We describe a conceptual and computational architecture called Knowledge-based Navigation of Abstractions for Visualization and Explanation (KNAVE). KNAVE is a domain-independent framework specific to the task of interpretation, summarization, visualization, explanation, and interactive navigation in a context-sensitive manner through time-oriented raw data and the multiple levels of higher-level, interval-based concepts that can be abstracted from these data. The KNAVE domain-independent navigation operators are mapped through the ontology of the knowledge-based temporal-abstraction problem-solving method to the domain-specific knowledge base. Thus, the domain-specific semantics are driving the domain-independent visualization and navigation processes. By accessing the domain-specific temporal-abstraction knowledge base and the domain-specific time-oriented database, the KNAVE modules enable users to query for domain-specific temporal abstractions and to change the focus of the visualization, thus reusing for a different task the domain model that has been acquired from the domain experts. Initial evaluation of the KNAVE prototype has been encouraging. The KNAVE methodology has potentially broad implications for tasks such as planning, monitoring, explanation, and data mining.
1. INTRODUCTION: TEMPORAL ABSTRACTION AND INFORMATION VISUALIZATION
In this paper, we present a conceptual and computational knowledge-based framework for interactive visualization, navigation, and browsing of time-oriented data and their multiple levels of temporal abstractions. We build on our previous studies into the nature of knowledge-based temporal abstraction, the automated acquisition of that knowledge, and the computational mechanisms using it.
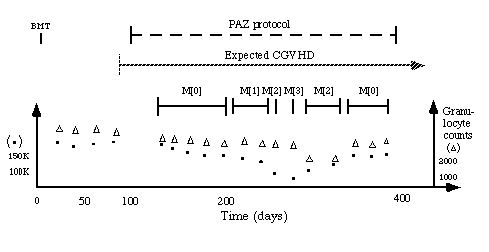
The temporal-abstraction task is the task of creating context-sensitive interpretations of time-stamped data in terms of higher-level concepts and patterns that hold over over time intervals. Interval-based abstractions are useful for planning and for monitoring the execution of plans. Temporal abstractions are also a prerequisite for creation of high-level summaries of time-oriented databases, such as electronic medical-record databases, and for visualizations and navigation through these summaries. Temporal abstractions are also helpful for explanation purposes by decision-support systems, and support data-mining applications in time-oriented databases. An example of the temporal abstraction task in a medical domain is shown in Figure 1.
Visualization of information in general and of large amounts of time-oriented data in particular is essential for effective decision making. Much effort had been put in the past into creation of effective visualizations for information; an excellent example is the classic series of books by Edward Tufte on methods to display information [Tufte 1983, 1990, 1997].
Previous work had typically focused on exploring separately three different subtasks of the problem we are tackling: temporal abstraction, information visualization, and knowledge acquisition.
Figure 1: Abstraction of platelet and granulocyte values during administration of the predisone/azathioprine (PAZ) clinical protocol for treating patients who have chronic graft-versus-host disease (CGVHD). The time line starts with a bone-marrow transplantation (BMT) event.
Several approaches have been applied to the task of abstraction of time-oriented data into higher-level concepts, especially in medical domains, in which both large amounts of data and considerable knowledge are available [Fagan, 1980; Downs et al., 1986; De Zegher-Geets, 1987; Kohane, 1987; Russ, 1989; Kahn, 1991; Larizza et al., 1992; Haimovitz and Kohane, 1993]. None of these approaches, however, emphasized the need for a formal representation that facilitates acquisition, maintenance, sharing, and reuse of the required temporal-abstraction knowledge; this emphasis is the focus of our previous and current research. Furthermore, previous temporal-abstraction approaches were typically not geared for use in a runtime system for visualization of and navigation through the domain-specific abstractions, and would not support a domain-independent interface.
Research in the areas of presentation and display techniques in general [Tufte 1983, 1990], visualization of clinical time-oriented data [Cousins and Kahn, 1991; Powsner and Tufte, 1994], and human-computer interfaces [Koljejchick et al., 1997; Rohrer and Swing, 1997; Wright, 1997; Becker, 1997] has developed useful visualization techniques for static presentation of raw time-oriented quantitative data and for browsing information, using various statistical and graphical methodologies such as scattergrams, pie charts, bar charts, three-dimensional representations [Carpendale et al., 1997] and their derivative techniques. These display methods, however, typically do not focus on visualization of domain-specific temporal abstractions and on the issue of dynamic navigation, using a domain-independent method, through multiple levels of these abstractions using domain-specific knowledge. The reason for that omission is that such capabilities require formal, domain-independent representations of the domain-specific temporal-abstraction knowedge, considerable effort in modelling the visualized domain, and the availability of computational mechanisms for creation of the relevant abstractions.
The past decade has witnessed considerable advances in semiautomated methods for knowledge acquisition and knowledge representation, based on approaches that operate at the knowledge level [Newel, 1982] and that assume task-specific but domain-independent problem-solving methods [Clancey, 1985; Chandrasekaran, 1986; McDermott, 1988; Musen, 1989; Weilinga et al., 1992, Genesereth and Fikes, 1992; Gruber, 1993; Eriksson et al., 1995] which often succeed in alleviation of the knowledge-acquisition bottleneck. However, these methods often are not associated with runtime end-user applications, and focus on use by knowledge engineers and domain experts.
Thus, visualization of time-oriented abstractions using domain-specific knowledge is an important task which requires an integrated solution to all three subtasks. Such an integrated framework will have broad implications for multiple tasks, such as planning, monitoring, interpretation, explanation of interpretations, and data mining.
1.1. Integration Of Knowledge-Based Temporal Abstraction And Visualization: An Overview
We are developing a computational architecture called Knowledge-based Navigation of Abstractions for Visualization and Explanation (KNAVE). KNAVE is a domain-independent conceptual framework that is specific to the task of summarization, visualization, explanation, and interactive navigation through time-oriented raw data and the multiple levels of higher-level, interval-based concepts that can be abstracted from these data in a context-sensitive manner. Although all of the computational operators used in KNAVE are domain independent, these operators are mapped through a predefined method ontology to the domain-specific knowledge that has been acquired for the purpose of abstraction of the domain-dependent data over time. Thus, the domain-specific semantics are driving the visualization and navigation processes.
The methodology underlying KNAVE is based on our previous work on the knowledge-based temporal-abstraction method. This method solves the temporal-abstraction task. The knowledge-based temporal-abstraction method depends on four well-defined domain-specific knowledge types: structural, classification (functional), temporal-semantic (logical), and temporal-dynamic (probabilistic) knowledge. Values for the four knowledge types are specified within the domain's temporal-abstraction ontology (which includes properties of measureable parameters, external actions, and contexts induced by parameters or actions) when developing a temporal-abstraction system, and are acquired from domain experts through a specialized graphical knowledge-acquisition tool. The knowledge-based temporal-abstraction method has been implemented in the RÉSUMÉ system, and has been evaluated in multiple medical and engineering domains with encouraging results.
Provision of a flexible, domain-independent computational paradigm and interface for visualization and navigation of time-oriented data, while allowing for domain-specific knowledge, implies that users need to be able to tap into the full temporal-abstraction ontology of the domain while interacting with the system. Thus, the KNAVE project develops new computational and graphical interface modules that perform knowledge-based visualization of the relevant data and its temporal abstractions. The framework enables users to query for domain-specific abstractions and to change the focus of the visualization in a natural manner, by capitalizing on the same domain model that has been acquired from domain experts, using the graphical knowledge-acquisition tool, to support tasks such as planning, monitoring, and data interpretation. Furthermore, the framework's interactive-navigation operators exploit well-defined, domain-independent semantic links in the domain's temporal-abstraction ontology, thus defining a conceptual knowledge-based navigation model, in which visual navigation along predefined relations in the domain's ontology implies certain computational transformations in the visualized abstractions (e.g., navigation along a functional-dependency link related to a visualized abstraction leads to the display of the data and/or abstractions from which the visualized abstraction is derived). Knowledge-based navigation is supported along six main semantic axes: (1) generalization or specialization of the parameter type using IS-A semantic links among parameters; (2) exploration of functional dependency among parameters using ABSTRACTED-FROM semantic links; (3) generalization or specialization of the context using the IS-A semantic links among contexts; (4) exploration of relations among contexts, using the SUBCONTEXT relation; (5) generalization/specialization of external actions, using the IS-A semantic links among interventions; and 6) exploration of relations among external actions, using the SUBPART relation. Different combinations of parallel motion along several semantic links in the domain's temporal-abstraction ontology define precisely several semantic-zoom operators. These operators are augmented by purely syntactic visualization operators, such as overlay, magnification, and temporal scrolling.
Typically, each type of data has certain ranges of temporal granularity within which it is meaningful to visualize it (e.g., hours to days) and beyond which it should be visualized differently by using some domain-specific aggregation operator (e.g., mean, standard deviation, distribution, etc). The KNAVE framework enables users to change on the fly the temporal granularity level of the interface (i.e., the relevent resolution of the presentation and interpretation process, as opposed to a temporal zoom, which involves only graphical magnification of the data).
KNAVE provides several mechanisms for explanations of data interpretations (e.g., zooming on the data on which a pattern depends, and dynamic retrieval of relevant classification knowledge). The architecture also lends itself well to explicit representation of domain-specific and individual-user preference models.
The KNAVE methodology has potentially broad implications for tasks such as planning, monitoring, explanation of interpretations, and data mining.
2. BACKGROUND: THE TEMPORAL-ABSTRACTION TASK
In this section, we describe briefly our previous work on the knowledge-based temporal-abstraction method and several of the theoretical and practical results it has achieved. These results support directly several of the knowledge-representation, knowledge-acquisition, and computational requirements of the KNAVE methodology. Thus, the KNAVE framework can be viewed as an innovative reuse and extension of the temporal-abstraction ontology, and the computational mechanisms implied by the knowledge-based temporal-abstraction method, into a conceptual and computational framework that supports a rather different task. This new task consists of providing interactive visualization of and navigation through time-stamped data and their multiple-level time-oriented abstractions.
The temporal-abstraction task is an interpretation task: given time-stamped parameters (raw and abstracted data), external events, and the user's abstraction goals, produce time-interval-based abstractions of the data, which interpret past and present states and trends, that are relevant for a given set of goals [Shahar, 1994] (see Figure1).
The goal of our previous and ongoing research was to develop a theoretical framework and an accompanying technology that can solve the temporal-abstraction task and thus provide concise, informative, context-sensitive summaries of time-oriented data stored on electronic media, such as medical records. The output of such a tool would be useful both to human users and to intelligent decision-support systems. Predefined or ad hoc queries should be answered at various levels of abstraction. Useful abstractions cannot use only time points, such as data-collection dates, but may need to create characterizations over time intervals (see Figure 1).
Creation of interval-based temporal abstractions of time-stamped data has several advantages:
1. Data summaries of time-oriented electronic data have an immediate value to a human user, such as to a physician scanning a long patient record for meaningful trends.
2. Temporal abstractions support recommendations by intelligent decision-support systems.
3. Abstractions support monitoring of plans (e.g., therapy) during execution.
4. Creation of meaningful temporal contexts enables generation of context-specific abstractions, maintenance of multiple interpretations of the same data in parallel (within different contexts), and a certain amount of automated foresight and hindsight, through the creation of interpretation contexts in the future and the past.
5. Temporal abstractions are helpful for explanation purposes by an intelligent system. Detection and presentation of temporal patterns is a justification for recommended actions.
6. Temporal abstractions are a useful representation for comparing an intelligent system's recommended plan with that of a human user and for recognition of that user's plan, when overall and intermediate goals common to both planners can be described in terms of creating, maintaining, or avoiding certain temporal patterns [Shahar and Musen, 1995].
7. Visualization of time-oriented data requires knowledge about temporal properties of the data (e.g., persistence of states when data are not sampled continuously, to create meningful discrete, interval-based characterizations of the data). Navigation among the resulting temporal abstractions requires knowledge of the semantic links amongst the visualized interval-based abstractions that are specific to the temporal-abstraction task. We will discuss this particular application at length in our description of the proposed KNAVE system for knowledge-based visualization and navigation of time-oriented data.
The long-term goal of our ongoing reseach is to develop a unifying, sharable (for similar tasks in other domains), and reusable (for other tasks in the same domain) knowledge-based approach to the task of context-sensitive abstraction, summarization, visualization, explanation, and navigation of time-oriented data.
2.1. The Knowledge-Based Temporal-Abstraction Problem-Solving Method
The framework that we have developed for solving the temporal-abstraction task and which we have been enhancing in our previous research, is an extension of our work on temporal-abstraction mechanisms [Shahar et al., 1992; Shahar and Musen, 1993; Shahar, 1994]. We have defined a general problem-solving method [Eriksson et al., 1995] for interpreting data in time-oriented domains, with clear semantics for both the problem-solving method and its domain-specific knowledge requirements: the knowledge-based temporal-abstraction method [Shahar, 1997]. This method comprises a knowledge-level [Newell, 1982] representation of the temporal-abstraction task and the knowledge required to solve that task. The knowledge-based temporal-abstraction method has a formal model of input and output entities, of their relations, and of properties associated with these entities [Shahar, 1997].
The knowledge-based temporal-abstraction method decomposes the temporal-abstraction task into five parallel subtasks: temporal context restriction, vertical temporal inference, horizontal temporal inference, temporal interpolation, and temporal pattern matching. The five subtasks of the knowledge-based temporal-abstraction method are solved respectively by five temporal-abstraction mechanisms (nondecomposable computational modules). The temporal-abstraction mechanisms require four well-defined types of domain-specific temporal-abstraction knowledge for any particular domain. Figure 2 presents an overall view of the knowledge-based temporal-abstraction method, its mechanisms, and its knowledge requiements.
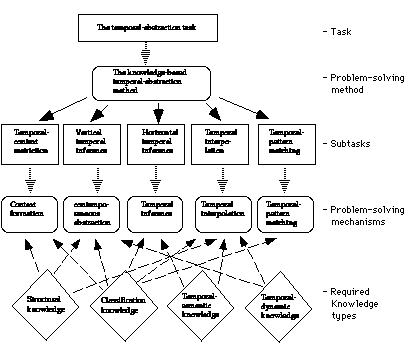
2.2. The Temporal-Abstraction Mechanisms
The temporal-abstraction mechanisms produce output abstractions of several abstraction types: state (e.g., LOW), gradient (e.g., INCREASING), rate (e.g., FAST), and pattern (e.g., QUIESCENT-ONSET).
The context-forming mechanism creates context intervals over which hold interpretation contexts [Shahar, in press]. Context intervals create a relevant frame of reference for interpretation and enable the temporal-abstraction mechanisms to focus only on abstractions relevant for particular contexts, thus creating interpretations that are context-specific and avoiding unnecessary computations. Interpretation contexts are induced dynamically at runtime by the presence of a context-forming proposition, not necessarily with the same temporal scope (e.g., the event of administration of AZT might create a future interpretation context of toxicity due to AZT). Explicit interpretation contexts, separate from the propositions inducing them and from the abstractions using them, have significant conceptual and computational advantages for interpretation of time-stamped data [Shahar, in press].
The contemporaneous-abstraction mechanism abstracts one or more parameters and their values, attached to contemporaneous time points or time intervals, into a value of a new, abstract parameter. Thus, it performs a classification of a given parameter's value or a computational transformation of the values of several parameters, using a classification function. An ABSTRACTED-INTO relation exists between input and output parameters.
The temporal-inference mechanism performs two subtasks: (1) inference of specific types of interval-based logical conclusions, given interval-based propositions, using a deductive extension of Shoham's temporal-semantic properties [Shoham, 1987] (e.g., unlike two consecutive periods of anemia, two episodes of 9-month pregnancies cannot be summarized as an episode of an 18-month pregnancy, since they are not concatenable, a temporal-semantic property [Shoham, 1987]), and (2) determination of the domain value of an abstraction created from two meeting abstractions (e.g., for a gradient abstraction, DECREASING Å SAME = NONINCREASING [Shahar et al., 1992]).
The temporal-interpolation mechanism bridges gaps between temporally-disjoint propositions of similar types, using domain-specific temporal-dynamic knowledge about the dynamic behavior of the parameters involved [Shahar, 1997]. The temporal-interpolation mechanism uses local and global truth-persistence functions to join temporally disjoint abstractions when values for direct determination of the abstractions are missing [Shahar, 1997a].
The temporal-pattern-matching mechanism matches predefined temporal patterns and runtime temporal queries with data and concluded abstractions. The output is a pattern-type parameter which holds over an interval. 2.3. Knowledge Requirements of the Temporal-Abstraction Mechanisms
The temporal-abstraction mechanisms require four domain-specific knowledge types for any particular domain: (1) structural knowledge (e.g., ABSTRACTED-INTO relations); (2) classification knowledge (e.g., definition of a parameter range as LOW); (3) temporal-semantic knowledge (e.g., the concatenable property); and (4) temporal-dynamic knowledge (e.g., persistence of a proposition over time when data is unavailable).
The input to the temporal-abstraction task is a set of measured time-stamped parameters (e.g., temperature), external events (e.g., insulin injections), abstraction goals (e.g., diabetes therapy), and domain-specific temporal-abstraction knowledge. The output of the temporal-abstraction task is a set of interval-based, context-specific parameters at the same or at a higher level of abstraction and their respective values (e.g., "a period of 5 weeks of severe anemia in the context of therapy with AZT"). An abstraction of a parameter (e.g., the state of the hemoglobin-level) is also a parameter. Time intervals are constructed from pairs of time stamps; time points are zero-length intervals. We call the structure {<parameter, value, context>, interval} a parameter interval; it denotes that the parameter proposition "the parameter has a particular value given a specific context of interpretation" holds during a specific time interval. Propositions hold only over time intervals. If the parameter is an abstract (computed) parameter, such a structure is called an abstraction. Output abstractions hold within interpretation contexts, which are induced by the existence of other propositions, such as certain events.
A temporal-abstraction ontology includes (1) parameter ontology-a theory of the relevant parameters and their temporal properties in the domain and the relations among these parameters (e.g., IS-A, ABSTRACTED-INTO), (2) an event ontology, which includes external events (e.g. medications), their interrelations (e.g., PART-OF relations) and properties, (3) a context ontology, which includes interpretation contexts (e.g., the temporal context defined by the effect of a drug) and relations (e.g., SUBCONTEXT) among interpretation contexts, (4) an abstraction-goal ontology, which includes all abstraction goals (which can induce contexts; e.g., monitoring of diabetes therapy) and their IS-A relations; and (5) all relations between inducing propositions and induced contexts.
2.4. RÉSUMÉ: An Implementation of Knowledge-Based Temporal Abstraction
In our previous research, we have implemented the knowledge-based temporal-abstraction method as the RÉSUMÉ system [Shahar and Musen, 1993; Shahar and Musen, 1996] in the CLIPS shell [Giarratano and Riley, 1994]. RÉSUMÉ generates temporal abstractions, given time-stamped data and events, and the domain's temporal-abstraction ontology. RÉSUMÉ is composed of a temporal-reasoning module (the five temporal-abstraction mechanisms), a static temporal-abstraction domain knowledge base (the temporal-abstraction ontology), and a dynamic temporal fact base that stores input intervals representing external events, abstractions, and raw data and output interval-based interpretation contexts and abstractions. Updates that cause retraction of previously concluded abstractions are propagated by a truth-maintenance system [Shahar and Musen, 1996]. Apart from conceptual advantages, such as faciliatation of knowledge-acquisition and maintenance, the RÉSUMÉ architecture has several computational advantages [Shahar and Musen, 1996; Shahar, 1997].
2.4.1. Application of the RÉSUMÉ System: As part of our previous research, we tested the RÉSUMÉ system in several different clinical and engineering domains: protocol-based care (experimental therapy of AIDS patients, therapy of chronic graft-versus-host disease, and prevention of AIDS-related complications) [Shahar and Musen, 1993; Shahar, 1994]; monitoring of children's growth [Kuilboer et al., 1993; Shahar, 1994]; therapy of patients who have insulin-dependent diabetes [Shahar and Musen, 1996], and even monitoring of traffic and evaluation of traffic-control actions [Shahar and Molina, 1996]. We evaluated the feasibility of knowledge acquisition, representation, and maintenance, and applied the knowledge-based temporal-abstraction method to various test cases. We found that both general temporal-abstraction computational knowledge and domain-specific temporal-abstraction knowledge were reusable.
Furthermore, the experiments in the traffic-control domain emphasized the generality of our methodology and its potential applicability not only to time-oriented data, but also to abstraction of data measured over any linear distance measure, and in particular, over linear space (e.g., spatial abstraction of data from traffic sensors along a highway).
In the diabetes domain, we have acquired a temporal-abstraction ontology from an endocrinologist; then, two diabetes experts formed independently temporal abstractions from more than 800 points of glucose and insulin data from eight patients. RÉSUMÉ created 132 (80.4%) of the 164 temporal abstractions noted by both experts [Shahar and Musen, 1996]. The experts agreed on 94% of theabstractions, but on none of the therapy recommendations, thus validating our premise that the intermediate temporal abstractions are more stable than are the rules using them.
We also have incorporated the RÉSUMÉ system within a domain-independent temporal mediator [Wiederhold 1992; Das et al., 1994], the Tzolkin system [Nguyen et al., 1997], which combines the RÉSUMÉ temporal-reasoning system with the Chronus temporal-maintenance system [Das and Musen, 1994]. Tzolkin answers all temporal-abstraction queries referred to a time-oriented database by analysing the query, retrieving the relevant data from the database and knowledge from the domain's temporal-abstraction ontology, and returning the appropriate abstractions. The Tzolkin system is now an integrated key component in the EON architecture for guideline-based medical care [Musen et al., 1996], which is being evaluated in domains such as guideline-based breast-cancer therapy.
2.5. The Temporal-Abstraction Knowledge-Acquisition Tool
As part of our previous research, we have constructed a graphical knowledge-acquisition tool for automated acquisition of temporal-abstraction knowledge from domain experts [Stein et al., 1996], using the PROTÉGÉ-II framework. The PROTÉGÉ-II project [Musen, 1992; Puerta et al., 1992; Musen et al., 1995; Tu et al., 1995] develops a library of highly-reusable, domain-independent, problem-solving methods [Gennary et., 1994; Eriksson et al., 1995]. One advantage of the PROTÉGÉ-II approach is the production, given the relevant problem-solving-method and domain ontologies, of automated knowledge-acquisition tools, tailored for the selected problem-solving method and domain. Preliminary evaluation of the knowledge-acquisition tool for usability of the tool and reusability of the knowledge, using several of our domain experts, have been quite encouraging.
3. THE KNOWLEDGE-BASED VISUALIZATION METHODOLOGY
We employ an integrated knowledge-based approach to the visualization of time-oriented data and their multiple levels of temporal abstractions, by combining our previous work on knowledge-based temporal-abstraction and on mediators to time-oriented databases with developments in knowledge-acquisition tools. In our approach,
(1) Our knowledge-based temporal-abstraction methodology [Shahar, 1997] is used to acquire, represent, and maintain an explicit representation of domain-specific temporal-abstraction knowledge, using semiautomated knowledge-acquisition tools, building on results from our previous theoretical and computational research;
(2) Our computational temporal-abstraction mechanisms create domain-specific, context-sensitive temporal abstractions of the data, again using results from our previous research [Shahar and Musen, 1996];
(3) At runtime, direct access is provided to the domain's temporal-abstraction ontology, which has been acquired from domain experts using the knowledge-acquisition tool. Direct access supports the formulation of the user's initial temporal queries, the creation of the resulting static temporal abstractions, and, in particular, the dynamic navigation by the user of these and additional abstractions by moving along predefined ontological temporal-abstraction semantic links, such as ABSTRACTED-FROM, IS-A, or SUBCONTEXT. Thus, the user navigates among multiple levels of domain-specific abstractions in a domain-indpendent, but task-specific, manner, and the domain-specific ontology is driving the navigation;
(4) Additional temporal-browsing operators are provided to the user; several are purely syntactic and do not depend on domain knowledge, and several use the direct access to the domain's ontology, such as determination of which data or abstractions are relevant for visualization at certain temporal-granularity ranges, and what alternative representations are useful at other temporal resolution levels;
(5) During the browsing process, the user can obtain context-sensitive explanations to questions such as "what classification function defines the creation of this abstraction from those data?" again, by exploiting the direct access to the domain's temporal-abstraction ontology, whicht was acquired from the domain expert(s).
(6) The architecture combines the knowledge-based temporal-abstraction system, the domain knowledge base, a temporal mediator, a semantic-navigation module, and a dynamic graphic interface, into an integrated new framework, composed of several well-understood independent components.
We call our evolving system Knowledge-based Navigation of Abstractions for Visualization and Explanation (KNAVE). We have already tested the feasibility of our methodology by implementing a small prototype of the KNAVE system (with limited functionality) and by evaluating it in a clinical domain using a static set of data and a small group of users. The preliminary results were quite encouraging [Cheng et al., 1997].
We are achieving the goals inherent in our overall approach by capitalizing on (1) the domain-independent RÉSUMÉ temporal-abstraction system, which we have developed in our prior research [Shahar and Musen, 1996; Shahar, 1997], and which we have tested in multiple medical and engineering domains, (2) the semi-automated temporal-abstraction knowledge-acquisition tool we have constructed [Stein et al., 1996], (3) The domain-independent Tzolkin temporal-mediator module, [Nguyen et al., 1997], which coordinates the RÉSUMÉ system and the Chronus temporal-maintenance system [Das and Musen, 1994] to mediate temporal queries to a time-oriented database, and (4) the use of a set of semantic-navigation operators that access the knowledge base that our graphical knowledge-acquisition tool will have acquired from domain experts for the purpose of computing domain-specific temporal abstractions in their respective domains.
Thus, the operators defining the temporal query, visualization, and navigation processes will embody, conceptually, the domain-independent semantics and ontology (basic entities, their properties, and their relations) of our knowledge-based temporal-abstraction method; but these operators will use, for any given domain, the domain-specific temporal-abstraction knowledge of that particular domain.
4. THE KNAVE PROJECT
In the KNAVE project, we have created and evaluated a preliminary functional prototype that proves the feasibility of the knowledge-based abstraction and visualization method [Cheng et al., 1997], and whose interface is used in this section to demonstrate our methodology. We are now in the process of reengineering the individual components to consolidate and generalize our conceptual methodology and its associated computational architecture. (The prototype has been implemented in Visual Basic and is now being reimplemented in Java.)
4.1. The KNAVE Architecture
The KNAVE architecture comprises three components
(Figure 3). The domain ontology server includes the domain-specific
temporal-abstraction ontology developed with the knowledge-acquisition
tool, well as domain-specific visualization knowledge and user-interface
preferences. The temporal- and statistical-abstraction (TSA) server
provides run-time information on the results of a Résumé
run and subsequet temporal and statistical queries, and serves
as a temporal mediator [Wiederhold, 1992] to the time-oriented
database. The visualization client is the core of the KNAVE architecture.
It includes a computational module, which processes information
obtained from the
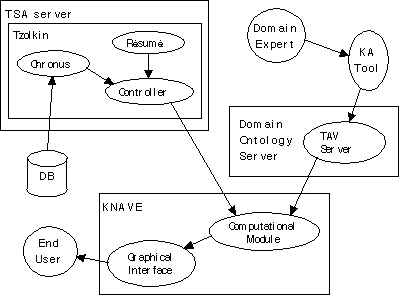
Figure 3: The KNAVE overall architecture. Arrow direction indicates flow of data. TSA server = temporal-and statistical-abstractions server; TAV server = domain-specific temporal-abstraction and visualization-knowledge server; KA tool = knowledge-acquisition tool.
TSA and domain-ontology servers to perform tasks such as interactive semantic navigation, and a user interface module, which displays the various windows and widgets which make up the KNAVE user interface, and which drives the computational module. The visualization and navigation computational component filters the information coming from the TSA server to construct an internal representation which is efficient for the task of interactive navigation. This allows the representation of abstractions and relations between abstractions in Résumé to be separated from the process of displaying the information, providing a common interface for various types of visual representations.
The mediation of temporal-abstraction queries from KNAVE to the time-oriented database in which data reside (i.e., the core of the TSA server) is performed by the Tzolkin temporal mediator [Nguyen et al., 1997] (see Figure 3). The abstraction of the data, if determined as necessary by Tzolkin's control module after analysis of the query, is performed by the RÉSUMÉ system. The other main component of Tzolkin, the Chronus system, is a temporal-maintenance system that is able to (1) communicate with a time-oriented relational database, (2) query for raw and abstracted (typically, concluded by RÉSUMÉ) time-oriented data using a well-defined temporal algebra [Das and Musen 1994], and (3) answer additional types of complex temporal queries that correspond to certain types of temporal patterns that are usually not created by the RÉSUMÉ system (e.g., those involving ordinality and cardinality, such as "the third episode of anemia out of at least five episodes within the past 6 years"). Thus, Tzolkin has a dual role: as a data-management system, and as an engine which processes sophisticated queries specified through the user interface of KNAVE by referring them into commands to Resume and/or Chronus.
During the first phase of the KNAVE project, we have designed and implemented the basic module of the KNAVE system, the knowledge-based static temporal-visualization interface. We have also designed in that phase the basic architecture of the KNAVE system, implementing the minimal links that enable static (or batch, as opposed to dynamic, or interactive) access to a domain temporal-abstraction and visualization knowledge server and to a temporal- and statistical-abstraction server that will be mediating between KNAVE and a time-oriented database. The resulting system enables the user to query a given database in a domain-specific manner for time-oriented raw data, external events, abstractions, and patterns, and to visualize graphically a static representation of the saved results of the temporal query. We ignored in the initial implementation phase functionalities such as navigation (Section 4.2), explanation (Section 4.6), and the dynamic link to the domain-knowledge and abstraction servers (Section 4.5).
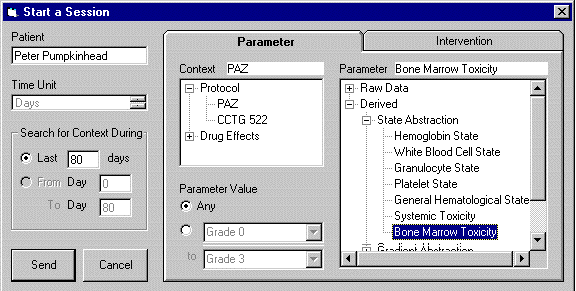
For example, using the static interface, the user can ask "show me all periods of bone-marrow toxicity of Grade II in the past 80 days, in the context of therapy by a Prednisone-Azathioprine (PAZ) protocol" (a guideline for treatment of chronic graft-versus-host disease, a complication of bone-marrow transplantation). The query will define the parameter type (e.g., bone-marrow toxicity), type of abstraction (e.g., STATE), parameter value restriction, if desired (e.g., only GRADE II or higher), the time span (e.g., past 6 months), and the context (e.g., therapy by the PAZ protocol) (Figure 4). Note that creation of a domain-specific runtime temporal-abstraction query, even with purely static graphic output, requires a dynamic link to the domain's temporal-abstraction ontology to browse it.
4.2. The Dynamic Knowledge-Based Semantic-Navigation Operators
Our preliminary experience with the use of the RÉSUMÉ temporal-abstraction system [Shahar and Musen, 1996] and with the KNAVE prototype [Cheng et al., 1997] has indicated strongly that users can benefit greatly from direct interaction with the data and its temporal abstraction. We are also building on experience gained in our laboratory from medical-record-summarization programs, such as Downs' program [Downs 1987] and de Zegher-Geets' IDEFIX program [de Zegher-Geets, 1987]. Both of these systems generated graphic displays of time-oriented clinical data at several levels of abstraction, and allowed a limited amount of interactive manipulation. To exploit the full power of the temporal-abstraction mediator module (Tzolkin), and to support a domain-specific meaningful dialog, users need to be able to tap into the full knowledge contained within the domain model while interacting with the system.
Thus, we have implemented a module that performs knowledge-based navigation through the visualized data and its temporal abstractions. We enable users to change the focus of the visualization by exploiting the domain knowledge that has been acquired from domain experts to support the creation of the temporal abstractions. In particular, we are using semantic links in the domain's temporal-abstraction ontology of parameters, interpretation contexts, and external events [Shahar, 1997].
We are exploring and implementing at least six main semantic-navigation operators, corresponding to analog relations in the temporal-abstraction ontology (see Figures 5 and 6):
(1) generalization/specialization of the parameter (e.g., from the white blood-cell count parameter to the class of hematological parameters and vice versa) using the IS-A semantic links among parameters;
(2) functional dependency among parameters (e.g., from a bone-marrow toxicity abstraction in the PAZ context to the platelet-state and granulocyte-state abstractions defining it, and eventually, to the platelet-count and granulocyte-count parameter values defining these abstractions) using the ABSTRACTED-FROM semantic links (Figure 6);
(3) generalization/specialization of the interpretation context (e.g., from the preprandial (before meal) to the prebreakfast context in diabetes therapy) using the IS-A semantic links among interpretation contexts;
(4) relations among contexts (e.g., from the context induced by the PAZ-therapy event to the context induced by a specific phase of that PAZ event, not necessarily contemporaneously) moving along the SUBCONTEXT relation;
(5) generalization/specialization of the external event (e.g., from the insulin-administration event to regular-insulin administration) using the IS-A semantic links among events;
(6) relations among events (e.g., from the PAZ-therapy event to a specific phase of the PAZ protocol in which a particular drug had been administered) moving along the SUBPART relation among events.
The knowledge-based semantic-navigation operators
are demonstrated in Figure 5 as a set of browser trees. 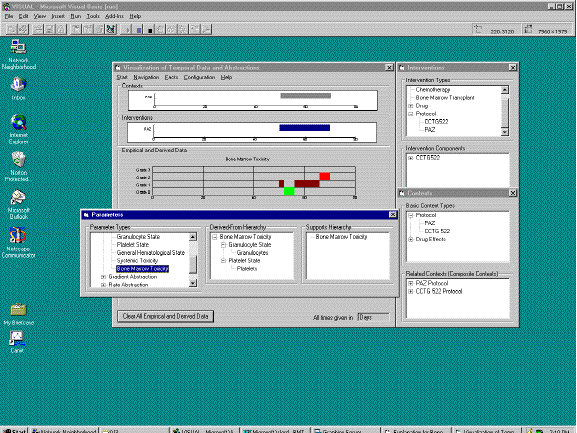
Figure 5: The interface to the dynamic knowledge-based semantic-navigation operators in KNAVE
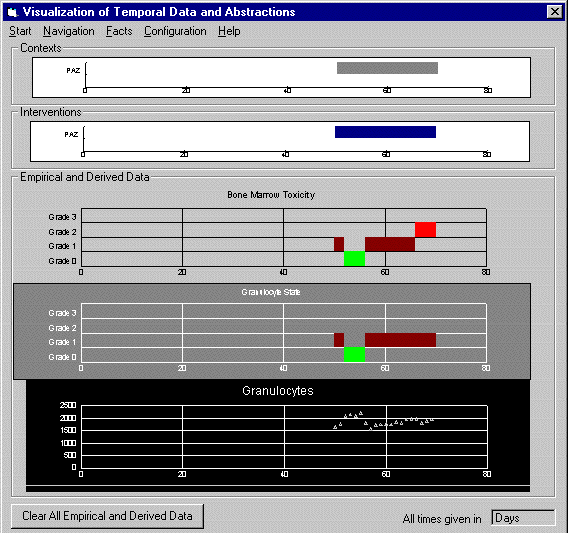
Figure 6: The result of an ABSTRACTED-FROM navigation query, given a bone-marrow-toxicity abstraction
Capitalizing on the initial feedback from our domain experts, we have split the dependency relation into the ABSTRACTED-FROM (derived from) and its inverse, ABSTRACTED-INTO (supports) relations to facilitate browsing. All browser trees are linked to the domain's temporal-abstraction ontology (in this preliminary prototype, in a hardwired fashion) and enable dynamic exploration of that ontology.
Figure 6 demonstrates the results of a motion along the ABSTRACTED-FROM (derived from, as the medical-domain customization prescribed in this case) semantic link, following an initial query that displayed a bone-marrow-toxicity abstraction interval. Here, the user chose to perform a "depth-first" navigation into the granulocyte-state supporting abstraction, and into the granulocyte-count raw data supporting that abstraction. The user could also display the parameters supporting the bone-marrow-toxicity abstraction in a "breadth-first" manner, thus displaying the granulocyte-state and platelet-state abstractions from which the bone-marrow-toxicity abstraction is derived.
4.3. Additional Temporal-Syntactic and Temporal-Semantic Navigation Operators
We are adding several additional browsing operators that facilitate browsing; several of these also are relying directly on access to the domain ontology.
For instance, to facilitate browsing of data and abstractions we have added a syntactic temporal-zoom operator; thus, selecting one panel in a visualization window (e.g., just platelet counts) expands the display of the data within the selected time and data period to fill the whole screen, magnifying the display and enabling the user to inspect data or abstractions shown during that time interval more closely. We are developing additional operators, such as temporal overlay of different types of data along the same timeline [Cousins and Kahn, 1991], horizontal scrolling along the temporal dimension, and vertical scrolling along the abstraction dimension.
Using the concept of syntactic and semantic browsing, we are now able to more accurately define, conceptually and practically, several categories of composite navigation operators, each of which can be defined as a specific combination of semantic-navigation and syntactic temporal-navigation operations. For instance, a common composite navigation operator, which is often called "drilling down the data" in information systems, consists of a syntactic temporal zoom (magnification) combined with moving along an ABSTRACTED-FROM semantic link.
In addition, we are enabling users to change the temporal granularity of the interactive interpretation and visualization process dynamically. Often, users need to examine data at different temporal resolution levels (e.g., minutes, days, years). Furthermore, certain levels of temporal granularity (e.g., weeks) are not meaningful for visualization of certain types of data (e.g., heart rates in the intensive-care-unit context need to be shown at the level of seconds or minute). Thus, each type of data typically has certain ranges of temporal granularity within which it is meaningful to visualize it and beyond which it should be visualized differently, by using a domain-specific aggregation operator (e.g., using descriptive statistics such as minimum, maximum, mean, standard deviation, distribution, etc., or moving to a higher abstraction of the parameter). We enable users to change on the fly the temporal granularity level of the interface (i.e., the relevent resolution of the presentation and interpretation process, as opposed to the syntactic temporal zoom, which involves only graphical magnification of the data display). The knowledge which temporal-granularity ranges are meaningful for each parameter in each context, and what aggregation operators should be used automatically when the granularity chosen is out of that range, is acquired and added to the domain model as part of the visualization knowledge. The knowledge is acquired from the domain experts as part of the process of acquiring the temporal-abstraction knowledge. The need for explicit representation of relevant temporal-granularity ranges in the domain's model was noted by Cousins and Kahn [1991], although their main goal was the development of a syntactic model for visualization of time-oriented clinical data, rather than exploration of the data abstractions using the domain's knowledge.
4.4. Enhancement of the RÉSUMÉ System and of the Knowledge-Acquisition Tool
We have found it necessary to make several enhancements to the implementation of the knowledge-based temporal-abstraction method in the RÉSUMÉ system and to the temporal-abstrction knowledge-acquisition tool, to support the KNAVE requirements:
1. We are enhancing the RÉSUMÉ system to enable creation of more complex abstraction patterns, and in particular, patterns comprising both temporal and statistical aspects. For example, a typical need in the diabetes-therapy domain is to visualize an increasing gradient of the weekely variance of the blood-glucose after breakfasts over the past 6 weeks. Such an abstraction, however, requires the knowledge to create the correct interpretation context. In this example, it is a prospective postprandial (after meals) context of the nonconvex type (i.e., composed of temporally disjoint intervals), specialized to the post-breakfast context, that is induced by the existence of breakfast events in the database. Then, a purely statistical abstraction (variance) needs to be computed over each relevant time granule (here, a week). Finally, the resulting (gradient-type) abstraction should be able to serve as input to a higher-level pattern.
2. We are enhancing the graphical temporal-abstraction knowledge-acquisition tool [Stein et al., 1996) so as to acquire more complex temporal patterns involving temporal-distance, temporal-relations, and parameter-value constraints. These patterns will then be first-class (abstract) parameters in the domain's ontology. We are enhancing the RÉSUMÉ temporal-pattern matching mechanism accordingly, to detect and create these patterns at runtime.
3. We are adding the ability to represent cyclical temporal patterns in the knowledge-acquisition tool, to abstract these patterns by the RÉSUMÉ system, and to visualize them within the KNAVE module. We have already started developing the necessary syntax and semantics within the Asbru langauge, which enables designers of clinical guidelines to express complex clinical therapy plans and their intentions [Shahar et al., in press; Miksch et al., 1997].
4. We are enhancing the knowledge-acquisition tool to enable acquisition of necessary temporal-visualization knowledge. Examples include the relevant temporal-granularity ranges that should be used for visualization of each parameter (see Section 4.3), the default abstraction or statistical functions that should be used automatically when the visualization granularity is outside of the scope of the relevant temporal granularity, and domain-specific interface customizations (see Section 4.7).
4.5. Dynamic Communication Within The KNAVE Architecture
We are designing and implementing several communication protocols implied by the full KNAVE architecture and its dynamic intercomponent links. The KNAVE architecture comprises three main conceptual components (see Figure 3). Thus, we are designing links between the knowledge-based visualization and navigation modules, the domain ontology, and the temporal-database mediator with an integrated view in mind [Wiederhold et al., 1986].
The communication protocols are designing support both the static and dynamic data (raw input), information (abstracted conclusions) and knowledge (from the domain's temporal-abstraction ontology) requirements of the KNAVE system. Certain changes might need to be carried out with respect to the fashion in which the Tzolkin control module coordinates the actions of the RÉSUMÉ temporal-abstraction module and the Chronus temporal-maintenance module. For instance, intermediate abstractions created by the RÉSUMÉ system might need to be returned as part of the output, for navigation purposes.
4.5.1. Controling the overall goal of the abstraction process: Often, the overall context for the abstraction process can be induced automatically from the database record and the domain's temporal-abstraction ontology. For instance, therapy by the PAZ protocol induces a PAZ-therapy interpretation context, contemporaneous with the intervention interval; within that time interval, clinical data (e.g., hematological parameters) will be interpreted by the RÉSUMÉ system in a manner specific to that context. However, often the appropriate context for the abstraction process cannot be derived automatically from the data. For instance, when a physician examines the record of a patient who is known to have, among others problems, diabetes, she would like to visualize a summary of the patient's data during the past four weeks, from the point of view of supporting a diabetes therapy goal. She would not want to interprete all types of data in all potentially useful contexts, and certainly not throughout the patient's history. This goal, however, is only in the mind of the care provider and needs to be stated explicitly, so that it can be part of the database (at least temporarily) and thus can induce the appropriate interpretation context(s) (through the context-forming mechanism). We are adding an interactive module that enables users, during the visualization session, to dynamically add to the interpretation and visualization process abstraction goals [Shahar, 1997], whose main object is to set the overall context(s) and relevant time span(s). The overall context enables the context-sensitive mechanisms of the RÉSUMÉ system to create meaningful abstractions. Such a goal-oriented mode of performing the abstraction process is both necessary, efficient, and supports a useful dialog with the end user.
4.5.2. Interactive hypothetical queries: Users often wonder if another specific datum would have changed the overall view of some segment of the data, if added of removed. We enable at runtime addition and retraction of data to and from the KNAVE dynamic memory. Thus, we enable the user to ask hypothetical ("what-if") queries by hypothetically asserting or retracting data (e.g., "what if the platelet count during the previous visit was in fact 50,000 and not 80,00?") and by visualizing the resulting abstractions (e.g., the bone-marrow-toxicity grade might change to Grade III during the time interval corresponding to that visit, while certain abstraction might disappear). Both the abstraction capability and the what-if queries are supported by the RÉSUMÉ system [Shahar and Musen, 1993; Shahar and Musen, 1996] and its specialized truth-maintenance system, which maintains logical dependencies among data and their abstractions [Shahar, 1994; Shahar and Musen, 1996]. The RÉSUMÉ truth-maintenance system supports the nonmonotonic nature of temporal abstraction, whose conclusions are always potentially defeasible by additional data.
4.6. Interactive Knowledge-Based Explanation Of Temporal Abstractions
Users often require meaningful explanations for either
data interpretations or action recommendations, such as when a
physician examines the visual results of a temporal query to a
patient's record. Using the tight link between the KNAVE core
visualization client and the domain ontology server (see Figure
3), we provide users with various types of context-sensitive explanations.
For instance, we may need to answer a query such as "why
is this interval characterized as bone-marrow toxicity grade 3?"
(in addition to the query "from which data is it abstracted?"
which can be answered by semantic navigation along the ABSTRACTED-FROM
link). To answer that query, we retrieve from the domain's ontology
the classification knowledge (in this case, a mapping function
represented as a table) that defines the abstraction of bone-marrow
toxicity grades from the toxicity levels of platelets and granulocytes
in a context-sensitive fashion (e.g., specific to the PAZ-therapy
context in which the abstraction was created) (Figure 7).
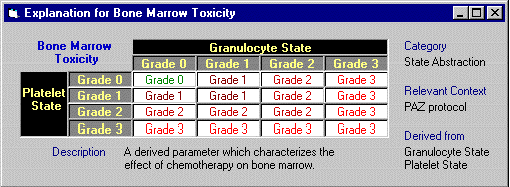
Figure 7: Providing an explanation to a bone-marrow-toxicity abstraction by showing a classification table
4.7. Explicit Representation Of Domain-Specific And Individual User Models
The KNAVE system should fit its interface terms and semantics (beyond the temporal-abstraction ontology) to the needs of each domain, and should accomodate the needs of different user types and even individual users within each domain. Thus, we enable a customization of the interface terms and behavior for each domain, including the listing of the relevant types of users in each domain (e.g., physcians, nurses, etc., in the case of medical domains) and their default preferences, and by also enabling customization by individual users in that domain. These customizations are part of the domain's (visualization) model. Thus, in the case of medical domains, we have added defaults specifying how to present data to various types of care providers such as nurses, interns, attending physicians, social workers, etc. Each user will be able to edit her own "user profile" and save it for future use. Examples include preferences such as whether to show just top level abstractions or all intermediate ones when returning the top-level abstraction in response to a temporal query (and similarly, whether to show just overall events or also their parts); over what span of time to start the initial query; what classes of data should be retrived by the initial query (e.g., a diabetes-therapy expert might want to always start a visualzation session by querying for the presence of certain periodic abstractions) and what types of abstractions are, in general, relevant to the user relevant (e.g., an intensive care nurse might be interested, as a default, only in rate and gradient abstractions of certain classes of parameters such as blood gases and vital signs).
The user interface module is being designed using a model-based approach. This means that in addition to the temporal-abstraction ontology, which is used to interpret data, there is also a domain model for the display of the data and its abstractions. Thus, the domain display model includes a set of arguments for modifying the layout, order of presentation, and customization of the behavior of semantic-navigation operators. Examples of using such a model can be found within all screen displays shown in this paper. Note the substitution of widget labels to provide domain-specific naming schemes. In the medical domain, concepts such as "primitive parameters", "abstract parameters", and "events," which originate from the ontology of the knowledge-based temporal-abstraction problem-solving method, were mapped [Gennari et al., 1994], respectively, to the terms "empirical data", "derived parameters", and "interventions" which are the default mappings for a medical domain.
The domain model also specifies a set of user profiles. These profiles further customize the display to accomodate the needs of particular user groups within a domain. This is not to be confused with the more common concept of user preferences, which are actually a further, individual, specialization on a particular type of a user profile.
5. EVALUATION OF THE KNAVE FRAMEWORK
We have performed a preliminary developmental assessment of a small prototype version of the KNAVE core modules, as a pilot study to test our hypothesis that a task-specific knowledge-driven visualization and navigation system is both feasible and useful, and to get preliminary feedback from potential users in various different medical domains [Cheng et al., 1997]. The data and the domain temporal-abstraction ontologies were represented as simple files. The prototype, whose screen displays were shown in Figures 4 to 7, included a subset of the static and dynamic, semantic and syntactic operators that we will implement in the reengineered system. Six users with varying medical and computer-use backgrounds were requested to answer within 20 minutes a fixed set of complex temporal queries about the particular set of data we used, using only the new interface and a brief introduction to the navigation interface. The users were not otherwise familiar with the KNAVE system. The results were highly encouraging with respect to the users' subjective enthusiasm towards the framework's potential and the objective capability of the prototype to provide visual answers to the various queries that the users tried to answer. One of the lessons we learned, which we will emphasize in the final implementation, was the importance of redundancy. Somewhat surprisingly, answers were typically found using several (up to four) different paths to get to the same visualized set of abstractions (e.g., through the semantic-navigation interface, by going back to the initial temporal-query interface, by using the navigaton drop menu, or by using a short-cut mouse right-button function). Based on the preliminary assessment, we are performing developmental assessments and evaluations from the very beginning of the final implementaton of the KNAVE architecture, using our collaborators in several medical domains and clinical data sets, several of which we already have, and several of which our collaborators supply as necessary.
We are also evaluating the overall KNAVE architecture within EON, an architecture for guideline-based medical care [Musen et al., 1996]. EON is evaluated in domains such as protocol-based care for AIDS patients and oncology.
In addition, our work in the traffic-control domain [Shahar and Molina, 1996; Molina and Shahar, 1996] provides significant amounts of spatiotemporal traffic sensor data that will be very useful for assessing the effectiveness of our domain-independent methodology. It is our hypothesis that our methodology is useful in most domains in which data are captured over a linear distance measure (such as uni-dimensional space along each highway, and the evolution of the spatial abstractions over time), and in which there exist several levels of abstraction of the data.
After the final reengineering is done, we will perform a more formal evaluation of the KNAVE framework, including more users, qualitative and quantitative questionairs, "thinking aloud" experiments, inclusion of well-defined target user behaviors, and application of standard methods for interface usability assessments [Gould, 1988].
6. DISCUSSION
We have presented a conceptual and computational knowledge-based framework for interactive visualization, navigation, and browsing of time-oriented data and their multiple levels of temporal abstractions. In this framework, the semantics of the querying, browsing, navigation, and explanation operators are defined by the domain-independent ontology of the knowledge-based temporal-abstraction problem-solving method. The semantic-navigation operators allow the runtime user to navigate visually through the domain-specific temporal-abstraction (sub) ontologies, thereby leading to reciprocal visual navigation through the multiple levels of temporal abstractions of the particular time-oriented database that is queried. Thus, although the KNAVE interface is essentially the same (apart from certain domain- and user-dependent customizations) in every domain, and the semantics of the syntactic and semantic navigation operators are identical, the resultant browsing process is specialized to the domain's parameter, event, context, and abstraction-goal (sub) ontologies, which the knowledge-based temporal-abstraction ontology comprises.
The visualization and navigation modules of the KNAVE architecture and the inference structure underlying them can be viewed as part of a new problem-solving method, specific to the task of visualization of and navigation through time-oriented data and its temporal abstractions. The ontology of this knowledge-based visualization method is a superset of the ontology of the knowledge-based temporal-abstraction problem-solving method, augmenting it with additional knowledge such as classes (e.g., statistical abstractions) and properties (e.g., visualization knowledge, such as what temporal resolution range is relevant for the visualization of each parameter) that are specific to the interactive-visuallization task. The domain-specific temporal-abstraction knowledge acquired from domain experts is thus reused by a different problem-solving method and shared by a different application within the same domain. The new method also reuses the computational mechanisms of the knowledge-based temporal-abstraction problem-solving method and augments them by the visualization and navigation mechanisms.
The applicabiity of the RÉSUMÉ system to strikingly different time-oriented domains such as guideline-based medical care, monitoring of children's growth, therapy of diabtes, and traffic control suggests that the new knowledge-based visualization methodology will be widely applicable as well. Furthermore, the experiments within the traffic-control domain [Shahar and Molina, 1996] have demonstrated that the knowledge-based temporal-abstraction methodology is useful for acquisition and maintenance of other types of linear-abstraction knowledge, such as spatial-abstraction knowledge. These experiments suggest similar applicability of the knowledge-based visualization methodology to domains that employ linear distance measures and to the semiautomated (interactive) support of tasks such as monitoring, planning, explanation, and data mining. The evaluation of the reengineered KNAVE system in severel different domains will provide further insights into these intriguing hypotheses.
Acknowledgements
This work has been supported by grants LM05708 and LM06245 from the National Library of Medicine and IRI-9528444 from the National Science Foundation. Computing resources were provided by the CAMIS project, funded under grant No. LM05305 from the National Library of Medicine.
References
Allen, J.F. (1984). Towards a general theory of action and time. Artificial Intelligence 23, 123-154 .
Becker B. G. (1997). Using MineSet for knowledge discovery, IEEE Computer Graphics and Applications 7/8, 75-78.
Blum, R.L. (1982). Discovery and representation of causal relationships from a large time-oriented clinical database: The RX project. In Lindberg, D.A. and Reichartz, P.L. (eds), Lecture Notes in Medical Informatics, volume 19, New York: Springer-Verlag.
Carpendale M.S.T., Cowperthwaite D.J., and Fracchia F.D. (1997). Extending Distortion Viewing from 2D to 3D. IEEE Computer Graphics and Applications 7/8, 42-51.
Chandrasekaran, B. (1986). Generic tasks in knowledge-based reasoning: High-level building blocks for expert system design. IEEE Expert 1, 23-30.
Cheng, C., Shahar, Y., Puerta, A.R., and Stites, D. P., (1997). Navigation and Visualization of Abstractions of Time-Oriented Clinical Data, Section on Medical Informatics Technical Report No. SMI-97-0688, Stanford University, CA.
Clancey, W.J. (1985). Heuristic Classification. Artificial Intelligence 27, 289-350.
Cousins, S.B., and Kahn, M.G. (1991). The visual display of temporal information. Artificial Intelligence in Medicine 3, 341-357.
Das, A.K., and Musen, M.A. (1994). A temporal query system for protocol-directed decision support. Methods of Information in Medicine 33(4), 358-370.
Das, A.K., Shahar, Y., Tu, S.W., and Musen, M.A. (1994). A temporal-abstraction mediator for protocol-based decision support. Proceedings of the Eighteenth Annual Symposium on Computer Applications in Medical Care, pp. 320-324, Washington, DC.
De Zegher-Geets, I.M. (1987). IDEFIX: Intelligent summarization of a time-oriented medical database. M.S. Dissertation, Medical Information Sciences Program, Stanford University School of Medicine, June 1987. Knowledge Systems Laboratory Technical Report KSL-88-34, Department of Computer Science, Stanford University, Stanford, CA.
Downs, S.M., Walker M.G., and Blum, R.L. (1986). Automated summarization of on-line medical records. In Salamon, R., Blum, B. and Jorgensen, M. (eds), MEDINFO '86: Proceedings of the Fifth Conference on Medical Informatics, pp. 800-804, North-Holland, Amsterdam.
Eriksson, H., Shahar, Y., Tu, S.W., Puerta, A.R., and Musen, M.A. (1995). Task modeling with reusable problem-solving methods, Artificial Intelligence 79 (2), 293--326.
Fagan, L.M. (1980). VM: Representing Time-Dependent Relations in a Medical Setting. Ph.D. dissertation, Department of Computer Science, Stanford University, Stanford, CA.
Genesereth, M.R., and Fikes, R.E. (1992). Knowledge Interchange Format, Version 3.0 Reference Manual. Technical Report Logic-92-1, Computer Science Department, Stanford University, Stanford, CA.
Gennari, J.H., Tu, S.W., Rothenfluh, T.E., and Musen, M.A. (1994). Mapping domains to methods in support of reuse. International Journal of Human-Computer Studies, 41 (1994) 399-424.
Giarratano, J., and Riley, G. (1994). Expert Systems: Principles and Programming. Boston, MA: PWS Publishing Company.
Gould J.D. (1988). How to design Usable systems, in M. Helander (ed), Handbook of Human-Computer Interaction. Elsevier Science Publishers.
Gruber, T.G. (1993). A translation approach to portable ontology specification. Knowledge Acquisition 5, 117-243.
Haimowitz, I.J., and Kohane, I.S. (1993). Automated trend detection with alternate temporal hypotheses. Proceedings of the Thirteenth International Joint Conference on Artificial Intelligence, pp. 146-151, San Mateo: Morgan Kaufmann.
Kahn, M.G., Abrams, C.A., Cousins, S.B., Beard, J.C., and Frisse, M.E. (1990). Automated interpretation of diabetes patient data: Detecting temporal changes in insulin therapy. In Miller, R. A. (ed), Proceedings, of the Fourteenth Annual Symposium on Computer Applications in Medical Care , pp. 569-573, Los Alamitos: IEEE Computer Society Press.
Kahn, M.G. (1991). Combining physiologic models and symbolic methods to interpret time-varying patient data. Methods of Information in Medicine 30, 167-178.
Kohane, I.S. (1987). Temporal reasoning in medical expert systems. Technical Report 389, Laboratory of Computer Science, Massachusetts Institute of Technology, Cambridge, MA.
Kolojejchick J., Roth S.F., and Lucas P. (1997). Information Applications and Tools in Visage. IEEE Computer Graphics and Applications 7/8, 32-41.
Kuilboer, M.M., Shahar, Y., Wilson, D.M., and Musen, M.A. (1993). Knowledge reuse: Temporal-abstraction mechanisms for the assessment of children's growth. Proceedings of the Seventeenth Annual Symposium on Computer Applications in Medicine, pp. 449-453, Washington, DC.
Larizza, C., Moglia, A., and Stephanelli, M. (1992). M-HTP: A system for monitoring heart-transplant patients. Artificial Intelligence in Medicine 4, 111-126.
McDermott, J. (1988). Preliminary steps toward a taxonomy of problem-solving methods. In Marcus, S. (ed), Automating Knowledge-Acquisition for Expert Systems. Boston: Kluwer.
Miksch, S., Shahar, Y., and Johnson, P.D. (1997). Asbru: A task-specific, intention-based, and time-oriented language for representing skeletal plans. Proceedings of the Seventh Workshop on Knowledge Engineering Methods and Languages (KEML-97), Open University, Milton Keynes, UK.
Molina, M., and Shahar, Y. (1996) Problem-solving method reuse and assembly: From clinical monitoring to traffic control. Proceedings of the Tenth Banff Knowledge Acquisition for Knowledge-based systems Workshop, Vol 1, pp. 7-1-7-20, Banff, Alberta, Canada.
Musen, M.A. (1989). Automated Generation of Model-based Knowledge-Acquisition Tools. San Mateo, CA: Morgan Kaufmann.
Musen, M.A. (1992). Dimensions of knowledge sharing and reuse. Computers and Biomedical Research 25, 435-467.
Musen, M.A., Gennari, J.H., Eriksson, H., Tu, S.W., and Puerta, A.R. (1995). PROTÉGÉ-II: Computer support for development of intelligent systems from libraries of components. In MEDINFO '95: Proceedings of the Eight World Congress on Medical Informatics, Vancouver, British Columbia.
Musen, M.A., Tu, S.W., Das, A.K., and Shahar, Y. (1996). EON: A component-based approach to automation of protocol-directed therapy. Journal of the American Medical Association 3 (6), 367-388.
Newell,A. (1982). The knowledge level. Artificial Intelligence 18, 87-127.
Nguyen, J., Shahar, Y., Tu. S.W., Das, A.K., and Musen, M.A. (1997). A Temporal Database Mediator For Protocol-Based Decision Support. Proceedings of the 1997 AMIA Annual Fall Symposium (formerly the Symposium on Computer Applications in Medical Care), pp. 298-302, Nashville, TN.
Powsner, S.M. and Tufte E.R. (1994). Graphical Summary of Patient Status, Lancet 344, 386-389.
Puerta, A.R., Egar, J.W., Tu, S.W., and Musen, M.A. (1992). A multiple-method knowledge-acquisition shell for the automatic generation of knowledge-acquisition tools. Knowledge Acquisition 4, 171-196 .
Rohrer, R., and Swing E. (1997). Web-based information visualization, IEEE Computer Graphics and Applications 7/8, 52-59.
Russ, T.A. (1989). Using hindsight in medical decision making. Proceedings, Thirteenth Annual Symposium on Computer Applications in Medical Care (L. C. Kingsland, Ed.), pp. 38-44, IEEE Comput. Soc. Press, Washington, D.C.
Shahar, Y., Tu, S.W., and Musen, M.A. (1992). Knowledge acquisition for temporal-abstraction mechanisms. Knowledge Acquisition 4, 217-236.
Shahar, Y., and Musen, M.A. (1993). RÉSUMÉ: A temporal-abstraction system for patient monitoring. Computers and Biomedical Research 26, 255-273. Reprinted in van Bemmel, J.H., and McRay, A.T. (eds) (1994), Yearbook of Medical Informatics 1994, pp. 443-461, Stuttgart: F.K. Schattauer and The International Medical Informatics Association.
Shahar, Y. (1994). A knowledge-based method for temporal abstraction of clinical data, Ph.D. dissertation, Program in Medical Information Sciences, Stanford University School of Medicine. Knowledge Systems Laboratory Report No. KSL-94-64, 1994. Department of Computer Science report No. STAN-CS-TR-94-1529, Stanford University, Stanford, CA, 1994.
Shahar, Y. (1997). A framework for knowledge-based temporal abstraction. Artificial Intelligence 90 (1-2), 79-133.
Shahar, Y., Das, A.K., Tu, S.W., Kraemer, F.B., Basso, L.V., and Musen, M.A. (1995). Knowledge-based temporal abstraction in diabetes therapy. Proceedings of MEDINFO-95, the Eight World Congress on Medical Informatics, pp. 852-856, Vancouver, B.C., Canada.
Shahar, Y., and Musen, M.A. (1995). Plan recognition and revision in support of guideline-based care. Proceedings of the AAAI Symposium on Representing Mental States and Mechanisms, pp. 118-126, Stanford University, CA.
Shahar, Y., and Musen, M.A. (1996). Knowledge-based temporal abstraction in clinical domains. Artificial Intelligence in Medicine 8 (3), 267-298.
Shahar, Y., Miksch, S., and Johnson, P.D. (in press). A task-specific ontology for the application and critiquing of time-oriented clinical guidelines. Artificial Intelligence in Medicine.
Shahar, Y., and Molina, M. (1996). Knowledge-based spatiotemporal abstraction. Proceedings of the AAAI-96 Workshop on Spatial and Temporal reasoning, pp. 21-29, Portland, Oregon.
Shahar, Y. (1997a). Knowledge-based temporal interpolation. Proceedings of The 1997 Fourth International Workshop on Temporal Representation and Reasoning (Time-97), Daytona, Florida, pp. 102-111.
Shahar, Y. (in press). Dynamic temporal interpretation contexts for temporal abstraction. Annals of Mathematics and Artificial Intelligence.
Shoham, Y. (1987). Temporal logics in AI: Semantical and ontological considerations. Artificial Intelligence 33, 89-104.
Snodgrass, R., and Ahn, I. (1986). Temporal databases. IEEE Computer, 19, 35-42.
Stein, A., Musen, M.A., and Shahar, Y. (1996). Knowledge acquisition for temporal abstraction. Proceedings of the 1996 AMIA Annual Fall Symposium (formerly the Symposium on Computer Applications in Medical Care), pp. 204-208, Washington, DC.
Tufte, E.R. (1982). The Visual Display of Quantitative Information. Graphics Press:CT.
Tufte, E.R. (1990). Envisioning Information . Graphics Press:CT.
Tufte, E.R. (1997). Visual Explanations. Graphics Press:CT.
S.W. Tu, M.G. Kahn, M.A. Musen, J.C. Ferguson, E.H. Shortliffe, and L.M. Fagan, Episodic skeletal-plan refinement based on temporal data, Communications of the ACM 32(12) (1989) 1439-1455.
Tu, S.W., Shahar, Y., Dawes, J., Winkles, J., Puerta, A.R., and Musen, M.A. (1992). A Problem-Solving Model for Episodic Skeletal-Plan Refinement. Knowledge Acquisition 4, 197-216.
Tu, S. W., Eriksson, H., Gennari, J., Shahar, Y., & Musen, M. A. (1995). Ontology-based configuration of problem-solving methods and generation of knowledge-acquisition tools: Application of PROTÉGÉ-II to protocol-based decision support. Artificial Intelligence in Medicine 7 (3), 257-289.
Wiederhold G., Blum R.L., and Walker M. (1986). An integration of knowledge and data representation. In: Brodie, M.L., Mylopoilos, J., and Schmidt, J.W., eds., On Knowledge base Management Systems: Integrating Artificial Intelligence and Database Technologies, 431-444, Springer Verlag.
Wiederhold G. (1992). Mediators in the architecture of future information systems, IEEE Computer 3, 38-49.
Weilinga, B., Schreiber, A.T., and Breuker, J. (1992). KADS: a modeling approach to knowledge engineering. Knowledge Acquisition 4, 5-53.
Wright, W. (1997). Business visualization applications.
IEEE Computer Graphics and Applications 7/8, 66-70.