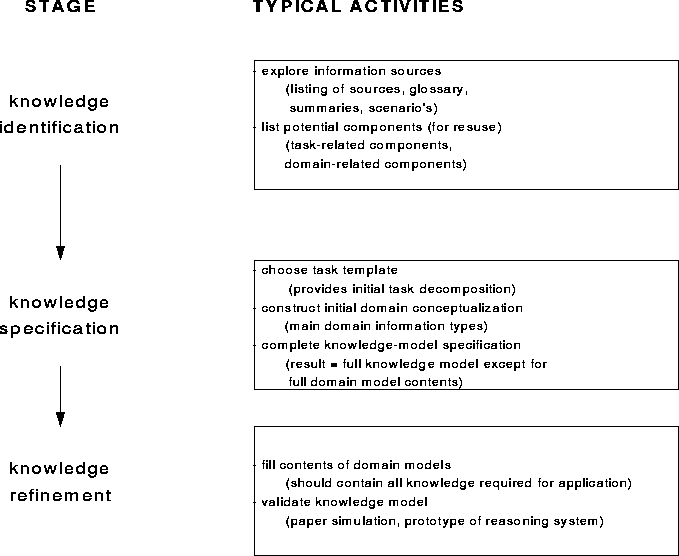
Figure 1: Overview of the three main stages in knowledge model construction. The arrows indicate typical but not absolute time dependencies. For each stage some activities are listed on the right
A. Th. Schreiber and B. J. Wielinga
Department of Social Science Informatics (SWI), University of Amsterdam, Roetersstraat 15, NL-1018 WB, Amsterdam, The Netherlands
The process of knowledge-model construction can be decomposed in a number of stages in which certain activities need to be carried out. For each activity a number of techniques exist. Guidelines help the knowledge engineer in deciding how to carry out the activities. The three main stages are: identification, specification and refinement. The central stage is ``specification''. There are two approaches one can take: start with the inference knowledge (middle-out) or start with domain and task knowledge in parallel (middle-in). The choice depends on the nature of the task template used. This article prescribes a particular approach with some variations, but the knowledge engineer should be aware of the fact that modelling is a constructive activity, and that there exists no single correct solution nor an optimal path to it.
This paper is derived from Chapter 8 of version 0.5 the draft textbook about CommonKADS [Schreiber et al., 1998]. Therefore, the text is rather CommonKADS-specific. For the same reason the present draft also does not contain many references to related on guidelines. We still hope to elicit useful comments and suggestions from the KA community on this difficult issue. Process support is crucial for the acceptance of the methods we're proposing. The paper still contains a number of TODOs.
So far, we have mainly concentrated on the contents of the knowledge model. As in any modelling enterprise, inexperienced knowledge modelers also want to know how to undertake the process of model construction. This is a difficult area, because the modelling process itself is a constructive problem-solving activity for which no single ``good'' solution exists. The best any modelling methodology can do is to provide a number of guidelines that have proven to work well in practice.
This chapter presents such a set of guidelines for knowledge-model construction. The guidelines are organized in a process model that distinguishes a number of stages and prescribes a set of ordered activities that need to be carried out. Each activity is carried out with the help of one or more techniques and can be supported through a number of guidelines. In describing the process model we have tried to be as prescriptive as possible. Where appropriate, we indicate sensible alternatives. However, the reader should bear in mind that the modelling process for a particular application may well require deviations from the recipe provided. Our goal is a ``90%-90%'' approach: it should work in 90% of the applications for 90% of the knowledge modelling work.
As pointed out in previous chapters, we consider knowledge modelling as a specialized form of requirements specification. Partly, this requires specialized tools and guidelines, but one should not forget that more general software engineering principles apply here as well. At obvious points we refer to those, but these references will not be extensive.
We distinguish three stages in the process of knowledge-model construction:
Typically, the description of knowledge items in the organization model and the characterization of the application task in the task model form the starting point for knowledge identification. In fact, if the organization-model and task-model descriptions are complete and accurate, the identification stage can be done in a short period.
The reusable model components selected in the identification stage provide part of the specification. The knowledge engineer will have to ``fill the holes'' between these predefined parts. As we will see, there are two approaches to knowledge model specification, namely starting with the inference knowledge and moving then to related domain and task knowledge, or starting with domain and task knowledge and linking these through inferences. The choice of the approach depends on the quality and detailedness of the chosen generic task model (if any).
In terms of the domain knowledge, the emphasis in this stage lies on the domain-knowledge schema, and not so much on the domain models. In particular, one should not to write down the full set of knowledge instances that belong to a certain domain model. This can be left for the next stage.
These three stages can be intertwined. Sometimes, feedback loops are required. For example, the simulation in the third stage may lead to changes in the knowledge-model specification. Also, completion of the domain models may require looking for additional knowledge sources. The general rule is: feedback loops occur less frequently, if the application problem is well-understood and similar problems have been tackled successfully in prior projects.
We now look at the three stages in more detail. For each stage we indicate typical activities, techniques and guidelines. Within the scope of this book, we cannot give full accounts of all the techniques. Where appropriate we indicate useful references for studying a particular technique.
Figure 1: Overview of the three main stages
in knowledge model construction. The arrows indicate typical but not
absolute time dependencies. For each stage some activities are
listed on the right
When we start constructing a knowledge model we assume that a knowledge-intensive task has been selected, and that the main knowledge items involved in this task have been identified. Usually, the application task has also been classified as being of a certain type, e.g. assessment or configuration (see the task types in [Schreiber et al., 1998, Ch. 6,]).
The goal of knowledge identification is to survey the knowledge items and prepare them in such a way that they can be used for a semi-formal specification in the second stage. This includes carrying out the following two activities:

The starting point for this activity is the list of knowledge items described in Worksheet TM-2. One should study this material in some detail. Two factors are of prime importance when surveying the material:
In the context of this book we cannot go into details about the multi-expert situation, but the references at the end of this chapter indicate a number of useful texts to help out.
Techniques used in this activity are often of a simple nature: text marking in key information sources such as a manual or a textbook, one or two structured interviews to clarify perceived holes in the domain theory. The goal of this activity is to get a good insight, but still at a global level. More detailed explorations may be carried out in less understood areas, because of their potential risks.
The main problem the knowledge engineer is confronted with is to find a balance between learning about the domain without becoming a full domain expert. For example, a technical domain in the processing industry concerning the diagnosis of a specific piece of equipment may require a large amount of background knowledge to understand, and therefore the danger exists that the exploration activity will take long. This is in fact the traditional problem of all knowledge engineering exercises. One cannot avoid (nor should one want to) to become ``layman expert'' in the field. The following guidelines may be helpful in deciding upon the amount of detail required for exploring the domain material:
Rationale: These ``outsiders'' have often undergone the same process you are now undertaking: trying to understand the problem without being able to become a full expert. They can often tell you what the key features of the problem-solving process are on which you have to focus.
Rationale: Usually, detailed theories can safely be omitted in the early phases of knowledge modelling. For example, in an elevator configuration domain the expert can tell you about detailed mathematical theories concerning cable traction forces, but the knowledge engineer typically only needs to know that these formulae exist, and that they act as a constraint on the choice of the cable type.
Rationale: It is often useful to construct a number of typical scenarios: a trace of a typical problem-solving process. Spend some time with a domain expert to construct them, and ask non-experts involved whether they agree with the selection. Try to understand the domain knowledge such that you can explain the reasoning of the scenario in superficial terms.
Scenarios are a useful thing to construct and/or collect for other reasons as well. For example, validation activities often make use of predefined scenarios.
Never spend too much time on this activity. Two person weeks should be the maximum, except for some very rare difficult cases. If you are doing more than that, you are probably overdoing it.
The results achieved at the end of the activity can only partly be measured. The tangible results should be:

However, the main intangible result, namely your own understanding of the domain, stays the most important one.
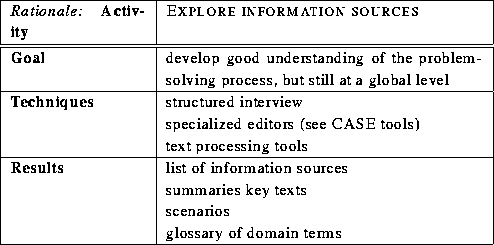
Table 1: Summary of key aspects of activity
``Explore information sources''
The goal of this activity is to pave the way for reusing model components that have already been developed and used elsewhere. Reuse is an important vehicle for quality assurance.
This activity studies potential reuse from two angles:
To be extended

Table 2: Summary of key aspects of activity ``List potential component''
The goal of this stage is to get a complete specification of the knowledge, except the contents of the domain model: these may only contain some example knowledge instances. The following activities need to be carried out to build such a specification:

Chapter 7 of [Schreiber et al., 1998] contains a small set of task decompositions for a number of task types such as diagnosis and assessment. This chapter also gives pointers to other repositories where one can find potentially useful task templates. We strongly prefer an approach in which the knowledge model is based on an existing application. This is both efficient and gives some insurance about the model quality, depending on the quality of the task template used and the match with the application task at hand.
Several features of the application task can be important in choosing an appropriate task template:
The following guideline can help the selection of a particular template with respect to alternative templates:
Rationale: Empirical evidence is still the best measurement of quality of a task template: a model that has proven its (multiple) use in practice is a good model.
Rationale: Although it is strongly recommended that a good template model is used in the knowledge modelling process, this may not always be possible. A task may be new or may have exotic characteristics. Experience has shown that it still is useful to select a template even if it does not fit the task requirements. Such as ``bad'' template can serve as a starting point for the construction of a new one.

Table 3: Summary of key aspects of activity ``Choose task template''
The goal of this activity is to construct an initial data model of the domain independent of the application problem being solved or the task methods chosen. Typically, the domain-knowledge schema of a knowledge-intensive application contains at least two parts:
Examples of this type of construct in the house assignment domain (see [Schreiber et al., 1998, Ch. 5,]) are applicant and house.
Examples in the house assignment domain are the criteria requirement and the decision rules.
This activity is aimed at describing a first version of the domain-specific conceptualizations. These are a good starting point, because these definitions tend to be reasonably stable over a development period. If there are existing systems in this domain, in particular database systems, use these as points of departure.
Rationale: Even if the information needs for your application are much higher (as they often are in knowledge-intensive applications), it is still useful to use at least the same terminology and/or a shared set of basic constructs. This will make future cooperation, both in terms of exchange between software systems, but also information exchange between developers and/or users, easier.
Rationale: The domain-specific part of the domain-knowledge schema can usually be handled by the ``standard'' part of the CommonKADS language. The notions of concepts, sub-types and relations have their counterparts in almost every modern software engineering approach, small variations permitting. The description often has a more ``data-oriented'' than a ``knowledge-oriented'' flavor. This activity bears a strong resemblance with building an initial object model (without methods!) in object-oriented analysis.
Rationale: See techniques in Ch. 6 of the OMT book.
Constructing the initial domain conceptualization can typically be done in parallel with the choice of the task template. In fact, if there needs to be a sequence between the two activities, it is still best to proceed as if they are carried out in parallel. This is to ensure that the domain-specific part of the domain-knowledge schema is specified without a particular task method in mind.

Table 4: Summary of key aspects of activity ``Construct initial
domain conceptualization''
There are basically two routes for completing the knowledge model once a task template has been chosen and an initial domain conceptualization has been constructed:
This approach is the preferred one, but requires that the task template chosen provides a task decomposition that is detailed enough to act as a good approximation of the inference structure.
This approach takes more time, but is needed if the task template is still too coarse-grained to act as an inference structure. An abstracted example of middle-in specification is shown in Fig. 2.
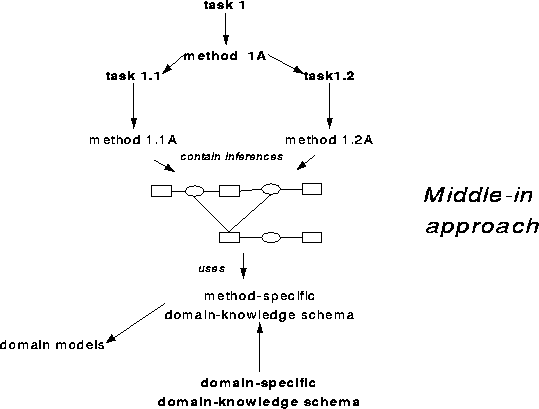
Figure 2: Middle-in approach for knowledge model
completion. Knowledge-model components in bold are given, the others
have to be defined. This sample task template only
provides one level of decomposition, but two levels turn out to be
necessary
Deciding on the suitability of the inference structure is there for an important decision criterion. The following guidelines can help in making this decision:
Rationale: A key point underlying the inference structure is that it provides us with an abstraction mechanism over the details of the reasoning process. An inference is a black box, as far as the specification in the knowledge model is concerned. The idea is that one should be able to understand and predict the results of inference execution by just looking at its inputs (both dynamic and static) and outputs.
Rationale: This is not a hard rule, but it often works in practice. The underlying rationale is simple: if there are more than two static roles (types of static domain knowledge in the knowledge base) involved, than it is often required to specify control over the reasoning process. By definition, no internal control can be represented for an inference, we need to consider this function as a task that is being decomposed.
Although in the final model, we ``know'' what are tasks and what are inferences, this is not true at every stage of the specification process. We use the term ``function'' to denote anything that can turn out to be either a task or an inference. We can sketch for what we call ``provisional inference structures'' in which functions appear that could turn out to be tasks. In such provisional figures we use a rounded-box notation to indicate functions. Fig. 3 shows an example of such a provisional inference structure. In this figure GENERATE and TEST are functions. These functions will either be viewed as tasks (and thus decomposed through a task method) or be turned into direct inferences in the domain knowledge.
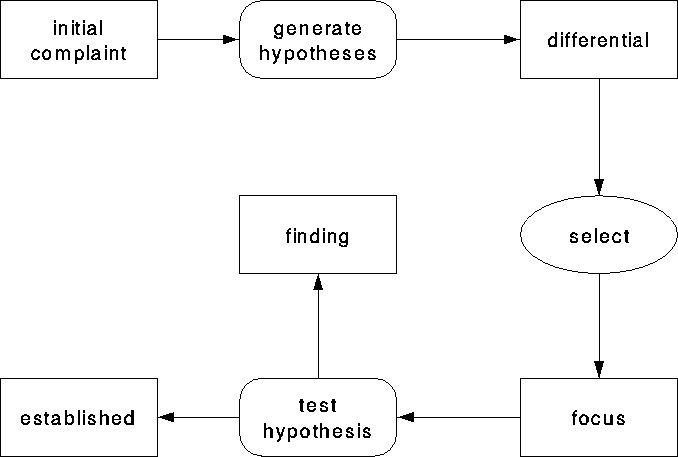
Figure 3: Example of a
provisional inference structure. GENERATE and
TEST are functions. These functions will either be viewed as
tasks (and thus decomposed through a task method) or be turned into
direct inferences in the domain knowledge. The knowledge engineer still
has to make this decision
An important technique at this stage is the think-aloud protocol. This technique usually gives excellent data about the structure of the reasoning process: tasks, task control, and inferences. The adequateness of a task template can be assessed by using it as an ``overlay'' of the transcript of a think-aloud protocol. The idea is that one should be able to interpret all the reasoning steps made by the expert in the protocol in terms of a task or an inference in the template. Because of this usage, task templates have also been called ``interpretation models''. If the task template is too coarse-grained and requires further decomposition, a think-aloud protocol usually gives clues as to what kind of decompositions are appropriate. Because we require of the knowledge model that it can explain its reasoning in expert terms, the think-aloud protocol (in which an expert tries to explain his own reasoning) is the prime technique for deciding whether the inference structure is detailed enough.
Also, such protocols can provide you with scenarios for testing the model (see the knowledge refinement activities further on).
Rationale: The control structure is the ``heart'' of the method: it contains both the decomposition (in terms of the tasks, inferences, and/or transfer functions mentioned in it) as well as the execution control over the decomposition. Once you have the control structure right, the rest can more or less be derived from it.
Rationale: The main point of writing down control structures is to characterize the reasoning strategy at a fairly high level: e.g. ``first this task, then this task'' or ``do this inference until it produces no more solutions''. Details of the control representation can safely be left to the design phase. If one spends much time on the control details in this stage, it might well happen that this work turns out to be useless when a decision is made to change the method for a task.
Rationale: Knowledge modelling (as in modelling in general) is very much about introducing an adequate vocabulary for describing the application problem, such that future users and/or maintainers of the system understand the way you perceived the system, The task roles are an important part of this naming process, as they appear in all simulations or actual traces of system behavior. It makes sense to choose these names with care.
Rationale: The static knowledge roles only appear when we describe inferences. The idea is to free the task specification from the burden of thinking about the required underlying knowledge structures. Of course, methods have their assumptions about the required underlying domain knowledge, but there is no point in already fixing the exact underlying domain-knowledge type.
Rationale: Real-time systems require asynchronous type of control. The transfer function ``receive'' can be useful for emulating this in pseudo code, but in many cases a state-transition type of representation is more natural, and thus worth using.
Rationale: Although the inference structure diagram contains less information than the textual specification, it is much more transparent.
Rationale: There are two ways to classify an inference: according to the role the inference plays in the overall reasoning process (e.g. ``rule out hypothesis'') and the type of operation it performs in order to achieve its goal (''select from a set''). Document the inference with both names.
Rationale: Earlier versions of KADS prescribed a fixed set of inference types, many of which are also used in this book. It has become consensus in the Knowledge Engineering community that prescribing a fixed set of inference types is too rigid an approach. Nevertheless, we recommend to adhere to a standard, well documented set as much as possible. This enhances understandability, reusability and maintenance. Aben [Aben, 1995] and Benjamins [Benjamins, 1993] contain descriptions of sets of inference types that have been widely used and are well documented.
Rationale: A typical example is the difference between abstract and classify. Both inferences produce a new label (concept or attribute value) given some input description, but classify typically uses a hierarchy of structured concept definitions, while abstract typically uses a set of specialized domain relations.
Rationale: A well known confusion in inference structures is caused by the lack of clarity whether a role represents one single object or a set.
Rationale: Although CommonKADS has no strict rules about the cardinality of the input and output roles of inferences, inferences without an input are considered unusual and inferences with many outputs (more than two) are also unusual in most models. Often these phenomena are indications of incomplete models or of overloading inferences (in the case of many outputs).
Rationale: It is tempting to use role names that have a domain specific flavor. However, it is recommended to use domain independent role names as much as possible. This enhances reusability.
Rationale: Like data flow diagrams, inference diagrams are often read from left to right. Structure the layout in such a way that it is easy to detect what the order of the reasoning steps is. The well known ``horse shoe'' form of heuristic classification is a good example of a layout that has become standardized.
Rationale:
Rationale: Inference structures are essentially static representation of a reasoning process. They are not very well suited to represent dynamical aspects, such as a data structure which is continuously updated during reasoning. A typical example is the ``differential'', an ordered list of hypotheses under consideration. During every reasoning step the current differential is considered and hypotheses are removed, added or reordered. In the inference structure this would result in an inference that has the differential as input and as output. Some creative solutions have been proposed (e.g. double arrows with labels), but no satisfactory solution currently exists. We recommend to be flexible and not to bother too much about this problem.
Rationale: Although an inference is considered to be a black box in the knowledge model, it is important input to the design phase to specify the conception that the knowledge engineer has in mind. Optionally, a number of possible methods to realize the inference can be enumerated.
Rationale: Getting the ``right'' representation is typically a design issue, and should not worry the knowledge engineer too much during knowledge modelling. The key issue is that the knowledge is available.
Rationale: Domain-knowledge modelling is partly carried out independently of the model of the reasoning process. This is a good strategy with respect to reuse (see [Schreiber et al., 1998, Ch. 7,]), but will almost always give rise to domain-knowledge types that are relevant for the final method(s) chosen for achieving the task. Also, the communication model may require additional domain-knowledge, e.g. for explanation purposes.
To be extended
During the knowledge-specification stage we are mainly concerned with structural descriptions of the domain knowledge: the domain-knowledge schema. This schema contains two kinds of types:
Instances of the ``data types'' are never part of a knowledge model. Typically, data instances (case data) will only be considered when a case needs to be formulated for a scenario. However, the instances of the ``knowledge types'' need to be considered during knowledge model construction. In the knowledge specification stage a hypothesis is formulated about how the various domain knowledge types can be represented. When one fills the contents, one is in fact testing whether these domain-knowledge types deliver a representation that is sufficiently expressive to represent the knowledge we need for the application.
Usually, it will not be possible to define a full, correct domain model at this stage of development. Domain models need to be maintained throughout their life time. Apart from the fact that it is difficult to be complete before the system is tested in real-life practice, such knowledge instances also tend to change over time. For example, in a medical domain knowledge about the resistance to certain antibiotics is subject to constant change.
In most cases, this problem is handled by incorporating editing facilities for updating the knowledge base into the system. These knowledge editors should not use the internal system representations, but communicate with the knowledge maintainer in the terminology of the knowledge model.
Various techniques exist for arriving at a first, fairly complete version of a domain model. One can check the already available transcripts of interviews and/or protocols, but this typically delivers only a partial set of instances. One can organize a focused interview, in which the expert is systematically taken through the various knowledge types. Still, omissions are likely to persist. A relatively new technique is to use automated techniques to learn instances of a certain knowledge type, but this is still in an experimental phase (see the references at the end of this chapter).
Rationale: Sometimes, we define a domain-knowledge type, such as a certain rule schema, on the basis of just a few examples, under the assumption we there are more those to be found. If this assumption turns out be wrong, it may well be that this part of the schema needs to be reconsidered. One can see a domain-knowledge type as a hypothesis about a useful structuring of domain knowledge. This hypothesis needs to be empirically verified: namely that in practice we can adequately formulate instances of this type for our application domain.
Rationale: Reusing part of an existing knowledge base is one of the most powerful forms of reuse: This really makes a difference! There is always some work to be done with respect to mapping the representation in the other system to the one you use, but it is often worth the effort. The quality is usually better and it costs less time in the end. See [Schreiber et al., 1998, Ch. 7,] for successful examples of this approach.
Validation can be done both internally and externally. Some people use the term verification for internal validation (``is the model right?'') and reserve ``validation'' for validation against user requirements (``is it the right model?'').
Checking internal model consistency can be done through various techniques. Standard structured walk-troughs can be appropriate. Software tools exist for checking the syntax. Some of these tools also point at potentially missing parts of the model, e.g. an inference that is not used in any task method.
External validation is usually more difficult and/or more comprehensive. The need for validation at this stage varies from application to application. Several factors influence this need. For example, if a large part of the model is being reused from existing models that were developed for very similar tasks, the need for validation is likely to be low. Molds for tasks that are less well understood are more prone to errors and/or omissions.
The main method for checking whether the model captures the required problem-solving behavior, it to simulate this behavior in some way. This simulation can be done in two ways:
This can best be done in a table with three columns. The left column describes a scenario step in knowledge-model terms: e.g. an inference is executed with certain roles as input and output. The middle column indicates how this knowledge model fragment maps onto a part of the scenario. The right column can be used for comments:

include example paper-simulation
The official outcome of knowledge-model construction is the actual knowledge-model description specified with the textual and graphical constructs provided by the CommonKADS Conceptual Modelling Language (see [Schreiber et al., 1998, Appendix C,] for the detals). However, it will be clear that in building this specification a large amount of other material is gathered that is useful output as a kind of background documentation. It is therefore wothwhile to produce a ``domain documentation document'' containing at least the full knowledge model plus the following additional information:
Worksheet KM-1 (see Table 5) provides a checklist for generating this document.
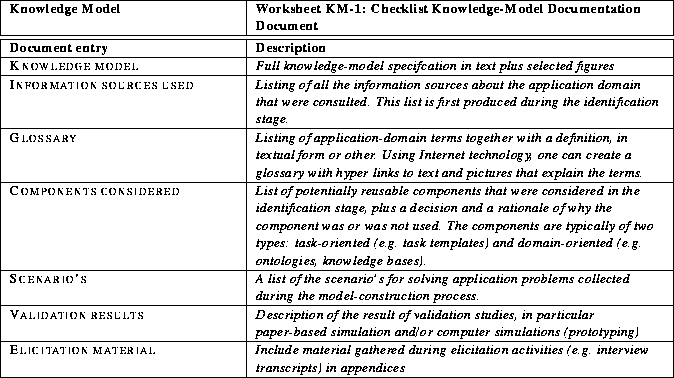
Table 5: Worksheet Worksheet KM-1: Checklist Knowledge-Model
Documentation Document
Several texts provide an overview of elicitation techniques, e.g. Meyer & Booker [Meyer & Booker, 1991] and McGraw and Harrison-Briggs [McGraw & Harrison-Briggs, 1989]. Think-aloud protocols are an important technique in knowledge-model specification. The book by Van Someren, Barnard and Sandberg [van Someren et al., 1993] provides a good and practical introduction into this technique.