CRIN/CNRS
Université Henri Poincaré - Nancy 1
B.P 239 54506 Vandoeuvre-lès-nancy Cedex
FRANCE
Email : Gaele.Simon@loria.fr
Abstract
In this paper, we describe important steps of the knowledge capitalization process we are working on, in a metallurgical domain. From this particular and practical experience, our purpose is to focus on general characteristics which seem to be reusable for other knowledge capitalization systems. We would like, particularly, to put emphasize on specific constraints linked to the design of this kind of systems, in order to make general methods, techniques and tools emerge allowing to answer to these requirements.
The capitalization experience we are working on is part of a larger project of corporate memory (Macintosh, 1994) and knowledge capitalization in a firm producing steel. This firm wants to save and capitalize its knowledge and its know-how concerning the production descriptions of the produced steels and, also, the metallurgical defects encountered during these productions. Indeed, if they have a real corporate memory at their disposal, new experts will be able to better understand the choices which have been done by their predecessors.
Moreover, to maintain the global quality of the production, it seems interesting for this firm to be able to exploit past mistakes or successes in order to reduce, as much as possible, the risk of mistakes in the design of new steels.
In this paper, we mean by the expression corporate memory , " a structured set of knowledge related to the firm experience in a given domain " . We mean by the expression knowledge capitalization, " the process which allows to reuse, in a relevant way, the knowledge of a given domain previously stored and modeled, in order to perform new tasks ". The new task to perform corresponds to the purpose of the capitalization process. In the context of our project, the knowledge previously stored corresponds to the corporate memory. So, the problem we are interested in, is to propose an implementation for the corporate memory containing knowledge on steel productions and metallurgical defects, and to associate to this corporate memory a reasoning mechanism in order to facilitate its use.
Up to the beginning of the project, no real structured information existed concerning the steel production process descriptions or generated defects. The main reason of this lack comes from the fact that the firm is composed of several geographic sites which have their own know-how. These sites did not have really the opportunity to compare their knowledge that is why nobody can have a global view of the knowledge of the firm concerning steel productions and defects.
In order to answer to this lack, a first step of the project consisted of the creation of common synthesis documents for all the sites. The initial aim of these documents was to allow experts from the different sites to describe their knowledge in the same format in order to be able, afterwards, to compare them more easily. The format of these documents has been designed in order to ensure that it could allow to homogenize the knowledge of the different sites. Two kinds of documents were created : a first kind allows to describe steel production processes and the other kind allows to describe already known defects. The chosen format reflects, in fact, the firm point of view concerning the described concepts. The set of synthesis documents represents a first step of the corporate memory which must be implemented. It is important to notice that these documents have not been specifically designed for a future computer implementation of the knowledge they contain.
The second step of the project consists in exploiting and broadening the synthesis effort begun by the firm during the first step. This second step is the object of our work and our study (Simon and Grandbastien 1995). It consists, in one hand, in proposing models allowing to implement the corporate memory in a computer system, using the set of synthesis documents. In the other hand, our study must provide in the same system one or several capitalization processes allowing to use the implemented corporate memory. A first capitalization purpose has been chosen and defined : it is called the defects detection. It consists in determining whether a given steel production process description can generate defects already described in the corporate memory.
In this paper, we present for each important step of the design of the system, which general characteristics or constraints have been pointed out, which methods or tools we have used to answer to these constraints and which parts of these methods or tools seem to be reusable for other capitalization systems. As a consequence, first of all, we present how the existing documents can be exploited at the beginning of the system design. Then we focus on the architecture of the system and the different kinds of users which seem to be necessary in order to make theses systems run. In a third part, we introduce concepts of help and explanations in this kind of systems. We present which kind of help can be proposed and for which users. Finally we come back to the knowledge acquisition process and show that the method we have used can be generalized. We show that this knowledge acquisition method can be not only used for the main capitalization task but also for the modeling of the different help and explanations.
The aim of this section is to point out the general characteristics of existing documents as we have perceived them in the context of our project and which seem to be shared by most of computerized corporate memories building experiences. We present which knowledge acquisition process has been used to answer to these characteristics. We will see that this process is composed of three main steps. In the next sections, we show how these characteristics have also influenced the system design and the modeling of the necessary knowledge.
Knowledge typology
Several knowledge classes can be distinguished according to their role or their source. Concerning their role, one can distinguish capitalization task specific knowledge or, at the opposite, general knowledge which must be integrated in the corporate memory. For example, in our project, knowledge allowing to evaluate occurrence risks of defects can be distinguished from general knowledge describing those defects.
Knowledge classes can be also distinguished according to their source. A large part of them, useful, both for the corporate memory and the capitalization process can be found in the existing synthesis documents which are described later. But we show that, in spite of the synthesis effort of the experts, a set of knowledge stay in the experts' heads and must be pointed out by using interviews.
Finally, one must distinguish knowledge really useful for the corporate memory design or the capitalization process from others. Indeed, although a corporate memory is supposed to be very general, it concerns a precise domain of work in the firm and it is built in a particular intention. So a coherent set of interesting knowledge must be found. This knowledge must be liable to help the users of the corporate memory to better know the chosen domain and to allow to implement various capitalization tasks.
Why and how to exploit existing documents?
In the context of the building of a corporate memory, the acquisition process must begin by the exploitation of existing documents for three main reasons. First of all, even if these documents are not specifically designed for the purpose of the system to be built, it is impossible to ask experts to express again knowledge they have already described and, in part, modeled. Secondly, it is crucial that the way the knowledge of the corporate memory is implemented is not too far from the way it is expressed in the synthesis documents in order to avoid the experts to be bewildered. Last, but not least, these documents are a very good mean to facilitate the communication with experts; so they must be studied by the knowledge engineer very soon in the acquisition process.
Using documents as a modeling frame
The first use of the documents can consist in exploiting their structure. Indeed, the documents, produced by a firm in order to save its knowledge, are often more or less implicitly structured. If this structure is not so obvious, the first task of the knowledge engineer must be to make it emerge. It is important to take this structure into account because it often represents a first step of modeling of the concepts to be included in the corporate memory.
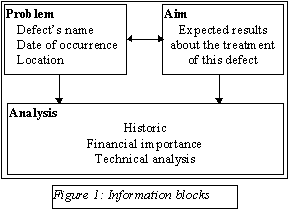
In the context of our project, the structure of the documents describing defects includes information blocks bound by semantic links, the type of which is often causal or temporal. Experts were in charge of filling up the different information blocks according to the steel production process or the defect to describe. Each information block is identified by a fixed title which is supposed to reflect the semantic of the block. Figure 1 shows a part of a document describing a defect containing some of the blocks.
The semantic of these blocks is the following :
¨ Problem : this block describes in a few words which kind of defect is treated in the document.
¨ Aim : this block describes what are the consequences of the defect and particularly the percentage of occurrences of defects of this kind which may be allowed.
¨ Analysis : this block is composed of three other blocks and describes the mechanisms of occurrence of the defect. The " historic " bloc contains a short history of the actions which have already been achieved in order to understand or correct this defect. The block called " financial importance " presents the financial consequences of the defect occurrence and profits which can be hoped if the defect can be eliminated.
Using documents as acquisition grids
In a second time, documents need to be exploited in more details in order to focus on their precise semantic. This new use of the documents shows generally that they contain a lot of implicits which must be clearly specified. That is why, after having used the documents' structure as a modeling frame, the knowledge engineer needs to base his work on a set of interviews with experts who have filled up the documents. During each interview, the synthesis document can be used as a sort of acquisition grid which would be already filled and from which the knowledge engineer can discuss with the expert.
The intensive use of the existing documents during the acquisition process has several advantages and disadvantages.
A first advantage is to allow to obtain rapidly a first model of the knowledge to represent in the system for the capitalization task. As a consequence, when interviews begin, the knowledge engineer has already a model to work with and to show to the experts.
A second advantage is that the documents can be used as a support during interviews. As a consequence experts know what to speak about with the knowledge engineer. So the communication is facilitated.
The intensive use of the documents implies some limitations too. First of all, they often contain a lot of implicits. Indeed, to summarize a part of knowledge in a document implies to make choices. Secondly, even if a common format is defined for all the documents, they are not homogeneous. Indeed, for example in our project, each expert has its own understanding of the semantic of the different information blocks of the format and, as a consequence, we don't always find the same kind of information in the same block.
The next part presents which kind of architecture can be used to represent knowledge capitalization systems and which kind of users are concerned by those systems.
In this part, we try to show that the kind of systems we describe in this paper implies an architecture identifying several kinds of specific users.
Figure 2 shows the general architecture we think to be suitable to many capitalization systems. First of all, this schema shows that, in this kind of systems, three general types of users can be distinguished. Each type of user is provided with a dedicated interface allowing him to manage different models of knowledge.
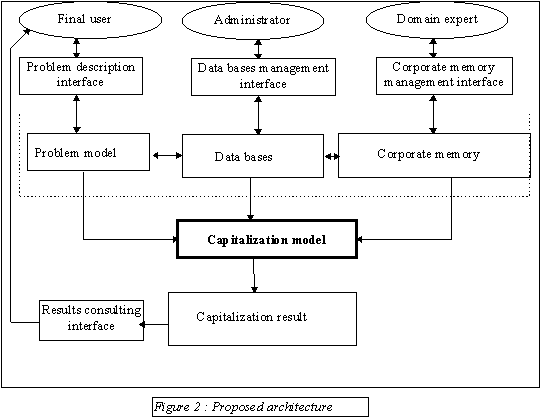
Different kinds of users
The first type of user is called the " final user ". This user is supposed to be interested in the capitalization side of the system. The main purpose of this user is to submit a new problem to the system which will be solved by a capitalization process. That is why two interfaces called " problem description interface " and " results consulting interface " are associated to this user.
The first one helps the user to describe the data of the problem he wants to be solved. This description is used by the system to build the " problem model ". The design of this interface depends on the capitalization aim of the system. In the context of our project, the aim of the capitalization is to detect defects from a steel production process description. So the associated interface allows the user to describe and to give values to the set of metallurgical parameters linked to the type of steel to be produced.
The second interface associated to this user allows him to see the results of the capitalization process used by the system in order to solve the problem. In the context of our project, the result is a list of defects coming from the corporate memory associated to a risk of occurrence. Using the proposed interface, the user can see, for each detected defect, the details of the evaluation of its risk of occurrence.
The second type of user is called the " administrator ". This user is in charge of the management of data bases used by the system to achieve the capitalization aim. These bases are supposed to contain basic knowledge of the capitalization and corporate memory domain. As for the first type of user, a specific interface is associated to this user, allowing him to consult and to modify the data bases. In the context of our project, those data bases contain, particularly, the description of all metallurgical parameters used by experts or engineers in their work.
The third type of user, called " domain expert " plays a major role in the system. Indeed, he has to enrich and maintain the " corporate memory " part of the system. The main aim of the acquisition step, described in the second part of this paper, was to find a model allowing to model this corporate memory. As a consequence, a fourth interface must be defined in the system, allowing the domain expert to manage the corporate memory using this model. In the context of our project, the corporate memory consists essentially of defect description using the defect model designed during the acquisition process. In that context, we do not have one domain expert but a set of experts who have filled up the synthesis documents describing metallurgical defects. The associated interface allows each expert to create or modify new or existing defects. To describe his defect, the expert uses a little modeling language based on the defect model showed later. He can also add comments to his defect description in order to explain his modeling choices.
The capitalization task
The model called " capitalization model " is the only one which is not accessible to users. This model contains knowledge and methods allowing to exploit the corporate memory, using data bases and the problem description, in order to generate results expected from the capitalization process. Each time the type of capitalization task changes, only this part of the system will have to be modified.
In the context of our project, the capitalization model uses case-based reasoning (Kolodner, 1992) (Aamodt and Plaza, 1994). Indeed, as it is presented in the next section, the corporate memory is represented by a case base, each case representing a defect of a synthesis document in terms of concepts of the defect model. Case-based reasoning is a particular kind of reasoning by analogy. It consists, in general, in solving a new problem by using cases already solved and collected together in a base. The first step consists of a selection of a subset of cases from the base which are judged to be relevant to the problem to solve. In a second step, each case of the subset is compared to the problem in order to calculate a similarity measure between them. Generally, a last step consists in adapting the solution of the case the most similar to the problem in order to obtain a solution for this problem. In the context of our project, only the two first steps are used. The defects are considered as " cases already solved " and the steel production process to analyze is considered as the problem to solve. As a consequence, in our system, the capitalization process consists in searching in the case base, the set of defects the most similar to the steel production process proposed by the final user (for further details, see (Simon, 1996)).
Why have we chosen this method for the capitalization process? The main reason is that, during the knowledge acquisition step, no general method concerning the detection know-how could be obtained or modeled. Indeed experts do not really perform this detection task when they design a new steel production process because it is too complex and too long. It is precisely because experts do not perform completely this task each time, that the system is useful. It is a way to extend experts' memories in order to reduce their mistakes. Case-based reasoning techniques are very well suited to situations where no other general method exists to perform a particular task and where a collection of cases already solved exists. That is why we have chosen to use it, considering a defect as a description of a bad steel production process in which only parameters involved in the defect occurrence are given.
Finally, the last module of the architecture called " capitalization result " contains a modeling of the results of the capitalization process. The aim of the interface called " results consulting interface " is to present this modeling in a suitable way to the final user. In the context of our project, this module provides the users with a list of the defects which are considered by the system as having a risk of occurrence if the proposed steel production process is really used. A quantitative value of this risk, calculated by the system, is associated to each detected defect.
In the next section, we show which consequences, in terms of modeling and knowledge representation, this kind of system and the associated architecture may imply.
In this section, we show which type of constraints must be taken into account when designing a knowledge capitalization system based on a corporate memory and which consequences these constraints imply for knowledge modeling. We show, too, how they have been taken into account in our specific context.
Architecture of the corporate memory : using cases
First of all, we would like to emphasize the choice which has been made concerning the corporate memory representation. This corporate memory, that is, as far as our project is concerned, the set of metallurgical defects, has been represented using a collection of cases. We think that this kind of representation for the corporate memory is general and can be reused for other knowledge capitalization systems because it answers to a set of general constraints induced by all capitalization systems (Caulier and Houriez, 1995).
First of all, a firm has very often as its disposal a collection of past experiences for which the solutions are known and which can be easily transformed into cases. Moreover, a corporate memory always evolve and can consequently never be built in one time. A representation in terms of cases allows an incremental design of the corporate memory by adding progressively new cases. Finally, a third characteristic of this kind of system is very often the scattering of the expertise necessary to the building of the corporate memory to be implemented. By that very fact, a corporate memory is the result of the global experience of the firm in its domain. And this experience is the result of the union of the knowledge of all the experts and engineers of the firm. A representation of the corporate memory using a collection of cases allows to answer to these characteristics because it ensures the locality of the modifications of this memory.
In the context of our project, the corporate memory is partly composed of defect descriptions. It is, consequently, represented by a collection of cases, each of them representing a defect. Figure 3 presents the case model allowing to represent a given defect. The case base can be used in different ways according to the purpose of the chosen capitalization task. As far as our project is concerned, the purpose of the capitalization is the defects detection and the chosen technique to achieve this task is the case-based reasoning. One could also imagine to use other reasoning techniques such as machine learning relying on neural networks for other kinds of capitalization tasks.
We have not evoked the problem of the organization of the case base. In our system, the case base is not yet organized, all cases are at the same level. In a general context, the choice of the case base organization, for example a hierarchical one, can be a way to model a part of the expertise.
Different levels of knowledge representation and modeling
The same knowledge environment is supposed to implement a corporate memory and propose capitalization mechanisms, this implies the need to model some concepts at different levels. In the context of our system, the defect concept is represented at three different levels. Within the case model, there exists two levels : the level called " general description " and the level called " causal description ". The first one describes the defect at a very general level with its name, the general conditions under which it has occurred, its physical appearance... This first level contains knowledge which can be termed as " surface knowledge ". Knowledge is often expressed as texts in this level.
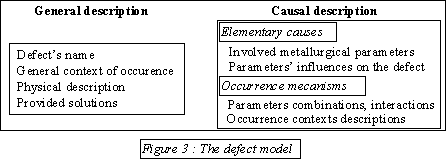
The second level presents the defects from the formation point of view and points out the different metallurgical involved parameters and their mutual interaction. This level contains more precise knowledge than the previous one. In this level, knowledge is structured into objects and modeled through a specific modeling language defined by the knowledge engineer. This language allows to formalize the knowledge. Finally, there exists a third level of representation of defects in the capitalization model. Indeed, as seen previously, the capitalization model uses the corporate memory and consequently its cases in order to generate expected results. So this model must contain further knowledge, concerning defect descriptions, allowing to make the descriptions contained in the cases more dynamic and operational. In the context of our project, the capitalization model contains, for example, a representation of the " parameters combinations " (figure 3) in terms of mathematical functions. For any kind of capitalization task, these different levels of knowledge representation can be found in most capitalization systems: a " surface " level, a more precise and generally causal level and a dynamic level bound to the kind of capitalization task.
Evolving knowledge
A major characteristic of the knowledge capitalization systems is the fact that the knowledge they contain is always evolving. The architecture and the knowledge representations must be chosen to allow this evolution. This implies that such a system must be the more generic as possible at every levels :
¨ The basic knowledge of the system : the basic knowledge of the system, in our project the metallurgical parameters, is knowledge used in the corporate memory description and in the problem description. We have shown that, in the proposed architecture, this knowledge is stored in separated data bases. This allows to obtain a first level of generality of the system. Indeed, the enrichment of these bases will immediately and, without any other modification, enlarge the system " know-how ". For example, in our system, the addition of new parameter descriptions in the bases implies that they are automatically put at the users' disposal in order to describe steel production processes or defects. Changing those bases could be a way to specialize the system for a particular geographic site or specific domain in the steel design.
¨ The capitalization model : Again, the capitalization model is a separate model in the general architecture and only uses the other one according to its own knowledge. One can hope, consequently, that when the kind of capitalization task will change, this model will be the only one to adapt. Everything else in the architecture is designed in order to remain the same from a capitalization task to an other.
¨ The corporate memory model : the corporate memory is implemented with a case base. This representation, as seen previously, answers, in part, to the problem of the evolution of knowledge. But it is not enough. The case model must also be as general as possible in order to be used as a corporate memory support and to allow different kinds of capitalization tasks. For that, it is crucial that the defect model must be declarative.
Finally we would like to point out the fact that the case-based reasoning technique specifically used, in our context, as the capitalization model answers very well to the problem of the knowledge evolution. Indeed, the defects base will always evolve and each case description will also evolve as their understanding by the experts will become better and better. As the detection task is based on the evaluation of a similarity measure between the analyzed steel production process and the defects, new defects will automatically be taken into account in the evaluation. So the detection mechanism will evolve itself.
Until now, we have only been interested in knowledge concerning the corporate memory or the capitalization task. In this section, we deal with knowledge necessary to allow to propose some help to the users of a capitalization system. Indeed, it has been shown that integrating explanation functions within a given system needs kinds of knowledge which are different from those necessary for the problem solving task (Clancey, 1983). Different kinds of help and explanations functions, which can be considered in a knowledge capitalization system, are presented. The last step of the first knowledge acquisition process for the main capitalization task, consisting of a sequence of tests with a prototype with an expert, allowed us to identify explanation and help needs at different levels. The needs are different according to the different kinds of users (see section 3) which are considered. More generally, we think that four kinds of help or explanations can be identified in such a system :
¨ to help the different users to use the software
¨ to help the final user to interpret the results produced by the system in terms of corresponding synthesis documents.
¨ to suggest to the final user some modifications of his proposed problem. In our context, it can consist in suggesting modifications in the proposed steel production process in order to eliminate or reduce the effect of the detected defects.
¨ to help the domain experts to use the case model in order to be able to enrich and maintain the corporate memory.
The first three kinds correspond to the traditional help and explanations which can be found in expert systems or CBILEs (Computer Based Interactive Learning Environments). The first type corresponds to the on-line help which can be found in every software. The second one corresponds to the help for a better understanding of the results produced by expert systems. The third onf help which can not be easily characterized in comparison with already known kinds of help. The main purpose of this help is to allow the domain expert, in our context the defect expert, to be as familiarized with the case model as possible in order to facilitate the modeling of his own cases. This kind of user is not supposed to use the system very often and, as a consequence, is not specially very informed about how the system runs. He is not the final user. This characteristic must be taken into account in the design of the help for this user. This help can be given in three ways :
¨ a synthetic presentation of the model produced by the user in order to make him understand what are the consequences of his choices.
¨ an explanation of the different components of the defect model and their role (relying on KADS models for example).
¨ a dynamic help to the modeling task of a new case of the corporate memory, in our context a defect.
In the following presentation, we are only interested in the explanations of the results produced by the system for the final user and in the dynamic help to model for domain experts. For each of them, we present their purpose, their content and the knowledge acquisition method which can be used in order to generate and propose those help and explanations.
Explaining the results of the capitalization process to the final user
The final user of a capitalization system is not an expert of the corporate memory domain but has a minimal set of knowledge. In our context, he can be a metallurgist engineer. As a consequence, the purpose is neither to explain the basic concepts of the domain nor to explain how the system has produced the results because those results contain the set of information allowing to understand the similarity measure calculus. But this user sees the corporate memory only through the cases' models produced by domain experts. He can not see choices on initial knowledge those experts had to do to achieve their models.
The idea of the proposed help is to allow the final user to interpret the results of the system. In fact, what we want to propose to the final user is a generation of explanations which could be given by a real domain expert seeing the problem of the final user. It can be considered as similar to the explanations generated by the system REX (Wick and Thompson, 1992). A way to do that is to automatically reproduce comments written by experts in their synthesis documents which, often, correspond to the type of explanation we are interested in. In the context of our project, these explanations should help the final user to interpret the risk of occurrence of a detected defect in terms of metallurgical, chemical or mechanical mechanisms coming from defect descriptions. This interpretation should help him to reconstruct the initial description of the defect before the domain expert modeling. The aim is somehow to propose to decompose the knowledge the domain expert has modeled.
Helping domain experts to use the case model in order to enrich the corporate memory
This kind of help is relatively new in comparison with the existing kinds of help because it is linked to the enrichment of the knowledge of the system. Indeed, the corporate memory will always evolve. As a consequence several persons, the domain experts, will have to maintain and modify this memory. Those users do not use the system in an intensive way. So they do not know completely how the system runs and which knowledge it uses. They only know a part of this knowledge : the cases they have to model. In the context of our project, more than ten domain experts will have to maintain the corporate memory. The role of this kind of user is crucial because the quality of their model have a direct influence on the quality of the results of the system. So, the main characteristics of this kind of user, to take into account for the generation of explanations, are the following :
¨ He is an occasional user.
¨ He does not use the system to solve any problem.
¨ He is a domain expert who is in charge to put a part of his knowledge at the system's disposal via the corporate memory.
¨ He does not know exactly how the system runs.
As the role of this user is so crucial, it seems important to help him to achieve his task of knowledge enrichment and modeling. This help can be achieved by dynamically guiding the expert during the use of the model according to his needs of modeling. The modeling task can be seen as specific problem solving activity. So this kind of help could seen as a more traditional help to problem solving. The specific difficulty here, is that the system does not know what the user wants to model. So the system must begin, when helping the expert, by identifying the type of difficulty encountered by the expert, for example by questions. In fact, the content of this kind of help can be seen, in part, as the set of questions asked to the experts during the acquisition process in order to design the model. The purpose of the help is to give a solution, using case model components, to the modeling problem expressed by the expert.
Integration of these helps and explanations in the capitalization system
Generation of kinds of help and explanations described previously will need to exploit the corporate memory again. The main difference between this exploitation and the one made for the detection task is that the generation of explanations needs also knowledge coming from the results produced by the detection task. So the generation of each kind of help or explanation will be implemented in new modules, data entry of which are in one hand knowledge coming from the corporate memory (as for the detection task) and in the other hand knowledge coming from the results produced by the detection task .
The knowledge acquisition step of a system design is no longer seen as a simple transfer of the expertise from experts to abstract structures. It is now seen as a real problem solving task the purpose of which is to design models reflecting the collected knowledge (Aussenac-Gilles, Krvine and Sallentin, 1992).
In this section, we present a general knowledge acquisition method adapted to the context of capitalization systems design within a firm. As in other known knowledge acquisition methods like KADS (Wielinga, Schreiber and Breuker, 1992; Schreiber, Wielinga and Breuker, 1993) or CERISE (Vicat, Busac and Ganascia, 1993), the acquisition process is perceived as a cyclic process of progressive knowledge elicitation and modeling. In the method we propose, this process is composed of three main steps, the last two ones being cyclic. What we call "acquisition step" is a part of the global acquisition process allowing to obtain an intermediate state of the knowledge model. This method must be used for each capitalization task to be included in the system and allows to obtain and model the knowledge needed for this task. What we propose is a general approach to drive the acquisition process for a capitalization system. But for each step of the method, we don't specify any modeling language. Existing ones, like the KADS expertise model, can be used.
Figure 4 presents a schema which summarizes the proposed method. In this schema, each step, symbolized by a circle, is associated to four others elements. First of all, each acquisition step has an input and an output which correspond to different states of the final models to be obtained. The input of the step i is the output of the step i-1.
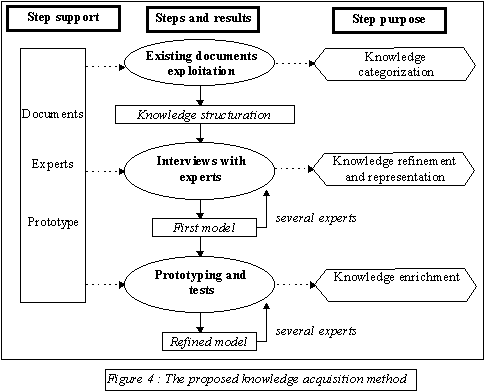
As a consequence this method proposes an incremental development of the models. Each step is also associated to one or several supports to be used during the step. It can be existing documents, a prototype or the experts. For some steps, as the first one, supports are fixed, for others they must be specified according to the capitalization task for which the method is used. Finally, each step is associated to a general purpose which can be stated precisely for a specific acquisition process.
The first step consists of the exploitation of the structure of the existing documents. We have already dealt with this exploitation in the second part of this paper. The aim of this first step is to categorize the knowledge that is to say which kinds of knowledge must be taken into account in the system. The support of this step is essentially the set of documents. This step produces a result called " knowledge structuration " that is to say a first organization of the knowledge but without any choice concerning the way they must be modeled.
The second step consists of interviews with domain experts. The general purpose of this step is to deepen the knowledge included in the "knowledge structuration" obtained in the first step in order to be able to model it precisely. This "knowledge structuration" is used as a modeling frame during this second acquisition step.
The support of this step is, at least, the set of experts concerned by the corporate memory domain. But other supports can also be used according to the purpose of the chosen capitalization task. The result produced by this step is a first model of the knowledge to be included in the corporate memory in order to achieve the capitalization task. This step consists of a sequence of several interviews, each of them producing a new state of the model taking into account the results of the discussion between the knowledge engineer and the last expert. This new state is used as the beginning point for the next interview of the sequence. It corresponds to the fact that, in the context of the design of a corporate memory, the knowledge is always disseminated among several experts. Each expert work on a different case (defect) which minimizes the possible contradictions between them. As a consequence, the method propose an incremental and progressive refinement of the model.
In the context of our project, we have chosen a set of five synthesis documents describing defects. These defects were judged by experts as being representative of the set of existing defects descriptions diversity. The purpose of each interview was to try to model each of these defects, taking into account the "knowledge structuration". As we have shown it in part two, synthesis documents were also used as support of this step.
The last step is called " prototyping and tests ". It consists in testing the model, obtained at the end of the previous step, with the help of a prototype implementing this model. The purpose of this step is to verify if the previous model is complete, that is to say allows to represent any element to be included in the corporate memory in order to perform the capitalization task. Indeed, at the end of the second step, a model is produced allowing to represent a subset of cases. The knowledge engineer has then to ensure that this model is general enough.
So this purpose can be called, as in the schema, " the knowledge enrichment ". To achieve this enrichment, the support of the step must be at least the prototype and the experts but additional supports can be used.
This last step consists of a sequence of trials with different experts, each trial enriching progressively the model. The final result of this step and of the acquisition process is a refined model. Between each test, the evolution of the model must be taken into account in the prototype in order to allow next experts to have a view of the work already done with the other ones. It is important that the experts working in the last step are not the same as those of the second step because the third acquisition step must give information not only about the generality of the model but also about its easiness of use. As a consequence, it is impossible to work with experts who were involved in the building of the model.
In the context of our project, the defect model has been implemented within a prototype which performs the chosen capitalization task, that is the defect detection, but only on a little number of defects. Each session was driven in the same manner : the aim was to use the prototype with the expert in order to represent a new defect in the model. Each time the work was based on the corresponding synthesis document. As a consequence, synthesis documents have been used as a further support of this acquisition step. Twenty sessions with thirteen different experts were organized. At the end of this third acquisition step, we have obtained a final model of the defect concept, available both for the corporate memory and for the capitalization task.
We think that this general method for knowledge acquisition can be reused for any capitalization task. Each time the supports and purposes of each step will have to be specified according to the type of the capitalization task.
A first advantage of this method comes from the fact that the interviews begin only in a second time. It helped us to center those interviews. Indeed, first of all, each interview was not centered on the general know-how of the expert but on a concrete case he had already described in a document. So the set of knowledge to be covered during the session was small.
Finally, the aim of each session was precisely defined : to be able to use the model in order to represent a given defect. It helped to be always centered on the set of knowledge we were interested in.
As a second main advantage of our method, we would like to underline the major role played by the prototype during the third acquisition step. Indeed, this experience shows that it is only when the future users of a system see this system running that they really describe what they expect from the system, give advice and have a precise idea of what kind of knowledge we want them to transmit. During the last step of the acquisition process, we have collected new information, particularly about defects, which could not be obtained during the second one. It can be explained by the fact that, in the second step, they were guided by our questions during the interview. In the last step, the task to be achieved during the interviews was the same: to model a given defect. But this time, the experts did not have to answer to our questions but to use the prototype. The prototype allowed them to understand really how the model is used by the system to achieve the capitalization task. As a consequence, they understood that there was a need to add new kind of knowledge in the model in order to improve the system's results.
Moreover, we would like to underline an other difficulty of the acquisition process in the general context of capitalization systems. In this kind of systems, knowledge to be modeled and capitalized is often evolving. As far as knowledge acquisition step is concerned, it implies several back-track during the process. In the context of our project, a defect description is always evolving. Each time a new defect is discovered, the notion of defect may have been modified. As a consequence, it was very important to choose a " good " first set of defects for the model design in order to minimize the number of back-tracks.
In a capitalization system, different kinds of knowledge must be represented : for the corporate memory, capitalization tasks, explanations... So several knowledge acquisition processes must be performed. As a consequence, it is important to try to unify these acquisition processes as much as possible by using a common approach. The method we have presented tries to answer to these requirements. In the context of our project, it has been used twice. It was used a first time for the acquisition of knowledge concerning the detection task. And it is now used a second time for the acquisition of knowledge concerning the explanations generation. Each acquisition process corresponds to the process described by the method, and is consequently composed of three main steps. We now show how the method has been used for the explanation part.
Knowledge acquisition processes for help and explanations
The first step of the method allows to obtain the kinds of knowledge necessary to generate those explanations. The support is the set of synthesis documents and particularly the comments written by the experts in those documents (see before).
The second step corresponds, in fact, to the third step of the acquisition process for the main capitalization task, in our context the defect detection. As a consequence, the support is a prototype without any explanation function and the experts. This step allows to specify precisely the need of experts for explanations. By observing them using the prototype, one can collect information on their difficulties in order to model them. So this step allows to produce a first model of these difficulties.
The third step, as for the main capitalization task, allows to enrich the previous models in order to obtain complete models. Here, the support is again a prototype but, this time, with explanation functions corresponding to the models obtained at the end of the second step. This time the tests with the prototype must be specifically dedicated to the problem of explanations which was not the case with the previous tests of the previous step. Indeed, an expert can not express his needs of explanation in general. So, it is necessary to begin by observing him using a prototype and then, only a in second time, to propose explanation functions and to ask him to react in specific sessions.
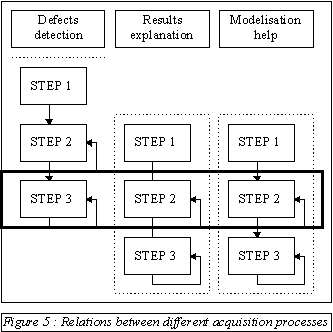
The schema of figure 5 summarizes the existing relation between the three acquisition processes. It shows they are not performed at the same time but they are not independent. The two knowledge acquisition processes for help and explanations are performed in the same time but, one step later than the acquisition process for the main capitalization task. This schema points out the fact that the second step of the acquisition processes for help and explanations is exactly the same as the third one for the first acquisition process concerning defects detection, which is the main capitalization task. We think, indeed, that knowledge acquisition processes concerning explanations can not be managed in the same time with the main acquisition process (Delozanne and Carrière, 1992) because it is only when the experts use a prototype that then can express their difficulties and, as a consequence, their needs for help and for explanations. So, although actual researches try to design expert systems which have explanation functions from the beginning (Bouri, Dieng, Kassel and Safar, 1990), we think that it is very difficult to specify them at the beginning of the design.
In this paper, we have shown that knowledge capitalization systems design imply a set of specific constraints, which are not found in all traditional expert systems, and which influence the knowledge modeling. Such characteristics include at least an extensive use of existing documents, a continuously evolving knowledge base, a disseminated expertise and many expertise providers, different kinds of users.
Our conclusion is that a corporate memory is altogether less and more than a traditional knowledge based system (KBS). It is less than a KBS because it is not dedicated to a specific task and consequently it does not include know-how related to such a task. It is more than a KBS because it should be used for several capitalization tasks and by several kinds of users.
We have adapted some general methods, techniques and tools in order to take these constraints into account. A knowledge acquisition method provided for a given capitalization task has been defined. A general architecture, with different kinds of users has been also defined. Finally we have dealt with the question of help and explanations which can be integrated in such a system. Different kinds of help have been defined and we have shown that for two of them, the knowledge acquisition method can be reused in order to obtain the new set of knowledge necessary to generate them.
Present and future work
Our prototype is written in C++ and Prolog and is running on PC's. It is currently experimented for the last refinement cycles in explanation knowledge acquisition. As far as corporate memory is concerned, it remains to observe how the case base is correctly updated and enriched by the different experts when they are in charge of this task.
The next step will consist in trying to integrate this system in a larger information system in the firm. Such an integration needs to define a methodology describing how to use the system. More precisely, protocols have to be specified in order to define how the corporate memory must be enriched, who must be in charge to enrich it and when to enrich it.
Aamodt, A. and Plaza, E. (1994). Case-Based Reasoning : Foundational Issues, Methodological Variations, and System Approaches, in AI Communications, Vol. 7, No. 1, p. 39-56.
Aussenac-Gilles, N. and Krivine, J.-P. and Sallentin, J. (1992). Editorial : L'acquisition de connaissances pour les systèmes à base de connaissances, Revue de l'Intelligence Artificielle, Vol 6, No. 1-2, p. 7-18.
Bouri, M. and Dieng, R. and Kassel, G. and Safar, B. (1990). Vers des systèmes experts plus explicatifs, in Bernadette Bouchon-Meunier (Eds.), Troisièmes jounées nationales du PRC-GDR Intelligence artificielle, Centre National de la Recherche Scientifique, HERMES publishing, p. 340-355.
Caulier, P. and Houriez, B. (1995). Apports de la modélisation des connaissances et du raisonnement à partir de cas à la capitalisation et la réutilisation de connaissances, in Actes des Journées Acquisition Validation Apprentissage, Grenoble (France), p. 331-345.
Clancey, W.J. (1983). The epistemology of a rule-based expert system : a framework for explanation, in Artificial Intelligence, Vol. 20, No. 3, p. 215-251.
Delozanne, E. and Carrière, E.. (1992). Définir un processus explicatif, une étude de cas : la conception d'ELISE, in proceedings of Deuxièmes journées Explication du PRC-GDR-IA, Centre National de la Recherche Scientifique, Sophia-Antipolis (France): INRIA publishing, p. 195-208.
Kolodner, J.L. (1992). An introduction to case-based reasoning , in Artificial Intelligence, Vol. 6, p. 3-34.
Macintosh, A. (1994). Corporate knowledge management - state-of-the-art review, in proceedings of ISMICK International Symposium on Management of Industrial and Corporate Knowledge, Compiègne (France), p. 131-145.
Schreiber, G. and Wielinga, B. and Breuker, J. (1993). KADS : a principled approach to knowledge-based system development, in Knowledge-based systems, Vol. 11, Academic Press.
Simon, G. and Grandbastien, M. (1995). Corporate knowledge : a case study in the detection of metallurgical flaws, in proceedings of ISMICK International Symposium on Management of Industrial and Corporate Knowledge, Compiègne (France), p. 42-51.
Simon, G. and Grandbastien, M. (1996). Case-based reasoning for knowledge capitalisation, to be published in proceedings of Expert Systems'96, Cambridge (UK).
Vicat, C. and Busac, A. and Ganascia, J.-G. (1993). CERISE : A cyclic approach for knowledge acquisition, in Lecture Notes in Artificial Intelligence (Eds), Toulouse and Caylus (France), Proc. of the 7th European Knowledge Acquisition Workshop, Springer-Verlag, p. 237-255.
Wick, M.R. and Thompson, W.B. (1992). Reconstructive Expert System, in Artificial Intelligence, Vol. 54, No. 1-2, p. 33-70.
Wielinga, B. and Schreiber, G. and Breuker, J. (1992). KADS : a modeling approach to knowledge engineering , in Knowledge Acquisition, Vol. 4, p. 5-53.