| Abstract. Many tools and techniques have been developed for the systematic acquisition of domain knowledge, including knowledge elicitation (KE) methods to acquire knowledge from a human expert, machine learning (ML) algorithms that infer knowledge from data, and knowledge base refinement (KBR) tools that refine existing knowledge bases (KBs). As the number and sophistication of knowledge acquisition tools increases, it becomes progressively more difficult for users (notably domain experts) to choose between them for particular applications, especially when more than one is needed. We recognise the importance of driving this process by the epistemological requirements of the problem solver(s) which have been selected to solve a particular task. To support this approach, we introduce the MUSKRAT toolbox, which includes an advisory system coupled to several knowledge acquisition tools and problem solvers. This advice-giving system compares the requirements of the selected problem solver with available sources of information (knowledge, data, human expert). As a result, it may recommend either the reuse of existing knowledge bases, or the application of one or more knowledge acquisition tools, based on their knowledge-level descriptions. In this paper, we present the MUSKRAT framework and illustrate it with a detailed description of the prototype currently being implemented, which includes three problem solvers and four knowledge acquisition tools. |
We present a framework for problem solving and knowledge acquisition in which the epistemological requirements of the problem solvers drive the KA process. We aim to describe the kinds of data and knowledge which each problem solver requires, such that an advisory system will be able to recommend how the available information and knowledge sources can be transformed by a series of KA tools into the knowledge required by the problem solver. We illustrate the feasibility of the framework by building MUSKRAT, a MUltiStrategy Knowledge Refinement and Acquisition Toolbox (Graner and Sleeman, 1993). MUSKRAT is an open architecture which incorporates a number of KA tools and problem solvers, as well as an advisory system for commenting on the means-ends guidance.
This paper explains the origins and intentions of this research. The following section presents its background; section 3 describes the basic MUSKRAT framework; section 4 details the requirements of means-ends analysis, and section 5 reports on current progress with our MUSKRAT prototype. Finally, in section 6, we summarise our work and indicate some possible future research directions.
Having a model of the target problem solver is useful for guiding the
KA process. This is generally acknowledged in the KE community:
| `` Currently the main theories of knowledge acquisition are all model based to a certain extent. The model based approach to knowledge acquisition covers the idea that abstract models of the tasks that expert systems have to perform can highly facilitate knowledge acquisition.'' (van Heijst et. al, 1992). |
The integration of learning and problem solving is also a major issue in the field of integrated systems (SIGART Bulletin, 1991; VanLehn, 1988). Some systems integrate several KA tools with a problem solver (as in PRODIGY (Carbonell, Knoblock and Minton, 1991)). Others integrate KA and problem solving in a single component, using a uniform technique (THEO (Mitchell et. al, 1991), SOAR (Laird et. al, 1991)). In both cases, the knowledge base is tied to a particular problem solver. In contrast, MUSKRAT integrates existing, stand-alone KA tools with existing, stand-alone problem solvers, so that the knowledge can be tested independently and shared among several problem solvers. Knowledge sharing and reuse is further supported by the fact that all the knowledge acquired by the system is expressed in a single representation language, such as CKRL (Common Knowledge Representation Language), (Morik, Causse and Boswell, 1991).
Finally, the selection of an appropriate ML tool is also an issue in
many multistrategy learning systems (Michalski and
Tecuci, 1991). Some multistrategy systems include several ML techniques
(for instance both symbolic and sub-symbolic algorithms) which are applied
successively to generate a single knowledge base. In MUSKRAT, the knowledge
to be acquired is structured into several knowledge bases, each of which
is obtained with an appropriate technique. Other multistrategy systems
use highly discriminating selection criteria to opt for the most suitable
KA tool, but we are not aware of any system that chooses from as broad
a range of techniques as MUSKRAT, including KE, ML and KBR tools.
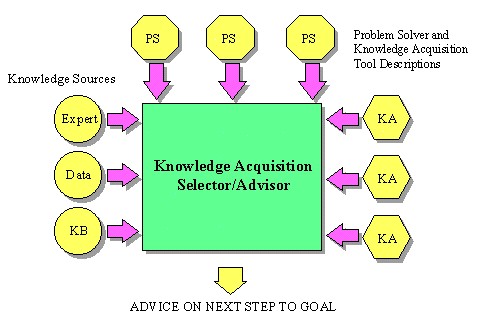
The MUSKRAT system is designed to support steps 3 to 5. It assumes that a problem solver has been selected for a particular task or sub-task, and directs the acquisition of knowledge for that problem solver. The system consists of any number of problem solvers, any number of KA tools, and a guidance module, the KA selector/advisor.
The tool selection process starts with a description of the problem and the subsequent selection of a corresponding problem solver. An advisory system may assist the user with this choice. This is not currently part of MUSKRAT, but a module similar to KEW's advice and guidance module (van Heijst et. al, 1992) should be applicable.
Once a problem solver has been selected, MUSKRAT knows which KB(s) are required. This follows because each problem solver specifies the knowledge it requires in terms of its functionalities and representation. These requirements are expressed in a formalism which provides descriptors for both knowledge-level and symbol-level features. We are currently defining such a formalism to describe the effects and requirements of the particular tools included in the MUSKRAT prototype.
The next step is to identify the available knowledge sources. We consider three broad categories of knowledge sources: available knowledge refers to knowledge that is already in the form required for a KB, e.g., a set of rules. It may be directly usable or require transformation or refinement. Note that knowledge bases are seldom available initially, but when MUSKRAT is used iteratively as part of a problem solving cycle, ``available knowledge'' refers to that acquired during a previous iteration. Available data refers to data that is relevant to the problem and from which useful information could be extracted, although it does not meet the requirements of the KB. Typically, this may consist of past cases, i.e., previously solved problems similar to the one at hand, from which insight into the new problem can be gained. Alternatively, if the problem is to diagnose faults in a complex system, ``available data'' may refer to a model of the system which is useful (or perhaps necessary) to perform diagnosis. Note that the distinction between knowledge and data is not intrinsic but depends on the KB requirements. For instance, a set of past cases is regarded as knowledge if it is to be used by a case-based reasoner that can use it directly, but only as data for a rule-based system which is unable to reason with cases. Finally, an expert is a person who can provide various forms of knowledge, possibly with the help of a KE tool and/or a knowledge engineer.
The KA selector/advisor is the central component of MUSKRAT (see Figure 1). It compares the requirements of the selected problem solver with the characteristics of available knowledge sources and recommends the use of one or more KA tools which should create the desired KBs. For that purpose, it needs a knowledge-level description of each available KA tool and performs a means-ends analysis to decide which one is most capable of reducing the differences for each of the required KBs. This is described in more detail in the following section.
Once the KA tools have been recommended, it is the user's responsibility
to run these tools on the specified inputs to acquire the required knowledge
bases. When this has been done for each of the KA tools, the user
should be able to run the recommended problem solver. If any of the above
stages fails it is currently the user who has to decide what course of
action to take. (When the system is built we will note carefully the actions
taken by users, with a view to a subsequent semi-automation of this stage.)
Additionally, it is the user's responsibility to evaluate the solution
obtained by the problem solver and, if necessary, to initiate a further
KA cycle.
In the rest of this section we focus on sub-topics associated with cases 1 and 2 given above.
In MUSKRAT, all knowledge bases are expressed in the same representation language, CKRL. CKRL (Common Knowledge Representation Language) is an information interchange language developed as part of the MLT project (Morik, Causse and Boswell, 1991). CKRL is not directly executable, but consists of declarations that can be translated into a tool's internal representation. To ensure that an unambiguous translation is possible to a wide range of representational schema, CKRL entities, (concepts, instances, relations, properties, sorts, rules, etc.) are defined at the epistemic level (Brachman, 1979). Our choice of a uniform knowledge representation was motivated by considerations of knowledge sharing and reuse: a KB should be usable by several problem solvers, even if these uses were not anticipated when the KB was created. It also allows the integration of new problem solvers and KA tools into MUSKRAT at the cost of implementing a single interface to and from CKRL.
Although CKRL was originally designed as a communication medium for ML tools, it is general enough to be useful in many situations where knowledge is to be transmitted or processed in a number of ways, including, for example, describing tools as part of the knowledge level model, and representing ontologies. An additional advantage of choosing CKRL is that some of the KA tools in our prototype are also part of MLT (Machine Learning Toolbox), and therefore already express their output in this language.
Each CKRL knowledge base is allocated an epistemological role when it is used as input to a problem solver or KA tool. The roles which each tool needs to have fulfilled before it can run are documented in the knowledge level model. For example, the conceptual clustering algorithm KBG expects two main inputs, a set of examples and a domain theory. Each of these represents a particular role which a knowledge base can play when used as input to KBG. The roles which a knowledge base plays when it is used in conjunction with one tool are not constrained by the roles which it plays when used in conjunction with others. We take the view that a collection of knowledge bases is not fit for the purposes of a particular problem solver unless all the required roles are fulfilled. To fulfil an allocated role, the knowledge contained in a knowledge base must be necessary, sufficient, and of the expected type. If a knowledge base is not fit for the role, we should like to determine why not, i.e., whether the knowledge it contains is:
- A rule base is inappropriate to be used as a set of examples.
- A knowledge base which contains both examples and rules is surplus to the requirements of a set of examples.
<knowledge base>
::= <ckrl entity>+
<ckrl entity>
::= { <concept> | <rule> | <relation> | <fact> | <instance>
| ...}
<rule base>
::= <rule>+
<set of examples>
::= <instance>+
<domain theory>
::= <domain entity>*
<domain entity>
::= { <concept> | <rule> | <relation> | <fact> | <instance>
}
In addition to inspecting the conceptual types of the proposed knowledge bases, we should like to ensure that the given knowledge is also the right knowledge for solving the problem at hand, but without actually running the problem solver. The advisor must therefore inspect each knowledge base with respect to the task and, with the assistance of descriptions of the competencies of the tool(s) in question, reject knowledge bases which clearly do not lead to a solution of the problem. Although our ideas are currently somewhat preliminary, this is the crux of the approach which we believe we can address at various levels of sophistication (details to be presented at the workshop).
Since the selection of KA tools must also fit into the framework of means-ends analysis, we also seek to specify:
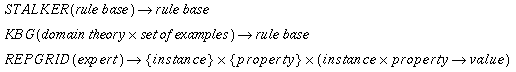
The prototype includes three different problem solvers and four KA tools
which were selected to deal with the given problems. In the following section
we describe the system-level architecture of the prototype, before describing
the components of MUSKRAT in more detail.
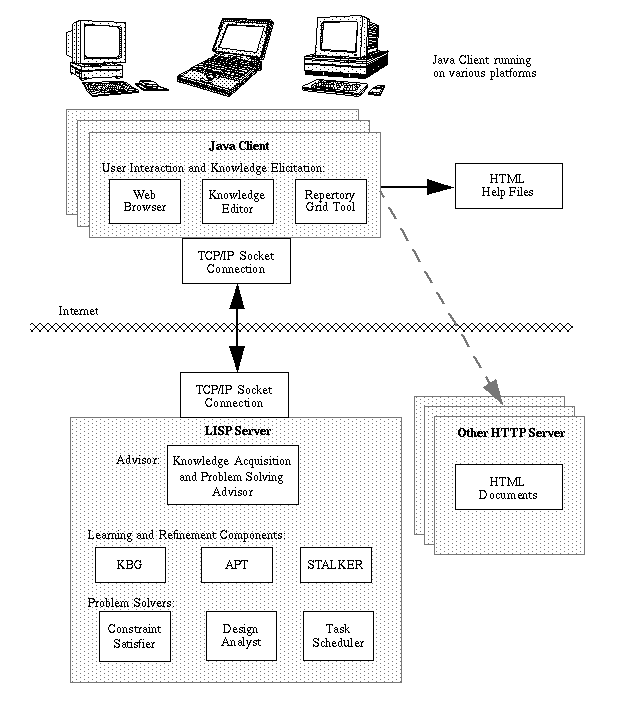
In line with current technology and communication trends, we decided to implement the MUSKRAT prototype as a client-server system which operates over the Internet (see Figure 2). This will not only make it easier for interested parties to try out our system, it will also provide a sound basis for further work in distributed knowledge acquisition and problem solving. The architecture consists of a LISP server and Java clients, which communicate via TCP/IP sockets. The client is relatively lightweight, currently providing a simple web browsing facility (envisaged mainly for help texts), a repertory grid tool9 (Boose, 1990), and automatic access to the server. We have also anticipated a visual CKRL knowledge editing tool, but the current implementation includes only a simple text editor. The LISP server contains the problem solvers, the rest of the KA tools, and the advisory system. We now describe the problem solvers, knowledge acquisition tools and the advisor in more detail.
The KBs required to solve this problem are:
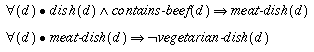
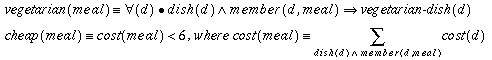
The KBs required by this problem solver are:
B2. A list of all the dishes that may appear in menus (identical to A2).
B3. A set of rules that relate descriptors to comments and recommendations, for instance
B4. Background knowledge not contained in any of the KBs B1-B3.
The KBs required by this problem solver are:
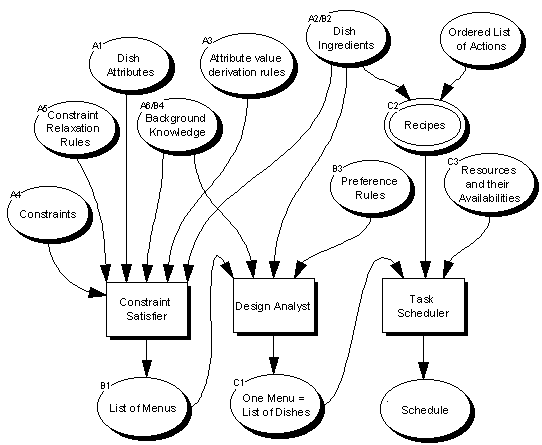
KB reuse in the MUSKRAT prototype is conveniently summarised in Figure 3. In this figure, the ovals denote knowledge bases, the rectangles denote problem solvers, and the arrows indicate the direction of knowledge flow.
Repertory Grid The repertory grid is a KE technique derived from social/cognitive psychology (Kelly, 1955; Boose, 1990). It provides a systematic way of interactively eliciting elements (examples) and constructs (descriptors) from an expert. Although it is fundamentally a methodology, it can be supported by software tools such as Tacktix (Reichgelt and Shadbolt, 1991) that not only acquire this knowledge but also compute similarities and correlations between elements and between constructs. More recently, repertory grid tools have also been implemented for use on the Internet (Gaines and Shaw, 1997).
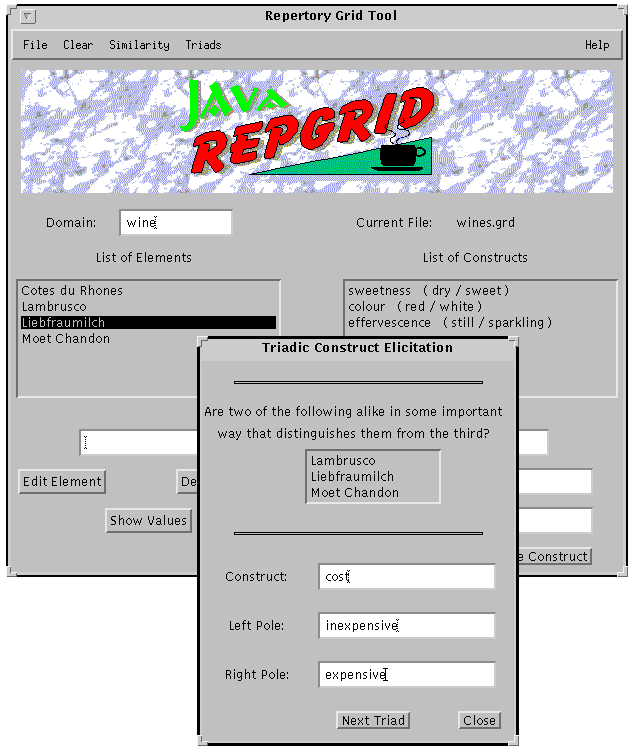
In our application, this tool is used to acquire simultaneously dish descriptors (A1) and descriptions (A2 and B2), since these KBs must be acquired directly from an expert (see Figure 4). In addition, correlations between descriptors suggest possible rules for A3, although those can be more adequately acquired by KBG (see below).
KBG KBG (Bisson, 1992) is an ML clustering and generalisation tool. It can either take unclassified examples and cluster them according to a particular, flexible metric, or take classified examples and induce discrimination rules. In both cases, it can also use background knowledge in the form of rules to complete example descriptions. An interesting feature of KBG is that its learning examples and output rules are expressed in (restricted) first-order logic, which means in particular that all the examples need not be represented by the same descriptors.
In our example, KBG is used to infer rules for A3: given a small number of complete dish descriptions, it finds correlations between descriptors that can later be used to complete new (incomplete) descriptions.
It can also be used to infer control rules for A5. In this case, a learning example is a set of constraints and an indication of which one should be dropped. Since constraints are complex objects that cannot be represented as attribute/value pairs, KBG's first order representation is very suitable for this task.
Finally, its clustering and concept formation ability can be used to select useful predefined constraints (A4). Since such constraints are provided only for user convenience, it is useful to detect patterns that occur frequently in user-defined constraints, and add them to the set of predefined constraints. KBG can help with this pattern detection.
APT APT (Nédellec and Causse, 1992) uses a combination of KE and ML techniques to acquire problem solving rules. It starts with a domain theory, in the form of a semantic network, and possibly an initial set of rules. When it cannot solve a problem with its rules, it asks the user for a particular solution, then uses the domain theory to generalise it. The user is constantly requested to validate the rules generated by the system, and can extend the domain theory if necessary to enable APT to infer correct generalised rules.
When a limited domain model is available, APT can be used as a KE tool to acquire rules and enhance the model. When an important set of rules is available, it can be seen as an interactive KBR tool. These capabilities, together with its rich knowledge representation (semantic network) make it suitable to acquire analysis rules (B3), as well as recipes (C2) that can be regarded as problem decomposition rules.
STALKER STALKER is an efficient automatic knowledge base refinement tool (Carbonara and Sleeman, 1996). Given a set of Prolog-like rules, and an example incorrectly classified by these rules, it considers many possible remedies (generalising or specialising rule premises, re-ordering rules, adding new rules, etc.), tests them against known cases and implements the most successful ones. It occasionally consults an expert to validate its recommendations. In our prototype, STALKER uses examples of menus commented on by an expert to refine the ``comment'' rules (B3).
Table 1 summarises the relationships between MUSKRAT's
problem solvers, KA tools and knowledge bases.
|
|
|
|
| A1 | Constraint Sat., Analysis | Grid |
| A2, B2 | Constraint Sat., Analysis | Grid |
| A3 | Constraint Sat., Analysis | KBG, Grid |
| A4 | Constraint Sat. | KBG |
| A5 | Constraint Sat. | KBG |
| B3 | Analysis | APT, STALKER |
| C2 | Scheduling | APT |
| C3 | Scheduling | (no tool) |
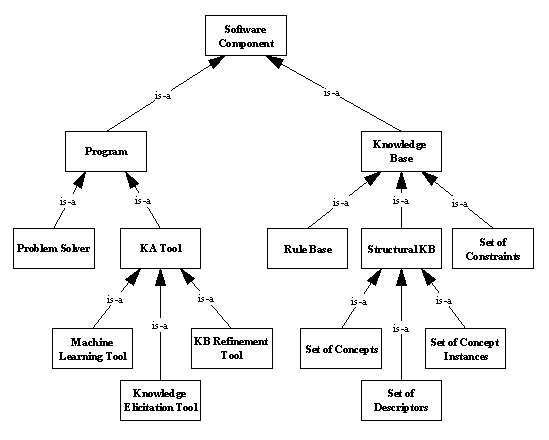
The advisor can currently perform two basic actions, which we call describe and run:
describe katool:
katool is-a program
ketool is-a katool
kbrtool is-a katool
mltool is-a katool
repgrid instance-of
katool
stalker instance-of
katool
kbg instance-of katool
apt instance-of katool
katool outputs kb
katool requires kb
describe constraint_satisfier:
constraint_satisfier
instanceof problem_solver
constraint_satisfier
instanceof program
constraint_satisfier
requires constraints
constraint_satisfier
requires dish_attributes
constraint_satisfier
requires derivation_rules
constraint_satisfier
requires constraint_relaxation_rules
constraint_satisfier
requires dish_ingredients
constraint_satisfier
outputs setof_menus
describe scheduler:
scheduler instance-of
problem_solver
scheduler instance-of
program
scheduler requires menu
scheduler requires recipes
scheduler requires setof_resources
scheduler outputs schedule
describe recipes:
recipes instance-of
kb
recipes has name
scheduler requires recipes
run constraint_satisfier:
Do not know how to acquire
constraints
try acquiring dish_attributes
with repgrid
try acquiring derivation_rules
with stalker
try acquiring derivation_rules
with kbg
try acquiring derivation_rules
with apt
constraint_relaxation_rules
already exists
try acquiring dish_ingredients
with repgrid
run scheduler:
try running design_analyst
to output menu
Do not know how to acquire
recipes
Do not know how to acquire
setof_resources
Our work is currently focusing on the following two issues.
Since the MUSKRAT prototype is being implemented as a client-server system, there are opportunities for enhancing the network architecture. For example, the KA Selector/Advisor could be implemented as a single broker agent which sends interested parties to one of a number of distributed MUSKRAT servers. This approach may lead to both improved support for distributed knowledge acquisition, which is particularly important for corporate intranets, and to easier access to problem solvers, together with their associated knowledge.
Whenever an existing knowledge base could be modified to meet a problem solver's requirements, the necessary transformations should be computationally identified and supported. A possible approach to this task is to carry out human-based empirical studies in which each subject is provided with a problem solver and a small set of knowledge bases which are unsuitable for immediate use by that problem solver. The subject's task is to transform the available knowledge into knowledge which is suitable for the problem solver, if necessary with the aid of KA Tools. Observation of the techniques which human subjects use may yield useful information as to how the task can be supported computationally.
A challenging goal for future research would be to enhance the MUSKRAT system such that the knowledge-level descriptions of problem solvers and KA tools are automatically generated (or refined) by letting the system perform its own experiments. This opens interesting perspectives in the field of autonomous multistrategy learning systems.
Acknowledgements This work is financially supported by an EPSRC research studentship. The Machine Learning Toolbox Project (ESPRIT project 2154) provided not only inspiration, but also an implementational foundation for some of our work. We are also grateful to the anonymous referees who provided very useful comments on a previous version of this paper.
Boose, J. H., (1990), ``Uses of Repertory Grid-Centered Knowledge Acquisition Tools for Knowledge-Based Systems'', in Boose, J., Gaines, B., (Eds.), Foundations of Knowledge Acquisition, Knowledge-Based Systems Book Series, Volume 4, pp. 61-83, London: Academic Press.
Brachman, R. G., (1979), ``On the Epistemological Status of Semantic Networks'', in Associative Networks: Representation and Use of Knowledge by Computers, Findler, N. V., (Ed.), New York: Academic Press, pp. 3-50.
Carbonara, L., Sleeman, D., (1996), ``Improving the Efficiency of Knowledge Base Refinement'', in Proceedings of ICML 96, Bari, Italy, pp. 78-86.
Carbonell, J. G., Knoblock, C. A., and Minton, S., (1991), ``Prodigy: An integrated architecture for planning and learning'', in (VanLehn, 1988), pp. 241-278.
Craw, S., Sleeman, D., Graner, N., Rissakis, M., and Sharma, S., (1992), ``CONSULTANT: Providing advice for the Machine Learning Toolbox'', in Proceedings of the 1992 BCS Expert Systems Conference, Bramer, M. (Ed.), Cambridge University Press.
Fensel, D., Groenbloom, R., (1997), ``Specifying Knowledge-Based Systems with Reusable Components'', in Proceedings of the 9th International Conference on Software Engineering & Knowledge Engineering (SEKE-97), Madrid, Spain.
Gaines, B., Shaw, M. L. G., (1997), ``Knowledge acquisition, modelling and inference through the World Wide Web'', International Journal of Human-Computer Studies, 46, pp.729-759.
Ganascia, J-G., Thomas, J., and Laublet, P., (1993), ``Integrating models of knowledge and machine learning'', in Machine Learning: ECML-93, Brazdil, P. B. (Ed.), Springer-Verlag.
Graner, N., Sleeman, D., (1993), ``MUSKRAT: a Multistrategy Knowledge Refinement and Acquisition Toolbox'', in Proceedings of the Second International Workshop on Multistrategy Learning, Michalski, R. S., Tecuci, G., (Eds.), pp. 107-119.
Gray, P. M. D., Preece, A., Fiddian, N. J., Gray, W. A., Bench-Capon, T. J. M., Shave, M. J. R., Azarmi, N., Wiegand, M., Ashwell, M., Beer, M., Cui, Z., Diaz, B., Embury, S.M., Hui, K., Jones, A. C., Jones, D. M., Kemp, G. J. L., Lawson, E. W., Lunn, K., Marti, P., Shao, J., and Visser, P. R. S., (1997), ``KRAFT: Knowledge Fusion from Distributed Databases and Knowledge Bases'', Conference on Database and Expert System Applications (DEXA '97), Toulouse, France.
Kelly, G. A., (1955), ``The Psychology of Personal Constructs'', Norton, New York, 1955.
Kodratoff, Y., Sleeman, D., Uszynski, M., Causse, K., Craw, S., (1992), ``Building a Machine Learning Toolbox'', in Enhancing the Knowledge Engineering Process, Steels, L., Lepape, B., (Eds.), North-Holland, Elsevier Science Publishers, pp. 81-108.
Laird, J., Hucka, M., Huffman, S., and Rosenbloom, P., (1991), ``An analysis of Soar as an integrated architecture'', in SIGART Bulletin Special Section on Integrated Cognitive Architectures, 2 (4), pp. 98-103.
Marling, C. R., Sterling, L. S., (1996), ``Designing Nutritional Menus Using Case-Based and Rule-Based Reasoning'', in Artificial Intelligence in Design `96, Kluwer Academic Publishers.
Michalski, R. S., and Tecuci, G. (Eds.), (1991), Proceedings of the First International Workshop on Multistrategy Learning (MSL-91), George Mason University, Fairfax, VA.
Mitchell, T. M., Allen, J., Chalasani, P., Cheng, J., Etzioni, O., Ringuette, M., and Schlimmer, J.C., (1991), ``Theo: A framework for self-improving systems'' in (VanLehn, 1988), pp. 323-355.
Morik, K., Causse, K., and Boswell, R., (1991), ``A common knowledge representation integrating learning tools'', in (Michalski and Tecuci, 1991), pp. 81-91
Nédellec, C., and Causse, K., (1992), ``Knowledge refinement using Knowledge Acquisition and Machine Learning Methods'', in Proceedings of EKAW-92, Springer Verlag.
Newell, A., (1982), ``The Knowledge Level'', Artificial Intelligence 18(1), pp.87-127.
Puerta, A., Egar, J., Tu, S., Musen, M., (1992), ``A Multiple-Method Knowledge-Acquisition Shell for the Automatic Generation of Knowledge-Acquisition Tools'', Knowledge Acquisition, 4, pp. 171-196.
Reichgelt, H., and Shadbolt, N., (1992), ``ProtoKEW: A knowledge-based system for knowledge acquisition'', in Artificial Intelligence, Sleeman, D, and Bernsen, NO (Eds.), Research Directions in Cognitive Science: European Perspectives, volume 6, Lawrence Erlbaum, Hove, UK.
SIGART Bulletin, (1991), Special section on integrated cognitive architectures, 2(4), Aug. 1991.
Sleeman, D., Rissakis, M., Craw S., Graner N., Sharma S., (1995), ``Consultant-2: Pre- and Post-processing of Machine Learning Applications'', International Journal of Human-Computer Studies, 43, pp. 43-63.
Sundermeyer, K., (1991), ``Knowledge-Based Systems: Terminology and References'', Bibligraphisches Institut Wissenschaftsverlag, Mannheim, Germany.
van Heijst, G., Terpstra, P., Wielinga, B., and Shadbolt, N., (1992), ``Using generalised directive models in knowledge acquisition'', in Proceedings of EKAW-92, Springer Verlag.
VanLehn, K. (Ed.), (1988), ``Architectures for Intelligence'', Proceedings of the 22nd Carnegie Mellon Symposium on Cognition, 1988, Lawrence Erlbaum, Hillsdale, NJ.
Visser, P. R. S., Jones, D. M., Bench-Capon, T. J. M., and Shave, M. J. R., (1997), ``An Analysis of Ontology Mismatches; Heterogeneity versus Interoperability'', AAAI 1997 Spring Symposium on Ontological Engineering, Stanford University, California, USA, pp.164-172.
Wielinga, B. J., Schreiber, A. T., and Breuker,
J. A., (1992), ``KADS: a modelling approach to knowledge engineering'',
Knowledge Acquisition, 4(1), pp. 5-53.
End Notes (these correspond to footnotes in the paper version).
| 1. Note that we use the term KA to include KE, ML & KBR techniques. |
| 2. In this paper the knowledge level is characterised by its implementation independence, as advocated by the KADS methodology (Wielinga, Schreiber and Breuker, 1992). |
| 3. Or, if you like, a top level description of the kinds of information transformations which each of the tools can achieve. |
| 4. We use the phrase "Means-Ends Analysis" interchangeably with "Means-Ends Guidance". Strictly speaking, the guidance should be dependent on the analysis! |
| 5. In this case, it may be reasonable to suggest a separation of the knowledge base into two or more knowledge bases. |
| 6. Extended Backus-Nauer Form. In this notation, angled brackets ('< >') denote non-terminal symbols, braces and the vertical bar ('{ ... | ... }') denote alternatives, an asterisk ('*') used as a postfix denotes zero or more occurrences of the preceding non-terminal symbol, and a plus sign('+') denotes at least one occurrence of the same. |
| 7. A reference could be supplied, where possible. |
| 8. Personal Construct Psychology uses the term element for an instance and construct for a property. |
| 9. Most of the main program components are better placed at the server site, where they can be monitored and maintained. However, knowledge elicitation tools are sometimes better placed in the client program because of their interactive nature. |
| 10. A demo of our Repertory Grid Tool is at http://www.csd.abdn.ac.uk/~swhite/repgrid/repgrid.html |
| 11. We are not currently addressing the repair problem which arises in the event of mismatches. |