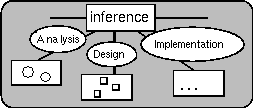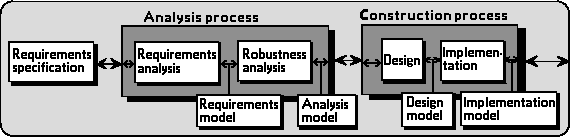
Figure 1.1. The analysis and construction parts of the OOSE process.[Jacobson et al., 1992].
Päivikki Parpola
Helsinki University of Technology
Department of Computer Science and Engineering
Hauenkalliontie 2 B 54, FIN-02170 Espoo, Finland
E-mail: pparpola@cc.hut.fi
Abstract:
Models, corresponding to different stages of knowledge-base developing, are integrated using
seamless
transformations. Knowledge is initially elicited through dependency graphs (DG), which can be seen as a
form of conceptual graphs. This enables combination of knowledge from different sources at an early stage
of development. DGs, together with associated descriptions, can be transformed (seamlessly) into an initial
inference structure with associated verbal descriptions. Its components refer to components of the domain
model, constructed simultaneously with the DGs. Other seamless transformations are based on sharing the
inference structure between analysis, design and implementation descriptions. The structured models can be
implemented using object-oriented programming.
Knowledge acquisition(KA), i.e. development and maintenance of knowledge bases (KB), can be divided into several phases, performed sequentially and iteratively. The most commonly recognized phases are requirements definition, analysis, design, and implementation. The disintegration, or gap, between phases has been recognized during early stages of KA [Marcus, 1988a; Motta, Rajan and Eisenstadt, 1988].
The problem has been overcome in narrow-focused automated tools, e.g. S-SALT [Leo, Sleeman and Tsinakos, 1994] and PROTČGE II [Eriksson et al., 1995]. In problems that cannot use scope-restricting heuristics, results achieved in an earlier phase of KA often cannot be fully utilized, but part of the work has to be duplicated. In general cases, the gap problem has been attacked for example through maintenance of the analysis model structure (recommended in structured KA methodologies like CommonKADS [Schreiber et al., 1994; de Hoog et al., 1994]). However, this maintenance is manual.
Object-oriented software engineering (OOSE) [Jacobson et al., 1992] views software engineering (SE) as an industrial process, and stresses the advantages of using objects in it. OOSE acknowledges that, in almost all systems, requirements change unpredictably, and the systems have to be designed for incremental development over their life-cycle.
Figure 1.1. The analysis and construction parts of the OOSE process.[Jacobson et al., 1992].
OOSE, partially illustrated in figure 1.1, consists of the iterative processes of analysis, construction, and testing. Requirements are used as input. Object-oriented (OO) models are created or modified during each phase. The requirements model consists of three parts, a domain model, a use-case model and an interface description. The analysis model is based primarily on the use case model, not the domain model, as there is experience indicating that the logical structure is more stable than the domain structure. By focusing on the more important aspects at an early stage, a base is laid for a maintainable system structure.
The aim is to keep the logical structure of the analysis model in the final system. An object identified during analysis must be found again in the code, so that the system is easy to understand and durable under easy modifications. Here, built-in traceability of object-orientedness (OO) is an important characteristic. Different parts of the system can simultaneously be at different stages of development. Some parts may be reused, possibly with slight modifications.
The transitions between models are seamless - we are ideally able to tell in a foreseeable way how to get from objects in one model to objects in another model. This is absolutely crucial for an industrial development process, as the result must be repeatable. Rules for transformations are defined separately between each two models. To be able to maintain the system it is also necessfary to have traceability between the models. This will come as a side-effect of the seamless nature of model transformations.
A major factor causing the gap is apparently the difference between the observation- oriented nature of gathering knowledge, and the operationality-oriented nature of producing a KB. Different approaches often lead to different representations, so that the analysis models normally cannot be directly utilized in developing the executable formalisms. For bridging the gap, it is proposed that representations of different phases be integrated. In addition, representation of knowledge is structured. To strengthen the effects of uniform representation and suitable structuring, seamless transformations between models corresponding to different phases are defined.
The paper is structured as follows: Section 2 explains the three proposals for producing more integration in the development of KBs: unified representation, suitable representation structure, and seamless transformations. Section 3 describes seamless development of a KB, presenting a technique that is described step by step. Section 4 gives an example of using seamless development. Section 5 contains discussion and conclusions.
As mentioned in the introduction, one apparent cause of disintegration is the use of different representation formalisms during different phases of development. Two representations are proposed for use in integration:
| aggregation | An attribute that is itself an object |
| association | A relation between object classes. For each class involved, it can be defined, whether the association applies to one single instance or an arbitrary number of instances of the class. |
| attribute | Description of a feature of the corresponding concept. |
| (object) class | A counterpart for a concrete or abstract real-world concept, or a generalization of other concepts. An object class is a template for all its instances. |
| inheritance, subclass, superclass | Inheritance is a mechanism allowing object classes to form a hierarchical structure, called an inheritance hierarchy or a class hierarchy. Parent nodes in this hierarchy are called superclasses, whereas child nodes are called subclasses. In this structure, subclasses by default inherit properties (attributes, methods) from their superclasses. |
| (object) instance | An individual realization of an object class. Attributes of the class are assigned values in an instance. |
| meta-class | A class, the instances of which are themselves classes. |
| method | Definition of a class-specific behaviour as a reaction to calling a method of an object instance with certain attributes. |
| object | Normally denotes an object instance. However, the term can be used in a more abstract sense, leaving unspecified whether an object class or an object instance is used. The term can also refer to the entire OO paradigm. |
Uniform formalism will now be combined with structured representation of knowledge, consisting of three main types of networks:
The three networks are described in more detail in sections 2.2.1, 2.2.2 and 2.2.3. The idea of an inference structure referring to the domain model comes from KADS [Wielinga and Breuker, 1986; Hesketh and Barrett, 1989] and CommonKADS [Schreiber et al., 1994; de Hoog et al. , 1994] methodologies. Here, however, attributes instead of concepts are referred to. The inference structure is shared among different phases of development. Dependency graphs have been added.
The three types of networks that are connected to each other are illustrated in figure 2.1. Connections between CGs, via use of the same concepts, are illustrated by exporting these concepts, and drawing lines to identical concepts in different graphs. The notation for identical concepts in different CGs is adopted from problem maps, presented by Lukose [Lukose, 1996].

Figure 2.1. CGs used in seamless structured KA. Different CGs are
separated by thickened lines. Concepts, appearing outside CGs, indicate interdependencies between CGs
through use of the same concepts.
A domain model (DM) is a description of relevant parts of the domain. Relevant means here "involved in the task at hand". A DM consists of concepts, with attributes describing (the state of) different features, and relations, describing more or less permanent relationships between concepts or attributes of concepts. Relations between concepts include inheritance relations.
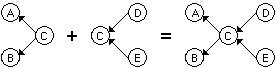
A dependency graph (DG) consists of concepts and binary directed dependency relations (dependencies) between concepts. Concept nodes have unique names, used as labels. If all dependencies of a DG are of the same type, the corresponding arcs (arrows) need not be labelled, If several relation types are used, the type of each dependency in a DG has to be indicated. Untyped DGs have been used in a system called Matias [Kontio, 1991]. The automated tools MOLE [Eshelman, 1988] and SALT [Marcus, 1988b] use untyped and typed dependencies between events.
If multiple sources of knowledge are considered, a DG can be created separately for each source. These initial DGs can be combined, as will be described below. In order to be able to combine knowledge acquired from different sources, it is first necessary to homogenize the terminology used. Also a domain model (see section 2.2.1), relating different concepts to each other, is necessary.
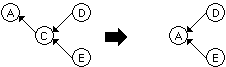
DGs can be considered as special forms of conceptual graphs CGs (see section 2.1). Dependencies are taken as conceptual relations with one arc, in which the label may be omitted. In DGs, concept labels may also be considered as types, i.e. often type(c)=c. If a superclass of c has the same essential properties from the point of view of the application, type (c) can also be this superclass. DGs can be combined using rules, described below.
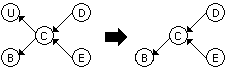
Theorem A group of DGs can be developed using the following rules:
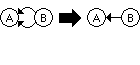
Figure 2.5. One of two duplicate dependencies may be
removed, however, preserving text descriptions of both.
Proof
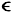 u, d
v, c=d. The common
generalization [Sowa84, definition 3.5.5] w of DGs u and
v would be a DG with the single concept d=dw. The join of
u and v is truth-preserving if
u, d
v, c=d. The common
generalization [Sowa84, definition 3.5.5] w of DGs u and
v would be a DG with the single concept d=dw. The join of
u and v is truth-preserving if  1:w
-> u and 2:w
-> v are compatible [Sowa, 1984, definition
3.5.6]:
1 dw)
1:w
-> u and 2:w
-> v are compatible [Sowa, 1984, definition
3.5.6]:
1 dw)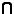 type(2dw)=type(c) type(d)=type(c) >
type(2dw)=type(c) type(d)=type(c) >  ,
1dw)type(2dw)::referent(1) and type(1dw)type(2dw)::referent(2) (type(c)::referent(c) and
type(c)::referent(d)), and
,
1dw)type(2dw)::referent(1) and type(1dw)type(2dw)::referent(2) (type(c)::referent(c) and
type(c)::referent(d)), and
Concepts can also be generalized, [Sowa, 1984, p. 100]. The validity of combining graphs that have not been compatible before generalizations of concepts depends on the domain, i.e. whether essential properties of the original concept hold also in the generalized concept.
It has to be kept in mind that dependencies presented in a DG need to be true only in a certain situation, and that these situations are not necessarily the same for all dependencies. In other words, the combined DG is only a hypothesis. Its value is in bringing together different pieces of knowledge, and showing a way in which they might be combined. Descriptions and possibly overlapping contexts provide more information.
DGs with undefined contexts present possibilities, not definite logical implications. Thus, combination of DGs cannot be described with normal terms of logic, like unification.
The inference model is actually an integration of three models, the analysis, the design and the implementation models. These three models share the inference structure (IS), consisting of roles and inferences. Roles refer to a number of attributes of concepts in the domain model. To each inference are attached three descriptions that can contain different numbers of blocks (figure 2.6.a). Submodels (e.g. the analysis model) consist of the shared IS, together with corresponding (e.g. analysis) descriptions of inferences. Thus, to the IS are attached three sets of descriptions, each belonging to one of the models forming the inference model (figure 2.6.b).
In KB construction, logical details of knowledge can be presented in the analysis models. Here it must be remembered that in the iterative process of development each phase is visited several times, so 'analysis model' does not always mean the initial model. Need for changes may be acknowledged in other phases of development, but through traceability between models the corresponding parts in the analysis model can be detected. The changes can then be made first to the analysis model and only after that be propagated to other models. These modifications include modifications of the IS.
Keeping in mind that the process is iterative, it can be said:
| In constructing a KB, all details can be first presented at the analysis phase, and the effort required in the design and implementation phases is to formalize them. |
In addition to using the same formalism in all models, and integrating the representation structure, one more way is used to integrate development of KBs. Seamless transformations are in KA templates for semi- automatic transformations between different models. Most of these transformations can be defined in both directions. Use of seamless transformations provides traceability between different models and careful utilization of work already done.
Seamless development of KBs consists of a sequence of seamless transformations. Figure 3.1 gives an overview of a technique for seamless development, called Seamless Structured Knowledge Acquisition (SeSKA). Three kinds of transformations are used: DGs are combined, the combined DG is transformed to the analysis model, and the analysis model is transformed via the design model to the final implementation model. The four rightmost transformations in figure 3.1 (DG <-> IS, DG <-> analysis, analysis <-> design, and design <-> implementation) are truly seamless, i.e. also two-directional. Transitions from an IS and analysis descriptions of inferences to DG with descriptions are ambiguous.
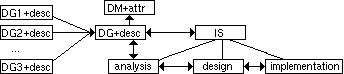
Figure 3.1. An overview of the SeSKA
technique.
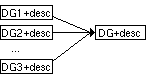
Figure 3.2. Combining acquired DGs in
SeSKA.
When pieces of knowledge elicited from different sources are presented in the form of DGs, they can be combined (figure 3.2) according to the rules presented in section 2.2.2. The rules 'copy', 'remove', 'join' and 'simplify' can be used to develop and combine a group of DGs.
Combination of conceptual graphs is useful in building a hypothesis. More information is provided through descriptions and contexts.
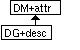
Figure 3.3. Forming the DM based on the DG in
SeSKA.
The term 'class', in context of a DG, refers to an attribute class of the DM, i.e. either an actual aggregate attribute class, or a simple attribute of a concept class. The DM in SeSKA is constructed in parallel with DG(s) (figure 3.3). As domain concept attributes of the DM are concepts in the DG, relevant concepts and attributes are automatically selected to the DM. Descriptive comments may be attached to all dependency relations.
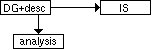
Figure 3.4. Forming the inference structure and the analysis
descriptions of inferences based on the DG in SeSKA.
A role refers to a collection of attributes of different concepts. These attributes are called member attributes of the role. The initial inference structure and the associated analysis descriptions can initially be constructed based on inferential dependencies with their associated descriptions (figure 3.4). One way to do this [Parpola, 1995], is to utilize dependencies defined, so that a role is formed from attributes that one attribute depends on, as illustrated in figure 3.5. Also other heuristics can be used, as well as manual construction and editing. If descriptions of dependencies have been given, the combination of descriptions of relevant dependencies form the first approximation of the analysis-level description of an inference.

Figure 3.5. Forming roles based on dependencies, in an
application for granting a bank loan.
c=customer, l=loan

Figure 3.6.Forming a DG based on the inference structure and
the analysis descriptions
Forming a DG based on the analysis model (figure 3.6) is not unambiguous, as several different DGs can produce the same analysis model. One way to form a DG is to take the roles connected by an inference, and set all concepts referenced by the conclusion role to depend on all concepts referenced by the premise role. The analysis description of the inference can be attached to all dependencies formed. Descriptions of dependencies can then be edited to include only information concerning a particular dependency between two concepts. The process can be repeated for each inference.
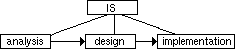
Figure 3.7. Formalizing descriptions of inferences in
SeSKA.
Analysis descriptions are formalized to implementation descriptions, e.g. rules, via design descriptions (figure 3.7). The process of refinement is iterative and modular. Instances of member attributes of roles are used as variables in the inference process. Inferences defined between two roles use member attributes of the premise role as input, and produce values of member attributes of the conclusion role as output. The internal structure of an inference is either a set of rules, or a function written in some programming language. Different inferences can be defined in different ways.
When an inference uses rules, the format of pseudo-representation available is a rule table, containing a premise part (on the left) and a conclusion part (on the right). Different rules are presented one below the other. In an individual rule, different premises can be presented in a kind of structured block diagram (figure 3.8). Conclusion values, to be assigned to conclusion variables, are presented in columns for different conclusion variables. Rules presented in a rule table are directly converted into rules presented in the implementation formalism used.
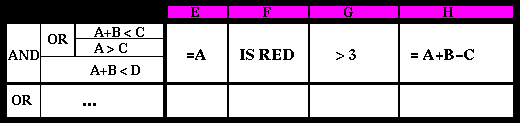
Figure 3.8. Rule table of an Inference between Roles with
member attributes (A B C D) and (E F G H).
If functions or procedures are used to define inferences, the input parameters must be member attributes of a premise role. Attributes modified (either through side effects during execution, or as result values) must be member attributes of the conclusion role. For reuse purposes, formal parameters are defined through ordinal numbers of attributes referenced.
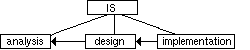
Figure 3.9. Tracing back to earlier models.
Often a need for change is acknowledged in implementation (or design). According to principles of seamless development, the changes, however, are not done directly in these models. Instead, the corresponding parts are traced in the analysis model, possibly via the design model. using the shared inference structure (figure 3.9). Corrected forms of action are first verbalized and then propagated to the more formal models. It may often be the practice of course to describe changes that have already been done, but the important thing is to keep the logical description up to date. However, representing the problem on the abstract (analysis) level may sometimes help in finding the solution.
Multiple sclerosis is a disease of the central nervous system, causing malfunctions mainly in the motory and sensory nerves or sight nerves. The symptoms are caused by auto-immune reactions against the protective myelin sheath of nerves in the spinal cord or in the white matter of the brain. The mechanism of damage is quite well-known, but there is disagreement on the causes. Mainstream research on MS concentrates on developing drugs. However, the best achievement until now only decreases the probability of new symptoms (for those who can tolerate it).
There has also been some research on the effects of nutrition on MS, mainly on fatty acid levels, absorption and effects. Antioxidants, for example, have also been investigated. Research on nutritients is regrettably scattered: only a small number of researchers try to build a conclusive hypothesis. The technique described in this paper will now be used to build a hypothesis of how the results of different research workers might be combined.
Figure 4.1 presents a hierarchy of fatty acids to provide a chemical background.
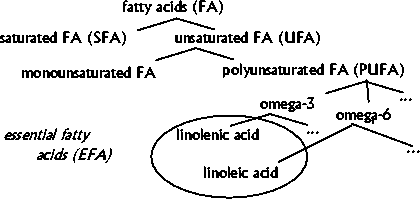
Figure 4.1 Inheritance hierarchy of fatty
acids.
Some research results concerning certain groups of fatty acids, vitamins and minerals have been elicited
from article abstracts, and been presented as DGs, by the author (figures 4.2 - 4.9). Captions show the
research results elicited, used as descriptions associated to dependencies. A few generalisations, e.g.
replacing linoleic acid by  6, have been made in the DGs. This
particular replacement is based on some properties that are common to the 6 group of fatty acids [FAO, WHO, 1993]. Captions show the
original form of results elicited. All of these figures describe the situation in an MS patient, possibly
compared with a healthy person.
6, have been made in the DGs. This
particular replacement is based on some properties that are common to the 6 group of fatty acids [FAO, WHO, 1993]. Captions show the
original form of results elicited. All of these figures describe the situation in an MS patient, possibly
compared with a healthy person.
 3
(levels) < normal [Cunnane et al., 1989, Neu,
1985]; b) 6 < normal [Cunnane
et al., 1989;Fisher et al., 1987; Navarro and
Segura, 1988; Navarro and Segura, 1989]; c) saturated FA >
normal[Navarro and Segura; 1988, Navarro and
Segura, 1989]. d) A predisposing factor causing MS seems to be related to a disturbance of the lipid
and fatty acid metabolism [Neu, 1985], A common aspect appears to be a lipid
imbalance involving the essential fatty acids (EFA), linoleic and linolenic, and trace fatty acids which result
from faulty lipid metabolism [Marshall, 1991].
3
(levels) < normal [Cunnane et al., 1989, Neu,
1985]; b) 6 < normal [Cunnane
et al., 1989;Fisher et al., 1987; Navarro and
Segura, 1988; Navarro and Segura, 1989]; c) saturated FA >
normal[Navarro and Segura; 1988, Navarro and
Segura, 1989]. d) A predisposing factor causing MS seems to be related to a disturbance of the lipid
and fatty acid metabolism [Neu, 1985], A common aspect appears to be a lipid
imbalance involving the essential fatty acids (EFA), linoleic and linolenic, and trace fatty acids which result
from faulty lipid metabolism [Marshall, 1991].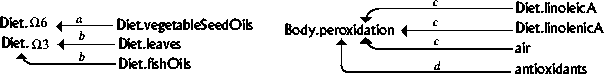
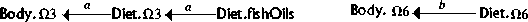 3 is
absorbed from dietary fish oils [Nightingale et al., 1990] b) linoleic acid
showed significant correlations with diet.[Fitzgerald et al.,
1987]
3 is
absorbed from dietary fish oils [Nightingale et al., 1990] b) linoleic acid
showed significant correlations with diet.[Fitzgerald et al.,
1987] 3 and 6 fatty acids caused reduction of the
severity and frequency of relapses and a mild overall benefit [Bates,
1990].
3 and 6 fatty acids caused reduction of the
severity and frequency of relapses and a mild overall benefit [Bates,
1990].
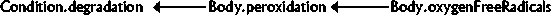

The DM, illustrated in figure 4.10. has been formed, using the concepts and attributes appearing in the DGs of section 4.2. Simultaneous formation of DGs reveals what attributes the concepts should have.

Figure 4.10. Domain model for nutrition of a person with
MS. The rounded rectangles represent concepts, and the bullets inside them attributes. The stabile relation
between concepts 'Diet' and 'Body' is 'Intake'. 'Condition' and Leukotrienes' are aggregate attributes (section
2.1.1) of 'Body'.
An example of combining DGs will now be given. DGs 1 and 3b, illustrated in figures 4.2 and 4.4, are combined, based on the appearance of
node 'Body.6' in both DGs, and rule 'join' in section 2.2.2. The resulting DG is illustrated in figure 4.11.
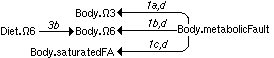
Figure 4.11. Combination of DGs 1 and 3b.
After joining DGs 3a and 2ab (in figures 4.4 and 4.3), there are duplicate relations between 'Diet.fishOils' and 'Diet.3', so rule 'simplify' has to be used. After joining DGs 4 and 5 also, the
DG in figure 4.12 is achieved.
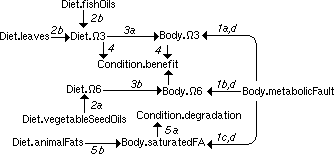
Figure 4.12 Combination of DGs 1, 2, 3, and
4.
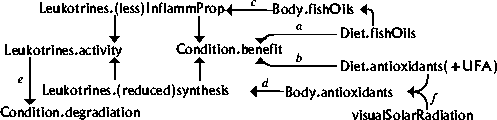
Starting from a different point, DGs 6, 7, and 8 are combined. After joining DGs 6 and 7 by node 'Body.peroxidation', DG 8 can also be joined. There are several nodes that have to be joined, 'Condition.degradation', 'Diet.antioxidants' and 'Body.antioxidants', causing a duplicate relation to be simplified bet ween 'Diet.antioxidants' and 'Body.antioxidants' The combined DG is illustrated in figure 4.13.
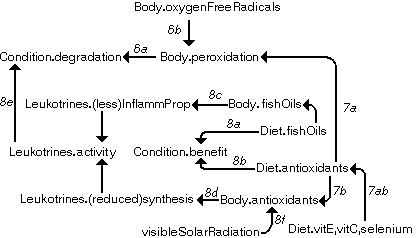
Figure 4.13. Combination of DGs 6, 7 and
8.
When DGs 1 - 8, presented in figures 4.2 - 4.9, or alternatively the two combined DGs in figure 4.12 and figure 4.13, are combined, the DG illustrated in figure 4.14 is achieved. Two additional (descriptive) links have been added. These links are unlabelled. Explanations associated with dependencies can be found from the captions of the DG figures in section 4.2 (numbers attached to dependencies refer to the numbers of DGs, letters to the dependencies in these DGs).
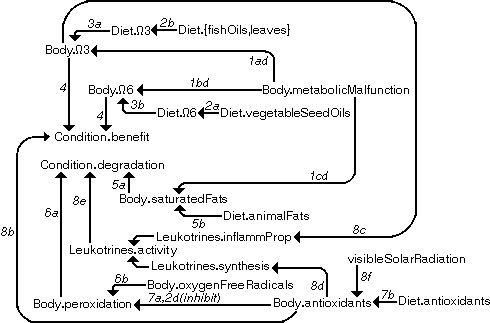
Figure 4.14 The combined DG. The numbers associated to
dependency arcs refer to DGs in section 6.2.
The combined diagram is in agreement with the results of some conclusive authors [Marshall, 1991; Hutter, 1993], as well as with the author's own experiences.
The IM, illustrated in figure 4.15, is based mainly on dependencies in figure 4.14, using the technique described in section 3.3 - combining attributes that a certain attribute depends on, as a role. Roles have then been given identifiers and descriptive names. The contents of roles are described in the caption. Inferences simply refer to the dependencies between components of roles. Explanations of the inferences are those of component dependencies.
A simple example of a transformation will now be given. 'Diet.3' depends on 'Diet.fishOils' and 'Diet.leaves', which are combined to form the role
'(A)DietarySourcesOf3' in figure
4.15, Capital letters in parenthesis are used only for identification of roles in the caption, the actual
name is supposed to be more descriptive. 'Diet.3' itself is a
member of '(B)3factors'. A more complex example is that
'Condition.benefit' depends in figure 4.14 on 'Body.3', 'Body.6' and 'Body.antioxidants' that are
collated to the role '(E)BenefitFactors' in figure 4.15.
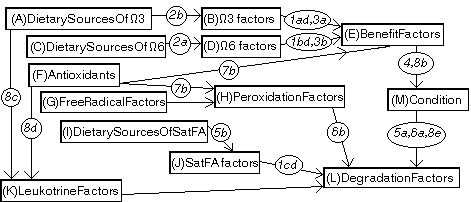
Figure 4.15. The initial inference structure with analysis
descriptions. The numbers associated with dependency arcs refer to initial DGs in Section 4.2. Contents of ROLES: (A){Diet.fishBodyOil, Diet.leaves}; (B){Diet.3, Body.metabolcMalfunction}; (C){Diet.vegetableSeedOils};
(D){Diet.6, Body.metabolicMalfunction)}; (E){Body.3, Body.6,
Diet.antioxidants}; (F){E,C,A,selenium}; (G) ?; (H){Body.oxygenFreeRadicals, Diet.antioxidants};
(I){Diet.saturated(Animal)Fats}; (J){Diet.saturatedFats, Body.metabolicMalfunction};
(K){Leukotrines.inflammProp, Leukotrines.synthesis}; (L){Body.saturatedFats, Leukotrines.activity,
Body.peroxidation}; (M){Condition.degradation, Condition.benefit}
Only an example is taken of rule formalisation. The verbal description of rule number '1bd,3b' is
"(Due to a fault in FA metabolism) Body.6 < normal;
6 is absorbed from dietary supplementation." The same
matter can be presented in a rule table in figure 4.16.a, which directly
converts into the rules in figure 4.16.b, presented in the implementation
language. As mentioned in section 3.5, the development process is iterative and
modular.
The gap between phases of knowledge acquisition (KA) is a problem in general cases, when no specific heuristic is applicable. Results achieved in an early phase of KA often cannot be fully utilized, but part of the work has to be duplicated. Object-Oriented Software Engineering (OOSE) uses seamless transformations to integrate object-oriented (OO) models, corresponding to different phases of development. Seamless transformations are characterized in the following way: "We are ideally able to tell in a foreseeable way, how to get from objects in one model to objects in another model".
It is proposed to attack the problem of disintegration between phases by combining three approaches: unified representation formalism, structured representation, and seamless transformations. The representation formalisms considered are conceptual graphs (CG), to be implemented, it is suggested, using OO networks. The representation structure includes dependency graphs (DG; a specialization of CGs describing inferential dependencies), a domain model, and an inference structure (IS) that is shared by descriptions for different phases of development. Sharing of the IS is possible as the presentation structure can be different in different descriptions, and modifications of the IS, required in other phases, can be made in the analysis phase. Seamless development of knowledge bases (KB) is a series of seamless transformations, following a certain template. The transformations are performed iteratively. Templates are defined for a number of seamless transformations: combining DGs, transforming a combined DG to an initial inference structure, building the domain model based on components in DGs, and transitions based on the shared inference structure.
SeSKA has been tested manually. A tool supporting SeSKA is under development using the programming language Java. Network templates will be implemented for the domain model, the dependency graph and the inference model. Components of these networks will be templates for components of the actual networks created by the user.
The approach provides three kinds of contribution to KA:
Seamless development of KBs is a rather thin approach, as it ignores, for example, all aspects of user interface development. This, however, makes it a very easy way of development, in fact ideal for fast prototyping. When used for real development, it has to be combined with other tools.
I thank Pekka A. Jussila, MSc. (tech.), for his fruitful comments, and his help in practical matters, and professor Markku Syrjänen for his advice and encouragement. I also thank Dr. Marja Mutanen for her help in finding literature on the basic properties of groups of fatty acids, and Mr. Michael Vollar for checking correctness of the English language.
Bates, D. (1990). Dietary lipids and multiple sclerosis, Uppsala Journal of Medical Sciences - Supplement Vol. 48.
Booch, G. (1991). Object-Oriented Design with Applications. Menlo Park, California: The Benjamin/Cummings Publishing Company.
Clausen, J., Jensen, G.E. and Nielsen, S.A. (1988). Selenium in chronic neurologic diseases. Multiple sclerosis and Batten's disease. Biological Trace Element Research, Vol. 15 (No. 1).
Cunnane, S.C., Ho, S.Y., Dore-Duffy, P., Ells, K.R., Horrobin, D.F (1989). Essential fatty acid and lipid profiles in plasma and erythrocytes in patients with multiple sclerosis. American Journal of Clinical Nutrition, Vol. 50 (No. 4).
Eriksson, H., Shahar, Y., Tu, S.W., Puerta, A.R. and Musen, M.A. (1995). Task Modelling with Reusable Problem-Solving Methods. Artificial Intelligence, Vol. 79 (No. 2).
Eshelman, L. (1988). MOLE: A Knowledge-Acquisition Tool for Cover-and-Differentiate Systems, in Marcus, S. (Ed.), Automating Knowledge Acquisition for Expert Systems. Kluwer International Series in Engineering and Computer Science. Boston: Kluwer Academic Publishers.
FAO (Food and Agriculture Organization of the United Nations), WHO (World Health Organization) (1993). Fats and Oils in Human Nutrition. Report of Joint Expert Consultation in Rome. FAO Food and Nutrition Paper 57.
Fisher, M., Johnson, M.H., Natale, A.M. and Levine, P.H. (1987). Linoleic acid levels in white blood cells, platelets, and serum of multiple sclerosis patients. Acta Neurologica Scandinavica, Vol. 76 (No. 4).
Fitzgerald, G., Harbige, L.S., Forti, A. and Crawford, M.A. (1987). The effect of nutritional counselling on diet and plasma EFA status in multiple sclerosis patients over 3 years. Human Nutrition. Applied Nutrition, Vol. 41 (No. 5).
Goldberg, A. (1984). Smalltalk -80: The Interactive Programming Environment. Reading, Massachusetts: Addison-Wesley.
Hesketh, P., and Barrett, T. (1989). An Introduction to KADS Methodology, Esprit Project P1098 report M1, STC Technology Ltd.
de Hoog, R., Martil, R., Wielinga, B., Taylor, R., Bright, C., and van de Velde, W. (1994). The CommonKADS model set. KADS-II//M1 /DM1.1b/UvA/18/6.0/FINAL. DM1.1c.
Hutter, C. (1993). On the causes of multiple sclerosis. Medical Hypotheses, Vol. 41 (No. 2).
Jacobson, I., Christerson, M., Jonsson, P., and Övergaard, G. (1992). Object-Oriented Software Engineering, A Use Case Driven Approach. Reading, Massachusetts: Addison- Wesley.
Kontio, J., (1991). Matias: Development and Maintenance of a Large but Well-defined Application. Expert Systems with Applications, Vol. 3 (No 2).
Leo, P., Sleeman, D., and Tsinakos, A. (1994). S-SALT, A Problem Solver Plus; Knowledge Acquisition Tool Which Additionally Can Refine Its Knowledge Base, in EKAW -94, the 8th European Knowledge Acquisition Workshop in Hoegaarden, Belgium.
Lukose, D. (1996). MODEL-ECS: Executable Conceptual Modelling Language. 10th Banff Knowledge Acquisition for Knowledge-Based Systems Workshop in Banff, Alberta, Canada.
Marcus, S. (1988a). Introduction, in Marcus, S. (Ed.), Automating Knowledge Acquisition for Expert Systems. Kluwer International Series in Engineering and Computer Science. Boston: Kluwer Academic Publishers.
Marcus, S. (1988b). SALT: A Knowledge-Acquisition Tool for Propose- and-Revise Systems, in Marcus, S. (Ed.), Automating Knowledge Acquisition for Expert Systems. Kluwer International Series in Engineering and Computer Science. Boston: Kluwer Academic Publishers.
Marshall, B.H. (1991). Lipids and neurological diseases. Medical Hypotheses, Vol. 34 (No. 3).
Motta, E., Rajan, T., and Eisenstadt, M. (1988). A Methodology and Tool for Knowledge Acquisition in KEATS-2, in 3rd AAAI-Sponsored Knowledge Acquisition for Knowledge- Based Systems Workshop in Banff, Alberta, Canada.
Navarro, X. and Segura, R. (1988). Plasma lipids and their fatty acid composition in multiple sclerosis. Acta Neurologica Scandinavica, Vol. 78 (No. 2).
Navarro, X., and Segura, R. (1989). Red blood cell fatty acids in multiple sclerosis. Acta Neurologica Scandinavica, Vol. 79 (No. 1).
Neu, I.S. (1985). Metabolic aspects of multiple sclerosis (Stoffwechselaspekte der Multiplen Sklerose). Wiener Medizinische Wochenschrift, Vol. 135 (No. 1-2).
Nightingale, S., Woo, E., Smith, A.D., French, J.M., Gale, M.M., Sinclair, H.M., Bates, D. and Shaw, D.A. (1990). Red blood cell and adipose tissue fatty acids in mild inactive multiple sclerosis. Acta Neurologica Scandinavica, Vol. 82 (No. 1).
Parpola, P. (1995). Object-Oriented Knowledge Acquisition, Licentiate's Thesis. University of Helsinki.
Rumbaugh, J., Blaha, M., Premerlani, W., Eddy, F., and Lorensen, W. (1991). Object-Oriented Modeling and Design}. Englewood Cliffs, New Jersey: Prentice-Hall.
Schreiber, G., Wielinga, B., de Hoog, R., Akkermans, H. and van de Velde, W. (1994). CommonKADS, a Comprehensive Methodology for KBS Development. IEEE Expert, Vol. 9 (No. 6).
Sinclair, H.M. (1984). Essential fatty acids in perspective. Human Nutrition. Clinical Nutrition, Vol. 38 (No. 4).
Sowa, J. (1984). Conceptual Structures: Information Processing in Mind and Machine. Reading, Massachusetts: Addison-Wesley.
Steele, G. L.(1990), Common Lisp, the Language, Second Edition. USA: Digital Press.
Swank, R.L. (1991). Multiple sclerosis: fat-oil relationship. Nutrition, Vol. 7 (No. 5).
Toshniwal, P.K., and Zarling, E.J. (1992). Evidence for increased lipid peroxidation in multiple sclerosis. Neurochemical Research, Vol. 17 (No. 2).
Wielinga, B., and Breuker, J. (1986). Models of Expertise in ECAI '86, Seventh European Conference on Artificial Intelligence in Brighton, UK.