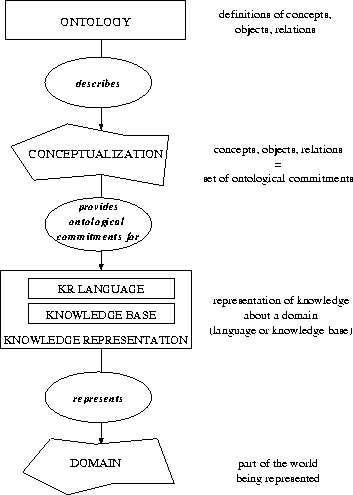
Figure 1: The relation between conceptualizations, ontologies, knowledge representations and domains.
Andre Valente
University of Southern California
Information Sciences Institute
4676 Admiralty Way, Marina del Rey, CA 90292
USA
e-mail: valente@isi.edu
Joost Breuker
University of Amsterdam
Department of Computer Science and Law
Kloveniersburgwal 72, 1012 CZ Amsterdam
The Netherlands
e-mail: breuker@lri.jur.uva.nl
An important issue in the newborn discipline of ontological engineering is the construction of libraries of ontologies which are designed for maximum reusability. Van Heijst et. al. suggested that a central part of ontology libraries is the definition of what they called a core ontology, containing elements that are as generic and method-independent as possible. However, their specification of how these core ontologies should be constructed is highly pragmatical, and leaves many problems unresolved. In this article we propose and discuss a number of specific principles for the construction of core ontologies. We demonstrate the advantages of these principles using as an example a core ontology we have built for the domain of law. Several conclusions about the construction of ontology libraries based on core ontologies are drawn.
An important issue in the newborn discipline of ontological engineering is the construction of libraries of ontologies which are designed for maximum reusability [van Heijst et al., 1996, Gruber, 1994]. A major challenge in building these libraries is to define how the ontologies are to be constructed, and what the relations should be among them. Several groups have proposed solutions to this problem. Most of these proposals have primarily addressed the organization, or indexing problem. That is, they specify how the ontologies should be organized in the library in such a way that they can be meaningfully and efficiently retrieved for reuse. For example, [van Heijst et al., 1996] propose an organization based on the definition of a ``core library''. This core library is in fact a very general ontology of a certain application domain, e.g., medicine. However, besides some practical guidelines dependent on the consensus in a domain, they do not make it clear how such a pivotal ontology is to be conceived.
In our view, core ontologies should consist of a clear, theoretical framework for the selection of elements of the domain and principles for their definition. In this paper we propose that these principled core ontologies be constructed using four main principles. First, they should be parsimonious, i.e., they should contain enough concepts, but only those concepts which are strictly necessary. Second, they should have a clear theoretical basis. A core ontology should not be a simple hierarchy of terms, but a theoretical framework that describes what the domain is about. A core ontology is not simply the top part of abstraction hierarchies. Third, and related to the previous point, core ontologies should not aim at the specification of the most common terms, but of basic categories of domain knowledge. Fourth, these basic categories should be coherent. By coherent we mean more than that the basic categories should be consistent and complete, but also that the frameworks (relations) in which these categories are stored must make sense. This sense is the sense of the domain: e.g., in medicine the diagnosis and treatment of diseases.
In the body of this paper, we will define and discuss these principles in detail. In order to show the advantages of principled core ontologies, we will present in some detail one such ontology we have devised for the domain of law, called the functional ontology of law [Valente, 1995]. This article is structured as follows. In Section 2 we clarify our view on ontologies and ontology libraries, and discuss the idea of principled core ontologies. In Section 3 we describe briefly the functional ontology of law. In Section 4 we discuss and illustrate or ideas about core ontologies based on the functional ontology of law. In Section 6 we present our conclusions.
There is an ongoing debate about the definition and role of ontologies in AI in general, and in knowledge engineering in particular. While we do not wish to contribute to the discussion in this paper, the large variety of views on ontologies requires that we at least clarify the meaning and role of ontologies used here.
It is impossible to represent the world in its full richness of detail. In order to represent a certain phenomenon or a part of the world (which is called a domain), it is necessary to restrict the attention to a small number of concepts which are meaningful and sufficient to interpret the world and provide a representation adequate to a certain task or goal at hand. As a consequence, a central part of knowledge representation consists of elaborating a conceptualization: a set of abstract objects, concepts, and other entities which are assumed to exist in a certain domain, as well as the relations that may hold between them [Genesereth & Nilsson, 1987]. The commitments which are implied by the choice of one set of concepts instead of another to describe a certain phenomenon are called ontological commitments. A conceptualization thus also carries a set of ontological commitments.
Elaborating conceptualizations (and thus selecting ontological commitments) is an essential component of the task of representing knowledge, because conceptualizations select which things are relevant to be represented and which are not [Davis et al., 1993]. Representing knowledge involves both the design of a knowledge representation language and the formulation of a specific set of sentences in this language which describe certain things in the world -- such a set of sentences is usually called a knowledge base. Ontological commitments precede the elaboration of both the knowledge representation language and the knowledge base.
A conceptualization is an abstract entity which is merely implied in a knowledge representation. An ontology is a specification of a conceptualization [Gruber, 1994]. An ontology comprises a description (e.g., through definitions) of the concepts, objects, relations, and so forth which make up a conceptualization. One of the basic roles of an ontology is to enable the study of conceptualizations and ontological commitments dissociated from the knowledge representations they may yield. Another important role is to support knowledge sharing and reusability [Neches et al., 1991, Patil et al., 1992, Gruber, 1994]. Particularly relevant are domain ontologies, i.e., ontologies which describe a part of the world or a human activity such as medicine, law, or engineering.
Fig. 1 shows the elements discussed above and their interrelations. Conceptualizations and domains are abstract things (represented by irregular polygons) while knowledge representations and ontologies are concrete things (represented by rectangles), for example, sentences in some symbolic language. Their interrelations are represented as ovals, and the direction of reading is indicated by the direction of the arrows. These interrelations are as follows: (i) an ontology describes a conceptualization using definitions of the elements of the conceptualization (objects, concepts, relations); (ii) a conceptualization provides ontological commitments which are used in elaborating knowledge representations, and these commitments are embedded either in the knowledge representation language, or in the knowledge base, or both; (iii) a knowledge representation represents a domain (a part of the world).
Figure 1: The relation between conceptualizations,
ontologies, knowledge representations and domains.
As stated in the introduction, a major problem challenge in the construction of libraries of ontologies is the issue of ontology construction and the relations between ontologies. Thus far the focus has been on the indexing (organization) problem.
One strategy to cope with the indexing problem is to use the ontology terms (names) themselves as indexes. This was roughly the solution adopted by the ARPA Knowledge Sharing Initiative [Neches et al., 1991, Patil et al., 1992] and implemented in the Ontolingua Repository [Gruber, 1994]. The problem, of course, is that there is no guarantee that the same term is being used with the same meaning in different ontologies. Most of the work in searching through the library is left to the user, and this strategy assumes that the user's understanding of the terms is similar to the one employed in the ontologies. In fact, the ontologies are not really organized as a library, but only ``stored'' in the repository. A second approach tries to correct this problem by defining a single meaning to each term, and again using the terms (and thus meanings) as the index. This is done by transforming the library into a single, large ontology, integrated by a very general, top-level ontology that is supposed to be coherent and complete (that is, to cover more or less all knowledge relevant in the given context). The basis proposed for building such generic ontology varies. One group of researchers proposes that it should be based on natural language -- that is, the top level terms should be natural language categories or roles of terms [Knight & Luk, 1994]. A second group, of which the CYC builders are and example, prefers to see the whole enterprise as an encyclopedia, and suggests the careful construction of what amounts to an ontology of commonsense knowledge [Lenat & Guha, 1990]. While these two groups share the same basic indexing strategy, their results are quite different. CYC-like ontologies are microtheories, which can be used for reasoning purposes by logical inferencing engines. In contrast, the concepts in natural language ontologies are usually almost empty, and most of the meaning is given by their place in the subsumption hierarchies in which they are stored.
A main difficulty in the above approaches is that they want to be both general and independent of possible applications. [van Heijst et al., 1996] tried to give a different focus by restricting their attention to the use of ontologies in constructing knowledge-based systems. Thus far, their proposal for organizing libraries of ontologies is the most specific and explicit one. Their proposed library has multiple indexing and organization characteristics. First, ontologies are indexed by their level of abstraction and by how their terms were used in in some application. We will not discuss here the problems involved in the latter way of indexing: it does not affect the overall organization of the library. With regard to the levels of abstraction, the highest level of abstraction contains concepts like subsumption, inclusion, cause, etc. that seem more likely to be candidates for representational services than for terms in a knowledge base. In fact they may be presupposed rather than being made part of the library. Therefore, in practice the highest organizing level of the library is the ``core ontology'' (theory): a very general ontology of a certain application domain, e.g., medicine. This core ontology should contain a number of generic concepts and method-independent definitions, characteristics that would give high reusability to the elements of this library.
While we agree that such core ontologies are extremely useful for reuse purposes, there are several problems in the criteria developed by van Heijst et al. for defining which elements it should contain. First, they propose that these core ontologies should have a very pragmatic, engineering-like character. For instance, they propose that the core ontology should minimize the number of inclusions -- which is just another way to define the engineering principle of modularity in this specific context. Further, the only clue they provide as to how to recognize the elements to be put in the core library is that they should be centered around ``natural categories''. By natural they mean that the categories should reflect a ``social consensus that exists in the [application domain] community'', and thus should allow communication between members of that community [van Heijst et al., 1996, pg.15,]. The flaw in this argument is that the fact that a term is used widely across a certain community does not mean that it is used with the same meaning. For instance, despite what one would expect, the meanings of terms like ``law'' and ``right'' are highly debated and disputed in the legal domain. Indeed, these terms are used in many different and sometimes contradictory meanings, to such extent that this fact is acknowledged by most legal theorists as unavoidable. Finally, [van Heijst et al., 1996] take `theories' as the principle for modularization of the library. Theories are viewed as parts with a high internal cohesion and a relatively low level of coupling with other parts of a library of ontologies.
Aside from the debate of what is and should be in an ontology, and what kinds of ontologies can be distinguished, there is the question of the roles an ontology can or should play in knowledge engineering. While these roles may all be subsumed under the term `knowledge sharing' [Gruber, 1994], different purposes of (re)use of ontologies also put different requirements on the ontologies.
It is interesting to notice that the need for careful and valid analysis -- and in particular for a formal base -- increases with the order presented above.
The discussion in this paper refers to ontologies that perform the fourth role, more specifically, with the reuse of a library of ontologies can provide.
Good engineering practice and pragmatism are of course important for building ontologies, but core ontologies require more than that. They should be based on a clear theoretical view of the elements of the domain, that can provide principles for their definition. In this paper we propose that these principled core ontologies are characterized by the following:
 However, as in cars, this ``thinness'' is the
consequence of good engineering. Being parsimonious with the
material has the advantage of easy processing and total economy.
However, when it comes to modifications (maintenance), this
parsimony may have been shortsighted, because new structures may be
added or made that cannot be supported by the existing architecture.
Therefore, an architecture in which the knowledge is somewhat
thicker (deeper) than strictly required for the application may last
longer through modifications.
However, as in cars, this ``thinness'' is the
consequence of good engineering. Being parsimonious with the
material has the advantage of easy processing and total economy.
However, when it comes to modifications (maintenance), this
parsimony may have been shortsighted, because new structures may be
added or made that cannot be supported by the existing architecture.
Therefore, an architecture in which the knowledge is somewhat
thicker (deeper) than strictly required for the application may last
longer through modifications.
When it comes to reuse of the knowledge, thickness becomes even more critical. Again the car metaphor can clarify the problem. Even if we can remove the body of a Renault, we cannot make it fit onto the chassis of a Volvo without modifying it and weakening its strength. The only way we can reuse a Renault for a Volvo is to go back to its essence: the material must be reprocessed, even melted. Ontologies for knowledge systems can be viewed as descriptions of properties of this material. The recipe for bringing back terms to their meaning (material) is understanding. The ontology can thus be used as a guidance in knowledge acquisition. By reading an ontology, a knowledge engineer or knowledge acquisition system can properly use the (terminological) knowledge when constructing a knowledge base.
Categories are not
top level terms in an abstraction hierarchy, but rather knowledge
types. For instance, the category ``disease'' refers to
knowledge about diseases, which may include a taxonomy of
``diseases'' (where disease is now used as a term). Categories have
a meta-term flavor.
There are several advantages to using principled core ontologies. First, they provide a common basis for comparison and translation. There is no such thing as the ``right'' or ``best'' ontology in general. The quality of an ontology is usually measured by its usefulness, or its reusability. However, since there is no way to define the best ontology, it is essential that we be able to compare them and translate ideas formulated in one ontology to another. We will show that principled core ontologies improve the chances of being able to compare and translate (core) ontologies. Second, a principled core ontology divides the domain into highly modular parts, greatly simplifying the problems of analyzing the specific reasoning mechanisms used in the domain and thus helping to design or classify problem-solving methods which can be used for that domain.
The functional ontology of law, as the name indicates, adopts a functional perspective. This perspective can be summarized as follows:
It is
important to note, however, that this `device-like' view does not
imply that the ontology is based on a simulation of the actual
behavior of the legal system.
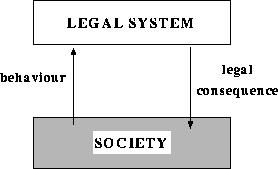
Figure 2: Main function of the legal system.
Given the view described above, an ontology of law can be built by identifying these functions and using them to distinguish categories of legal knowledge. In the following sections, a number of primitive functions of legal sources and corresponding categories are proposed and described. Some of these categories are primitive, while others are defined using the primitive categories. The primitive categories are: normative knowledge, world knowledge, responsibility knowledge, reactive knowledge, creative knowledge, and meta-legal knowledge. It was shown in [Valente, 1995] that most of the important non-primitive categories, such as rights, can be defined based on the primitive ones. This issue, however, is outside the scope of this paper.
Normative knowledge is the most characteristic category of legal knowledge, to such an extent that to many authors `normative' and `legal' are practically the same thing. From an ontological perspective, however, it may be interesting to differentiate more types of legal knowledge and thus give to normative knowledge a more specific structure, content and role.
Normative knowledge is seen in the legal theory literature as having two functions: prescribing behavior and defining a standard of comparison for the social reality. These functions are clearly related. One can think that norms prescribe behavior by defining a standard or, the other way around, set up a standard by prescribing behavior. Which side is the central one is an issue subject to debate in legal theory. In this ontology, we adopt the conceptualization that the definition of a standard is the central characteristic of normative knowledge, and the prescription of behavior is one of its effects.
The basic conception of norm used in the ontology is largely derived from [Kelsen, 1991]. A norm expresses an idealization: what ought to be the case (or to happen), according to the will of the agent that created the norm. This idealization is expressed by reference to a description of the reality (the world) in which some configurations of facts and behavior are `cut out' to make it an ideal world. Since they express an ideal world, norms can be either observed or violated. A norm is observed when the behavior in the real world does not conflict with its specification in the ideal world, and violated otherwise. To apply a norm means to verify or compare the reality with the ideal world defined in the norm, classifying the reality as either compliant or non-compliant with the norm. This classification is the normative status of the behavior with respect to the norm.
Normative systems are defined on the basis of individual norms in the sense that the standard defined by the normative system is defined in terms of the standards defined by the individual norms. The difference between the standard defined by the normative system on the one hand and the standards defined by the norms on the other hand is fundamental to understanding the role of normative knowledge in law, and it is accounted for by knowledge about individual norms. This distinction is captured by defining the categories of primary norms and meta-legal knowledge. Primary norms are entities that refer to human behavior, and give it a normative status. This normative status is, in principle, either allowed (legal, desirable, permitted) or disallowed (illegal, undesirable, prohibited). However, each norm refers only to a few types of behavior, in the sense that it can provide a status only when it is applied to certain types of cases. For the remaining types of cases, the norm is said to be silent.
There may be a difference between the normative status given by a single norm and the status given by the normative system. The normative status with respect to the normative system is based on the normative status with respect to the primary norms. One of the functions of meta-legal knowledge is to specify how this process occurs, i.e., how the normative status with respect to the normative system is built from the normative status with respect to the primary norms. The basic mechanism involved is the solution of conflicts between primary norms. Another function of meta-legal knowledge is to specify which legal knowledge is valid. Validity is a concept which can be used for specifying both the dynamics of the legal system and its limits. A valid norm is the one which belongs to the legal system, and vice versa.
By its very nature, law deals with behavior in the world. Therefore, it must contain some description of this behavior. For instance, in order to describe how the world should (ought to) be, primary norms must describe how things are or can be. This description is not directly available from the legislation, but is usually implicit. However, this type of knowledge is distinct from (albeit connected to) normative knowledge -- that is, primary norms describe an ideal world based on the description of reality. This separation between the knowledge used to describe the world and the normative knowledge was first explicitly proposed by Breuker [Breuker, 1990], who called this category world knowledge.
In addition to adopt the distinction of a category of legal knowledge which describes the world, we propose that this knowledge constitutes a structured model. Thus, the term legal abstract model or LAM is used as a synonym for world knowledge when its model character is to be stressed. Also, this term stresses that this model is a `double abstraction': as discussed below, the LAM gives a more restricted meaning to commonsense concepts which are already abstract.
The legal abstract model is an interface between the real world and the legal world. Its role is to define a model of the real world which is used as a basis to express normative and other categories of legal knowledge. The bulk of the LAM consists of definitions of concepts that represent entities and relations in the world. These concepts are usually organized in subsumption hierarchies. In defining concepts and relations based on other concepts and relations, it occurs naturally that some concepts are taken as primitive, i.e., are not completely defined based on others. These concepts are supposed to be interpreted by people. Indeed, since the law is supposed to be comprehensible to the people who are addressed by it, every concept used in legislation is supposed to be comprehensible to any person. That means these concepts are supposed to be part of this `consensus reality' mentioned by [Lenat & Guha, 1990] -- that is, these terms are in fact supposed to be interpreted using commonsense knowledge. This means that the legal abstract model is not complete or self-contained: the LAM is in fact a layer of definitions of concepts and relations built on top of a large layer of commonsense knowledge. The primitive (non-defined) concepts and relations in the LAM are the interface between the world knowledge and the commonsense knowledge. For instance, it is possible to define in detail the characteristics of an intellectual work to be used in a copyright law. It is also possible to define it referring to other concepts, such as books, sculpture, etc. However, if the concept book is left undefined (primitive) the only way to interpret it is to rely on commonsense knowledge. Therefore, a concept within the LAM is defined in two steps: first defining it in terms of other concepts in the LAM until the level of primitive concepts is reached, and second the commonsense `definition' of the primitive concepts. When one retraces the way back -- verifying whether or not a certain legal concept (a concept in the LAM) applies to a certain entity in the world -- there are again two interpretive steps. First there is the interpretation of the reality in the primitive terms of the legal abstract model, e.g., asserting that a specific thing in the world is a book. Second, there is the interpretation of the primitive terms with respect to the defined ones, e.g., asserting that a book is a type of intellectual-work. The first process involves purely commonsense knowledge, while the second is supported by world knowledge. The process from an entity in the world to primitive concepts or vice-versa is called commonsense interpretation. The process from a primitive (or defined) concept to a defined concept within the LAM or vice-versa is called legal interpretation. The view just described is shown in Fig. 3.
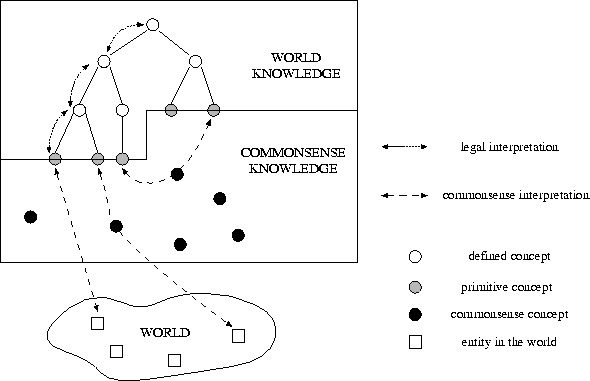
Figure 3: The role of the legal abstract model.
The legal abstract model is not only a static description of salient features of society, but a model of social behavior. For instance, legislation is passed as a form of social control, under the supposition that it will affect social behavior in a certain way, and this supposition is to some extent embedded in the legal abstract model. Therefore, a LAM should ideally allow predictions about behavior in the world. Nevertheless, this requires more than definitions, because these are purely static. The definitions alone are a domain ontology which falls short of a model, because it does not enable such predictions. The view imposed in the law about behavior is thus largely a static description of possible or relevant behaviors, but the full reasoning about them is left to commonsense.
Apart from describing the world, what is behavioral reasoning used for
in law? We propose that this description of possible and relevant
behaviors is built around the concept of cause, in order to
allow the assignment of responsibility of an agent for a certain case.
Causal knowledge, however, refers or
uses a static description of the world (e.g., to model world states).
Accordingly, we propose that the world model is actually composed of
two related types of knowledge: definitional knowledge and
causal knowledge. The definitional knowledge is used by the
normative knowledge to describe the ideal world they define. The
causal knowledge is used by the responsibility knowledge to describe
who or what have caused a given state of affairs, and can thus be
considered responsible for it.
It is commonplace to affirm that cause and responsibility are important concepts in law, but it is not equally simple to provide a more concrete account of how these concepts enter the realm of law. We see responsibility knowledge as a category of legal knowledge that has as a function to assign or limit the responsibility of an agent over a given (disallowed) state of affairs -- i.e., to (dis)establish a link between the violation of a norm and an agent which is to be considered responsible (accountable, guilty, liable) for this violation. This responsibility link may be established by a causal connection between the agent and the disallowed behavior, but this is not the only way to establish responsibility.
Responsibility is the intermediary concept between normative and reactive knowledge, since a reaction can only occur if the agent is is held responsible for a certain norm violation. Responsibility knowledge plays the role of linking causal connections with a responsibility connection -- i.e., that connection which makes an agent accountable for a norm violation and possibly subject to legal reactions (see also Section 3.2.5). As [Hart & Honore, 1985] point out, however, responsibility does not have ``any implication as to the type of factual connection between the person held responsible and the harm'' -- that is, causal connections are only a ``non-tautologous ground or reason for saying that [an agent] is responsible'' [Hart & Honore, 1985, pag. 66,].
In principle, commonsense says that one is only responsible for what one causes. Naturally, there is an a priori link between these two relations: in principle, all agents are legally responsible (and only responsible) for that which they cause. But this causal connection is not always necessary or always sufficient for establishing responsibility in a legal context. The role of responsibility knowledge is exactly to `interfere' with this prima facie connection between causing and being responsible. This interference is made so that legal systems ``extend responsibility [or] cut it off in ways which diverge from the simpler principles of moral blame'' [Hart & Honore, 1985, pag. 67,]. This mechanism has rather practical motives. Given the innumerable problems in establishing, proving and reasoning with causal connections, the assignment of legal responsibilities which bypass these connections to some extent is used to give more precision in situations where the use of the commonsense or moral concept of responsibility by the law can lead to inconsistencies or undesired results, or when there is a practical interest (based on an implicit of explicit policy) that a frontier should be drawn so that it becomes easier to define what are the limits of responsibility under certain circumstances.
There are two basic mechanisms which are used in responsibility knowledge. First, the law may establish a responsibility connection independent of a causal connection -- i.e., a responsibility assignment. This can be seen in a rule used in e.g., French, German or Brazilian law, by which parents are held responsible for the the damage done by their children even if there is no specific causal link between their attitudes or actions and the damage. That is, the parents are held responsible even though they have not necessarily caused the damage. Second, the law may limit the responsibility of an agent under certain circumstances, disregarding some possible causal connections -- i.e., a responsibility restriction. For instance, in England a man is not guilty of murder if the victim dies more than one year after the attack, even if the death was a consequence of this attack. Other well-known factors that may influence the establishment of responsibility connections in law are knowledge and intention.
To reach the conclusion that a certain situation is illegal (based on normative knowledge), and that there is some agent to blame for it (responsibility knowledge) would be probably useless if the legal system could not react towards this agent. That knowledge that specifies which reaction should be taken and how is what we call reactive knowledge. Usually this reaction is a sanction, but in some situations it may be a reward. The penal codes, which are usually a fundamental part of legal systems of the Romano-Germanic tradition, contain basically responsibility and reactive knowledge only.
A legislator may indirectly create some entity that did not exist before in the world, using what we call creative knowledge. It is usually stated in imperative terms, designating an agency that previously did not exist as part (or not) of the reality from a certain point of the time on. The creative function has a somewhat exceptional (or even abnormal) status if compared to the other ones. In this case, the law not only wants to classify or to react over certain agents that already exist in the real world, but attempts to create a new agent. A simple example is the creation of a department within the government or a company. Note that the department created is itself an abstract entity which will later be `filled' with workers, facilities, etc. to become a concrete (physical) entity. Creative knowledge is not necessarily restricted to the State: the creation of organizations by contracts and agreements can also be considered creative knowledge. This type of knowledge appears at a first glance to be almost negligible, but it has in practice a very important role. The legal system must regulate itself as just another social organization. There is an important difference, though: the law can design the structure of the legal system as an organization, in much the same way companies design their structure by their internal regulations. The creative knowledge is what is used to perform this function.
So far, a set of categories that divide legal knowledge like pieces of a puzzle was presented. These categories are distinguished by their function or role in the legal system, and together realize the main function of the legal system as discussed in section 3.1. However, it still remains to be shown how these pieces together make the whole puzzle, that is, why they are sufficient to represent legal knowledge. In order to do that, this section tries to put these functions together and show that they perform the function the whole legal system performs. That is the coherence of the ontology, and to some extent its completeness.
Fig. 4 shows how the functions/categories identified compose together the main function of the legal system. This is an `expansion' of the functional view pictured in Fig. 2, in which the kinds of abstract processes which occur inside the legal system are detailed, as are the types of knowledge used. Of course, it is not meant that there is a one to one correspondence between these abstract processes and the actual social processes and procedures in a legal system. Instead, they are functional dependencies which describe how the main function is decomposed in sub-functions which together perform it. In Fig. 4, the rounded boxes represent functions (or, alternatively, bodies of knowledge which perform the function), and the solid arrows indicate functional dependencies (inputs and outputs). The dependencies which correspond to actual interactions with the society are indicated in the figure in non-solid arrows. The entities in the society are specific social agents, e.g., the University of Amsterdam (a school), Joost Breuker (a private person), the Ministery of Education (a government agency), Philips (a company), etc.
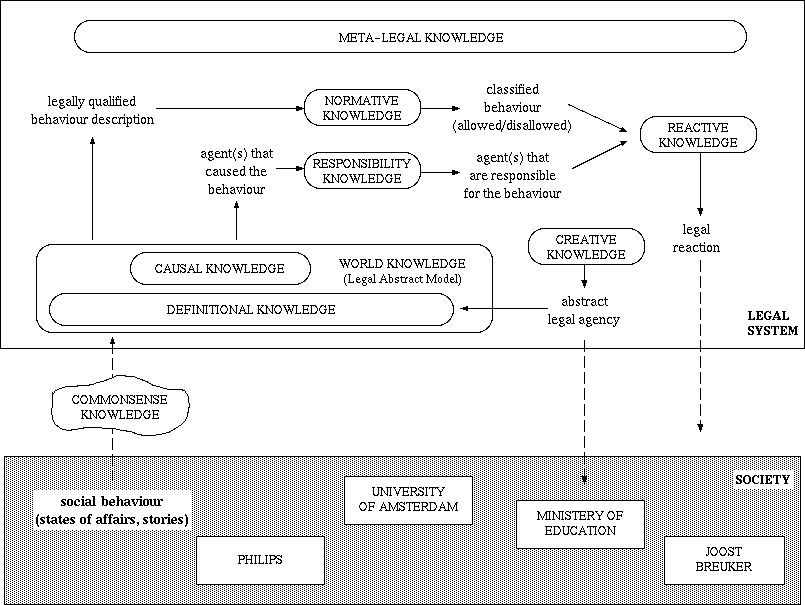
Figure 4: Functional roles of legal knowledge in
the operation of the legal system.
A cycle starts with a real world situation, which is interpreted in order to generate an abstract description of the case in the terms that the legal sources use. This abstract case description is called a legal situation, and the knowledge used to produce this step is the world knowledge, which forms the legal abstract model. Then, the legal situation is analyzed against the normative knowledge to verify whether it violates any norm, thus producing what is called a classified situation (a situation classified as either `allowed' or `disallowed'). In another path, the situation is analyzed using again world knowledge (but here particularly its causal component) in order to find out which agents in the world (if any) have caused the situation. This information is then used as input to the responsibility knowledge which determines which agents (if any) are to be held responsible for the situation. The results obtained in these two paths (the classified situation and the responsible agents) are then used as inputs for a function that defines a possible legal reaction using reactive knowledge. Further, outside this cycle, the law may also create an abstract entity (part of the legal system) using creative knowledge; this entity is also added to the legal abstract model. Finally, meta-legal knowledge refers to all these entities.
We have presented in the previous section an ontology that follows the principles we propose in this paper:
Several advantages came from using the functional ontology of law using these principles. They are loosely related to the fact that principled core ontologies can be excellent tools to implement a divide-and-conquer strategy in knowledge acquisition, and that is how we used the functional ontology of law. Since an ontology defines how one sees the world in terms of primitive knowledge categories and their interrelations, it divides the world into pieces which can be solved separately -- provided, of course, that care is taken of their dependencies. For example, the ontological commitment to the six categories proposed in the functional ontology of law naturally divides the study and representation of legal knowledge in six parts. This leads to several interesting consequences.
First, a degree of flexibility is added by the fact that the solutions given to the parts may not be at the same level of detail. One can be formal and principled studying one category and pragmatic and symbol-level studying another. For example, while we were able to propose a formal theory for reasoning with normative and meta-legal knowledge (in fact detailing this part of the ontology), the many challenges in proposing a general solution to the representation of commonsense and world knowledge refrained us from doing the same to these categories. Instead, we proposed only that a certain type of representation formalisms (terminological or concept languages) were particularly adequate. This is specially important in the design of domain-specific representation formalisms. In general, ontologies are an excellent basis for designing specialized languages or representation formalisms for a certain domain. In principle, different languages may be built based on a certain ontology. These languages may differ for instance in syntax or notation, varying from semi-formal languages to mathematical logic, or in using other (additional) ontological commitments, for instance to using defaults as allowed (and stimulated) by frame-based representations. In the functional ontology of law, we proposed languages varying from formal to semi-formal for representing most of the categories proposed (see [Valente, 1995]).
Because a principled core ontology partitions the domain in reasonably self-contained pieces, one does not need to find a single general formalism to reason with them. For instance, it is commonly proposed in AI & law that the use of rule-based formalisms or some form of deontic logics can be enough to represent legal knowledge. This departs from the assumption that we are looking for a single, unifying reasoning engine. In the operationalization of the functional ontology of law we have proposed different reasoning engines for each category, depending on the specific representation used. Although this was not proven in formal terms, this strategy has the clear potential to make general reasoning with legal knowledge more tractable, since each basic category has specific requirements and restrictions which can be explored in building efficient reasoning mechanisms. In other words, the use of a principled core ontology such as the functional ontology of law can simplify the study of domain specific reasoning, and can potentially improve the tractability of the reasoning engines proposed.
Finally, principled core ontologies naturally constrain the types of arguments and explanations used in the domain. For example, the scheme shown in Fig. 4 can also be seen as the basic structure of legal arguments. Each category corresponds to a type of argument that has as antecedents the inputs and as conclusions the outputs of each function, and as warrants the knowledge belonging to that category. For normative knowledge, for instance, the conclusion is whether a situation is allowed or disallowed, and the warrants are normative knowledge. Moreover, the conclusions in a legal argument are concatenated as shown by the dependencies in the figure; for instance, an argument involving world knowledge (say, concluding that a certain person is considered a `minor' according to a certain definition) being used as subsidiary for an argument involving normative knowledge (say, concluding that a situation in which this person was driving a car is disallowed according to a certain norm). To use Toulmin's terminology [Toulmin, 1969], an ontology defines what types of conclusions, warrants and argument chains are commonly used and/or held valid. This may be an important factor if domain-specific reasoning is viewed as the production and evaluation of arguments (as it is indeed the case in law) .
These advantages were explored in designing the ON-LINE architecture
for legal problem solving [Valente & Breuker, 1995]. ON-LINE represents the
functional ontology in the description logic/system LOOM
[MacGregor, 1991], and uses this representation to define
specialized representations for objects in each of the categories of
the ontology. However, the main advantage of using a principled core
ontology as proposed in this paper appears when defining reasoning
mechanisms. Different mechanisms are used to reason with each
category. For world knowledge, for example, we borrowed LOOM's
classification/subsumption reasoning engine. For normative reasoning, on the other hand, we devised a
specific algorithm for applying norms to cases [Valente, 1995] (in
contrast with e.g. using a deontic reasoning engine). In other
words, instead of trying to define an all-encompassing formalism and
reasoning mechanism that fits all types of legal knowledge, the
functional ontology of law provided a basis for defining specialized
representations and algorithms that are easier to handle and
potentially more tractable.
In most works on ontology and reuse it is not clear what is reused
more than the literal terms. An ontology consists of concepts
(terms), their definitions and some relations with other terms. These
relations express in the first place similarities and distinctions
between terms via subsumption or inclusion hierarchies. Also causal,
temporal or topological relations are used in ontologies. In general,
there is no structural correspondence between the relationships in
ontology and a knowledge base. Correspondence is only by identity
of names of terms, and (parts of) definitions. As the terms in an
ontology are defined as concepts, (parts of) the definition may be
translated directly into knowledge base propositions. It should
be noted that the definitions in a useful ontology are in general
richer than what is to be used in the knowledge base. The meaning of
the concepts get a more specific sense when it comes to a
particular use in the knowledge base. The famous ``interaction
effect'' demands a specific, thin interpretation of a term. This is
what is meant by ontological commitment: the sense/meaning of a term
that is assumed, and not explicit in a knowledge base. For example,
in the functional ontology of law we could have specified the meaning
of cause in more detail, by adding one of the theories of causation
proposed in AI. However, there is no guarantee that the assumptions
made in one such theory are valid in a specific legal system. Indeed,
we found that to some extent each legal system constructs its own
theory of causation based on commonsense views held in a particular
society, and that frequently have to do with ethics and religion. In
other words, while the role of causation is the same across
legal systems, and we were able to express that in our ontology, it
would be a mistake to include a specific interpretation of the term,
since it would probably not reusable.
Another point worth noting is that an ontology may not contain all knowledge that is in the knowledge base. Some empirical or compiled-out practical knowledge that is dependent on the particular method may not find an easy, and principled place in an ontology. This is not bug in an ontology, as [Motta et al., 1996, p 361,] believe, but a feature. An (application) ontology is not a full application documentation, but a conceptualization and consensus of terms. For that reason, the Sisyphus-II reconstructions of the VT-application (not: domain) could not be solely based upon whichever of the ontologies available. Because it is not easy to distinguish the concepts that exist only in order to express some task-specific knowledge from the ones which are not, if we would demand that all application specific knowledge is in the (application) ontology, reuse will be exclusively restricted to applications with exactly the same functionality. The definitions and positions/roles in structures of the ontology are used to give the term the right position, i.e., fitting a particular role in a new knowledge base. For instance, in medical diagnosis a disease may take the role of a hypothesis/solution, but it may also be used as evidence for the presence of a specific other disease, or even as evidence for any infectious disease by causing immunosuppression (the example is from [van Heijst, 1995]). An ontology should enable and even suggest the multiple roles that a concept may take in problem solving.
This point can be further illustrated by reference to an example of building an ontology for reuse purposes, based on an existing knowledge base of an application. In a recent work by one of the authors, an ontology was constructed from the knowledge base of INSPECT, a system for critiquing air campaign plans [Valente et al., 1996]. The idea was to make this ontology public within a group of researchers that are building other applications in the air campaign planning domain. In the process of building the ontology, certain concepts that were used in INSPECT had to be removed, because they did not make sense outside the application context. For example, a concept like objective-with-too-many-parents (the objectives are arranged in a hierarchy) only makes sense within INSPECT, because the definition of what ``too many'' means is dependent on the context of critiquing the formulation of the objectives. This concept would either make no sense or have to be totally redefined if it was to be used in e.g., an application that generates air campaign plans.
The main theme of this paper is the construction of (more) principled
core ontologies to support libraries of ontologies. We largely agree
with [van Heijst et al., 1996] that the organization of such a library
should be dependent on its relations with this core library and the
major goal of this paper is to take one step further and propose a
more principled instead of (or additional to) the rather pragmatic
approach of van Heijst et al. Principles sound nice. They are
the basis of good, i.e., (cost) effective engineering. However,
principles in engineering are not simply given, but grow from
pragmatic driven experiences and reflection. As there are no real
experiences with libraries of ontologies for knowledge
acquisition, we still have to rely on reflection on the
results presented so far, i.e., what is the consequential difference
between [van Heijst et al., 1996] (see also: [van Heijst, 1995]) medical
core library and the one we propose here for law. The second question
is whether we can predict or guess whether these differences will have
an effect on large scale library construction and maintenance.
In comparing the two results we are not so much interested in how they are brought about. Implicitly the same principles that we have proposed may have been included in the results. This is indeed what it looks like to some extent. For example, let us take a closer look at the core ontology for medicine proposed by van Heijst et al. Based on Fig. 5.2 and Table 5.1 in [van Heijst, 1995] we find the following terms (``theories'') in the core library: 0) generic concepts 1) fundamental-medical -concepts (e.g., human-body), 2) anatomy, physiology, 3) findings, drugs, surgeries 4) clinical state abstractions and 5) diseases. Indeed a highly heterogeneous and unprincipled set. The way these terms are related is as heterogeneous. However, a closer look reveals two or three points of view mixed: real theories (anatomy, physiology) and clinical environment (not clear what it contains). Between these there is the real core consisting of a diagnosis branch (tests, diseases, findings) and a therapy branch (therapy, drugs, surgeries). This core is a highly functional one and in our terminology we would call this a functional ontology of the medical system. Moreover, the categories look also like lines of argument: clinical state abstraction connect diseases with findings; therapies connect diseases with drugs and surgery. The conclusion is twofold:
What does it mean that we appear to be inclined to take a functional
stance when it comes to defining a core ontology for such high level
and complex domains as medicine or law? The following is suggested.
The domains are distinguished from their environment as ``systems''
[Hobbs, 1995]. This distinction is the basis of behavioral or
functional characteristics [Breuker, 1994]. Knowledge about such a
domain, world or system becomes ``a model of a system''
[Clancey, 1985]. There are two views on this (functional)
model-like character of domain ontologies for knowledge
acquisition. The first one may coincide with philosophers' views
on ontology. It suggests that the designers of these ontologies have
been seduced into modeling rather than that they have kept a purely
ontological stance. Function is a commitment that may overlook
essence. The second one is the one we prefer and that is that an
ontology is not a model of a type of system, but it is based on one.
This basis is the rationale behind the ontology, i.e., ontology is
based upon our knowledge of a world, and not that our knowledge of a
world is based upon ontology. Of course, one may assume as in
perception that both ``processes'' may occur in order to extend our
knowledge about worlds in a kind of bootstrapping, but the process of
knowledge acquisition for building systems relies on existing
knowledge and is not aimed at creating new knowledge (it may be a
side-effect).
The effect of a functional modeling perspective in a domain ontology appears to bring `automatically' all the principles we proposed for crucial core ontologies. The ontology looks more homogeneous and it is sufficient. We can `show' that we do not need other categories. To be precise, if one can propose a legal category or term that is not in our ontology of law, the ontology is refuted, like a theory. However, in a pragmatic approach there is no criterion for coherence. Categories can be added or deleted without affecting the whole. There is no notion of completeness or covering other than by debate and agreement, i.e., the way terminological standards are set in professional communities. These `ontologies' are lists rather than structures. However, debate is not a solid foundation for an ontological library where the core should remain immanent for at least a decade. To start the debate, we - as medical outsiders - see no reason to preclude from the medical core library such categories like biochemistry, biomechanics, psychology, epidemiology, Bayesian statistics, and in fact the full curriculum of medical students. Moreover, why only drugs and surgery as possible therapies while there is radiation, exercise, physical stimulation, good words etc. Further, medicine does not consist only of diagnosis and therapy: where do preventive activities come in? In summary, pragmatics based on ``naturelness'' and ``agreement'' are not sufficiently constraining because they refer to the eternal debate on the nature of the world. Taking on a functional modeling perspective, where the emphasis is on coherence, may indeed reveal the implied texture of common understanding. The ontology of law has a category called ``normative knowledge''; the terms within this category, such as rights, permissions etc. are highly debated in legal theory, but the existence of normative categories in law is not disputed; only how this may differ from norms in ethics or normative standards in applied technology.
In summary, we put forward the hypothesis that a principled (core) domain ontology should be based on the notion of modeling a type of system. This will not only provide coherent and sufficient ontologies, but also reflect the notion that an ontology of a domain is based upon knowledge of a domain.
We gratefully acknowledge the support of DARPA with the contract DABT63-95-C-0059 as part of the DARPA/Rome Laboratory Planning Initiative.