In this scenario, we show how the formal KL-models of five agents (the incremental inductive learning algorithms ID4, ID4R, ID5, ID5R and IDL [van de Velde 91]) can be analyzed in order to understand the different ways in which they carry out the task of incremental inductive learning. The task of incremental inductive learning is to find a consistent and small decision tree which represents a target concept by progressively refining, with a current example, a previous decision tree learned from a set of examples known so far. Incremental means that examples are given sequentially, i.e. one after another instead of all at a time. The formal descriptions of the KL-structures that integrate their formal KL-models are examined in decreasing order of complexity, leading to a breath first exploration of the agents task structures (see fig. 2). As the five agents are algorithms of a same family, their task structures are almost identical till the fourth level of decomposition (differentiating KL-structures are framed by boxes with thicker borderline in fig. 2). Whenever a differentiating KL-structure is encountered, the different formal descriptions agents assign to it are analyzed and compared in order to identify differences and similarities.
![]()
Figure 2: Common part of the agents task structures.
We illustrate this comparison process through the analysis of the different formal descriptions the agents have for the KL-structure expand-TDIDT-IDM. In order to make comparison easier, we have grouped together the formal descriptions of the instantiated decomposition method expandTDIDT of several algorithms. The formal description on the left hand side describes expand-TDIDT as ID4 would do it, but if we replace each part that is followed by a box with the content within the box we obtain the formal description of ID5. The same holds for the formal description on the right hand side, ID4R, ID5R and IDL.
First, we observe that the formal descriptions of ID4 and ID5 establish the same task decomposition, data and control flows among their subtasks, although they apply different methods to carry out split and prune subtasks. The same argument applies to ID4R, ID5R and IDL, the difference being that they introduce different task decomposition, data and control flows than the first group. With respect to the differences in the methods applied to split and prune subtasks, similarities are found between ID4 and ID4R, which use split-IRM and prune-IRM, while ID5, ID5R and IDL use pull-up-IDM and virtual-prune-IRM.
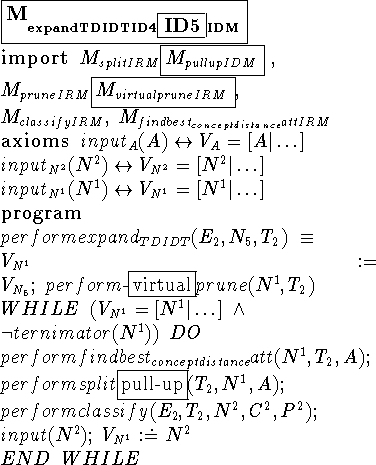 \
\
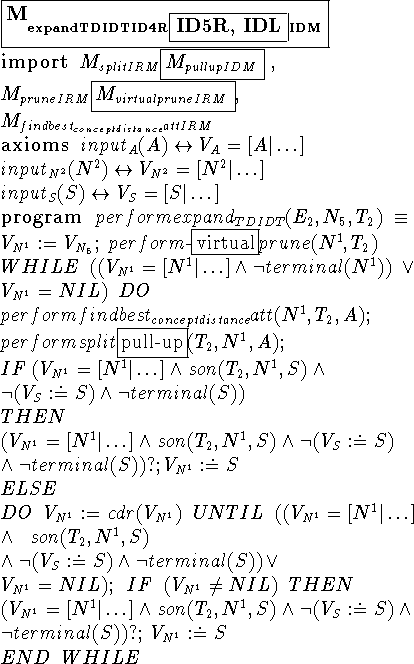
The use of virtual-prune-IRM is advantageous because it may save a substantial amount of computational effort, so ID5, ID5R and IDL are more efficient than ID4 and ID4R. On the other hand, the control flow established by ID4 and ID5 expands only the following node on the classification path of the example using concept-distance as selection measure, while the control flow established by ID4R, ID5R and IDL expands all the sons of a node using the same selection measure. This means that ID4R, ID5R and IDL enforce the statistically best attribute at a higher number of nodes in the tree, and therefore produce more accurate decision trees than ID4 and ID5.