
Mike Uschold, Peter Clark, Mike Healy, Keith Williamson, Steven Woods
{mfu,clarkp,mjhealy,kew,woods}@redwood.rt.cs.boeing.com
Boeing Applied Research and Technology, PO Box 3707, Seattle, USA
In this paper, we describe an investigation into the reuse and application of an existing ontology for the purpose of specifying and formally developing software for aircraft design. Our goals were to clearly identify the processes involved in the task, and assess the cost-effectiveness of reuse. Our conclusions are that (re)using an ontology is far from an automated process; it requires not only consideration of the ontology, but also of the tasks for which it is intended. We describe and illustrate some intrinsic properties of the ``ontology translation'' problem and argue that fully automatic translators are unlikely to be forthcoming in the foreseeable future. Despite the effort involved, our subjective conclusions are that in this case knowledge reuse was cost-effective, and that it would have taken significantly longer to design the knowledge content of this ontology from scratch in our application. Our preliminary results are promising for achieving larger-scale knowledge reuse in the future.
If there is to be a future for the construction of large-scale, knowledge-based systems, then it is essential that researchers be able to share and reuse representational components built by others. However, despite the potential advantages of such sharing, and the availability of such components in component libraries (e.g. [Neches et al., 1991, Benjamins, 1993]), it remains a challenging task to import and use such components.
There are still only a few published examples of such reuse
(e.g. [Borst et al., 1996, Cutkosky et al., 1993, McGuire et al., 1993]). There
are also few published examples describing details of how ontologies are
applied.
Furthermore, in cases where an ontology is reused, (e.g. as the basis
for building another ontology rather than starting from scratch) descriptions
of how the ontologies are applied are terse or absent.
In this paper, we describe the start-to-finish process of reusing and applying
an existing ontology. We conducted an experiment consisting of the following
steps: a) take the engineering math ontology[Gruber & Olsen, 1994] written in
Ontolingua [Gruber, 1993a] from the library of ontologies at the Stanford
Knowledge Systems Laboratory (KSL) Ontology Server [Farquhar et al., 1995], b) translate it into
a target specification language c) integrate it into the specification of
an existing small engineering software component d) transform and refine the
enhanced specification into executable code using Specware, a system for the
specification and formal development of software and e) demonstrate the ability
to add units-conversion capabilities and dimensional consistency-checking to
the engineering software.

Figure 1: Process of Implementing an Ontology
In the literature, it is common to distinguish between reuse of ontologies (``knowing what'') and reuse of problem-solving methods (``knowing how''). Our main focus in this experiment was with the former. We draw a fundamental distinction between the specification of a set of concepts and relations (e.g. in Ontolingua), and their implementation in a form supporting mechanized reasoning (e.g. in Loom [MacGregor & Bates, 1987], Lisp, Classic [Brachman et al., 1991], etc.). Ontolingua does not have an associated inference engine for tractable, complete reasoning with its axioms; furthermore, because it supports the full expressivity of first-order logic, such an inference engine is intrinsically impossible to build. Therefore, in order to make use of an Ontolingua ontology in an implementation, one must compromise in some way.
We argue that one should be guided by the nature of the intended tasks and the required computational functions in choosing how to restrict the inference capabilities of the implemented ontology (see figure 1). This dependence of implementation on task, as well as ontology, makes the ontology translation process inherently difficult to fully automate; this realization was a significant result of our investigation, and an important point of note in this paper. Our experience concurs with the ``interaction hypothesis'' [Bylander & Chandrasekaran, 1988], namely that one cannot meaningfully implement a domain model without knowing what questions it is supposed to answer (sometimes referred to as ``competency questions'' [Gruninger & Fox, 1994]), and the behavior of the implementation language.
One goal of this exercise is to identify the issues that affect successful reuse and application of existing ontologies. This should result in a clearer understanding of how to identify a reuse situation that is likely to succeed, as well as what kind of technical issues and problems will need to be faced. Important questions include:
Our conclusions are that (re)using an ontology is far from an automated process, and instead requires significant effort from the knowledge engineer. The process of applying an ontology requires converting the knowledge-level [Uschold, 1998] specification which the ontology provides into an implementation. This is time-consuming, and requires careful consideration of a) the context, intended usage, and idioms of both the source ontology representation language, and the target implementation language, and b) the specific task of the current application.
Despite this, our subjective conclusions from this experiment are that overall, knowledge reuse is cost-effective, and that it would have taken significantly longer to design the knowledge content of this ontology from scratch in our application, or from just reading the technical papers describing it. We are therefore cautiously optimistic about the longer term goal of achieving large-scale knowledge reuse.
We begin with a brief of summary of the background context and motivation for our experiment. We examine each step in the process of reusing and applying the engineering math ontology. We highlight important issues and indicate our progress to date. We conclude by summarizing what we have learned from this exercise.
Here we describe the application problem that we are addressing, the target platform for ontology reuse and application (Specware), and the language that the original ontology is written in (Ontolingua).
The task performed by the engineering software component whose functionality we are trying to enhance with the engineering math ontology, is a simplified version of the layout design of a stiffened panel (e.g. Figure 2). The specific task is to determine the placement of ``lightening holes'' (for saving weight) on the panel, subject to cost and weight constraints as follows: GIVEN: a length of panel, constraints on hole placement (e.g. various minimum separation distances), and a cost function, DETERMINE: how many holes of what size should be drilled, optimizing the cost function for the panel.
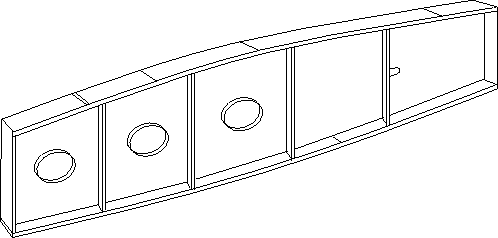
Figure 2: Drawing of a stiffened panel.
We started with a fragment of production code which had been reverse engineered and re-implemented in Slang, the language of Specware (see below). This first entailed teasing out and declaratively representing much engineering knowledge and hidden assumptions that were implicit in the original code. The design was augmented with a simple, but explicit, model for manufacturing cost.
Finally, the specification was refined by selecting and specifying data structures and algorithms; from this, Specware synthesized executable code in Lisp.
Our model of panel layout is a research prototype intended to, among other things, demonstrate the feasibility of deriving knowledge based engineering software from reusable components of formalized engineering knowledge.
Our platform for demonstrating ontology reuse and application is Specware, [Waldinger et al., 1996] a system for the specification and formal development of software. It has a rigorous mathematical foundation, based on logic and category theory. It provides an order-sorted higher order logic representation language called Slang, and supports the process of refining specifications into provably correct implemented code. The semantics of Slang are founded on categorical type theory.
Specware was developed to support the process of software development (neither excluding nor emphasizing knowledge-based systems). Slang is a wide-spectrum language used to represent specifications ranging from purely abstract mathematical theories (e.g. for sets) which may be completely free of implementation biases, all the way to detailed specifications which include data structures and corresponding algorithms. For example, to implement sets using a list data structure, an algorithm for inserting new elements into lists which prevents duplicates is required.
Slang contains primitives for specifying refinements, which are formal mappings between specifications which move closer and closer to implementation. Formally, these consist of morphisms in the category of specifications and specification morphisms[Williamson & Healy, 1997]. The higher level specifications are refined step by step until sufficient implementation information is given that Specware may automatically generate executable code (currently in Lisp or C++).
Slang includes a rich set of primitives for composing specifications by reusing and parameterizing one or more copies of other specifications. The user specifies what and how various component specifications are to be included in the whole, and the colimit operation from category theory is used to compute the whole (see figure 4).
Although Slang was not designed to represent knowledge-level ontologies it is entirely adequate for that purpose. The higher level specifications in Slang correspond to ontologies in Ontolingua (see below), in that both are intended to implementation-neutral. Lower level specifications in Slang must contain implementation information in order for Specware to generate code from them.
Ontolingua, was developed specifically for the purpose of knowledge sharing and reuse in the context of knowledge-based systems, not for the development of software in general. Ontolingua, based on KIF[Genesereth & Fikes, 1992], was to facilitate reuse and inter-operability by acting as an interchange format so that knowledge bases could be translated into and out of it.
However, there is no inference engine for Ontolingua, thus, unlike Slang, the only way an ontology written in Ontolingua can be used (by machine), is by translating it into some implemented language. Translating arbitrary sets of axioms in logic to any given output language, is not feasible. For this reason, Ontolingua is biased towards an object-oriented representation style. [Gruber, 1993a].
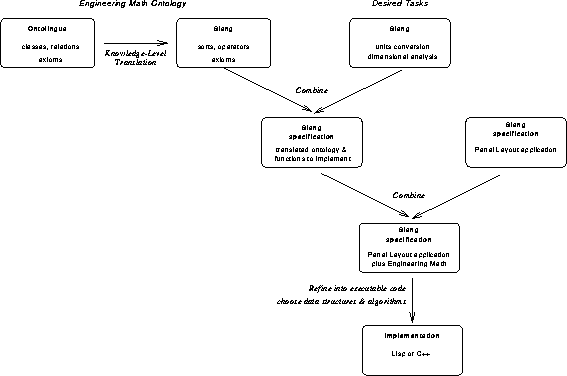
Figure 3: Process of Ontology Reuse and Application
Our goal in this experiment was to obtain these benefits. Instead of rewriting the original application from scratch, we tried to reuse and apply the engineering math ontology by incorporating it into this application. This ontology defines in a principled implementation-neutral manner, a set of concepts and relations for representing and manipulating physical quantities and units of measure.
Due to the unique nature of Specware, the process of converting the engineering math ontology into an implemented format is not a single translation step into a target knowledge representation language. Instead, we first translate the ontology into knowledge-level Slang specifications; these are refined into executable code in a separate step. Overall, our experiment involved the following steps (see figure 3):
We now describe each of these steps in detail.
The engineering math ontology is well documented both as a technical paper [Gruber & Olsen, 1994] and its Ontolingua form. The latter is web-browsable and contains additional documentation not found in the paper. The process of understanding the ontology continued throughout the translation phase, as more details were required. Overall, we found the quality and clarity of the ontology to be high, but we also found some problems.
The engineering math ontology [Gruber & Olsen, 1994] covers a wide range of mathematical and physical concepts in the engineering domain. Many of these things (e.g. tensors) are not of immediate relevance to our simplified panel layout application. Therefore, the first step in this experiment was to identify a kernel, a subset of the full ontology, which captures the essential ideas needed for our two intended tasks: units conversion and dimensional analysis. Initially, only this kernel would be translated into Slang.
The minimum we require from the engineering math ontology is the ability to convert between quantities specified in different units and to perform dimensional analysis. A important secondary requirement is that sufficient axioms are present to be able to prove properties that must hold in order for the algorithms to be valid. This requires the axioms describing the algebraic properties of these operations to be included (e.g. commutativity). The kernel of the engineering math ontology identified to meet our tasks is described below.
These operations over quantities and dimensions have specific properties, and are examples of common algebraic objects. For example, physical dimensions form a vector space over the reals, where vector addition is multiplication of physical dimensions, and scalar multiplication corresponds to exponentiation defined on physical dimensions and real numbers. Understanding these algebraic properties provides the basis for performing dimensional analysis, e.g. to prevent adding `3 feet' to `45 calories'.
Here we describe the process and results of translating the knowledge-level representation of the engineering math ontology in Ontolingua to an equivalent knowledge-level formulation in Slang.
Note, this is a somewhat unique way to use an Ontolingua ontology. Ontolingua was designed with the expectation that ontologies would be translated directly into an implemented language such as Loom or Clips, not to an equivalent knowledge-level formulation which had to be further transformed into an implementation.
Initially, importing Ontolingua's representation appeared to be reasonably straightforward. The following are some informal mapping rules for translating Ontolingua to Slang.
Ontolingua is an unsorted logic, so conversion to Slang resulted in a more concise notation, avoiding frequent use of unary predicates required in Ontolingua. As a tradeoff, Slang's type theory requires using a relax operator to map sorts to supersorts, which is inconvenient and makes expressions harder to read. The differences seemed relatively minor.
This being the case, there was hope that some automated assistance might be possible, if only to kick-start the translation process. However, on closer examination, a number of important differences and other problems were identified. First, there are fundamental semantic differences. Second, even if we were able to produce a direct semantically correct translation using the above mapping rules, it may not use the expected representational idioms and conventions in the target language. This makes the translated version hard to understand and/or awkward to use. This is analogous to `misuse' of Prolog by someone who is unfamiliar with the logic programming paradigm. Finally, whether or not the representational idioms are being correctly used, there may be representational choices that are influenced by the intended task. We discuss some of these issues below.
Because Ontolingua is an extension of KIF, its semantics are founded on set theory; the semantics of Slang are founded on categorical type theory. To be confident of mapping classes and subclasses to sorts and subsorts, semantic differences would have to be carefully checked. If inferences were possible in one but not the other, work would have to be done to identify and contain the semantic differences responsible for such inconsistencies, in order to produce correct translations. We have not resolved this issue.
In Ontolingua, every class must be a subclass of Thing, which in the set-theoretic semantics of KIF means that it is not an unbounded set. In Slang, there is no need to distinguish bounded vs unbounded sets. Naive application of the above mapping rules would result in every Ontolingua class being introduced as a subsort; this is unnecessary and undesirable. Furthermore, every specification would have to have a sort corresponding to Thing, which brings us to the next point.
Virtually every ontology in Ontolingua imports the frame ontology, which is itself an extension of KIF. This is a substantial amount of infrastructure, including the class Thing, definitions of relations, numbers etc. Slang has its own notion of relations which is not explicitly defined in Slang, but rather is built in as part of the language. Slang specifications exist which define numbers. Instead of attempting to ensure that the whole Ontolingua/KIF infrastructure was represented in Slang, we introduced such things on an as-needed basis.
The most obvious and significant difference between styles of use between Ontolingua and Slang is how composition of larger modules from smaller ones is accomplished. The difference is fundamental and is reflected in the composition primitives available in each language. Slang's composition mechanism is defined in using diagrams in category theory; it is more general but also has some drawbacks.

Figure 4: Composition of Modules in Specware
Ontology inclusion in Ontolingua results in the union of the sets of axioms in all included ontologies. This semantics allows for cyclic inclusion of ontologies (e.g. A includes B which includes C which includes A). Slang does not support this. On the other hand, this way of doing composition makes it impossible to compose an ontology in Ontolingua by including multiple copies of an existing ontology which are instantiated differently by using parts of the ontology as parameters.
In Slang, this capability is fundamental. Specifications are often highly abstract, and effectively instantiated many times over. For example, one can include two copies of the specification for binary operators one for addition of physical quantities, and one for multiplication of physical quantities. This is made convenient by being able to introduce different local names for the different instantiations of the pieces of a specification. In one copy, you might call the operator which was named binop in the original spec as plus-q and in the other, times-q. Importantly, in Slang, these are two genuinely different things. Figure 4 illustrates some of these points using a more complex example.
Ontolingua allows you to give the same thing different local names when included into different ontologies. However, each local name is just a synonym; internally there is only one term to which all the synonyms refer. For example, suppose we have ontologies A, B, and C; X is a class defined in A, B and C both include A, X is renamed to Y in B and to Z in C. This results in the single class whose `real name' is `X@A'; the two local names `Y@B' and `Z@C' are synonyms. If C had also used the local name `Y' for X then the second synonym would be `Y@C' instead - this difference is of no real import.
Conversely, in Slang, when different specifications import the same component specification, copies of the original specification are inserted. In each copy, a unique local name may be given which is different from the original name, but unlike Ontolingua, they refer to different things, even if they have the same local name. Analogous to the example above, A, B, and C are specifications, and X is a sort; B and C both import specification A; and the local renaming is as above. There is no relationship between the local names for X in B and C unless you specify it. The two copies of sort X are called `Y.B' and `Z.C'. If C also renamed X to Y, then the second variable would be called `X.C'. It is not a synonym for anything.
Suppose we wish to specify that B and C are both to be part of yet a larger specification (say D). In Slang, composition is achieved by creating a formal diagram (as defined in category theory). All the specifications in the diagram are brought together using the colimit operation resulting in D. The user can specify in the diagram that both copies of the variable X, `Y.B' and `Z.C', refer to a single term in the composite specification: X.D. In this case the names are synonyms, as in the Ontolingua example.
This flexibility enables reuse of specifications to operate in a sophisticated parsimonious way. The price paid for this flexibility is that simple things can be more work to specify. Also, they may appear unduly complicated to those unfamiliar with this style of composition.
Ontolingua has alternate ways to achieve the parsimony and multiple reuse of basic concepts such as a binary operator which in Slang is accomplished by importing multiple parameterized versions of specifications (see next section).
Each language supports a very different way of thinking about and specifying composition. There are advantages and disadvantages of each. Because these differences are so large, each language has its own idioms and conventions for what constitutes a `good' way to modularize a theory. It turns out that the smallest ontologies in Ontolingua which are used to build up larger ontologies tend to be much larger than the smallest component specifications in Slang.
The Ontolingua ontology was well structured, using general principles from abstract algebra which are then used to specify the algebraic properties of the operations on physical quantities and dimensions. This aspect naturally lent itself to conversion into Specware, which emphasizes modularity and reusing and extending abstract specifications in more specific situations. However due to the Slang style of specification the modules created were much smaller in size and reuse was achieved quite differently.
For example, in Slang, there is a tiny specification called BINOP which defines a binary function directly. It may be imported as required in many different specifications. In Ontolingua, there is a higher order relation called BINARY-FUNCTION which achieves the same thing, semantically. In the single Ontolingua ontology, ABSTRACT-ALGEBRA, many properties were defined, (e.g. commutativity, associativity) which in turn were used to define algebraic objects such as semi-groups, groups and abelian groups. Each of these are relations. The axiom: (Abelian-Group Unit-Of-Measure * Identity-Unit) in the Ontolingua ontology says that the Class Unit-Of-Measure forms an abelian group with the operation `*' and the identity is `Identity-Unit'.
Abelian-Group is defined using the higher order relation: Commutative. The above abelian group assertion implies that (Commutative * Unit-of-Measure). An attempt to apply the direct mapping rules outlined above to translate this into Slang would have resulted in syntactically incorrect Slang code because it would require quantifying over sorts.
Even if we could have done it, it would not have suited our task. Saying something is an abelian group, among other things says that the commutative property holds. In Ontolingua, from a statement such as: (commutative * Unit-of-Measure) and the higher-order definition of the commutative relation, it can be inferred that for all instances u1 and u2 of the class Unit-of-Measure, u1*u2 = u2*u1. This axiom is not explicitly stated.
The manner in which we use the Slang specification requires that the axioms are used to prove certain properties. To avoid an impossible burden on the theorem prover, we need to have the axiom explicitly stated. Using Slang's parameterized composition facility, one creates a specification which does not explicitly assert that something is an abelian group, rather, the abelian group specification is combined with the physical quantities specification which defines Unit-of-Measure and the multiplication operation. The user creates a diagram and specifies that the abstract operator in the abelian group specification corresponds to the `*' operator in the physical quantities specification. This is just as in the example above where Y.B and Z.C were specified to be the same sort in D. In this way, the resulting specification includes all the axioms of abelian groups. Figure 4 illustrates how this works.
We judged the quality of the engineering math ontology to be very high overall, but there were some problems. For example, the definition of a Unit-of-Measure was circular. It turned out that to give a proper definition, was non-trivial and required adding more semantics to units of measure than was stated. We had to make educated guesses as to what was intended.
Some questions remain open. We had to examine and puzzle out what was probably intended from the plentiful documentation both in the technical paper and in the ontology itself. For example, are scalar physical quantities isomorphic to the reals? We are not completely sure, but have decided that most likely they are, and our specifications reflect this assumption.
Missing axioms caused a failure in the verification step (see later in Section 3.4), and so we subsequently added a more general axiomatization of some of these primitives. For example, definitions for basic algebraic concepts such as monoid, group, vector space, etc. were added in Slang in a modular fashion, for reuse in any specific theoretical or applied context (see figure 4).
Existing Slang specifications were also imperfect. We discovered some minor errors in the specifications provided by Specware for abstract algebra.
It turned out that Units-of-Measure not only form an abelian group as noted above, but from the stated axioms it was also true that it forms a vector space over the reals. Vector spaces were not defined in the Ontolingua abstract algebra ontology, we added a specification for it. Figure 4 indicates how we state this more general property using Slang's composition mechanism.
The translation of the initial kernel the engineering ontology into Slang resulted in an equivalent knowledge level formulation. We aimed for increased generality to support a variety of ways to implement operations on physical quantities and dimensions.
We did have certain tasks in mind, however, that the Slang specifications would be used for - namely, units conversion and dimensional analysis. Although the engineering math ontology was designed to make it possible to perform these tasks, they were not specified. These need to be identified and specified in Slang in order to apply the ontology (see figure 3).
This adds a task-specific component to the Slang specification, and included the necessary functions for performing units conversion. What is still missing is sufficient information about how to implement the knowledge-level theory of physical quantities as executable functions. This we describe next.
In keeping with the design decisions of the original ontology, the knowledge-level Slang encoding does not commit to any implementation details. In order to generate executable code, there are two main tasks. First, we must choose data structures for representing quantities and dimensions. Second, we must specify algorithms for performing operations on those data structures that correspond to operations and tasks to be performed on quantities and dimensions in the knowledge-level specification (e.g. addition, multiplication, units conversion).
If strings were used to represent physical dimensions, then string operations (e.g. concat) would be used to specify algorithms. Similarly, if lists were chosen, then list operations such as head and tail would be used. In this experiment, we chose to represent the dimension of a physical quantity as a tuple of real exponents, one for each of the basic dimensions (e.g. length, mass, time, money). For example, (1 0 0 0) and (1 0 -1 0) represent length and velocity respectively. Multiplication of dimensions is computed by adding exponents.

Figure 5: Data Structures and Algorithms
In Slang, data structures are specified using the sort-axiom statement, which states an equivalence between two sorts. For example, the sort Quantity is equivalent to a two-tuple whose first argument is a real number, and whose second argument is a dimension. The sort, Dimension, in turn is a 4-tuple of reals. See figure 5 for Slang specifications of these data structures, as well as algorithms for computing multiplication of quantities and dimensions.
A formal relationship is stated between the knowledge-level and implementation-level specifications. These are refinements. There may be a sequence of refinements, or just one depending on the particular problem. After we specified the required refinements, Specware generated Lisp code which successfully performed the required operations. When different units are specified, the necessary conversions take place.
Specware is a system for the specification and formal development of software. It assists the user in producing executable code that is provably correct with respect to the specification. In the previous step, we described how the user defines a series of refinements which ultimately lead to executable code. It is the user's responsibility to prove the validity of each refinement step, using the theorem prover provided.
For example, if sets are implemented as lists, then one must prove that the axiom in set theory stating that there are no duplicates is provable as a theorem from the definitions of set operations using the list data structure. Above, we described how we implemented physical quantities and units of measure as tuples. Multiplication of physical dimensions in the abstract theory is commutative. Therefore, to verify the refinement, we must prove that multiplication of dimensions as defined by manipulating tuples is still commutative. Given that multiplication is implemented by adding integer exponents, this follows from the fact that integer addition is commutative. We have manually performed some of the required proofs, but this verification step remains unfinished in our experiment.
Interestingly, we discovered (manually) that at least one axiom in the original Slang specification could not be proved from the refined implementation-level theory. This failure was traced not to an error in the refinement process, but to `missing' axioms in the original Ontolingua ontology. Specifically, the proof required axioms about some concepts which were treated as primitives, and hence were undefined, in the original engineering math ontology. We subsequently added these axioms in our Slang formulation.
The absence of this axiom in the engineering math ontology need not be viewed as an error. Eventually definitions must ground in some primitives. Because we needed to prove theorems, we had to add axioms that were deemed unnecessary in the original ontology. This example also shows how the required tasks which the ontology is to support affects representational choices in the original design, and subsequently affects ease of reuse.
The last phase is to integrate the result into the panel layout application. At present, this integration has been partially completed. Integration is not a simple matter of merging the code from the previous step with the code that already had been generated by Specware from the specification of the panel layout application. This will not work because the functions and equations in the former, do not refer to any of the things in the engineering math specification (see figure 3). In particular, recall from § 3 that the original version of the application represented physical quantities as real numbers. This is the usual thing to do in engineering software. However because we wish to add the capabilities of doing units conversion and dimensional analysis, this is no longer appropriate.
We proceed by modifying the specification of the panel layout task, and then merging this with the engineering math specification. In the new version, physical quantities are represented not as real numbers, but as instances of the sort physical-quantity in the Slang language. So instead of weight: panel -> real, we have weight: panel -> physical-quantity. This allows us to gain the desired functionality.
Importantly, integration does not occur at the implementation level, e.g. by inserting Lisp functions from both applications into a larger application. Rather it occurs at the specification level. This is advantageous, as the changes are then being made at a level of abstraction above executable code, and hence are simpler to make and more reusable. For example, we could change the refinement step described in the previous section and represent physical dimensions as strings rather than as tuples of integers. The knowledge-level specification would remain unchanged.
After the specifications have been merged, the combined declarative specifications must together, be refined into executable code. We have generated a Lisp function that computes the volume of a panel given dimensions in different units, providing the answer in a specified unit. We have also demonstrated two possible ways to perform dimensional consistency analysis. This is step towards our goal of having a general capability for producing engineering applications whose equations are always dimensionally correct.
A very important feature in Specware is that the refinement of a composite specification may be specified in terms of refinements of its individual components. The idea is that to refine the module containing both the engineering math and the panel layout specifications, we need only refine the revised versions of the panel layout specifications, while leaving the engineering math refinements unchanged. This is then combined with the results in the previous step of refining the engineering math specification. As compositions and refinements of existing knowledge already exist for the original panel layout example, only minor adaptations were be needed.
This is fundamental to achieving reuse, but comes at a price: it is complicated. It requires a solid understanding of the some of the basics of category theory in general, and of the category of specifications and specification morphisms in particular. Furthermore, there are some limitations of the Specware system which require can creative work-arounds. We have much to do before the application is fully developed using all of the functionality of Specware.
We have now described the start-to-finish process of reusing and applying an existing ontology in an engineering application. The application is small, and this is a feasibility demonstration only. Also, it remains to complete the integration, and to demonstrate that the approach to ensuring dimensional consistency and units conversion is sufficiently convenient to work with and scales to larger problems. Nevertheless, we have learned a great deal from this experiment.
This experiment was designed to explore and test the premise that it is possible to reuse existing bodies of engineering knowledge that may be used in the design of aircraft. We now reflect on our experience, and draw some conclusions about the engineering math ontology itself, Ontolingua, and the issues involved in incorporating an ontology into an application. We also assess the general feasibility of this process based on our experience and shed some light on how to identify reuse situations that are likely to succeed..
The engineering math ontology is of high quality. The formal approach required by Specware meant that additional work was needed to augment the existing axiomatization. Furthermore, we discovered nothing in the design of the engineering math ontology that seemed over-specific to a particular context or task that would limit its generality. It is important to note that this is exactly as it intended by its designers. Thus, other ontologies which were developed in more specific contexts may be harder to reuse.
As described earlier in Section 3.2, one significant issue did arise, namely: where should off-the-shelf ontologies ``ground out'' into primitives with assumed definitions? In our case, the grounding in the engineering math ontology was not a perfect match with our requirements, and we had to augment it with manual definitions for some of its assumed primitives. This is a general issue for the design of sharable ontologies, and one which requires further investigation.
Ontolingua appears satisfactory as an ontology representation language from the standpoint of being able to read and understand the ontology. In particular, it appropriately provides a rich, implementation-neutral, `knowledge level' language for specifying concepts, relations and axioms. The KSL ontology server provides a convenient way to browse the ontologies.
Perhaps the most important observation from this experiment is that there is significant manual effort involved in translating an ontology. This is true whether one is translating into an equivalent knowledge-level formulation, or directly into an implementation. This observation is particularly significant given recent interest in fully automatic translation between Ontolingua and AI languages supporting computation (e.g. Lisp, Prolog, LOOM) [Gruber, 1993b]. General and robust automatic translators from Ontolingua to implementation languages remain an open challenge to build.
From our experience here, we believe that the issue involves not only a rich source of difficult challenges which may in time be surmounted, there are some inherent barriers to fully automating the process of producing an accurate translation between any two highly expressive languages. Technical barriers include the requirement that the translator must embody full knowledge of the syntax and semantics of both languages. Related to this is the question of how much of the foundational infrastructure of a language must be translated before beginning with the ontology of interest. Even if these problems were overcome, and a provably correct mapping was possible between an arbitrary sentences in a given language, the output may be either hard to understand, or hard to use. This will likely arise when there are differences in the paradigms and/or intended purposes of the two languages. It will be especially difficult to integrate such automatic translations with hand-crafted knowledge bases which will use the correct idioms. An excellent example of this is the dramatically different styles of composition from component modules for Slang and Ontolingua.
Intrinsic problems that may never be overcome arise when design decisions required to make a good translation depend on information not present in the original ontology. In particular, one must consider the tasks to which the ontology is intended to serve.
This is not to advocate abandoning work on translation tools, but to suggest that such tools will likely be user-assisted for the foreseeable future.
We believe that Specware provides a very good platform for exploring ontology reuse and application. It has a very rich composition framework which encourages reuse of specifications at all levels. Also, by supporting formal refinements from knowledge-level to implementation, it is a way to directly use and apply ontologies.
Although significant work was involved in the full process of incorporating the engineering math ontology into our application, our subjective conclusions are that it would have taken significantly longer to design the knowledge content of this ontology from scratch in our application, or from just reading the technical papers describing it. The definitions in Ontolingua provided a clear, formal description of the target vocabulary, and greatly assisted us in understanding what was meant by the terms it defined. Finally, if the engineering math ontology becomes to some degree a standard, there is the longer-term potential that this and other applications built with it can interoperate more easily, as they conform to the same physical-quantities vocabulary. Although this conclusion is tentative, it is promising for achieving larger-scale knowledge reuse in the future.
We are grateful to Mike Barley for helpful discussions about the process of ontology translation in general with particular emphasis on translating Ontolingua into Slang.
(http://www-ksl.stanford.edu/knowledge-sharing/papers/README.html#ontolingua-intro. Also see the project page at http://www-ksl.stanford.edu/knowledge-sharing/ontolingua/index.html).
(http://www-ksl.stanford.edu/knowledge-sharing/papers/shade-papers.html).