrapolated. This terminological KBS provides an anticipatory system for the computer, in keeping with Kelly�s view of humans as anticipatory systems. In some of the computer implementations of PCP, Induct is used to derive an A-box from the T-box developed using the repertory grid technique. Regardless of the different starting points, both approaches differ greatly from current approaches that look at building terminological KBS using ontologies (Guha and Lenat 1990, Patil et al 1991, Pirlein and Struder 1994) or general problem solving methods (Chandrasekaran and Johnson 1993, Schreiber, Weilinga and Breuker 1993, McDermott 1988, Steels 1993, Puerta et al 1992).These latter approaches place emphasis on complex modelling as a prerequisite to the capture of domain knowledge which also necessitates using a KE as an intermediary between the expert and the computer. The strength of systems built on PCP is the assistance they give the expert to understand the concepts and relationships of the knowledge they are dealing with, without having to explicitly describe their conceptual or problem solving model and the ability to directly interact with the system without a KE. Similarly the strength of systems built using RDR is the ease and intuitiveness of simply assigning a conclusion and picking some relevant features without the need for a KE.
Just as systems built on PCP and RDR share similar strengths they also
suffer from similar limitations. It has been found that ETS and a descendant
system KAQ was limited to classification problems and it was also difficult
to extract causal, procedural or strategic knowledge (Boose et al 1989).
Current research using MCRDR for construction addresses this first problem
and work by Lee and Compton (1995) has looked at deriving causal explanations
from RDR KBS. Since RDR and PCP aquire the same type of knowledge, although
the knowledge is used differently, it is expected that PCP could be adapted
in a similar manner to RDR to handle configuration problems.
4.1 The Importance of Context and Cases
PCP, RDR and FCA place a strong emphasis on the importance of knowledge in context, a view supported by much of the knowledge reuse community (Guha and Lenat 1990, Patil et al 1992). Context is used in KSS0 to focus attention in the elicitation process. FCA is also:
"guided by the conviction that human thinking and communication always take place in contexts which determine the specific meaning of the concepts used" (Wille 1996, p. 23).
The RDR focus on context is based on a socially situated view of knowledge. Compton and Jansen (1990) found that experts do not offer explanations of why they made a decision rather they offer a justification and that justification will depend on the audience to which it is directed. Context in RDR is supported by the exception structure and storing of cornerstone cases. Kelly's view of templets and the construction corollary reveals a situated view of the way humans perceive events:
"Man looks at his world through transparent templets
which he creates and then attempts to fit over the realities of which the
world is composed" (Kelly 1955, pp.8-9).
The construction corollary states: "a person anticipates events by
construing their replications (Kelly 1955)".
The sociality corollary, which states:
"to the extent that one person construes the construction processes of another, he may play a role in a social process involving another person" (Kelly 1955).,
does not place as much stress on the impact of social influences on human action compared to the socially situated view of human action. However, Kelly does go on to say that the role a person plays is:
"an ongoing pattern of behaviour that follows from
a person's understanding of how the others who are associated with him
in his task of thinking" (Kelly 1955 in Shaw 1980, p.22).
In a similar vein, PCP, RDR and FCA do not consider the knowledge
captured to be globally applicable but relevant or 'convenient' within
the given context as discussed in the range corollary:
"a construct is convenient for the anticipation of
a finite range of events only" (Kelly 1955).
Another key similarity between all three approaches is the use of
cases or examples to elicit knowledge. Cases are beneficial because:
"from a psychological point of view, cases are abstractions
of events or processes with temporal and spatial tabs �[and] are models
of the original experience" (Woodward and Shaw 1993, p 13-8).
In the repertory grid technique stereotypical cases are seen as
a critical part of eliciting conceptual models and a good set of cases
will lead to a good and compact set of rules. Repertory grids assume that
people are better able to offer good examples than define some globally
applicable rules or heuristics. In stereotypical cases there is less likelihood
of non-significant attributes. The cases used by RDR tend to be historical
or actual cases which clearly have irrelevant attributes. Thus, although
each case that prompts a rule to be added is stored, no claim is made regarding
the significance of that case. It is acknowledged that if a "good"
representative set of cases exists then the KBS can be built quicker and
will mature sooner, although if there are sufficient cases it may be better
to make use of a suitable machine learning algorithm for KA. In RDR the
cases are being used to assist the user to define the key features of the
case, whereas in PCP the user is asked to define these features without
being prompted by a case. In the case of PEIRS the use of actual cases
was natural because they were available and the problem was to add an interpretation
to them. The view of cases in PCP and FCA is more alike and there is a
similarity between the PCP repertory grid and the FCA crosstable. We can
view the constructs and elements in PCP as analogous to the attributes
and objects in FCA, respectively. In FCA the use of cases is similar to
that of PCP, that is to uncover a conceptual model and derive some implications.
In RDR the purpose is to acquire rules which we later use to derive the
conceptual model using FCA.
In all approaches, cases assist the user in defining properties that
allow cases to be distinguished from one another. In PCP triadic elicitation
requires the user to add constructs which describe how two elements are
alike and how the third element differs. In RDR difference lists are used
to assist the user with picking features in a case that differentiate between
the current case and the cornerstone case associated with the rule that
gave the misclassification. In PCP it is necessary to look at the overall
clusters. In RDR the concern is with individual cases. The role of cases
in providing an extensional definition for a concept in FCA and PCP is
discussed in the next section where we look at how the logical foundations
and visual language based on PCP compares with the concept matrices and
lattices developed using FCA.
4.2 Logical Foundations, the Visual Language
and Implications
Gaines and Shaw state:
"there is a very direct relationship between the psychological
conceptual structures presupposed in personal construct psychology and
those implemented in term subsumption logics, and this is highly significant
in supporting expertise transfer as a process of modelling the basis of
human skilled performance in operational terms " (Gaines and Shaw
1993a, p.51.
Shaw and Gaines further describe Kelly's geometry as:
"an intensional logic, one in which predicates are defined
in terms of their properties rather than extensionally in terms of those
entities that fall under them" (Shaw and Gaines 1994, p. 259).
Kelly's notion of a distinction may be used to carve out regions of psychological
space that can be compared to regions carved out by other distinctions
according to the subsume and disjoint relations, briefly mentioned in section
2 and shown in Figure 1. The subsumption relation is asymmetric and transitive
and supports Kelly's organisation corollary which states:
"each person characteristically evolves, for his convenience of anticipating events, a construction system embracing ordinal relationships between constructs" (Kelly 1955).
and provides a partial ordering of distinctions (Shaw and Gaines 1991).
As described in section 3.1, FCA uses the subsumption relation to order
the set of all concepts. In FCA concepts that can be reached by ascending
or descending paths can be compared in terms of the subsumption relation.
In the intensional logic developed for PCP, the intersections of primitive
concepts form non-primitive concepts from which the subsumption relation
may derived. In our approach the MCRDR rules are the primitive concepts
and using FCA we find the intersections of sets of attributes and the set
of objects that share those objects form our non-primitive higher-level
concepts. These higher level concepts in our implementation MCRDR/FCA can
be labelled by the user if they wish and combined with the primitive concepts
to form the concept lattice. Similarly, Kelly describes the intersection
of sets of attributes as part of his theory of anticipation:
"What one predicts is not a fully fleshed-out event,
but simply the common intersect of a set of properties" Kelly 1955).
Like the concept lattice derived using FCA, a semantic network or
overall task or domain ontology can be found by determining the ordinal
relations between concepts derived from the constructs and elements in
PCP (Gaines and Shaw 1993a). Gaines and Shaw (1993a) further point out
the 'is-a' relation may be computed for non-primitive concepts whereas
the 'is-a' relation is defined for primitive concepts.
Kelly's dichotomy corollary:
"a person's construction system is composed of a finite number of dichotomous constructs" (Kelly 1955).
is supported by the disjoint relation which is a symmetric relation.
It is asymmetrically defined because the sequence in which terms have been
defined may result in reference to an undefined term (Shaw and Gaines 1991).
In geometrical terms a disjoint relation occurs where regions do not overlap.
In FCA the disjoint relation can be seen as (X1,Y1)
![]() (X2,Y2)
= 0. In terms of the concept lattice a disjoint relation between two concepts
exists where paths of the two concepts do not intersect. Note that although
all paths intersect at the top or bottom concept the intersection set may
have no members.
(X2,Y2)
= 0. In terms of the concept lattice a disjoint relation between two concepts
exists where paths of the two concepts do not intersect. Note that although
all paths intersect at the top or bottom concept the intersection set may
have no members.
From Gaines and Shaw (1993a), using the subsume and disjoint relations
four possible binary relations can be formed: a![]() b,
b
b,
b![]() a, a__b
, or none of these. If the two subsumption relations hold they form an
equivalence relation on distinctions. The disjoint relation is inherited
through subsumption so that:
a, a__b
, or none of these. If the two subsumption relations hold they form an
equivalence relation on distinctions. The disjoint relation is inherited
through subsumption so that:
a__b and c![]() a
a
![]() c__b
c__b
These relations are also present in the FCA concept lattice. An equivalence
relation would be shown as a merged concept where the intent includes all
the attributes of the two concepts and the extent covers all the objects
associated with the two concepts. The inheritance of disjoint relations
via subsumption is obvious since any concept that subsumes another will
also be disjoint from any concepts from which a subsumed concept is disjoint.
For example, in Figure 7 concept 8 is disjoint from concepts 3 and 4. Concept
8 is subsumed by concept 5 which is also disjoint from concepts 3 and 4.
Shaw and Gaines (1991) state:
"a visual language that is both comprehensible and formal
offers attractive possibilities not only for the comprehension but also
for the editing, and for parts of the elicitation process itself"
(Shaw and Gaines 1991, p.9).
As can be seen in Figure 8, the visual language mentioned in Section
2 offers a graphic representation of the subsume and disjoint logical relations.
The concept lattice is the visual counterpart in FCA. Both approaches seek
to tap into the psychological benefits associated with graphics and that
of semantic networks in particular. The concept lattice structure can offer
more than a semantic net because it provides:
"hierarchical conceptual clustering of the objects (via
the extents) �. and a representation of all implications between the attributes
(via its intents)" (Wille 1992, 497).
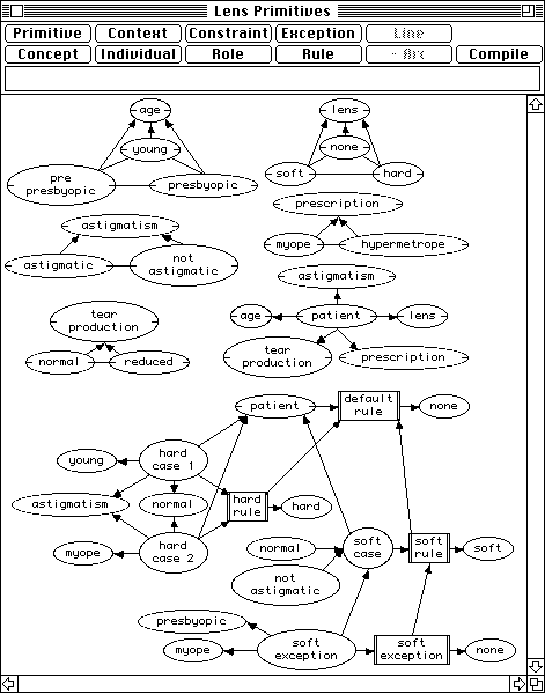
Figure 8 Contact Lens Domain and Rules Represented in the Visual Language (Gaines and Shaw 1993)
Shaw and Gaines (1991) make the point that such a representation is not
unlike other work, such as that by Cruse, that manually produces diagrams
but that the computational representation allows deductive inference as
well as graph-theoretic analysis. However, it is noted that the use of
anticipations as rules to support inferencing is not a necessary but a
possible relation. In FCA through the techniques known as attribute (Wille
1989) and concept exploration (Stumme 1997) it is also possible to derive
implications. However, concept exploration is still under investigation
and both techniques can be time-consuming for the user requiring a process
of evaluating, accepting or rejecting possible implications and the offering
of suitable counterexamples if the implication is rejected. In RDR we are
not using the concept lattice to derive rules but as an alternative higher-level
model of the rules we already have. The RDR approach to capturing rules
may be more manageable for the user than the definition of counterexamples.
A major difference between the KL-ONE (Brachman 1979) like approach used
by Gaines and the use of FCA is that FCA also describes concepts extensionally.
This aspect has been criticised since an intensional definition implies
an extensional definition but the converse is possibly but not necessarily
true (Zalta 1988). We agree that the extensional definition is problematic
and too restrictive for some uses such as when we use the concept lattice
to assist KA and validation of new concepts (Richards and Compton 1997a).
In keeping with our lack of commitment to developing globally applicable
rules:
"Extensional forms such as "for all" are avoided
because it is not reasonable to assume that statements can be made about
an indefinite extension whose members are not yet identified and may never
be known" (Shaw and Gaines 1991a, p. 5).
However, in a given context we also agree:
"if two distinctions have the same extension it may
be regarded as evidence that they have the same intension" (Shaw and
Gaines 1991a, p.15)
Shaw and Gaines admit, as does the author, that such a hypothesis
is flawed and suggest that the information contained in the extension is
worth considering but with reservation. Similarly, the use of cases requires
that we approximate the subsume and disjoint relations based on the intensional
properties of the cases, or objects. We can only approximate:
"because of the one way implication between intensional
subsumption and extensional inclusion in an open world context, or, in
psychological terms, that past behaviour is only an indicator, not a determiner,
of future commitments" (Shaw and Gaines 1991a, p.14).
Much KBS research has shown that it is important to understand the conceptual
structures that underlie expertise and is explained by:
"If the person becomes more aware of the structure and
organisation within the structure he becomes more able to make adequate
predictions and act according to them" (Shaw 1980, p.7).
Feedback is a key element in supporting KA so that the knowledge can be
verified and validated "at every stage of development" (Gaines
and Shaw 1993a, p.51). This is one of the strengths of computerised over
manual repertory grid methodologies (Shaw and Gaines 1991). However, it
is not just the automation of the approach but the use of value-added tools
such as FOCUS, Princom and Socio in KSS0 that provide "a deeper understanding
and a reconstruction of a person's system" (Shaw 1980, p.149). The
importance of feedback is demonstrated in the benefits of PEGASUS over
MIN-PEGASUS which automated the repertory grid but didn't provide feedback
and analysis tools (Shaw 1980). While a person can offer feedback there
is a danger of interpersonal interactions that may bias or distort the
results. The FOCUS work aims:
"to comply with the spirit of psychologists such as
Rogers and Kelly [so that ] one must aim to interpret the results as little
as possible, leaving this to the subject" (Shaw 1980, p.33).
By minimising the role of the KE and giving the user tools such as the
focused grid the individual is allowed to reflect on their own without
the introduction of external bias. The three main analysis tools in KSS0
are Socio, PrinCom and FOCUS. The range of analysis tools available in
the MCRDR/FCA implementation include: rule traces and browsing, the concept
matrix (Figure 6), the concept lattice (Figure 7) and a k-distance weighted
nearest neighbour algorithm. None of these correspond directly to PrinCom
or FOCUS although the concept matrix and lattice provide hierarchical clustering
as well as a visual representation of the relationships between objects
and attributes. We take a brief look at each of the analysis tools in KSS0,
spending more time on FOCUS and then describe our nearest neighbour algorithm.
Socio is used for comparison of conceptual structures from multiple sources
and a good account is given in Shaw (1988). We have begun to look at this
area in our work on requirements engineering (Richards and Menzies 1997)
which focuses particularly on conflict detection and resolution. A further
tool being developed by Biederman (1997) is the use of a triadic representation
that allows multiple crosstables to be shown concurrently and we hope to
benefit from his research in comparing the models.
PrinCom uses principal components analysis (Slater 1977) to provide spatial
clustering. It is one of the most popularly used methods of grid analysis
using techniques such as the Euclidean distances divided by the 'expected'
distances to find inter-element distances. PrinCom produces a map which
gives a visual representation of the relationships between objects and
attributes. Shaw argues that such approaches which extract factors or components
can distort the results because they can encourage bias in naming, data
collection and experimentation (Shaw 1980). Nevertheless, PrinCom is a
valuable inclusion in KSS0 because of its widespread usage with repertory
grids. Our nearest neighbour algorithm gives a score between 0 to 1 of
the degree of closeness of one rule/concept to another but unlike PrinCom
does not provide a spatial drawing of each concept in relation to each
other.
FOCUS provides hierarchical clustering. The focusing algorithm developed
by Shaw (1980) is a simple technique that does not impose as many restrictions
as principal components analysis and interference with the subject's data
is minimal. Following Shaw (1980, p. 33-34), the construct matching score
is scaled to provide a percentage matching score. The distance between
two constructs i and j (7) is given as:
dij
-200dij + 100 (7)
(n
- 1) e
where dij is the sum of the difference for each element
(the city block metric), n is maximum value of the rating scale and e is
the number of elements. This produces results between -100 and 100, where
-100 is a perfect cross match, 0 is no match and 100 is a perfect match.
Similarly the element matching score (8) is computed as:
dij
-100dij + 100 (8)
(n- 1) c
where c is the number of constructs. The distance is multiplied in
this case by -100 instead of -200 because elements are not bipolar and
all results should be positive. As shown in Figures 9(a) and (b), the matching
scores are placed in a symmetrical matrix and used to determine which construct/element
should be linked together, the length of the branches and the ordering
of the constructs/elements within the tree. This new ordering is used to
reorder the grid with one tree for the elements and another for the constructs
which are attached to the corresponding nodes.
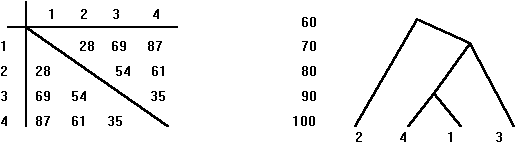
9(a) 9(b)
Figure 9. The symmetrical matrix of the construct/element
matching scores in (a) are used to build the hierarchical tree of the relationships
between the constructs/elements in (b).
These measures, and those used by PrinCom and Socio, are useful and
appropriate for the repertory grid input where the user assigns a number
that indicates where along the construct an element should be placed. However,
unless we modify our rules using something like fuzzy logic, we do not
have an equivalent numerical input value in an MCRDR KBS. This may change
in the future as Roderiguez Martinez (personal communication) is currently
investigating the fuzzification of RDR. What we have in RDR KBS to determine
the distance is a rule premise, made up of a string of rule conditions,
and a conclusion. In this situation a better concept than distance is proximity,
P, because the higher the score the closer the concept. Our measure for
P uses a distance-weighted nearest neighbour algorithm (9) that considers
the number of string matches compared to the number of conditions being
compared.
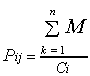 *
*
![]()
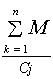 (9)
(9)
Where i and j are the two rule premises being compared, M is the matching
score and C is the cardinal number of conditions. Each condition in a rule
premise is compared to each of the conditions in every other premise. A
straight comparison is not made but the two conditions are broken down
into three parts, the attribute, operator and value. A matching score is
based on the distance between these parts. For example, if the condition
to be matched was RAIN = High then a complete match would be given a score
of 3. The same attribute and operator with a neighbouring value such as
RAIN = Normal would gain a score of 2 and a match on attribute but not
a bordering value such as RAIN = Low gains a score of one. This score was
then divided by 3 and added to the total score. The reasoning behind giving
scores to neighbouring values is to overcome differences in perception
that occur between users and within a user at different times (Gaines and
Shaw 1989). Giving a score of 1/3 to matches on attribute alone is done
to show that there is a greater relationship between conditions that use
the same attribute even if the values are opposite than there is with another
condition that doesn't use that attribute at all. It may be the relationship
is a negative one and that the score provided be shown as positive or negative
as is done with the construct matching score used in FOCUS but this has
not currently been investigated.
The current use of this algorithm is to support the user in exploring if
a relationship exists and to what extent between rules and conclusions
and in particular to assist them to determine how a new proposed rule relates
to the existing rules. The nature of the relationship is not given but
can be found through comparison between the concepts derived from FCA.
The TESTP (test pathways) screen has been developed in MCRDR/FCA to assist
the user in evaluating a particular rule pathway either against all pathways
or another selected pathway using the nearest neighbour algorithm or a
comparison with the intensional definition of the concepts derived using
FCA.
Gaines and Shaw (1993a) also describe a distance metric between two concepts
in the visual language in an extensional context. The distance measure
simply considers the number of individuals in the extension of the minimal
upper bound of the two concepts minus the number of individuals in the
extension of the maximal lower bound of the two concepts. This can be extended
to dichotomous constructs by subtracting the number of individuals in the
maximal lower bound of one pole and then the other. When the scales are
numbered linearly it equates to the city block distance measure used in
FOCUS. The distance between the intensions of two concepts is given in
the relational structure of the visual structure. The distance measures
are used to cluster concepts for an individual and to compare conceptual
models between experts. As part of our requirements engineering research,
we are interested in computing the distance between two or more viewpoints.
For this we need to take into account if the concept is in a state of consensus,
contrast, correspondence or conflict (Gaines and Shaw 1989). Consensus
receives a score of 0 and contrast a score of 1 and given two concepts
we can compute the degree of conflict by counting the number of objects
and attributes that separate the two concepts divided by the total number
of attributes and objects for both concepts.
4.4 Validation and Maintenance
Gaines and Shaw say that as KA tools mature they should be able to:
"extend in scope from initial elicitation, through detailed
knowledge modelling, to validation and knowledge base maintenance."
(Gaines and Shaw 1993a, p.76).
In the RDR approach, maintenance and validation are inextricably
entwined with KA and there is no clear distinction between the three. The
exception structure, the use of cornerstone cases and difference lists
ensures that previously correctly classified cases are not affected by
the addition of new exception rules. Maintenance, and KA, is designed to
be performed on-line while the system is in routine use. In PCP and FCA
validation and maintenance of the repertory grid or crosstable are supported
as evidenced by the various analysis tools in KSS0. However, when it comes
to deriving rules RDR supports incremental acquisition which is not supported
by PCP or FCA. These latter approaches require the set of implications
to be regenerated. If this requires input from the user, as in the case
of FCA, then this is not only time-consuming but frustrating and error-prone.
Another aspect of validation that differentiates PCP from RDR is that in
RDR validation is performed by the expert whereas in PCP validation is
primarily a task performed by the KE (Gaines and Shaw 1993b).
Apart from the automatic validation supported by the use of cornerstone
cases we have been using the concepts derived from FCA and the nearest
neighbour algorithm as described above as a means of supporting the validation
of new knowledge (Richards and Compton 1997a). One of the strengths of
starting with a performance system is that we are able to validate the
knowledge we are acquiring by checking that the conclusion reached by the
system matches either the conclusion reached by the user or the conclusion
in the case, depending on the nature of the cases we have. The calculation
of the measures described in Shaw (1988) and the distance measures as described
above are also ways of assessing the validity in terms of consistency between
and within subjects. However, we feel that starting with a T-box makes
validation more difficult and to some degree inappropriate since we are
dealing with descriptive models that are by their very nature imperfect
representations. The subjectiveness of validating a model is exemplified
in the following statement:
"The validity of the analysis [provided by FOCUS] is
only measured in terms of the subjective feeling of personal significance
assessed by the occurrence or otherwise of what has been called the 'aha'
experience" (Shaw 1980, p.33).
The lack of distinction between KA, validation and maintenance in RDR leads
us to consider the differences between the RDR KA process shown in Figure
4 and the system development life cycle of systems based on PCP.
4.5 The Knowledge Acquisition Process
Figure 10 summarises the stages in the PCP system development life cycle
(Gaines and Shaw 1993a, p.81):
Figure 10: A General PCP System Development Life Cycle of Systems
In RDR the stages are not so clearly defined. It seems reasonable that
any system will commence with some stage similar to Stage 0. This is also
the case for RDR KBS where there would be a number of meetings to determine
what the system was to achieve and the domain to be covered. This, however,
would not be as structured as what is probably performed in the interviews,
protocols and media processes outlined in Stage 0 of the PCP development
life cycle.
Stages 1 and 4 are not applicable to the RDR methodology. In PEIRS knowledge was captured which covered a number of subdomains such as blood-gases, thyroid, liver functions, endocrines and catecholamines. The expert decided which subdomain to add first and others were added later. Particularly with the use of MCRDR there is no reason why all subdomains can not be added at the same time. The case-driven nature of RDR will to a large extent determine what subdomains are populated first. The decision to add subdomains concurrently or sequentially is not a restriction of the system and there is no need for integration between subdomains as is performed in Stage 4. PCP differs because it is important to the repertory grid technique that the context be restricted and fixed so that the purpose and domain do not change during elicitation (Gaines and Shaw 1993a, p.61) otherwise the conceptual model being built may be distorted. In RDR new attributes and conclusions can be added at any point and while the case provides the context, cases from different subdomains can be shown in any order. An MCRDR which covers a number of subdomains is equivalent to a set of individual trees for each subdomain, but the KA task and repetition is reduced by dealing with a number of subdomains concurrently. It is also envisaged that valuable relationships between subdomains will be more apparent when they are combined into one system.
As described in the previous subsection, the absence of stage 5 in which testing occurs is in keeping with the incremental nature of maintenance and validation provided by the RDR KA technique. Even the use of new reflective modes of KA, such as critiquing (Richards and Compton 1997b), are designed to be performed on-line as part of the KA process each time a rule is added.
The visual representations described in this paper are similar and related to work that has been done using concept maps (Gaines and Shaw 1995) and Case Map and Con Map (Woodward and Shaw 1993) as a way of capturing and representing conceptual models. The main difference is that the concepts and diagrams are given directly by the user in concept mapping whereas in PCP and FCA the concepts and diagrams are generated from repertory grids or crosstables, respectively. As mentioned earlier, the use of simple techniques which avoid having to directly acquire models in PCP, RDR and FCA are necessary where the user is unable to draw a concept map.
In this paper a number of representations of the contact lens data including
the MCRDR rules in Figure 3, the concept lattice derived from them using
FCA in Figure 7, the visual language of the PCP concepts and rules in Figure
8. Each representation offers certain features. The concept lattice in
Figure 7 includes not only the inference paths but also an extensional
definition as does the visual language in Figure 8. The MCRDR rule structure
shows the inference paths, the cases associated with each rule and is the
simplest representation but does not contain any of the higher-level concepts
shown in Figure 7 and Figure 8, which is the most complex diagram.
The PCP approach has been strengthened through the incorporation and use
of other computer technology such as hypermedia, the web, group decision
support systems and collaborative learning, We are moving towards group
use through provision of the MCRDR/FCA modelling tools to compare conceptual
models and to support requirements engineering. RDR research is also exploring
the web with a web-based on-line help desk (Kang et al 1997) and a web-based
version of RDR (Thong 1997).
The combination of PCP and RDR is seen as beneficial, just as the incorporation of FCA into RDR has been important in providing better explanation tools through the development of abstraction hierarchies. It is conjectured that the use of PCP as a means of eliciting cases would be useful for RDR in domains where cases do not exist or are difficult to develop. The use of triadic elicitation for KA in RDR could also be considered. Currently, in MCRDR all cornerstone cases that can reach a particular conclusion must be differentiated and are offered to the user when a rule is being defined. What the MCRDR system is doing is selecting all cases that are similar and asking the user to differentiate. In triadic elicitation the user specifies which two cases (elements) are the same and a third case which is different. Perhaps it would be beneficial to allow the user some input into which cases should be differentiated. However, in RDR systems there tend to be many cases to be classified and asking the user to suggest which cases should be compared would greatly increase the size of the KA task. There is also the problem of how the new knowledge would be incorporated into the KBS. In KSSn there is already the option to output rules as RDR-exceptions although the storage of cornerstone cases and an incremental maintenance strategy are not facilitated.
From the discussion presented in this paper it is apparent that the
focus on systems used directly by the end-user, the use of simple techniques
based on cases to acquire knowledge and the ability to support inferencing
and explanation is shared by both PCP and RDR. The major difference is
that RDR begins with a performance system and derives the explanation system
and PCP does the opposite. From the point of view of validation and maintenance
we see that the RDR approach is stronger but from the point of view of
conceptual modelling the tools offered by PCP are more developed and extensive.
The conclusion is that the approaches are complementary rather than competing.
Acknowledgements
RDR research is funded by grants from the Australian Research Council.
References
Beail, N. (1985) Repertory Grid Technique and Personal Constructs:
Applications in Clinical and Educational Settings Croom Helm, Sydney.
Biederman, K. (1997) How Triadic Diagrams Represent Conceptual Structures In Dickson Lukose, Harry Delugach, Marry Keeler, Leroy Searle, and John F. Sowa, (Eds) (1997),Proceedings of the Fifth International Conference on Conceptual Structures (ICCS'97), August 3 - 8, University of Washington, Seattle, USA, Lecture Notes in Artificial Intelligence, Springer-Verlag, Number 1257, Berlin pp:304-317
Boose, J.H., J.M. Bradshaw, C. M. Kitto and D.B. Shema. (1989) From ETS to Aquinas: Six Years of Knowledge Acquisition Tools in Proceedings of the 4th Knowledge Acquisition for Knowledge-Based Systems Workshop. Banff, Canada:
Brachman, R.J. (1979) On the Epistemological Status of Semantic Networks In Findler, N.V. (ed) Associative Networks: Representation and Use of Knowledge by Computers Academic Press, New York, 3-50.
Chandrasekaran, B. and Johnson, T. (1993) Generic Tasks and Task Structures In David, J.M., Krivine, J.-P. and Simmons, R., editors Second Generation Expert Systems pp: 232-272. Springer, Berlin.
Clancey, W.J., (1991) The Frame of Reference Problem in the Design of Intelligent Machines In K. VanLehn, ed. Architectures for Intelligence, Erlbaum, Hillsdale.
Clancey, W. (1997) The Conceptual Nature of Knowledge, Situations and Activity In Feltovich, Paul J., Ford, Kenneth, M. and Hoffman, Robert R. (eds) Expertise in Context: Human and Machine AAAI Press/MIT Press, Cambridge, Massachusetts.
Collins, H.M. (1997) RAT-Tale: Sociology's Contribution to Understanding Human and Machine Cognition In Feltovich, Paul J., Ford, Kenneth, M. and Hoffman, Robert R. (eds) Expertise in Context: Human and Machine AAAI Press/MIT Press, Cambridge, Massachusetts.
Compton, P. and Jansen, R., (1990) A Philosophical Basis for Knowledge Acquisition.. Knowledge Acquisition 2:2
Edwards, G., Compton, P., Malor, R, Srinivasan, A. and Lazarus, L. (1993) PEIRS: a Pathologist Maintained Expert System for the Interpretation of Chemical Pathology Reports Pathology 25: 27-34.
Edwards, G., Kang, B., Preston, P. and Compton, P. (1995) Prudent Expert Systems with Credentials: Managing the expertise of Decision Support Systems Int. Journal Biomedical Computing 40:125-132.
Gaines, B. R. and Shaw, M.L.G. (1989) Comparing the Conceptual Systems of Experts The 11th International Joint Conference on Artificial Intelligence :633-638.
Gaines, B.R., (1991a) Induction and Visualization of Rules with Exceptions In J. Boose & B. Gaines, Eds, Proceedings of the 6th Banff AAAI Knowledge Acquisition for Knowledge-Based Systems Workshop. Vol 1:7.1-7.17, Banff, Canada:
Gaines, B.R. (1991b) An Interactive Visual Language for Term Subsumption Languages IJCAI91: Proceedings of the Twelfth International Joint Conference on Artificial Intelligence. pp.817-823.
Gaines, B. R. and Shaw, M.L.G. (1993a) Knowledge Acquisition Tools Based on Personal Construct Psychology Knowledge Engineering Review 8(1):49-85.
Gaines, B.R. and Shaw M.L.G. (1993b) Eliciting Knowledge and Transferring it Effectively to a Knowledge-Based System, IEEE Transactions on Knowledge and Data Engineering 5(1) 4-14.
Gaines, B. R. and Shaw, M.L.G. (1995) Collaboration through Concept Maps CSCL'95 Proceedings September 1995.
Guha, T.V., and Lenat, D.B. (1990) CYC:A Mid-Term Report AI Magazine 11(3):32-59
Kang, B., Compton, P. and Preston, P (1995) Multiple Classification Ripple Down Rules: Evaluation and Possibilities Proceedings 9th Banff Knowledge Acquisition for Knowledge Based Systems Workshop Banff. Feb 26 - March 3 1995, Vol 1: 17.1-17.20.
Kang, B., (1996) Validating Knowledge Acquisition: Multiple Classification Ripple Down Rules PhD Thesis, School of Computer Science and Engineering, University of NSW, Australia.
Kang, B., Yoshida, K, Motoda, H, and Compton, P. (1997) Help Desk with Intelligent Interface Applied Artificial Intelligence 11:611-631.
Kelly, G.A, (1955) The Psychology of Personal Constructs New York, Norton.
Kelly, G.A, (1970) A Brief Introduction to Personal Construct Theory. Bannister, D. (ed) Perspectives in Personal Constructs Theory London, Academic Press, 1-29.
Lee, M. and Compton, P. (1995) From Heuristic Knowledge to Causal Explanations Proc. of Eighth Aust. Joint Conf. on Artificial Intelligence AI'95, Ed X. Yao, 13-17 November 1995, Canberra, World Scientific, pp:83-90.
McDermott, J. (1988) Preliminary Steps Toward a Taxonomy of Problem-Solving
Methods Automating Knowledge Acquisition for Expert Systems Marcus,
S (ed.) Kluwer Academic Publishers, pp: 225-256.
Mulholland, M., Preston, P., Sammut, C., Hibbert, B. and Compton, P. (1993)
An Expert System for Ion Chromatography Developed using Machine Learning
and Knowledge in Context Proceedings of the 6th Int. Conf. on Industrial
and Engineering Applications of Artificial Intelligence and Expert Systems
Edinburgh.
Patil, R. S., Fikes, R. E., Patel-Schneider, P. F., McKay, D., Finin, T., Gruber, T. R. and Neches, R., (1992) The DARPA Knowledge Sharing Effort: Progress Report In C. Rich, B. Nebel and Swartout, W., Principles of Knowledge Representation and Reasoning: Proceedings of the Third International Conference Cambridge, MA, Morgan Kaufman.
Pirlein, T. and Studer, R. (1994) KARO: An Integrated Environment for Reusing Ontologies A Future for Knowledge Acquisition 8th European Knowledge Acqusition Worksop EKAW'94, pp:220-225. Springer Verlag.
Puerta, A. R, Egar, J.W., Tu, S.W. and Musen, M.A. (1992) A Mulitple Method Knowledge Acquisition Shell for Automatic Generation of Knowledge Acquisition Tools Knowledge Acquisition 4(2).
Richards, D., Chellen, V. and Compton, P (1996) The Reuse of Ripple Down Rule Knowledge Bases: Using Machine Learing ot Remove Repetition Proceedings of Pacific Knowledge Acquisition Workshop PKAW'96, October 23-25 1996, Coogee, Australia.
Richards, D and Compton, P (1996) Building Knowledge Based Systems that Match the Decision Situation Using Ripple Down Rules, Intelligent Decision Support '96 9th Sept, 1996, Monash University.
Richards, D and Compton, P, (1997a) Finding Conceptual Models to Assist Validation Proceedings of AAAI'97 Verification and Validation Workshop Technical Report WS-97-01, July 28, Providence, Rhode Island. AAAI Press: Menlo Park, CA, pp:53-62.
Richards, D. and Compton, P. (1997b) Uncovering the Conceptual Models in RDR Proceedings of the International Conference on Conceptual Structures ICCS'97 Seattle August 4-8 1997, Springer Verlag.
Richards, D. and Menzies, T. (1997) Extending Knowledge Engineering to Requirements Engineering from Multiple Perspectives Proceedings of 3rd Australian Knowledge Acquisition Workshop AKAW'97 in conjunction with AI'97, University of Western Australia, Perth, Australia (in print).
Schmalhofer, F.J., Aitken, S. and Bourne, L. E. (1994) Beyond the Knowledge Level: Descriptions of Rational Behaviour for Sharing and Reuse A Future for Knowledge Acquisition 8th European Knowledge Acqusition Worksop EKAW'94, pp:220-225. Springer Verlag.
Schreiber, G., Weilinga, B. and Breuker (eds) (1993) KADS: A Principles Approach to Knowledge-Based System Development Knowledge-Based Systems London, England, Academic Press.
Shadbolt, N., (1996)URL:http://www.psyc.nott.ac.uk/aigr/research/ka/SisIII
Shaw, M.L.G., (1980) On Becoming a Personal Scientist: Interactive Computer Elicitation of Personal Models of the World Academic Press, London.
Shaw, M.L.G., (1988) Validation in a Knowledge Acquisition System with Multiple Experts In Proceedings of the International Conference on Fifth Generation Computer Systems edited by ICOT. pp:1259-1266.
Shaw, M.L.G. and Gaines, B.R., (1991) A Methodology for Analyzing Terminological and Conceptual Differences in Language use Across Communities Invited paper presented to the First Quantitative Linguistics Conference, QUALICO, Trier, Germany 23-27 September, 1991.
Shaw, M.L.G. and Gaines, B.R., (1992) Kelly's "Geometry of Psychological Space" and its Significance for Cognitive Modeling, The New Psychologist, 23-31, October, 1992.
Shaw, M.L.G. and Gaines, B.R.. (1994) Personal Construct Psychology Foundations for Knowledge Acquisition and Representation 8th European Knowledge Acquisition Workshop, EKAW '94. Springer Verlag, 256-276.
Slater, P. (1977) Dimensions of Intrapersonal Space: Volume 2 John Wiley.
Steels, L. (1993) The Componential Framework and Its Role in Reusability In David, J.M., Krivine, J.-P. and Simmons, R., editors Second Generation Expert Systems pp: 273-298. Springer, Berlin.
Stumme, G. (1997) Concept Exploration - A Tool for Creating and Exploring Conceptual Hierarchies In Dickson Lukose, Harry Delugach, Marry Keeler, Leroy Searle, and John F. Sowa, (Eds) (1997), Proceedings of the Fifth International Conference on Conceptual Structures (ICCS'97), August 3 - 8, University of Washington, Seattle, USA, Lecture Notes in Artificial Intelligence, Springer-Verlag, Number 1257, Berlin pp:318-331.
Thong (1997) http://www.cse.unsw.edu.au/~s2176432/index.html
Wille, R. (1982) Restructuring Lattice Theory: An Approach Based on Hierarchies of Concepts In Ordered Sets (Ed. Rival) pp:445-470, Reidel, Dordrecht, Boston.
Wille, R. (1989) Knowledge Acquisition by Methods of Formal Concept Analysis In Data Analysis, Learning Symbolic and Numeric Knowledge (Ed. E. Diday) pp:365-380, Nova Science Pub., New York.
Wille, R. (1992) Concept Lattices and Conceptual Knowledge Systems Computers Math. Applic. (23) 6-9:493-515.
Wille, R. (1996) Conceptual Structures of Multicontexts Conceptual Structures: Knowledge Representation as Interlingua (Eds. P.Eklund, G. Ellis and G. Mann) pp:23-390, Springer.
Woodward J.B and Shaw, M.L.G., (1993) Cognition Support Tools for Knowledge Acquisition in Proceedings of the 8th Knowledge Acquisition for Knowledge-Based Systems Workshop. Banff, Canada, 13.1-13.20.
Zalta, E.N. (1988) Intensional Logic and the Metaphysics of Intentionality,
Cambridge, Massachusetts, MIT Press.