
Improving the efficiency of business processes results in a reduction of time needed to perform the task and of costs. This business objective leads to approaches as lean management and business process reengineering & optimization. In order to fulfill these objectives, workflow management approaches often are introduced in the enterprise (Georgakopolous, and Hornick, 1995). The workflow management coalition defines workflow management as:
„The automation of a business process, in whole or part, during which documents, information or tasks are passed from one participant to another for action, according to a set of procedural rules." (Workflow Management Coalition, 1996).
Today, workflow management approaches are basically only used to support repetitive administrative tasks whereas knowledge-intensive tasks are not supported. There are several reasons for this:
Although there were tremendous improvements in software engineering over the last decades, basic problems remain:
Understanding commonalties and differences between process types is a key factor for better process support. Process support includes improved communication, guiding people when performing processes, improving both processes and their results, and automating process steps (Rombach, and Verlage, 1995).
Software process modeling and enactment is one of the main areas in software engineering research. Several frameworks have been developed (e.g. procedural (Sutton, Osterweil, and Heimbigner, 1995], rule-based (Kaiser, Feiler, and Popovich, 1988; Tong, Kaiser, and Popovich, 1994; Peuschel, Schäfer, and Wolf, 1992], Petri net based (Bandinelli, Fuggetta, and Grigolli, 1993a], object-oriented (Conradi, Hagaseth, Larsen, Nguyen, Munch, Westby, Zhu, 1994)).
Process-sensitive software engineering environments which support evolution of executed process models (Conradi, Fernström, Fuggetta, 1993) are a focal point of current research, but the results are still immature (Madhavji, and Penedo, 1993). Several approaches to support the evolution and flexibility of software processes were developed (Bandinelli, Fuggetta, and Ghezzi, 1993b; Ben-Shaul, and Kaiser, 1993; Cugola, Di Nitto, Ghezzi, and Mantione, 1995; Pérez, Emam, and Madhavji, 1995). None of these approaches is supporting globally distributed software processes and their evolution (although work in this direction is starting (Kaiser, 1997; Conradi, 1997)).
Published approaches on process evolution mainly deal with changing the enacted process model so that it reflects the changed real world process. Automatically sending notifications about the changed process/products over the Internet to the appropriate members of the global team is not supported. To determine them, the system needs a kind of understanding of the causal dependencies between processes and products. Software change impact analysis [Bohner, and Arnhold, 1996) deals with causal relation between and in products.
Managing software process knowledge is also the goal of the experience factory approach (Basili, 1989; Basili, Gianluigi, Caldiera, and Rombach, 1994). They distinguish between the organizational structure to manage the software knowledge (the experience factory department) and the activities that have to be carried out to build an experience factory.
In this paper, we give a process-oriented view on knowledge-intensiv tasks in software development. In section 3, we define requirements on process-oriented knowledge management systems. Section 4 discusses our process modeling language MILOS and explains how knowledge is linked to generic business processes. The next section shows how this knowledge can be incorporated into concrete projects. A concept for the architecture of a process-oriented knowledge management system is described in Section 6. Section 7 gives an overview on the state of implementation. In Section 8 we discuss related work. The last section gives a summary of the paper.
Globally distributed work processes have to deal with many problems arising from
Requirement 1: Synchronous work support
Around the clock development requires that - at the end of the working day - the results of the day have to be efficiently communicated to the co-worker in the next time zone who just starts to work. This poses the requirement on modeling approaches, that models have to be easily understood and that an overview on the changes since the last day has to be provided. Nevertheless, synchronous communication between the team members will help in communicating the current state of the work. Audio and video conferencing capabilities can be used as well as shared workspaces and distributed meeting rooms. The technology for that is available but the costs for a wide spread use are still too high.
Requirement 2: Asynchronous work support
In globally distributed software development processes, people work asynchronously in different locations and at different times. Therefore, a support system shall facilitate the coordination and the management of the process. Process enactment support techniques - or, in a broader sense, workflow management techniques - try to provide the right information to the right people at the right time with the right tools. They have to be extended to support work over wide area networks.
Requirement 3: Ubiquitous communication infrastructure
To reduce the problems in setting up a global team, a ubiquitous infrastructure has to be used. Each team member has to be able to connect to the development process without effort.
Requirement 4: Transparent & fast access to process knowledge
For a smooth development process, every team member needs easy access to all relevant project data (e.g. to-do lists, source code, requirement specifications, defect reports etc.) as well as generic knowledge (e.g. coding & documentation standards, effort estimation guidelines etc.). This knowledge can be represented for human use or for use by KBS interpreters. Project data has to be defined in a product model (which imposes a requirement on modeling tools to be open for external access). Using web techniques, the access to data is transparent to the user: It does not matter where the data is stored. Clearly, due to current bandwidth limitations, this is not the naked truth: Accessing the data on a foreign server often needs much more (sometimes prohibitive) time than accessing local information.
Requirement 5: Distributed configuration management
Configuration management systems are used to maintain several versions of a system and all the information related to it. They are a basis for an orderly development process. Consequently, they have to be extended for the virtual environment of globally distributed teams.
Requirement 6: Repository for ontologies
To overcome problems with different ontologies, a project repository has to be provided that defines commonly used terms. Using the Web as the medium, the repository should be organized and maintained at several locations. The repository should be extended to provide an experience base for software development storing generic process and product models as well as metrics gathered in past projects. These could then be used to improve cost and time estimations for new projects.
Requirement 7: Flexibility of development processes
Most software process support environments require a complete, fine-grained process model before the execution starts. For large-scale software projects, that is not realistic: The project plan needs to be refined and extended while the development is already in progress. In addition, there will be no central project plan in globally distributed projects but there will be plans at every location which have to be coordinated. Using and extending knowledge-based techniques, project planning and execution can be interlinked giving a greater flexibility to the people involved in the project. Agent-oriented approaches may help to coordinate the plans of different locations.
Requirement 8: Proactive change notifications
The coordination of globally distributed processes will be improved if part of the task is done automatically. Coordination problems often result from changes introduced into the process because of new external requirements and/or erroneous assumptions. Explicit causal relations between process information generate traceability and can be used by a system to proactively send notifications to team members whose work is influenced by the change (e.g. a task may become obsolete, interfaces of imported modules are changed and users of the interface get notifications). To use change notification mechanisms in worldwide distributed projects; „real" push mechanisms have to be developed. A process enactment engine has to generate events and allow clients to create event listeners.
MILOS allows to represent knowledge about work processes explicitly, especially software development processes. The core notion of MILOS is the PROCESS. Any other information is grouped around this notion: Products are inputs or outputs for processes. Factual knowledge is linked to processes. In this sense, MILOS supports a process-centered structuring of knowledge.
Knowledge needed to plan and execute includes
· project plans & schedules,
· products developed within projects,
· project traces, and
· background knowledge such as guidelines, business rules, studies etc.
With MILOS product & resource models can be developed and integrated into process models. For a new project, these kinds of models are the basis for the definition of project plans.
Based on a given product model, products that contain general and specific project knowledge of a company can be specified. The underlying product model defines the structure and the type of that knowledge. A main mechanism for associating knowledge to entities in the process model is using external references to the knowledge. This is further explained in the Section 6.1.
A process is defined by a description of the process goal, a set of conditions, process attributes, the products needed to plan and to execute the process, a set of alternative methods to reach the process goal, the products to be produced, and resource allocations.
Methods are either complex or atomic. Complex methods refine a process into one ore more subprocesses whereas the application of an atomic method results in the production of products that are the outputs of the process.
Inputs of a process may either be products, that are produced by other processes during project enactment, or predefined products taken from generic process models.
Every process is associated with a set of roles and qualifications which are needed to perform the task (e.g. the process „Implement Class" is associated with the qualifications „Java knowledge available" and the role „Programmer").
Process models are generic descriptions of the general way of the course of projects. The models have to be specialized and customized within the projects.
In Table 1 you can find a summary of the basic language concepts of MILOS.
|
|
|
| process | Set of activities that have to be executed in order to reach a given goal. |
| condition | A condition controls the execution of a project plan. We distinguish between preconditions and postconditions. |
| product type | The description of type and structure of a class of products. |
| product | A product is an information unit of a given product type, for example a document or a piece of code. |
| product reference | Product references stand for the type of products that are used and/or produced by a process or a method. We distinguish between products that are consumed for planning, consumed for execution, produced, and modified. |
| produce | This parameter type stands for a product of a given type that is produced by an atomic method of a process. |
| consume for planning | Product reference that describes the read only access to a product within the planning of a process. |
| consume for execution | Product reference that describes the read only access to a product during the execution of a process. |
| product mapping | Defines the product flow within the process/method hierarchy. |
| method | Problem solving method to reach a process goal. |
| atomic method | Leaf within the process/method hierarchy. It produces or modifies a product. |
| complex method | Problem solving method that refines a process into one or more subprocesses. |
| attribute | Attributes are properties of processes, products, methods and resources. |
| product attribute | Attribute of a product. |
| process attribute | Attribute of a process. |
| resource | Resources are used for the execution of the project. We distinguish between two types of resources: agents and tools. |
| resource attribute | Attribute of a resource. |
| role | A predefined resource attribute. It describes the task of a resource within an organization. |
| qualification | A predefined resource attribute. It describes a skill of a resource. |
| tool | A program that supports activities. |
| agent | A human or machine that carries out activities within a process. |
| precondition | A condition that has to be valid to carry out a process. |
| postcondition | A condition that has to be valid after a process has been executed. |
Customizing process models to project plans is part of project planning. Using generic process models, even inexperienced project managers are able to come up with a plan according to the company’s quality standards and procedures. In general, the project starts using an initial plan that defines the general course of action and the first project steps. Customizing extends over the project start. On base of the results of early project activities (for example information gathering activities) parts of the plan are further customized during project execution.
We developed techniques to support (a) plan refinement (b) plan adaptation and (c) error correction during project execution. Methods define possible plan refinements. Selecting a method during execution results in a refined plan. Plan adaptation takes place when the definition of the plan is changed, for example when requirements change or within optimization tasks. Plan adaptation allows, for example, to add new processes to the plan, change the process decomposition, change the order of process execution, and change task delegations.
Finally, planning errors may be detected and have to be corrected if the project is already in execution. Changing the plan may affect project execution, if the changed parts of the plan have already been executed and work has been done. For this, our system supports project execution by
Changes and adaptations may be located within (local) project plan as well as in the process and product models. This causes two problems:
Generic Process Models: The first tier handles generic and reusable process models and associates generic knowledge to the entities of the process model. Knowledge may be stored in several forms:
Project Specific Process Models (Project Plans): The second tier contains project specific process descriptions. Using the single representation trick (known from machine learning), the mapping of generic process models to project specific process descriptions is easy: We use the same representation for both tiers and are able to copy generic models to a project. Then the generic descriptions are customized to be used in the specific project.
Copying models from the first tier to the second tier is easy. Open problems surely exist:
Project plans contain the knowledge about the tasks to be done and the knowledge related to them. They are a basis for project enactment and coordination. Using a process enactment engine in a project, a project plan is the basis for actively guiding human users in their work.
Dynamic Project Data: The third tier handles dynamic knowledge which is the core of a flexible workflow/process engine: The state of the work process and its tasks, do-do lists for its users, the products created during process enactment, causal relationships between process entities, etc.
The knowledge stored in this tier is created during process execution: it is the output of the work processes. In software development processes this includes e.g. requirements specifications, design documents, design rationales, traceability matrixes, source code etc.
The third tier provides - beside a product-oriented view - also a process-oriented view on the data created during task enactment. User are able to access information based on the processes carried out and they can follow the information flow in the project (thereby tracing where and by whom a specific information was used).
Figure 2 shows the graphical interface for describing the information flow within a process model. The editors for defining the process decomposition, and for editing product and resource models are omitted.
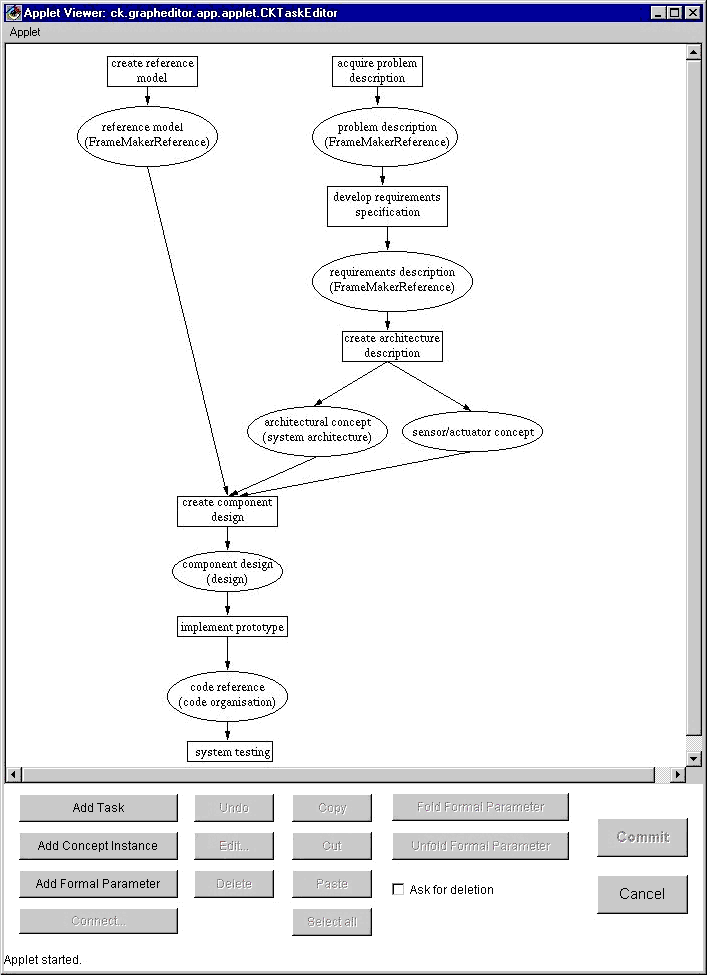
The interface for defining project plans will look similar. In addition, the user will have access to the model library from where he can copy suited models.
For project execution, the system provides workspaces for managers, developers, and planners. The workspaces are very powerful, because they provide the user with relevant project data, guide them through their tasks, and automatically start required tools.
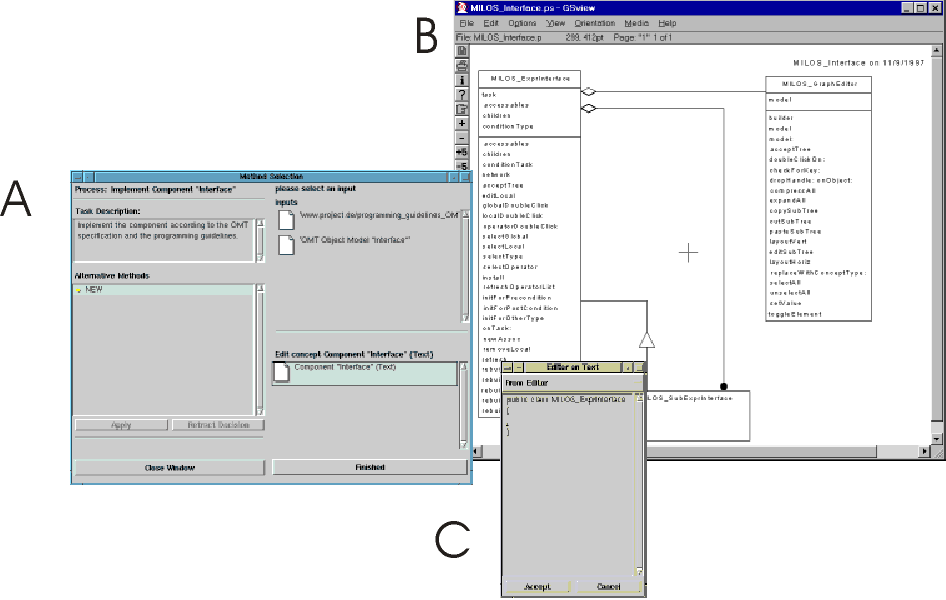
Figure 3 shows the workspace of Mr. Holz, who is actually executing an atomic method. His task is to develop an interface component in Java based on an OMT specification. The left window (A) displays him the documents he can access and he has to produce in order to finish the task. Clicking on the document symbols, customized editors to edit the products are automatically opened. In this example, a postscript viewer on the OMT specification (B) and an editor to edit the component (C) have been opened. After finishing the work, the task window and dependent tools will be closed by the system.
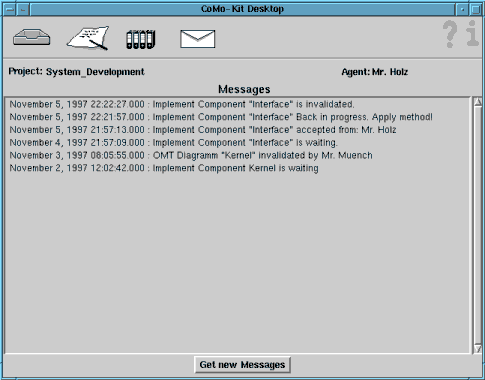
For coordination tasks each workspace provides a window that displays incoming notifications relevant for the work of the workspace owner (see Figure 4). If he wants to know more about the context of the notification, he can start the information assistant. This web based component navigates the user trough the project plan and provides background information about the project state, decisions and their rationales, and the developed products. Figure 5 shows a screenshot of the information assistant.
6.3 Technical Perspective
In this section, we describe how a process-centered knowledge management system can be designed which fulfills the requirements stated in Section 3. We also discuss design alternatives for building the system and explain why we use a specific technology. The whole system is being built using state of the art information technology that is in industrial use.
To fulfil Requirement 3 (Ubiquitous communication infrastructure), Internet technology is clearly the way to go. The Internet - and, in the future, the Internet II - will provide this infrastructure to lesser costs than point to point (satellite) lines. In fact, the wide spread use of Internet-based communication as well as the increasing speed of its introduction to a „standard" working environment make it the obvious and cost-effective choice for global teams. Internet-based virtual private networks create a secure environment for work groups based on encryption techniques. Current problems, e.g. bandwidth, latency, quality of service guarantees, will be overcome with the broad introduction of Internet II and the new protocols. Internet access is more or less available in every workplace - or will be in the next couple of years. To be able to access process and/or project information, the only widely available cross-platform environment is the web. Other environments are either restricted to one platform or use proprietary communication protocols that are not supported in every company. To be able to build up virtual corporations, we decided for a common denominator: TCP/IP and web browsers.
Ubiquitous access to process information also means that every entity needs to have an unique identity and that by using this identity a user is able to access the information (we omit a discussion of security issues here). URLs are the means of the Web allowing to access distributed information. Using URLs an object may be located on an arbitrary computer in the Internet. In addition, Web browsers are able to associate file types with application programs and start them automatically when a document of that type is loaded from an URL. Therefore we decided to use URLs as the unique identifiers of the objects handled by our system and are implementing Java based user interfaces for manipulating the objects that are not stored in files. One possible extension would be to use URL addresses for every object stored in the configuration management and use http as the protocol to access versions of an object stored on arbitrary configuration management servers.
Storing information persistently, several technologies can be used: File systems, relational databases and object-oriented databases. File systems are restricted concerning version management, transaction support, and replication support. On the other hand they are easily accessible by (commercial) web servers. Databases support transactions and - often - replication of data. Relational databases only support table-oriented structures. More complex data structures are supported by object-oriented databases. Therefore, they are the means of choice for software process support (which is our main application area). Using OODBMS technology, we are implementing a configuration management system that allows to store arbitrary versions of products. We will extend this to support distributed configuration management using the built-in capabilities of the OODBMS GemStone (Requirement 5).
Resulting from the remarks above, we can define a first architecture for process support environments (Figure 6). The Internet is the backbone for the distributed system. Client computers access process data using web browsers. Process models, project plans and dynamic project data are stored in a central object-oriented database with additional information stored in files. The database server supports project execution by implementing a process engine that handles to-do lists for team members and by providing access to all project data.
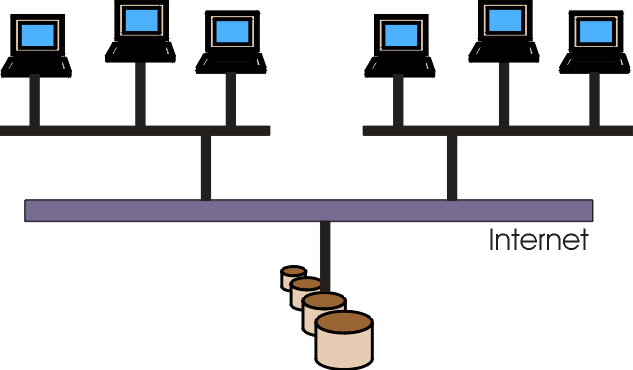
The problem with this architecture is that – due to the low bandwidth available on some Internet links – it does not always fulfil Requirement 4 (fast access to process knowledge) and Requirement 5 (distributed configuration management). These problems can be overcome by using proxies, caches and replication techniques that bring the information nearer to the end user. The process support system is then responsible for providing transparency by caching or replicating process data at different locations. Figure 7 shows an appropriate system architecture.
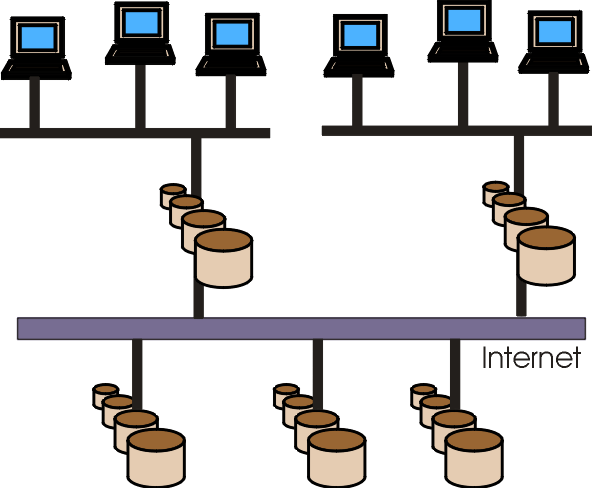
The next question to be answered is how to implement this distributed architecture. Several frameworks for distributed system implementation were developed in the last couple of years. The main competitors in the market are now:
We use Java applets to reduce the problem of distributing (project specific) software tools to team members whereas CORBA allows object-based communication between tools.
Requirements 2 (asynchronous work support) will be fulfilled using our published workflow management approach (Dellen, Maurer, and Pews, 1997; Maurer, 1997). Our approach focuses on methods and techniques that increase the flexibility of workflow management by alternating project planning and project execution steps (Requirement 7). In addition, we developed an approach that supports project coordination by automatically sending change notifications to appropriate team members. This functionality is based on traceability relations that are generated automatically using knowledge contained in process models (Maurer, and Paulokat, 1994; Dellen, Kohler, and Maurer, 1996). Our current approach to traceability is somehow limited: It only generates causal relationships between process data based on generic process notions (processes, process decomposition, and information flow). One of our students, Quan Li, currently develops a framework that allows to define domain-specific traceability relations using event-condition-action rules (ACT-NET Consortium, 1996). The extended framework fulfils Requirement 8 as soon as the notifications - which currently are only distributed in a local area network - are distributed over the Internet.
Product models specify the structure and relationships of (software development) products. In that sense, they describe the ontology of the domain - although they are not formally specified using logical representations (e.g. Ontolingua, KIF, or terminological logic). Using the restricted expressiveness of object-orientation, our system is neither able to automatically classify instances nor can it build up inheritance hierarchies automatically. On the other side, object-oriented approaches support the definition of arbitrary methods for objects. In our opinion, this is an advantage - from a system implementation point of view - compared to the use of terminological languages.
Requirement 1 (Synchronous work support) is not in the focus of our research. Therefore, we decided to use available technology for incorporating this functionality into our environment. Microsoft’s NetMeeting and Netscape’s Conference tools allow for audio and/or video conferencing over the Internet as well as shared whiteboards and/or shared applications (although this functionality currently is restricted to Windows PCs).
CoMo-Kit was developed using the OODBMS GemStone/S and VisualWave for Smalltalk as the programming environment. GemStone/S data definition language and data manipulation language is a Smalltalk dialect. Therefore, we are able to prototype systems in the Visualwave environment and than transfer part of the implementation into the GemStone database (gaining distribution over local area networks and transaction management).
The implemented prototype supports process modeling and process enactment. It contains a traceability component that generates causal relations based on process models and uses these to send change notifications to appropriate users.
We currently are in the process of re-designing and re-implementing the whole system in Java. An initial prototype of the user interface that allows to model the information flow in processes will be available in February 1998. The re-implemented user interfaces are Internet-enabled and support the access to a centralized database that stores all project information.
In addition, a complete re-implementation of a MILOS-based process modeling and process enactment environment is undertaken as a joint effort of the groups of Dr. Richter and Dr. Rombach (both University of Kaiserslautern, Germany) and Dr. Maurer (University of Calgary, Canada).
Work in knowledge management is influenced from several perspectives. There is the organizational perspective that discusses how companies can organize their knowledge management (van Heijst, van der Spek, and Kruizinga, 1996). Often these approaches concentrate on human resource aspects (Sierhuis, and Clancey, 1996).
(Simon, 1996; Dieng, Giboin, Amergé, Corby, Després, Alpay, Labidi, and Lapalut, 1996) discuss the problem of acquiring the knowledge for knowledge management systems.
Knowledge management for distributed enterprises is discussed in (Gaines, Norrie, Lapsley, and Shaw, 1996). The authors show how the web can be utilized for knowledge management. Their approach does not explicitly model the work process.
Several authors developed tools for managing different aspects and representation formalisms over the web (Gaines, and Shaw, 1996; Farquhar, Fikes, and Rice, 1996; Kremer, 1996). None of these is explicitly representing work processes (which - in our opinion - are the glue that holds several products together).
(Abecker, Bernardi, Hinkelmann, Kühn, and Sintek, 1996) integrate information retrieval and knowledge management. Although their approach also deals with work processes, they do not represent them explicitly so that the processes can be changed on the fly.
The process-centered structure of the system has the following advantages:
ACT-NET Consortium (1996). The Active Database Management System Manifesto: A Rulebase of ADBMS Features. ACM Sigmod Record 25(3): 40-49.
Armitage, J., and Kellner, M. (1994). A conceptual schema for process definitions and models. In D. E. Perry, editor, Proceedings of the Third International Conference on the Software Process, p. 153–165. IEEE Computer Society Press.
Bandinelli, S., Fuggetta, A., and Grigolli, S. (1993). Process Modeling-in-the-large with SLANG. In IEEE Proceedings of the 2nd International Conference on the Software Process, Berlin (Germany).
Bandinelli, S., Fuggetta, A., and Ghezzi, C. (1993). Process Model Evolution in the SPADE Environment. IEEE Transactions on Software Engineering. Special Issue on Process Evolution.
Basili, V. R. (1989). The Experience Factory: packaging software experience. In Proceedings of the Fourteenth Annual Software Engineering Workshop, NASA Goddard Space Flight Center, Greenbelt MD 20771.
Basili, V. R., Caldiera, G., and Rombach, H. D. (1994). Experience Factory. In Encyclopedia of Software Engineering (John J. Marciniak, ed.), vol. 1, pp. 469--476, John Wiley Sons.
Ben-Shaul, I., and Kaiser, G. (1993). Process Evolution in the Marvel Environment. 8th International Software Process Workshop : State of the Practice in Process Technology.
Bogia, D. P., Kaplan, S. M. (1995). Flexibility and Control for Dynamic Workflows in the wOrlds Environment. In Proceedings of the Conference on Organizational Computing Systems.
Bohner, S., and Arnold, R. (1996). Software Change Impact Analysis. IEEE Computer Society Press.
Conradi, R., Hagaseth, M., Larsen, J. O., Nguyen, M., Munch, G., Westby, P., and Zhu, W. (1994). EPOS: Object-Oriented and Cooperative Process Modeling. In PROMOTER book: Anthony Finkelstein, Jeff Kramer and Bashar A. Nuseibeh (Eds.): Software Process Modeling and Technology, 1994, p. 33-70.Advanced Software Development Series, Research Studies Press Ltd. (John Wiley).
Conradi, R., Fernström, C., and Fuggetta, A. (1993), A conceptual framework for evolving software processes. In ACM SIGSOFT Software Engineering Notes, 18(4): 26–35.
Conradi, R.(1997). Cooperative Agents in Global Information Space, http://www.idi.ntnu.no/~cagis/
Cugola, G., Di Nitto, E., Ghezzi, C., and Mantione, M. (1995). How to deal with deviations during process model enactment. In Proceedings of the 17th Int. Conf. on Software Engineering (ICSE 17).
Curtis, B., Kellner, M., and Over, J. (1992). Process modeling. Communications of the ACM, 35(9): 75–90.
Dellen, B., Kohler, K., and Maurer, F. (1996). Integrating Software Process Models and Design Rationales. In Proceedings of Knowledge-Based Software Engineering Conference (KBSE-96), IEEE press.
Dellen, B., Maurer, F., and Pews, G. (1997). Knowledge-based techniques to increase the flexibility of workflow management. In Data & Knowledge Engineering Journal, Vol. 23 No. 3, page 269-295.
Dieng, R., Giboin, A., Amergé, C., Corby, O., Després, S., Alpay, L., Labidi, S., and Lapalut, S. (1996). Building of a Corporate Memory for Traffic Accident Analysis. In Proceedings of the KAW-96, Banff, Canada.
Farquhar, A., Fikes, R., and Rice, J. (1996). The Ontolingua Server: a Tool for Collaborative Ontology Construction. In Proceedings of the KAW-96, Banff, Canada.
Gaines, B. R., Norrie, D. H., Lapsley, A. Z., and Shaw, M. L. G. (1996). Knowledge Management for Distributed Enterprises. In Proceedings of the KAW-96, Banff, Canada.
Gaines, B. R., and Shaw, M. L. G. (1996). A Networked, Open Architecture Knowledge Management System. In Proceedings of the KAW-96, Banff, Canada.
Georgakopolous, D., and Hornick, M. (1995). An Overview of Workflow Management: From Process Modeling to Workflow Automation Infrastructure. In Distributed and Parallel Databases 3, 119-153.
van Heijst, G., van der Spek, R., and Kruizinga, E. (1996). Organizing Corporate Memories. In Proceedings of the KAW-96, Banff, Canada.
Kaiser, G. E., Feiler, P. H., and Popovich, S. S. (1998). Intelligent Assistance for Software Development and Maintenance, IEEE Software.
Kaiser, G. (1997). OzWEB, http://www.psl.cs.columbia.edu/ozweb.html.
Kremer, R. (1996). Toward a Multi-User, Programmable Web Concept Mapping "Shell" to Handle Multiple Formalisms. In Proceedings of the KAW-96, Banff, Canada.
Madhavji, N., and Penedo, M. (1993). Guest editor’s introduction. IEEE Transactions on Software Engineering, 19(12):1125–1127, December 1993. Special Section on the Evolution of Software Processes.
Maurer, F. (1997). CoMo-Kit: Knowledge Based Workflow Management. In Proceedings Workshop on Knowledge Management, AAAI Spring Symposium, pages 106-110.
Maurer, M., and Paulokat, J. (1994). Operationalizing Conceptual Models Based on a Model of Dependencies. In: A. Cohn (Ed.): ECAI 94. 11th European Conference on Artificial Intelligence, pages 508-515, John Wiley & Sons, Ltd.
Osterweil, L. (1987). Software Processes are Software Too. In Proceedings of the Ninth International Conference of Software Engineering, Monterey CA, pp. 2-13.
Pérez, G., Emam, K., and Madhavji, N. (1995). Customizing Software Process Models. In Proceedings of the 4th European Workshop on Software Process Technology, pp. 70 -78, Springer.
Peuschel, P., Schäfer, W., and Wolf, S. (1992). A Knowledge-based Software Development Environment Supporting Cooperative Work. In the International Journal on Software Engineering and Knowledge Engineering, 2(1): 79-106.
Rombach, H.-D., and Verlage, M. (1995). Directions in software process research. In M. V. Zelkowitz (Eds.), Advances in Computers, vol.41, pages 1–63. Academic Press.
Sierhuis, M., and Clancey, W. J. (1996). Knowledge, Practice, Activities and People, AAAI Spring Symposium on Artificial Intelligence in Knowledge Management, AAAI Technical Report, Stanford.
Simon, G. (1996). Knowledge Acquisition and Modeling For Corporate Memory: Lessons Learnt from Experience. In Proceedings of the KAW-96, Banff, Canada.
Sutton, S., Osterweil, L., and Heimbigner, D. (1995). APPL/A: a language for software process programming. In IEEE Transactions on SE and Methodology, Vol. 4, No. 3, p. 221-286.
Tong, A., Kaiser, G., and Popovich, S. (1994). A Flexible Rule-Chaining Engine for process Based Software Engineering, 9th Knowledge-Based Software Engineering Conference.
Verlage, M. (1994). Multi-view modeling of software processes. In B. C. Warboys, ed., Proc. Third European Workshop on Software Process Technology, Springer, pp. 123-127.
Verlage, M., Dellen, B., Maurer, F., and Münch, J. (1996). A synthesis of two software process support approaches. In Proceedings 8th Software & Engineering and Knowledge Engineering (SEKE-96), USA.
Workflow Management Coalition: Terminology & Glossary,
http://www.aiai.ed.ac.uk/WfMC/DOCS/glossary/glossary.html