- Correct and complete?
- The PSMs have been translated and/or specified in CML and errors may have been made.
- Effective?
- Like any method, PSMs are used to achieve some goal. The question is whether a PSM can effectively be (re)used to obtain the results it is supposed to achieve. In other words, the question is whether the PSM works according to its (claimed) function.
- Efficient?
- Methods may differ largely in the costs of resources they may require. In a comparative study we can assess whether PSMs which yield the same results differ in demands on resources.
Validating (testing) systems or devices differs somewhat from that of PSMs, because a PSM is always incomplete. It has applicability conditions and needs domain knowledge to operate. In the specification of reusable PSM these conditions and required domain knowledge are called features (in the Library, see also (Steels, 1990}), or requirements and assumptions (Fensel & Benjamins). The domain requirements go often under the name `method ontology' (Erikson et al. 1995). The effect (main function) of a PSM can also be viewed and described as an assumption or requirement that is implied by the PSM. For instance, GDE finishes successfully by the identification of one or more components of a system which can be blamed for some malfunction(s) of a system. However, heuristic classification can be used to classify the malfunctioning of a system, which is assumed to be a diagnosis. GDE therefore requires that `components' are an explicit part of the domain knowledge, while heuristic classification requires that there is some hierarchy of classes of malfunctions. As a PSM consists of subtasks, for each subtask input/output requirements can be specified. In CML these are called roles. Therefore PSMs are riddled with assumptions: not only on what constitutes the outcome in terms of domain knowledge, but for all the roles it imposes on the domain knowledge to play. Besides this ``method ontology'' (Eriksson et al., 1995) of a PSM with respect to domain knowledge, many more kinds of assumptions and requirements are involved in PSMs, that act like applicability conditions in restricting the scope of use (Fensel & Benjanmins, 1996). Therefore, we may be concerned more in general with testing the assumptions and requirements of the methods, and not only focus on those that describe the main function. This makes the problem even more complex, as the assumptions and requirements are not of a uniform nature.
The use of assumptions is also at the bottom of the next validation question: the efficiency of a method. Given two PSMs with the same effect (function), one PSM may use less resources (computations, domain knowledge) than the other one. In general, there is a trade-off between efficiency and assumptions: making assumptions instead of making inferences makes cheap problem solving. Compiled out knowledge takes less steps than derivations from ``first principles'' to arrive at the same conclusion, etc. Assumptions that make PSM efficient or even tractable put the burden of validation questions to the completeness and correctness of the specific application domain knowledge, and in particular to the credibility of the source of the knowledge. Therefore, efficiency of a PSM cannot be a single criterion to prefer it as its choice may lead to less flexible and maintainable knowledge systems than less efficient candidates.
Assumptions are called ``features'' in the Library. However it is for certain that only a small part of the assumptions and requirements of the PSMs are made explicit: most are specified to discriminate between PSMs which means that only the features that distinguish between PSM with similar functionality are described. Therefore an important goal of the CoCo project is to check the PSMs in such a way that assumptions become explicit. This can/is expected to occur in various ways, as we will explain in the next section.
1.2 Formal vs operational validation
Another way the Library can be evaluated is by translating the CML specifications into (ML)2, as was also foreseen in the KADS-II project. (ML)2 preserves the structure of the expressions in CML, so that there is an easy mapping between the two versions. This mapping allows a semi-automatic initial translation by the use of the Si((ML)2) toolset, which makes the correspondence between a conceptual and a formal specification highly transparent (Aben et al., 1994). In (Van Harmelen & Aben, 1996) the process of translating the ``informal'', but well structured CML specifications into (ML)2 specifications, and its use in specification validation is fully described. Structure preserving means in this context that the ``layers'' or types of knowledge that the CommonKADS CML distinguishes -- domain, inference and task -- are identified in both languages. However, within each layer, there is not a one to one correspondence between the syntactic categories of CML and those of (ML)2. For instance, CML distinguishes at the domain layer a number of categories, like concept, property, attribute, relation, expression, etc while this layer is expressed in (ML)2 by classical FOPL (extended with ordered sorts). The translation here implies to `descend' to less ontological commitment. However, this is not true for the inference layer, which requires a more precise commitment to the domain layer than CML requires. The CML inference layer expresses the inferences as functions between input and output roles, and these roles are to be filled with domain knowledge. Therefore, in (ML)2 the inference layer is a logical meta-theory, which also `knows about' roles and their content, i.e., the reflective predicates ask-domain-axiom and ask-domain-theorem are used to establish the connections with the domain layer. For the task layer, which specifies the control of the reasoning, (ML)2 uses dynamic logic. Therefore some `verification-by-refinement' is implied by this translation process: (ML)2 requires to specify which axioms or theories are to be consumed by a specific inference function. However, also in this case we need domain knowledge to validate the PSMs.
Besides a specification of a (generic) knowledge base of domain knowledge, one needs some dynamics as well. The formal specifications written in (ML)2 can be `animated' by the use of theorem proving procedures. These proof procedures are an instrument to verify and validate (V&V) the specification (see (Van Harmelen & Aben, 1996) for the general picture and a worked out example). The proof procedures perform consistency checking and the tracing of the validity of the specifications in one and the same general theorem proving exercise. Using this formal way certainly has its advantages, but requires still a lot of hand crafted formalization in (ML)2, which is by no means a trivial effort (Ruiz et al., 1994).
Although formalization is certainly the royal road to validation, also
other procedures are available, particularly because PSMs are not quality
critical products, such as e.g., safety systems. A 100 % Strictly speaking, CML has no semantics, nor an interpreter. The mapping
to (ML)2 only provides `semantics-by-association'. For instance, in (ML)2
the domain layer is represented by sorted logic, and does not distinguish
the syntactic categories of the official grammar. The Cokace environment is constructed at INRIA and consists of three
components (see (Corby & Dieng, 1996) for the details):
Cokace has an apparent disadvantage over the two other operational CML
environments: the task/inference layer does not operate directly on the
CML domain specifications. For each inference, a small knowledge base of
rules has to be constructed by hand to make the interpreter run. The first step is to use one and the same domain for the validation
procedures, so we can reuse the same terms or concepts all the time. Or
rather: we can select from the same domain ontology the concepts we need
for constructing knowledge bases. With domain ontology we mean also the
inclusion of its ontological commitments. As many PSMs use various types
of domain knowledge, we may specify these types as generic model
specification. For instance, many PSMs use causal, behavioural, functional,
structural etc. knowledge, often in the form of models of the problem situation,
or as generic library components from which models of the situation can
be constructed. Particularly, model based reasoning PSMs require these
kinds of typed generic model knowledge. These generic models are not necessarily
``task neutral'' as they may contain specific interpretations of the relations.
For instance, in many abductive PSMs for finding causes of abnormal states,
the interpretation of the causal relation is more ``compiled out'' than
in the behavioural models that are used in model based diagnostic reasoning.
CML distinguishes between ontologies and models, but this is only a nominal
distinction: the language categories used are the same for both. Knowledge bases are to be constructed from these ontologies and model
knowledge. We will leave aside for the moment the problem of translation
into different knowledge representation formalisms. CML specifications
have a frame based, object oriented flavour, while Cokace uses rules. This
translation can be performed largely in a syntactic way, as long as there
are explicit semantics, which is to a large extent what ontologies are
about and makes them `portable' (Gruber 1993). Where semantics come in
we have a more general problem anyway, as an ontology and the knowledge
typing cannot be directly mapped onto a knowledge base, at least not in
a straightforward manner, if one keeps the notion of ontology as different
from knowledge base, i.e., as task neutral as possible. It is
suggested in the use of CML specified ontologies that via relatively simple
mapping operations the components of these specifications can be turned
into knowledge bases (Schreiber et al., 1995). However, the distance between
what's in an ontology and the requirements of a knowledge base, given a
PSM, is not necessarily simple. There can be two types of these ``knowledge
mismatches'':
A small complication in the use of Cokace as our testing environment
is that fact that the CML task/inference layer does not operate on one
single knowledge base. Each inference requires its own knowledge base.
It means that the knowledge has to be distributed in advance over these
inferences. It will have as an additional effect that we will be able to
study also the reusability of specific domain inference knowledge. We expect
this reusability to be rather limited as the KADS inferences define formal
functions rather than content on which they operate. Figure 1
summarizes the specification steps for the static inputs (domain knowledge)
for our experiments.
However, we will not only be interested in the final state and match
it against the problem type. This can in many cases also be accomplished
by a static verification of the kind of domain knowledge that is supposed
to fill the solution-role of a PSM. In fact this is what Cokace can easily
achieve for these cases. In operational validation we can be more precise:
The PARC Windows user interface has been the leading paradigm for graphical
user interfaces (GUIs) for more than a decade, and with good reasons. It
exploits an intuitive analogy between information structure and graphical
layout. Our abstract domain is about these windows. We will strip away
all additional features and end up with a domain as abstract as the blocks
domain. For instance, our windows have no scrollbars, as they have no content:
they are really transparent, ``clean windows''. The clean windows are empty
information containers, which have the capacity to open/close, move and
to change size. These actions can be triggered via buttons and the buttons
can be connected as to propagate the initiation of specific actions. In
this way all states are visible on the screen. We are implementing this
relatively simple domain in such a way that it can be interfaced (via X-Windows)
to Cokace, so that all problem solving states can be directly mapped onto
the screen. In the next section we will present the ontology that is the
specification both for Clean Windows and the domain knowledge for CoCo.
The primary entities visible on the screen usually go by the name of
objects or devices in GUI designers' parlance. Since object is too general
and already has a fixed meaning in CML, we adopt the name device
as a general term for the window-system and its subsystems. The notion
of a device in a programming environment does not correspond directly to
that of a physical device. The most notable difference is that devices
on the screen are not easily described in terms of distinguishable and
static inputs and outputs. The basic meaning however is fixed, stating
that it is some man-made artifact that shows some behaviour that is useful.
Note that the screen is not a device. The screen cannot be designed
and is therefore for all practical purposes not a device, but something
like a place: an environment in which the two-dimensional spatial extension
of devices makes sense. The screen itself and the devices displayed on
it share some parameters inherited from the concept region; Both
are rectangular, observable spatial entities. Rectangleness implies that
regions can be described with exactly two x-boundaries and exactly two
y-boundaries; We call these their x-start, x-end, y-start and
y-end. The region is subject to the constraints x-start =<
x-end and y-start =< y-end. Two other parameters of regions,
width and height, are derived from the boundaries and can be defined by
the constraints width = x-end - x-start and height = y-end
- y-start. Other derived measures, like area and aspectratio, will
spring to mind but these are not actually used to classify types of regions.
Boundaries , and differences between boundaries of the same type,
can be ordered on a dimension (measuring scale). All obvious ordering relations
apply to boundaries (=,>,<,=<,>=). Rectangles are usually defined
as polylines which are in turn defined by points, but this solution is
more complex and ignores a concrete fact about screens; Screens can only
display rectangles. A point, or more accurately a pixel, is a type of region
subject to the constraints x-start = x-end and y-start = y-end.
It thus has a width and height of 0, but would still be a rectangle on
the screen. Our regions and pixels are "places" according to Hayes (e.g.
in (Hobbs & Moore, 1985)), not positions. A region defines two intervals
in two dimensions, (x and y) on which all thirteen primitive relations
between intervals identified by Allen and Kautz (e.g. in (Hobbs
& Moore, 1985)) apply for each single dimension. Note that a qualitative
calculus based on these primitives does not always suffice for reasoning
in two dimensions as it does in one dimension; Numbers are be assigned
to boundaries in order to prevent ambiguity. A region includes its boundaries
as its starting (s) and finishing (f) subintervals. The boundary
interval represents a row of pixels on the screen and cannot be any further
decomposed. The width and height intervals of the screen define what is
commonly known as its resolution. Furthermore we have a 2.5th dimension:
the order in which devices should be displayed.
Regions All regions are mereological individuals (m-individuals).
The difference between screens and devices is that the screen cannot be
a proper-part-of a device, while devices can be proper-part-of a screen.
The screen is thus composed of devices. The binary relation s-proper-part-of
is a one-to-many relation between a screen and devices. Another difference
is that a device has one or more stimulus (boolean) parameters and
a named parameter display-status, with the valueset {open, closed},
its value depending on whether the device is at present visible on the
screen or not. At least some devices can be decomposed. To this end serves
the distinction between frames that have other devices as their proper
parts, and components that cannot have any parts (simple-m-individuals).
The relation between a frame and its parts is modelled by the one-to-many
relation f-proper-partition-of. A frame must have at least one device as
its part and only frames can be directly s-proper-part-of the screen. The
enumeration of the proper partitions of the frame is exhaustive (and of
course disjoint) meaning that any arrangement of devices can be assembled
in a frame. For now we will skip the window and continue with components.
Controllers and displays Another important differentiation is
that between controllers and displays. Exactly one action acts on a controller
and it will usually trigger operations through a stimulus changing the
state of the Clean Windows GUI (but dummy controllers are not disallowed
by this definition). Controllers have a parameter control-status.
Displays achieve the function of displaying some type of information: e.g.
a text or image. Controllers always display some type of information indicating
the consequences of manipulating it. Most often this is text, since actions
are notoriously hard to picture. The only controllers we are concerned
with are buttons. Buttons add the value set {pressed, depressed}
to control-status and realize the action press. Full dialog including e.g.
line- and text-editors is not considered for this domain, since it is too
complex and irrelevant. If, for instance, we consider a standard "open
file" frame, we will see a line-editor, a list of choice item buttons displaying
filenames and a button displaying "open" or something like that (and a
"cancel" button that closes the frame). Clean Windows will not react to
selection of a filename and will either open some type of window or do
nothing except closing the frame if the "open" button is pressed. Editor
components can be pressed and will become "active" wrt. keyboard events,
but this event never changes the interface. The application events are
irrelevant to the window behaviour in which we are interested. In the kind
of applications we will design, all events have direct visible consequences
on the screen.
Fixed vs variable The last differentiation we make wrt. components
is that between fixed-size and variable-size components. Fixed-size-components
always have a predefined width and/or height and thus constrain the assignment
of x-start, x-end, y-start and y-end. Buttons are always of fixed-size
wrt. to both width and height. A text-view on the other hand does not have
to display the entire text. Optimality requirements may however specify
a preferred or minimal size. Note that width and height more or less correspond
with "duration" of a temporal interval in Allen and Kautz (in Hobbs &
Moore, 1988). Fixed-size components can not be resized. The leaf component
concepts, like label and icon, are not transparent to this ontology.
Application The application concept seems similar to the frame
and has only been recently added to disambiguate the frame. The application
is an m-individual that has a parameter name (a string) and serves as a
wrapper for coherent, possibly reusable ("case knowledge") designs or classes
of known systems to be used in classification problem-solving. Behaviour,
state and layout of frames in relation to each other can be encapsulated
in application descriptions. An application contains at least one region;
this is modelled with the one-to-many relation a-proper-part-of. The difference
between frames and applications is that applications are not necessarily
rectangular; An application cannot be described in terms of boundaries.
Mereology extensions The relations s-proper-part-of and f-proper-partition-of
imply a transitive layout relation: inside. A region that is contained
by another region is inside that other region. If a component is f-proper-partition-of
a frame that is s-proper-part-of the screen, the component is r-proper-part-of
the screen and thus inside the screen. Insideness is transitive. The screen
as well as the frame could be a-proper-part-of an application and the component
would be transitively proper-part-of the application, while not being inside
it. Obviously, the proper-part-of relation is irreflexive and asymmetric.
The proper-part-of generalization tree is shown below in Table 3
with the appropriate domains.
Only in the case of devices that overlap or are inside each other, a
third (or 2.5th) display dimension comes into play; Some constraints on
the order in which devices should be displayed must be made. If a device
is r-proper-part-of another device, this device is the one that is displayed
first. If two devices overlap, no clear criterion can be specified. In
that case a device covers the other because it has been displayed last.
Covers only adds asymmetry to the symmetric overlaps relation. The generalization
hierarchy in Table 4 shows these layout-relations. All
concrete (leaf) relations are asymmetric. The meaning of l-relations wrt.
Allen and Kautz (in Hobbs & Moore, 1988) is added as a disjunction
of applicable primitives on the x-axis and y-axis. Note that the rationale
of the hierarchy is based on quantitative constraints, not these primitives.
The meets (m mi) primitive has a specific meaning with respect to
boundaries between intervals: m(region1, region2) implies (x-end of
region1 - x-start of region2= -1).
In the window ontology it may not be immediately obvious how a non-trivial
assignment problem can be specified. We do however have a example of an
assignment problem that is as complex or simple as we want, depending on
which knowledge and assumptions we use to solve it. The configuration of
a window gives us all ingredients we need to formulate an example of an
assignment problem. Our standard window concept is visualized in Figure
4 below. We assume that a model of this device has been
designed. It specifies that we have a window s-proper-part-of a screen
that has a number of devices as its proper-partitions: an icon-button (to
close), a label to display the title and a device that is no further specified
(which we will call the canvas). Two out of three parts of the window are
fixed-size. The concept screen and device introduce a number of parameters
assigned to an integer describing a two-dimensional region: x-start, y-start,
x-end, y-end. The relations between the screen and devices as well as devices
and devices introduce a number of constraints on the values these parameters
can take. Constraints come from the following sources:
Significant reductions in the number of constraints can be achieved
by taking into account transitivity of <, =<, >, >= and the possibility
of unification of =, >= and =< for x-boundaries and y-boundaries. Unifying
>= and =< does add strong commitments to the ontology. In some cases
it is clearly correct to assume that boundaries that can be equal are indistinguishable.
In other cases this assumption may prevent finding a valid solution to
the problem. In most non-trivial cases, for instance, one cannot assume
that the window can be "maximized" (spatially indistinguishable from the
screen). Solving this problem in a generate & test approach (propose
any boundaries and then test all constraints) is extremely complex. This
PSM is obviously warranted by the ontology, but is extremely inefficient
for this problem.
Typical assignment PSMs, such as Propose & Revise (Marcus &
McDermott, 1989) and other lookalikes, e.g. (Poeck & Puppe, 1992),
suggest exploiting constraints in a more productive way. If we take into
account transitive relations to do static presorting, we are left with
10 x-boundaries and 10 y-boundaries ordered to increasing value and a total
order of increasing values. If we exploit unification of equality operators
(including width and height definitions) and the m-b-connection to define
calculations this is reduced to seven key design parameters for which a
value should be proposed. Note that changing equality constraints to assignment
calculations introduces the requirement of no cyclic dependencies between
parameters (Marcus & McDermott, 1989). This requirement is trivially
satisfied by the two boundary-scales. Transitivity can be exploited to
deduce incremental fixes, but for this problem this only makes sense if
we do no presorting. Fixes usually contain two types of revision knowledge;
redesign knowledge and dynamic sorting knowledge (in effect changing the
order in which parameters or values are tried) both based on diagnostic
knowledge. This type of problem does not involve dynamic sorting criteria
on parameters and values. Dynamic assignment problems can however be contrived
for this domain if we take behaviour and causation into account.
Behaviour In order to be able to design, plan, predict and diagnose
we have to address the behaviour of devices and the way in which connections
in a design mediate causation. First we will describe states and change.
A state of a device is an abstraction of the parameter values and
roles of a device. Sets of parameter-value tuples referring to one device
can be grouped together as a state. States should always maintain integrity
wrt. specified constraints on the parameter-values. Most constraints are
concerned with coherent layout, one constraint is concerned with coherent
display-status; The display-status of a frame cannot be closed if the display-status
of any of its parts is open. A state persists until it changes to be consistent
with the structure description of its device. Shoham (1988) discusses persistence
and the assumptions that must be taken into account in order to make unique
and consistent prediction of the consequent history of a device.
An event is a change of state of some device and the type of
an event is defined by constraints on the initial and final state of the
device. A derived process can be characterized as a sequence of events,
or an ordering of states induced by change. For this purpose there is the
relation before (<) and its inverse after (>) between events imposing
a temporal scale on events. Note that often a description of process in
terms of its parts will be sufficient (during interval etc.). We
may, for instance, not care to know to know the sequence (or lack of it
in a concurrent system) in which parts of a frame close. All interesting
events happen to devices and change the values of the parameters x-start,
x-end, y-start, y-end, width, height and/or display-status. Open and close
are defined as a change of display-status from closed to open or open to
closed, respectively. Resize changes the value of one or more of the parameters
x-start, y-start, x-end and y-end; Move changes all of these while width
and height remain constant. Any number of events can act on a device. This
is modeled with the many-to-one relation acts-on between events
and devices. A least open and close act on any device. The events discussed
thus far are operations. An example description of the operation close
is given below in Table 6:
We will use the window model as an example for behaviour. The window
has three parts that have the same display-status as the window itself.
These four display-status parameters are all connected by eq-connections.
If the window closes, it changes from a state in which display-status is
open to one in which it is closed. Since the same change happens to the
parts of the window, we have established that during this process its parts
have closed. The same thing applies to other operations. If the window
resizes by changing its y-start (becoming longer) and the y-start of the
icon and label have an eq-b-connection with this parameter, the same change
happens to the y-start of the icon and label. These however have a fixed
height. To keep height constant the icon and label change their y-end too,
resulting in two move operations that occurred during the resize process
of the window. If the y-start of the canvas would have a m-b-connection
with the icon and label, the canvas would resize. Since we do not know
in which sequence these events must have happened, we assume concurrency.
The events that can occur concurrently, or events that have consistent
conditions, cannot have inconsistent consequences. Resize and move as defined
are able to break constraints if, for instance, they are allowed to move
a device out of the screen. The only way to prevent this from occurring
is giving the device nonlocal access to other parameters: the resolution
boundaries of the screen. This violates the principle of locality of behaviour
description (a more specific version of no-function-in-structure),
unless we introduce more complex connections to a.o the screen to accommodate
conditions to events. The disadvantage to this solution is that these connections
cannot be visualized. This is an accurate reflection of this domain. We
have to assume some underlying invisible machinery to explain things like
this. Systems dynamics concepts can only give an incomplete description
of behaviour in this domain: some global constraints simply cannot be factored
out. Our guesses about the structure and behaviour of this underlying machinery
that explains these constraints are as good as anyone elses.
The only root cause of any process is some trigger event caused by an
action on a controller. The action is an unqualified input to the system.
The trigger effect in this case is a stimulus. The action press acting
on a controller will change the control-status of the button to pressed,
which is the precondition to a trigger operation that sets a stimulus to
true. The stimulus can have an eq-connection to another stimulus in another
device. This stimulus in turn can be precondition to some individual event,
for example the resize already described. The stimulus is a bit of a poor
man's solution to this problem, similar to the notion of effort (the cause
of change or flow) in physical domains (see e.g., (Borst & Akkermans,
1997)). Connections between stimuli are the main source of degrees of freedom
in design.
We have thus far focussed on the first part of the problem dependency
graph in Figure 2. Both the graph and common sense suggest
that we could not have done it the other way around We have tried to cater
for two mainstream approaches to design: hierarchical/case-based design
and arrangement of connection topologies. Nontrivial planning is possible
in this domain, as opposed to, for instance, common electronic domains
or the blocks domain. The problem wrt. locality of behaviour descriptions
we mentioned before is not a design, planning or prediction problem. It
presents a problem if we want to localize faulty behaviour in a structural
entity in a design. This is the goal of several diagnosis PSMs (see e.g.,
(de Kleer & Williams, 1987)). This need not be a serious problem, since
we for instance established that a Cover & Differentiate PSM (Duursma,
1992) can be applied to postdict a specific subset of design models (barring
feedback loops). PSMs need not be universal for this world: we just want
to know why they are not.
A recurring problem in constructing this ontology was the lack of a
problem-specific context (or the abundance of them). For instance, for
every primitive introduced the distinction between candidates and facts
arises wrt. relations ( can be vs. is a variants of basically
the same relation). These roles are part of what is now commonly known
as a method ontology (and we could add a task and problem ontology). Problem-specific
contexts introduce their own semantics as the Propose & Revise assignment
example, for instance, showed for the change of the equality operator to
an assignment operator. Only then the cyclic dependency problem comes into
existence. The accuracy of knowledge bases may depend less on their meaning
wrt. this ontology than it does on method-specific features. In a way this
is an encouragement, if it means that assumptions in general have less
to do with the domain than with our way of looking at it.
However, the other side of this coin is that CoCo provides a
unique way to assess the relative importance of the ``interaction hypothesis'',
which states that domain knowledge is never task neutral. This is indeed
unique because thus far this effect has been only assessed in studies of
reuse where domain knowledge was used for other purposes (tasks), e.g.,
(Coelho et al., 1996), or in rational reconstructions as in the Sisyphus-II
project (Schreiber & Birmingham, 1996). Another side effect is that
another hypothesis can be tested: that problem types, and therefore also
the decompositions implied by the PSM are dependent upon one another in
a fixed way, as specified by a ``suite of problem types'' (Breuker, 1994b).
One of the conclusions that this project is supposed not to yield
is about the specification language, CML. Whether specified in CML or any
other language the working of the PSMs should be the same. However, in
passing we have seen that CML is in fact not well suited for operationalization,
in particular with respect to the domain layer specifications. Not one
of the operational versions of CML in fact uses the specification categories
of the domain layer, and neither do the formal versions!
This document was generated using the LaTeX2HTML
translator Version 95 (Thu Jan 19 1995) Copyright © 1993, 1994, Nikos
Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
The translation was initiated by Alexander Boer on Wed Nov 26 14:54:14
MET 1997
Cokace
Cokace was selected for our purpose, primarily for two reasons: (1) it
consisted of a ready made programming and testing environment for CML specifications,
in particular because of its type-checking, and (2) Cokace contains the
full CML specification, while the other two systems have some minor variations:
in particular, they do not follow the CML domain categories, but have their
own (like (ML)2). Additional reasons are that the Cokace environment lends
itself very well for a full implementation of the Library, complete with
the search and navigation tools as required by the design specification
of the Library. Finally, mechanisms are under construction that allow interactive
search, selection, editing and prototyping van CML specifications via internet
(see http://www.inria.fr/acacia/Cokace).
The type checker and CML editor allow us to have a first semi-automatic
verification of the CML specification. The interpreter is the major vehicle
for validity testing. This testing of the PSMs can only be performed if
some domain knowledge is available to operate upon.
2 Planning the experiments: the
CoCo cycle
2.1 Specifying the inputs
2.1.1 Keeping domain knowledge
constant
It is obvious that in the latter case the construction of a knowledge base
from an ontology (via models) is by no means a straightforward mapping.
It may mean complex transformations and even additional knowledge acquisition.
In the CoCo project we may choose or construct an artificial domain,
where we can avoid these complications in domain modeling and knowledge
base construction. In the domain we have designed, no (relevant) knowledge
has to be imported to explain the working of lower grain size levels (Section
3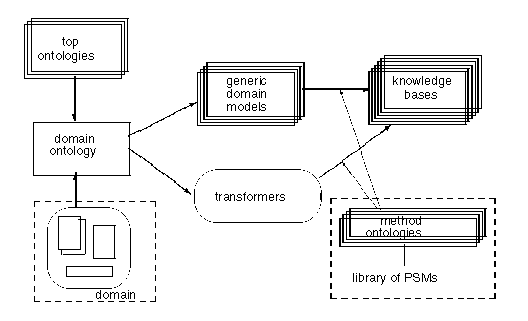 Figure 1:
Dependencies (steps) in constructing knowledge bases for the CoCo
test.
Figure 1:
Dependencies (steps) in constructing knowledge bases for the CoCo
test.
2.1.2 Generating tests
Assessing the interaction hypothesis
This (exhaustive) testing of the PSMs also implies an experiment on the
exhaustive reuse of a domain ontology. However, the expectation
that several, probably many knowledge bases have to be constructed to test
all our PSMs, is the consequence of the famous interaction `hypothesis'
which states that knowledge is geared to its use (Chandrasekaran, 1987).
Although there is no doubt that this interaction between knowledge and
task/method exists, it is not clear to what extent this is true. First
there is the problem of what is meant by `knowledge'. We assume here that
knowledge as specified in an ontology, i.e., the terminology of
a domain, is use-neutral, but also in no way directly usable by a PSM.
By restating the interaction hypothesis that all operational knowledge
is geared to its use, we make it almost trivial and tautological. Therefore,
an operational definition for the interaction effect is that not all knowledge
that can be used in a PSM can be reused in another PSM. That is exactly
what this CoCo experiment is going to find out. Therefore a side
effect of this project is the assessment of the size and nature of the
interaction effect. In KADS the interaction effect was only recognized
late (end 80-ies) and assumed to be of relatively little importance (Wielinga
et al., 1992) talk about the ``limited interaction hypothesis''). It was
assumed that a large part of interaction effects were due to sloppy modeling
and knowledge acquisition which took expert reasoning as its first guideline
and paid no attention to the underlying, reusable domain principles, much
in the spirit of (Clancey, 1985). At the other extreme we may (still?)
find the Generic Task approach, hypothesizing that no reuse should be possible
if the PSMs have nothing in common. In the 90-ies this potential controversy
was not followed up, but it is clear that an assessment of this effect
may have large implications the to be expected revenues of reuse of domain
knowledge for problem solving.
2.2 What is to be observed?
type of problem
generic solution
modelling
separating system from environment
design
structure of elements
planning/reconstruction
sequence of actions
assignment/scheduling/configuration
distribution/assignment of objects or values
prediction
state of system, value of parameter
monitoring
predicted or discrepant states
diagnosis
faulty elements
assessment
class/grade attribution
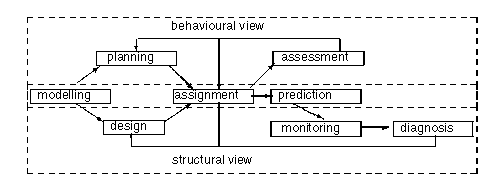 Figure 2:
Dependencies between types of problems: a problem type requires the solution
of its dependent problems. The structural view focuses on the internal
structure of a system; the behavioural view focuses on the interactions
between system(s) and environment.
Figure 2:
Dependencies between types of problems: a problem type requires the solution
of its dependent problems. The structural view focuses on the internal
structure of a system; the behavioural view focuses on the interactions
between system(s) and environment.
Assessing the dynamics by comparing what happens to the intermediary roles
instead of only looking what is left in the last role-slot provides also
an empirical test to the hypotheses that have lead to the construction
of the suite of problem types: that the dependencies within a PSM
follow the suite. It sounds plausible that the testing procedures for selecting
a good and correct design or plan follow the paths that lead to assessment
and/or diagnosis, but we need far more detailed and systematic observations
to support, or reject this hypothesis. A straightforward static comparison
between PSMs is not only obscured by the fact that the terms for roles
and subtasks are common sense and often arbitrary ones, but also because
the PSMs in the literature are presented as decompositions and the dependencies
are only visible in an indirect way. In CoCo we can operationalize
the content of the dependencies by reference to the same domain entities.
2.3 Summarizing the CoCo cycle
In the next section the first steps of the CoCo project are presented:
the specification of a screen windows world by means of an ontology, some
model fragments and some examples of how problems can be specified in this
world. We do not expect to have this world constructed ``right'' from the
start. Therefore we foresee that we better start the testing by try-outs
and explorations in which the actual use may learn us about the behaviours
of this small but virtual world. This ``formative'' way of testing is expressed
in Figure 3 as a cycle.
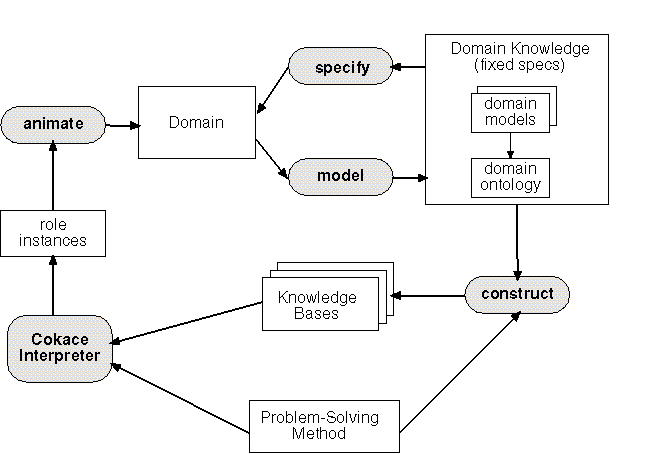 Figure 3:
The CoCo validation cycle of problem solving methods (PSM).
Figure 3:
The CoCo validation cycle of problem solving methods (PSM).
3 The design of a domain
3.1 Clean windows
These requirements fit typical toy domains used in AI like the blocks world.
A disadvantage of the blocks world is that it does not satisfy the first
requirement. The blocks do not exhibit active processes, or we must add
a world of physics that includes gravity, which makes it not very ``lively'':
it is a typical steady state domain. For instance, it is difficult (but
not impossible) to see what kind of ``devices'' can be constructed from
connection blocks (design problems), or how blocks can be defective components.
Therefore, we rather create a virtual blocks world in the machine in which
the blocks themselves can be active elements. Such a blocks-world can easily
be found in the basic notions underlying computer windowing systems. When
we abstract from the content of these windows and their underlying management
systems and exclusively specify what happens on the screen, we have a simple
world of ``two-and-half'' spatial dimensions, where the windows themselves
have processes which can affect their own spatial behaviour and/or that
of other windows. The windows can be programmed as minimal `agents'.
3.2 An ontology for a window world
This section describes the ontology we constructed for the CoCo project
and as an example relates it to one of the problem types to which it should
be mapped. The CML specification is not included for practical reasons;
It specifies nothing that cannot be expressed in the textual description
and we hope to save some trees by omitting meaningless syntax. An overview
of the most important concepts in the windows domain is given by the generalization
tree in Table 2. The subtypes imply disjoint, but not
necessarily exhaustive, membership and the features that differentiate
between these subtypes will all be mentioned in the description.
Any object visible on a screen can be described by its spatial and temporal
extents. An object can be described by the region it occupies in space and
the interval it occupies in time. Three objective measurement scales exist:
the x-axis, y-axis and time. If an object is furthermore part-of another
object, it is inside that object or equal to it in both a spatial and temporal
sense. Composite objects on the screen can be characterized by their cohesion
over time. Cohesion can be axiomatized by the connectedness of devices
in spatial terms. A design may put constraints on both cohesion (layout
topology) and spatial extension (fixed or minimal/maximal extension) of
objects. Cohesion in this sense is a variety of causal connection; If x
and y are connected in this way, moving x might for instance cause y to
move in the same direction and with the same displacement. Since these
views are quite common, this ontology reuses the mereology and topology
definitions of the PHYSSYS ontology
(Borst & Akkermans, 1997) and applies Allens' thirteen primitive relations
between intervals (e.g. Allen and Kautz in (Hobbs & Moore, 1985)) on
both time and space.
individual
- m-individual
- - region
- - - screen
- - - device
- - - - frame
- - - - - window
- - - - component
- - - - - display
- - - - - - fixed-size-display
- - - - - - - icon
- - - - - - - label
- - - - - - variable-size-display
- - - - - - - text-view
- - - - - - - image-view
- - - - - controller
- - - - - - button
- - - - - - - label-button
- - - - - - - icon-button
- - application
- - state
- - event
- - - operation
- - - - open
- - - - close
- - - - resize
- - - - move
- - - - trigger
- - - action
- - - - press
- parameter
- - boundary
- - - x-boundary
- - - y-boundary
- - stimulus
- connection
Layout Layout constraints have thus far been mentioned only indirectly.
The transitive and asymmetric relation inside has already been mentioned
as a layout consequence of a r-proper-part-of relation between two appropriate
regions. A number of other layout relations between regions share this
feature of transitivity: left-of, right-of, above, below, covers, is-covered-by.
The symmetric relations outside and overlaps are not transitive. All layout
relations are subtypes of l-related and some l-relation always applies
to any two regions. L-related is irreflexive. Layout-relations reflect
obvious constraints on the defining boundaries of subject regions. Some
of these constraint definitions are quite complex, like e.g. overlaps,
but their meaning is clear and can be sorted out with a sheet of paper.
proper-part-of (m-individual, m-individual)
- r-proper-part-of (region, region)
- - s-proper-part-of (screen, device)
- - f-proper-partition-of (frame, device)
- a-proper-part-of (application, region)
- p-proper-part-of (process, event)
Topology extensions Although the layout relations can be very helpful
during design, we distinguish between layout relations as a descriptive
aid and connections to actually define coherence between devices. Connections
connect boundaries. Again the meets (m mi) primitive plays a pivotal role.
Table 5 shows the available connections. Connections
mediate causality and are fixed over time. B-connections are asymmetric.
The difference between the values of the connected boundaries remains constant
at {-1,0,1} depending on the type of connection.
l-related {x,y:(= < > s si d di f fi m mi o oi)}
- outside {x,y:(< m mi >)}
- - above {y:(< m)}
- - - above-attached {y:(m)}
- - below {y:(> mi)}
- - - below-attached {y:(mi)}
- - left-of {x:(< m)}
- - - left-attached {x:(m)}
- - right-of {x:(> mi)}
- - - right-attached {x:(mi)}
- inside {x,y:(= s d f)}
- has-inside {x,y:(= si c fi)}
- overlaps {x,y:(o oi)}
- - covers (inv is-covered-by) {x,y:(o oi)}
Assignment example To show how a PSM should exploit this kind of
domain knowledge we create an assignment problem for the layout of a window
design model. The Assignment problem type is characterized by two disjoint
sets of elements, where each element of one set, the demand set, must be
assigned to exactly one element from the other set, the supply set, satisfying
given requirements while not violating given constraints. The assignment
problem type is covered by Sundin (1994) in the CommonKADS Library document.
Assignment is related to parametric design/configuration. The difference
between these two problem types is apparently that in the latter problem
type some trivial redesign can be included, affecting the assignment sets,
and that the supply set can be further carved up into disjoint sets of
possible candidates or hypotheses for each demand element. In order to
cast a problem into the assignment mold we must show how it involves two
disjoint sets and how the solution to the problem is characterized as a
set of relation tuples between elements of the two sets, where each element
of one set necessarily participates in a relation tuple.
connection (parameter, parameter)
- b-connection (boundary, boundary)
- - eq-b-connection (boundary, boundary) (=)
- - m-b-connection (boundary, boundary) (m)
- - mi-b-connection (boundary, boundary) (mi)
- eq-connection (parameter, parameter) (=)
The graphical layout of the window model introduces additional constraints.
The close-icon is always at the top-left of a window and both the title
and close-icon are at the top of the Window. The three parts never overlap.
A good window satisfies at least the following constraints in this ontology:
We have a bag of parameters; the boundaries of the screen, the window,
icon, title and canvas. These thus number 5*4=20 in total. We have two
bags of boundaries (integer values) that can be assigned to these parameters,
value-sets, and we have a number of constraints specifying that the assigned
values to a device or the screen form an actual description of a region,
or x_start =< x_end and y_start =< y_end for all
devices and the screen. Furthermore we have the constraints already summed
up above. Although this problem is very simple, we have already assembled
37 constraints on the values that the parameters can take, not counting
the not overlap constraints. The other constraints already exclude the
possibility of overlap of devices. A requirement may be for instance a
preferred size of the canvas. A graphic representation of the spatial constraints
on the devices of interest is given in Figure 4.
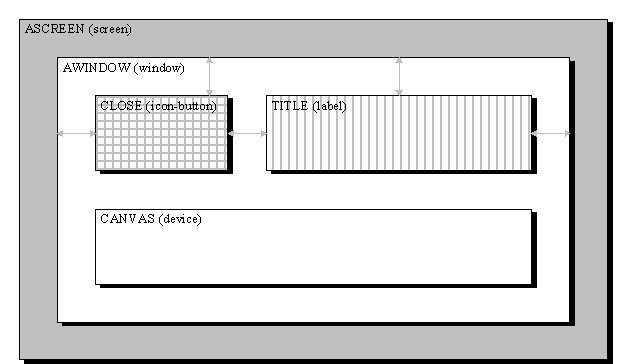 Figure 4: A spatial representation of the imposed order of x-boundaries
and y-boundaries of devices on the screen. Ordering constraints are imaged
by the relative locations of the devices. Fillpatterns show width and height
constraints. The grey arrows denote connection of boundaries.
Figure 4: A spatial representation of the imposed order of x-boundaries
and y-boundaries of devices on the screen. Ordering constraints are imaged
by the relative locations of the devices. Fillpatterns show width and height
constraints. The grey arrows denote connection of boundaries.
An added complication is that the flow of causality between devices should
be derivable from the structural connections between devices. This presents
a special problem to actions on controllers. The flow of causality can
be inferred in part for operations and the known constraints on states
preserving coherence with structure description. We for instance know that
the closing of the parts must accompany the closing of a frame. Similarly,
resizing operations can be ordered in multiple ways to achieve a coherent
layout. The consequences of acting on a controller are not constrained
at all.
operation: close
description: This operation changes the state of a device from open to closed
acts-on: device
initial-state: final-state:
display-status = open display-status = closed
constraints: none
Models
Spread out over this section we have introduced parts of a domain model
of a single window. The window is a device that can be acted upon by an
external system by pressing a close-button that closes the window. The
window can be decomposed into an icon-button, a label and a frame. To complete
the design in order to achieve the desired behaviour a connection topology
has been specified that includes several b-connections between boundaries,
eq-connections between display-status and the eq-connection between stimuli.
The resulting model is an example of a reusable "case" for design case
libraries. After that an assignment problem has to be solved: assigning
numbers to the boundaries and values to parameters in accordance with the
design. The resulting parametrized state suffices to predict the behaviour
of the window, which is quite trivial in this case.
4 Conclusions
The major conclusion that we can draw is that the actual empirical testing
exercises appear only further away than our initial expectations. Instead
of a straightforward empirical cleaning-up operation using Cokace as an
operational environment for CML specifications, we went into theoretical
explorations which made clear that appropriate verification and validation
involves a number of well controlled steps. The first and most important
step involves the use of a well defined, transparent domain that can feed
the PSM with required knowledge. A second step is the definition of problem
situations that form the dynamic inputs to the methods. Because the indexing
of the PSMs requires that their similarities and differences have to be
assessed, the validation also involves a large scale comparative analysis
of the results. In total, the design of the experiment shows that the apparent
straightforwardness of operational validation compared to formal validation
is somewhat misleading as many control activities have to be built in.
One of the questions we have now is whether we can obtain the same results
in a somewhat more efficient way, in particular by reducing the number
of test cases that we have to generate for testing each PSM.
References
Notes
About this document ...
So you want to validate your PSMs?
latex2html -show_section_numbers -split 0 kaw-98-valid-psm.tex.