Building Ontologies at the Knowledge Level
using the Ontology Design Environment
M. Blázquez, M. Fernández, J. M. García-Pinar, A. Gómez-Pérez
Laboratorio de Inteligencia Artificial
Universidad Politécnica de Madrid
Campus de Montegancedo sn.
Boadilla del Monte, 28660. Madrid, Spain.
Tel: (34-1) 336-74-39, Fax: (34-1) 336-7412
Email: {mblazque, mfernand, jgarcia, asun}@delicias.dia.fi.upm.es
This paper discusses how ontologies can be specified at the knowledge level using the set of intermediate representations (Gómez-Pérez, Fernández & de Vicente 1996) proposed by METHONTOLOGY (Fernández, Gómez-Pérez & Juristo 1997; and Gómez-Pérez 1998). These intermediate representations bridge the gap between how people think about a domain and the languages in which ontologies are formalized. Thus, METHONTOLOGY enables experts and ontology makers unfamiliar with implementation environments to build ontologies from scratch. In this paper, we also present the ODE (Ontology Design Environment) as a software tool to specify ontologies at the knowledge level. ODE allows developers to specify their ontology by filling in tables and drawing graphs. Its multilingual generator module automatically translates the specification of the ontology into target languages.
Like KBS development, ontology development faces the knowledge acquisition bottleneck problem. However, unlike KBS, the ontology developer comes up against the additional problem of not having any sufficiently tested and generalized methodologies recommending what activities to perform and at what stage of the ontology development process these activities should be performed. That is, each development team usually follows their own set of principles, design criteria and steps in the ontology development process. The absence of structured guidelines and methods hinders the development of shared and consensual ontologies within and between teams, the extension of a given ontology by others and its reuse in other ontologies and final applications. Until now, few domain-independent methodological approaches have been reported for building ontologies. Uschold's methodology (Uschold & Gruninger 1996), Grüninger and Fox's methodology (Grüninger & Fox 1995 and 1994) and METHONTOLOGY (Fernández, Gómez-Pérez & Juristo 1997 and Gómez-Pérez 1998) are the most representative. These methodologies have in common that they start from the identification of the purpose of the ontology and the need for domain knowledge acquisition. However, having acquired a significant amount of knowledge, Uschold proposes codification in a formal language and METHONTOLOGY proposes expressing the idea as a set of intermediate representations (IR) and then generating the ontology using translators. These IR's bridge the gap between how people see a domain and the languages in which ontologies are formalized. The absence of the conceptualization step causes the following problems:
This example shows that unless you are very familiar with the language, it is almost impossible for you to understand existing definitions and to write new definitions. If you are successful in this process, it will have taken a big effort. So, the problem is not understanding that the density is equal to the mass divided by the volume at the knowledge level but writing this in a target language. Therefore, something which is apparently very simple at the conceptual level is extremely complicated when expressed at the implementation level, if developers are not familiar with the language. This means that ontologies are exclusively built by developers who are perfectly acquainted with the languages in which they are to be implemented. As ontology developers are not necessarily expert in the domain for which the ontology is built, ontologists spend a lot of time and resources on the knowledge acquisition process.
First, we present the METHONTOLOGY framework, including the ontology development process and a life cycle based on evolving protoypes. Then, we will show the process of building ontologies from scratch and how to re-structure an ontology when an ontological reengineering process is carried out. Finally, we will introduce the Ontological Design Environment (ODE), a software tool that supports METHONTOLOGY.
Ontological engineering requires the definition and standardization of an ontology life cycle as well as methodologies and techniques that drive their development. The METHONTOLOGY framework enables the construction of ontologies at the knowledge level and includes: the identification of the ontology development process, a life cycle based on evolving prototypes, a method for specifying ontologies at the knowledge level and multilingual translators that automatically transform the specification into several target codes. The environment for building ontologies using the METHONTOLOGY framework is called ODE (Ontology Design Environment).
The ontology development process (Fernández, Gómez-Pérez & Juristo 1997) refers to which activities are carried out when building ontologies. It is crucial to identify these activities if consensual ontologies are to be built by geographically distant co-operative teams with some guarantee of correctness and completeness. If this is the case, it is advisable to perform the three categories of activities presented below and steer clear of anarchic constructions.
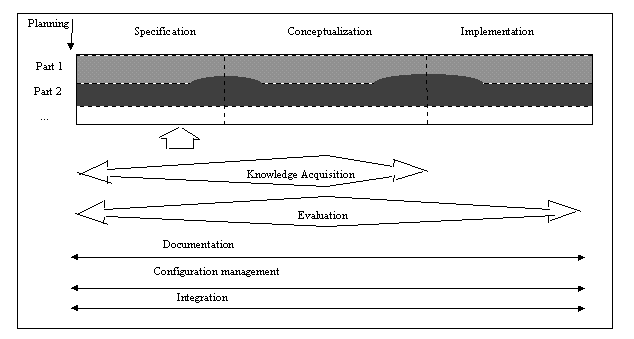
Project Management Activities include Planning, control and quality assurance. Planning, identifies which tasks are to be performed, how they will be arranged, how much time and what resources are needed for their completion. This activity is essential for ontologies that need to use ontologies which have already been built or ontologies that require levels of abstraction and generality. Control, guarantees that planned tasks are completed in the manner that they were intended to be performed. Finally, Quality Assurance, assures that the quality of each and every product output (ontology, software and documentation) is satisfactory.
Development-Oriented Activities include specification, conceptualization, formalization and implementation. Specification, states why the ontology is being built and what are its intended uses and who are the end-users. Conceptualization, structures the domain knowledge as meaningful models at the knowledge level. Formalization, transforms the conceptual model into a formal o semi-computable model. Finally, Implementation builds computable models in a computational language.
Support Activities include a series of activities, performed at the same time as development oriented activities, without which the ontology could not be built. They include knowledge acquisition, evaluation, integration, documentation and configuration management. Knowledge Acquisition, acquires knowledge of a given domain. Evaluation, makes a technical judgment of the ontologies, their associated software environments and documentation with respect to a frame of reference during each phase and between phases of their life cycle (Gómez-Pérez, 1996). Integration of ontologies is required when building a new ontology reusing other ontologies that are already available. Documentation is details, clearly and exhaustively, each and every one of the phases completed and products generated. Configuration Management records all the versions of the documentation, software and ontology code and to control the changes.
It identifies the set of stages through which the ontology moves during its life time, describes what activities are to be performed in each state and how the states are related (relation of precedence, return, etc.). In (Fernández, Gómez-Pérez & Juristo 1997), the authors justified why the ontology life cycle is based on evolving prototypes. Figure 1 shows that:
The IRs used in the conceptualization phase are one of the essential pillars of METHONTOLOGY for building ontologies at the knowledge level. When most of the knowledge has been acquired, the ontology maker has a lot of unstructured knowledge that needs to be organized. The objective of conceptualization is precisely this: to organize and structure the acquired knowledge using external representations that are independent of the implementation languages and environments. METHONTOLOGY proposes ontology conceptualization using a set of IRs based on the IRs used in the conceptualization phase of the IDEAL methodology for knowledge-based systems development (Pazos 1995). In this paper, we discuss how ontologies were built at the knowledge level in the context of the (KA)2 initiative.
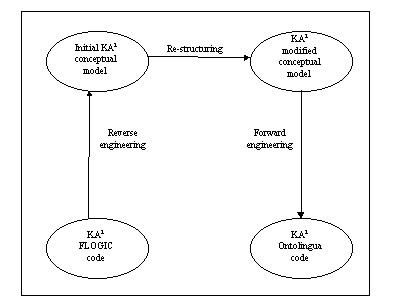
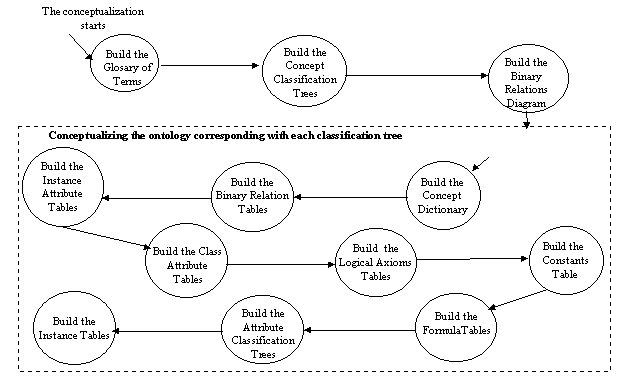
(KA)2 is an initiative to develop an ontology that models the Knowledge Acquisition Community (its researchers, topics, products...). A first release of this ontology was built in Flogic (Kifer, Lausen & Wu 1995). A decision was made to translate the ontology to Ontolingua to make it accessible to the entire community through the Ontology Server. Since concepts as far apart as authors, research centers, publications, etc., had been represented in a single ontology, the option of directly translating from Flogic to Ontolingua was ruled out, and it was decided to carry out an ontological reengineering process. First, we obtained the (KA)2 conceptual model attached to the Flogic ontology manually by reverse engineering. Second, we restructured it (according to the modularity criterion) using ODE conceptualization modules and we got a new conceptual model. Finally, we converted the (KA)2 conceptual model into Ontolingua language using METHONTOLOGY and ODE translators. Figure 2 shows the (KA)2 ontology life cycle. Note that, in this case, our source of knowledge was an ontology that had already been implemented in the Flogic language. So, knowledge acquisition involved understanding an ontology that had already been built. The ontology implemented in Flogic was the specification we took as an input for the conceptualization phase. The knowledge restructuring process at the knowledge level was performed as shown in figure 3 and can be described as follows.
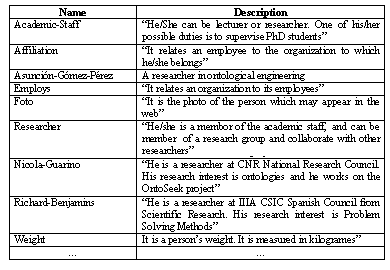
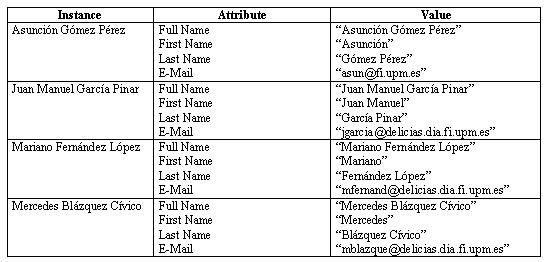
First, we built a Glossary of Terms that included all the terms (concepts, instances, attributes, verbs, etc.) of the domain and their description, as shown in table 1.
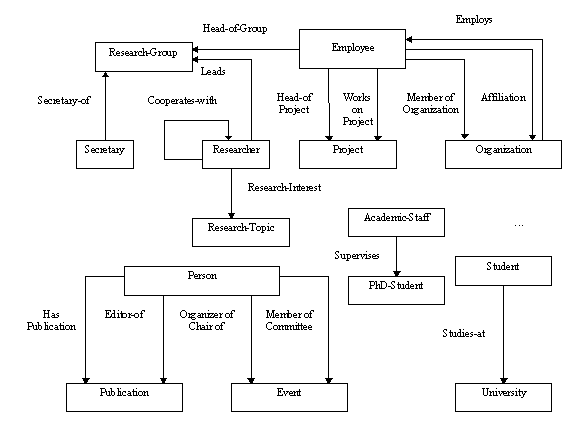
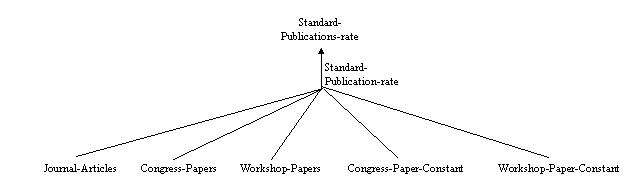
When the glossary of terms contained a sizable number of terms, Concept Classification Trees were build using relations like: subclass-of1, mutually-disjoint-subclass-of2, exhaustive-subclass-of3, etc. So, we identified the main taxonomies of this domain, and each taxonomy produced an ontology as prescribed by METHONTOLOGY. In the (KA)2 ontology, we identified five taxonomies related to: people, publications, events, organizations and research topics. Figure 4 shows an outline of the above taxonomies.
The next step was to build "Ad-hoc" Binary Relations Diagrams between concept classification trees. The goal of this diagram is to establish relationships between concepts of the same or different ontologies. Note that this diagram will set out the guidelines for integrating ontologies, because if a concept C1 is linked by a relation R to a concept C2, this means that the ontology containing C1 includes the ontology containing C2, provided that C1 and C2 are in different concept classification trees. Figure 5 presents a simplified diagram of the "ad hoc" binary relations in the (KA)2 ontology. Note that the People-Ontology includes Organization-Ontology because the source concept of the relations named Affiliation is in the People-Ontology hierarchy. Similarly, if the relation Employs is defined as the inverse relation of Affiliation, the Organization-Ontology can be said to include the People-Ontology.
For each concept classification tree generated, we built the following IRs:
Note that the process of building these IRs is not sequential in the sense of a waterfall life-cycle model, but some order must be followed to assure the consistency and completeness of the knowledge already represented. However, our experience in the use of the model shows that the first table built is the glossary of terms. After this, we build concept classification trees and "ad-hoc" binary relations diagrams. Then, we proceed to build the concept dictionary, the "ad-hoc" binary relations tables, the class attributes and instance attributes and axiom tables.
Embedded in the conceptualization method itself, there are a series of controls for verifying that each IR is used correctly and that the knowledge represented is valid, that is, that the semantics of the conceptualized knowledge is what it should be. For a detailed description of the intermediate representations and individual and cross representation verification see (Gómez-Pérez, Fernández & deVicente 1996).
ODE (Ontology Design Environment) is the environment that enables the development of ontologies at the knowledge level using the approach proposed by METHONTOLOGY. The goal of ODE is to support the ontology maker during the entire life cycle of the ontology development process, from requirements specification, through the phases of knowledge acquisition and conceptualization, to implementation with as much integration and evaluation as possible. To reach this goal, it seeks to automate each ontology development activity and automatically integrate the results of each phase with the input of the following phase.
The functions included in the current version of ODE are: manage ontologies (including: open, close, save, save as, integrate, print, etc., an ontology); manage ontologies in tabular notation (create and remove table, add and delete table rows, print table, etc.); manage intermediate representations in graphic notation, automatically generate code in formal languages; customize the user interface; and manage conceptualization and user interface errors.
As the conceptualization of a complete and consistent ontology involves the management of a huge amount of information, the decision was made to store the entire ontology in a relational database. This has the big advantage that future applications will access the ontology easily using SQL queries because this database management and access language is widely used in practice which facilitates the creation of applications, networked or otherwise, that use our program.
In order to maintain the consistency within each intermediate representation and between intermediate representations, it was considered necessary to study the constraints in the fields of a conceptual table or between the fields belonging to different conceptual tables. This study was based on the rules of verification of the intermediate representations proposed in (Gómez-Pérez, Fernández & de Vicente 1996) and seeks to identify any effects possibly caused by the operations of editing an ontology at the conceptual level and how the above operations are implemented in the database.
As user experience in ontology development varies, ODE also provides an option of guided conceptualization that enables inexperienced users to learn about ontology development. This guided conceptualization, has proved very useful for domain experts who want to build their own ontologies.
It shuld be noted to say that ODE is being designed as an environment that is completely independent of any system capable of managing ontologies. That is, although ODE generates Ontolingua code in ASCII, ODE does not interact with Ontolingua.
Finally, the computational requirements to run ODE are: a Pentium with a Windows 95 operating system. ODE has been programmed in Visual Basic version 5.0. Its user interface complies with Microsoft design standards for the development of event-oriented applications and the ontology is stored in an Access (version 7.0) database.
ODE's big advantage is that it enables specification of ontologies at the knowledge level, delegating implementation to fully automated code generators. So, non-experts in the languages in which ontologies are implemented could specify ontologies using this environment.
In order to assure translation of the conceptual model to as many languages as possible, the translator module was designed using the principles of modularity and reusability. The translator module works on the following elements:
the data dictionary is expressed as shown below:



Using the translator that converts the conceptualization into an implementation, error-free code can be generated, which dramatically cuts the time and effort involved in implementation. Furthermore, the architecture of this translator allows other translators to be developed in series. By merely changing the rules that identify the patterns of the terms to be generated and the second column of the table which relates the conceptualization to the implementation, a new translator can be built. This was how we built a translator for SFK in a short period of time.
5. CONCLUSIONS
This paper provides a series of guidelines for specifying ontologies at the knowledge level, as defined by Gruber (Gruber 1993), as an automatically generated explicit specification of a conceptualization. It also presents ODE as an environment for building ontologies during the entire ontology life cycle and implementing them automatically using translators.
METHONTOLOGY is a structured method for building ontologies at the knowledge level from scratch and when an ontological reengineering process is carried out. It seeks to build the ontology incrementally using a life cycle based on evolving prototypes. The methodology centers on the process of building conceptual models by defining concepts, instances and properties of the above concepts, organizing concepts in taxonomies, defining relations between taxonomies by means of "ad-hoc" relations, defining concept axioms and defining formulas. It also includes verification and validation of the ontology at the knowledge level.
ODE is a tool that automates ontology development activities and, therefore, seeks to automatically integrate the results of each phase. ODE uses a relational database to store the ontology and to assure consistency within and between IRs. Finally, the ontology can be constructed off-line and target code can be generated using ODE translators. It has a very intuitive user interface and it works on a Pentium.
We are grateful to the Knowledge Sharing and Reuse Group at the Laboratorio de Inteligencia Artificial of the UPM for their contribution to ODE design and implementation, and particularly to Julio Arpírez, Oscar Corcho and Javier Castillo.
![]() Fernández, M.; Gómez-Pérez, A.; Juristo, N. (1997) METHONTOLOGY: From Ontological Art Towards Ontological Engineering. Spring Symposium Series. Stanford. PP: 33-40.
Fernández, M.; Gómez-Pérez, A.; Juristo, N. (1997) METHONTOLOGY: From Ontological Art Towards Ontological Engineering. Spring Symposium Series. Stanford. PP: 33-40.
![]() Gómez-Pérez. A. (1998). Knowledge Sharing and Reuse. The Handbook of Applied Expert Systems. Edited by Liebowitz. CRC.
Gómez-Pérez. A. (1998). Knowledge Sharing and Reuse. The Handbook of Applied Expert Systems. Edited by Liebowitz. CRC.
![]() Gómez-Pérez, A. (1996). A framework to Verify Knowledge Sharing Tec hnology. Expert Systems with Application. Vol. 11, N. 4. PP: 519-529.
Gómez-Pérez, A. (1996). A framework to Verify Knowledge Sharing Tec hnology. Expert Systems with Application. Vol. 11, N. 4. PP: 519-529.
![]() Gómez-Pérez, A.; Fernández, M.; de Vicente, A. (1996). Towards a Method to Conceptualize Domain Ontologies. Workshop on Ontological Engineering. ECAI'96. Budapest. Hungary. PP: 41-52.
Gómez-Pérez, A.; Fernández, M.; de Vicente, A. (1996). Towards a Method to Conceptualize Domain Ontologies. Workshop on Ontological Engineering. ECAI'96. Budapest. Hungary. PP: 41-52.
![]() Gruber, T. (1992). Toward Principles for the Design of Ontologies Used for Knowledge Sharing. Technical Report KSL-93-04. Knowledge Systems Laboratory. Stanford University, CA.
Gruber, T. (1992). Toward Principles for the Design of Ontologies Used for Knowledge Sharing. Technical Report KSL-93-04. Knowledge Systems Laboratory. Stanford University, CA.
![]() Gruber, T. (1993). A translation Approach to Portable Ontology Specifications. Knowledge Acquisition. Vol5. 1993.
Gruber, T. (1993). A translation Approach to Portable Ontology Specifications. Knowledge Acquisition. Vol5. 1993.
![]() Gruber, T.; Olsen, G. (1994). An Ontology for Engineering Mathematics. Fourth International conference on Principles of Knowledge Representation and Reasoning. Doyle, Torasso and Sandewall (Eds). Morgan Kaufmann. Also as KSL-94-18.
Gruber, T.; Olsen, G. (1994). An Ontology for Engineering Mathematics. Fourth International conference on Principles of Knowledge Representation and Reasoning. Doyle, Torasso and Sandewall (Eds). Morgan Kaufmann. Also as KSL-94-18.
![]() Grüninger, M.; Fox, M.S. (1995). Methodology for the Design and Evaluation of Ontologies. IJCAI Workshop on Basic Ontological Issues in Knowledge Sharing. Montreal, Quebec, Canada.
Grüninger, M.; Fox, M.S. (1995). Methodology for the Design and Evaluation of Ontologies. IJCAI Workshop on Basic Ontological Issues in Knowledge Sharing. Montreal, Quebec, Canada.
![]() Grüninger, M.; Fox, M.S. (1994). The Role of Competency Questions in Enterprise Engineering. IFIP WG 5.7. Workshop on Benchmarking. Theory and Practice. Trondheim, Norway.
Grüninger, M.; Fox, M.S. (1994). The Role of Competency Questions in Enterprise Engineering. IFIP WG 5.7. Workshop on Benchmarking. Theory and Practice. Trondheim, Norway.
![]() Kifer, M.; Lausen, G.; Wu, J. (1995). Logical Foundations of Object-Oriented and Frame-Based Languages. Journal of the ACM.
Kifer, M.; Lausen, G.; Wu, J. (1995). Logical Foundations of Object-Oriented and Frame-Based Languages. Journal of the ACM.
![]() Pazos J. (1995). Conceptualización. Máster en Ingeniería del Conocimiento. Facultad de Informática de Madrid. Universidad Politécnica de Madrid. SPAIN.
Pazos J. (1995). Conceptualización. Máster en Ingeniería del Conocimiento. Facultad de Informática de Madrid. Universidad Politécnica de Madrid. SPAIN.
![]() Uschold, M.; Grüninger, M. (1996) ONTOLOGIES: Principles, Methods and Applications. Knowledge Engineering Review. Vol. 11; N. 2.
Uschold, M.; Grüninger, M. (1996) ONTOLOGIES: Principles, Methods and Applications. Knowledge Engineering Review. Vol. 11; N. 2.
Figure 1. Ontology Life Cicle
Figure 2. Ontological Reengineering Process of the KA2 Ontology
Figure 3. The knowledge restructuring process
Figure 4. Concept Classification Trees in (KA)2
Figure 5. Diagram of Binary Relations in (KA)2
Figure 6. Attributes Classification Tree in (KA)2
Table 1. Glosary of terms in (KA)2
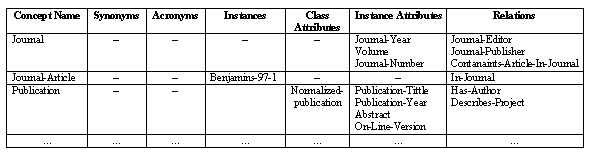
Table 2. Concept Dictionary in the domain of People
Table 3. Concept Dictionary in the domain of Publication
|
Table 4. Binary Relation Employs |
Table 5. Binary Relation Affiliation |
|
Table 6. Instance Attribute Photo |
Table 7. Instance Attribute Weight |
|
Table 8. Named Axiom |
Table 9. Named Axiom |
|
PhD-Student-Is-Not-InDoctoral-Tesis-Jury |
The-Head-of-Project-Works-on-at-Project |
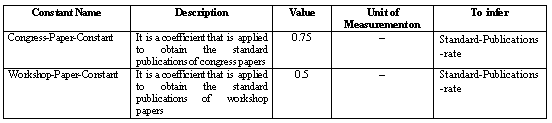
Table 10. Constants in the domain of Publication
Table 11. Formula of Normalized Publications
Table 12. Instances in the domain of People
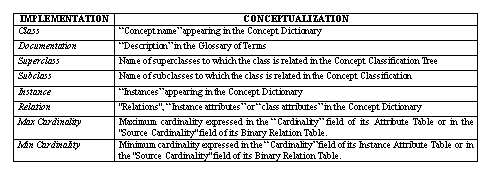
Table 13. Relationship between conceptualization and implementation for classes