Complexity is a measure of the resources which must be expanded in
developing, maintaining, or using a software product.
A large share of the resources are used to find errors, debug, and retest;
thus, an associated measure of complexity is the number of software errors.
Items to consider under resources are:
- time and memory space;
- man-hours to supervise, comprehend, design, code, test, maintain and
change software; number of interfaces;
- scope of support software, e.g. assemblers, interpreters, compilers,
operating systems, maintenance program editors, debuggers, and other utilities;
- the amount of reused code modules;
- travel expenses;
- secretarial and technical publications support;
- overheads relating to support of personnel and system
hardware.
Consideration of storage, complexity, and processing time may or
may not be considered in the conceptualization stage. For example, storage of
a large database might be considered, whereas if one already existed, it could
be left until system-specification.
Measures of complexity are useful to:
- Rank competitive designs and give a "distance" between rankings.
- Rank difficulty of various modules in order to assign personnel.
- Judge whether subdivision of a module is necessary.
- Measure progress and quality during development.
Complexity theory does not yet allow us to measure the separate aspects, e.g.
problem, algorithm, design, language, functions, modules and combine them to
measure and compare overall complexity. Most complexity measures concentrate
on the program. Instruction counts are used to predict man-hours and
development costs. A high level language may have between 4:1 and 10:1 ratio
to machine language.
Statistical approach, used by Halstead, looked at total number of operators and
operands, and related this to man-hours. This measure was rooted in
information theory -- Zipf's laws of natural languages, Shannon's information
theory.
Zipf studied the relationship between frequency of occurrence nr and rank r
for words from English, Chinese and Latin, and found that
n(r) /n . r = constant (c)
or n(r) = c n / r
n is sample size
Consideration of the length and difficulty of individual program statements
does not account for the interrelationships among instructions, i.e. structural
intricacy. Recent work on structural complexity relates to graph topological
measures. Graph theory is not able to represent storage, or operands. It
concentrates on transfer of control.
Similar to set theory: collection X, mapping M
e.g. X-set elements, M-set mapping rules
- Positions of pieces on a chess board
- Rules for moving and capturing pieces
- A group of relatives
- Units of electrical appratus
- Wires connecting the units
- Instructions in a computer program
- Rules of syntax a sequence which govern the processing of the
instructions
Each element belonging to X is represented by a point
called a vertex or node. Mapping rules define connections between the
vertices. If there is an order in the connection, or arc then it is a directed
graph or digraph. If there is no order the connecting line is an edge.
A directed graph and a "regular" graph
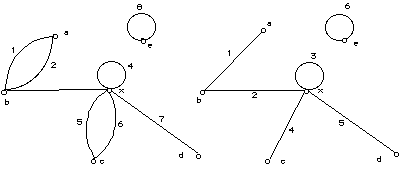
- Two arcs are adjacent if they are distinct and have a vertex
in common.
- Two vertices are adjacent if they are distinct and there
exists an arc between them.
- A path is a sequence of arcs of a graph such that the terminal
vertex of each arc conicides with the initial vertex of the succeeding arc.
- A path is simple if it does not use the same arc twice, and
composite otherwise.
e.g. 1, 3, 7 or a, b, x, d is a simple path 1, 3, 4, 4,
7 or a, b, x, x, d is composite
- A path is elementary if it does not meet the same vertex more than
once.
e.g. simple: (1, 3, 7), (1, 3, 4, 7), (1, 3, 6, 5, 7) elementary: (1,
3, 7) only
- A circuit is a finite path where the initial and terminal nodes
coincide.
- An elementary circuit is a circuit in which no vertex is traversed
more than once.
- A simple circuit is a circuit in which no arc is used more than
once.
- The length of a path is the number of arcs in the sequence.
- The length of a circuit is the length of its path.
- A digraph is complete if every distinct node pair is connected in
at least one direction, e.g. node e is not connected, so graph is not complete.
- A digraph is strongly connected if there is a path joining every
pair of vertices in the digraph, e.g. not strongly connected as can not go d to
c.
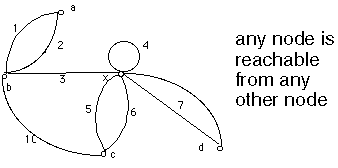
In linear algebra, a set of vectors x(1), x(2), ..., x(n) is linearly
dependent if there exists a set of numbers not all zero s.t. a(1)x(1) +
a(2)x(2) + ... + a(n)x(n ) = 0. If no such set of numbers exists then the set
of vectors are linearly independent.
Any system of n linearly independent vectors e(1), e(2), ..., e(n) forms a
basis in n-dimensional vector space.
In graph theory, if the concept of a vector is associated with each circuit or
cycle, then there are analogous concepts of independent cycles and a cycle
basis.
The cyclomatic number v(G) of graph G is equal to the maximum number of
linearly independent cycles. The cyclomatic number v(G) of a strongly
connected digraph is equal to the maximum number of linearly independent
circuits. v(G) = m - n + p
where there are m arcs
n vertices
and p separate components
e.g. m=9, n=5, p=1, v(G)=5
There are various other methods for calculating the cyclomatic number of a
graph.
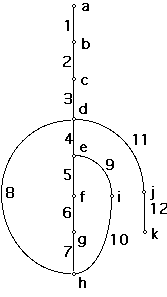
A program graph is obtained from shrinking each process and decision symbol in
a flowchart to a point (vertex) and lines joining them (arcs). Direction in a
program is important, hence a directed graph (digraph) is obtained.
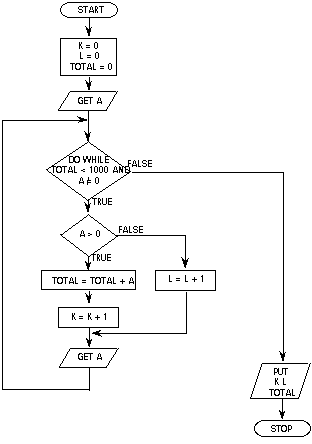
e.g. digraph of program flowchart given:
nodes a and k correspond to start and stop nodes
node c corresponds to GET A
node i corresponds to L = L + 1
The cycle (loop) is composed of arcs 4, 5, 6, 7, 8
IF THEN ELSE appears as 5, 6 and 9, 10.
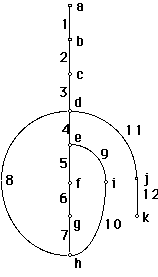
The cyclomatic number of the digraph gives a complexity
metric. Comparisons show that a high cyclomatic complexity is associated
with error-prone programs.
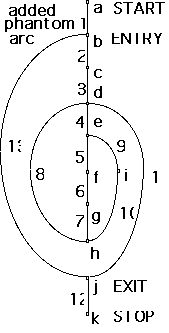
A graph is constructed with a single start node and a single stop node. If
there is an unreachable node, that represents unreachable code or coding error
which must be corrected.
In general the graph is not strongly connected, so form a loop round the entire
program (phantom arc).
e.g. v(G)= 13 - 11 + 1 = 3
number of arcs m = 13
number of nodes (vertices) n = 11
separate parts p = 1
Results
McCabe says that v(G) is a good measure of complexity and all modules
should have v(G)<10. This replaces the general rule of thumb that a
module should be one page of code (50 to 60 lines). He has shown that programs
with a large v(G) are error-prone.
Much theory exists in this area, but as yet has not been applied on a wide
scale.
Practical
Software Engineering,
Department
of Computer Science
mildred@cpsc.ucalgary.ca 12-Jan-96