Constructing Planners Through Problem-Solving Methods
V. Richard Benjamins1
- Leliane Nunes de Barros2 -
André Valente3
1University of Amsterdam, Social
Science Informatics (SWI), Roetersstraat 15, NL-1018 WB Amsterdam,
The Netherlands, richard@swi.psy.uva.nl
2University of Maryland, Department of
Computer Science, College Park, MD 20742, USA, leliane@cs.umd.ed
3University of Southern California,
Information Sciences Institute, 4676 Admiralty Way, Marina del
Rey, CA 90292, USA, valente@isi.edu
Abstract:
Constructing a planner for a particular application is a difficult
job, for which little concrete support is currently available. The
literature on planning is overwhelming and there is no clear
synthesis of the various planning methods which could be used by
knowledge engineers. In this paper, we show how a general,
knowledge-level framework for conceptually specifying
knowledge-based systems, can be of concrete use to support knowledge
acquisition for planning systems. The framework encompasses three
interrelated components: (1) problem-solving methods, (2) their
assumptions and (3) domain knowledge. The presented analysis of
planning performed in the framework can be considered as a library
with reusable components, based on which planners can be configured.
Two experiments are presented that illustrate the use of the library
in knowledge engineering.
When engineering a planning application, a serious knowledge engineer
would believe it is wise to search the literature on planning looking
for a method that is adequate for the problem at hand. He/she would,
however, probably be overwhelmed by the enormous amount of literature
and the almost total absence of a clear synthesis of the available
methods and their applicability. Most of the methods are described in
terms of search, which offers little help in understanding the
applicability of the method to a certain domain. The few analyses of
the existing methods have concentrated on characteristics such as
efficiency, soundness and completeness, and expressiveness --- which,
again, do not help to construct an application. Clearly,
something is necessary to ``make sense'' of the methods available and
help in the knowledge engineering and acquisition process. A first
and essential step towards developing tools to automate knowledge
acquisition for planners is to have a model of what existing planning
methods do and how they work [Kingston et al., 1996].
In this paper, we present a knowledge-level framework for representing
and analyzing planning methods that can help knowledge engineers in
constructing planning applications. The result of the analysis can be
viewed as a library of problem-solving methods for planning, and
as such we will use our analysis for knowledge acquisition and
engineering. The library specifies reusable components to configure
problem solvers rather than to build them from scratch. These
components are represented, based on the knowledge-level framework of
the CommonKADS methodology [Schreiber et al., 1994]. The library is based
on three interconnected groups of building blocks. The first group of
components is used to specify how domain knowledge is structured by
the methods, the second is used to specify how the methods actually
solve a planning problem, and the third is used for connecting these
internally and to an application domain. The components are:
- A set of typical knowledge roles used in planning methods.
These roles characterize the main types of domain knowledge used in
planning methods. They also help in understanding the way knowledge
is structured by providing an index to the domain models used
to play these roles.
- A set of basic methods used in composing a planning
reasoning strategy. A task-method decomposition structure
indexes the basic methods by defining in what ways a planning task
can be decomposed, and what decomposition results from applying the
basic methods to those tasks. Specifically, the library proposes a
characterization of planning methods in general, as distinct
realizations of a basic decomposition of the planning task into
three tasks: propose, critique and modify.
- A set of features (or assumptions) of
problem-solving methods is used to specify the connection between
these two groups by defining when a method is applicable to a domain
or a problem.
Earlier versions of (parts of) the library presented in this paper
were discussed in [de Barros et al., 1996,Valente, 1995]. In
[Valente, 1995], we discussed in detail the knowledge roles and
domain models. In [de Barros et al., 1996] we concentrated on the basic
methods and the task-method decomposition structure. In this paper, we
focus on the knowledge acquisition benefits of the library, by
concentrating on the third group of components, namely the
assumptions. We also extend the library in order to cover a broader
class of planning problems.
The aim of this paper is to show how the proposed library can help to
construct planners for particular application domains by providing a
high-level, abstract synthesis of the available planning methods.
Specifically, we will concentrate on an analysis of the so-called
assumptions of problem-solving methods as the basic connection
between reasoning and domain knowledge. We will show how these
features can be used both to (i) characterize a method and find out to
which domains it is applicable, and (ii) characterize a domain and
find out which methods are adequate to be used. In order to partially
automate this process, we stored the problem-solving components in a
tool called TINA ( Tool in Acquisition).
Currently, the library concentrates on so-called classical
planners, which implies that it inherits their limitations and
behavioral assumptions. For example, it assumes there is a single agent;
changes in the world can only be caused by the agent; actions do not
take time to be performed; etc. The library can, however, naturally
be extended to comprise other types of planners (e.g., case-based,
planners that use uncertainty) as well as methods for other types of
planning problem (e.g., plan execution, plan recognition).
This paper is structured as follows. In Section 2, we
briefly describe the CommonKADS framework. Section 3
summarizes the domain part of the library, namely the knowledge roles
and domain models. Section 4 describes the task part of the
library, namely the task-method decomposition tree and the basic
methods used to compose it. In Section 5, we describe how our
library can support the knowledge acquisition process. Two kinds of
support are demonstrated: (1) given a description of domain
characteristics, to find what possible planners are adequate for the
domain, and (2) given a planner, define its assumptions (domain
requirements). At the end of the section, we discuss the merits and
limitations of the approach followed, and, in
Section 6, we present conclusions.
CommonKADS is a methodology for developing knowledge-based systems.
The components used to represent problem-solving knowledge include the
following:
Tasks are represented using a functional perspective, i.e.,
specified by a set of input/output relations which is called a
function. A function includes a goal, i.e., a specification
of what needs to be achieved. For example, the goal of a
planning task is to come up with an ordered sequence of operations
that transforms a given initial state into a goal state. We represent
the input and output by roles that knowledge plays in the
problem-solving process. For instance, in diagnosis, an input or
output role like hypothesis means that some domain structure or
element plays the role of hypothesis. Static roles are roles
whose contents do not change during problem solving (they correspond
roughly to a knowledge base in a knowledge-based system); dynamic
roles are roles whose contents change.
Problem-solving methods (PSMs) describe how the goal
of a task can be achieved. A method has input and output roles, and
either decomposes a task into subtasks (composite method) or is
primitive. Tasks and PSMs can be organized in a task-method
decomposition structure, where a task may be realized by alternative
methods, each of which consists of subtasks or is primitive.
Figure 2 presents such a diagram for planning. A
primitive method can usually be implemented by a general or weak
method (e.g., constraint propagation). A composite method specifies
the allowed data flow (in terms of their roles) between the subtasks,
and the control knowledge over them. Control knowledge is represented
by a control structure, which determines the execution order and
iteration of the subtasks. This paper does not elaborate on control
knowledge.
Assumptions are important constructs to make explicit the
interaction between a PSM and the domain knowledge, as
demonstrated by recent work [Benjamins & Pierret-Golbreich, 1996,Benjamins et al., 1996]. In the
context of this paper, we will use assumptions to specify the
requirements of a PSM on domain knowledge, which corresponds to
the ontological assumptions of [Benjamins et al., 1996] and the
epistemological assumptions of [Benjamins & Pierret-Golbreich, 1996].
Epistemological assumptions are further divided into
availability assumptions, which refer to the availability of domain
knowledge, such as the availability of a causal model in diagnosis;
and property assumptions, which refer to properties of the
domain knowledge, for instance, that a causal model is non-cyclic.
assumptions of [Benjamins & Pierret-Golbreich, 1996].
Epistemological assumptions are further divided into
availability assumptions, which refer to the availability of domain
knowledge, such as the availability of a causal model in diagnosis;
and property assumptions, which refer to properties of the
domain knowledge, for instance, that a causal model is non-cyclic.
Domain ontologies provide a vocabulary that can be used to
describe a certain domain. An ontology specifies the concepts,
relations, etc. independently from the specific system that is
reasoned about. Examples of domain ontologies in planning domains are
the formalisms used to represent the world, time and actions (e.g., the
situation calculus or the event calculus). We will not deal further
with domain ontologies in this paper. Domain models are
structures to be used in problem-solving methods, built using elements
of the domain ontology. Typical examples are models that specify
causal dependencies between symptoms and diseases in medical domains
(causal models), or models that specify structural hierarchies for
physical devices (structural models).
One of the critical elements in the analysis of a planning method is
to specify which types of knowledge it employs --- in other words,
which roles knowledge can play. In this section, we will present
(i) a set of four general dynamic roles in planning tasks, and (ii) a
part-of organization of static roles, originally defined in
[Valente, 1995]. These two sets give a high-level view of the
types of knowledge used in planning, both in the sense of the
knowledge that is input or output to the task, and in the sense of the
knowledge that used as part of the knowledge base.
The basic problem solved in planning tasks is to generate a sequence
of actions (a plan) whose execution accomplishes a given goal. A
planning problem is characterized by two inputs: an initial state and
a goal description of the world. We distinguish the following dynamic
roles in planning PSMs:
The role current state is initially
filled by a description of the world in the initial state, and later
it is modified to contain intermediary states in the plan.
The role goal describes the changes
to the world that must be accomplished by the plan. The content of
goal can be a set of conditions or a set of actions to be
accomplished. Initially this role points to the original problem goal.
During the planning process the content of the role is dynamically
modified by establishing new subgoals and deleting achieved goals.
The dynamic knowledge role plan is a
composite role whose content is constantly modified during the
planning process until a solution is found. It consists of the
following:
- Plan-steps which are the steps in the plan that correspond
to actions in the domain.
- Ordering constraints over the plan-steps, such as that one
action precedes another. The type of order imposed on the plan-steps
in the plan (e.g., partial or total) depends on the static role
plan structure (which will be described later) employed by the
planner.
- Variable bindings constraints which keep track of how
variables of plan-steps are instantiated with domain knowledge such
as objects, resources and agents.
- Auxiliary constraints that represent temporal and truth
constraints between plan-steps and conditions. Auxiliary
constraints are present in the plan only as support knowledge for
the planning process. When a solution plan is found, they are no
longer useful, unless the plan is to be reused. An example of an
auxiliary constraint is a causal link, which is defined by (i)
a condition in the plan that has to be true (e.g., a goal
condition), (ii) a plan-step that needs this condition to be true,
and (iii) another plan-step that makes this condition true. Another
example of an auxiliary constraint is point truth
constraint, which requires that some condition be true before a
certain plan-step can occur [Kambhampati, 1994].
The role conflict contains the result of
checking the plan for inconsistencies with respect to its conditions.
Whenever a condition is unexpectedly false, a conflict is detected.
The conflict role can point directly to a plan-step that
violates some interval of the truth value of a condition, or just
point to a set of inconsistent constraints (like in UMCP
[Erol et al., 1994]).
Figure 1 shows a part-of organization of static roles
[Valente, 1995]. The fact that this is a part-of tree means that
every planning method must use as a static role either the root or
one of the logical ANDs of its constituting decompositions.
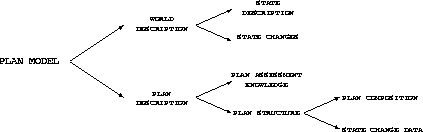
Figure 1: Part-of tree of static roles in planning.
The plan model role defines what a plan is and what it is made
of. It consists of two parts: the world description and the
plan description. Below is a brief description of these roles and
their sub-roles.
The world description role describes the world about which we
are planning and comprises two sub-roles: state description and
state changes. The state description contains the
knowledge necessary to represent or describe the state of the world.
Examples of domain models to play this role in planning systems are a
set of first-order predicates (STRIPS-like) or a set of fluents
from the Situation Calculus [McCarthy & Hayes, 1969]. The state
changes role comprehends all the information connected to the
specification of changes in the state of the world. This is also the
specification of the elements a plan is composed of (but not how
they are composed, see plan composition below). Examples of
domain models to play this role in planning systems are: the
add-delete lists (ADL) used in STRIPS [Fikes & Nilsson, 1971]; or
the hierarchical task networks (HTNs) [Tate, 1977,Erol et al., 1994]
which are, in fact, descriptions of sub-plans; or skeletal plans
[Friedland & Iwasaki, 1985] which are abstract descriptions of previously
generated plans. In case of HTNs, the sub-plans may come fully
or partially specified. Fully specified means that the sub-plans
contain all the auxiliary constraints necessary for continuing the
planning process (e.g., ordering constraints or truth constraints such
as causal-links). Partially specified means that the sub-plans come
with a correct and useful task decomposition but not with all the
needed causal-links (for a real world planning application).
The plan description role describes the structure and features
of the plan being generated and comprises two sub-roles: plan
structure and the (optional) plan assessment knowledge:
(1) Plan structure This role specifies how the parts of a plan
(actions, sub-plans) are assembled together. It also specifies
(indirectly) how the plan is to be executed. There are several
varieties in the structure of plans that can be identified in the
literature. They can be described by two main knowledge roles: the
plan composition role contains the description of the plan with
respect to how the state changes are arranged in order to make up a
plan. This includes, for instance, whether the plan will be a partial
or a total ordering of a set of state changes, or whether it includes
iteration or conditional operators. The composition may also be
hierarchical: plans are composed of sub-plans, and so on up to
atomic plans, which are normally state changes. The state
change data role contains the plan information besides the
structure of state changes. For example, important state change data
are interval constraints for binding the variables involved in the
state changes. It is also possible to assign different
resources to each state change or sub-plan. Two particularly
important resources are agents and time.
(2) Plan Assessment Knowledge determines whether a certain plan
(or sub-plan) is valid (hard assessment knowledge), or whether a plan
is better than another (soft). Based on this knowledge, a plan can be
modified or criticized. An example of hard plan assessment
knowledge is the truth-criterion, which is used to find out
if a condition is true at some point in the plan. TWEAK
[Chapman, 1987] uses a modal truth criterion (MTC) which
defines when a particular condition in a plan is necessarily or
possibly true by formally stating all possible interaction problems.
Another example of a domain model for hard plan assessment
knowledge is causal-link knowledge used in SNLP
[McAllester & Rosenblitt, 1991]. Knowledge for testing the consistency of the
auxiliary constraints is also an example of hard plan assessment
knowledge. An example of soft knowledge would be that plans with
smaller number of plan-steps are preferred. This paper only deals with
hard assessment knowledge. Assessment knowledge can also be
domain-specific, in which case it can be used to criticize the plan
more efficiently.
Based on an analysis of many classical planning systems, we have
identified relevant tasks and problem-solving methods. They can be
organized into a task-method decomposition structure
[Orsvärn, 1996] (see Figure 2), where a method
consists of (solid lines) subtasks and a (sub)task can be realized by
alternative (dashed lines) methods. Ellipses represent tasks and
rectangles methods.
We claim that the class of planners we are dealing with share a
general, high-level problem-solving method which we call
propose-critique-modify (PCM). That is, all planners contain in one way or another these
three basic tasks: (i) propose refinement, (ii) critique
plan and (iii) modify plan. Planners differ in how they
achieve each of these steps; that is, in what PSMs they use to
perform these three tasks. These differences also reflect their
choices in terms of how planning knowledge is represented.
Figure 2 shows a set of PSMs we have found in the
literature to realize these tasks.
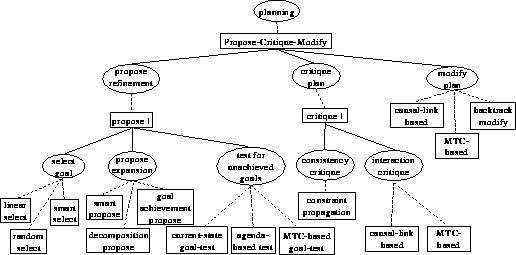
Figure 2: A task-method decomposition structure for planning.
Actually, the PCM method represents a whole family of methods,
in the sense that sometimes not all of its subtasks need to be carried
out. For example, the PCM family includes methods that only do
propose, or propose and modify. The tasks presented in
Figure 2 are described below.
This task has the goal of adding new
steps or constraints to the plan. The input knowledge roles for this
task are: world description, plan structure and plan
assessment knowledge. To realize this task, we found a method
called propose I, which can be decomposed into three sub-tasks:
select goal, propose expansion and test for unachieved goals.
Select goal This task selects a goal from the set of goals to be
accomplished. The goal can be either a goal state to be achieved or a
goal action to be accomplished by a number of actions. For select
goal, three methods can be used: linear select, random
select and smart select. STRIPS chronologically selects
the last goal state established by its search strategy, which we call
linear select. NONLIN [Tate, 1977] randomly selects any
goal that has not yet been accomplished. SNLP
[McAllester & Rosenblitt, 1991] randomly selects goals from the set of pending
goals. It is also possible to select a goal in a more intelligent
manner which minimizes possible future modifications ( smart
select) [Drummond & Currie, 1989]. In this case, the method uses the
static role plan assessment knowledge to select a goal. An
example of smart select was proposed by [Kambhampati, 1995], where
a goal-selection strategy is described called MTC-based goal selection, which
selects a goal state only when it is not necessarily true according to
the modal truth criterion.
Propose expansion This task takes the selected goal, and
proposes a way to accomplish it using state changes. This can
be a new plan step, or an action decomposition which will be added to
the plan at the place of the goal action. The propose expansion task
can be realized by three alternative methods. Decomposition
propose proposes a goal decomposition, which means to propose a
more detailed way to accomplish the goal. This method is only applied
if the goal is a goal action. Goal-achievement propose, selects
an operator whose effect includes the selected goal, constraining the
place of the operator in the plan to be necessarily before the
selected goal. When a new operator is added to the plan, its
preconditions are added to the set of goals. When there is already a
step in the plan that achieves the goal, only the ordering constraint
is added to the plan. This method is used by SNLP and REFINEMENT SEARCH [Kambhampati, 1995] planning algorithms. The
smart propose method is applied by STRIPS and PRODIGY [Carbonell & the PRODIGY Research Group, 1992] which are implemented by means-end
analysis [Newell & Simon, 1963], and exploits the difference between the
goal state and the current state to select an operator. Within each
of the three methods, there are still different ways to propose an
expansion, depending on the backtrack points left (e.g., on the
decomposition choice, on the operator, or on variable bindings). In
the case of adding a step, the different insertion points in the plan
can be considered as another backtrack point (e.g., TOCL
[Barret & Weld, 1994]).
Test for unachieved goals This task checks the current plan for
unachieved goals, and records them in the dynamic role goal. It
also tests whether the preconditions (sub-goals) of an operator are
already achieved in the current state (when the plan composition is
total-order). We identified three methods to realize this task: the
MTC-based goal-test, the current-state goal-test and
the agenda-based goal test. Planners that exploit causal-links
use the simple agenda-based method, because they only need to check
for the existence of goals not yet processed; goals, once achieved,
are preserved through the causal links.
The critique plan task checks for
conflicts and the quality of the plan generated so far, using plan
assessment knowledge. The role plan assessment knowledge can
point to `hard' constraints (interaction and the satisfiability of the
plan constraints) and `soft' constraints (the factors that define when
a given plan is better than another. We identified one method to
realize this task which we called critique I. This method
consists of two subtasks: consistency critique and interaction
critique.
Interaction critique When checking for conflicts, this task
verifies whether the proposed action for accomplishing the goal would
interact with other goals in the plan (e.g., one action might undo the
precondition of another action). Note that this task involves explicit
reasoning about interactions. For realizing the interaction critique
task, we identified two methods: (i) the causal-link-based
critique, which checks if the proposed plan-step threats any
existent causal link; (ii) and the MTC-based critique,
which uses the modal truth criterion to check the existence of a step
that possibly deletes any achieved goal.
Consistency critique This task checks the consistency of the
overall constraints on the plan generated so far. This task differs
from the interaction critique in the sense that it can find more
general conflicts between the constraints than the deleted-condition
conflict. More complex planning systems can also check the consistency
of the assigned resources and agents. We identified the
constraint propagation method to realize this task.
The modify plan task is responsible for
modifying the plan with respect to the results of the critique plan
task (a conflict). By using plan assessment knowledge, a modification
can be done by adding ordering, binding or secondary preconditions to
the plan until the possible conflict (violation) is solved or avoided.
We identified three methods to realize this task: the
causal-link-based and the MTC-based method for
partial-ordered plans, and the backtrack
modification method for
total-order plans. The causal-link-based method adds causal
links to the plan which prevent the conditions contained in
conflict from being undone. The MTC-based method adds
constraints to the plan in such a way that the conditions in
conflict are necessarily true.
The backtrack method modifies a plan by backtracking upon
failure. Backtracking is possible if there are alternative decision
points. It is important to note that a planner can have different
possible points to backtrack on, such as the selected goal, the
proposed expansion, or the variable bindings.
In the previous section, we have presented a knowledge-level analysis
of planning problem-solving methods and we mentioned how their static
roles are filled by different kinds of domain knowledge. We can
consider the result of the analysis as a library with reusable
components, that encompasses the planners based on which it is
developed as well as new planners. As pointed out in the
introduction, we aim primarily at supporting knowledge engineers
in their task to develop knowledge-based systems. Thus, we take an
intermediate position between planning experts and domain experts. One
should bear in mind that this has consequences for the goals of our
analysis and the terminology used. For instance, planning experts
would be more interested in support related to the efficient
implementation of domain concepts and procedures. However, as a side
effect, domain experts and planning experts may also benefit from our
analysis of planning.
In previous work [Benjamins, 1994,Benjamins, 1995], we have developed
a knowledge acquisition tool TINA ( Tool in
Acquisition) that is based on the notions of tasks, PSMs,
assumptions, domain knowledge and strategies. TINA works by
matching assumptions of PSMs with domain knowledge, and is able
to give the following kinds of support: (1) Given a particular domain,
generate the applicable strategies. (2) In case no applicable
strategies can be found, allow relaxation of some assumptions and
generate the legal strategies along with their not fulfilled
assumptions. (3) Given a particular strategy, obtain the corresponding
assumptions. (4) Given a partial strategy, obtain its possible
completions along with the assumptions. By strategy we mean a
particular combination of PSMs. In this paper, we focus on (1)
and (3). In the sequel, we first explicate how our library for
planning can be described in terms of TINA, and then, we perform
two experiments corresponding to (1) and (3).
In order to work, TINA needs three kinds of knowledge: (a) a
generative grammar describing the legal PSM
combinations, (b) conditions on the rewrite rules of the grammar, and
(c) domain characterizations.

Figure: 3 Some grammar rules representing planning methods.
The term at the left side of the arrow in a grammar rule represents
a task. The right part of the arrow represents a composite method
(ending in -CM). It consists of a reference to the method's
assumptions, and a set of subtasks (ending in -) T and/or primitive
PSMs (ending in -PM, and appearing in [ ]).
The
decomposition structure shown in Figure 2 can easily be
represented as a grammar. The decomposition structure is represented
as a quadruple 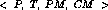 , where T denotes the set of tasks
relevant for the planning task P. PM stands for the set of
primitive PSMs. CM is the set of composite problem-solving
methods that decompose tasks into subtasks. In terms of a grammar, P
would be the start symbol, T the non-terminals, CM the rewrite
rules and PM the terminals. Starting at P, a grammatically legal
sentence corresponds to a valid planning strategy.
, where T denotes the set of tasks
relevant for the planning task P. PM stands for the set of
primitive PSMs. CM is the set of composite problem-solving
methods that decompose tasks into subtasks. In terms of a grammar, P
would be the start symbol, T the non-terminals, CM the rewrite
rules and PM the terminals. Starting at P, a grammatically legal
sentence corresponds to a valid planning strategy.
Figure 3 illustrates some of the composite PSMs
represented as rewrite rules. TINA uses the Definite Clause
Grammar (DCG) of Prolog to represent the task-method
decomposition. Because DCG allows for normal Prolog code within
the grammar, we can easily include the assumptions.
Figure 3 depicts two alternative PSMs for planning,
which belong to the PSM-family, and three PSMs for the test for unachieved
goals task.
The
identified relation between static roles of a PSM and their
fillings by domain knowledge (see Section 3), are in fact
the assumptions of the PSM: the fillings characterize the domain
requirements of the PSM. Therefore, assumptions are implemented
as constraints between static roles and domain knowledge. Assumptions
are represented as conditions on the rewrite rules, which means that a
rewrite rule can only be applied if its assumptions are satisfied.
They are implemented separately from the grammar, as shown in
Figure 4.

Figure: 4 Some examples of PSM assumptions.
One result of our analysis of planning is the identification of static
roles and their relations to domain knowledge
(Figure 1). Our analysis has revealed that there are
three main static roles which can be fulfilled by different kinds of
domain knowledge. The three main static roles are: (1) plan
composition, (2) world description and (3) plan-assessment knowledge.
Their respective fillings by domain knowledge are: (1) total or
partial order, (2) ADL or HTN and (3) causal links or
truth criterion. Below we list six examples of meaningful domain
types in planning:
- total-order/HTN/causallinks
- total-order/ADL/causallinks
- partial-order/ADL/causallinks
- partial-order/ADL/truthcriterion
- partial-order/HTN/causallinks
- partial-order/HTN/truthcriterion
Figure 5 illustrates two examples as
they are represented in TINA.

Figure 5: Two examples of domains, characterized by static-role fillings.
The aim of this experiment is to see whether the library can be used
to generate reasonable planning strategies given a particular domain
type. Suppose we take the domain type (1) from
Figure 5: ``partialorder_ADL_truthcriterion''. If we
give this to TINA, it outputs four different applicable
strategies. The fact the several strategies are found is due to the
fact that tasks can have several alternative methods to realize them.
One of the strategies generated, is shown below as a tree of methods:
propose_critique_modify_CM
propose_I_CM
random_select_goal_PM
goal_achievement_propose_expansion_PM
mtc_based_test_for_unachieved_goals_PM
critique_II_CM
mtc_based_interaction_critique_PM
mtc_based_modify_plan_PM
We can see that this strategy uses the PCM method, consisting of
its three subtasks. For each of the subtasks, the possible methods
have been checked for applicability by evaluating their assumptions.
The generation process has bottomed out in the primitive methods
(ending in ` PM'). Actually, the presented strategy is that of
TWEAK [Chapman, 1987]. TWEAK randomly selects a goal
to be achieved and proposes an expansion that has the goal condition
as an effect. It uses MTC-based methods to check for unachieved
goals and interactions, and to modify the plan. The
critique-II belongs to the family of the critique-I
methods, the first being a degenerated version (no consistency
critique) of the second.
If we input domain type (2) (Figure 5:
``totalorder_ADL_causallinks''), we are presented with 8 different
strategies, among which are those of PRODIGY and STRIPS.
Both strategies are part of the PCM family, but they do not
contain a critique step.
PRODIGY's strategy is as follows:
propose_modify_CM
propose_I_CM
random_select_goal_PM
smart_propose_expansion_PM
current_state_test_for_unachieved_goals_PM
backtrack_modify_plan_PM
PRODIGY randomly selects a goal that has not yet been achieved,
leaving a backtrack point on the other goals. It uses the
smart-propose expansion method (implemented by means-end-analysis
[Newell & Simon, 1963]). Unachieved goals are found by checking whether all
the goal states are logically implied by the current state. If PRODIGY fails to generate a plan, it backtracks to another goal and
continues from there. Note that the fact that the domain knowledge
contains plan assessment knowledge in the form of causal links, does
not mean that this knowledge necessarily has to be used.
STRIPS' strategy is as follows:
propose_modify_CM
propose_I_CM
linear_select_goal_PM
smart_propose_expansion_PM
current_state_test_for_unachieved_goals_PM
backtrack_modify_plan_PM
STRIPS uses the linear select method to select a goal to
plan for, which does not leave a backtrack point. For the rest, it
uses the same methods as PRODIGY. However, the backtrack
modify method cannot pursue alternative goals to plan for, but only
other operators and variable bindings.
In summary, the main difference between STRIPS and PRODIGY
resides in how they backtrack. STRIPS backtracks
chronologically on the proposed operator/action and variable bindings.
It cannot backtrack on ``select goal'' since it uses the linear
select goal method which leaves no alternative choices (this
accounts for the `linear' [Tate et al., 1990] characteristic of STRIPS). PRODIGY uses the random select goal method
which leaves choice points. Backtracking can thus be performed on the
goals selected (which makes PRODIGY a `nonlinear' planner).
Looking at the result, we can say that our library for planning can be
used to suggest various specifications of planners, given specific
domains. Moreover, the fact that TINA generated several
strategies (respectively 4 and 8 for the domain types (1) and (2) of
Figure 5), is an indication that the library we are
proposing has the competence to explore new, yet unknown, planning
strategies.
In this experiment, we use TINA the other way around. We input a
certain strategy, and as output we get the assumptions that have to be
true in order for the planner to be applicable. Currently we have
represented five well-known planners: STRIPS, PRODIGY,
SNLP, NONLIN and TWEAK. In this experiment, we will
input SNLP and NONLIN.
SNLP is represented as follows:
propose_critique_modify_CM
propose_I_CM
random_select_goal_PM
goal_achievement_propose_expansion_PM
agenda_based_test_for_unachieved_goals_PM
critique_I_CM
constraint_propagation_consistency_critique_PM
causal_link_based_interaction_critique_PM
causal_link_based_modify_plan_PM
For each constituting method of the strategy, the assumptions are
given. Some methods do, however, not have assumptions (e.g.,
random select goal).
propose_critique_modify_CM:
plan_composition=partial_order
goal_achievement_propose_expansion_PM:
world_description=ADL
constraint_propagation_consistency_critique_PM:
plan_composition=partial_order
causal_link_based_interaction_critique_PM:
plan_assessment_knowledge=causal_links
causal_link_based_modify_plan_PM:
plan_assessment_knowledge=causal_links,
plan_composition=partial_order
NONLIN is represented as:
propose_critique_modify_CM
propose_I_CM
random_select_goal_PM
decomposition_propose_expansion_PM
mtc_based_test_for_unachieved_goals_PM
critique_I_CM
constraint_propagation_consistency_critique_PM
causal_link_based_interaction_critique_PM
causal_link_based_modify_plan_PM
The generated assumptions are:
propose_critique_modify_CM:
plan_composition=partial_order
decomposition_propose_expansion_PM:
world_description=HTN
mtc_based_test_for_unachieved_goals_PM:
plan_composition=partial_order,
plan_assessment_knowledge=truth_criterion
constraint_propagation_consistency_critique_PM:
plan_composition=partial_order
causal_link_based_interaction_critique_PM:
plan_assessment_knowledge=causal_links
causal_link_based_modify_plan_PM:
plan_assessment_knowledge=causal_links,
plan_composition=partial_order
In NONLIN, the truth-criterion is used to test for unachieved
goals. Critiquing the plan is performed by means of causal links,
which, in NONLIN are represented in the so-called ``goal
structure'' (GHOST).
In summary, this second experiment demonstrates that it is possible to
obtain the assumptions that underly a particular planning strategy. It
is then up to the knowledge engineer to decide whether a specific
application domain satisfies the assumptions.
The assumptions we discussed so far relate to the problem-solving
methods in the sense that they specify what the methods need in order
to operate. In order to know whether a method can be used in a given
application domain, the domain must guarantee that these assumptions
are fulfilled. The method assumptions refer to the domain in three
main ways:
- First and foremost, they may request the availability of a
certain type of knowledge to operate. In terms of the library
developed here, this means that knowledge must be available to fill
a certain static role. Indeed, an assumption such as
world_description=HTN presupposes that there is knowledge
available in the domain to fill the role of world description.
Notice however that, in this paper, we are not concerned with how
this domain knowledge is actually extracted (but see work on PROTÉGÉ [Puerta et al., 1992]).
- Second, the method assumptions may specify particular
requirements about the specific domain models that will fill the
static roles. For example, in the assumption
world_description=HTN, the main requirement is that the knowledge
available in the domain for playing the role of world
description can be structured in a hierarchical task network
(HTN). Another example is that in the assumption
plan_composition=partial_order, the main requirement is that the
knowledge available in the domain for playing the role of plan
composition, can be structured in a partial-order network.
- Third, specific methods may require not only that knowledge is
available and can be meaningfully structured in certain domain
models, but also that it fulfills certain additional requirements.
For instance, certain types of planners that use causal links
require not only that these are available but that they form a
complete causal theory. This type of requirement has not been
investigated in this paper, and will be subject of further research.
The first corresponds to availability epistemological
assumptions, whereas the second and third correspond to property
epistemological assumptions [Benjamins & Pierret-Golbreich, 1996].
There are several important issues with respect to these assumptions
in using them to select a PSM or in characterizing domains.
First, it must be kept in mind that in some cases they are `soft'
requirements. If one has an implemented planner that would be easier
to use for whatever reason, the acquisition process becomes biased
towards forcing the domain to fulfill the assumptions required by this
planner. Domains can be, to some extent, malleable enough to be bent
to these needs. For instance, in some cases it does not matter whether
to model the plan sets as add-delete lists or as tasks organized in a
hierarchical manner. For instance, Unix can be seen as a planning
application domain in which the goals are sets of information of
states of the files and directories, and the steps consist of issuing
Unix shell commands. Since there seems to be very little hierarchy in
the command set, it seem more natural at a first glance to model the
Unix commands as operators. On the other hand, as every experienced
Unix user knows, one can specify aliases and shell scripts that in
practice implement higher level commands for specialized tasks --- the
existence of languages such as awk relies to a large extent on
this. So the question sometimes is not whether you can model the
domain in a certain way, but whether it seems natural or adequate to
do so.
Second, and more importantly, availability is not only a matter of
looking at what your method needs, but at what is already available in
the domain. One should try to use the maximum of the knowledge
available in the domain. If (hypothetically speaking) all we have is
the Unix manual, flat operators is the best we can come up
with. However, if we do have experts that can devise or have already
devised efficient shell scripts, it is best to use them. There is a
natural trade-off between knowledge and search. In figurative terms,
knowledge is the result of previous search recorded in a compiled
form. The more (heuristic) knowledge you have, the less you need to
rely on search. Of course, a planner can come up alone with the shell
scripts, and many learning architectures rely precisely on that.
However, if you have them available, why not using them and therefore
`save' in search? In this sense, different assumptions and
requirements made by different methods present opportunities to make
the best use of the knowledge naturally available in the domain.
Third, it is possible (at least in principle) to characterize planning
domains using the features, in the same way that we use them to
characterize types of methods --- e.g. partial-order versus
total-order planners. However, this requires establishing a more clear
relation between real domain characteristics and these features
oriented to domain representations. For instance, while a method
assumption for ``decomposition propose expansion'' requires that
knowledge is available and appropriate to fill the world
description with an HTN domain model, it is not totally clear
what characteristics or features of the application domain indicate
whether such assumption will hold. One indication is the way goals are
seen: when goals are naturally seen as `actions', HTNs are
adequate, whereas when goals are `states', ADLs are more
suitable. In other words, we are interested in finding the relations
between practical domain characteristics and domain representations,
which then are, through our library, related to PSMs for
planning.
As we already pointed out above, however, one of the problems is that
it is very difficult to characterize domains in hard terms. Further,
very little or no research has been spent on characterizing
application domains. Therefore, instead of proposing a complete set of
domain features that can be used on planning, in the following we will
give a first step in this direction by defining a number of domain
features that have emerged as important in the course of the research
presented in this paper. They will be presented as patterns that
connect characteristics of domains to types of planners, passing
through the static roles which are relevant and the characteristics of
domain models that they invoke. Table 1 gives an overview
of these patterns.

Table 1: The relation between application-domain features,
static-roles, domain model characteristics (fillings) and methods
for planning.
Planning goals can be
expressed in terms of the actions that have to be executed (``go to
Amsterdam'') or in terms of a state descriptions that describe a
desired state of the world (``be in Amsterdam''). The relevant
static role here is world description, and the two most common
types of domain models are HTN and ADL.
Domains where goals can be expressed either as actions or states, lead
to HTN-like planners such as UMCP [Erol et al., 1994]. An
example of a type of domain with this characteristic is air
campaign planning. Air campaign plans (as studied under the
DARPA-Rome Planning Initiative [Tate, 1996]) have their goals
typically formulated as actions. Partly as a consequence, such plans
are formulated in a hierarchical fashion, in which more specific
actions are devised to execute the action-goal, up to the level of
primitive actions.
Domains where goals are only expressed in terms of states, allow for
STRIPS-like planners such as PRODIGY [Carbonell & the PRODIGY Research Group, 1992]
or SNLP [McAllester & Rosenblitt, 1991]. An example of a type of domain
with this characteristic is information gathering. In this type
of domains (of which the Web is an increasingly important and
well-known instance), the goal is to have a specified information with
certain constraints, expressed in a query. The planning problem is to
devise a series of information retrieval and manipulation steps to
obtain the desired information (for an interesting discussion on the
challenges of this type of domain, see [Knoblock, 1996]).
This raises the question, why to use STRIPS-like planners at
all, since HTN planners can work with both state and action
goals. The reason is efficiency. HTN planners are rather
complex and heavy systems compared to STRIPS-like systems. So,
whenever a planning problem can be solved by a STRIPS-like
planner, it seems wise to use that option.
Sussman
illustrated the problem of planning with interacting goals and actions
(the so-called ``Sussman anomaly'') [Sussman, 1975]. Goals are
interacting when the effect of an action possibly deletes the
precondition of another action. The static role in question here is
plan composition, and the possible fillings are partial order
and total order. Much research has been performed concerning the
appropriateness of total- and partial-order planners for domains with
interacting and independent actions. In general, the conclusions are
that total-order planners (STRIPS, ABSTRIPS
[Sacerdoti, 1974], PRODIGY) are suitable for domains with
independent actions and goals, whereas partial-order planners (TWEAK, SNLP, NONLIN, NOAH) are better for domains
where actions and goals interact. However, in [Stone et al., 1994] is
shown that there exist `interacting' domains where total-order
planners (in particular, PRODIGY) do better than partial-order
ones.
Causal links refer to the availability of
a causal theory in the domain, where a causal theory specifies the
dependencies between plan-steps and the conditions they achieve. They
are used to facilitate the planning process, but do not necessarily
end up in the plan solution. It is possible to have a domain where
previous plans can be re-used. Such plans can come with or without
such a causal theory. In the former, the role filling for plan
assessment knowledge points to causal links, leading to causal-link
like planners, such as SNLP. If there is no causal knowledge in
the domain, the truth criterion is needed to assess the plan. MTC-like methods therefore compute, whenever needed, the causal
dependencies in the plan (e.g., TWEAK).
We can also see the use of causal links as an important factor related
to memory management of a planner. Causal links are some kind of
bookkeeping mechanism that keeps track of which action contributed to
specific situations (cf. truth maintenance systems [Doyle, 1979]).
Typically, such mechanisms require a lot of static memory. On the
other hand, MTC-like planners do not keep track of such
dependencies, but generate them on the fly when needed. Consequently,
they need few static memory, but much dynamic.
In this paper, we have presented a knowledge-level framework for
representing and analyzing planning methods, which can be considered
as a library with three types of reusable components:
(1) problem-solving methods, (2) their assumptions and (3) domain
knowledge. Assumptions form the connection between reasoning knowledge
(PSMs) and domain knowledge, and they form an important factor
to provide concrete knowledge acquisition support for engineering a
planning application.
We have demonstrated, by means of the tool TINA, that the
library is able to concretely support the knowledge acquisition
process. One kind of support concerned the configuration of an
applicable planner for a particular application domain using the PSMs from the library. The application domain in question is
matched to the assumptions of PSMs until an adequate
configuration of PSMs is found to solve the specific problem. In
fact, all possible PSM configurations are found that
match the domain at hand, yielding, in several cases, `new' planners.
The other kind of knowledge acquisition support concerned the
generation of the domain requirements, given a particular planner. The
planner is decomposed into its constituting PSMs, and the
assumptions of each of the PSMs refer to domain requirements.
The library proposed in this paper has been constructed by abstracting
problem-solving strategies (i.e., PSMs) from planning systems
and algorithms described in the literature. This characterizes a
system-driven approach to the construction of libraries of PSMs. Nevertheless, this is not the only possible approach for
building such libraries. For example, one may use a domain-driven
approach to obtain PSMs by extracting reasoning knowledge from
a domain expert through knowledge acquisition techniques. One may also
integrate these two approaches by starting with a domain-driven
approach and then comparing the resulting model with a selected
system-driven planning model (e.g., one of the models presented in
this paper). An approach along these lines has been proposed in
[Cottam & Shadbolt, 1996]. It is important to notice, however, that the
library presented here can always be extended with new PSMs
generated by any of those approaches. Of course, for each PSM
added to the library, the respective domain requirements (assumptions)
for its selection must also be included.
The library proposed in this paper is basically a modeling aid. That
is, it helps a knowledge engineer in selecting a problem-solving
method adequate to the application. However, a question that remains
is how to operationalize this PSM. The type of library we
constructed follows the CommonKADS tradition of separating analysis
and design. The conceptual model is supposed to be a product by
itself, based upon which the engineer proceeds to design an
application and then program a computer system. Design issues are
left to a separate model, the design model, which is distinct from the
model of expertise where PSMs are specified.
Other research groups such as
[Klinker et al., 1991,Swartout & Gil, 1995,Chandrasekaran, 1986] have proposed
libraries that use a different approach. Whenever a model has been
specified, a number of program modules or routines are provided (or
must be programmed) that can immediately operationalize the model into
a working system. For example, in the EXPECT architecture
[Swartout & Gil, 1995], a method is expressed in terms of goal
decompositions up to the point where a level of `primitive' methods,
implemented as CommonLisp functions, is reached. By using this
strategy, EXPECT can compile a method specified in abstract,
knowledge-level, terms into a CommonLisp program.
Of course, each of those approaches has its own advantages and
disadvantages. For example, the separation between analysis and design
used in CommonKADS does prevent the knowledge engineer from mixing up
the analysis with design issues. Moreover, the separation does not
restrict the knowledge engineer to use a fixed programming language,
operational system or graphics toolkit that may be inappropriate in a
given application's setting. On the other hand, authors like
[Klinker et al., 1991] have argued that conceptual models hide too many
details that have to be decided at design time, and that these design
decisions may render the conceptual model inadequate later on.
In order to be able to test the proposed library in a more operational
setting, we intend to use the second approach. Specifically, we
intend to use the EXPECT system to bridge the gap between the
conceptual specification and an implemented system. This will be done
in the following steps: (1) construct a set of EXPECT primitive
methods corresponding to the lower-level methods that are not
decomposed in our library, (2) specify the domain models and domain
features used in our library in terms of the domain modeling language
used in EXPECT --- namely Loom [MacGregor, 1991], and (3)
translate our function structures and control structures into EXPECT methods.
Since EXPECT currently does not have facilities for expressing
and using libraries of PSMs such as the one proposed in this
paper, the configuration process of creating an EXPECT method
will have to be done externally (for example by using TINA) and
manually. In a later phase, additional facilities will be built into
the EXPECT system to manage libraries of methods, in such a way
that the system will be able to handle at least part of the
configuration process.
Other further work relates to various extensions of the library. First
of all, we will extend the library with more planning methods in order
to cover more planners, including skeletal planners, case-based
planners, planners that use operators with uncertainty and planners
that deal with resources. Secondly, as we include more planning
methods, we will also have to include their respective assumptions
describing the domain features required by the methods. Thirdly, we
will have to deepen the notion of assumption of our planning
methods. In this paper, assumptions were described as constraints
between static roles and their domain fillings or domain model
characteristics (e.g., world_description=HTN). However, we
still need to establish a relation between these domain-model
characteristics and the application-domain features. We need to find
answers to questions such as ``is the HTN world description a
domain feature (available or not in the domain) or is it a choice of
domain model (that can always be used to structure the domain)?'' We
made a first step in this direction, and in future research we will
investigate the possibility to express assumptions in terms of such
application-domain features.
Richard Benjamins was supported by the Netherlands Computer Science
Research Foundation with financial support from the Netherlands
Organization for Scientific Research (NWO). Leliane Nunes de
Barros acknowledges the CNPq, a Brazilian research foundation.
André Valente gratefully acknowledges the support of DARPA
through contract DABT63-95-C-0059, as part of the DARPA/Rome Laboratory Planning Initiative (ARPI).
References
- Barret & Weld, 1994
-
Barret, A. & Weld, D. S. (1994).
Partial-order planning: evaluating possible efficiency gains.
Artificial Intelligence, 67.
- Benjamins, 1994
-
Benjamins, V. R. (1994).
On a role of problem solving methods in knowledge acquisition:
experiments with diagnostic strategies.
In Steels, L., Schreiber, A. T., & van de Velde, W., (Eds.),
Lecture Notes in Artificial Intelligence, 867, 8th European Knowledge
Acquisition Workshop, EKAW-94, pages 137--157, Berlin, Germany.
Springer-Verlag.
- Benjamins, 1995
-
Benjamins, V. R. (1995).
Problem-solving methods for diagnosis and their role in knowledge
acquisition.
International Journal of Expert Systems: Research and
Applications, 8(2):93--120.
- Benjamins et al., 1996
-
Benjamins, V. R., Fensel, D., & Straatman, R. (1996).
Assumptions of problem-solving methods and their role in knowledge
engineering.
In Wahlster, W., (Ed.), Proc. ECAI--96, pages 408--412.
J. Wiley & Sons, Ltd.
- Benjamins & Pierret-Golbreich, 1996
-
Benjamins, V. R. & Pierret-Golbreich, C. (1996).
Assumptions of problem-solving methods.
In Shadbolt, N., O'Hara, K., & Schreiber, G., (Eds.),
Lecture Notes in Artificial Intelligence, 1076, 9th European Knowledge
Acquisition Workshop, EKAW-96, pages 1--16. Springer-Verlag.
- Carbonell & the PRODIGY Research Group, 1992
-
Carbonell, J. & the PRODIGY Research Group (1992).
PRODIGY4.0: The manual and tutorial.
Technical Report CMU-CS-92-150, School of Computer Science, CMU.
- Chandrasekaran, 1986
-
Chandrasekaran, B. (1986).
Generic tasks in knowledge based reasoning: High level building
blocks for expert system design.
IEEE Expert, 1(3):23--30.
- Chandrasekaran, 1990
-
Chandrasekaran, B. (1990).
Design problem solving: A task analysis.
AI Magazine, 11:59--71.
- Chapman, 1987
-
Chapman, D. (1987).
Planning for conjunctive goals.
Artificial Intelligence, 32:333--377.
- Cottam & Shadbolt, 1996
-
Cottam, H. & Shadbolt, N. (1996).
Domain and system influences in problem solving models for planning.
In Shadbolt, N., O'Hara, K., & Schreiber, G., (Eds.),
Lecture Notes in Artificial Intelligence, 1076, 9th European Knowledge
Acquisition Workshop, EKAW-96, pages 354--369. Springer-Verlag.
- de Barros et al., 1996
-
de Barros, L. N., Valente, A., & Benjamins, V. R. (1996).
Modeling planning tasks.
In Third International Conference on Artificial Intelligence
Planning Systems, AIPS-96, pages 11--18.
- Doyle, 1979
-
Doyle, J. (1979).
A thruth maintenance system.
Artificial Intelligence, 12:231--272.
- Drummond & Currie, 1989
-
Drummond, M. & Currie, K. (1989).
Goal ordering in partially ordered plans.
In Proc. of the 11th IJCAI, pages 960--965,
Detroit, MI.
- Erol et al., 1994
-
Erol, K., Hendler, J., & Nau, D. S. (1994).
UMCP: a sound and complete procedure for hierarchical task-network
planning.
In The Second International Conference on Artificial
Intelligence Planning Systems (AIPS-94).
- Fikes & Nilsson, 1971
-
Fikes, R. E. & Nilsson, N. J. (1971).
STRIPS: A new approach to the application of theorem proving to
problem solving.
Artificial Intelligence, 2.
- Friedland & Iwasaki, 1985
-
Friedland, P. & Iwasaki, Y. (1985).
The concept and implementation of skeletal plans.
Journal of Automated Reasoning, 1.
- Kambhampati, 1994
-
Kambhampati, S. (1994).
Refinement search as a unifying framework for analyzing planning
algorithms.
In Proc. Principles of Knowledge Representation and Reasoning
(KRR). Proceedings of Knowledge Representation and Reasoning (KRR).
- Kambhampati, 1995
-
Kambhampati, S. (1995).
Planning as refinement search: a unified framework for evaluating
design tradeoffs in partial-order planning.
Artificial Intelligence, 76.
Special issue on planning and scheduling.
- Kingston et al., 1996
-
Kingston, J. K. C., Shadbolt, N., & Tate, A. (1996).
CommonKADS models for knowledge based planning.
In AAAI--96.
- Klinker et al., 1991
-
Klinker, G., Bhola, C., Dallemagne, G., Marques, D., & McDermott, J. (1991).
Usable and reusable programming constructs.
Knowledge Acquisition, 3:117--136.
- Knoblock, 1996
-
Knoblock, C. (1996).
Building a planner for information gathering: a report from the
trenches.
In 3rd Internation Conference on AI Planning Systems, AIPS-96,
pages 134--141. AAAI Press.
- MacGregor, 1991
-
MacGregor, R. (1991).
Inside the LOOM classifier.
SIGART Bulletin, 2(3):70--76.
- McAllester & Rosenblitt, 1991
-
McAllester, D. & Rosenblitt, D. (1991).
Systematic nonlinear planning.
In Proc. of AAAI-91, pages 634--639, Anaheim, CA.
- McCarthy & Hayes, 1969
-
McCarthy, J. & Hayes, P. J. (1969).
Some philosophical problems from the standpoint of artificial
intelligence.
In Machine Intelligence 4.
- Newell & Simon, 1963
-
Newell, A. & Simon, H. (1963).
Gps: A program that simulates human thought.
In Feigenbaum, E. & Feldman, J., (Eds.), Computers and
Thought, pages 279--293. New York, McGraw-Hill.
- Orsvärn, 1996
-
Orsvärn, K. (1996).
Principles for libraries of task decomposition methods -- conclusions
from a case-study.
In Shadbolt, N., O'Hara, K., & Schreiber, G., (Eds.),
Lecture Notes in Artificial Intelligence, 1076, 9th European Knowledge
Acquisition Workshop, EKAW-96, pages 48--65. Springer-Verlag.
- Puerta et al., 1992
-
Puerta, A., Egar, J., Tu, S., & Musen, M. (1992).
A multiple-method shell for the automatic generation of knowledge
acquisition tools.
Knowledge Acquisition, 4:171--196.
- Sacerdoti, 1974
-
Sacerdoti, E. D. (1974).
Planning in a hierarchy of abstraction spaces.
Artificial Intelligence, 5:115--135.
- Schreiber et al., 1994
-
Schreiber, A. T., Wielinga, B. J., de Hoog, R., Akkermans, J. M., & Van de
Velde, W. (1994).
CommonKADS: A comprehensive methodology for KBS development.
IEEE Expert, 9(6):28--37.
- Stone et al., 1994
-
Stone, P., Veloso, M., & Blythe, J. (1994).
The need for different domain-independent heuristics.
In Proceedings of the Second International Conference on AI
Planning Systems.
- Sussman, 1975
-
Sussman, G. J. (1975).
A Computer Model of Skill Acquisition, volume 1 of
Artificial Intelligence Series.
New York, American Elsevier.
- Swartout & Gil, 1995
-
Swartout, W. & Gil, Y. (1995).
Expect: Explicit representations for flexible acquisition.
In Proceedings of the Ninth Knowledge Acquisition for
Knowledge-Based Systems Workshop.
- Tate, 1977
-
Tate, A. (1977).
Generating project networks.
In Proceedings IJCAI--77, Paris, pages 888--893.
- Tate, 1996
-
Tate, A., (Ed.) (1996).
Advanced planning technology - technological achievements of the
ARPA/Rome Planning Initiative.
AAAI Press.
- Tate et al., 1990
-
Tate, A., Hendler, J., & Drummond, M. (1990).
A review of ai planning techniques.
In Allen, J., Hendler, J., & Tate, A., (Eds.), Readings
in Planning, pages 26--49. San Mateo, CA, Kaufmann.
- Valente, 1995
-
Valente, A. (1995).
Knowledge level analysis of planning.
SIGART Bulletin, 6(1):33--41.
- van Heijst et al., 1992
-
van Heijst, G., Terpstra, P., Wielinga, B. J., & Shadbolt, N. (1992).
Using generalised directive models in knowledge acquisition.
In Wetter, T., Althoff, K. D., Boose, J., Gaines, B., Linster, M., &
Schmalhofer, F., (Eds.), Current Developments in Knowledge
Acquisition: EKAW-92, Berlin, Germany. Springer-Verlag.
...epistemological
The other types of assumptions
distinguished in [Benjamins & Pierret-Golbreich, 1996,Benjamins et al., 1996], namely
teleological and pragmatic assumptions, are not relevant
for the aim of this paper.
...(PCM It is interesting to note
that the idea of proposing a single high-level method for a class of
problems is not new. In [Chandrasekaran, 1990], a similar method
is proposed, also called propose-critique-modify, to solve design
problems.
...MTC-based When we write MTC-based or causal-link
based, we mean MTC or causal-link like. Thus they do not
have to be pure MTC or causal-link.
...modification Actually, the backtrack method
represents control knowledge rather than inference knowledge
(as all the other methods do). However, because in this paper, we do
not consider control knowledge, we included the backtrack method in
order to show relevant differences between planners.
...grammar see [Benjamins, 1994] for a discussion
on the relation between TINA and other `grammar' approaches
such as GDMs [van Heijst et al., 1992].
...PSM-family Note that the second
grammar rule for planning represents a `degenerated' member of the
PCM family.
...planning See Section 5.4 for an
elaborate discussion on static role fillings and domain
characteristics.
Constructing Planners Through Problem-Solving Methods
This document was generated using the LaTeX2HTML translator Version 95.1 (Fri Jan 20 1995) Copyright © 1993, 1994, Nikos Drakos, Computer Based Learning Unit, University of Leeds.
The command line arguments were:
latex2html -split 0 -show_section_numbers doc.tex.
The translation was initiated by Richard Benjamins on Thu Sep 19 14:54:03 MET DST 1996
Richard Benjamins
Thu Sep 19 14:54:03 MET DST 1996