APECKS: a Tool to Support Living Ontologies
Ontology servers are currently under-developed in terms of the support they provide for collaborative activities on their content. This paper presents the APECKS (Adaptive Presentation Environment for Collaborative Knowledge Structuring) system, an ontology server which supports collaboration by allowing individuals to create personal ontologies. These ontologies can be compared with others' to prompt discussion about the sources of their differences and similarities. Support for structured communication in this way should, we suggest, produce richer, more detailed ontologies, as well as design rationales for their structure. We assert that ontologies must be viewed as living, debated and maintained resources: APECKS is a system to support collaborative work with them. The APECKS system and its lifecycle is described and discussed and future research directions highlighted.
The progress of the World Wide Web (WWW) is gradually bringing with it a change in the nature of documents. Instead of being static information that is simply transferred in the same way to whoever requests it, documents are becoming animated: growing and evolving information that adapts its presentation according to the needs of the user. Systems which support these Living Documents not only store and supply information, but support collaboration through structured communication which itself becomes part of the document. This paper argues that, in the same way, ontologies should develop into Living Ontologies, facilitating collaboration between their creators.
The importance of ontologies as a key resource for knowledge engineers and knowledge management is increasingly recognised. Libraries or repositories of ontologies are seen as an essential ingredient in promoting knowledge modelling, reuse and dissemination. Ontologies conceived as an explicit knowledge level specification of a conceptualisation (van Heijst, Schreiber & Wielinga, 1997) are here to stay. We need software tools to support the development and maintenance of ontologies. APECKS attempts to provide a set of capabilities based around the fundamental premise that developing ontologies will be a collaborative exercise.
In the next section we review the current state of the art in ontology management. We will focus particularly on the requirement for collaborative activities. We will next present the range of such activities embodied in APECKS. The rest of the paper will describe how APECKS is organised to provide this support.
Ontology Servers provide ontologies for general use in knowledge intensive applications through the Internet. This section details and examines a number of these Ontology Servers in terms of the manner in which interaction between the server and users is handled, and how interaction between users is handled.
Interaction with Users
Ontology servers store ontologies and provide them to their users. The ontologies served by ontology servers are usually defined through a knowledge representation language such as KIF (within the Ontolingua server - Farquhar, Fikes & Rice, 1996; Rice et al., 1996; Farquhar, Fikes, Pratt & Rice, 1995) or LOOM (in the Ontosaurus browser - Swartout et al., 1996). This underlying knowledge representation is then translated into HTML (HyperText Mark-up Language [1]) pages which can be viewed through the WWW, a process Farquhar, Fikes & Rice (1996) describe as having the knowledge 'projected through a variety of lenses
'. The translation is typically done through either CGI scripts [2] which interface between the knowledge representation and the HTTP (HyperText Transaction Protocol [3]) server itself, or through a programmable HTTP server such as CL-HTTP [4], the common-lisp HTTP server. The Ontolingua server also allows users to access the ontologies it holds either programmatically, through a networked API, or by having them translated into different knowledge representation languages, such as LOOM or CLIPS.
When accessed through the WWW, ontology servers generally offer a frame-based
view of the knowledge represented within the ontology being viewed. Having a frame-based view of the ontology means that users view pages which represent either different real-world objects, such as 'Granite' (a type of rock), or conceptual classes which group a number of such objects together, such as 'metamorphic rocks'. These pages give information about the object's location within a conceptual hierarchy (with links to other objects) and specific information about the object itself. This information can usually be altered through HTML forms within the pages, allowing the user to change the ontology as they desire. Other types of views of the structures of ontologies are offered by different servers. The Co4 system, for example, allows users to define sets of viewpoints which give alternative hierarchical classifications of the objects within the ontology (Euzenat, 1996b).
More recent developments, like Tadzebao and WebOnto (Domingue, 1998) use JavaTM[5] applets as clients to ontology servers. The use of Java gives much more flexibility and interactivity in interface design than vanilla HTML, while maintaining much of the portability and platform independence of HTML.
Ontology servers are designed to let a number of users create an ontology together.
Communication between users is particularly important for ontology servers designed
to be used for corporate memory, so that the system becomes more than a simple record of events (Euzenat, 1996b). Examples of the types of collaboration currently supported are:
- Subscription
- Within some systems, such as SHADE (SHAred Dependency Engineering - Gruber, Tenenbaum & Weber, 1992), users can 'subscribe' to certain areas of interest within a knowledge representation. They are then notified of any changes that occur to those areas.
- Annotations
- The support of human-readable ontologies often involves the use of basic annotations, both to make the axioms more easily understandable and to aid communication between multiple users who may be accessing the same ontology. HyTropes (Euzenat, 1996b), for example, allows users to add annotations to either the top or the bottom of any HTML page it generates.
- Group Sessions
- The Ontolingua server supports group sessions where a number of users can work on an ontology at the same time and receive notification when changes are made by other users within the session.
- Synchronous Communication
- Tadzebao (Domingue, 1998) enables collaborators to send short messages to each other, including images and ontologies.
Some argue that the primary aim in the construction of ontologies, for knowledge engineers, is to create a single ontology that can be used in every possible knowledge intensive application. This perfect ontology could then be trimmed down to provide a knowledge base suited for a particular task or domain using techniques such as those described by Swartout et al. (1996). It is still a moot point whether monolithic ontologies can be built: alternatively, smaller ontologies can be brought together to create a knowledge resource. Whichever method is used, the ideals of correctness and consistency remain and large scale collaborative effort towards the creation of ontologies needs to be supported.
Ideally, the easiest way to achieve a consistent and comprehensive ontology is to base it on the knowledge of a single expert. However, in many if not most cases, a single expert is not sufficient due to the restricted nature of their knowledge which may be specialised, out of date or culturally specific. Thus multiple experts are used to create a larger and more accurate picture.
Unfortunately, experts differ in terms of their goals, priorities, opinions and beliefs. The task of the knowledge engineer, in creating a 'correct' ontology, is to sort the factual wheat from the fictional chaff and pull out a core of useful knowledge. In the main, the correct knowledge is taken to be equivalent to the consensual knowledge, and thus the knowledge engineer's task becomes one of finding consensus within the divergent knowledge of the experts. This leads to the type of assertion as made by Farquhar et al. (1996), that ontologies, by definition, represent consensual knowledge: the single accepted definitions of technical terms used within the domain.
It can be argued that the expertise of a knowledge engineer lies in the art of constructing these consensual ontologies from the knowledge of a number of experts, and there are a number of techniques that can be used to compare expert knowledge, such as Shaw & Gaines' (1989) consensus/conflict/correspondence/contrast classification and Boy's (1996) Group Elicitation Method. Where differences occur between experts, the knowledge engineer acts as a negotiator or simply chooses which source to trust on the basis of their estimated reliability. In this way, knowledge engineers play an essential role in the construction of a consistent ontology.
However, one of the desired consequences of internet-accessible knowledge engineering tools, and to a lesser extent those that are computer-aided generally, is that less direct intervention on the part of the knowledge engineer is required. Instead of a knowledge engineer leading the expert through a number of knowledge acquisition techniques, the expert can be left to carry them out in their own time. Ontology servers have generally been designed for by use by knowledge engineers: could they also be used directly by experts?
While allowing experts direct access to ontologies saves time for the knowledge engineer, it may also cause problems in the creation of consensual ontologies. Without the knowledge engineer taking on the role of middle man, how can consensus be achieved in these systems? How can different knowledge engineers reach consensus on the ontologies they create, which may, after all, be different? The answers in currently available ontology servers range from a free-for-all, where any user can make changes, through to consensual systems where all users must agree before a change can be made.
At the most basic level of management of multi-user ontologies, access to ontologies can be restricted through the use of user and group read and write permissions, set by the owner of an ontology, as in the Ontolingua server. These permissions can be supported by the use of communication techniques as outlined above which enable the users to keep track of the changes that others are making.
Within the Ontosaurus Browser (Swartout et al., 1996), changes can only be made by an individual user if they are consistent with the rest of the ontology. This is made possible due to the reasoning capabilities built-in to the LOOM representation language and prevents inconsistent ontologies from being built. This facility is not only useful for multi-user ontology construction, but also for checking the consistency of knowledge from a single user.
Co4 (Euzenat, 1996a & 1996b) goes one step further in structuring the interactions between individuals working on the same ontology. Ontologies are built into a hierarchy of group knowledge bases, each one of which represents the consensual knowledge for the users that are subscribed to that group. At the bottom of the hierarchy, each user can have a number of knowledge bases which they can alter as they please. When a change is proposed for the group base, each of the users subscribed to it is notified of the proposal and may either accept or reject it. If all users accept the proposal, the group knowledge base is changed, but if a single user objects, the change is not made in its present form. This procedure models itself on the submission procedure for academic journals. Individual users can also choose not to accept any changes into their own individual knowledge bases, even if they are accepted on a group level.
In Swartout et al. (1996)'s vision of the future in knowledge base design through a collaborative ontology servers, knowledge engineers are able to familiarise themselves with the domain and construct an initial knowledge base from a pre-existing ontology. This ontology can be translated into the many formats, such as KIF, LOOM or C++, for use by the system they are building. If a knowledge engineer has knowledge to add to the ontology, they can 'check out' part of the ontology, update it, and then 'check it back in'. At this point, the system itself assesses the new knowledge for compatibility with the previous version of the ontology. Other users are able to look at a record of the changes that have occurred to the knowledge base.
The problems with the use of these systems directly by experts, in our view, lie in the avoidance of consideration of the causes of a lack of consensus between them. As discussed earlier, characteristics of individual experts may have an implicit influence on the decisions they make. Making these implicit differences explicit can enhance understanding of the domain, and doing this is one of the tasks of the knowledge engineer. Where a knowledge engineer is unavailable, as in these ontology servers, experts may argue a particular point, having changes blocked or continuously changed back without reaching an understanding of the true differences between them.
Our approach seeks to enable experts to address the sources of their disagreements and to argue with a productive end. It is also hoped that this approach will also enable the knowledge engineers who use ontology servers to discuss their differences more thoroughly, leading to a better understanding of the criteria on which ontology design is based. This approach is instantiated in an ontology server named APECKS (Adaptive Presentation Environment for Collaborative Knowledge Structuring).
There are five intertwined innovations within APECKS that further the development of ontology servers. Firstly, it is based on personal ontologies which we call roles. Secondly, it is positioned in the context of other networked knowledge-based resources. Thirdly, it can be used directly by domain experts as well as knowledge engineers as it supports a number of knowledge acquisition techniques. Fourthly, it not only records the changes that are made within it but also the rationale behind those changes. Finally, and most importantly, it supports collaboration through structured communication between users.
Existing ontology servers hold unrelated ontologies which can only be accessed for changes by those to whom permission has explicitly been given. On top of this, preference is given to the existing state of affairs, with changes having to satisfy certain constraints, such as consistency with the rest of the representation or the agreement of all the other collaborators. This may, we argue, lead to stagnant and restricted ontologies.
APECKS, on the other hand, is based on personal ontologies, representing an individual's understanding of a domain. Creating such ontologies is quick and easy, with support for copying and adapting the whole or part of other peoples', and anyone can create them. The ontologies can exist in a state of inconsistency within themselves, or with other individual's ontologies, so that the reasons for these inconsistencies can be explored. The emphasis in the creation of ontologies within APECKS is on change and exploration: a brainstorming process. This, we contend, will lead to dynamic and diverse ontologies.
While current ontology servers can be accessed by users either through a hypertext interface or programmatically, their focus is, as their name suggests, on serving information: they do not access other networked resources. APECKS, on the other hand, is envisioned as acting as a client as well as a server, accessing network-accessible knowledge acquisition applications and other ontology servers. Currently, it uses WebGrid (Gaines & Shaw, 1996a & 1996b) to support knowledge acquisition. In the future, it is envisioned that the ontologies held by other ontology servers would be accessed by APECKS and used just like the other personal ontologies APECKS holds. In this way, APECKS positions itself in the centre of the network of knowledge on the Internet.
Existing ontology servers give support to knowledge engineers in the construction of ontologies. APECKS is geared towards the support of domain experts, who are not necessarily experts in the construction of ontologies. APECKS currently carries out basic knowledge acquisition itself. Other, more sophisticated techniques can be slotted into APECKS as they become available in internet-accessible tools. WebGrid (Gaines & Shaw, 1996a & 1996b), for example, is already used to give support for repertory grids within APECKS.
Within linear communication media, it is easy for a user to tell when a change has occurred, when a post has been added to a newsgroup or when someone has said something. With hyper-communication media, where communication is structured in a hypertext network of comments and annotations, it is harder for the user to identify where changes have been made.
Chronological awareness tools have been developed which generate information about changes in hypertext structures (Chen & Gaines, 1996) which can be client-side or server-side. Server-side chronological awareness tools such as CHRONO (Chen, 1996) keep track of changes to documents within a file structure on a server and create a page listing these changes.
Change is very important within APECKS, so support is needed for recording the changes, recording the reasons for the changes and making the rationale available and explicit to users. When they return to the system after a period of absence, users are notified of changes related to their personal ontologies. These changes can be annotated, giving the reasons behind the alterations. This rationale can later be searched by other users seeking to answer questions about why certain actions were taken.
The real innovation of APECKS, however, lies in its support for collaboration between users through the comparison of their personal ontologies. APECKS automatically compares the personal ontologies constructed by its users in terms of the consensus/conflict/correspondence/contrast classification put forward by Shaw & Gaines (1989). Ontologies are not just compared in terms of whether they are consistent with each other or not, but the degree of consistency with each other.
Users of APECKS are prompted to take action or communicate with each other on the basis of the comparisons made between their personal ontologies. For example, if one ontology classifies rocks in terms of their 'quartz content' while another does so in exactly the same way, but uses the term 'silica content', APECKS would recognise this as a state of correspondence (different terminology being used for the same concept). The users who constructed these ontologies would be prompted to either change the term to bring them into line with the other or to start a discussion about why different terms were being used.
Discussion based on comparisons between ontologies has two useful consequences. The first is that domain-related detail is uncovered. In the case of 'quartz content' vs. 'silica content', discussion would uncover that higher silica content causes higher quartz content within a rock, a detail that may have been missing otherwise. In this way, richer, more detailed ontologies are built up.
The second consequence of discussion is that criteria used in the construction of ontologies are made explicit. In this example, the reason for using the term 'quartz content' may be an assumption that identifying the degree of quartz content is easier for geologists in the field that estimating a percentage of silica, which might lead to the explicit construction of a premise such as "The users of the KBS will be geologists in the field." The explicit statement of the criteria under which the ontologies are constructed provides meta-information about their purpose that is usually left implicit.
The rest of this paper describes and discusses APECKS. We start by giving a description of the system, including the technology it utilises, the way it represents knowledge internally and how it can be used for browsing ontologies. The second section goes through the lifecycle of the system, from seeding, through to the cycle of the construction of ontologies, their comparison and the following discussion and reconstruction. Finally, the discussion outlines the future directions that this work may follow.
APECKS is an ontology construction system for domain experts rather than for knowledge engineers. In this way it is similar to Co4 (Euzenat, 1996a & 1996b) and SHADE (Gruber, Tenenbaum & Weber, 1992; McGuire, Kuokka, Weber, Tenenbaum, Gruber & Olsen, 1993) as it can operate as a corporate memory, used by those interested in the domain themselves, rather than through a specialist intermediary. While APECKS can be used to construct a consensual ontology, the emphasis within APECKS is not on the outcome (the ontology itself), but rather the process: the disagreements and discussion that are involved in creating a consensual ontology.
APECKS supports collaboration between users by supporting the construction of both a semi-formal knowledge representation and a semi-formal discussion of the domain through techniques similar to CSCW and design rationale systems such as IBIS (Rittel & Kunz, 1970; Conklin & Begeman, 1988; Conklin & Yakemovic, 1991), PHI (Fischer, Lemke, McCall & Morch, 1991; Fischer, Grudin, Lemke, McCall, Ostwald, Reeves & Shipman, 1992), QOC (MacClean, Young, Bellotti & Moran, 1991; Bellotti, MacClean & Moran, 1991; Bellotti, 1993; Buckingham Shum, 1993), DRL (Lee & Lai, 1991) and The Coordinator (Winograd, 1988).
The following sections describe the technology behind APECKS; the knowledge representation schema it utilises; and the ways in which ontologies can be browsed within APECKS.
APECKS is based on a internet-accessible multi-user text-based virtual environment named MOO (Multi-user domain - object-oriented; Curtis, 1992). The original and primary purpose of MOOs was to provide a communication facility that is environmentally richer than inter-relay chat (IRC) and less adventure-oriented than multi-user dungeons (MUDs). This somewhat unconventional system is used as the basis for APECKS for a number of reasons:
- Object oriented database
- MOOs consist of two parts: an object-oriented database which defines each individual MOO and a server program which interprets and runs the database file. The object-oriented nature of MOOs means that object-oriented representations, like the frame representations used in knowledge engineering, are very simple to employ.
- Internet accessibility
- MOOs are accessible via the internet using the telnet protocol. The mechanisms for opening, closing and maintaining connections between computers necessary for ontology servers are built into the MOO server program. Several MOO developers have built on top of this and made available MOO databases which allow objects within them to be viewed and manipulated through the WWW.
- Programmability and rapid prototyping
- MOOs are programming environments. Any object within a MOO database can be programmed to interact with users or other objects. Because these programs are part of the database itself, they do not have to be compiled, leading to rapid prototyping. For the purposes of behaving as a WWW server, MOOs can be programmed to dynamically generate HTML.
- Multi-user synchronous communication
- MOOs allow multiple users to connect to them and interact with each other using synchronous text-based communication. Built into the standard LambdaMOO database (Curtis, 1992) are user representations, which facilitate user modelling, and other communication methods, such as asynchronous mail.
For APECKS, three modifications were made to the standard LambdaMOO database (Curtis, 1992). Firstly, the APECKS database understands HTTP, and can therefore act as both a WWW server and, when in the role of a proxy or gateway, a WWW client. Secondly, the APECKS database generates vanilla HTML (without any Java applets or ECMAScript [6]) dynamically on the basis of its internal object representations, enabling the user to interact with the objects using a WWW browser. Finally, a number of 'generic' objects were added to the database, which form the basis of the Knowledge Representation Schema used by APECKS.
APECKS is a Frame Representation System which represents ontologies in a manner based on that defined by the Frame Ontology (Karp & Gruber, 1997). Representing knowledge using the frames defined by the Frame Ontology means that translation between the representation within the APECKS system and that in other frame representation systems can be facilitated by Ontolingua and the Generic Frame Protocol (Karp, Myers & Gruber, 1995, Karp & Gruber, 1997). Since the Frame Ontology is used as the basis of the representation of knowledge in Ontolingua, it also means that network-accessible Ontolingua ontologies can be seamlessly incorporated into the APECKS ontology representation.
The basis of the APECKS knowledge representation is a number of individuals which are grouped into classes and have slots, which define values and have facets. It handles multiple inheritance through the class hierarchy, such that the value of a slot for an individual can be inherited from its types (classes). Slots can hold many different kinds of values, and can hold many at the same time. Some restrictions apply within APECKS as the knowledge representation is only intended as a proof of concept: the class hierarchy is, in the main, determined by the membership of individuals to classes rather than being directly defined by the user; users cannot define facets or axioms. In the main, these restrictions serve to make it easier for users who are not knowledge engineers to understand and use the system.
Knowledge stored within an APECKS database is divided into a number of domains. This division is necessary since, instead of only holding a single ontology for a domain, APECKS represents a number of ontologies each of which is defined by a single user. Any user may define multiple ontologies within a single domain, representing different aspects of the domain or different tasks that might be carried out within it. Each of these ontologies is known as a role. None of the defined ontologies are shared in the manner of Ontolingua shared sessions or as in Ontosaurus. Instead, each role is represented almost entirely separately, in a similar manner to the separate knowledge bases in Co4.
There is some overlap between roles, however, in that the same individuals can be classified in many different roles. Each individual has slots for information which define it uniquely, such as its name and description, but the class membership of an individual, its inherited slots and the values of those slots, may vary from role to role. A representation of the similarities and differences between two or more roles is known as a comparison: these are discussed in greater detail in the section on ontology comparison, below.
On top of those objects which encode the ontologies, there are objects which facilitate discussion about them. There are two types of these objects: criteria, which are short, general, assertions about the reasons for a particular state of affairs; and annotations, which are longer discussions, sometimes with more than one author. These are discussed in greater detail in the section on communication within APECKS, below.
The ontologies stored within APECKS can be browsed either through the WWW or, in the future, through a text-based virtual environment interface within the MOO.
Within APECKS, each object (individual, class, slot, role, domain, comparison, criterion or annotation) has a number of WWW pages associated with it. These pages are each dynamically created on the basis of the current state of the object and the identity of the user (which determines whether they have permission to edit the object). The pages that are generated in this way vary according to the type of object.
The main view of the object gives essential information about it, including its name and description and other relevant information depending on the type of object, such as slot values, subclasses and slot constraints. These characteristics can be edited using HTML forms within a separate page.
The changes view gives a list of all the changes that have happened to the object since the list of changes was last looked at. This page also offers a search engine, allowing a user to search for changes on an object by date, the person who made the change, and other details about the change. In the future, it is envisioned that users of APECKS will be notified when they first connect of changes that have happened to roles related to their own, as well as annotations by other people which have been made to their own roles.
The comments view gives a list of the annotations and criteria that pertain to the object. This page also offers a search engine, allowing a user to search for comments on an object by date, the person who made the comment, for keywords within the comment and other objects to which the comment is related.
Finally, to support use by domain experts as well as knowledge engineers, help is available for every type of object. For roles and classes, users may also view pages which display list of suggested actions, supporting knowledge acquisition from the user. These are discussed in detail in the section on the ontology construction phase of APECKS use, below. Separate pages also give links to views of related objects within other roles.
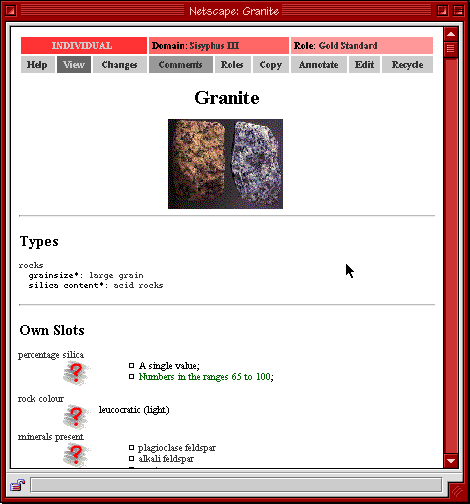
A screenshot of the view of an individual, 'Granite', is shown in Figure 1. Each of the pages shown within APECKS contains a status bar which indicates the type of object, the domain it is in, and (where applicable) the role that it is being viewed under and the class whose instances are being looked at. Under the status bar is a button bar allowing the user to navigate to a different page or create new objects, such as annotations.
The virtual environment interface to APECKS is currently undeveloped, but the basis for it is present in the choice of using MOOs as the basis for APECKS. Within MOOs, every object within the database appears as a virtually 'physical' thing within the virtual environment, and can thus be picked up and carried around, have things put in it, or travelled through. The potential therefore exists for creating a virtual environment in which the representation of knowledge is browsed and altered by the manipulation of virtual objects. Examples of this include:
- Class hierarchies might be represented by a virtual tree: branches represent classes and the leaves on them represent individuals. Climbing the tree allows the user to traverse the hierarchy.
- Card sorts might be carried out by users picking up virtual representations of the individuals, such as wooden blocks, and putting them in virtual representations of classes, such as toy boxes.
- Rooms might represent frames within an ontology and having discussions while within that virtual location may lead to an annotation being attached to that frame, the content being the discussion that went on.
This section describes the life-cycle of a domain within the APECKS system. The process starts with the seeding of the domain, during which a number of individuals are defined. The process continues with a cycle of ontology construction, comparison of ontologies and discussion of differences between them, which in turn may lead to experts making changes to their ontologies.
The seeding process is a short stage during which the system is set up with information to start the collaborative process. The user community can be given identities at this stage, or create their own identities automatically later. The next step is create an object to hold information about the domain as a whole.
Individuals within the domain are then created and given names, descriptions and, if applicable, URLs of images of the individuals. These form a starting basis for the construction of roles by the other users of the system. Individuals can be created by other users as necessary to give extra examples: the initial set is simply a starting point.
If the user seeding the domain has a good idea about how the roles within the domain should be designed, they might also create a set of criteria to prompt other users in that direction. More about the purpose of criteria is given below, in the section on discussing ontologies.
The second stage, and one that is continuous throughout the life of the system, is one of construction of ontologies by individual users. Users first construct a role to represent their personal view of the domain and the individuals within it. Within that role, they are then free to classify any or all of the individuals within the domain according to their own view.
APECKS supports this process of ontology construction for knowledge engineers by allowing them to explicitly create new individuals, classes, and slots and assigning properties to them. However, because APECKS is also intended for use by people who are not experts at the construction of ontologies, extra knowledge acquisition support is given both internally and externally, in the form of WebGrid (Gaines & Shaw, 1996a & 1996b).
Basic knowledge acquisition support is given within APECKS through the use of pages listing possible actions which can be carried out by the user. The listed actions prompt the user into making changes of three kinds: to expand the ontology by adding individuals or classes; to rerepresent parts of the ontology, such as by rerepresenting categorical slots as subclass partitions; and changes that maintain consistency when the ontology is inconsistent.
For any of these action prompts, the user is also given the opportunity to create an annotation explaining the current state of affairs. Making such an annotation prevents the action prompt being shown again. These annotations become part of the design rationale for the ontology.
Repertory grids are one of the more powerful knowledge acquisition techniques available to knowledge engineers, particularly as they are easy to automate. APECKS uses the network-accessible WebGrid-II server (Gaines & Shaw, 1998) to provide this technique for its users. WebGrid-II acts as an intermediary between HTTP clients (usually WWW browsers) and Repertory Grid elicitation, analysis, comparison, modeling and inference tools, enabling these tools to be accessed through the WWW.
During a user's interaction with WebGrid, APECKS acts as a gateway: it behaves like a HTTP client towards WebGrid-II, while still acting as a HTTP server for the user's WWW browser. Throughout the interaction, the user is presented with the same navigation bar as is normal viewed in APECKS, so that the process is as transparent as possible. APECKS performs three processes which to enable this facility: the translation of the ontologies into grids; behaving as a gateway for requests to WebGrid; and the translation of grids into ontologies.
WebGrid encodes grids through the use of hidden fields within HTML pages, which are submitted with each action the user takes. This client-side representation differs from APECKS's server-side representation.
To initiate an interaction with WebGrid, APECKS must first generate a form submission that, when submitted to WebGrid, will encode the knowledge representation of a role or subsection of a role. Thus the initial step is the translation from APECKS's internal knowledge representation to WebGrid's hidden fields, which is carried out once, at the beginning of an interaction between the user and WebGrid. Submission of these hidden fields results in the WebGrid's main page, which gives prompts for triad elicitation, the editing of constructs and elements and so on.
The major problem in the linkup between APECKS and WebGrid lies in the translation between the hierarchical structure used by APECKS and the flat structure used by WebGrid, and back again. APECKS stores explicit information about hierarchical structures, through the use of classes. Analysis techniques provided within WebGrid-II can expose hierarchical structures within grids (Shaw & Gaines, 1998) from ratings on constructs, but users may not initially supply these dimensions as slots. Also, since APECKS users are also intended to be domain experts, they are not necessarily adept at using and interpreting the outcome of these grid analysis techniques, while the usually graphical output is not amenable to machine interpretation. Our solution to this problem involves isolating three separate grids within each role, and offering users the facility of using WebGrid with any one of these grids at a time.
The simplest and most usual translation between APECKS and WebGrid involves each instance within a role is represented as an element within WebGrid and each slot and class is represented as a construct. For example, each instance of the class 'rocks' would be represented as an element within WebGrid. The slot 'hardness' would be represented as a rating scale construct and the class 'acid rocks' would be represented as a boolean rating scale construct, with each instance taking either the value 1 ('in-acid-rocks') or 2 ('not-in-acid-rocks').
The second kind of grid that can be constructed involves the elements within WebGrid being based on classes within APECKS, the constructs being based on slots and the values taken by the constructs being the default values for the instances of the class. For example, all the subclasses of the class 'rocks', such as 'large grainsize', 'medium grainsize' and 'small grainsize' would be represented as elements. The slot 'grainsize' would be represented as a categorical construct, taking the value 'large' for the element 'large grainsize', 'medium' for the element 'medium grainsize' and so on.
The third, and probably least used of the grids that are created by APECKS is one that allows users to gain an overview of the types of slots that are used within a role. This allows users to set various characteristics of slots: the inverse, whether it is inherited, and its symmetricity, reflexivity and transitivity. For example, the slot 'minerals', which holds values encoding which minerals are in a rock, and the slot 'rocks', which holds values encoding which rocks a mineral is part of, would be represented as elements within WebGrid. The construct 'inverse' would hold the value 'rocks' for the element 'minerals' and vice versa.
HTML hidden fields are constructed which encode these grids on the pages which prompt for actions. When users submit these forms, the transaction with WebGrid begins, and APECKS begins the next process: acting as a gateway.
APECKS acts as a gateway while the user interacts with WebGrid, with all HTTP requests to and responses from WebGrid passing through APECKS. Requests are passed from the user's web browser exactly as-is, but the response goes through three processes before being sent to the user:
- Logging of WebGrid fields
- The WebGrid fields that are contained within the response are logged.
- Changing of URLs
- URLs which point directly to WebGrid are changed so that the transaction continues to take place using APECKS as a gateway.
- Checking for invalid WebGrid fields
- The most important filtering of the page sent by WebGrid in response to the user request is to check for changes that have been made that, while valid within WebGrid, would cause problems for APECKS. The fields from the previous submission are checked to make sure that the user has not renamed elements, changed the way that class membership has been encoded, or made other alterations to the grid which would disrupt the translation from the WebGrid grid back to APECKS's representation. If such changes have been made, the user is warned and the response altered to undo the change.
When a user requests a page within a role that may have been altered on the basis of a WebGrid interaction, the recorded fields from the most recent response from WebGrid are used to make changes to the APECKS ontology. Changes to APECKS are postponed until then to reduce the amount of processing that APECKS must perform during a user's interaction with WebGrid. The user is not required to take any action to indicate the end of a WebGrid session, as this would compromise the aim of transparency between APECKS and WebGrid.
Once roles have been at least partially constructed, the process of comparing them to locate differences between experts can begin. The comparisons between roles are made using the consensus/conflict/correspondence/contrast classification expounded by Shaw & Gaines (1989). Table 1 shows the four classifications of relationships between conceptual structures.
Table 1: Consensus, conflict, correspondence and contrast among experts. From Shaw & Gaines (1989).
|
| Terminology
|
| Same
| Different
|
| Attributes
| Same
|
| Consensus
|
|---|
| Experts use terminology and concepts in the same way
|
|
| Correspondence
|
|---|
| Experts use different terminology for the same concepts
|
|
| Different
|
| Conflict
|
|---|
| Experts use same terminology for different concepts
|
|
| Contrast
|
|---|
| Experts differ in terminology and concepts
|
|
The above classification was intended for use on repertory grids, which have a flat structure where each element has a rating for each construct. The relationships between ontologies are more complicated than the relationships between grids. Firstly, some of the slots defined within the ontology may not hold values that are suitable for comparisons: these are 'key' values which define an individual uniquely, such as its name or a description of the individual. Secondly, and more importantly, elements within ontologies are not only defined by the values they have in their slots, but also by their position in the class heterarchy.
There are two ways in which the class structure represented within different roles
can be compared:
- Recoding the class structure in terms of categorical slots on the individuals represented within the role or boolean rating scales which represent whether or not an individual is a member of a class.
- Comparing the classes defined within the ontologies in terms of their instances. In the same way as the names of slots (terminology) and the values that they hold on individuals (attributes) can indicate consensus, conflict, correspondence or contrast between experts, so can the names of classes (terminology) and their instances (attributes). If, within two roles, there are two classes that are named the same and have the same instances as members, this indicates correspondence between the experts. If, within two roles, there are two classes that are not named the same, and yet have the same set of instances as members, this indicates correspondence between the experts. Similarly, if there are two classes that are named the same and have different sets of instances as members, this indicates conflict. Having no overlap in either terminology or the set of instances indicates contrast.
APECKS supports both these methods of comparing class hierarchies and supports the comparison of slots and slot values by converting roles to grids and using WebGrid-II in a similar manner to that described above in the section on using WebGrid for knowledge acquisition.
The result of these comparisons is a number of pages which indicate how roles compare to one another and prompt users to take actions to explore any differences between them. At present, until WebGrid or another similar system gives programmatic analysis of its comparisons, users are only given prompts concerning the class hierarchies in the compared roles. They may then change either the name or instances of a class in a role that they own, or write an annotation justifying the hierarchy they have chosen to use.
Figure 2 shows part of a page which details the differences in the class structure between two roles. Figure 3 shows the WebGrid-II comparison of two roles. Both these figures are from a comparison of two roles: one based on the Gold Standard constructed for the Sisyphus III experiment (the 'Gold Standard' role) and the other on the example on the same material used in Gaines & Shaw (1996a) (the 'WebGrid Example' role).
As can be seen in Figure 2, users are presented with a classification of the degree of similarity between the classes within the roles. The classification not shown here, 'conflict' occurs when classes in the compared roles share the same name but have different instances. When this occurs, users are shown a table displaying those instances which are in the class within each role individually and which are within both. Wherever classes fall within the classification, users are prompted to change its name or instances, or to start discussion about the differences if necessary. In the example above, clicking on the prompt "Create an annotation explaining why you have used the name `small grain'." allows the creator of the 'Gold Standard' role to start asynchronous unstructured communication about the naming of classes.
Figure 3 illustrates the result of an analysis of the correspondence between the same roles as carried out through WebGrid-II. It also effectively illustrates the problems involved in translating between the richer knowledge structure maintained by APECKS and the flatter one used by WebGrid. In order to use WebGrid, class membership and slots with multiple values are translated into boolean rating scales. The following rows within the grid are particularly illustrative of the issues involved:
- The first row of Figure 3 shows a correspondence between the class '
fine grain size' within the 'WebGrid Example' role and the class 'small grain' within the 'Gold Standard' role. This correspondence is also identified by APECKS, as shown in the page extract above (Figure 2).
- The eighth row of Figure 3 shows how different ways of representing the same information can be seen as corresponding to each other. Within the '
WebGrid Example' role, silica content is coded on a rating scale from 1 (high silica content) to 9 (low silica content) while within the 'Gold Standard' role, the corresponding information is represented as three exclusive subclasses, 'acid', 'intermediate' and 'basic'.
- The ninth and thirteenth row illustrate how users might choose different ways of encoding slots. Within the '
WebGrid Example' role, the colouring of rocks is coded on a rating scale from 1 ('light - leucocratic') to 9 ('dark - melanocratic') whereas within the 'Gold Standard' role, the corresponding slot is categorical, with the three possible values 'melancratic (dark)', 'mesocratic (medium)' and 'leucocratic (light)'.
- The tenth row illustrates how comparing roles in this way can indicate causal knowledge which may otherwise be missing. The presence of alkali feldspar, encoded within the '
Gold Standard' role is related to the colour of the rock, encoded within the 'WebGrid Example' role.
- Some of the correspondence between the two roles indicate the greater detail within the '
Gold Standard' role. For example, the second row might indicate that rocks with porphyritic texture are being classed under 'fine grain size' within the 'WebGrid Example' role.
- Many of the rows, such as the third through to seventh, however, give information that is not of much use for furthering understanding of the domain. These rows show correspondences which appear to be artefacts of both the way slots which take multiple values are translated into constructs for WebGrid and the technique used to compare them. Within the '
Gold Standard' role, the slot 'minerals present' lists the minerals present within the rock. For the purposes of comparison, the slot is translated into multiple boolean rating scale constructs indicating whether or not each individual mineral is present within the rock. This leads to constructs which hold the same value across all elements.
Since APECKS is designed to promote communication between users, it is particularly important that it supports a range of styles of collaboration. Communication between individuals can be classified as asynchronous or synchronous, where synchronous communication requires that the participants be copresent, at least temporally, and asynchronous communication does not. Communication can also be classified in terms of the extent to which a structure is imposed on the participants. In structured communication, such as that in The Coordinator (Winograd, 1988), the purpose of each utterance is specified by the participants and they are prompted to follow formats of communication usually based on Speech Act Theory. In The Coordinator, the system prompted its users to send certain types of emails to each other in response to the types sent to them. Structured communication in which a system does not act as an intermediary requires that the participants understand explicit or implicit rules governing their exchanges, such as in word games or wedding ceremonies.
Discussion within APECKS usually occurs as a result of a comparison between two roles: users are expected to argue the case for creating the ontology in the way they have. APECKS supports three of the four combinations of synchronicity and structure in archived communication (unstructured synchronous communication, unstructured asynchronous communication, and structured asynchronous communication) by associating objects with each other using annotations or criteria objects.
Using a MOO as the basis for APECKS means that there is already support for synchronous communication built into the system. Discussion between users in the same virtual room can be recorded within an annotation, and then automatically associated with the objects that were talked about. People who missed the discussion could then read and comment on the record of the discussion using unstructured asynchronous communication.
Unstructured asynchronous communication within APECKS is freeform annotation of objects. Each annotation object can be attached to many objects and each object (including annotation objects) can reference many annotations. Structured communication often limits the expressiveness of discussion and can be subverted by users to enable them to make their point, which detracts from its utility. Non-formal annotation enables the users of the system to explore their reasoning more fully and to bring together items that appear to be disparate to the system but that can be seen to be similar to human intelligence. This full discussion might then lead on to the construction of the criteria used in structured asynchronous communication.
Structure in asynchronous communication is useful in three ways:
- it can be prompted by the system
- it means that common communication actions can be simplified
- it provides a structure for argumentation
The process of developing a collaborative ontology can be seen as the design of an artefact that is an ontology, and therefore any of the design rationale methodologies can be put into effect for documenting the argumentation behind it. For the purposes of the argumentation in APECKS, the QOC (questions, options & criteria) methodology is used (MacClean, et al., 1991). Within QOC, a number of design questions are formed, each of which may prompt the proposal of many options which are judged against a set of criteria. QOC differs from other argumentation systems since it makes explicit the general overarching criteria against which design options should be judged.
Within APECKS, the overall design question is 'How should the domain be represented?'. Each role created by an expert can be seen as an option in answer to that question. Sub-questions relate to the structure of the ontologies that are created, such as 'Which individuals belong to this class?', 'What are the slots on this class?' and 'What is the value for this slot on this individual?'. The questions and the options that are created are thus implicit within APECKS. The criteria used to create the options are also implicit to each user unless they choose to make them explicit in order to justify the way they have structured one of their roles. APECKS allows the users to generate a set of criteria, each of which can operate across any number of roles. Each role likewise can define explicitly a number of criteria under which it was created.
Where the specification of criteria is not enough to explain the reasoning behind design decisions, unstructured asynchronous communication can be used to annotate the compared roles, but users are encouraged to create criteria wherever possible as these represent reusable reasoning.
This paper has illustrated what we see as some of the problems facing ontology servers at present. We feel that support for more structured communication between the builders of ontologies will allow deeper discussion of a domain, leading to both a richer ontology and a design rationale which can be reviewed and used to inform the construction of future ontologies. The APECKS system provides this facility and future evaluation studies of its use will show whether it lives up to its promise.
APECKS is designed to be useful to two overlapping but distinct groups of people:
- Knowledge Engineers
- APECKS offers the same benefits of other ontology browsers to knowledge engineers (albeit in a more limited manner) - that of creating, browsing and storing ontologies in a network-accessible manner. On top of this, knowledge engineers can use APECKS to compare and discuss ontologies that they have constructed and to identify the implicit criteria they use in their construction, leading to more specific methodologies.
- Domain Experts
- APECKS offers a knowledge-oriented way of structuring and recording communication about a domain, with support for knowledge acquisition techniques. This has utility in organisational memory, design rationale, teaching and other tasks involving the recording of opinion.
The future work on APECKS will focus necessarily on its evaluation. However, there are a number of areas into which APECKS, or ontology servers of its kind, may be developed in future.
- The further integration of networked ontology servers, knowledge acquisition tools and discussion tools. APECKS already utilises WebGrid-II in this way and its use of a Frame Representation Schema means that ontologies from other ontology servers, for example, could in future be imported as separate roles to be compared programmatically with both each other and roles created directly by domain experts and knowledge engineers.
- The development of methods of presenting ontologies directly to domain experts so that they can understand them without background in knowledge engineering. Particularly interesting to us is the use of virtual reality in creating representations of ontologies that either reflect the domain directly (such as representing an individual '
car' as a virtual car) or metaphorically (such as representing hierarchies as trees).
- The development of techniques in comparing the entire, complex, structure of ontologies rather than simply the grid of slot values, and generating consensual ontologies from these comparisons.
- An automated approach to generating consensual ontologies. In much the same way as individual knowledge bases are integrated into group knowledge bases within Co4, individual roles could be automatically combined on the basis of those objects which are consensual across roles. At the moment, any building of a consensual or group ontology within APECKS has to be done by hand by one individual or using a group-owned role which somewhat defeats the purpose of using roles.
- The development of design rationale methodologies and structures that support the types of communication carried out by developers of ontologies. The speech acts that are used by designers of other systems are not necessarily the same for ontology developers. Reflecting these structures in annotations should enhance communication by users of the system.
We believe that the wide scale adoption of ontologies will necessitate the type of functionality embodied in APECKS. Alongside the technology we will also need to understand the collaborative process of ontology construction and refinement.
This research was carried out as part of Jenifer Tennison's PhD, which is supported by the University of Nottingham. Our thanks are also due to Brian Gaines in allowing us to use WebGrid-II, and for his help and advice concerning its use.
Bellotti, V. (1993) Integrating Theoreticians' and Practitioners' Perspectives with Design Rationale. In Proceedings of the 1993 Conference on Human Factors in Computing Systems, INTERACT'93 and CHI'93. Amsterdam, The Netherlands, 24-29 April, 1993.
Bellotti, V., MacClean, A. & Moran, T. (1991) Generating Good Design Questions. Technical Report EPC-91-136. Rank Xerox Research Group, Cambridge, UK.
Boy, G. (1996) The Group Elicitation Method: An Introduction. In Proceedings of the 9th European Knowledge Acquisition Workshop (EKAW'96). Nottingham, UK, May14-17, 1996.
Buckingham Shum, S. (1993) QOC Design Rationale Retrieval: A Cognitive Task Analysis, & Design Implications. Technical Report EPC-93-105. Rank Xerox Research Group, Cambridge, UK.
Chen, L.L-J. (1996) Chronological Awareness Tools: CHRONO and Meta-CHRONO. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/chen/kawchrono.html.
Chen, L.L-J. & Gaines, B.R. (1996) Knowledge Acquisition Processes in Internet Communities. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/chen/ka-chen-gaines.html.
Conklin, E.J. & Begeman, M.L. (1988) gIBIS: A Hypertext Tool for Exploratory Policy Discussion. ACM Transactions on Office Information Systems,6(4), 303-331. Also in Proceedings of the Conference on Computer-Supported Cooperative Work (CSCW'88). ACM Press.
Conklin, E.J. & Yakemovic, KC.B. (1991) A Process-Oriented Approach to Design Rationale. Human-Computer Interaction, 6, 357-391.
Curtis, P. (1992) Mudding: Social Phenomena in Text-based Virtual Realities. In Proceedings of the 1992 Conference on the Directions and Implications of Advanced Computing, Berkeley. Also available as Xerox PARC technical report CSL-92-4. URL ftp://ftp.parc.xerox.com/pub/MOO/papers/DIAC92.ps.
Domingue, J. (1998) Tadzebao and WebOnto: Discussing, Browsing and Editing Ontologies on the Web. In Proceedings of the 11th Workshop on Knowledge Acquisition, Modeling and Management (KAW'98). Banff, Canada, April 18-23rd, 1998.
Euzenat, J. (1996a) HyTropes: a WWW front-end to an object knowledge management system. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/euzenat/euzenat96c.html.
Euzenat, J. (1996b) Corporate memory through cooperative creation of knowledge bases and hyper-documents. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/euzenat/euzenat96b.html.
Farquhar, A., Fikes, R., Pratt, W. & Rice, J. (1995) Collaborative Ontology Construction for Information Integration. Research report 63, Knowledge System Laboratory, Stanford University, Stanford, CA, US. URL ftp://ksl.stanford.edu/pub/KSL_Reports/KSL-95-63.ps.
Farquhar, A., Fikes, R. & Rice, J. (1996) The Ontolingua Server: a Tool for Collaborative Ontology Construction. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/farquhar/farquhar.html.
Fischer, G., Lemke, A.C., McCall, R. & Morch, A.I. (1991) Making Argumentation Serve Design. Human-Computer Interaction, 6, 393-419.
Fischer, G., Grudin, J., Lemke, A., McCall, R., Ostwald, J., Reeves, B. & Shipman, F. (1992) Supporting Indirect Collaborative Design With Integrated Knowledge-Based Design Environments. Human-Computer Interaction, 7, 281-314.
Gaines, B.R. & Shaw, M.L.G. (1996a) A Networked, Open Architecture Knowledge Management System. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/gaines/KM.html.
Gaines, B.R. & Shaw, M.L.G. (1996b) WebGrid: Knowledge Modeling and Inference through the World Wide Web. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/gaines/KMD.html.
Gaines, B.R. & Shaw, M.L.G. (1998) Developing for Web Integration in Sisyphus-IV: WebGrid-II Experience. In Proceedings of the 11th Workshop on Knowledge Acquisition, Modeling and Management (KAW'98). Banff, Canada, April 18-23rd, 1998.
Gruber, T.R., Tenenbaum, J.M. & Weber, J.C. (1992) Toward a Knowledge Medium for Collaborative Product Development. In J.S. Gero (ed.) Artificial Intelligence in Design '92. Proceedings of the Second International Conference in Design. Pittsburgh, USA, June 22-25, 1992. pp. 413-432. Kluwer Academic Publishers. URL ftp://ksl.stanford.edu/pub/knowledge-sharing/papers/shade.ps.
Karp, P.D., Myers, K.L. & Gruber, T. (1995) The Generic Frame Protocol. In Proceedings of the 1995 International Joint Conference on Artificial Intelligence (IJCAI'95), pp. 768-774. URL http://www.ai.sri.com/pubs/papers/Karp96-768:Generic/document.ps.Z.
Karp, P.D. & Gruber, T. (1997) The Generic Frame Protocol [WWW document]. URL http://www.ai.sri.com/~gfp/spec/paper/paper.html.
Lee, J. & Lai, K-Y. (1991) What's in Design Rationale? Human-Computer Interaction, 6, 251-280.
MacClean, A., Young, R.M., Bellotti, V.M.E. & Moran, T.P. (1991) Questions, Options, and Criteria: Elements of Design Space Analysis. Human-Computer Interaction, 6, 201-250.
McGuire, J.G., Kuokka, D.R., Weber, J.C., Tenenbaum, J.M., Gruber, T.R. & Olsen, G.R. (1993) SHADE: Technology for Knowledge-Based Collaborative Engineering. Journal of Concurrent Engineering: Applications and Research (CERA), 1(2)
Rice, J., Farquhar, A., Piernot, P. & Gruber, T. (1996) Using the Web Instead of a Window System. In Proceedings of Computer-Human Interaction '96 (CHI'96), pp. 103 - 110. Vancouver, BC, Canada, April 13-18, 1996. URL http://www-ksi-svc.stanford.edu:5915/doc/papers/ksi-95-69/ksi-95-69-linearised.html.
Rittel, H. & Kunz, W. (1970) Issues as elements of information systems. Working paper #131. Institut fur Grundlagen der Planung I.A. University of Stuttgart.
Shaw, M.L.G. & Gaines, B.R. (1989) Comparing conceptual structures: consensus, conflict, correspondence and contrast. Knowledge Acquisition, 1, 341-363.
Shaw, M.L.G. & Gaines, B.R. (1998) WebGrid II: Developing Hierarchical Knowledge Structures from Flat Grids. In Proceedings of the 11th Workshop on Knowledge Acquisition, Modeling and Management (KAW'98). Banff, Canada, April 18-23rd 1998.
Swartout, B., Patil, R., Knight, K. & Russ, T. (1996) Toward Distributed Use of Large-Scale Ontologies. In Proceedings of the 10th Knowledge Acquisition Workshop (KAW'96). Banff, Canada, Nov. 9-14, 1996. URL http://ksi.cpsc.ucalgary.ca/KAW/KAW96/swartout/Banff_96_final_2.html.
van Heijst, G., Schreiber, A.T. & Wielinga, B.J. (1997) Using explicit ontologies in KBS development. International Journal of Human-Computer Studies, 45, 183-292.
Winograd, T. (1988) A Language/Action Perspective on the Design of Cooperative Work. Human-Computer Interaction, 3, 3-30.