1 Context: Sisyphus-III
The goal of the third Sisyphus project Rocky-III is to compare knowledge engineering methodologies and techniques in terms of effectiveness, efficiency and scalability. Participants are provided with knowledge acquisition material in three phases and are required to keep a log of their activities.
In the first phase, participants are invited to build a system that must be able to classify sixteen types of igneous rock. The system should also function as a tutorial aid in this field. Knowledge acquisition material will be released in stages. The first release includes a detailed problem specification together with a first set of acquisition material which is common to all participants. In future releases participants will be free to select some or all of the KA material offered.
A second release of material will be available together with an announced expansion of the problem set to be solved. Finally, a third stage will announce a significant extension to the functionality of the system that should be incorporated if possible.
This is largely a quote from the Sisyphus-III documentation.
2 Approach and Scope
This paper constitutes a progress report on the work done by the authors in Phase 1. Our work on phase 1 effectively started on June 1. The work is part of the PhD project of the first author, The central research question in his work is as follows:
- Can we prove that additional work on ontology construction in the early phases of a project, pays off in later phases?
- The pay-off can be of different types, e.g.shorter development and/or maintenance time, higher quality and/or reliability.
This research question fits well with the overall Sisyphus-III aims.
Operationalizing this question in terms of Sisyphus-II implies
that we intended to spend more time in Phase 1 on ontology development,
but that we expect that this extra work will pay off in phase 2 and 3.
The work at UvA will be somewhat biased towards the ontological
aspects of the problem domain.
Our practical goals in the first three months (the period on which we
report here) have been twofold:
- To develop a demonstrator application for rock classification that meets the aims of phase 1.
- To develop a number of ontologies more or less independent of the demonstrator.
The basic idea is that in developing the ontologies we do not want to
be biased too much by the current system. Of course, parts of the
ontologies are used in the demonstrator, but actual ontology usage was
not a conditio sine qua non for ontology development. The scope
of the ontologies in Sec. 4 is therefore broader than
the domain knowledge used by the demonstrator described in
Sec. 6.
The overall knowledge engineering approach used is CommonKADS as it is
documented in the draft textbook about this approach (Schreiber et al, 1997).
This paper is structured as follows. First, we provide data about the
knowledge engineering process, in particular on the activities
performed, the knowledge-acquisition material used, and the time
spent. The three following sections describe the actual work done. In
Sec. 4 we discuss the different ontologies we
developed. Sec. 5 describes the method for classification
that we used. It turned out we could use a simple pruning method, but
that we had to employ that method in a recursive
way. Sec. 6 shows fragments of the demonstrator
application. In the final section we discuss a number of issues that
came up during this work.
3 Data about the Knowledge Engineering Process
In this section we present an overview of the activities conducted in the context of the Sisyphus project. Time is measured in days as if performed by one person. Work on the Sisyphus project was done by one person most of the time. Building the ontologies and discussing them involved two or three people. All persons were also engaged in other activities not related to the Sisyphus project.
Domain familiarization
A first preliminary study of the domain was started in June 1997. This consisted of studying the KA material provided by the Sisyphus team and examining works like Schumann (1992). The other domain texts mentioned at the Internet site of Sisyphus and the material from the Open University could not be obtained.Building ontologies
Instead, the Internet was used as an information source and Raymond (1995) and McKenzie (1995) were consulted. The information found on the Internet was often helpful but incomplete. We did not find any ontologies or software which could be helpful in the classification of rocks. We did however stumble upon a program called MINID (Reeves, 1986), a DOS-program which assists in the identification of minerals in thin sections. We used this program as the basis for the thin sections program in the demonstrator.
Having no previous experience in the field of petrology the investigation into the domain of igneous rocks and minerals took the largest amount of time. The study was conducted by one person and took a total of 12 days of full time work.
An ontology of rocks was built based on the information present in Schumann (1992). This book describes the classification of igneous rock according to the diamond-shaped Streckeisen-diagram. This diagram was not easy to describe in common ontology-representational formalisms. The inclusion of graphical representations in ontologies is a point worth discussing in more depth.Discussing ontologies
The mineral ontology could be compiled from various sources. The mineral descriptions were well described in Raymond (1995) and could be gathered from the MINID program and a good introduction of investigating minerals in thin section was given by MacKenzie (1995).
The texture ontology was compiled within half a day and based on information found at the Internet site of the University of British Columbia . Later, corrections were made based on Raymond (1995).
The ontologies were built by two persons and together took about 10 days of full-time work.
The ontologies were discussed on a regular basis. Since the rock, mineral and texture ontologies were quite straightforward, discussions centered on the construction of the classification ontology. The appropriate representation of the diamond-shaped Streckeisen-diagram was also discussed. Discussions were mainly among the three authors of this paper and taken together took 7 days.Classification methods survey
A brief survey of classification methods was conducted. At this stage both Stefik (1995) and Wielinga (1997) proved to be very helpful. A simple prototype program for apple classification implementing the pruning method was built in order to explore this method in more detail. Some alternatives for the attribute selection step were studied, using also ideas from machine-learning algorithms. This activity took 6 days.Building the demo-system
The demonstrator described in Sec. 6 was built in 7 days by one person. The thin section part of the program was based on the MINID program. The attributes and values of this program were used and a running prototype with graphical user-interface was written within a day. Part of the program-code of the demonstrator was also used in classification of other domains.
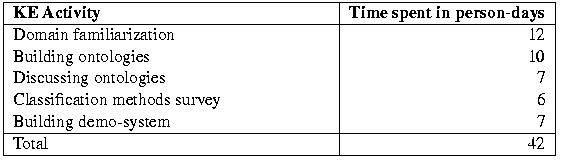
TABLE 1: summarizes the time spent on the five knowledge-engineering activities performed.
3.1 Knowledge acquisition material
The analysis of the knowledge acquisition material was brief after it was discovered that information in the interviews was often incorrect or unreliable. An example from the first laddered grid from the Sisyphus material will illustrate this:
... these are sort of metamorphic ones which you're going to get a large grains in a fine-grained sort of matrix thing.
This is quite misleading. What the "expert" is referring to is a so-called porphyritic texture in which you find larger grains scattered in a matrix of finer grains. This texture is common in many igneous rocks and in this context has nothing to do with metamorphic processes.
The question therefore arises in what cases to use material acquired with the help of knowledge acquisition (KA) techniques and when not. Generally KA methods are a good source of information if one is after the cognitive aspects of expert reasoning. In complex domains where problems are often computational intractable KA methods are a good way of discovering heuristics.
To gather information about domains where the need for heuristic methods is not immediately apparent, the use of KA methods in the initial stage (such as in phase 1 of Sisyphus) is doubtful. The material provided by laddered grids and think-aloud protocols is not well-suited to act as as a first guide to a domain.
There are two additional points to be made here: Firstly, it is hard to interpret the correctness of the information provided by the expert if the Knowledge Engineer (KE) has no or little knowledge of the domain. Experts may make mistakes, or give false information. Mistakes of course can be very helpful in discovering heuristics or cognitive modeling. In order to make a useful interpretation of the KA material one already needs some understanding of the domain.
Secondly, experts may try to make clear to the Knowledge Engineer information that is well-documented elsewhere. For example it does not make much sense to interview an expert chess-player if one is after the rules of the game. If however one chooses to do so one has to rely heavily on the verbal capabilities of the expert. In case of misinterpretations or omissions one might end up with the wrong set of rules. In this case it is far more efficient to read an introductory book on chess and try to play the game self first. This seems to be true for all knowledge which is objective and well-documented.
For the domain of igneous rocks similar remarks can be made. The science of rocks (petrology) is well-developed and inspection of the knowledge-acquisition material shows that experts at least try to classify rocks according to known classification schemes. In addition the KA material contains quite a few contradictions and errors. In order to get a good grasp of the domain of rock classification it seems more helpful to read additional introductory material on the subject of petrology than to dive into grids and protocols. Raymond (1995) offers a systematic introduction to this field and was used to acquire an understanding of the domain. Much of the information on the rocks themselves was derived from the Dutch edition of Schumann (1992).
3.2 A note about missing rocks
The rock adamellite was mentioned in neither Raymond (1995), Schumann (1992) nor MacKenzie (1995). A clear description could not be constructed from the official Sisyphus knowledge acquisition material either. Consulting some other books on igneous rocks finally resulted into an exact description.
The rock Kentallenite could not be found in textbooks or on the Internet. This rock also puzzled some experts as a quote from the first laddered grid of the Sisyphus material shows:
Ke... (Kentallenite) I can't even say the word, I've never heard of that one
A post on the newsgroup sci.geo.geology finally resulted in this quotation taken from .
"...a dark monzonite composed of approximately equal amounts of augite, olivine, orthoclase and plagioclase, with biotite, apatite and opaque oxides"
This definition however is not in line with the official UIGS classification method and can therefore not be classified with the help of our demonstrator. As there are several classification schemes in use for identifying igneous rocks by geologists, there are several rock-names which are meaningful only to a few.
4 Ontologies
We describe several ontologies for this application domain. These ontologies can be seen as belonging to two categories of ontologies:Application-domain ontologies
These ontologies abstract as much as possible of the task, and are aimed at representing the static structure of a domain. In the case of igneous rocks, we expect to find descriptions of rocks and their elements.Application-task ontologies
Domain-specific ontologies, such as a rocks ontology, can also be generalized to higher-level conceptualizations, such as an ontology about object types: e.g. natural inorganic objects. We have not done any work on such ontologies yet within this context: Instead we have concentrated on the domain-specific ontologies that stood out as useful schematic descriptions.
A second category of ontologies describe the way in which we conceptualize the world from the functional perspective, i.e. the task we want to perform. In a publication about the previous Sisyphus project ,(Schreiber & Terpstra, 1996) we argued that it is useful to distinguish between at least two types of ontology within this category:
Task-specific ontology is an ontology which captures the knowledge structure always encountered with a certain type of task. The ontology developed for the VT domain by Gruber et al. (1996) can be seen as an example of such an ontology for the configuration task.
Method-specific ontology is an ontology that contains precisely those knowledge types needed for a certain problem-solving method to work. Often, such a method-specific ontology can be represented as having a task-specific ontology as its core part to which a number of method-specific extensions are added. It can be shown that this enables knowledge-base reuse (Rothenfluh et al.,1996; Schreiber & Terpstra, 1996).
In the Rocky domain we have concentrated on the task-specific ontology for classification.
This separation between domain and task ontologies lies at the heart of the PROTEGE-II approach (Tu et al. 1995). We follow their view that the ontology of a particular application is in fact an amalgamation of ontologies from both categories, and that it is wise to keep these ontologies explicitly separate by generating an application ontology from explicit mapping relations between the ontologies (Gennari et al,. 1994).
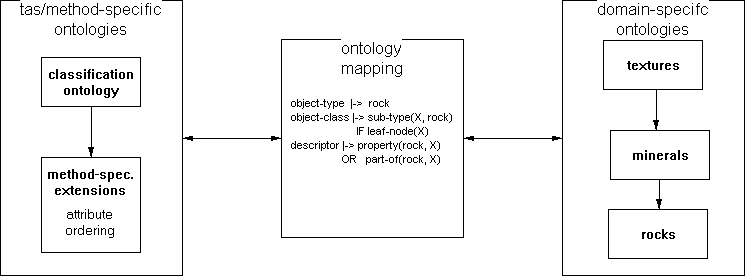
FIGURE 1: Overview of the ontologies developed in the context of phase 1.
Fig. 1 gives a graphical overview of the types of ontologies involved in this study. In this section we give a brief description of the domain-specific and the task-method-specific ontologies (the ontologies in the boxes on the left and the right). We briefly mention the issues involved in the ontology mappings (the central box in Fig. 1 ), but this is really a subject we have not tackled yet for this application.
4.1 Domain-specific ontologies
Rocks This ontology contains a sub-type hierarchy of rock types. rocks shows fragments of this hierarchy. Each rock is characterized through number of properties (e.g. texture, grain-size and colour). A rock can have a mineral-content relation with a mineral. This relation is reified into a concept (*) (the dotted line starting from the solid relation line in rocks) and can be used to represent information about mineral-content percentages. The mineral-content-constraint is an example of the use of a special CommonKADS modelling construct rule-schema. It denotes a set of expressions about one or more other constructs, in this case about mineral-content. These constraints provide us with a way of describing the Streckeisen-diagram. For example, the instances of mineral-content-constraints for the rock syenite are represented as follows:
mineral-content(syenite, alkali-feldspar).percentage >= 65; mineral-content(syenite, plagioclase).percentage =< 35; mineral-content(syenite, quartz).percentage =< 20; mineral-content(syenite, foids).percentage =< 10;
(*) Relation reification is a powerful modelling construct in modern data-modelling. See for example the association-class construct in OMT (Rumbaugh et al., 1991).
These expressions are a textual representation of the knowledge about mineral percentages in syenite represented in the Streckeisen diagram. Minerals are described in a separate ontology which is imported into the rocks ontology.
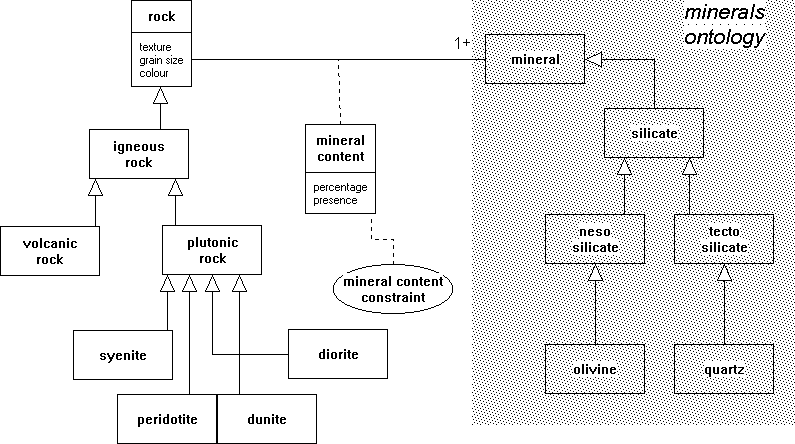
FIGURE 2: Graphical overview of the rocks ontology. Arrows with open heads are used to denote a subsumption relation. Only a few sub-classes of rock are shown in the figure. The ontology uses the "minerals" ontology. A key concept is mineral-content. This can be used to indicate the amounts of minerals present in a certain rock. The mineral-content-constraint is an example of the use of a special CommonKADS modelling construct RULE-SCHEMA. It denotes a set of expressions about one or more other constructs, in this case about mineral-content. These constraints provide us with a way of describing the Streckeisen-diagram
Minerals This ontology describes the minerals that may be present in igneous rocks. The attributes of the mineral classes are those attributes that can be used to identify a mineral (within a thin section of an igneous rock) under a microscope. In addition, the crystal structure and the chemical formula are also listed.
Textures In the texture ontology all features of a rock that are related to the texture of rocks are described in a hierarchic fashion. This includes grain-sizes, grain-types, crystal shapes and habits, fabrics and textures. From this ontology one can completely describe a rock in textural terms. A graphical overview of the texture ontology is shown in Fig. 3. The leafs of this tree serve as values for their parent-nodes.
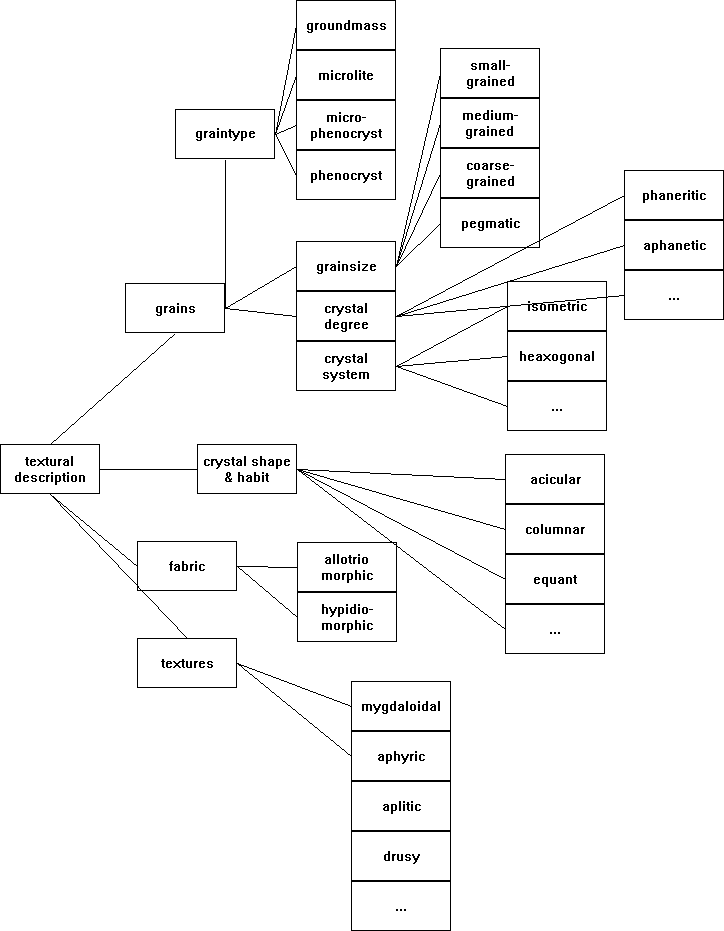
FIGURE 3: A graphical (incomplete) overview of the texture ontology. The boxes marked with '...' refer to more leaf-classes than there are shown here
4.2 Task/method-specific ontologies
An ontology for classification tasks We have constructed an ontology for classification tasks, A graphical overview of the ontology is shown in Fig 4. This ontology has the status of a proposal and will typically be subject of discussion and revision.
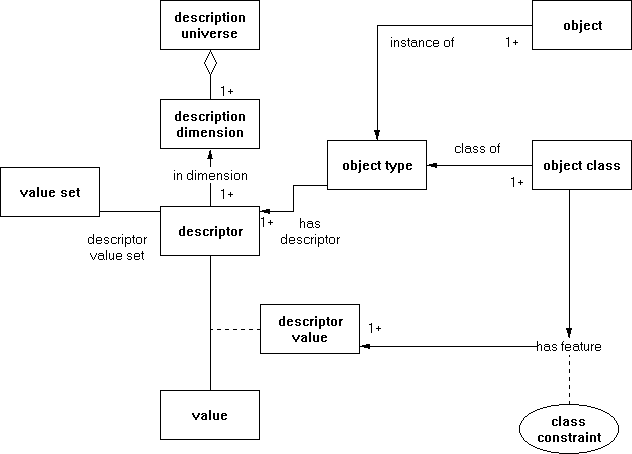
FIGURE 4: A first attempt to define an ontology that contains the conceptualizations common to classification tasks
The two central concepts in the classification ontology are object-type and descriptor. "Object-type" represents the general category to which objects that need to be classified belong, e.g. apple, rock or art object. A descriptor provides information about instances of the object type. For example, colour and grain size are descriptors of apples. Descriptors are part of a space of descriptors, termed the description-universe which consist of several dimensions. Each descriptor belongs to one dimension. These dimensions are mostly different ways of observing an object. For example, for rocks we distinguish between a macroscopic and a microscopic dimension. For apples, we could have the surface inspection and the internal inspection as two different descriptor dimensions. Each descriptor has an associated value set. The reified relation descriptor-value is used to represent a descriptor-value pair.
Each object type has a number of object classes. For the moment, we did not include a hierarchy of object classes, mainly because we have focused on capturing in this ontology the minimal conceptualizations necessary for classification. The object-instance represents the actual objects being classified, i.e. a particular apple or a particular rock. Most of the classification knowledge is represented through the rule schema class-constraint. This rule schema denotes the existence of a set of logical dependencies between object classes and descriptor-value pairs. For example. in the apple domain an instance of this rule schema could be the statement that a James Grieves apple is either green or yellow-green.
In this way one can describe a domain in terms of descriptors, objects and object-classes. Such a representation lies at the heart of several classification tasks, including rock classification. The concept of rock can be modeled as an object type which has several descriptors such as colour and grain-size. The rock type granite is represented as an object class. For granite the value for the descriptor grain-size is restricted by an instance class constraint that tells us that the value fine-grained can be excluded.
Method-specific extensions The classification ontology should provide the core knowledge for classification problem solvers. The specific methods used in an application will typically have additional domain-knowledge demands. As we will see in the next section, the classification methods applied in our demonstrator make use of additional attribute ordering knowledge. At his moment, we have not built an explicit ontology for these method-specific extensions.
Another way of extending the classification ontology is by making use of hierarchy information in the domain. Currently the classification ontology does not represent such information. The demonstrator too does not make use of such hierarchies present in the domain.
4.3 Ontology mapping table
If one constructs and/or reuses different ontologies (e.g. a classification ontology and a rocks ontology) the need arises for methods that support a systematic integration of these ontologies such that they can be used in an application. One possible method is an ontology-mapping table. A formal ontology mapping has not been developed at the moment, but will be a central topic of interest for us in continuation of Sisyphus. The basic idea is illustrated by Fig. 1. Every element in the classification ontology should be mapped on an element in the ontology of the domain, e.g. a rock ontology. Object type should be mapped on rock. Object-classes are those concepts in the rock ontology that are subsumed by the type rock and are themselves leaves in the subsumption hierarchy. Descriptors map on properties or parts of rock.
5 Classification Method
5.1 Method selectionWe selected the default classification method provided by the draft CommonKADS textbook (Schreiber et al., 1997). The method employs a simple pruning strategy. One starts off with the full set of possible candidates, specifies a feature of interest, obtains its value and "prunes away" all candidates that are inconsistent with the incoming data. This process is repeated until there is only one candidate solution.
The specification of this method is shown in Fig. 5.

The first while loop generates the set of candidate solutions. The second while loop prunes this set by obtaining new information. The method finishes if one of the following three conditions is true (see the condition of the second while loop):
Fig 6. shows the
corresponding inference structure. Three inferences are used in this
method plus a transfer function for obtaining the attribute value:
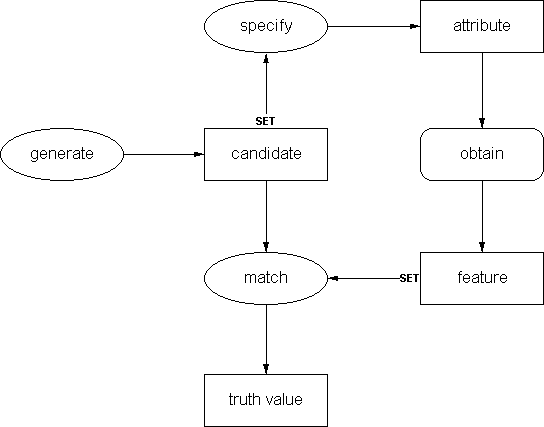
FIGURE 6: Inferences structure for the
pruning classification method
Generate candidate In the simplest case, this step is just a
lookup in the knowledge base of the potential candidate solutions.
Specify attribute
There are several ways for realizing this inference. The simplest way
is to just do a random selection. This can work well, especially if
the "cost" of obtaining information is low. Often however, a more
knowledge-intensive attribute specification is required.
Obtain feature
Usually, one should allow the user to enter an "unknown"
value. Also, sometimes there is domain knowledge that suggests that
certain attributes should always be obtained as one group.
Match
This inference should be able to handle an "unknown" value for
certain attributes. The default approach is that every
candidate is consistent with an "unknown" value for a certain
attribute.
5.2 Method customization
The pruning method was customized for use in Rocky by providing three
alternative strategies for the attribute-selection inference.
Random choice of attributes
A random choice will work if the information is easily obtainable and
the number of attributes is not too large. In this case the user will
have to supply far more values to attributes than is needed.
Order attributes
A more sophisticated method is to explicitly order the attributes and
turn them into a decision tree. In this case one uses domain knowledge
of the form If grain-size is coarse-grained ask about colour.
Such explicit attribute ordering information can very often be
replaced by a domain-independent method like:
Find an attribute that is present in as many of the classes that are
among the possible solutions.
Find most informative attribute
Another way is to choose the most informative attribute. The amount
of information of an AV-pair reflects the measure of reduction of
possible solutions. The way to calculate this amount is to count the
number of binary decisions needed to come to this reduction.
The amount of information of an AV-pair, I(AVi) can be computed as follows:
All three methods were explored and implemented in the demo-program
in a domain-independent way.
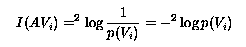
In order to compute the amount of information of an attribute (instead
of an attribute value-pair) we simply compute the amount of all
possible AV-pairs for this attribute and divide it by the number of
possible values.
This is different from the entropy formula as known in information theory:
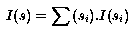
This formula weighs the probabilities as chances and is useful in
cases similar to flipping an unbalanced coin or learning. The same
idea is also used in ID3 (Quinlan, 1988). Note that in our case we take the
distribution of an AV-pair as it appears in the set of candidate
solutions.
5.3 Nesting classification methods
The classification of igneous rocks takes place on two
levels. First, information from a macroscopic level will be
obtained. If this suffices to prune away all but one of the known rock
classes there is no need for a microscopic investigation.
However a problem arises when one is not sure about some features of
the rock that are necessary for a good classification. This problem
often occurs when classifying small-grained volcanic rocks. A few
quotes from the first interview taken from the Sisyphus
material illustrate this issue:
Assuming you've got a coarse grained rock, the mineralogy would be
very easy to identify (..)
And from your identification of the mineralogy you'll be able to
arrive at a basic chemistry
Now the difference here is going to be in, you can't really identify
the minerals very easily cause they're fine grained and the minerals
could be only a twentieth of a millimetre across in these
That's going to be difficult to tell in hand specimen cause you can't
identify the minerals so well.
Taken from
Structured Interview I - Sisyphus KA Material
Classification of minerals is a science in itself and many of the
features described in the interviews and books regarding mineral
classification, apply to fully developed (crystallized) minerals. The
problem with identifying minerals in igneous rocks, particularly when
they are small-grained, is their lack of crystallization. To overcome
this difficulty minerals can be identified in thin slices of rock
under the microscope.
Therefore the classification of igneous rocks involves nesting methods
of classification. Instead of simply obtaining a value for the
selected attribute it could be decided that the value itself is
subject to classification. This is likely to occur when the attribute
is not directly observable and can only be inferred from other
observables at the microscopic level.
We illustrate this process with an example:
Identification of the mineral quartz in igneous rocks with a coarse-grained
texture is not very difficult. Quartz is common in many rocks, often
abundant in lightly coloured ones. It is often colourless or grey and
it does not show clear-cut cleavages: it splinters when broken.
Such information doesn't constitute a classification in itself. It
serves more as an explanation of the attribute quartz-presence.
In rocks with fine-grained rocks the process is far more
complicated. Individual grains cannot be seen, even with the help of a
small hand lens. It's here that a investigation of the thin section is
necessary. Of course one could also resort to the investigation of thin sections
in case of a rock with a coarse-grained texture.
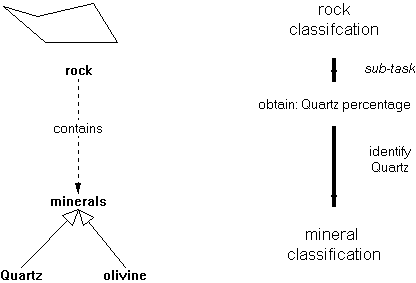
FIGURE 7: Nested classification. In order to establish a rock type it may be necessary to provide information about minerals present in the rock. A recursive classification process can be employed to classify a mineral in the rock.
Fig. 7 depicts
the nesting of classification in a graphical way.
Instead of
obtaining a value for an attribute, one recursively starts another
classification process.
The attributes that will trigger the recursive call are typically the
presence of certain minerals. In order to identify these, the
classification procedure will start from the beginning. A set of
possible candidates will be generated (these will all be minerals
now), an attribute is specified, and so forth, until the mineral class
is established.
6 Demonstrator
A demo-program has been built which can assist in classifying
igneous rocks. The program makes use of the pruning-strategy described
earlier. It looks up all the rocks known to the system and prunes away those
candidates which are inconsistent with the attribute information
provided by the user. If there is only one candidate left a
picture of the rock is shown. Fig. 8 shows a snapshot of
the interface of the demonstrator.
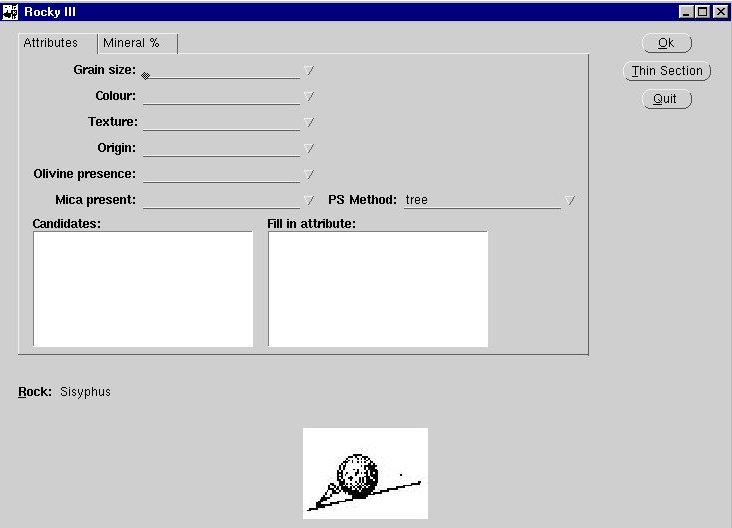
FIGURE 8: Opening window of the Rocky III demo
At the top a number of text items
are shown that allow selecting values for the main rock attributes
such as colour, texture and grain size.
The left list-browser will show the list of candidates consistent with the
current data. The list-browser on the right will give the user a hint about
the attribute to fill in next. This is the result of
attribute ordering inference described in the previous section.
This ordering is dependent on the problem-solving
method. The default-value for this option is
"tree" (most common attribute for remaining candidates).
The other options are "info" (using the most informative)
and "prune" (random selection).
Pressing the Help button launches Netscape with a local HTML-file.
Here an explanation of the descriptors and classification method is given.
As long as no solution has been found,
Sisyphus himself is shown in full labour.
According to the International Union of Geological Sciences (UIGS)
igneous rocks are classified based on the (relative) percentages of
certain minerals. The user can submit this information to the system
by making use of sliders (see Fig. 9).
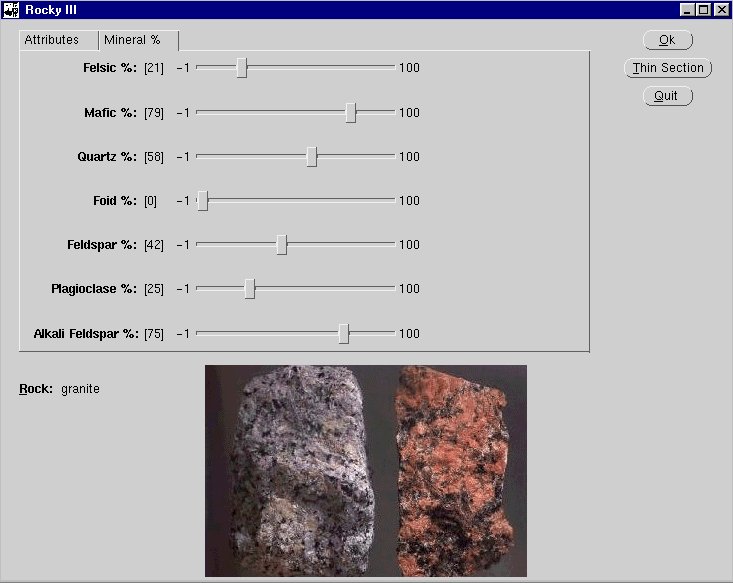
FIGURE 9: Snapshot of the sliders that can be
used to submit percentages of minerals to the system
Initially the values of all
sliders are set to -1, which means that the values are unknown.
Between some sliders constraints are defined, which make it
impossible for the user to enter incorrect or inconsistent data. For
example, setting the slider for quartz to a non-zero value
will result in a foid
percentage of zero, because the two minerals are never found
together in a rock. The reverse also holds: presence of foids excludes
the presence of quartz.
Within the system every rock is represented as a class together with
certain attributes
and their possible values. In case of the mineral percentages a lower
and upper bound is stated for each rock.
In case of medium or fine grained rocks it is often very difficult to
determine the minerals contained in the rock. For this purpose the
minerals themselves are subject of classification in a thin section of
the rock. To start the program to classify minerals in thin section
the user simply pushes the Thin Section button in the main program.
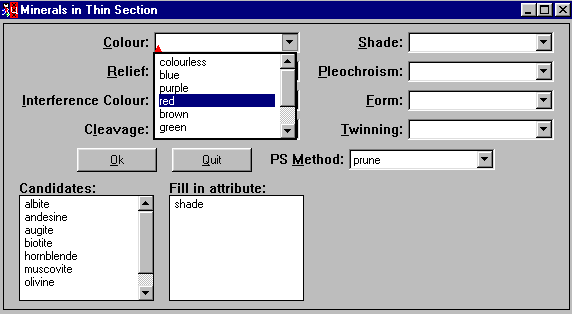
FIGURE 10: The main window for classifying
minerals in thin section
The window for Thin Sections shows a number of attributes with a each
a restricted number of values. In order to explain each of the
attributes the user may click on the labels. This will result in the
execution of Netscape and load a page explaining how to obtain a value
for the attribute.
The classification of minerals is similar to the case of igneous
rocks. Inconsistent candidates are pruned away. After the nature of
the minerals has been determined the user may close the Thin Section
program and continue with the classification of rocks.
New attributes, minerals and rocks are quite easy to add to the
program. All are kept in separate modules in easy to understand
code. Minerals are, like rocks, represented as classes with lists of
attribute-value pairs. Attributes are represented as a list with the
range of values. Minerals and rocks can be added by editing the appropriate files and inserting code. Adding attributes works similarly. No changes to the graphical interfaces will have to be implemented.
The interface is build up dynamically and changes
automatically as the attributes change.
At this moment the program does not make use of the ontologies written
in CML. The representation of rocks and minerals is however very
similar to the ones used in the rock- and mineral ontologies and
future versions are likely to be extended by making use of a CML-API.
The program also does not make use of the hierarchy of igneous rocks
and minerals. It uses a flat list of classes instead. The information
in the texture ontology is incorporated as attribute information and
therefore less explicitly present than in the ontology. The
classification ontology is not used at all in this demo.
The system was written in SWI-Prolog and XPCE, and consequently runs
on both UNIX and PC (Windows) systems.
7 Discussion
The first round of the Sisyphus III project certainly was a useful and
interesting exercise. The domain of rock classification shares many
characteristics with other real world domains: it is rich, much
terminology is standardized but individual experts use ideosyncratic
terms, the procedures for classification depend heavily on the type of
information available and on the viewpoint and expertise of the person
who performs the classification (amateur, astronaut, petrologist). As
a consequence, much effort in the early knowledge-acquisition phases
concerned familiarization with the domain, scoping of the knowledge
types, studying and evaluating the source material and obtaining
additional information. One lesson that we learned in this KA process
is that in well-understood and well-documented domains a good textbook
is preferrable above interviews with experts or other results of
elicitation activities.
The strategic approach that we have taken focussed on ontology
construction. Problem-solving methods for classification tasks are
widely available and quite well understood, although their formal
properties are not always clear. Thus, PSM's have not been a major
topic of our efforts sofar. We have reused classification PSM's that
were developed for other purposes (Wielinga et al., 1997). The main
challenge of the Sisyphus-III task for our group was to find a rich
and coherently partitioned representational framework of the domain
knowledge.
The knowledge of rock classification was partitioned along several
dimensions. A first dimension concerns the task dependency. The
classification ontology that describes the structure of objects,
classes and their descriptions is independent of the domain of
igneous rocks, but specific for classification tasks. In fact a
very similar ontological structure is used in the domain of
classification of art and antiques object in the GRASP project.
The second dimension is domain dependent and concerns distinctions of
materials (rocks and minerals) and their various attributes. Domains
that involve perceptual attributes as well as semi-quantitative
attributes require separate ontologies for the attributes and their
potential values. Much of the knowledge involved in domains like rock
classification and art and antiques concerns the determination of the
relevant properties of the object at hand. A clear separation is
required between properties in the various domains: phenomenological
properties (colour, grainsize, texture), thin-section properties,
physical properties (hardness, specific weight) and chemical
properties.
The coupling of the various ontologies in the demo application
requires a mapping. This mapping can be viewed as an ontology in
itself. Mapping ontologies are a powerful tool to reuse existing
knowledge bases and ontologies, but are poorly understood sofar. More
work has to be done to understand the mapping knowledge at a generic level.
In summary, we have focused on the groundwork for the future phases
of the Sisyphus-III project rather than on an application for
Round-I. However, a demo system could be built in a short period of
time using parts of the ontologies and existing implementations of
Problem Solving Methods for classification. The ontology construction
work has not been finished and will focuss on the structural aspects
of ontologies for classification domains.
Acknowledgements
We gratefully acknowledge the contributions of Arno Stam and Mark
Verkerk in discussion we had on the Rocky domain.
References
Gennari, J. H., Tu, S. W., Rotenfluh, T.E., & Musen, M.A. (1994). Mapping domains to methods in support of reuse. International Journal of Human-Computer Studies, 41:399-424.
Gruber, T. R., Olsen, G. R., & Runkel, J. (1996). The configuration-design ontologies and the VT elevator domain theory. International Journal of Human-Computer Studies, 44(3/4):569-598.
Howell, J.V. (1957). Glossary of Geology and related Sciences. Washington, American Geological Institute.
MacKenzie, W. & Adams, A. (1995). A Colour Atlas of Rocks and Minerals in Thin Section. New york, Manson Publishing.
Quinlan, J. (1988). Semi-autonomous acquisition of pattern-based knowledge. Teaching, Solving and Learning, pages 192-207. Address: The Rand Corporation.
Raymond. L, A. (1995). Petrology, The Study of Igneous , Sedimentary, Metamorphous Rocks
London, Wm. C. Brown Publishers.
Reeves, M.(1986). Minid, optical identification in thin sections (DOS program). This software can be downloaded.
Rothenfluh, T.F., Gennari, J.H., Eriksson, H., Puerta, A.R., Tu, S. W., & Musen, M. A. (1996). Reusable ontologies, knowledge acquisition tools and performance systems: PROTEGE-II aolutions. International Journal of Human-Computer Studies, 44(3/4):303-332.
Rumbaugh, J., Blaha, M., Premerlani, W., Eddy, F., & Lorensen, W. (1991). Object-Oriented Modelling and Design. Englewood Cliffs, New Jersey, Prentice Hall.
Schreiber, A. Th., Akkermans, J. M., Anjewierden, A. A., De Hoog, R., de Velde, W.V., & Wielinga, B.J. (1997). Engineering of Knowledge: The CommonKADS MethodologyUniversity of Amsterdam.
Schreiber, A.T. & Terpstra, P. (1996). Sisyphus-VT: A CommonKADS solution. International Journal of Human-Computer Studies, 43(3/4):373-402.
Schumann, W. (1992). Collins Photo Guide to Rocks, Minerals and Gemstones. London, Harper Collins Publishers.
Stefik, M. (1995). Introduction to Knowledge Systems. Morgan Kaufmann Publishers.
Tu, S.W., Eriksson, H., Gennari, J.H., Shahar, Y., & Musen, M.A. (1995). Ontology-based configuration of problem-solving methods and generation of knowledge acquisition tools: The application of PROTEGE-II to protocol-based decision support.. Artificial Intelligence in Medicine.
Wielinga, B.J., Akkermans, J. M., & Schreiber, A. T. (1997). A competence theory approach to problem solving method construction. Submitted for publication. Copy available from the first author.