Tim Menzies
Artificial Intelligence Department
School of Computer Science and Engineering
The University of NSW
timm@cse.unsw.edu.au
http://www.cse.unsw.edu.au/ timm
February 20, 1998
If we lack an objective human expert oracle which can assess a system, and if we lack a library of known or desired behaviour, how can we assess an expert system? One method for doing so is a critical success metrics (CSMs). A CSM is an assessment of a running program which reflects the business concerns that prompted the creation of that program. Given pre-disaster knowledge, a CSM can be used while the expert system is in routine use, without compromising the operation of the system. A general CSM experiment is defined using pre-disaster points which can compare (e.g.) human to expert system performance. Examples of using CSMs are given from the domains of farm management and process control.
How are we to assess the knowledge engineering techniques being reported in the knowledge acquisition (KA) literature? We should carefully assess superlative claims for the efficacy of case tools or formal methods or object-oriented knowledge representations or problem solving methods (PSM) [Schreiber et al., 1994] or ontologies [Gruber, 1993] or ripple down rules [Preston et al., 1993] or abduction [Menzies, 1996] or the problem space computational model [Yost, 1993] or whatever. In the software engineering literature, there are many examples of software engineering techniques (e.g. CASE tools, formal methods) which are in common use but, when evaluated, cannot be shown to be beneficial to the software process [Fenton et al., 1994]. Also, in the KA literature, many of the claims in the PSM literature are not supported by the currently available empirical evidence [Menzies, 1997a].
Clearly, we need some better method than reading the glowing reports from the authors of these KA techniques. Even if these authors are expert in their fields, they may still be unable to perform objective expert evaluations. Experts can often disagree about what constitutes a competent system ([Shaw, 1988, Gaschnig et al., 1983]). The halo effect prevents a developer for looking at a program and assessing its value. Cohen likens the halo effect to a parent gushing over the achievements of their children and comments that...
What we need is not opinions or impressions, but relatively objective measures of performance. [Cohen, 1995], p74.
The method for assessment explored in this article is critical success metrics (CSMs); i.e. some number inferred from the system which, if it passes some value, demonstrates conclusively that the system is a success. If such a critical measurement is observed, then the system will be deemed to be a success, regardless of other less critical measures (e.g. slow runtimes).
For example, consider the PIGE farm management expert system [Menzies et al., 1992]. PIGE advised on diets and genotypes for pigs growing in a piggery. Given a particular configuration of the livestock, an optimisation model could infer the annual profit of the farm. Alternate configurations could be explored using a simulation model. A user can choose some settings, then run the simulation model to see if the system's performance improved. The CSM for PIGE was can the system improve farm profitability as well as a pig nutrition expert?. If this could be demonstrated, then the tool could be sold as an a kind of automatic pig growth specialist. To collect this CSM, at the end of a three month prototyping stage, we compared the performance of the pig nutritionist who wrote the PIGE rules against PIGE. We observed that, measured in purely economic terms, this expert system out-performed its human author (!!). The CSM study results for PIGE are shown in Figure 1.
|
| ++++
200 - ++++++++++++++ + ++
| + o ++ ++ Legend
| +o oo +++ ------
| +o oo ooooooooo + PIGE
percent | ++o ooo o human
profit 100 - + o
increase | +o
| +o
|+o
+o
0 +-----|----|-----|----|-----|----|----|
1 2 3 4 5 6 7 8
simulation run number
This single CSM study changed the direction of the project. The graph of the CSM study became a succinct argument for collecting further funding. It was also very useful in sales work. PIGE became Australia's first exported expert system and was used on a routine daily basis in America, Holland, Belgium, France, Spain and Australia. In part, the success of the system was due to its ability to demonstrate its utility via a CSM.
Nevertheless, the CSM study of PIGE is a poor evaluation study. A good experiment is run multiple times with some variation between each trial [Cohen, 1995]. CSMs should be viewed as the inner measurement process within a well-defined experiment. A general class of such experiments are described below, along with an example in a process control domain. This example will use a technique called a pre-disaster point (defined below). Our example will be preceded by general notes on CSMs and their advantages.
This section offers some basic notes on CSMs. CSMs are a reflection of the contribution of the behaviour of the software in a particular business context. Hence:
Even if can't collect CSMs until an expert system is deployed, we should still define them at a very early stage. Evaluation should be considered as early as possible when building a system [Gaschnig et al., 1983]. The incremental application of a pre-defined success criteria can be a powerful tool for managing evolving systems [Booch, 1996]. Often, the evaluation criteria imposes extra requirements on the implementation. We may need to build a very simple initial system that collects baseline measurements which reflect current practice. For example, once I identified increases sales per day as the CSM for a dealing room expert system. However, this number was not currently being collected in the current software. Sales per day could be estimated from the quarterly statements, but no finer grain data collection was performed at that site. Hence, prior to building the expert system, a database system had to be built to collect the baseline data.
While CSMs are obvious in retrospect, they can take weeks of analysis to uncover. For example:
The observation that CSMs can take some time to isolate would not surprise software engineering metrics researchers. Basili [Basili, 1992], characterises software evaluation as a goal-question-metric triad. Beginners to experimentation report whatever numbers they can collect without considering the goal of the research project, what questions relate to that goal, and what measurements could be made to address those questions. Before goal-question-metric there must an analysis involving the stake holders of the project to establish the appropriate goals. Offen and Jeffery [Offen & Jeffery, 1997] offer the appropriate caution that this important task can take a non-trivial amount of time.
CSMs have business-level advantages as well as technical advantages as an assessment tool. For many business situations, CSMs are useful:
As an evaluation tool, CSMs have advantages over other evaluation tools for expert sytems. Expert systems are usually evaluated via panels of experts or some database of known or desired behaviour. Such evaluations can report the accuracy of those system to an enviable degree of accuracy. For example:
Using CSMs, we are placing a business-level success criteria on a running system. Hence, we can evaluate a system even when:
Also, the evaluation will be a business-level evaluation. Business users may demand objective evidence as to the business value of some program before allowing it to control some critical business process. This evaluation may not comprise developer-level concerns such as runtimes or (in the case of PIGE) current fashions in theories of protein utilisation. In the PIGE and dealing room examples, the CSMs had to reflect the fundamental business case which motivated the project: increased profitability.
Further, given a pre-disaster point, we can do this while the system is in routine operation. A pre-disaster point refers to a state of the system that is less-than-optimum, but not yet critically under-performing. As we shall see below, CSMs plus pre-disaster knowledge allows us to assess a system without compromising its operation.
This section offers a general design for an evaluation experiment using CSMs and a pre-disaster point. The aim of this evaluation is to check if the program is dumber than than some human, with respect to some chosen CSMs. In the experiment, the human or expert system is trying to control some aspects of the environment (e.g. make a diagnosis, prescribe medicines which reduce fever, improve profitability, etc).
Trials would alternate between the human and computer experts. A trial would begin when the system is in some steady state; i.e. there appears to be no currently active problems. During the course of each trial, the expert under trial would have sole authority to order adjustments to the environment. The trial would terminate whenever the pre-disaster point was reached. Authority to adjust the environment would then pass to the human experts. At the conclusion of each trial, a CSM is applied to assess the environment during the trial period.
At the end of a statistically significant number of trials (say, 20
for each population of experts), the mean performance of the two
populations of experts would be compared using a t-test as follows.
Let m and n be the number of trials of expert system and the human
experts respectively. Each trial generates a peformance score:
![]() ...
... ![]() with mean
with mean ![]() for the humans;
and performance scores
for the humans;
and performance scores
![]() ...
... ![]() with mean
with mean ![]() for the expert system.
We need to find a Z value as follows:
for the expert system.
We need to find a Z value as follows:
![]()
![]()
![]()
Let a be the degrees of freedom. If n=m=20, the a=n+m-2=38.
We reject the hypothesis that expert system is worse than the human
(i.e. ![]() ) with 95% confidence if Z is less than
(
) with 95% confidence if Z is less than
( ![]() ).
).
Note that this human/expert system comparison could also be used to assess different expert systems.
This section offers a detailed example of the above experiment. In the summer of 1986/87, I implemented QUENCH, an expert system computer program for the control of the quench oil tower at ICI Australia's Olefines petrochemical plant in Sydney [Menzies & Markey, 1987]. Once the system was built, I offered to management the experimental design discussed below. The evaluation experiment was approved but, due to a change in management, never performed. Nevertheless, the experiment is relevant here since it illustrates many of the practical issues associated with CSM evaluations. For example:
The Olefines petrochemical plant produces 240,000 tonnes of ethylene per year. It is a highly complex plant consisting in part of some 125 km of piping connecting numerous chemical processes. A unit of this plant is the quench oil tower. Inside the tower, hot cracked gases are cooled from around 400C to around 100C by mixing with oil. Certain gases are extracted at the top of the tower and the used quench oil, containing variable amounts of dissolved gases, is removed from the bottom. These dissolved gases effect the density of the removed oil. If the quench oil density moves outside of a certain narrow range, it can not be sold. In this case, ICI loses the revenue that would have come from its sale. Further, it must pay for the reprocessing or the disposal of the bad oil.
In order to keep the density on specification, the temperature at the bottom and the top of the tower must be maintained within one half of a degree of a target temperature. This is accomplished by altering the flow rates though the piping that surrounds the tower and/or by adjusting the heat exchange units attached to this piping. In practice, this is a non-trivial task. There have been cases when the operators of the tower have spent days attempting to return the density to an acceptable value. This process is directed by the the supervising engineers who communicate their instructions to the operators using heuristics similar to production rules. For example, to correct a very high quench oil density, an engineer could say to an operator:
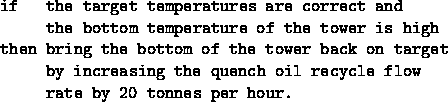
QUENCH contained 104 such rules.
Large petrochemical plants have certain features that complicate the process of evaluation. Safety is a paramount consideration. Unsafe operating conditions could cost the lives of the workers in these plants.
Large petrochemical plants produce hundreds of millions of dollars worth of chemicals each year. The loss of a single day's revenue can cost a company hundreds of thousands of dollars. These economic imperatives are so pressing that the prolonged operation of these plants at less-than-optimum performance can not be tolerated.
There are major difficulties associated with deriving precise formalisations of these complex systems. For example, a mathematical model of the quench oil system would require the solutions of hundreds of simultaneous equations. Certain parameters required in these equations require uncertain physical properties data; i.e. these parameters are not known. Consequently it is possible that after months of development work, a mathematical model of the quench oil system may be grossly inaccurate. Without precise formalisations, the only way to accurately predict the effects of certain changes to the plant is to make those changes and observe the effects.
The design of these large plants is typically customised to meet local requirements. Hence, the experience gained in (e.g.) controlling quench oil towers in other plants may not be relevant to this quench oil tower. In fact, the two supervising engineers who helped write QUENCH's rules are the only authorities on the control of the Olefines' quench oil tower. In the jargon of the psychologist or the statistician, there is no control group available for experiments on the tower. Further, there is no objective expertise that can be called upon to accurately assess the suggestions made by quench oil tower experts (be they computers or human beings).
One method for assessing the expertise of the program by running it in parallel with the existing system. The supervising engineers could compare QUENCH's suggestions with their own advice for problem situations. This method will be referred to as the obvious method and (the pre-disaster CSM evaluation will be called the preferred method). The obvious method has several advantages:
Regrettably, there are glaring design faults in the obvious method (discussed below).
Campbell and Stanley [Campbell & Stanley, 1970] assess experimental designs in terms of their internal and external validity.
Internal validity is the basic minimum without which any experiment is uninterpretable: Did in fact the experimental methods make a difference in this specific experimental instance? External validity asks the question of generalisability: To what populations, settings, treatment variables, and measurement variables can this effect be generalised? [Campbell & Stanley, 1970] (p4).
Internal validity is of particular concern. If we can not interpret the results of our experiment, then the experiment would have been pointless. Campbell and Stanley list several factors that could jeopardise internal validity. These factors have one feature in common: they could result in the effect of an experimental variable under study being confused with other factors. Each represents the effects of:
As to external validity, the claim of this paper is that the preferred method is generalisable to other expert system evaluations.
On several of the above points, the obvious method ranks quite well.
Hence, we reject the obvious method and move to the preferred method.
The preferred method requires CSMs and a pre-disaster point. This section offers CSMs. The next section offers a pre-disaster point.
There are three possibles CSMs for QUENCH:
Methods two and three are not exclusive. The system could be studied using both criteria.
We define the QUENCH pre-disaster point as follows: the point at which the supervising engineers realise that, despite their best efforts, the plant is defying their control strategies. If the plant reaches this pre-disaster point, then the control of the plant should be transferred to the best possible control system. In the case of testing QUENCH, the best possible control system is the supervising engineers. In the other case, when it is the engineers controlling the plant, the engineers would retain their authority to order alterations to the plant. They would then continue in their attempts to regain control over the plant processes.
Pre-disaster for QUENCH could be define as a bad quench oil density that was not improving, for (say) two days in succession. The time delay of two days allows for the expert time to recognize a problem, give advice for that problem, and for the tower to react to the expert's advice. If the at end of this time the density was still bad and not improving, then the expert would be deemed to have lost control of the tower.
The terms bad and not improving could be defined using the ranges developed during the implementation of QUENCH. The expert system has the ability to assigns symbolic tags to numeric ranges. The ranges for the quench oil density (expressed in kilograms per cubic meter) are shown in Table 1.
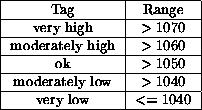
Table: Assessing quench oil density in QUENCH. From [Menzies & Markey, 1987].
The time rate of change in the density (expressed in change in density per 24 hours) has the symbolic tags shown in Table 2.

Table: Defining changes in QUENCH. From [Menzies & Markey, 1987].
Using these tags, we can define the pre-disaster point as a quench oil density that is either:
While the preferred method addresses the problem of objectivity seen with the obvious method, it will be effected by maturation. Consider the following:
Another way of expressing the above could be to say that the experiment is testing the expertise of a system that is learning. The evaluation experiment is to be attempted for an expert system who is in the shallow end of a learning curve. As a result of the experience gained during the evaluation process, the rule set would be improved and the expert system will move rapidly up the learning curve. The problem is that this improvement would occur concurrently with the experiment.
Kehoe (personal communication) offers an interesting resolution to the maturation problem. He argues that another CSM could be added to the system. Let F be the number of times the system is executed divided by the number of times the knowledge base is edited:
Another response to this maturation problem would be to to forbid the modification of the rules during the evaluation period; i.e. stop the system moving along the learning curve. This is an undesirable solution. It is highly probable that the existing rule set could be vastly improved. It was developed in a fortnight and this is a surprisingly short time for an expert system. Human cognitive processes are notoriously hard to formalise. The experience of expert systems developers is that any current specification of an expert solution to a problem is incomplete [Menzies, 1997b]. As experience with an expert system accumulates, inadequacies in the system's reasoning will always be detected. To correct these inadequacies, the system's knowledge based (e.g. QUENCH's rule set) must be modified. This cycle of flaw detection followed by knowledge base modification can continue indefinitely but concludes when the user is satisfied that the system can provide adequate performance in an adequate number of cases. Depending on the expert system application, this refinement process can continue for many years. Compton reports one case where the modification process seemed linear; i.e. it may never stop [Compton, 1994].
This is not to say that the existing rule set lacks any utility for controlling the tower. The problem of assessing QUENCH only arose since the supervising engineers reported that they are satisfied with the output of the program. The short development time might have resulted from the choice of problem. QUENCH was ICI Australia's first direct experience with expert systems. The quench oil tower problem was selected as a comparatively simple first test case for the expert system methodology. One of the factors that made the problem simple was the Olefines' supervising engineers. These people spend significant amounts of their time explaining the workings of the Olefines plant to the control room operators. Hence, they have had considerable experience in expressing their knowledge in a concise manner.
Nevertheless, it is the author's belief that the program's rule set would benefit from further modification. It would be foolish to believe that QUENCH had somehow avoided the need for the long term knowledge base refinement process found to be necessary in other expert system application. Further, ICI would prefer the best possible control system for their tower. They may be less than enthusiastic about an experiment that inhibits the development of an optimum rule set. Hence, except for the Kehoe extension, I offer no revision to the preferred method to handle maturation.
At the time of creating the QUENCH system, there was nothing in the petrochemical literature about empirical evaluation of expert systems. For example, in [Morari & McAvoy, 1986] and [Ctc96, 1986] we can read hundreds of pages on American and Japanese expert systems and never read anything about evaluation. Perhaps the reason for this curious omission is the difficulties inherent in the task. As seen above, a whole host of factors threaten the internal validity of evaluating experiments in such plants.
More generally, business-level empirical KBS evaluation is rarely performed in the knowledge engineering field (but some exceptions were noted in the introduction). By business-level, I mean measures of a running expert system which relate to the business case which motivated the development of that expert system. A CSM is a business-level evaluation measure. Elsewhere, I have criticised this lack of evaluations in the knowledge engineering field [Menzies, 1997b, Menzies, 1997a]. This critique motivated Feldman and Compton [Feldman et al., 1989], followed by myself and Compton [Menzies & Compton, 1997], to devise and refine a general graph-theoretic abductive framework for assessing a KBS using a library of known or desired behaviour is discussed in [Menzies, 1995]. An example of using this framework is given in [Menzies & Compton, 1997]. One advantage of this framework over standard verification and validation is that the computational limits of the technique can be studied via mutators which auto-generate variants of known graphs [Menzies, 1996, Waugh et al., 1997, Menzies et al., 1997].
General principles for comparative empirical evaluation of knowledge engineering methods are discussed in [Menzies, 1997a]. Such comparative evaluations can take the form of:
The verification and validation community offer test procedures for KBS:
CSMs let us evaluate a system without requiring a panel of experts of a database of known or desired behaviour. A behavioral success criteria is derived from the business case that motivated the construction of the expert system. The system is then executed and measurements are made which inform the success criteria. Coupled with a pre-disaster point, CSMs let us statistically evaluate a system in operation, without compromising that operation.
The general themes of CSMs presented here are as follows. CSMs are usually very domain-specific since they reflect the contribution of the behaviour of the software in a particular business context. Hence, they typically do not refer to internal properties of a program and they cannot be developed by programmers without extensive input from business users. CSMs are usually obvious, but only in retrospect: a CSMs can take weeks of analysis to uncover. CSMs may only be collectible from the working system. However, CSMs should be explored very early in the life cycle of an expert system since CSM collection may imply the extension of the system's design to collect the required data.