This paper describes the Observo-Soar system
which learns task knowledge, suitable for planning and execution, from
observation of an expert. Learning by observation is a very efficient
form of knowledge acquisition which requires nothing of the expert
beyond demonstrating the task. Previous learning by observation
systems have suggested techniques for learning in complex domains and
taking advantage of complex forms of knowledge representations.
Observo-Soar combines the strengths of these related system and
introduces some new concepts to make learning by observation even
more effective. Observo-Soar is an independent learning agent
which observes the expert's behavior and attempts to generate
and improve it's own task knowledge based on these observations.
1.0 INTRODUCTION
The acquisition and encoding of task knowledge is a difficult and time consuming process usually involving both a subject matter expert (SME) and a knowledge engineer. Any agent which interacts directly with the SME to automatically learn or encode knowledge can considerably reduce the cost of knowledge acquisition. The SME is able to teach the agent directly rather than the two step process of the SME teaching the knowledge engineer and then the knowledge engineer encoding the knowledge. However, the SME is still required to organize and describe the necessary knowledge. Describing all the relevant knowledge in sufficient detail can be difficult for a SME or even impossible in sub-cognitive tasks such as flying a plane or riding a bike.
An agent which observes the SME performing the task and automatically learns task knowledge directly from these observations does not require the SME to do any knowledge description. Learning by observation requires the SME to do nothing other than perform the task at which he is an expert. In addition to making fewer demands on the SME, observation has a number of other advantages as a knowledge source. Since the SME doesn't have to describe the necessary knowledge, learning by observation is equally effective on cognitive and sub-cognitive tasks. It is generally cheap and easy to record traces of the expert's behavior as logs of the information the expert receives and the expert's actions. If multiple experts are available, observations can capture variations in their behavior and provide multiple styles of behavior or a combined style which draws on the experience of a group of experts. Also, learning by observation is easily be combined with other knowledge sources which help the learning system focus on the relevant details of the expert's behavior.
This paper describes the Observo-Soar system which learns task knowledge, suitable for planning and execution, from observation of an expert and a limited amount of expert input. In our system, task knowledge takes the form of an operator hierarchy and a set of state elaborations. Each operator in the hierarchy has a set of state features as pre-conditions, a set of potentially conditional actions, a set of state features as termination conditions and a set of sub-operators. State elaborations are simply new features which are placed on the state based on one or more existing features. To be suitable for planning as well as execution, the operators must include some knowledge about their expected effects. These effects are necessary for the planning system to predict the effectiveness of a plan.
Observo-Soar's observations consist of a sequence of time steps with the input from the environment (i.e. sensor inputs) and any actions taken by the expert recorded at each time step. The system can act as a real time agent, using these observations as they are generated, or the observations can be stored and used to learn off line. The sensor inputs and actions are described in terms of the description language for the domain. A knowledge engineer is still be required to develop this domain description language, which should attempt to mimic the concepts used by the expert as much as possible. The Observo-Soar system is designed to work in complex domains with real time behavior requirements, external actions, non-determinism and other complications. Thus the time steps can potentially be very short with lots of activity in some time steps and no activity in others.
In the next section two previous research
efforts which have resulted in learning by observation systems,
behavioral cloning (Sammut, Hurst, Kedzier and Michie, 1992, Bain
and Sammut, 1995) and the OBSERVER system (Wang, 1995), are described.
Observo-Soar, which is described in the third section, combines
many of the strengths of these two systems while overcoming some
of the weaknesses. Section three also presents results from our
preliminary use of Observo-Soar as a learning agent in a complex
domain.
2.0 RELATED RESEARCH
The Observo-Soar system described in this paper draws on aspects of two previous research efforts. Behavioral cloning uses pure induction to build decision trees which decide which actions to take based on the sensor input. Unlike many other machine learning algorithms, behavioral cloning has been successfully applied to a complex, real world domain. However, the representation of the task knowledge learned by behavioral cloning is limited and not suitable for planning. The OBSERVER system uses a version spaces type approach (Mitchell, 1978) to learn STRIPS style operators (Fikes and Nilsson, 1971). OBSERVER learns complex forms of task knowledge which include knowledge about the effects of operators required for planning. However, OBSERVER makes many assumptions about the domain which limits its effectiveness in complex, dynamic domains. Observo-Soar can be viewed as an attempt to combine the powerful knowledge representation of OBSERVER with the techniques used by behavioral cloning to learn in a complex domain.
2.1 Behavioral Cloning
Sammut, Hurst, Kedzier and Michie have used behavioral cloning to learn the knowledge necessary to fly a Cessna along a specific flight plan within the Silicon Graphics flight simulator. A human expert, whose behavior is to be cloned, flies a strictly defined flight plan 30 times. An observation log of each flight is created by recording the sensor inputs and the value of each control approximately 20 times a second. These observation logs form a large set of training examples with the sensor inputs as the attributes and the controls as the class values. Behavioral cloning uses this set of training examples to induce decision trees which classify the appropriate control value (or action) based on the current sensor inputs. These decision trees can then be used to mimic the expert's behavior and fly the plane by setting each control to the value specified by applying the current sensor inputs to the decision tree.
Initial attempts to induce decision trees from the entire set of observations log were unsuccessful. Simple data analysis led to some modifications in how the observation logs were presented to the induction program (Quinlan, 1987). For example, rather than learn a single decision tree for each control, the flight plan was divided into seven stages and a separate decision tree was learned for each stage. Since each stage has a different goal, such as takeoff and fly to an altitude of 2,000 feet, the expert's responses to the same sensor inputs differ and a separate decision tree is needed. Thus, splitting the observation logs into stages adds a goal directed aspect to behavioral cloning. Similarly, observations from multiple experts were not combined as different experts achieve goals using different techniques.
With these (and other) modifications, the induction program was able to learn 28 decision trees which effectively controlled the four controls over the seven stages of the flight plan. Using these decision trees, the execution system was able to successfully take off, follow the defined flight plan and land in a manner very similar to the expert. The learned task knowledge actually flew a smoother flight than the experts. Sammut et al. attribute this to the clean-up effect in which the learned knowledge captures the expert's overall behavior in the 30 flights without the constant small error corrections exhibited in each individual flight.
One of the most impressive aspects of behavioral cloning is its effectiveness in such a complex domain. The flight simulator domain is non-deterministic, includes a large set of complex sensors, exhibits standard and homeostatic goals and the observation logs contain noise in the form of the expert's constant minor error corrections. The SGI flight simulator uses the computer's system clock to control the simulator and updates the environment very rapidly. This fine grained, real time requirement precludes any form of knowledge representation which can't generate responsive behavior rapidly. By using a number of small decision trees, behavior cloning splits the knowledge into many, rapidly processed rules which can be evaluated sufficiently quickly.
Due to the noise and non-determinism of the domain, behavior cloning must avoid learning knowledge based on a single observation. A single observation might be incorrect due to noise or might represent a very unlikely situation. Learning from an incorrect observation will result in incorrect knowledge while learning to account for every situation will require huge decision trees which aren't sufficiently reactive. The inductive learning algorithm used by behavioral cloning generates decision trees based on the entire set of observations and therefore learns correct, compact decision trees even in noisy, non-deterministic domains.
Another strength of behavioral cloning is its use of goals in the learning process. By taking the current goals of the expert, as represented by the stage of the flight plan, into account the task knowledge can be better focused on obtaining these goals. One major factor in the failure of the initial attempts to induce decision trees was the lack of goal knowledge in the learning process. Learning a single decision tree to perform all seven stages of flight was too difficult a problem. Learning seven decision trees, each focused on a single goal, was tractable.
The major weakness of the behavioral cloning technique is the limited usefulness of decision trees as a form of knowledge representation. The decision trees learned are effective for a single flight plan but are no longer applicable once the flight plan or the type of aircraft changes. Because decision trees can't easily handle symbolic inputs, such as flight plans, it is impossible to learn generally useful decision trees which could fly multiple paths. Another weakness of decision trees is that they only encode reactive knowledge useful for execution. To be used in planning, task knowledge must be predictive to allow the outcome of potential plans to be foreseen and tested. Decision trees contain no information about the effects of their actions and therefore are not appropriate for planning.
2.2 OBSERVER
The OBSERVER system learns STRIPS style operators, which are more useful than decision trees, using a learning method similar to version spaces. Xuemei Wang developed OBSERVER and applied it to a process planning domain in which the task is to generate a plan to produce machine parts given a set of specifications. For each operator OBSERVER creates and refines a most specific set of operator preconditions S(Op), a most general set of operator preconditions G(Op) and a set of operator effects E(Op). OBSERVER initially learns S(Op) and E(Op) in a learning by observation phase. Then a second, learning by practice phase, is used to improve S(Op) and E(Op) and to learn G(Op). When S(Op) and G(Op) match then the operator's preconditions are assumed to be correct.
The observations used by OBSERVER consist of a sequence of steps which the expert performed to generate the machine part. For each step in the observation the state of the system is recorded. There is no aspect of external time or external action in the process planning domain. Each step in the observation represents an arbitrary amount of real time and is considered to be a single operator application. The only changes to the environment are directly caused by the actions of the operators. In addition to these two factors, the process planning domain is made even less complex by the lack of noise and non-determinism.
OBSERVER begins learning by generating initial versions of S(Op) and E(Op) during the observation phase. The most specific preconditions, S(Op), of an operator are generated by examining the state of the system in the step before the operator Op is applied. Features which are always present in this pre-state are likely to be pre-conditions of the operator and should be included in S(Op). At the beginning of the observation phase a single observation is selected and S(Op) is initialized as the set of all features in the pre-state of the system when Op was applied. S(Op) is then generalized by examining additional observations and removing features not present when Op was applied. The effects of the operator, E(Op), can be determined by examining how the state of the system changed when the expert applied the operator. For example, the pick-up operator might add an is-holding feature to the state and remove an on-table feature. The addition of is-holding and the removal of on-table is called the delta state of the pick-up operator. In a fashion similar to the generation of the most specific preconditions, the effects of an operator are initialized to the entire delta state of a selected observation. However, when additional observations don't contain features in the initial E(Op) these addition features are assumed to be conditional effects and a set of action preconditions are learned. At the end of the observation phase reasonable values have been obtained for S(Op) and E(Op). During the practice phase these initial values are used to attempt to solve practice problems. As these practice problems are solved the values of S(Op) and E(Op) are refined and G(Op) is generated. As the research presented here focuses on learning by observation the practice phase won't be described in detail.
An obvious advantage of the OBSERVER system over behavioral cloning is that the task knowledge learned by OBSERVER uses a less limited form of representation. The STRIPS style operators learned by OBSERVER include such complex forms of representation as negated preconditions and conditional actions. While these operators are somewhat more difficult to learn, they can represent general knowledge effectively and can deal with the types of complex symbolic inputs which decision trees could not handle. Additionally, the operator effects, E(Op), which are learned as part of each operator, predict how applying the operator will change the current state. These effects provide the predictive knowledge necessary to track the outcome of proposed plans and determine whether they will achieve the desired goals.
The OBSERVER system is described in the
context of the process planning domain which, unfortunately, isn't
as complex as the flight simulation domain. One weakness of the
STRIPS style operators used by OBSERVER is that they are better
suited to representing large, complex actions and might not be
sufficiently reactive and fine grained for the flight simulation
domain. Since the process planning domain contains no noise or
non-determinism OBSERVER can and does generates knowledge based
on a single observation. In more complex domains this might result
in incorrect or over specific operators. OBSERVER also fails
to use any goal knowledge in it's learning process. Goal knowledge
would be very useful in learning operator effects as the goal
provides a set of features which the operators are trying to achieve
and are therefore likely to appear in the effects of the operators.
3.0 OBSERVO-SOAR
Observo-Soar can be viewed as a learning by observation agent which combines a form of knowledge representation similar to OBSERVER's with behavioral cloning's ability to learn effectively in complex domains. Observo-Soar uses Soar style operators (Laird, Newell and Rosenbloom, 1987) for knowledge representation which are similar to the STRIPS style operators used in OBSERVER. This allows Observo-Soar to learn generally useful, complex knowledge which is appropriate for planning and execution. However, Observo-Soar's Soar style operators are better suited to complex, dynamic domains. Observo-Soar's learning algorithm also bears some resemblance to OBSERVER's version spaces approach but it is also modified to take advantage additional knowledge available in dynamic domains.
Many of the techniques used by behavioral cloning to learn effectively in the complex flight simulator domain are also found in Observo-Soar. The Soar style operators are expressed as a number of small individual rules each of which can be fired quickly. As with behavioral cloning's decision trees, this allows Observo-Soar to react quickly in a rapidly changing, real time domain. Observo-Soar also avoids learning based on single observations, instead allowing subsequent observations to correct or even replace previously learned knowledge. Additionally, Observo-Soar makes extensive use of goal knowledge to focus the learning process. Unlike behavioral cloning's fixed goals, Observo-Soar uses dynamically updated goals and subgoals provided by the expert as part of the observation.
3.1 Knowledge Representation
The knowledge representation used in Observo-Soar is a modified version of STRIPS style operators which retains the concept of an operator as a step towards the goal, which is useful for planning without losing the reactiveness of decision trees. As with the STRIPS operators, Soar operator contain operator preconditions and operator effects. However, Soar operators also contain a set of operator termination conditions which specify when the operator's actions have been completed. In the STRIPS model of one operator application per time step there is no need for operator termination conditions. However in more dynamic domains, such as the flight simulator domain, an operator may be applied over a series of time steps and termination conditions are necessary. Furthermore, separate if-then rules are learned to propose (or start) the operator when the preconditions are matched, perform the actions of the operator, and terminate the operator when the termination conditions are achieved. By splitting the operator into multiple smaller rules reactiveness is retained without losing the central concept of the operator. The operator proposal rules record the name of the current operator on the state and the action and termination rules test this value to guarantee that they only fire when appropriate. Soar operators may contain no effect or action rules in which case a subgoal is created when the operator is selected and a sequence of sub-operators are selected, applied and terminated. This hierarchical operator structure is very useful in representing the hierarchical goals which experts frequently use to describe tasks. Both behavioral cloning and OBSERVER are limited to a flat operator structure.
In addition to operator proposal, action and termination rules, a fourth type of rule available in the Soar style of knowledge representation is the state elaboration rule. A state elaboration rule fires independently of any operator and simply tests a set of features on the current state and, based on their values, adds a new feature to the state. This new feature persists as long as the instantiation of the rule which created it is matched. These state elaboration rules are very useful for representing relationships between features on the state which are commonly tested in the domain. For example, a state elaboration rule might test that the value of the current-altitude feature is equal to the value of the cruising-altitude feature. If the conditions of this rule were met then an (achieved-cruising-altitude true) feature might be added to the state. This new feature could then be tested directly by any number of operator rules or other state elaboration rules. While each of these rules could test the original conditions directly the state elaboration approach has a number of advantages. If multiple operator rules need to test the same feature relations it is more efficient to learn that relation once and reuse that learned knowledge rather than relearn the relation for each operator rule. Also, state elaborations used in multiple places are likely to represent concepts in the domain which are familiar to the expert making the learned operator rules easier to understand.
3.2 Observo-Soar System Description
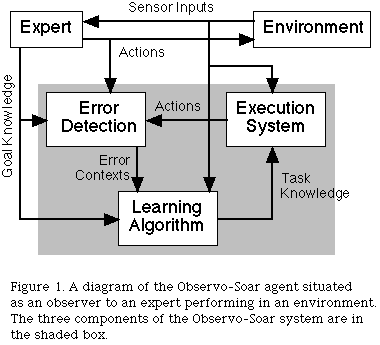
In the Observo-Soar system the task knowledge is used to perform the task in parallel with the expert and differences between the expert's actions and the task knowledge's actions are detected and used to learn improved task knowledge (see figure 1). The three basic components of the Observo-Soar system are the execution system, the error detection system and the learning algorithm. The execution system component reads the sensor inputs and determines what actions would be taken based on these inputs and the current task knowledge. These actions are passed to the error detection component which compares the task knowledge's actions to the expert's actions and discovers any discrepancies. These discrepancies are flagged as potential task knowledge errors and passed to the learning component which attempts to generate improved, error free task knowledge from the context of the error and the relevant sensor inputs. Goal knowledge provided by the expert is used in error detection and learning to direct and focus the creation of operators and the operator hierarchy.
Behavior is generated from the task knowledge through the use of the Soar architecture as the execution system. At a simple level, the Soar architecture updates the current state with the sensor inputs and any state elaborations and then selects an operator with matching preconditions. Once an operator is selected its action rules and/or sub-operators are applied until the termination conditions are met. When the operator is terminated a new operator is selected and applied. A full description of the Soar architecture (Laird, Newell and Rosenbloom, 1987) is not necessary to understand the Observo-Soar system. The important point is that the Soar architecture generates actions based on the sensor inputs and the task knowledge. These actions are passed to the error detection component.
The error detection component takes the task knowledge's actions, the expert's actions and any available goal information and determines if significant differences are present between the expert's and task knowledge's actions. The goal knowledge is used to compare the expert's current goals with the goals being pursued by Observo-Soar. If a significant difference is found between the expert's behavior and the task knowledge's behavior then the context of the difference (or error) is passed to the learning algorithm. The context of a behavior error consists of the two differing actions, the task knowledge operator which generated the incorrect action and the current set of goals. In some cases, especially when the domain is initially being learned, the error may be caused by the lack of an operator which resulted in no action on the part of the task knowledge. In other cases an operator may exist but may have incorrect preconditions or actions resulting in the task knowledge performing a different action than the expert. Distinguishing between trivial differences and significant differences in behavior is a challenging area of future work. The currently implemented Observo-Soar system considers any difference in behavior to be significant.
The learning algorithm takes the information in the error context, the current sensor inputs and the available goal knowledge and attempts to generate new or improved task knowledge which is then added to the execution system. The currently implemented learning algorithm is very simple but does effectively learn two types of task knowledge, operator proposal rules and operator termination rules. If the expert begins working on a new goal, as specified by the goal knowledge in the observation, and an equivalent operator is not selected within the task knowledge then an error is detected and a new operator proposal rule must be learned. The last set of features to change on the sensor input before the expert selected the new goal are used as the conditions of the new proposal rule. The new proposal rule simply proposes the operator and records it on the state. Similarly, the last set of features to change on the sensor input before the expert terminates a goal are used as the conditions for the operator termination rule. This learning bias towards the most recent changes is motivated by the belief that one of these recent changes in the sensor input triggered the change in goals. Subsequent observations of goal changes can make the rules more general by removing or modifying conditions which were not observed to change as the goal shift occurred a second time
3.3 Preliminary Results
While the components of the currently implemented system are relatively simple they are capable of learning some types of task knowledge in the racetrack domain. The racetrack domain contains many of the same complexities as the flight simulator domain. The task in this domain involves a simulated flight in the ModSAF flight simulator consisting of taking off, flying to a specific position, flying away from that position in a specified direction for a specified distance and then flying back to the position (see figure 2). In air to air combat the racetrack maneuver is commonly flown by aircraft patrolling or protecting a location. The racetrack position, direction and distance are specified in the sensor data as part of the mission description. The results presented here are generated by applying Observo-Soar to the racetrack domain using the TacAir-Soar agent (Tambe, Johnson, Jones, Koss, Laird, Rosenbloom and Schwamb, 1995) as the expert. The domain description language (i.e. the features used to describe the environment in the sensor inputs) used in these experiments were developed as part of the TacAir-Soar project and have not been altered in any way to support Observo-Soar. The micro-TacAir-Soar agent divides the domain into two top level goals, takeoff and fly-racetrack, and three sub-goals of fly-racetrack, fly-to-position, fly-outbound-leg and fly-inbound-leg. Since Observo-Soar currently learns only operator proposal and termination rules, the goals on which these rules are based will be described without the details of the expert's actions. Two examples of Observo-Soar's learning process are presented here.
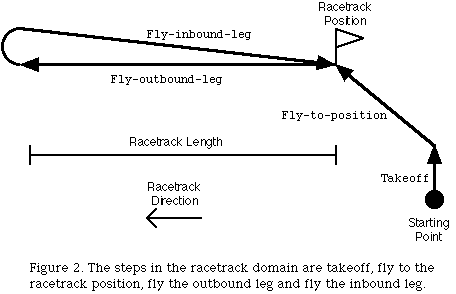
Takeoff is the initial goal and is satisfied once the takeoff heading, altitude and speed have been achieved. At the beginning of the observation the expert declares takeoff to be the current goal. Observo-Soar has no takeoff operator initially and therefore an error is detected. This error is passed to the learning algorithm which creates a takeoff proposal rule (see figure 3). As described above, the conditions of the takeoff proposal rule consist of any features recently added to the sensor input. When the takeoff goal is selected the system is starting up and a large number of features are being added to the sensor inputs. As a result, the takeoff proposal rule has a large number of conditions. While most of these conditions are unnecessary they are not incorrect in that the takeoff rule will only be matched once at the very beginning of a trial. When the observation log declares that the takeoff goal has been achieved the most recent additions to the sensor inputs are the heading-achieved, altitude-achieved and speed-achieved features. The resulting termination rule tests the exact three conditions which caused the expert to declare the takeoff goal achieved.

Another interesting example of Observo-Soar's learning process is demonstrated by the precondition of the fly-inbound-leg operator (see figure 4). The expert stops fly-to-position and begins the fly-outbound-leg goal when the range to the position is less than 3000 meters. This value of 3000 meters is present in the sensor inputs as the (position-achieved-range 3000) feature. Observo-Soar isn't currently powerful enough to realize the relationship between the goal shift when (range-to-position 2987) appears and the (position-achieved-range 3000) feature. Hopefully, future versions of the system will be able to discover this relationship given sufficient observations and will build a state elaboration to represent when a position has been achieved. The present version of Observo-Soar does continue to generalize the preconditions of fly-inbound-leg by adding a new disjunctive condition for each new observation. Thus the second time fly-inbound-leg is observed the preconditions of the operator are satisfied by two separate values (see figure 5).


Given the simplicity of the current learning
component of Observo-Soar it is surprisingly effect in generating
precondition and termination rules for the racetrack domain.
Of the 9 rules learned all but the takeoff proposal rule are reasonable
versions of the expert's knowledge. Furthermore, additional observations
continue to improve these rules. As work continues on Observo-Soar
more powerful error detection and learning components will undoubtedly
improve the effectiveness and applicability of the system.
4.0 CONCLUSION
The research presented here is still in the preliminary stages and obviously suggests many avenues of future research. The next step in the development of the Observo-Soar system is to extend the capabilities of the learning algorithm so that it can learn operator actions as well as preconditions and effects. This extension should be fairly straight forward and will result in a simple but complete learning system. One of the most exciting open questions is how to extend the learning algorithm to learn state elaborations. No previous research on learning by observation has addressed state elaborations. The central problem of learning state elaborations is discovering combinations of existing state objects which are frequently tested as a unit. One approach is to occasionally search the learned rules for objects which are often tested together. Complex state elaborations which test a relationship between state objects, such as the achieved-position elaboration discussed in the previous section, are sure to be even more difficult to learn.
Another area open to future research is the error detection component. A more sophisticated error detection system would allow for some variation in behavior if the variations were insignificant relative to the current task. The error detection component must also be able to deal with variable delays between sensor input and the expert's actions. The actions of human experts will be somewhat delayed from the sensor changes which prompted those actions. Different experts will have different delays resulting in a range of delays between the triggering sensor input and the action. The error detection component much take these delays into account to appropriately compare the expert's and task knowledge's behaviors. Similarly, the learning component must account for the delay so that actions can be matched with the appropriate sensor changes. This issue is made even more complicated when experts begin to anticipate sensor changes and perform actions before the triggering sensor inputs have even occurred.
The preliminary results show the potential
of the Observo-Soar system and the learning by observation technique
as a powerful form of knowledge acquisition. As research continues
on the Observo-Soar system the scope of knowledge which it can
learn will increase. While behavioral cloning and the OBSERVER
system were both successful, Observo-Soar demonstrates an even
more effective approach based on the combination of the two systems.
ACKNOWLEDGEMENTS
This research was supported under contract N61339-97-K-008 from the Defense Advanced Research Projects Agency (ARPA).
BIBLIOGRAPHY
Bain, M. and Sammut, C (1995). A framework
for behavioral cloning. in S. Muggleton, K. Furakawa, and D.
Michie (Eds.), Machine Intelligence 15. Oxford University
Press.
Fikes, R.E. and Nilsson, N.J. (1971). STRIPS:
a new approach to the application of theorem proving to problem
solving. Artificial Intelligence 2(3,4):189-208.
Laird, J. E., Newell, A. and Rosenbloom,
P.S. (1987). Soar: An architecture for general intelligence. Artificial
Intelligence 33:1-64.
Mitchell, T. (1978). Version Space: An
Approach to Concept Learning. PhD thesis, Stanford University.
Quinlan, J. R. (1987). Simplifying decision
trees. International Journal of Man-Machine Studies, 27,
221-234.
Sammut, C., Hurst, S., Kedzier, D. and Michie,
D. (1992). Learning to Fly. in D. Sleeman (Ed.) Proceedings
of the Ninth International Conference on Machine Learning,
Aberdeen: Morgan Kaufmann, 385-393.
Tambe, M., Johnson, W. L., Jones R. M.,
Koss, F., Laird, J. E., Rosenbloom, P. S. and Schwamb, K. (1995).
Intelligent agents for interactive simulation environments. AI
Magazine 16(1):15-39.
Wang X. (1995). Learning by Observation and Practice: An Incremental Approach for Planning Operator Acquisition. in Proceedings of the 12th International Conference on Machine Learning.