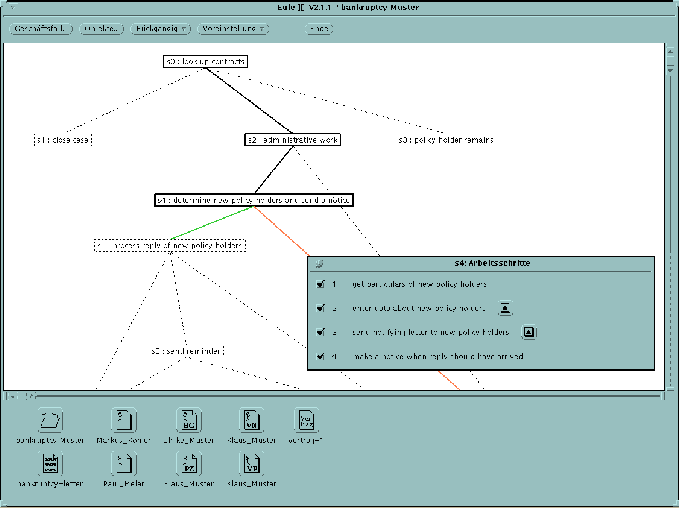
Figure 1: An Office Task Description as the User Sees it
Ulrich Reimer
Swiss Life, Information Systems Research Group, Postfach, CH-8022 Zürich, Switzerland
ulrich.reimer@swisslife.ch
The paper starts with a discussion of the roles an organizational memory (OM) should play and what kind of knowledge should go into it. We then identify two kinds of integration problems. The first one is concerned with integrating the knowledge bases of different knowledge-based systems employed in an organization into one physically or virtually unified knowledge base which is to be considered as part of the organization's OM. The second problem concerns the integration of several representations of the same knowledge with different degrees of formalization, ranging from formally represented knowledge via semi-structured text to plain text. It is argued to solve the two integration problems by making use of a high-level language whose representation ontology is explicitly defined. Such a language is rather comprehensive, but only parts of it are used at a time and actual inferencing is done in optimized, low-level formalisms to which this language is compiled.
It is increasingly acknowledged that knowledge is one of the most important assets of organizations. Especially in industrialised countries with expensive but highly educated employees, products and services must be outstanding in terms of innovation, flexibility, and creativity. A prerequisite for being able to face current and future challenges is the systematic management of the knowledge assets. An advanced knowledge management requires what is called an organizational or corporate memory (not necessarily (fully) computerized [Stein, 1995]). It is the central repository of all the knowledge relevant for an organization. Building up such organizational memories (OM) and making them available to people and application systems with quite converging needs is a big challenge which can only be met by an integration of approaches from various fields of computer science as well as business and administration science [van Heijst, van der Spek, and Kruizinga, 1996].
There are two major roles an organizational memory can in principle play. In one role it has a more passive function and acts as a container of knowledge relevant for the organization (including meta-knowledge like knowledge about knowledge sources). It can be queried by a user who has some specific information need.
The second role an OM can adopt is as an active system that disseminates knowledge to people wherever they need it for their work. This second functionality is not just mere luxury but of considerable importance as users often do not know that an OM may contain knowledge currently helpful to them. Furthermore, querying an OM whenever the user thinks it might be possible that the OM contains relevant knowledge is not practical because the user does not always think of querying the OM when it might actually be helpful and because it would be too time consuming (as it interrupts the users primary work and takes time for searching and browsing the OM).
For the OM to be able to actively provide the user with the appropriate knowledge it needs to know what the user is currently doing. Unfortunately, this is usually not the case. How can this be achieved at all in a realistic way? In our view, the only practical approach to achieve this is to give people systems which help them do their work wherever this makes sense. These systems (partly) know what the user is doing and what kind of information she needs and thus can provide her (often implicitly, cf. [Cole, Fischer, and Saltzman, 1997]) with relevant knowledge she may not be aware of as existing. These systems may be knowledge-based, i.e., have their knowledge explicitly represented in a knowledge base, or are based on document management systems with a keyword-oriented and/or free-text retrieval component. This scenario is not primarily motivated by the idea of having an OM but to provide people with as much support as possible. When such systems get installed in an organization their knowledge bases begin to form an OM - so to speak as a side effect.
A closer analysis of the scenario described above yields the following implications and conclusions:
From the conclusions above it gets clear that one of the main research problems to be solved is how to integrate the various pieces of knowledge into a coherent OM, and how to ensure its extensibility. Especially the following integration problems arise:
Integration of distinct knowledge bases
From point 2 above follows that the knowledge bases of the various application systems must in some way be integrated to become part of the OM. This can be done physically by making one big knowledge base out of them, or virtually by coupling them via an overall framework. To make things worse, the knowledge bases are typically not disjunct. At least with respect to the terminology there is an overlap, and possibly also with respect to the represented business rules, office tasks, organizational structure, etc. This means that even without the aim of fully integrating these knowledge bases to one OM they should at least be integrated to such an extent that knowledge is not represented repeatedly, avoiding problems with maintenance and consistency.
Integration of several representations of the same knowledge with different degrees of formalization
It may very well be the case that part of the knowledge also resides in the OM in a less formalized state - typically as semi-structured (hyper)text. For example, company regulations may be given in the OM as text but also in a formal representation, e.g., for use by an intelligent workflow system. It should be possible to link all the more or less formalized versions of the same knowledge together such that different kinds of queries become possible. The query system decides which query to evaluate on which representational form(s).
In this paper, we outline a solution to solving both kinds of integration problems and to gradually building a comprehensive OM. As we have realized a knowledge-based system for supporting office work, called EULE2, that already comprises knowledge which should be part of an OM, it is important to have an approach that ensures the integration of various knowledge sources into an OM. We believe that this kind of situation, where certain parts of (not necessarily formally represented) knowledge that should go into an OM already exist, is quite typical. Thus, in the subsequent section (Sec.2) we give a concise introduction to EULE2, while Section 3 motivates the usage of a high-level representation language to build up and maintain the knowledge in EULE2. This high-level language then serves as a starting point for solving the integration problems mentioned above for building an OM (Sec.4). The application of the integration approach to couple EULE2 with a workflow management system is outlined in Section 5. Section 6 concludes the paper.
At Swiss Life, as in many other companies, office workers for customer support are no longer specialists dealing with certain kinds of office tasks only, but are becoming generalists who must deal with all kinds of tasks. The work of this new generation of office workers is quite demanding and calls for a better support. For this purpose, the Information Systems Research Group of Swiss Life has developed a knowledge-based system, called EULE2, that aims at providing a user with a maximal guidance in performing office tasks she may not be familiar with.
Figure 1: An Office Task Description as the User Sees it
An office task can be visualised as a graph (cf. Fig.1). Its nodes stand for (a sequence of) actions the user can perform, while its links are associated with conditions that must be fulfilled for the subsequent action to be permitted. The conditions result from the law and the company regulations. An office worker starts work with EULE2 by selecting an office task and entering task-specific data as requested by the system (EULE2 takes most of the data needed from various data bases and does not request it from the user). As long as the office task is not completed each action has one or more possible subsequent actions. From the data given EULE2 decides which path to follow in the graph. However, nothing is done automatically. The control of what to do next stays with the user but she cannot go on to actions that are not permitted. Some of the actions (like generating letters) are performed by EULE2 (possibly delegating it to another application system), the others are done by the office worker, telling EULE2 when they have been completed. The office worker may decide to proceed to a permitted, subsequent action, or may first ask for an explanation why this particular transition is permitted while the others are not (there is maximally one permitted next action). It is always possible to change incorrectly entered data, maybe causing another subsequent action to become permitted. The office task is completed when a terminal node in the graph is reached.
When we regard the knowledge EULE2 makes use of as being part of an OM then EULE2 makes that OM an active system (with respect to that knowledge) in the sense as it has been mentioned in Section 1: In guiding the user through an office task the system supplies her with exactly that knowledge that she needs at a certain moment (cf. the idea of an ``electronic performance support system'' as discussed in [Cole, Fischer, and Saltzman, 1997]), namely what to do next and why (the latter only if she is interested to know). Since EULE2 is a system that provides people with knowledge they need and ensures that every user always gets up-to-date knowledge EULE2 serves the purpose of knowledge management.
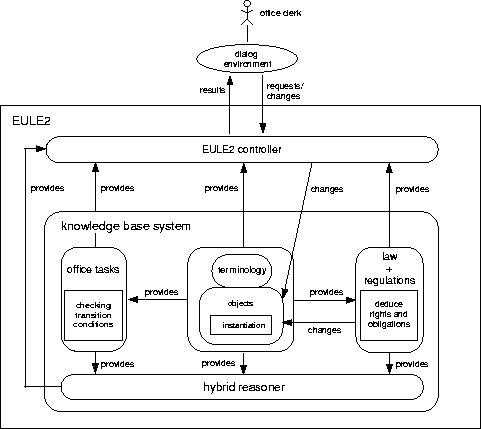
Figure 2: The Architecture of EULE2
To achieve its functionality EULE2 requires the representation of (cf. Fig.2)

Figure 3: Fragment of the Original Text of the Law SchKG 232
Each of the three kinds of knowledge requires a representation formalism of its own. The knowledge about office tasks is represented as a state-space graph with first-order transition conditions . Knowledge about concepts and instances is formulated in a terminological logic [Woods and Schmolze, 1992]. Knowledge about law and regulations is encoded in a clausal logic where we distinguish integrity constraints that must not be violated and deduction rules which derive new attribute values or whole concept instances when their condition part is fulfilled. For example, the deduction rule in Figure 4 specifies a condition when a certain kind of obligation exists and thus represents the subsection of the law in Figure 3. Accordingly, the architecture of EULE2 (cf. Fig.2) provides for a knowledge base with three sub-components each of which offers its own inference services.
. Knowledge about concepts and instances is formulated in a terminological logic [Woods and Schmolze, 1992]. Knowledge about law and regulations is encoded in a clausal logic where we distinguish integrity constraints that must not be violated and deduction rules which derive new attribute values or whole concept instances when their condition part is fulfilled. For example, the deduction rule in Figure 4 specifies a condition when a certain kind of obligation exists and thus represents the subsection of the law in Figure 3. Accordingly, the architecture of EULE2 (cf. Fig.2) provides for a knowledge base with three sub-components each of which offers its own inference services.

Figure 4: A Deduction Rule Representing the Law SchKG 232(2)(4)
EULE2 had to be integrated with several existing data bases where data needed for the office tasks resides. To this end we mapped the schemas of those data bases to a newly defined, integrated schema. Every relation schema belongs to a concept in EULE2's terminology while the relation tuples are seen by EULE2 as instances of the according concepts. Thus, for EULE2 it is completely transparent which concepts and instances come from one of the data bases and which reside in its terminology component only. The data bases are only read. Since no updates are made by EULE2 we avoid the problem of having long transactions with long locks. Data is changed by an office clerk in her usual way, namely through the application systems that already exist. For more details on EULE2 see [Reimer, Margelisch, and Novotny, 1998].
As can be seen, the EULE2 knowledge base captures quite some knowledge important to Swiss Life. Via EULE2 this knowledge is made available to an office worker in such a way that she gets always that knowledge offered which is relevant in the current situation. Besides for supporting office work, the knowledge EULE2 has available is also useful for other people and for other purposes, e.g., for tutoring new employees, for inquiring about the effect of certain company regulations on office tasks, or for finding out about past instances of office tasks performed. Reusing the knowledge represented in the EULE2 knowledge base for other systems will be quite hard since the formalisms used have been selected to efficiently support the kind of reasoning that occurs in EULE2. Thus, they may not suit very well the purposes of another application. In order to facilitate reuse and to make building and maintaining the EULE2 knowledge base easier we are developing a high-level representation language (HLL) that abstracts away from the representation formalisms actually used in EULE2. In terms of the representational levels introduced in [Brachman, 1979] HLL is on the conceptual level while the EULE2 formalisms are on the logical level (only its terminological logic being on the epistemological level). Thus, the representation constructs offered by HLL already introduce certain fundamental concepts, like obligations, rights, and actions. They are especially tailored to the representational tasks encountered with developing EULE2. In the following, we introduce the main constructs of HLL (Sec.3.1), give some remarks on their mapping to the low-level formalisms of EULE2 (Sec.3.2) and then give an ontological account of HLL (Sec.3.3).
Concepts and their instances
We employ a terminological logic to represent concepts and an associated assertional formalism to represent concept instances. The terminological logic comprises constructs for defining atomic attributes (of type integer, string, money, date, time duration and boolean), relationships to other concepts, value restrictions for attributes and relationships, as well as cardinality restrictions. Examples of concept definitions are given in Figure 6.
Conditions on the existence of attribute values and relationship instances
Sometimes, certain attribute values or relationships of an instance to another one depend on (a certain constellation of) other attribute values or relationships (of the same or other instances). A construct of HLL allows to specify such dependencies. For example, a provident insurance which has the value `irrevocable beneficiary' for the property `clauses' cannot be sold by auction in the case of the bankruptcy of the policy holder and thus has the derived property `exempt from seizure'.
Conditions on the existence of concept instances
During an office task new concept instances may have to be introduced, e.g., to keep certain information needed later on. For example, in the office task which deals with the bankruptcy of a policy holder an instance of the concept `bankrupt's estate' is introduced where all those policies and other assets of the policy holder are collected which are administered by Swiss Life and have to be considered in the bankruptcy proceedings. A construct of HLL covers such cases by allowing to give a (necessary and sufficient) condition for the existence of the instance, to specify the concept to which the instance belongs, and the properties and relationships to other instances it must have. An example of applying this construct is shown in Figure 5. An instance whose existence condition no longer holds ceases to exist.

Figure 5: Example of an Existence Condition for a Concept Instance
Laws and regulations
An important requirement for HLL is to support the representation of law and regulations that influence how an office task is properly executed. A law defines a right or an obligation and specifies when it holds. HLL therefore knows of two predefined concepts `right' and `obligation'. A certain (sub)section of a law is then represented by introducing an appropriate specialization of `right' or `obligation' and by describing the conditions under which a certain instance of it exists. This is done with the construct for defining conditions on the existence of concept instances as introduced above. An example is depicted in Figure 6.

Figure 6: Example of Representing a Subsection of a Law
Company regulations which introduce rights and obligations, too, are represented in the same way. A second kind of company regulation gives an interpretation of a right or an obligation and stipulates the activities to be performed or forbidden in the case that right or obligation exists. A third kind of company regulation is not concerned with rights or obligations but says when what activity must be performed. As opposed to the first kind of regulation the last two ones directly affect activities. They are represented with the HLL construct of a precondition for an activity (see below).
At this point we very clearly see a fundamental conflict we encountered while developing HLL. On the one hand, HLL constructs can support the representation in terms of knowledge sources, i.e. law and company regulations. Providing constructs for directly representing law and regulations has the advantage that there is a one-to-one correspondence between the law and regulation text and representation structures in the HLL knowledge base. However, law and regulations touch quite a diversity of kinds of knowledge. A law often starts by defining concepts and then introduces rights and/or obligations and says when they hold. Thus, a construct for representing law would have to cover the expressiveness of a terminological logic as well as that of existence conditions for concept instances. Company regulations are even worse. They may introduce concepts, existence conditions for instances, or may define a precondition for an activity. Thus, a construct for company regulations would have to cover nearly all kinds of knowledge currently supported by HLL and thus would have to unify all the corresponding formalisms into one construct. This simply does not work for a knowledge engineer who would soon lose the overview of what she is doing. As a consequence, we decided to provide HLL with constructs for kinds of knowledge, i.e. concepts, instances, existence conditions, preconditions, etc. This is the best as far as knowledge engineering is concerned. However, for the purpose of knowledge integration the knowledge source view is needed (cf. Sec.4). By attaching to each HLL construct a reference to a knowledge source (see Figs. 6, 7) it becomes possible to compile for a given knowledge source (a (sub)section of law or a company regulation) all associated representation structures. In this way, we can always reconstruct the knowledge source view from the knowledge kinds view.
Activities and office tasks
For modelling office tasks activities need to be represented. HLL distinguishes several kinds of activities and correspondingly offers different contructs for them. An atomic activity appears as atomic to HLL. This can be the call of an object editor so that the user can enter data, or it is an activity outside of the system, like making a phone call to a customer. A simple activity is a linear sequence of atomic activities. A composite activity is a set of partially ordered activities (of any sort). The last two constructs are used to group together activities which form a logical unit from the office worker's point of view.
There are further kinds of activities of a more specialized nature, e.g. for splitting up and joining of split activities. An office task, finally, is a simple or composite activity that has been designated as being an office task.
Preconditions for activities
Any kind of activity can have a precondition that must be fulfilled for the activity to be permitted. Preconditions always correspond to company regulations (but not vice versa). Often, a precondition refers to the existence of a right or obligation which is the cause to perform the activity. An example of a precondition is given in Figure 7.

Figure 7: Example of a Precondition for an Activity
Special constructs
The formulation of a law or regulation in natural language often refers to other text passages in order to state an analogy, an exception, or a restriction. This is a convenient way to avoid duplication of text. For the same reason it would be nice if a knowledge engineer has similar means in HLL. Therefore, HLL is currently being extended with according constructs. For example, it is possible to give an existence condition a label and to refer to that condition via this label when defining another existence condition, while allowing to substitute certain parts of the referenced condition.
HLL is not directly implemented but compiled into a combination of the more general representation languages underlying EULE2 where all the inferences are drawn. The semantics of HLL is then defined by its mapping to the underlying languages and their semantics. Concept definitions and their instances directly correspond to the terminological and assertional components of a terminological logic with the usual semantics. Existence conditions for attribute values and concept instances are special cases of deduction rules and are mapped to clauses in Datalog ![]() [Ceri, Gottlob, and Tanca, 1990] with unary and binary predicates only. Similarly, preconditions for activities are mapped to Datalog
[Ceri, Gottlob, and Tanca, 1990] with unary and binary predicates only. Similarly, preconditions for activities are mapped to Datalog ![]() clauses. Whereas the deduction rules are used to derive new facts the clauses resulting from preconditions act as integrity constraints and are tested on demand for being satisfied or violated. Activities and office tasks are mapped to acyclic, nested graphs whose nodes contain a graph again or are an atomic activity. Finally, special constructs for modelling analogies, restrictions, etc. are nothing more than shortcuts for more lengthy representations and are correspondingly resolved by the compiler. Thus, they do not demand any further expressiveness from the underlying formalism.
clauses. Whereas the deduction rules are used to derive new facts the clauses resulting from preconditions act as integrity constraints and are tested on demand for being satisfied or violated. Activities and office tasks are mapped to acyclic, nested graphs whose nodes contain a graph again or are an atomic activity. Finally, special constructs for modelling analogies, restrictions, etc. are nothing more than shortcuts for more lengthy representations and are correspondingly resolved by the compiler. Thus, they do not demand any further expressiveness from the underlying formalism.
In contrast to the low-level formalisms into which HLL is compiled it offers the following advantages:
The move from the logical level of the underlying representation formalisms of EULE2 to the conceptual level of HLL introduces a representation ontology (like the Frame Ontology in [Gruber, 1992] - not to be confused with a domain ontology) which is reflected by the constructs of HLL. As [Guarino, 1995] suggests, the definition of the ontology underlying a representation language adds an additional, ontological level to the ones suggested by [Brachman, 1979], situated between the epistemological and the conceptual level. Thus, having a language on the conceptual level implies that there is an underlying ontological level which, however, is not necessarily made explicit. The onotological level of HLL is not introduced so far, but we will do this in this section.
As already discussed in Section 3.1 we can have two different ontological views on HLL - the view in which HLL supports the representation of various kinds of knowlegde and the view in which HLL supports the representation of knowledge such that the underlying structure corresponds to the sources from which the knowledge is obtained. Although the actual constructs provided implement the former view the latter one is still implicitly there due to the labels attached to constructs which reference the knowledge source (i.e., law or regulation) the particular statement originates from. An explicit ontological account of HLL defines all the concepts underlying the HLL constructs so that they come into existence and it is possible to talk about them and to state relationships between them where meaningful.
Although it is not necessary for the purpose of EULE2 to give this ontological account we will need it for integrating an EULE2 knowledge base with other knowledge bases (see Sec.4). Definitions of some of the concepts the HLL ontology comprises are given in Figure 8. They are written down in the syntax of ConceptBase, a deductive, object-oriented meta data management system we employ for defining ontologies [Jarke et al., 1995]. Several observations can be made from the definitions in Figure 8. First, there are concepts in the ontology, like right and obligation, that are already predefined in HLL because together with the construct of existence conditions for concept instances they are needed to represent law and certain kinds of regulations. In the ontological view both concepts are extended so that their existence condition becomes a part of their definition. Second, there are concepts, like law or law-section, that have no equivalent in HLL, neither as a predefined concept nor as a representation construct. Third, there are concepts, like activity, that exist as constructs in HLL but not as concepts. As with the right and obligation concepts whose definitions comprise their existence conditions the definition of the activity concept includes the associated precondition.

Figure 8: Some of the Ontological Concepts Underlying HLL
The ontological view of HLL (in the following HLL ![]() is not intended to be used for making inferences (just as for HLL) nor does it replace HLL. The view HLL offers is good for building knowledge bases for EULE2 while the view of HLL
is not intended to be used for making inferences (just as for HLL) nor does it replace HLL. The view HLL offers is good for building knowledge bases for EULE2 while the view of HLL ![]() is good for knowledge integration and supporting meta-level querying (cf. Sec.4.2). HLL
is good for knowledge integration and supporting meta-level querying (cf. Sec.4.2). HLL ![]() does not add anything that is in one or the other way not already existent in HLL. Consequently, the HLL
does not add anything that is in one or the other way not already existent in HLL. Consequently, the HLL ![]() view can always be generated from a given HLL knowledge base (and vice versa). However, making explicit what is only implicitly given in HLL is a necessary precondition for being able to integrate an HLL knowledge base with other knowledge bases. The following section takes a closer look at this.
view can always be generated from a given HLL knowledge base (and vice versa). However, making explicit what is only implicitly given in HLL is a necessary precondition for being able to integrate an HLL knowledge base with other knowledge bases. The following section takes a closer look at this.
As discussed in Section 1 there are two kinds of integration problems with respect to building an OM. One of them is the integration of the knowledge bases of several application systems into one physically or virtually integrated knowledge base which would form a part of the OM. The integration causes a considerable added value due to the following reasons:
The integration of knowledge can only be achieved when it is represented either in the same language or in different languages that can be mapped to each other. Therefore, we intend to take HLL which has already been developed for EULE2 and extend it to a language we can use for representing the OM (the knowledge of EULE2 would then just be a small part in the OM). Due to reasons already discussed in Section 3.3 we do not use HLL proper but its ontologically explicit version HLL ![]() . As the inferential requirements can be quite distinct for different application systems their knowledge can only then be uniformly described in one representation language if the language is on the conceptual level (rather than on the logical level), thus abstracting from the low-level representational views which reflect the measures taken for efficient inferences. This is the case with HLL
. As the inferential requirements can be quite distinct for different application systems their knowledge can only then be uniformly described in one representation language if the language is on the conceptual level (rather than on the logical level), thus abstracting from the low-level representational views which reflect the measures taken for efficient inferences. This is the case with HLL ![]() . The extension of HLL
. The extension of HLL ![]() to additionally represent other kinds of knowledge pushes it more and more into the direction of a general-purpose language. Still, for a given application system only a certain subset is needed. By specifying the underlying representation ontology explicitly [Guarino, Carrara, and Giaretta, 1994] the representational impacts of all constructs and their possible interrelationships stay clear (similar ideas underly the meta-modelling approach for customizing modelling languages as e.g. described in [Nissen et al., 1996]). Due to such an ontology it is for example possible to have generalizations between constructs, like a general construct for representing activities with several specializations of it which serve different needs of different application systems. The various constructs for representing activities may even be based on different conceptualizations of the world as long as the ontology keeps track of this so that a unified view can be generated. Different conceptualizations that are not on the level of constructs but affects how knowledge is actually represented can, of course, not be handled. HLL
to additionally represent other kinds of knowledge pushes it more and more into the direction of a general-purpose language. Still, for a given application system only a certain subset is needed. By specifying the underlying representation ontology explicitly [Guarino, Carrara, and Giaretta, 1994] the representational impacts of all constructs and their possible interrelationships stay clear (similar ideas underly the meta-modelling approach for customizing modelling languages as e.g. described in [Nissen et al., 1996]). Due to such an ontology it is for example possible to have generalizations between constructs, like a general construct for representing activities with several specializations of it which serve different needs of different application systems. The various constructs for representing activities may even be based on different conceptualizations of the world as long as the ontology keeps track of this so that a unified view can be generated. Different conceptualizations that are not on the level of constructs but affects how knowledge is actually represented can, of course, not be handled. HLL ![]() fulfills all the above requirements and is therefore an ideal starting point.
fulfills all the above requirements and is therefore an ideal starting point.
The necessity to make conceptualizations underlying a representation (language) explicit in order to better maintain, reuse, and share knowledge is widely accepted for quite some time [Clancey, 1983]. The idea of using ontologies for sharing and integrating knowledge has come up later on [Gruber, 1991] and is since then being discussed in the literature (for an overview see Section 6 in [van Heijst, Schreiber, and Wielinga, 1997]). We apply these ideas to facilitate the building of an OM by integrating knowledge sources. As these sources may be extremely diverse our approach needs to be accordingly general. Approaches to integration based on wrappers and mediators [Wiederhold, 1992] usually aim at an integration on a more syntactical level. However, the more of the meaning of the integrated pieces of knowledge is covered, the closer these approaches come to integration approaches based on ontologies.
Two different scenarios of integrating knowledge bases that need a different treatment can be distinguished. The bottom-up integration combines already existing knowledge bases while the top-down integration generates different knowledge bases from a common representation.
Bottom-up integration
The integration of already existing knowledge bases in order to be able to query all of them as a unified whole poses the problem that the knowledge bases may be incomparable due to different underlying conceptualizations. This can be resolved in HLL ![]() where the common aspects of seemingly completely different concepts can be made explicit. For example, the representation of a concept `activity' for a workflow system might look completely different than in EULE2. In contrast to the EULE2 representation it may only be atomic, may be called working step instead of activity, and has completely different attributes. Modelling the different EULE2 activities and the workflow system's working step as specializations of a more general concept `activity-generic' provides a bridge between the two different conceptualizations. The example depicted in Figure 9 goes even a step further and additionally expresses that the concept of a working step is closer to an atomic activity of EULE2 than to the general concept of an activity. Other conceptualizations of an activity may be added, e.g., where an activity is exclusively described by specifying its pre- and postconditions.
where the common aspects of seemingly completely different concepts can be made explicit. For example, the representation of a concept `activity' for a workflow system might look completely different than in EULE2. In contrast to the EULE2 representation it may only be atomic, may be called working step instead of activity, and has completely different attributes. Modelling the different EULE2 activities and the workflow system's working step as specializations of a more general concept `activity-generic' provides a bridge between the two different conceptualizations. The example depicted in Figure 9 goes even a step further and additionally expresses that the concept of a working step is closer to an atomic activity of EULE2 than to the general concept of an activity. Other conceptualizations of an activity may be added, e.g., where an activity is exclusively described by specifying its pre- and postconditions.

Figure 9: Adding the Concept `activity-generic' to the Ontology of Fig.8 to Facilitate Bottom-Up Integration
Top-down integration
Quite different is the case of integrating two information systems via a common language for describing their contents, for example when we couple EULE2 with a workflow management system (cf. Sec.5). Here again, the problem of overlapping terminology with different conceptualizations arises. However, as the common representation is not created bottom-up from already existing knowledge bases, as in the first case above, but will be used to generate them, it does not add the smallest commonalities of two differently conceptualized concepts but the combination of all their features, thus becoming a subordinate concept of them. For example, a representation language that covers the representational needs of EULE2 as well as of a workflow system might add a concept `activity-comb' as shown in Figure 10. All activities are modelled as instances of that concept. The activities specific to EULE2 or to the workflow system are then more general than these instances. From an instance of `activity-comb' the EULE2 view (as an instance of `activity') and the workflow system view (as an instance of `working-step') can be generated. Each covers exactly the features needed by the corresponding system and can be compiled into the respective internal representation languages.
![]()
Figure 10: Adding the Concept `activity-comb' to the Ontology of Fig.9 to Facilitate Top-Down Integration
We think that the foundation we have laid with HLL ![]() will be the right starting point for incrementally designing a representation language that covers all the contents of an organizatinal memory. For a specific portion of the OM (like the EULE2 knowledge base) only a certain subset of HLL
will be the right starting point for incrementally designing a representation language that covers all the contents of an organizatinal memory. For a specific portion of the OM (like the EULE2 knowledge base) only a certain subset of HLL ![]() is needed so that the actual modelling activity will not use the complete language but the required part only. We therefore think that the resulting language for representing organizational memories will not suffer from being not manageable. In particular, it cannot be inefficient as it is always compiled into formalisms that are optimized for the respective tasks.
is needed so that the actual modelling activity will not use the complete language but the required part only. We therefore think that the resulting language for representing organizational memories will not suffer from being not manageable. In particular, it cannot be inefficient as it is always compiled into formalisms that are optimized for the respective tasks.
The second integration problem concerns the linking of representations of the same pieces of knowledge in notations that have a different degree of formalisation. We illustrate the need for doing this by the example of knowledge about company regulations which are represented in three different formalisations in the OM (cf. Fig.11):
The OM as outlined in Figure 11 additionally contains a content representation of the office tasks and a comprehensive terminology. The content representations of the regulations and the office tasks as well as part of the terminology also forms the intensional part of the knowledge base of EULE2.
The different representation components of the OM fit quite well into the representational levels of an OM as discussed in [Abecker et al., 1997]. On their object level is the primarily interesting knowledge, in our case the terminology, both content representations, and the regulation texts. The content characterization (of the regulation texts and thus, transitively, of the content representation of the regulations) belongs to their knowledge description level. The authors additionally suggest a relevance description level where the task-specific relevance of knowledge is represented so that it becomes possible to actively deliver exactly that knowledge which people need at a given time. This level has (currently) no direct correspondence in the OM architecture of Figure 11. However, the knowledge is implicitly present as part of the office task representations, but not independently on a meta-level.
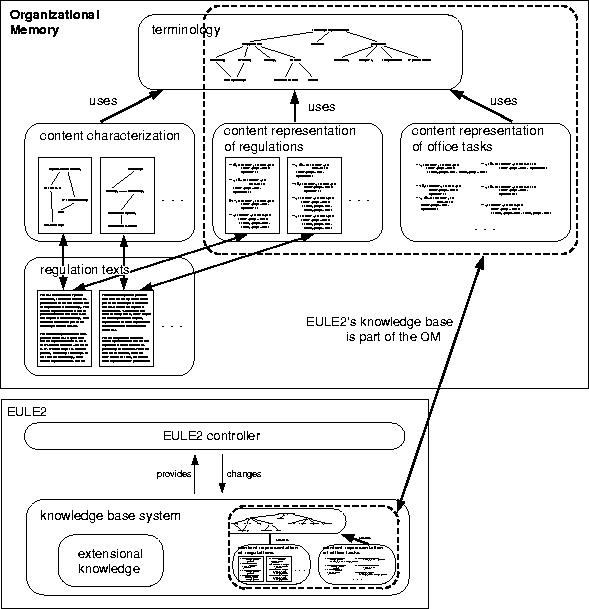
Figure 11: The Architecture of an Organizational Memory
A wide range of queries concerning company regulations can be posed to the OM. We give just a few examples (cf. with Fig.11):
For some of the office tasks retrieved the user may then want an explanation in what aspects the regulation influences the way the task is to be performed. This request is satisfied with the help of the explanation component of EULE2.
The examples above illustrate that all three formalisations of company regulations are needed to evaluate all the possible queries. They also show that for the evaluation of one query more than one representation may be needed, for example, if a user specifies a regulation in terms that have to be evaluated against the regulation texts, and then, once the intended regulation is found, looks for regulations that are exceptions of it, which requires evaluation against the content representation. To the user it must remain completely hidden against which representation a query is evaluated so that she does not need to know to which representational form to pose the query nor to know all the query languages required. Instead, she always makes use of one and the same query interface. Consequently, there must be links between all the representational forms of regulations, as indicated in Figure 11. Again, these links can be provided by HLL ![]() (resp. an extension of it). For example, regulations as well as (sub)sections of laws are already concepts in HLL
(resp. an extension of it). For example, regulations as well as (sub)sections of laws are already concepts in HLL ![]() . Thus, to establish the integration of textual representations with their formal counterparts new versions of the regulation and law concepts that contain only the natural language text are provided (`law-section-text' and `law-subsection-text' - see Fig.12). Instances of these new concepts are linked to the textual knowledge base from which the corresponding text is dynamically taken whenever the instance is queried. The concepts `law-section' and `law-subsection' that already exist in our ontology are integrated with these two new concepts via common generic concepts `law-section-generic' and `law-subsection-generic' (see Fig.12). In this way, we get a one-to-one correspondence between law represented in EULE2 and its original natural language formulation (the same is done for regulations and their textual forms). The correspondence is on the level of (sub)sections when law is concerned and (usually) on the paragraph level for regulation texts. Having a one-to-one correspondence on the sentence level or even below is in general not possible as a certain piece of knowledge is often described in more than just one sentence.
. Thus, to establish the integration of textual representations with their formal counterparts new versions of the regulation and law concepts that contain only the natural language text are provided (`law-section-text' and `law-subsection-text' - see Fig.12). Instances of these new concepts are linked to the textual knowledge base from which the corresponding text is dynamically taken whenever the instance is queried. The concepts `law-section' and `law-subsection' that already exist in our ontology are integrated with these two new concepts via common generic concepts `law-section-generic' and `law-subsection-generic' (see Fig.12). In this way, we get a one-to-one correspondence between law represented in EULE2 and its original natural language formulation (the same is done for regulations and their textual forms). The correspondence is on the level of (sub)sections when law is concerned and (usually) on the paragraph level for regulation texts. Having a one-to-one correspondence on the sentence level or even below is in general not possible as a certain piece of knowledge is often described in more than just one sentence.

Figure 12: Extending the Ontology of Fig.10 for Integrating Formal and Textual Representations of the Same Knowledge
The integration of knowledge represented in EULE2 and its corresponding textual representation has not only advantages from an OM point of view but is also a necessary prerequisite for generating explanations that use phrases of the original text so that the user can more readily see the correspondence of a restriction she encounters in the office task with a certain law or regulation.
The first major integration (besides integration with law and regulation texts) we are doing combines EULE2 with a workflow management system. The functionality of EULE2 as described in Section 2 is in some aspects already similar to that of a workflow system. However, a close analysis reveals that, in fact, EULE2 is rather complementary to a workflow system. The Workflow Management Coalition defines a workflow system as
``A system that defines, creates and manages the execution of workflows through the use of software, running on one or more workflow engines, which is able to interpret the process definition, interact with workflow participants and, where required, invoke the use of IT tools and applications.''Thus, a workflow system coordinates tasks where more than one person is involved. It knows which subtasks must be performed by which (kind of) people and manages the flow of control between people, possibly accompanied by a flow of documents.
EULE2, in contrast, has a more local view and supports one office worker only, this however at a degree of detail which by far surpasses the abilities of existing workflow systems. This is possible because EULE2 has much more knowledge about the office tasks, about the relevant law, and about company regulations. As it does not make sense to reprogram all the functionality of a workflow system that EULE2 is missing, the only meaningful approach is to integrate EULE2 with a workflow system. Doing this we encounter a situation where knowledge that belongs in an OM is in the knowledge base of EULE2 as well as in the knowledge base of a workflow system. Clearly, a coupling of EULE2 with a workflow system must be designed in such a way that this knowledge becomes integrated, too. This will be the first step of an evolutionary approach at building up an OM at Swiss Life. The solution we envisage is along the lines of the approach oulined in Section 4.1.
Figure 13 depicts the overall scenario. All the knowledge - the parts needed by EULE2 as well as the parts needed by the workflow system - is represented in an extended version of HLL ![]() and resides in one repository - the OM. A compiler maps the respective parts from HLL
and resides in one repository - the OM. A compiler maps the respective parts from HLL ![]() into the HLL format of EULE2 and the modeling language of the workflow system (see Sec.4.1 where this aspect has already been discussed). The HLL representation is compiled one more time into the internal representation formalisms of EULE2.
into the HLL format of EULE2 and the modeling language of the workflow system (see Sec.4.1 where this aspect has already been discussed). The HLL representation is compiled one more time into the internal representation formalisms of EULE2.
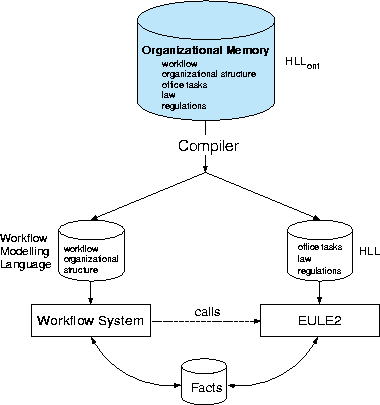
Figure 13: Centralizing the Knowledge Needed by EULE2 and a Workflow System in an OM
As the workflow system has the global view on the office task it gets the overall control of office task execution. Whenever needed it calls EULE2. The cooperation of the workflow system and EULE2 at execution time is illustrated in more detail in Figure 14. The knowledge about the subtasks and the individual steps an office task is composed of resides in the workflow system as well as in EULE2. The workflow system also knows which steps must be executed by whom so that it can initiate a transfer from one office worker to another one (including, of course, parallelism where appropriate). The knowledge about the conditions under which one of several possible subsequent steps in an office task is to be performed resides in EULE2. When the workflow system needs to know which of several possible subsequent steps is to be performed next it calls EULE2 (cf. Fig.14). EULE2 writes the results of its decision into the fact base shared with the workflow system (technically, it is a boolean variable being set and referenced by the workflow system). The approach makes use of the interfaces any workflow system ought to have according to the workflow reference model of the Workflow Management Coalition [Hollingsworth, 1994], and thus does not require any EULE2-specific adaptation on the side of the workflow system.
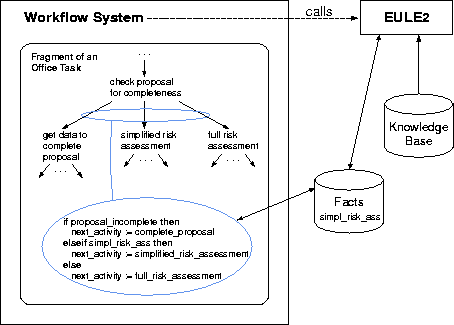
Figure 14: Cooperation of EULE2 and a Workflow System at Execution Time
The above approach is elegant also from the OM point of view, as it quite easily allows to have an integrated representation of the knowledge needed by EULE2 and the workflow system. Maintenance of that knowledge and its reuse in other systems is quite easily possible via HLL ![]() . Moreover, being in one repository, the knowledge can be queried via an interactive query interface.
. Moreover, being in one repository, the knowledge can be queried via an interactive query interface.
We have outlined an approach to creating an OM by integrating the knowledge bases of existing application systems as well as those to be built in the future. To support the integration we advocate to employ a high-level representation language, HLL ![]() , which is used to represent the knowledge in all the knowledge bases. HLL
, which is used to represent the knowledge in all the knowledge bases. HLL ![]() is on the conceptual level (according to [Brachman, 1979]) because only in this way it can abstract from the lower-level inferential commitments made to achieve efficiency. The ontological level underlying HLL
is on the conceptual level (according to [Brachman, 1979]) because only in this way it can abstract from the lower-level inferential commitments made to achieve efficiency. The ontological level underlying HLL ![]() is made explicit so that the concepts underlying the constructs of HLL
is made explicit so that the concepts underlying the constructs of HLL ![]() come into existence and it is possible to talk about them and to state relationships between them. In this way, we can even support different conceptualizations of the world in different knowledge bases while still using the same representation language. Although HLL
come into existence and it is possible to talk about them and to state relationships between them. In this way, we can even support different conceptualizations of the world in different knowledge bases while still using the same representation language. Although HLL ![]() would be quite a comprehensive language, for a certain application only a certain part is needed. An HLL
would be quite a comprehensive language, for a certain application only a certain part is needed. An HLL ![]() representation is compiled into the actual representation formalisms used in the various knowledge based systems, thus guaranteeing efficiency.
representation is compiled into the actual representation formalisms used in the various knowledge based systems, thus guaranteeing efficiency.
We have also addressed the need of having the same pieces of knowledge in more than just one representation in the OM. The representations differ in the degree of formalisation, ranging from natural language text to deep, first-order representations. These representations are needed to answer the various kinds of queries that may occur. A query interface to the OM must hide from the user what kind of query is evaluated on what kind of representation. To enable the query system to pick out that representation which is the proper one for the current query the textual and more formalized representations must be linked to each other. We have shown how this can be done in HLL ![]() , resulting in a one-to-one correspondence between a piece of natural language text and its formal representation.
, resulting in a one-to-one correspondence between a piece of natural language text and its formal representation.
The first version of HLL ![]() has been implemented for EULE2, a system to support office work. Further extensions, especially concerning the support of certain complex natural language phrases, are under way. The ideas of using HLL
has been implemented for EULE2, a system to support office work. Further extensions, especially concerning the support of certain complex natural language phrases, are under way. The ideas of using HLL ![]() for building an OM are currently being proved valid by integrating EULE2 with a workflow management system. This integration is intended to become the condensation point for Swiss Life's OM.
for building an OM are currently being proved valid by integrating EULE2 with a workflow management system. This integration is intended to become the condensation point for Swiss Life's OM.
Acknowledgements:
I am grateful to my colleagues Jörg-Uwe Kietz and Martin Staudt for their helpful comments on an earlier version of this paper. The principal idea of how to integrate EULE2 with a workflow system as outlined in Section 5 has been developed by my colleague Thomas Vetterli. I also like to thank the reviewers of an earlier version of this paper for their comments, which helped considerably to improve this paper.