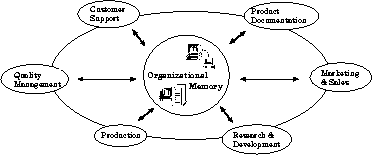
Figure 1: Managing enterprise knowledge in an Organizational Memory
Andreas Abecker
Ansgar Bernardi
Knut Hinkelmann
Otto Kühn
Michael Sintek
German Research Center for Artificial Intelligence - DFKI GmbH
Postfach 2080, 67608 Kaiserslautern, Germany
Phone: +49-631-205-3467, Fax: +49-631-205-3210
Email: {aabecker,bernardi,hinkelma,kuehn,sintek}@dfki.uni-kl.de
An Organizational Memory is an enterprise-internal application-independent information and assistant system. It integrates various techniques and tools to support knowledge management. Motivated by the growing need for enterprise-wide knowledge management we performed several studies and identified the functional requirements for an Organizational Memory. To cope with these we propose a three-layered architecture for representing the knowledge. On this basis, the Organizational Memory shall serve as an intelligent assistant to the user and process both formal and non-formal knowledge elements in a task-oriented way. The concepts described here are the object of ongoing research, but are employed and tested in several application projects which run in parallel.
Knowledge has been recognized as one of the most important assets of an enterprise, which decisively influences its competitiveness. This has led to a growing interest in Knowledge Management and has raised questions about what information technology should be provided for its support.
Our long-term vision is the Organizational Memory (OM) at the core of a learning organization, supporting sharing and reuse of corporate knowledge and lessons learned. Intelligent knowledge utilization services are arranged around an OM which actively provide the user working on a knowledge-intensive operational task with all the information necessary and useful in order to optimally fulfill the task.
This view of an Organizational or Corporate Memory which was developed based on practical experiences conforms well with definitions suggested in the literature: Together with [23] we consider as the main function of an OM to improve the competitiveness of an organization by improving the way in which it manages its knowledge. Short-term efforts should concentrate on knowledge preservation [3] and, in particular, knowledge capitalization [17], but in the long run an OM should also support knowledge creation and organizational learning [1, 13]. Together with [11] we think that an OM has to be more than an information system but must help to transform information into action.
In the current paper, we will first present some essential practical requirements for a successful OM, which we identified in industrial case studies and which have to be taken into account when discussing technological issues. We will then identify typical functionalities and suggest an architecture. We will conclude by discussing OMs as intelligent assistant systems, make suggestions for knowledge maintenace, and present some intended future work.
During recent years we performed several case studies, prototype developments, and evaluations concerning knowledge-based systems for supporting complex tasks in technical domains, e.g. motor design or configuration of production facilities. Dialogs with industrial customers and the growing understanding of their particular needs led to a shift in focus from the expert system approach centered around the idea of an autonomous problem solver towards the idea of an intelligent assistant system emphasizing the support of the human user by providing, collecting, and distributing relevant information and knowledge. The central topic common to the different tasks proved to be the structuring, maintenance, and effective utilization of various kinds of organizational knowledge available in different forms. This observation corresponds well with the growing interest in Knowledge Management in general and has been reinforced by an increasing number of inquiries by customers from non-technical fields.
In [8] two of the authors have summarized the experiences from three case studies, in which two system specifications and one prototype for an Organizational Memory were developed. From the numerous interviews conducted with prospective users and the discussions with IT personnel and management, the following requirements were identified as crucial for the success of an Organizational Memory in industrial practice:
Given the practical requirements, an OM has to provide the following functionality:
An OM is an enterprise-internal application-independent information and assistant system. It stores large amounts of data, information, and knowledge from different sources of an enterprise. It will be permanently extended to keep it up-to-date and can be accessed enterprise-wide through an appropriate network infrastructure (cf. Figure 1).
Figure 1: Managing enterprise knowledge in an Organizational Memory
The ultimate goal of an OM is to provide the necessary knowledge whenever it is needed. To assure this, the OM realizes an active knowledge dissemination approach which does not rely on users' queries but automatically provides knowledge useful for solving the task at hand. To prevent information overload this approach has to be coupled with a highly selective assessment of relevance. The resulting system shall act as an intelligent assistant to the user.
There are two principal ways to interact with an Organizational Memory:
During the utilization it may turn out (e.g. as user feedback) that the knowledge is false, out of date, or incomplete, and new knowledge may be generated. Therefore, both ways of dealing with an OM have to be integrated [9]. At the time when new knowledge is added into the OM it is generally not known who will use the knowledge for which task.
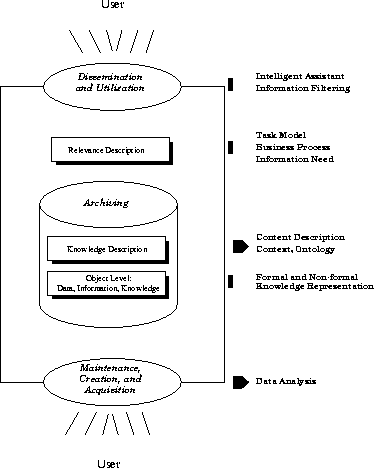
Figure 2: Principal Architecture of an Organizational Memory
Given the intended functionality of an Organizational Memory, we propose a three-layer architecture for its implementation (cf. Figure 2):
In the following subsections these layers are described in more detail.
Given the practical requirement of keeping up-front knowledge engineering at a minimum, an OM has to use available sources of information which usually are documents and databases. The costs and efforts required for formalizing major amounts of knowledge are prohibitive, so that an OM will have to deal with nonformal knowledge contained in more or less structured electronic documents. Furthermore, informal knowledge offers the advantage that it is well tailored to human needs. Natural language, graphics, or images can be readily produced and understood in order to express and exchange every kind of knowledge, whereas for the acquisition and presentation of formal knowledge special translation tools have to be developed (see [10]).
Informal knowledge contained in documents has, however, the serious disadvantage that it cannot be applied for automatic problem solving and is of rather limited use for providing computer assistance to human problem solving. Therefore, crucial parts of corporate knowledge which have to be processed by the the computer need to be formalized whereas other parts which need only be understood by humans may be left informal. In [9] an OM prototype is presented in which parts of a company's design knowledge are formalized as rules which are employed for critiquing and suggesting viable solutions. The reasons for the design rules which are important for assessing the relative merits of several viable design alternatives are attached as natural language annotations taken directly from the expert interview protocols.
At the object level of an OM we thus distinguish informal knowledge in documents, database records, and formalized knowledge. To access databases and document management systems Information Retrieval techniques are applied [15]. For the sharing and reuse of formal knowledge appropriated methods such as developed in the ARPA Knowledge Sharing Effort [12] will be employed. In both cases, it is essential to supplement object-level items with additional information that enable efficient retrieval, promote the comprehension, and allow their utilization in various task contexts. This information is provided at the knowledge description level.
The knowledge description level is a meta-level characterization of the object-level knowledge describing its content and form, together with links to the original sources. The knowledge description enables
Without this description, non-formal knowledge is not ingeniously usable. It is decisive for successful knowledge sharing and exchange. Information Retrieval techniques [15] supplement documents with additional data that enable efficient retrieval. Examples are the attachment of key words or document classification. For representing knowledge decriptions, we will adapt and extend document representation languages from Hypermedia Retrieval (cf. [6, 14]) towards the specific needs of representing knowledge elements.
Concerning the content of such a knowledge description, Table 1 shows an example of possible attributes in a kind of frame representation. In addition to the description of van der Spek and de Hoog [22, 23] we add as a fourth category ontological information underlying the given formalization. This approach to knowledge organization in an OM is inspired by the KADS methodology for organizing reusable components of formal knowledge in expert system development.
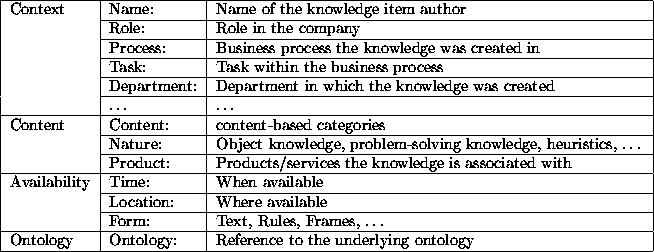
Table 1: Knowledge Description Attributes
Data, text documents, and formal knowledge are examined as basic elements containing information at the object level. There are three types of meta-level descriptions for these kinds of informations:
Enterprise ontologies are developed in various projects like TOVE [5], KACTUS [16], or the Enterprise Project [21, 19]. The relationship between data models and ontologies has been extensively investigated in the KACTUS project. The development of ontologies and data models takes place prior to filling the object level information (with possible iterations) and takes up a considerable portion of the total development effort. In contrast, thesauri are usually automatically built-up from collections of available documents.
The integration of these kinds of meta-level descriptions poses an interesting research question. Of special interest is their tailorization towards task- and context-specific knowledge reuse and the idea of automatically constructing more formally based classification systems in the spirit of thesaurus generation.
Other contributions to cheaply filling the knowledge description level come from document analysis and understanding. The description of the document content can in part be extracted automatically. In [4] a number of document analysis techniques are described that were developed in our department. They extract relevant information, learn appropriated classes of documents, or classify documents according to a given set of classes. Some of the techniques are specifically qualified to extract information from printed documents and thus allow the reuse of already existing documents in an OM.
For the effectivity of an OM it is important that the user receives relevant information at the right time without being overwhelmed with a flood of irrelevant information. Information is relevant if the user can perform his task better with this information than without it. Thus, relevance of information is always defined wrt its utilization.
In contrast to conventional information filtering, actively providing information in an OM is primarily oriented according to a task model instead of a user model. Up to now, knowledge on task-specific relevance is only implicitly represented in application programs, encoded in database queries, or not represented at all, but hidden in assumptions underlying the active by-hand-navigation in hypertext information systems. Instead we propose to explicitly represent the relationship between task, application situation, and knowledge context in a declarative way. Explicit modeling facilitates application development and maintenance, makes automatic analyses possible, and allows for systematic evolution of the OM content and behaviour over time.
Since there is no general definition of relevance, we will examine how task-specific relevance is related to concepts like similarity in Case-Based Reasoning, interestingness in Information Filtering and Data Mining, and relevance in Information Retrieval.
One way to achieve task-specific relevance is by orientation towards a business process. There are tools for modeling businesses which, however, do not establish any association to organizational knowledge. The modeling techniques of these tools can be extended by appropriate attributes to characterize the knowledge relevant for processing a particular task.
The actual state of process execution specifies the context for providing relevant information and giving active assistance. This context information is available in Workflow Management Systems. A long-term objective is to combine an Organizational Memory with a Workflow Management System.
Following these concepts we develop the means to explicitly model the connection between information elements and the application tasks which rely on them. According to the definition knowledge = information made actionable we thus realize the transition from information handling to Knowledge Management--which is what the whole idea really is about.
An important goal of Artificial Intelligence has been to build knowledge-based systems that were able to solve challenging problems on their own. In contrast, an intelligent assistant system cooperates with a human user in order to solve a problem. It contributes to the solution, for instance, by solving subproblems, performing calculations, or by verifying or criticizing the user's solutions.
This approach has gained considerable interest due to a variety of reasons: Well-known difficulties of conventional knowledge-based systems like brittleness or limited user acceptance called for adequate solutions. Many successfully deployed expert systems achieved their results by being used to support the human experts, hence as assistant systems [20]. To solve important problems it is often desired to let the computer work out what might be done but to let the human user decide (cf. [7]), thus distinguishing workload vs. decision competence and responsability. The combination of the assistant system and the user shall result in increased problem-solving capabilities as well as better user acceptance.
Brooks illustrated this cooperation by the formula ![]()
meaning
that an Intelligence Amplification system--machine and a mind--can
beat an Artificial Intelligence system--a mind-imitating machine
working by itself [2].
An OM realizes the idea of an intelligent assistant system. Working on the formal knowledge, the inference engine takes over the tasks of knowledge dissemination, utilization, and maintenance. This part of the system is completed by a component for information filtering which handles the non-formal knowledge (cf. Figure 3). Both subsystems are guided by an adequate task model and interact closely with the human user who is thus empowered to solve the complex problem at hand. In summary, the combination of suitably processed formal knowledge and relevant and specific non-formal knowledge together with the user's problem-solving skills result in problem-solving capabilities which surpass any of the components alone.
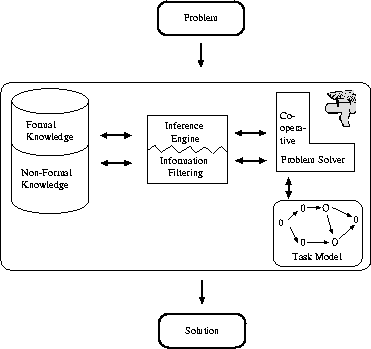
Figure 3: The Organizational Memory as Intelligent Assistant
The OM resides in a dynamically changing environment and will be subject to frequent changes and adaptations. The development of tools and methodologies for an efficient maintenance of the OM is thus a crucial research topic.
The proposed three-layered architecture for the representation of knowledge in the OM offers a structured basis for maintenance activities, but requires additional effort to keep the three layers consistent and up-to-date.
In particular we identify several maintenance-related questions:
The overall vision motivating these research topics is the continuous evolution of the Organizational Memory in tight integration with its use [9].
The concept of an enterprise-wide Organizational Memory as described in this paper has been implemented only rudimentary. It is based on studies and prototypical realizations for parts of enterprises [8].
For the implementation of our three-layer architecture we build upon previous work done in the context of knowledge acquisition and knowledge structuring, currently being further developed for requirements engineering in software development. An important goal in this context is to enable the automatic gathering of knowledge descriptions as additions to non-formal knowledge elements.
The implementation and use of specific task models is highly dependent on particular applications. Our research is accompanied by several application projects in cooperation with industry and other research projects. Among them is a project on intelligent filtering and presentation of Internet resources. A project on intelligent fault recording and diagnosis support in a mechanical engineering domain provides a vast amount of well-structured but non-formal technical documentation together with a concise domain ontology and a crisp task model. We thus expect to be able to realize the concepts presented here in this domain. The resulting organizational memory shall be operational in one year's time.