 User
Interface and Its Functionality
User
Interface and Its Functionality
This paper introduces CHRONO and Meta-CHRONO tools for managing chronological awareness at websites. The paper acts as a tutorial about how to set up CHRONO for a website. CHRONO is an HTTPD server-side system which generates chronological listings of web pages that have been changed recently at specific sites. It provides a basic awareness-support that lets visitors of a web site (e.g., members of a group, or other Net surfers) see which web pages have been modified since their last visit. Currently, the CHRONO system is implemented on a UNIX platform. CHRONO presents visitors with an HTML document that lists the titles of web pages at the site in reverse chronological order. This chronological listing also functions as a collection of hyper links to the listed web pages (Chen & Gaines, 1996). Meta-CHRONO is another awareness tool which collects CHRONO listings from related websites, then generates a collective chronological awareness listing reflecting the changes at those websites.
User
Interface and Its Functionality
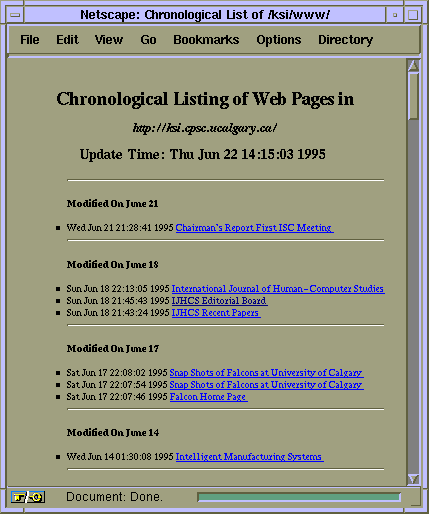
The user interface of the CHRONO system is straightforward and
intuitive for web users. It looks like an automated what's
new page to the users. From the list, the visitors are able
to tell at a glance what documents have been modified or created
recently. They can also scroll down the list to check those older
documents at the site. Because the titles of the listed pages
also act as hyper links to the actual web pages, visitors can
simply click and jump to the relevant pages of interests (Chen
& Gaines, 1996b).
Chronological hyper links presented in the CHRONO listings provide the visitors the means to access the newly modified or created pages. This time-line (or history) dimensionality complements the functionality of the associative memory characteristic found in typical hyper links which join related information.
The time-line dimension allows frequent visitors of a web site an immediate awareness on what have been changed since their latest visit. The changes may reflect some web pages in which they have been previously interested or they may show some pages that the visitors have never seen before but now appeal to them. Hence this chronological browsing characteristic is analog to spatial (subject-category) browsing characteristic that library patrons have often experienced when looking for books on open book-shelves (i.e., accidentally finding other relevant books near the books that they were looking for originally). Unlike a manually updated What's New page in which the users have to rely on timely updates made by a web master (or by the document authors), CHRONO provides the time-line dimension to the users automatically, in a reliable and periodic fashion.
The CHRONO system has been running at the Department of Computer
Science at the University of Calgary since March, 1995. It currently
services seven web locations: two research units and five individuals.
People associated with the two research units: Knowledge Science
Institute and GroupLab periodically have utilized the system to
check on new developments of each other (both within group and
between groups).
From a preliminary examination of the HTTPD access_log of the CHRONO system site and from talking with individual group members, we have found that the chronological listings of the five personal sites have offered other group members more focused chronological awareness about these five individuals' working patterns. Occasionally, some people had discovered new projects the targeted individuals were working on that they were not previously aware. This positive usage experience of personal chronological listings suggests to us that there is a need to further examine the effectiveness of providing different sub-groupings of chronological listings to group members.
Meta-CHRONO is recent addition to support special interest
community awareness for distributed research teams and groups
(Gaines, Shaw & Chen, 1996).. This meta-level awareness tool
collects CHRONO listings from related websites, then it generates
a collective chronological awareness listing reflecting the changes
at those websites. This allows visitors to become aware recent
modifications of changes at all registered websites via a centralized
Meta-CHRONO index-listing. This meta-level awareness support of
CHRONO listings is a natural extension from Miller's living systems
theory (Miller, 1978) and the CyberOrganism framework (Chen &
Gaines, 1997).
There are three other systems that provide support for chronological awareness based on different designs and implementations (Chen & Gaines, 1996):
This section describes how to install and run CHRONO Version 1 on the UNIX platform. First step describes how to compile CHRONO; second step illustrates how to run CHRONO; and third step shows how to setup crontab to run CHRONO automatically in periodic fashion.
Download the CHRONO source code for compiling or skip this step by obtaining a pre-compiled SUN OS compressed binary executable and SGI IRIX binrary executable (compressed) for a specific platform.
The source code "chrono.c" can be readily compile on the UNIX platform (SunOS Release 4.1.4 and SGI IRIX 5.3) without modification. It should be relatively easy to compile on the other UNIX versions.
The executable can be compiled under the GNU GCC like the following:
[dk chrono 1 ]> gcc -o chrono chrono.c
The executable can also be compiled under the normal cc like the following:
[dk chrono 1 ]> cc -o chrono chrono.c
If nothing goes wrong, an executable named chrono should be created.
To initiate CHRONO on a specific www directory designate for indexing. The following sub-steps test run and demonstrate basic ideas of how CHRONO works.
The CHRONO program takes (at least ) 3 parameters for arguments (the 4th one is an optional parameter to be discuss later in the advance usage section).
chrono <dir> <outputfile-name> <http path>
[index patterns file]
| |
|
|
| an http path name this is the entry point to the directory specified in the <dir> |
|
the name of file containing string patterns for index matching. If not specified, CHRONO will match files with ".htm" and ".HTM" patterns. |
For example: the following statement is used to create an index webpage named KSI-chrono.html of a web directory named /ksi/www/ where the URL: http://ksi.cpsc.ucalgary.ca/ refers to:
[www 2] > chrono /ksi/www/ KSI-chrono.html http://ksi.cpsc.ucalgary.ca/
CHRONO will recursively traverse the directory /ksi/www/ can create a reverse chronological index webpage called KSI-chrono.html in the current directory
The above step describes how CHRONO can be executed to create a CHRONO webpage. The following sub-steps illustrate how crontab (see detail explanation of crontab by doing a manual page on UNIX: i.e., man crontab) can setup an automatic periodic schedule for running CHRONO and creating CHRONO webpage(s).
crontab is used to register any command line statement for automatic periodic execution by the UNIX system.
The following crontab format is used to execute a specific command line every hour, at half of an hour:
30 * * * * <command line>
Therefore if one wants to execute a CHRONO program like the one in stage 2, one just substitutes the command statement in the <command line> field.
IMPORTANT NOTICE: the command line has to take the whole path names for the CHRONO program and corresponding files; therefore, if the CHRONO program is resided in /ksi/chrono/ one has to specific the whole path name, e.g.,
15 * * * * /ksi/chrono/chrono /ksi/www/ /ksi/www/KSI-chrono.html http://ksi.cpsc.ucalgary.ca/
The above crontab statement will create a CHRONO webpage (named
KSI-chrono.html) of http://ksi.cpsc.ucalgary.ca/ (under
directory /ksi/www/)and put the webpage inside the /ksi/www/ directory.
The specific CHRONO webpage will be updated every hour at quarter
after. (note: remember to chmod the KSI-Chrono.html
to be readable by others after it is created first time).
To register for SGI IRIX:
[dk chrono 7 ]> crontab _sgi.chrono
where _sgi.chrono is an text file with crontab statement(s).
To edit a crontab schedule file (FOR SUN OS), type:
[dk chrono 7 ]> crontab -e
that will bring up the editing mode, once in the mode, one can start to enter the crontab statement. Usually the default editor for crontab is vi, one can use one's favorite editor (e.g., emacs) to create a crontab file (e.g., _spuds) in advance then loaded it in while one is in crontab -e mode in vi (key sequence: 'ESC' ':' 'r _spuds' 'CTRL-x') . Or you can set the UNIX environment variable VISUAL or EDITOR to a favorite editor.
For example, here is an example crontab file
named _spuds
There are two other useful crontab switches:
| crontab -l | List the user's crontab file |
| crontab -r | Remove the current user's crontab file from the crontab directory. |
Usually, one uses crontab -l to examine the current schedule
of cron daemon; if one wants to modified or create a new
CHRONO index, one can edit a crontab file (e.g., _spuds)
before one uses crontab -e. Once one is satisfied with
the crontab file, one can simply use crontab -r to remove
(clear) the existing cron schedule and use crontab -e to
load the newly modified crontab file. By keeping a crontab file
and editing it, the organization of the CHRONO webpages will be
relatively simple.
Once the CHRONO program has been compiled successfully, CHRONO
can be use to index a www directory in reverse chronological fashion
to produce a CHRONO webpage. CHRONO takes 3 parameters: (1) the
path of the www directory to be indexed; (2) the resulting CHRONO
webpage file name; and (3) the http URL of the indexed www directory.
Using crontab, an automatic, periodic command-schedule
can be setup to generate automatic CHRONO webpages. The important
point is that the CHRONO command and its parameters need to be
specified by their whole path-names.
Finally, to make the generated CHRONO webpages readable by others,
by using the chmod a+r <file name(s)> command.
After one gets CHRONO running, one can start to experimenting
with advance usage features: e.g., matching patterns, CHRONO.CONTROL
files, etc.
This section describes how CHRONO indexing patterns can be changed. For example, a website maintainer may wish certain sub-directories or files not to be indexed by CHRONO. He or she may also want to index additional file formats than HTML (e.g., GIF, JPEG).
By default CHRONO will recursively index every HTML files under the directory specific by the <dir> parameter.
chrono <dir> <outputfile-name> <http path> [index patterns file]
There is an optional index pattern file [index patterns file] for CHRONO that allows web master to overwrite the default index patterns for deciding what to be indexed. The absence of this file will result in default patterns which match any file with .htm and .HTM (default) string patterns. For examples, files such as test.html, MORE.HTM, and OK.HTM.also.match will be indexed by CHRONO.
One can specific a global control file, for example, CHRONO.PATTERN:
#INCL#
.htm
.HTM
.gif
#EXCL#
photo
.HTM.
The keywords #INCL# and #EXCL# signal to CHRONO the followings line(s) will be inclusion (file) pattern(s) and exclusion (file and directory) pattern(s).
If a file or directory name satisfies one of the inclusion patterns it is indexed unless it also satisfies one of the exclusion patterns.
Therefore the above example add one more inclusion file pattern .gif so now any GIF files with the .gif as extension will be matched. And CHRONO will avoid indexing any files or directories containing string patterns like photo or .HTM. (recursively) under www directory <dir>. Notice with such exclusion patterns, file OK.HTM.also.match will no longer be indexed.
If the specified index pattern file exist but is null (with size of 0 byte), CHRONO will result in another default which matches all files without regards to any patterns, therefore everything will be matched and be indexed.
One can place a control file, named "CHRONO.LOCAL", in any webpage directory (and its sub-directories). Unlike the optional index pattern file described earlier (which the effect is global), the CHRONO.LOCAL file specific exclusion index patterns that are only local to the current directory which the file is placed.
This control file will be used by CHRONO whenever it tries to index that webpage directory; so that, any sub-directory or file names that have watched the string patterns specified in the control file will not be indexed. For examples, if we have a webpage directory containing the following subdirectories and files:
Agenda0.html
CHRONO.LOCAL
private_subdir/
public_subdir/
agenda1.html
agenda2.html
agenda3.html
another_world.html
ok-file.html
www_agenda/
www3/
Considered if we have two string patterns, "public_subdir" and "agenda" which we want to use for filtering out subdir or file name patterns. We will write a CHRONO.LOCAL file containing both string patterns, (note that each string pattern is listed in a seperate line; and there is no extra space in front or behind each of pattern string). For example, if CHRONO.LOCAL contains the following two lines (with two patterns for matching).
public_subdir agenda
With the control file, CHRONO.LOCAL, in place, CHRONO will omit the following files and subdirectories for indexing:
public_subdir/
agenda1.html
agenda2.html
agenda3.html
www_agenda/
And the following files and subdirectories will be indexed by CHRONO (note the string pattern is case sensitive, hence "Agenda0.html" won't be matched by string pattern "agenda"):
Agenda0.html
public_subdir/
another_world.html
ok-file.html
www3/
Please note that the effects of the omission control file is only local to the directory. So if there are some files called "agenda-4.html" and "agenda-5.html" under the "public_subdir" sub directory, and one wants to omit them for indexing, one needs to place the string pattern "agenda" in another CHRONO.LOCAL file in the "public_subdir" sub directory.
One can tell the CHRONO not to index a specific directory (consequently all its subdirectories) by place a null (0 byte size) control file, names "CHRONO.LOCAL" in the directory.
Agenda0.html
CHRONO.LOCAL
private_subdir/
public_subdir/
agenda1.html
agenda2.html
agenda3.html
another_world.html
ok-file.html
www_agenda/
For example, if one places the control file CHRONO.LOCAL with size of 0 byte in the above example directory, nothing in and under the directory will be indexed. The effect of this null control file, "CHRONO.LOCAL", basically stops CHRONO from traversing down in any of its subdirectories; therefore, nothing under private_subdir and private_subdir will be indexed either.
To join the CHRONO Mailing List (fairly low traffic) for discussion about questions, problems, announcements, suggestions, future ports to different platforms, send a message with the body "subscribe" to chrono-request@cpsc.ucalgary.ca
Chen, L. L.-J. and Gaines, B. R. (1996). Knowledge Acquisition
Processes in Internet Communities. Proceedings of KAW96, Banff,
AB, pp. 43-1~43-18. http://ksi.cpsc.ucalgary.ca/KAW/KAW96/chen/ka-chen-gaines.html
Chen, L. L.-J. and Gaines, B. R. (1996b). Methodological Issues
in Studying and Supporting Awareness on the World Wide Web. Proceedings
of WebNet96. Association for the Advancement of Computing
in Education, Charlottesville, VA. http://ksi.cpsc.ucalgary.ca/articles/WN96/WN96Chrono/WN96Chrono.html
Chen, L. L.-J. and Gaines, B. R. (1997). A CyberOrganism Model
for Awareness in Collaborative Communities on the Internet. International
Journal of Intelligent Systems, (in press). http://www.cpsc.ucalgary.ca/~lchen/current/ijis/
Gaines, B. R., Shaw, L. G., and Chen, L. L.-J. (1996). Utility,
Usability, and Likeability: dimensions of the net and web. Proceedings
of WebNet96. Association for the Advancement of Computing
in Education. http://ksi.cpsc.ucalgary.ca/articles/WN96/WN96HF/WN96HF.html
Miller, J. G. (1978) Living Systems. McGraw Hill, New York,
NY
NetMind (1995). The URL-Minder: Your
Own Personal Web Robot. NetMind. http://www.netmind.com/URL-minder/URL-minder.html
Newberry, M. (1995). Katipo--a Web
Lurker. Victoria University of Wellington, New Zealand. http://www.vuw.ac.nz/~newbery/Katipo.html
Specter (1995). WebWatch. Specter Communications. http://www.specter.com/
[ Knowledge Acquisition Workshop '96, Banff, Alberta, Canada, Nov. 9 - 14, 1996 ]