
Figure 1. Problem space view of the design process
| Abstract. The aim of this paper is to understand what is involved in parametric design problem solving. In order to achieve this goal, in this paper i) we identify and detail the conceptual elements defining a parametric design task specification; ii) we illustrate how these elements are interpreted and operationalised during the design process; and iii) we formulate a generic model of parametric design problem solving. We then re-describe a number of problem solving methods in terms of the proposed generic model and we show that such a re-description enables us to provide a more precise account of the different competence behaviours expressed by the methods in question. |
The aim of this paper is to understand what is involved in parametric design problem solving. In order to achieve this goal, in this paper i) we identify and detail the conceptual elements defining a parametric design task specification; ii) we illustrate how these elements are interpreted and operationalised during the design process; and iii) we produce a generic model of parametric design problem solving, characterised at the knowledge level, which generalizes from existing methods for parametric design. We then re-describe a number of problem solving methods in terms of the proposed generic model and we show that such a re-description enables us to provide a more precise account of the different competence behaviours expressed by the methods in question.
Many authors - e.g. (Wielinga et al., 1995) - distinguish between an analysis and a synthesis phase in the design process. The analysis phase consists of transforming a set of "needs and desires" into a formal set of requirements and constraints, while the synthesis phase is concerned with the construction of a solution design which satisfies the given formal specification. In this paper we will focus almost exclusively on the synthesis phase, although our discussion (i.e. analysis!) of the parametric design task specification is obviously also relevant to the analysis phase, as it precisely defines its output.
The paper is organised as follows: in the next section we formally describe the structure of parametric design applications; in section 3 we present a problem space view (Newell, 1980) of parametric design problem solving, and we re-interpret task knowledge for parametric design in terms of the problem space framework. In section 4 we describe a number of problem solving methods for parametric design. In section 5 we illustrate a generic model of parametric design problem solving. In section 6 we apply the generic model to the methods presented in section 4 and we use the resulting re-descriptions to compare and contrast their behaviour. Finally, in section 7 and 8 we compare our work to other relevant contributions and we re-state the main contributions of this paper.
These concepts are described in the next sections.
 P, and vij Vi. The following definitions
characterise different types of design models:
P, and vij Vi. The following definitions
characterise different types of design models:
Figure 1. Problem space view of the design process
2.1.3. Legal values. For each parameter, say pi, we assume that a value range, Vi, is given, which specifies the set of legal values which can be assigned to pi. In principle, this value range can be either finite or infinite. For instance, the value of parameter motor-model in the VT domain can be one of six possible types of motor models, while the value of parameter hoist-cable-traction-ratio is constrained to a real number in a certain interval and therefore is potentially infinite. However, a value range of infinite cardinality does not imply that a parameter can really be assigned anyone of an infinite number of values. For instance the value of hoist-cable-traction-ratio in the VT domain is functionally determined by the values of other parameters, whose value range is finite. Therefore its value range is in practice finite too. Our experience with a number of parametric design applications suggests that it is very unlikely that the value of a parameter can be really drawn from an infinite range. Typically, when the range of a parameter is potentially infinite and it is not the case that its value is functionally determined by the values of other parameters, additional heuristic knowledge is brought in, either as part of the task specification itself, or as part of domain-specific, heuristic problem solving knowledge, to limit the number of available options - see discussion in section 3.1.2.
In order to account for the cost-related aspects of parametric design problems our framework includes two additional concepts: preferences and cost function, which are discussed in the next two sections.
2.2.1. Preferences. Preferences describe task knowledge which, given two design models, D1 and D2, allows us to make a judgement about which of the two - if any - is the 'better' one, in accordance with some criterion. For instance, the Sisyphus-I room allocation problem (Linster, 1994) includes informal statements such as "Secretaries should be as close as possible to the head of group" and "Project synergy should be maximised". Given that these statements specify desired solution features, we could consider modelling them as requirements. If we take this approach, then we define a solution allocation model as one which (among other things) maximises project synergy and in which the distance between secretaries and head of group is minimized. Although this approach is possible, it is not entirely satisfactory. A statement such as "secretaries should be as close as possible to the head of group" appears to indicate a criterion which might or might not be entirely satisfied - depending on the distance between secretaries and head of group - not one which is either satisfied or violated. In other words, our feeling is that to interpret these statements as requirements would unduly restrict the space of solutions. A better approach is therefore to consider the above statements as expressing preference knowledge and defining two criteria by which solutions to the Sisyphus-I problem can be assessed. In particular, if take this approach, the first statement could be interpreted as stating that, given two admissible design models for the Sisyphus-I problem, say D1 and D2, D1 is 'better' than D2 if the distance between the secretaries' room and the head of the group's in D1 is less than in D2. Of course, given an informal design specification, there are in general alternative admissible formal task specifications which can be produced during the analysis stage of the design process. Deciding on the 'best interpretation' in a real scenario is very much the result of an iterative analysis and negotiating process between designers and clients and it is outside the scope of the present discussion. The important aspect here is that the triadic partition of the problem specification into preferences, constraints, and (proper) requirements provides us with an adequate conceptual framework to analyse and represent the desired features and constraints on the solution design.
From a formal point of view a preference can be represented as a binary
relation predicated over design models. Thus, we will use the notation
prefer (D1, D2) to indicate that design model
D1 is to be preferred over design model D2. For
instance, we can represent our preference for allocation models which minimize
the distance between secretaries and the head of group in the Sisyphus-I
example by means of the following rule, expressed in the OCML language (Motta, 1995).

2.2.2. Global cost function. As shown by the aforementioned
statements concerning the Sisyphus-I problem, a task specification typically
includes a number of preferences which express different criteria for
distinguishing good solutions from 'less good' solutions. In order to
harmonise the possible multiple preference criteria uncovered during the
analysis phase, it is useful to introduce the notion of global cost
function, to provide a global cost criterion for ordering solution
designs. Such a criterion should be constructed by combining
preference-specific cost criteria. In order to do this, it is necessary to
specify preference-specific cost functions first, expressing the cost criteria
defined by each preference. Having done this, it is then possible to define
the global cost function for a parametric design application as the combination
of the preference-specific cost criteria. More precisely, given a task
specification <P, Vr, C, R, Pr, cf>, where Pr = {pr1,.......,
prj}, we define the global cost function cf = cf(pr1)
o......o cf(prj), where cf(pri) is the cost function
associated with preference pri.
For example, Balkany et al (1994) characterise the preferences which apply to
the Sisyphus-I domain as statements with the form "x should be close to y". In
accordance with this approach they define a cost function which values a
solution in terms of the distance between the relevant <x,y> pairs. In
order to extend this criterion with one which also takes into account the
preference about maximizing project synergy, we need to define a
preference-specific cost function for this second criterion and then integrate
it with the one defined by Balkany et al. A possible cost function measuring
the degree of project synergy denoted by a model could be defined as one which
scores positively (say +1) each shared allocation which involves researchers
belonging to different projects and which scores negatively (say -1) each
shared allocation which violates this criterion. The two preference-specific
cost functions could be combined in different ways, for instance by trying to
come up with commensurable criteria or by giving priority to one of the two and
assessing each allocation by means of a two-dimensional vector
<cf1, cf2>, where cf1 is the cost
function associated with the 'closeness' preference, and cf2 is the
cost function associated with the 'synergy' preference. The OCML lambda
expression shown below defines a possible formalization of a cost function for
the 'synergy' criterion.

As shown by the above definition, a cost function, whether global or
preference-specific, can be characterised as a function which takes as input a
design model and whose output is a n-dimensional vector. We assume that a
lower score denotes a better solution. Thus, we say that a design model Dsol-k is an optimal solution to a parametric design
problem if it is a solution, and there is no other solution, say
Dsol-j, such that cf(Dsol-j) <
cf(Dsol-k).
Other examples of cost functions can be found in an earlier paper of ours, (Zdrahal and Motta, 1995), in which we discuss a number of cost functions for the VT application, which attempt to model the revision-oriented cost model used by the domain experts. As already mentioned, the domain experts in the VT problem assess the quality of a design by means of an informal metric which attempts to characterise the 'distance' between the design produced and an ideal, low cost design. This metric was 'compiled' in the Propose & Revise design method used in the original VT application ( Marcus et al., 1988). Thus, the cost of an elevator configuration was computed in terms of the individual costs associated with each revision step required to fix the constraints violated during the design process. In our 1995 paper we formalised the informal criterion given in the VT problem specification by means of a number of different metrics, which used both archimedian and non-archimedian criteria for combining individual revision costs.
In the statement of the first goal above, we use the expression 'essential knowledge-intensive activies' to indicate that i) we are interested in design as a knowledge-based process and that ii) we want to devise a 'parsimonious' conceptual framework for characterizing it. The first point spells out our view of (parametric) design as a complex decision-making process where task and domain specific knowledge is brought in to reduce the complexity of a problem. In accordance with such a position, in this paper we identify the decision-making activities (i.e. subtasks) required for parametric design in general, and we characterise them at the knowledge-level (Newell, 1982; Van De Velde, 1994), i.e. in terms of their knowledge requirements and abstract inference structures. Having identified the relevant subtasks, we will then use them to compare and contrast different problem solving methods.
Finally, we say that our framework should be 'parsimonious' to emphasize the fact that we want our framework to be both complete, i.e. useful for examining any specific problem solving method, and minimal, i.e. not introducing unnecessary distinctions.
3.1.1. Key design parameters. Assuming an average of k possible values for a parameter, and n parameters, it follows that the size of the design space associated with a parametric design application is kn. This of course is a very large number even for relatively small applications. However, it turns out that many parameters do not contribute to the size of the search space, given that there is no degree of freedom associated with their assignment. This is the case when the possible value of a parameter is functionally determined by a constraint or requirement. For example, the value of the parameter door-operator-weight in the VT domain (Yost and Rothenfluh, 1996) is calculated as the sum of the door operator engine weight and the door operator header weight. This means that from a design point of view the value of this parameter is functionally determined by a domain constraint, and therefore a design problem solver does not need (or indeed cannot) make any decision about it. In the rest of the paper we will use the expression functionally bound to denote parameters whose value is uniquely determined by a functional constraint or requirement. The parameters which are not functionally bound are called key design parameters. Key design parameters and their possible values define the degrees of freedom in the design process and, consequently, the 'real' size of the design space. In other words, the essential decision-making activity during the design process is to decide upon the values to be assigned to key design parameters; the values of the other parameters can then be determined by propagating the relevant functional constraints.
In the rest of the paper we will use the attribute constructive to refer to those requirements and constraints which functionally determine parameters. Non-constructive constraints and requirements will be referred to as restrictive. The role of restrictive requirements and constraints in the design process is to eliminate certain combinations of parameter values.
It is important to point out that deciding which are the key design parameters is not just a matter of analysing the syntactical format of constraints and requirements. On the contrary, such a decision is part of the analysis process during which task knowledge is interpreted in terms of the operational framework provided by a problem solving method. In other words, domain knowledge is needed to distinguish key parameters from the others. For instance, the expression "door operator weight = door operator engine weight + door operator header weight" can be formulated in three different ways, each of which defines different key parameters. It is domain knowledge[1] which tells us that the dependent parameter in the expression is door operator weight and not one of the other two.
The concept of key design parameter is very useful both because it allows us to focus the design process only on the 'important' design parameters and also because it reduces the size of the search space. For example, only 24 of the 199 parameters given in the VT problem specification are key design parameters, which means a reduction in the complexity of the search space from k199 to k24, if we assume again that on average each parameter can have no more than k possible values. Moreover, given a parametric design task specification, it is possible to define an isomorphic problem, which is specified only in terms of key design parameters. Hence, we can take advantage of this property and we can define parametric design as the process of assigning values to key design parameters. A consequence of this approach is that, with no loss of generality, we can limit the discussion to design models comprising only key design parameters.
3.1.2. Heuristic value range narrowing. In section 2.1.3 we indicated that while typically the task specification for a parametric design problem specifies (either directly or indirectly) a finite value range for each parameter, it is possible that some parameters have an infinite number (or at least a very large set) of possible values. In this case, additional domain knowledge can be brought in, either as part of the task specification itself, or as part of domain-specific heuristic problem solving knowledge, to narrow down the number of possible values. An example of this kind of 'heuristic value range narrowing' can be found in the VT domain and is used to restrict the potentially very large space of values for parameter counterweight-to-hoistway-rear down to two choices.
As shown in figure 2, the parameter counterweight-to-hoistway-rear specifies the distance between the counterweight and the rear of the hoistway. From a theoretical point of view the counterweight can be positioned anywhere in the space defined by the distance between the platform and the rear of the hoistway (this space is called "counterweight space"). However, the description of the VT application (Yost and Rothenfluh, 1996) indicates that only two options are ever considered by the VT domain experts, when deciding on the position of the counterweight. The preferred solution locates the counterweight half way between the platform and the U-bracket. If this solution does not work (because the counterweight is too close to the U-bracket), then the alternatives are: i) to reduce the depth of the counterweight; ii) to move the counterweight closer to the platform; and iii) to increase the counterweight space (presumably by decreasing the depth of the platform). In practice all this means that a VT domain expert only considers two positions for the counterweight: either half way between the platform and the U-bracket, or, in case the previous approach fails, a position ensuring that its distance from the U-bracket is more than 0.75 inches. Because we have no access to the original VT domain experts, it is not possible for us to ascertain whether this refinement of the value range is really part of the task specification (i.e. whether or not these two positions are the only ones which make sense for the counterweight) or whether it is just a way of reducing the complexity of the design process. Whichever the case,[2] this example provides a good illustration of the way heuristic design knowledge can be used to narrow down the number of design choices available for a parameter.
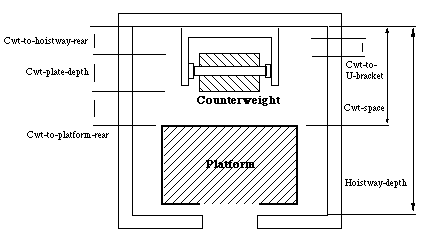
Figure 2. The elevator example
When two design states, say Si and Sj, are linked by a design operator pointing to Sj, we say that Si is the predecessor of Sj and that of the successor state and that of the predecessor state. In the rest of the paper we will use the notation cf (Si -> Sj) to denote the cost of an operator connecting Si to Sj.
The approach we take here to identify the generic subtasks of parametric design problem solving is basically top-down. Given the design space representation we have adopted, there are essentially only four actions which can be carried out: selecting a design state, selecting a design operator, applying a design operator to the selected state, and evaluating the resulting design model. The latter is needed to assess its properties, e.g. whether it provides a solution, its cost, etc. Although these four subtasks are adequate to describe the process of searching the design space, such a framework is not rich enough to model design methods which exhibit some flexibility in their behaviour. For example, an intelligent parametric design problem solver could employ a number of different state selection strategies and use them in different moments of the design process (Zdrahal and Motta, 1996). Moreover, the selection of a design operator goes normally through a number of 'important' decision-making activities, which include the selection of a design context (e.g. extend-design vs revise-design) and the selection of a design focus. This can be seen as an abstraction mechanism which extracts from the current design state the relevant information which is used to restrict the field of possible operators. An example of a design focus is the constraint violation which a Propose & Revise problem solver attempts to resolve during a particular fix appplication.
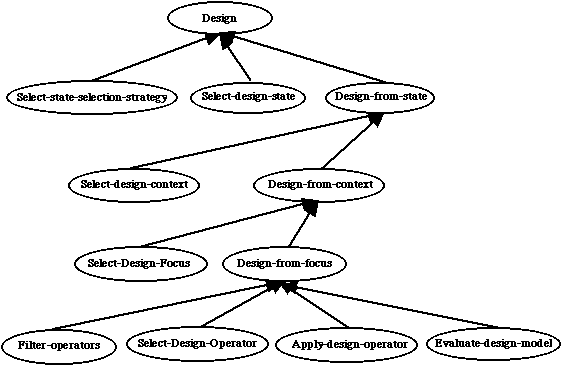
Figure 3. Main task-subtask hierarchy in parametric design problem
solving.
In figure 4 we show a KADS-style inference structure (Wielinga et al., 1992), showing the input/output behaviour of the subtasks in the first four layers of the task-subtask decomposition given in figure 3. Italicized labels indicate repeated occurrences of a knowledge role.
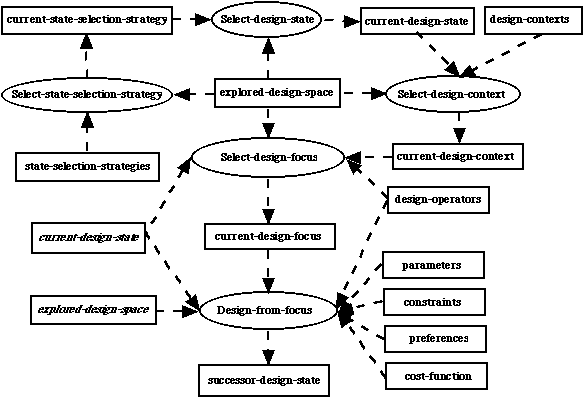
Figure 4. Inference structure in parametric design problem solving.
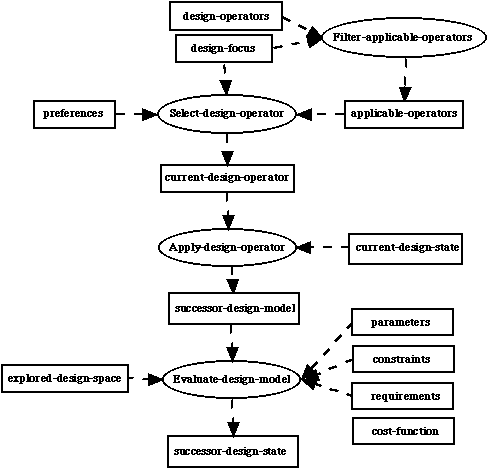
Figure 5. Inference structure of task Design-from-focus
From a decision-making point of view, there are seven interesting tasks in our model: the six selection/filtering tasks and task Evaluate-design-model. These tasks provide a set of dimensions along which problem solving methods can be differentiated and compared. These subtasks and the associated roles are discussed in the next three sections.

Figure 6. Task-subtask decomposition for task Evaluate-design-state
Assuming that a rational problem solver would not normally select a design state known to be unfeasible, it follows that state selection is carried out in terms of the other three main criteria discussed in the previous section: contents of the design model, constraint violations, and cost. For example, both EMR and CMR use a strategy of selecting the state which maximizes the number of assigned parameters, minimizes the number of constraint violations, and minimizes the cost. These criteria are applied in order, i.e. the second criterion is used when the first one has not enough discrimination power, and the third one is used only when the application of the first and second criteria fail to produce a single candidate. CMR-A* uses instead a different strategy and selects the cheapest state among those that maximize the number of assigned parameters. As we'll see more in detail in section 6, this difference in the way states are selected accounts for the different competence patterns expressed by EMR and CMR-A*. In other words a sound state selection strategy is crucial for the competence of a problem solver. In practice, given the complexity of design applications, selecting the right state is also important for performance reasons, as efficient pruning of the search space is needed for all but the most trivial applications. Of course, the crucial aspect here is to be able to remove only the 'bad' states. Otherwise we could eliminate states leading to a solution, thus affecting the competence of the design method.
As we discuss extensively in other papers (Motta et al, 1996; Zdrahal and Motta, 1996), selecting the 'right' design focus, i.e. the right parameter or constraint violation, is important to solve the VT problem using a Propose & Revise approach. From a competence point of view this is a side-effect of the restricted search model used by EMR and CMR problem solvers - see section 6.1. However, even with more flexible search mechanisms, selecting the right focus is very important to minimize unnecessary backtracking. This problem has been extensively analysed in the constraint satisfaction literature and various heuristics have been devised to improve the efficiency of variable (in our case, focus) selection (Dechter and Meiri, 1994).
Because parametric design is about finding optimal or sub-optimal solutions, the relevant preference knowledge is used to drive the selection of a design operator. This is often called local preference knowledge (Poeck and Puppe, 1992) and it is defined as preference knowledge which can be used to make locally optimal decisons, i.e. to perform best-first search. For instance, a problem solver tackling the Sisyphus-I problem would normally use the preference criterion discussed in section 2.2.1 when trying to allocate secretaries.
The input to task Select-design-state in figure 4 comprises two knowledge roles: current-state-selection-strategy and explored-design-space, which we can use to structure our analysis.
6.1.1. Comparison by role explored-design-space. The explored search space considered by all the methods except CBR consists of all design states generated within the current design process. It means that these problem solvers can only exploit design states produced when solving the current problem. In contrast with the other methods, the design space considered by CBR includes both the design states generated within the current design process as well as solutions to similar design problems generated in the past.
6.1.2. Comparison by state selection strategy. We will specify the state selection strategies used by different methods in terms of selection rules.
EMR, CMR. Let S1 be the set of states denoted by role explored-design-space with the maximum number of assigned parameters in the associated design model. Let S2 be the set of states in S1 with the minimum number of constraint violations. Select the state from S2 with the minimum cost.
CMR-A*. Let S1 be the set of states denoted by role explored-design-space with the maximum number of assigned parameters in the associated design model. Select the state from S1 with the minimum cost.
CMR-HC. Let S1 be the set of states denoted by role explored-design-space with the maximum number of assigned parameters in the associated design model. Denote as S2 the set of states from S1 with the minimum number of constraint violations. Select the state from S2 with the maximum cost.
CBR. There is no single strategy for design state selection which is applicable to all CBR design methods. Each method is characterised by its own technique. Some possibilities are presented in (Zdrahal and Motta, 1996).
The criteria used by the different methods for selecting design states are
summarised in table 1.
Design Model
|
Violated
Constraints
|
Cost
| |
| CMR,
EMR
|
max
|
min
|
min
|
| CMR-HC
|
max
|
min
|
max
|
| CMR-A*
|
max
|
not
applied
|
min
|
| CBR
|
method
dependent
|
method
dependent
|
method
dependent
|
Select-design-context. If CVi is empty and Di is incomplete, the context is extend-design. If CVi is not empty, then the context is revise-design.
Select-design-focus. If the context is extend-design, then the design focus is one of the unassigned key design parameters, say pi. If the context is revise-design, then the focus is one of the violated constraint violations, say cvij.
Filter-applicable-operators. If the current context is extend-design, then the procedure which provides a value for parameter pi is selected. If the current context is revise-design, then the set of applicable design operators is given by the set of all fixes which 'affect' cvij.
Select-design-operator. If the current context is extend-design, this task is trivial. If the current context is revise-design, then the design operator - i.e. fix or fix combination - with lowest cost is selected (i.e. a best-first strategy is used).
CMR
Select-design-context. If Di is incomplete, then the context is extend-design. Otherwise, the context is revise-design.
Select-design-focus. The same as in the case of EMR.
Filter-applicable-operators. The same as in the case of EMR.
Select-design-operator. The same as in the case of EMR.
CMR-HC
Select-design-context. The same as in the case of CMR.
Select-design-focus. The same as in the case of EMR and CMR.
Filter-applicable-operators. The same as in the case of EMR and CMR.
Select-design-operator. If the current context is extend-design, this task is trivial. Otherwise all operators (i.e. fixes and fix combinations) with the lowest cost are tentatively applied. If one of the operators solves cvij, then this operator is selected. Otherwise the operator which results in the maximum decrease of the amount by which cvij is violated is selected. If no such operator exists, i.e. all operators with the lowest cost increase the amount by which cvij is violated, then the same procedure is applied to the operators with the next highest cost, and so on. If this procedure fails even for the operators with highest cost, then the task fails.
CMR-A*
Select-design-context. The same as in the case of CMR.
Select-design-focus. The same as in the case of EMR and CMR.
Filter-applicable-operators. The same as in the case of EMR and CMR.
Select-design-operator. The same as in the case of EMR and CMR.
CBR
The task specifications for these tasks differ depending on the particular revision strategy used, i.e. CMR, CMR-HC or CMR-A*, and are the same as those used by the relevant method.
6.2.2. Successor state generation in problem solving methods: summing up. The main result of the comparison carried out in this section is that there is no much difference in the way successor design models are generated by these methods. More specifically, there is no difference between the approach used by CMR-A* and the others. We can therefore conclude that the superior competence of CMR-A* is only a result of the state selection strategy it employs.
The DIDS system (Balkany et al., 1994; Runkel and Birmingham, 1994) provides domain-independent support for building design applications. The system is based on a generic model of configuration design problem solving, which defines the generic data structures and tasks, called mechanisms in the DIDS terminology, required for building design applications. Our work has a number of similarities with the DIDS approach. We also characterise design as search through a design space, and one of our goals was also the development of a generic problem solving model for design. A difference between our analysis and theirs concerns the application area, which is narrower in our case, as we concentrate on parametric, rather than configuration design problems. This wider focus allows the DIDS researchers to define a richer set of data structures, than it is possible within the parametric design framework used in this paper. On the other hand, the DIDS framework is very method-oriented in the sense that it only focuses on the generic method ontology required for building configuration design applications. On the contrary, in this paper we have also analysed, in a method-independent way, the structure of parametric design applications, and discussed the relationship between this structure and the generic problem solving model.
In a separate paper (Balkany et al., 1993) the DIDS researchers analyse a number of configuration design systems, and try to classify the various mechanisms used by these systems into a number of generic categories: select design extension, make design extension, detect constraint violation, select fix mechanisms, make fix mechanisms, and test if-done. For each of these generic tasks a number of mechanisms drawn from the various systems are identified - e.g. 41 "make design extension" mechanisms are listed in the paper. The granularity of the mechanisms uncovered by this analysis varies significantly. Some mechanisms are low-level actions such as "do-step", which performs "one step of a task", others are fairly high-level mechanisms such as "create-goal-for-constraint". The problem with such a bottom-up approach is that each system uses a different terminology, solves a different class of tasks - for instance arrangement vs parametric design - and employs control mechanisms at very different levels of abstraction. Therefore it is difficult to compare them. The approach we have taken here is diffferent. We have specified exactly the class of tasks we are dealing with - parametric design - and then we have formulated the generic structure of the problem solving required for this class of tasks. This means that specific parametric design problem solvers can then be described by analysing how they carry out the generic tasks introduced by our framework.
The paper by Gero (1990) provides a comprehensive analysis of the design process in general, not just parametric or configuration design, and identifies the general classes of knowledge which are needed for design. This analysis leads to the formulation of a representation framework which can be used to support design activities. In comparison to this paper our scope here is much narrower. However, by restricting our analysis to parametric design we can of course analyse the relevant concepts in much more detail than it is possible in papers with a wider scope. Moreover, we believe that in-depth studies of parametric design problems are also very important for the broader design area, for two main reasons. First, all design activities include parametric design sub-activities. Second, frameworks for more complex types of design can be devised as extensions of parametric design task and method ontologies.
The analysis by Chandrasekaran (1990) has also a broader scope than ours. In this paper he decomposes the design task in four subtasks: propose, verify, critique, and modify, and then discusses the different methods which can be used to tackle these subtasks. For instance verification can be carried out by means of simulation methods. For each method, Chandrasekaran briefly describes its knowledge requirements and computational properties. We share Chandrasekaran's philosophy and this paper is an attempt to instantiate some of his ideas - e.g. the use of task analysis to understand problem solving - in a precisely defined subset of the space of design applications.
If we take a broader perspective, it seems to us that the main result of this paper is that our generic model of parametric design problem solving clearly shows the need for flexible problem solving models in design. In particular, the analysis of the various instances of Propose & Revise architectures shows important trade-offs between competence and performance. There are no good methods and bad methods. EMR and CMR do perfectly well for most parts of the VT domain. However, the assumptions on which these methods are based do not hold for the machinery component of the VT model - see also (Zdrahal and Motta, 1996). From a problem solving point of view this means that research into problem solving methods should produce control architectures which can opportunistically switch to a different problem solving regime when the current one fails. From a knowledge acquisition point of view, the implication is that we need better techniques and tools to verify that the assumptions underlying a problem solving method actually hold for a particular domain. Recent papers by Fensel (1995) and Benjamins and Pierret-Golbrich (1996) on specifying and verifying assumptions of problem solving methods are initial steps in this direction.
Balkany A., Birmingham W.P. and Runkel J. (1994). Solving Sisyphus by Design. Int.Journal of Human-Computer Studies, 40, pp. 221-241
Benjamins, R. and Pierret-Golbreich, C. (1996). Assumptions of Problem Solving Methods. Proceedings of the 6th Workshop on Knowledge Engineering Methods and Languages. Gif-sur-Yvette, France, January 15-16.
Chandrasekaran, B. (1990). Design Problem Solving: A Task Analysis. AI Magazine, 11(4), pp. 59-71.
Dechter, R., and Meiri, I. (1994). Experimental Evaluation of Preprocessing Algorithms in Constraint Satisfaction Problems. Artificial Intelligence Journal, Vol. 68, pp. 211-241.
Fensel, D. (1995). Assumptions and Limitations of a Problem Solving Method: a Case Study. In Gaines and Musen (Eds.), Proceedings of the 9th Banff Knowledge Acquisition Workshop.
Gero, J. S. (1990). Design Prototypes: A Knowledge Representation Schema for Design. AI Magazine, 11(4), pp. 26-36.
Linster M (1994). Problem statement for Sisyphus: models of problem solving. International Journal of Human-Computer Studies, 40, pp. 187-192
Marcus, S, Stout, J., and McDermott, J. (1988). VT: An Expert Elevator Designer that uses Knowledge-Based Backtracking. AI Magazine, 9(1), pp. 95-112, Spring 1988.
Motta, E. (1995). KBS Modelling in OCML. Proceedings on the Workshop on Modelling Languages for Knowledge-Based Systems, Vrije Universiteit Amsterdam, January 30-31, 1995.
Motta E., Zdrahal Z. (1995). The Trouble with What: Issues in method-independent task specifications. In Proceedings of the 9th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop (B.R.Gaines and M.Musen eds.). pp. 30-1 - 30- 17.
Motta E., Stutt A., Zdrahal Z., O'Hara K.and Shadbolt N.(1996). Solving VT in VITAL: a study in model construction and knowledge reuse. International Journal of Human-Computer Studies, 44(3/4), pp. 333-371.
Newell A. (1980). Reasoning, Problem Solving, and Decision Processes: The Problem Space as a Fundamental Category. In R.S. Nickerson (Ed.), Attention and Performance VIII, Lawrence Erlbaum Associates, Hillsdale, New Jersey.
Newell A. (1982). The knowledge level. Artificial Intelligence. Vol. 18, 1. pp. 87-127
Newell A. (1990). Unified Theories of Cognition. Harvard University Press.
Poeck, K. and Puppe, F. (1992). COKE: Efficient Solving of Complex Assignment Problems with the Propose-and-Exchange Method. 5th International Conference on Tools with Artificial Intelligence. Arlington, Virginia.
Runkel, J. T. and Birmingham, W. B. (1994). Solving VT by Reuse. Proceedings of the 8th Banff Knowledge Acquisition Workshop, Banff, Canada, 1994.
Stefik M.(1995). Introduction to Knowledge Systems. Morgan Kaufmann. 1995.
Van de Velde, W. (1988). Inference structure as a basis for problem solving. Proceedings of the 8th European Conference on Artificial Intelligence, pp 202-207, London, Pitman.
Van de Velde, W. (1994). Issues in Knowledge Level Modelling. Proceedings of the 8th Banff Knowledge Acquisition Workshop, Vol 2, 1994a. 38-1 - 38-11.
Wielinga B. J., Schreiber A.Th. and Breuker J., (1992) KADS: A Modelling Approach to Knowledge Engineering. Knowledge Acquisition 4(1) pp.5-53.
Wielinga B.J., Akkermans J.M. and Schreiber A.Th. (1995). A Formal Analysis of Parametric Design Problem Solving. In Gaines and Musen (Eds.), Proceedings of the 9th Banff Knowledge Acquisition Workshop, pp. 37-1 - 37- 15.
Yost G.R., Rothenfluh T.R. (1996). Configuring elevator systems. International Journal of Human-Computer Studies, 44(3/4), pp 521-568.
Zdrahal Z., Motta E. (1995). An In-Depth Analysis of Propose & Revise Problem Solving Methods. In Gaines and Musen (Eds.), Proceedings of the 9th Banff Knowledge Acquisition Workshop, pp. 38-1 - 38- 20.
Zdrahal Z., Motta E. (1996). Improving Competence by Integrating Case-Based Reasoning and Heuristic Search. Proceedings of the 10th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop.
[1] Although in this example, one only needs common-sense knowledge to decide on the 'direction' of the constructive constraint.
[2] Our hunch is that this heuristic value range narrowing is just a way of managing complexity during problem solving.
[3] An anonymous reviewer has suggested that, given the right assumptions about the application domain, one could envisage sound, converging criteria based on monotonic decreasing of constraint violations. Of course, this is true in principle. However, in practice it is much more difficult to guarantee that design operator applications will monotonically reduce the number of constraint violations. This is the same as guaranteeing that no antagonistic constraints can be found in the application in hand. Such assumption only applies to relatively simple applications chracterised by low connectivity in the constraint network.