
Department of Computer Science, Instituto Tecnológico Autónomo de México, Río Hondo 1, 01000-México D.F.
Department of Social Science Informatics (SWI), University of Amsterdam, Roetersstraat 15, 1018-WB Amsterdam, The Netherlands
Abstract:
In the early 1980s, different companies began to commercialize knowledge-based systems (KBS) and knowledge-engineering tools for the construction of KBS and to acquire, verify, validate and sustain knowledge about applications (Hayes-Roth and Jacobstein, 1994). Thousands of KBS have been developed and applied in different knowledge domains. Even though, many of the technologies have changed and allowed the improvement of KBS performance since then, the crucial problem and bottleneck in the development of these applications remains the same: knowledge acquisition (KA). This paper proposes a model-based methodology to attain knowledge acquisition from multiple knowledge sources. The objective of KAMET is to improve, in some sense, the phase of knowledge acquisition and knowledge modeling process making them more efficient.
1. INTRODUCTION
In the early 1980s, different companies began to commercialize KBS and knowledge-engineering tools for their construction and to acquire, verify, validate and sustain application knowledge. Thousands of KBS have been developed and applied world-wide in different areas of knowledge, mainly in finances, manufacturing industries, management, airlines and scheduling, customer services, military design, etc (Hayes-Roth and Jacobstein, 1994). Although, technologies have been perfected; knowledge acquisition remains the crucial problem and bottleneck in the development of these applications.
The problem is clear, although extremely complex. Knowledge used by humans to solve problems must be acquired. However, even if much is known about the neural and biochemical activities of the mind, little is known about memory and thinking. The process whereby humans represent knowledge is not very clear yet (Vámos, 1996). These efforts must undoubtedly involve specialists from different areas, such as psychology, sociology, philosophy and computer science.
A great deal of literature is nowadays published on KA. There are structured methodologies for the construction of KBS, for instance CommonKADS (Schreiber, Akkermans, Anjewierden, de Hoog, Van de Velde and Wielinga, 1997; Schreiber, Wielinga, de Hoog, Akkermans and Van de Velde, 1994), and automatic tools for knowledge acquisition (Batty and Kamel, 1995). There are also many publications related to hypotheses and discussions (Medsker, Tan and Turban, 1995; Forsythe and Buchanan, 1992), different strategies -anthropological (Wooten and Rowley, 1995), psychological (Hoffman, 1987), philosophical (Compton and Jansen, 1990) and cognitive (Moody, Will and Blanton, 1996; Gaines, 1989)-, and guidelines (Wiig, 1994; Scott, Clayton and Gibson, 1991; McGraw and Harrison-Briggs, 1989) to deal with the critical and fundamental problem in the construction of KBS: knowledge acquisition. Few of these publications, however, have focused on formal plans to manage knowledge acquisition and from multiple knowledge sources (Cairó, 1998; Cairó, 1997; Angele, Fensel, Landes, Neubert and Studert, 1993).
This paper addresses this important problem. KAMET is a methodology based on models designed to manage knowledge acquisition from multiple knowledge sources (KS). The method provides a strong mechanism with which to achieve KA in an incremental fashion, and in a cooperative environment. In addition, models are utilized to apply the methodology. These in turn are used as a means of communication between human experts (HE) and knowledge engineers (KE), as tools in reasoning strategies, and for the structuring and description of knowledge independently of its implementation. The models constitute an intermediate point between knowledge acquired from multiple knowledge sources, and knowledge represented in the knowledge base. The complete models represent the knowledge and reasoning of different knowledge sources in a specific area of knowledge. The use of models, as we will show later, leads to well structured and maintainable knowledge bases. KAMET is a modeling methodology. It seeks to be general, although it is mainly directed toward problems of diagnosis.
2. KNOWLEDGE SOURCES
In KAMET, it has been considered appropriate to distinguish among different kinds of knowledge sources. We therefore distinguish between active knowledge sources (AKS) and passive knowledge sources (PKS). HE represent AKS. These experts deal with private type of knowledge, knowledge that manifests itself through experience and abilities acquired over time, thus enabling them to establish a diagnosis with acceptable plausibility, even when working with inaccurate and/or incomplete information. Within AKS, we also perceive dedicated active knowledge sources (DAKS) and consulting active knowledge sources (CAKS). Experts with whom knowledge engineers interact largely represent the formers. These are the HE directly linked to the project. The latter are represented by specialists who contribute to the project by providing ideas, experiences and suggesting alternatives, without being totally devoted to the project. PKS respond to both passive and static definition of knowledge. Passive, in the sense that knowledge belongs to the public domain. This is seen in textbooks, articles and/or any written material. It is likewise static, in the sense that facts are presented in a neutral form; i.e., without analyzing problems that may be solved by means of this knowledge.
3. THE KAMET LIFE-CYCLE MODEL
The KAMET life-cycle model (LCM) provides a framework for managing both the phase of knowledge acquisition from multiple knowledge sources and the knowledge modeling process. The approaches also helps set up and facilitate ways to characterize and organize the knowledge acquired from multiple knowledge sources, implement the required actions, review the project situation, identify risks of not reaching objectives, monitor project progress, and check the control quality project.
3.1. The Main Features of the LCM
The LCM of KAMET is a synthesis of a group of ideas about software engineering, knowledge engineering, artificial intelligence, and experiences in building KBS. It should be emphasized that KAMET was inspired mainly in two main ideas: Boehm�s influential spiral model (Boehm, 1988) and on the essence of the cooperative process. Both ideas are strictly related to the principle of risk-reduction, which is a fundamental part of project management in a KAMET development. The KAMET LCM has a number of interesting features. The most important are described concisely below.
4. THE STAGES OF KAMET
KAMET is a modeling methodology. In fact, we suggest that knowledge acquisition should be undertaken as an explicit modeling activity, rather than an activity of extraction or mining. This removes many of the psychological and practical problems related to knowledge acquisition if seen as extracting something from an expert (Breuker, 1987). It is not a novel idea.
KAMET provides a strong mechanism with which to achieve KA from multiple knowledge sources in an incremental fashion, and in a cooperative environment. The number and type of stages, the input and output for each one of them, the steps that constitute the stages, as well as the activities related to each one of the steps, is the result of a careful research process and later testing. It must also be remembered that stages, steps and activities were defined only as guidance for the project manager (PM). They do not represent an inflexible sequence, which should be followed for all projects.
We are also assuming that a company or a group of fund sponsors have decided to put some effort in a KBS project, as an alternative to solve a current problem or fulfill a current need. We also know: what problem will the organization attempt to solve, what problems do fund sponsors want to support, what needs do both company and fund sponsors try to satisfy. This is the starting point for KAMET be applied.
KAMET consists of four stages: the strategic planning of the project, construction of the initial model, construction of the feedback model, and construction of the final model. Following is a brief description of different stages.
4.1. The Strategic Planning of the Project
The first stage, the strategic planning of the project, is essential for the development of the project. The PM and the four groups involved in the project (KE responsible for KBS implementation, HE who provide knowledge, representatives of potential users (PU), and fund sponsors (FS) who provide funds) must be in total agreement with the definition of the project to assure its success. If the groups are experienced in projects of this nature, strategic planning may turn out to be a simple task. Participants contribute ideas, suggest alternatives and answer the questions asked by the project manager. However, if the groups have only vague ideas of what a KBS is and what it can achieve, defining the project may prove to be a complex task (Scott, Clayton, and Gibson, 1991). In these instances, it might be convenient for the project manager to initially explain the following questions to the participants in a precise way: What is a KBS? How does it work? What does KA consist of? and what are the roles played by the group members in the project? The following are the steps comprised in the first stage:
Define project goals. The goals of the project should be defined in this stage by means of group interviews. Human experts, fund sponsors and potential users may have different perspectives on what KBS can and should do. This may affect and hamper information processing. The PM must coordinate the groups, encourage participants to consider and establish different project goals and, finally, achieve general agreement among the participants. The goals of the project must be defined carefully. Studies carried out by DeMarco (1982) show that many projects fail simply to fulfill original expectations and goals. It is rather the fault of inflated and unreasonable goals.
The project manager must plan each interview correctly and, prior to them, hand the participants a document entitled Meeting Organization containing the points to be dealt with in the specified and described session areas. In each interview, the PM must introduce and present the theme, motivate and persuade the participants to consider the project�s goals; stimulate opinion, knowledge and experience exchange through brainstorming; encourage and guide; and keep the discussion within the foreseen framework. He must also avoid conflicts and hostility among participants; direct them toward the proposed objectives, attain general agreement; and promote and draw conclusions. In addition, during the first sessions where the goals of the projects are to be discussed, it would be convenient for the PM to present a table listing the general goals of a KBS, taking various factors into account (Scott, Clayton, and Gibson, 1991). Participants, on the other hand, should understand the general goals of a KBS. They have the possibility of listening to different proposals from other participants and develop a clearer and more solid perspective on what a KBS must do.
Define project scope and limitations. Once the problem has been rationalized and the goals defined, the project manager must conduct a consistent discussion to define this point. The PM, jointly with KE and HE, must also develop a document -entitled Software Requirements (Sommerville, 1996) to establish scope and limitations for the problem solving space. Requirements must be complete and consistent. Complete, in the sense that all the services required by the user must be considered. Consistent, in the sense that no requirement should contradict others. Nonetheless, in practical terms and for projects of large size and complexity, it is almost impossible to define complete and consistent requirements in the beginnings of a project. Requirements often change during a life cycle of a project. KAMET, according to our experiences in building KBS, has sufficient built-up flexibility to be adjusted to these changes.
Identify potential users. Potential users of the KBS must be identified. Remember that users are not only those who interact directly with the system, but also those who will benefit from its results. In practice, goal definitions, scope, and limitations of a KBS must not be detached from user identification. The acceptance and use of a KBS is what in fact establishes its effectiveness. If users do not perceive a collective benefit when using a KBS, it is likely they will not use it.
Specify potential benefits. The PM, jointly with the members of each group, must specify and emphasize in-group interviews the potential benefits of the project. It encompasses such aspects as improve client�s satisfaction, increased competitiveness, improved quality, more favorable profitability, higher productivity, progress trough better performance, improve the staff�s use, etc. The PM should analyze possible positive impacts the KBS could have when fielded. It is also important to distinguish if the KBS will be installed in a specific organization or in many branches, subsidiaries, workplaces, etc. The benefits can be completely different.
The PM must convey these benefits to the different groups and then obtain their commitment. He must manage for the fund sponsors to commit themselves to the creation of incentives for KBS use. If necessary, they must construct mechanisms or, if not, suppress alternative mechanisms to achieve the critical mass in a short time. Regarding users, he must obtain their commitment to use the tool while observing the collective benefits it provides.
Divide the knowledge domain into sub-domains. The idea behind that is to improve the control knowledge, and as a way to increase the flexibility of control later in the KBS. When a system is larger than tiny, partition it into pieces so that each of the pieces is tiny. Then apply traditional methods to the pieces (DeMarco, 1982). Modularization (dividing into small models) undoubtedly has a cost. However, if correctly made, benefits will outweigh the expenses, complexity will be reduced, resource management and assignation will improve, and parallel work will be encouraged, among other things. In pragmatic terms, there are no specific modularization rules. One interesting alternative is the following: defining independent models, defining limits for the models, identifying subsystems fulfilling a physical function and considering the different dynamics that may be found in the problem. Different methods can be then applied to measure the dependency level among models. The results obtained with these methods allow the establishment of a developmental module order. Scott, Clayton, and Gibson (1991) have also set forth-other modularization criteria. It is also known that there are different lines of artificial intelligence research in which the theory-underlying problem solving in KBS is studied (see for instance, McDermott (1988), Chandrasekaran, Johnson, and Smith (1992), and Clancey (1992)).
Identify the KS that will be involved in the project. The PM and KE cannot begin to work on the project until they have identified the KS that will provide the necessary knowledge for the KBS. The PM needs to identify handbooks, catalogs, textbook or any other written material related to the knowledge area of the application. Additionally, he must investigate if there are databases related to the different work areas. Afterwards the project manager must analyze the written material and evaluate whether it can be used without help. In case of needing it, he must ask the HE group for assistance. On the other hand, and once knowledge is modularized, the PM should select the AKS that will participate in the project. The number of experts and the way the work team will be integrated (a single HE, a succession of human experts, HE groups for task solving, HE in different work areas, or HE groups in different work areas) generally depends on the available resources, application, size and complexity of the project.
Define model verification and validation mechanisms. KE generally verify and validate a KBS by running a group of cases and comparing the results with known data and expert opinions. The success performance percentage is estimated considering the number of right and wrong responses. This percentage strongly depends on the number and kind of selected cases. The goals of the verification and validation activities in the KA phase consist in assessing and measuring the quality of the models. While a model must be totally error-free and reveal perfect behavior, this is something difficult to attain in real life. Validation and verification concepts should not be considered as binary decision variables whereby models are absolutely valid or invalid. Since models are representations or abstractions of reality, we cannot expect perfect performance (O´Keefe, Balci, and Smith, 1987). The level of performance, however, must be clearly stated in this stage.
The methods that can be applied include the following: paired t-test, Hotelling´s one-sample t2 test, simultaneous reliance intervals, and consistency measurements. All of them are quantitative methods. Presential validation, predictive validation, Turing�s test, and subsystem validation can also be applied successfully. All of them are qualitative techniques. Quantitative techniques offer more accuracy during model verification and validations but in most cases require the development of complex mathematical model which may be time-consuming and very expensive. They can be used in critical applications or when the model presents multiple responses. Qualitative techniques, on the other hand, are the techniques generally used in most applications.
Build the dictionary for the project. Before eliciting knowledge from knowledge sources, the PM and KE must understand the concepts required in the area of application, as well as the terminology employed to name or describe these concepts. They must construct the dictionary of the project, with the assistance of the DAKS. The dictionary consists of an indexed on-line list of general terms, concepts and/or vocabulary used by HE in the area of application. Communication among PM, KE and active knowledge sources will undoubtedly be more efficient if the same language, knowledge and/or points of reference about the area of application are shared.
Specify other necessary resources to attain KA. The PM must answer the following questions (Tansley and Hayball, 1993) to determine additional necessary resources for the KA phase. Which materials, staff or resources are needed to attain KA? What kind of abilities does the staff need? Are there financial resources to invest in software, hardware or any unforeseen resource? Which requirements are needed regarding computers, printers, power source, air conditioning and/or heating? What kind of physical space is needed for the project�s development? Are there any environmental restrictions, such as temperature, humidity or magnetic interference? Must there be copies of the documentation in different places? Should any anti-theft or anti-fire measures be adopted? Concerning the staff, the PM must take into account the tasks to be done and the abilities and experience the crew needs to perform its work in an efficient way. It is advisable for individuals to be communicative to share ideas and knowledge, be able to listen, be organized and have good technical knowledge, analytical and logical skills, as well as adequate experience.
Define techniques to attain knowledge elicitation. The PM and KE must consider different techniques to attain knowledge elicitation. Estimating the initial number and type of necessary interviews is a basic requirement for scheduling and establishing the project�s expenses. Registering methods must be analyzed, as well as documents pertaining to the sessions.
Interviews offer distributed or face to face communication and can be conducted on an individual or group basis. The techniques that may be applied are conversational, observational or multidimensional. Conversational techniques are verbal techniques for the expert to remember, ponder and explain his behavior in a given situation. Directed, non-directed and structured interviews, self-examination and tutorial interviews are the most important of this kind. Observational techniques, protocol analysis and observations by the expert may include or not the production of a verbal protocol. The expert finds himself in different situations of real life simulating the solution to the problem. KE observe how HE solve problems. Disadvantages of these techniques are that our eyes have no direct access to all the details involved in a problem solving processes. It is also difficult to report what is going on. Multidimensional techniques are artificial techniques through which information is obtained by non-verbal means. Techniques often compel the expert to think about the domain in a different way from how he usually does. The most important multidimensional techniques include repertory grid, card sorting and matrix generation. Disadvantages of these techniques are that they only generate classifications, and that results are highly dependent on the way the knowledge has been obtained. KE must always resort to a battery of techniques as well as procedures to evaluate their benefits and disadvantages. This is in order to adequately appraised in which cases he must use one of them. Techniques vary in their application, the type of information they yield -verbal or non-verbal- and the type of knowledge they elicit, among other things.
It is also necessary using techniques that will allow KE to document all the information. The notebook and tape recorder are jointly used as the most common technique to register elicited knowledge. Documenting the session, on the other hand, is a basic activity in the knowledge elicitation process. Documentation may be useful in any aspect of the project�s life cycle. Although standards and quality evaluation are essential to produce good documents, the ability of the writer to construct a technically clear and concise text is the most important factor in this sense. Editing systems are the most powerful registering instrument.
Estimation of the time required completing the KA stage. Estimating cost, duration or the effort needed for the whole project or any of its constituent tasks or activities, is undoubtedly a difficult task as it involves envisaging the future on the basis of what one knows about the past. In the first stage, the PM must make the estimate based on his experiences and considering the difficulty and extent of the project. Having completed some of the steps of the second stage, he must then review and refine the original estimates. Generally, once the project starts running, more information is obtained both on the nature of the work being undertaken and on how far the assumptions made during the earlier estimation processes have been correct (Berkeley, de Hoog, and Humphreys, 1990). This is the ideal procedure. However, to be able to do it this way, it must be negotiated and approved by fund sponsors. The PIMS PDCS (Leclerc, 1989) technique may be used to determine this estimate. This perspective focus on the resource aspects of the project in terms of time and resources, which may be assigned to tasks according to, needed skills or characteristics.
Estimation of costs for the project. It is one of the most difficult tasks in project management. Several factors may affect cost estimates. There are also different techniques to make the estimation. However, there are no methods available that are specific for KA projects. Hardware, software and staff are the main factors affecting the cost estimation in project developments. Regarding the way on how to determine it and considering what was above-mentioned, we suggest to apply the following techniques: the expert judgment technique, the DELPHI technique, and COCOMO. The first two are experimental models that rely on the expert�s discernment to make the estimation. The accuracy of the prediction depends on competence, experience, objectivity and perception of the discerning judge. COCOMO, on the other hand, allows time and cost development prediction, scheduling the project and breaking down efforts into parts for each activity. This hybrid method arises from combining experimental and non-lineal static models. The experience of the PM is fundamental for selecting the appropriate technique. The PM can also use case-based reasoning. It will allow him to compare the project to some similar past experiences.
Specify project documentation. Three levels of project managing documentation should be produced during a KAMET development: the project�s plan, stage documents, and model documents. The project�s plan is produced once all the points of the first stage have been defined. It is a document where the formal definition of the project must be explicitly stated. It should not be updated as the project progresses unless necessary, i.e. if it contains errors, inconsistencies, some changes were highly recommended, etc. The elaboration of the documents has two main purposes: allowing the project manager to review the project�s global definition and allowing the different groups to be formally acquainted with its definition. Stage documents are created at the start of the stage, and completed as the stage progresses. In some projects, mainly if the stage documents become too large, it might be useful to keep some information in separated documents. Model documents are created at the start of the modeling activity. They contain information about modeling, and completed as the model is developed. Model documents as well as stage documents must be prepared by KE, and agreed by PM.
4.2. Construction of the Initial Model
In the second stage, KE elicit knowledge from PKS and DAKS and proceed to construct the initial model. An initial model is constituted by one o more models -it will be explained in section five-. This stage involves the largest number of risks, which mainly arise because interviews involve introspection and verbal expression of knowledge, resulting in a difficult task for humans, and especially for experts. On the other hand, if the communication language among project manager, knowledge engineers and human experts is not clear, this may also cause conflicts. The knowledge elicitation in these instances may be monotonous and ineffective. These problems lead to consider a certain degree of inaccuracy in the formulation of the initial model. Because of this, it is advised to ensue the following two stages. Steps comprised in the second stage are the following:
Attain knowledge elicitation from PKS. KE firstly define the plan to be followed and subsequently proceeds to PKS knowledge elicitation. It consists of a four-step process that involves general readings, interviews, interview analysis, and knowledge representation.
Achieve knowledge elicitation from DAKS. KE must develop a plan correctly before proceeding to DAKS knowledge elicitation. The plan undoubtedly depends on the number of experts, the constitution of the work team and the project�s application, size and complexity. It should contain a set of activities to achieve the knowledge elicitation, resources allocated to these activities, dependencies for activities, timetable, etc.
Reassessing the project time. Once the project starts running the PM as well as KE gain more information. Reassessing in the second stage is based on the obtained results, advancement and remnants of the project. This allows the possibility of error to be minimized. Approval by fund sponsors is required to carry out the estimate by increments.
Develop a library of cases. HE depend largely on the memory of experiences to solve new problems. The attainment of a group of cases is of crucial importance to understand task experts perform, as well as for the design, development, verification and validation of models. The library of cases must include prototypical and exceptional cases of the knowledge domain. The former are constituted by those cases which frequently occur and whose solution can be applied -perhaps with some minor modifications- to new situations. The latter represent conflictive cases that share certain characteristics with the prototypical cases and that nonetheless require different treatment because of a special feature. Prototypical and exceptional cases are in turn divided into common, historical and hypothetical cases (Cairó, 1998). The participation of DAKS is essential to develop the library of cases. They must establish the distinctive features of each case and help the KE to classify and select them, in such a way that only the representatives of each category will be included.
Develop the initial model. KE, and agreed by PM must construct the initial model, one for each working area or knowledge sub-domain. The modeling activity consists first of the analysis and synthesis of concepts belonging to a specific area of knowledge, and then of its representation in a conceptual model (see section five).
Verification and validation of the initial model. The purpose behind verifying and validating in the second stage consists in assessing and improving the quality of the initial model, by applying the aforementioned methods. It should be noted that the model expresses a representation or abstraction of reality and thus verification and validation must be undertaken according to the previously defined range of performance.
Revision and documentation of the initial model. The PM and KE must show the DAKS that the initial model conveys the knowledge and reasoning used by HE for task and/or problem solving in the knowledge domain of the application. They must clearly explain how the employed representation works. The initial model might correctly represent knowledge, even if this representation differs from the HE internal organization. The project manager and knowledge engineers must also complete the stage and model documentation.
Lastly, it should be emphasized that if only one HE or a group of experts working in succession constitutes the working team of experts, the knowledge acquisition phase concludes at this stage.
4.3. Development of the Feedback Model
The opinion of consulting active knowledge sources is obtained in the third stage. The KE distributes the initial model among the CAKS for its analysis, and ideas, experiences or perspectives are exchanged about it. Finally, the PM, KE, jointly with the DAKS, reviews and analyzes the changes introduced to the initial model and constructs the feedback model. The inaccuracy of the model at the end of the stage must be less, since the model now expresses the knowledge of several specialists in the knowledge domain of the application. It must be remembered that the feedback model is only a refined and better initial model. Following are the steps that constitute the third stage:
Distribute the initial or feedback model among CAKS. The KE must distribute the initial model among the CAKS for its analysis. KE must also develop and hand the CAKS a document where the theme is introduced and discussed, explaining the employed knowledge representation; encouraging opinion, knowledge and experience exchange among experts, guiding them through the work they must carry out, and directing them to the proposed goals. It is important for the CAKS to correctly understand the employed representation and be motivated to analyze and criticize it. It is most useful if experts indicate that the representation is exact, complete or consistent, if it adequately solves the problem, if it is acceptable although it contains mistakes, if there are cases that have not been considered, etc. The distribution of the model takes place in two moments, and in both instances non-verbal techniques are used to get the experts� opinions. The initial model is first distributed, and then the feedback model.
Analysis by the CAKS of the initial or feedback model. Based on their knowledge and experience, CAKS analyze models. In the first round, with the aid of the DELPHI technique experts give their opinions, express their ideas, and solve problems about the initial model writing mainly anonymous answers -if they so wish- to questionnaires prepared by KE and agreed by PM. The format for the ideal solution (Larson, 1969) and Maier�s format (Maier, 1963) are the proposed techniques in the second round to evaluate alternative solutions in search for the most effective and closest ones to the ideal solution. Larson's technique is suitable in search for the ideal solution. This is useful when there are different alternative solutions in an attempt to reach the ideal one or the closest to it. Maier's technique is adequate to evaluate two or more opposing ideas. The technique is very detailed and allows polarization to be diminished.
Develop the feedback model. KE and agreed by PM must develop the feedback model, one for each working area or knowledge sub-domain, integrating the knowledge from the different CAKS who collaborated in different degrees and ways to attain the solution for the problem.
Verification and validation of the feedback model. The purpose of verification and validation in this stage consists in assessing and improving the quality of the feedback model applying the aforementioned methods.
Revision and documentation of the feedback model. The PM must show to the different groups that the feedback model expresses the knowledge acquired from multiple knowledge sources in the domain knowledge. He must clearly explain how the developed model works. The PM must first introduce and present the feedback model and afterwards encourage, persuade and influence the participants to criticize it, through the exchange of opinions, knowledge and experiences. The PM and KE must also complete the stage and model documentation.
4.4. Construction of the Final Model
In the last stage, active knowledge sources participate in a series of interviews, under the coordination of the PM, to develop the final model. The stage is considered to be over when the model satisfies the proposed objectives with a high degree of plausibility and/or there are no AKS capable of further transforming it. Inaccuracy at the end of the stage must be minimal, since the model now expresses the knowledge acquired from multiple knowledge sources, and of course from multiple human experts who collaborated in different degrees and ways to solve the problem. Remember that the final model is only an improve version of the feedback model. Following are the steps that constitute the fourth stage:
Analysis of the model by the AKS. The PM and KE must explain the behavior of the developed model to the AKS participating in the group interview. Exchange of ideas and opinions must be achieved, while heeding to the proposed recommendations to ultimately develop a solid and strong model that will conform to the proposed goals with a high degree of plausibility. Group interviews in the last stage are especially important. The PM and KE must attain the general consent of the AKS on the behavior of the constructed model. It is highly advisable for the PM to plan each session correctly and follow an agenda (agenda standard or the nominal group technique) for its development. Electronic meeting system can also be employed if the necessary resources are available.
Develop the final model. KE, and agreed by PM must construct the final model. They must integrate the knowledge obtained from multiple knowledge sources, and of course, from multiple HE who collaborated in different ways and degrees to achieve the solution to the problems. The process of developing the final model concludes when it expresses the knowledge and reasoning acquired from multiple KS with a high degree of plausibility and/or there are no AKS capable of further transforming it. A maximum amount of time must also be established for the construction of the final model. We do suggest that the analysis of the first two steps be cyclic to allow successive refinement.
Verification and validation of the final model. The goal of this process is assess and improve the quality of the final model applying the previously mentioned methods. The final method expresses a representation or abstraction of reality and therefore verification and validation must be carried out according to the defined quality standards.
Revision and documentation of the final model. The PM and KE must explain the participants of the different groups how the employed representation operates, without confounding them. The final model might correctly represent knowledge, even if it partially differs from the internal organization some HE may have. The PM and KE must firstly introduce and present the final model and afterwards encourage the AKS to criticize the model through opinion, knowledge and experience exchange. The PM and KE must also complete the stage and model documentation.
5. KNOWLEDGE-MODEL CONSTRUCTION IN KAMET
In the last decade, KA has been recognized as a critical stage in the construction of KBS, and as a bottleneck for their development. Although the last years have seen a rapid growth in capabilities in building KBS, knowledge acquisition remains the same. KA still constitutes the main factor that hamper a well controlled KBS life cycle. Nonetheless, some considerations related to knowledge acquisition have changed since then. First, as Breuker and Wielinga (1989) early state, problems in eliciting knowledge do not constitute the true bottleneck, for the simple reason that we would not know how to represent the implicit, detailed knowledge of a HE. The process whereby humans represent knowledge is not very clear yet (Vámos, 1996). Second, the knowledge obtained from multiple knowledge sources is in general extensive, inaccurate, incomplete, and qualitative and not systematically ordered, so those major problems of interpretation arise (Breuker and Wielinga, 1989). Third, the transfer of knowledge directly from the different KS to artificial machines is less organized, less reliable, less comprehensible, and less effective than when it is represented in models in an intermediate manner. The knowledge is too rich to be transferred automatically from different knowledge sources to artificial machines. Therefore, the main problem appears to be due to a lack of methods for knowledge modeling, tools to cope with this methods, and conceptions about how we could analyze this knowledge.
In KAMET, a model should be built for every common work area or knowledge sub-domain. We suggest reflecting on several points before explaining the knowledge modeling method:
The proposed method takes into account the previously above-mentioned points and attempts to provide the necessary elements for KE to build good models. The results, nonetheless, will depend to a great degree on the good judgment of knowledge engineers, as well as on the logical, psychological and epistemological considerations that they make at the right time. It should also be remembered that KAMET seeks to be general, although it is mainly directed toward problems of diagnosis. The knowledge modeling method, on the other hand, focuses on domain knowledge.
5.1. The KAMET CML Assumptions
The KAMET Conceptual Modeling Language (CML) is presented after a discussion of what the potential problems are in KA. We consider that pure rule representation as well as an object-modeling language, data dictionaries, entity-relationship diagrams, among other methods; are considered no longer sufficient neither for the purpose of system construction nor for that of knowledge representation. We believe that knowledge is to rich to be represented with the above-mentioned methods. This requires stronger modeling facilities. A knowledge modeling method should provide a rich vocabulary in which the expertise can be expressed in an appropriated way. Knowledge and reasoning should be modeled in such a way that models can be exploited in a very flexible fashion.
The KAMET CML has three levels of abstraction. The first one corresponds to structural constructors and structural components. The structural constructors are used primarily to highlight the problem itself. Within structural constructors, we considered convenient to distinguish among problem, classification and subdivision structural constructors (figure 1).
FIGURE 1. Structural constructors.
The structural components (figure 2) are used to establish the characteristics and possible solutions of the problem.
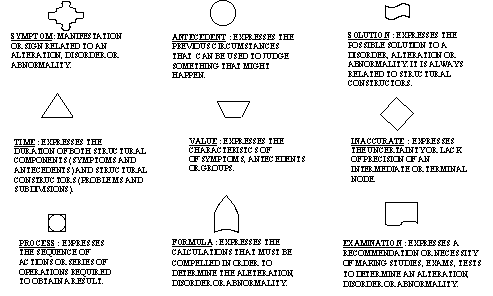
FIGURE 2. Structural components.
The second level of abstraction corresponds to nodes and composition rules. Digraphs represent the model. The most important elements of a digraph are its nodes and arcs. We changed a little bit this notations. We introduced the terminology node (N) instead of vertices, and the expression composition rules (C) instead of arcs. Structural constructors and structural components form the nodes. We distinguish among different kinds of nodes: initial, intermediate and terminal. Composition rules (figure 3), for their part, are the ones that permit the adequate combination of the structural constructors and components.

FIGURE 3. Composition rules.
The third level of abstraction corresponds to the global model. It consists of at least one initial node, any number of intermediate nodes, and one or more terminal nodes. A global model should represent the knowledge acquired from multiple knowledge sources in a specific knowledge domain.
5.2. Formalization: Diagrammatic Conventions and Postulates
Diagrammatic conventions. Following are the diagrammatic conventions of the method.
![]()
FIGURE 4. Names of structural constructors and structural components.
(a) symptom: 1; (b) antecedent: 3; and (c) inaccurate: low risk.
![]()
FIGURE 5. Indicators.
(a) indicator: n; (b) indicator: n+; and (c) indicator: n,m.
![]()
FIGURE 6. Groups.
(a) group; (b) group with indicator n; and (c) recursive group.
![]()
FIGURE 7. Chains.
(a) two antecedents and one symptom concatenated; (b) one symptom, one group, two antecedents and one group concatenated; and (c) one symptom, one antecedent and two groups concatenated.

FIGURE 8. Names assignation.
(a) assigning a name to a node; and (b) using a node with a name assigned to it.
Postulates. Following are the method�s postulates.
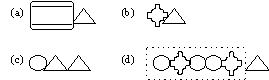
FIGURE 9. Assigning the structural component time.
(a) a problem with time; (b) a symptom with time; (c) an antecedent with two times; and (d) a group with time.

FIGURE 10. Assigning the structural component value.
(a) an antecedent with a value; (b) a symptom with values 2 and 7; (c) a group with values 2 and 7 and the indicator that only one of them should be present; and (d) a group with a recursive value.
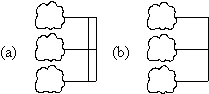
FIGURE 11. Molecular nodes.
(a) conjunctions; and (b) disjunctions.
5.3. Simple Examples of Modeling
In this section we will provide two very simple examples of modeling in order to illustrate the method sketched in the previous section. The first one concerns diagnosing faults in electricity (figure 12). The model expresses that the problem P1 can occur due to two different situations. In the first one, the model expresses that if the symptoms 1 and 2 are known to be true then we can deduce the problem P1 is true with probability 0.7. In the second one, the model shows that if symptoms 1 and 5 are observed then we can conclude that the problem is P1 with probability 0.60. On the other hand, we can deduce that the problem P3 is true with probability 0.40 if symptoms 1 and 4 are known to be true. Finally, we can reach a conclusion that the problem is P2 with probability 0.90 if problems P1 and P3 and the symptom 3 are observed.
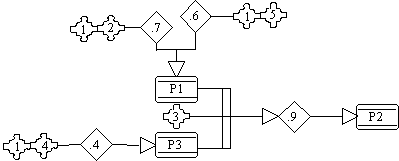
FIGURE 12. Simple electrical diagnosis.
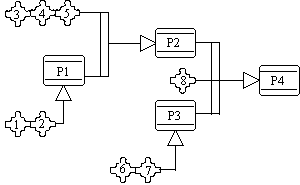
FIGURE 13. Diagnosing car's faults.
In figure 13, we can observe another example of modeling. It corresponds to diagnosing car's faults. The model expresses that the problem P1 is true if symptoms 1 and 2 are observed. On the other hand, we can deduce that the problem is P2 if symptoms 3, 4 and 5 together with problem P1 are known to be true. Problem P3 can occur if symptoms 6 and 7 are observed. Finally, we can conclude that the problem is P4 if problems P2 and P3 and the symptom 3 are detected.
6. CONCLUDING REMARKS
In this paper, we presented a knowledge acquisition methodology from multiple knowledge sources. The main goal of KAMET is to improve, in some sense, the phase of knowledge acquisition and knowledge modeling process making them more efficient. There are two fundamental ideas in KAMET. The first one is associated with the knowledge acquisition process itself. The second one is strongly related to the knowledge modeling method.
The methodology is still undergoing revisions, in particular because of investigating a more appropriated way for monitoring project progress. The KAMET CML is also subject to some changes. However, the major features of KAMET appear to be stable to enable such an assessment.
KAMET is integrated with up-to-date literature, and seeks to be general, although it is mainly directed toward problems of diagnosis. We believe that the use by, and feedback from, the researchers working in this area, will generate ideas, points of view and opinions, which will allow us to discern the proposal�s strong and weak points. The results of the exploration will become visible in the future.
ACKNOWLEDGMENTS
I am grateful to all my colleagues for their contributions to the KAMET methodology and their constructive criticism, which lead to the sharpening of my thinking. In particular, I would like to thank Robert de Hoog, Bob Wielinga and Guus Schreiber from University of Amsterdam who provided valuable comments on an earlier version of this paper.
REFERENCES
Angele, J., Fensel, D.; Landes, D.; Neubert, S. and Studer, R. (1993). Model-Based and Incremental Knowledge Engineering: The MIKE Approach. In J.Cuena (ed.), Proceedings of the IFIP TC12 Workshop on Artificial Intelligence from the Information Processing Perspective. Elsevier, Amsterdam.
Batty, D. & Kamel, M. (1995). Automatic Knowledge Acquisition: A Propositional Approach to Representing Expertise as an Alternative to Repertory Grid Technique. IEEE Transactions on Knowledge and Data Engineering, 7 (1), 53-67.
Berkeley, D.; de Hoog, R. and Humphreys, P. (1990). Software Development Project Management. Ellis Horwood Books in Information Technology.
Boehm, B. (1988). A spiral model of software development and enhancement. IEEE Computers, pp. 61-72.
Breuker, J. and Wielinga, B. (1989). Models of Expertise in Knowledge Acquisition. G. Guida and C. Tasso (eds). Topics in Expert Systems Design: methodologies and tools. North Holland Publishing Company, Amsterdam, The Netherlands.
Breuker, J. (1987). Model Driven Knowledge Acquisition: Interpretation Models. In Breuker (eds). Deliverable A1, Esprit Project 1098, memo 87, VF Project Knowledge Acquisition in Formal Domains. University of Amsterdam, The Netherlands.
Cairó, O. (1998). KAMET: A Comprehensive Methodology for Knowledge Acquisition from Multiple Knowledge Sources. Expert Systems with Applications (forthcoming).
Cairó, O. (1997). The KAMET Methodology: A Modeling Approach for Knowledge Acquisition. In Smith and Niku-Lari (Eds) Technology Transfer Series, UK.
Cairó, O., Guardati, S. and Boom, T. (1994). A formal methodology for acquiring and representing knowledge from multiple experts. In: Proc. of the Sixth International Conference on Software Engineering and Knowledge Engineering. Published by Knowledge System Institute, pp281-288, Jurrmala, Latvia.
Chandrasekaran, B., Johnson, T. and Smith, J. (1992). Task-structure analysis for knowledge modeling. Communications of the ACM, 35(9), 124-137.
Clancey, W. (1992). Model construction operators. Artificial Intelligence, 53(1).
Compton, P. and Jansen, R. (1990). A philosophical basis for knowledge acquisition. Knowledge Acquisition, 2, 241-257.
DeMarco, T. (1982). Controlling Software Projects. Yourdon Press.
Forsythe, D. and Buchanan, B. (1992). Nontechnical problems in knowledge engineering: Implications for project management. Expert System with Applications, 5, 203-212.
Gaines, B. (1989). Social and cognitive processes in knowledge acquisition. Knowledge Acquisition, 1, 39-58.
Hayes-Roth, F. and Jacobstein, N. (1994). The State of Knowledge-Based Systems. Communications of the ACM, 37 (3), 27-39.
Hoffman, R. (1987). The problem of extracting the knowledge of experts from the perspective of experimental psychology. AI Magazine, 8 (2), 53-67.
Larson, C. (1969). Forms of analysis and small group problem solving. Speech Monographs 36.
Leclerc, A. (1989). PIMS status conceptual schema presentation. Doc. CSI-T21-SP, PIMS Consortium, Grenoble.
Maier, N. (1963). Problem-solving discussion and conferences. McGraw-Hill.
McDermott, J. (1988). Preliminary Steps toward Taxonomy of Problem-Solving Methods.In Marcus, S., editor. Automating Knowledge Acquisition for Expert Systems, 225-255. Boston, Kluwer.
McGraw, K. and Harrison-Briggs, K. (1989). Knowledge Acquisition: Principles and Guidelines. Prentice-Hall International.
Medsker, Y., Tan, M. and Turban, E. (1995). Knowledge acquisition from multiple experts: problems and issues. Expert Systems With Applications, 9 (1), 35-40.
Moody, J., Will, R. and Blanton, J. (1996). Enhancing knowledge elicitation using the cognitive interview. Expert Systems With Applications, 10 (1), 127-133.
O´Keefe, R., Balci, O. and Smith, E. (1987). Validating Expert System Performance. IEEE Expert, 2 (4), pp. 81-90, winter 87.
Schreiber, A., Akkermans, H., Anjewierden, A., de Hoog, R., Van de Velde, W. and Wielinga, B. (1997). Engineering of Knowledge: The CommnoKADS Methodology. University of Amsterdam. Version 0.3.
Schreiber, G., Wielinga, B., de Hoog, R., Akkermans, H. and Van de Velde, W. (1994). CommonKADS: A Comprehensive Methodology for KBS Development. IEEE Expert, 9 (6), pp. 28-37.
Scott, A., Clayton, J. and Gibson, E. (1991). A practical guides to knowledge acquisition. Addison Wesley.
Sibelius, P. (1993). Information condensation in conceptual modeling. Information modeling and knowledge bases IV. IOS Press.
Sommerville, I. (1996). Software Engineering. Addison-Wesley Publishing Company.
Tansley, D. and Hayball, C. (1993). Knowledge-based systems analysis and design. Prentice Hall.
Vámos, T. (1996). Expert Systems and the Ontology of Knowledge Representation. In Lee, J.; Liebowitz, J. & Chae, Y.(Eds). Critical Technology, Cognizant Communication Corporation, pp3-12.
Wiig, K. (1994). Knowledge Management. Schema Press, Ltd.
Wooten, T. and Rowley, T. (1995). Using anthropological strategies to enhance knowledge acquisition. Expert Systems With Applications, 9 (4), 469-482.