Luc Poittevin
Laboratoire de Recherche en Informatique
Université Paris-Sud
F-91405 Orsay Cedex
FRANCE
e-mail: Luc.Poittevin@lri.fr
ABSTRACT: This paper describes REVINOS, an incremental modeling and cooperative revision tool for Knowledge Bases (KB) expressed with situation nodules. Situation nodules are simple and understandable objects, which allow to specify step by step interactions between the knowledge-based system and his environment. Knowledge representation by situation nodules has been applied for defining the chaining of French Minitel dialogues. This representation can be useful for building "evolutive" KB in an incremental and operational approach. Representations and tools that facilitate the comprehension and revision of the KB are very helpful in this context. The goal of our cooperative revision tool is to let the user concentrate on the modeling of some objects of the KB (situations, actions, facts) while the updating of the chaining rules of situation nodules are made automatically by machine learning techniques.
To facilitate the comprehensibility and the revision of the KB, we propose a knowledge representation based on the concept of situation. Situation nodules are structures that represent situations in KBS. They contain actions to perform in the situation and rules for choosing the next nodule. Situation nodules allow to describe explicitly what to do each situation at each step of the achievement of a task by the KBS. This representation has been successfully applied to the design of on-line customized services for the French Railways.
Knowledge representation by situation nodules shares (Compton and Jansen, 1990)'s view on the nature of knowledge. Indeed knowledge representation by situation nodules is an invitation to view every knowledge as bound to a context and to adopt an incremental knowledge elicitation approach. The descriptions of concrete situations and of actions relevant to these situations are extended when others concrete situations are encountered. This model stands therefore in an incremental knowledge acquisition perspective as systems like TEIRESIAS (Davis, 1979) or ETS (Boose, 1985). This approach could be opposed to a knowledge acquisition approach by modeling before operationalisation, as the KADS methodology (Wielenga, Schreiber and Breuker, 1992). We rather view the process of building a KB as an incremental "operational modeling". This approach is made feasible because in our framework the reasoning model and the implementation are enough similar to enable incremental design of the KB and to quickly test and revise it (rapid prototyping).
Sections 2, 3, 4 and 5 present the knowledge representation by situation nodules, from the motivations to the application to the design of French Minitel services. Section 6 shows the similarities with knowledge representations like Compton's Ripple-Down Rules, Gaines's EDAGs or Boy's Blocks. Section 7 describes the visual environment that allow to create and modify the objects of the KB. The problem of the KB comprehensibility is briefly discussed. Section 8 details the revision process that can be applied to a KB expressed with situation nodules. This process is based on Machine Learning techniques that allow the system to help the user to revise and generalize the KB. We conclude by sketching a generalization of our approach, that could be called "Situated Revision" approach.
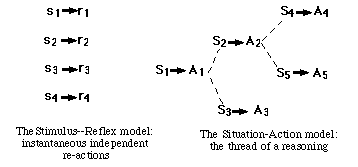
The central idea of this work is the concept of situation, drawn from an extension of the Stimulus-Reflex model : the Situation-Action model. A situation in this model is an interpretation of the environment during the achievement of a task. A situation is therefore subjective, closely linked to the current task.
Knowledge representation with situation nodules has been designed with the same goal as the Ripple-Down Rules (Compton and Jansen, 1990). The philosophical view of the nature of knowledge developed in (Compton and Jansen, 1990) is that knowledge has its primary validity in context and that generalization must be a secondary activity. This idea leads to :
Tropistic agents (Genesereth and Nilsson, 1987) are reactive agents : they have no memory and are incapable of planning. What they do is reacting to events in the environment. Their activity at any moment is determined entirely by their environment at that moment. Pengi (Agre and Chapman, 1987) is an example of tropistic agent.
It is possible to extend this Stimulus-Reflex model to a more complex model where the agents owns a memory. Agents with internal states are called hysteretic agents (Genesereth and Nilsson, 1987). They are able to execute tasks because their memory allows to ensure a continuity in their activity. We call this model : Situation-Action model (see figure 1).
Figure 1. Stimulus-Reflex versus Situation-Action
The concept of situation in this Situation-Action model has a special meaning. A situation is not only defined by the state of the environment, but also by the task which is achieved by the agent. A situation is not viewed as "the complete state of the universe at an instant of time" as in the situation calculus formalism (MacCarthy and Hayes, 1969). But it is defined here as a subjective interpretation of the environment during/for the achievement of a task. The current task determines the parts of the environment that define the current situation.
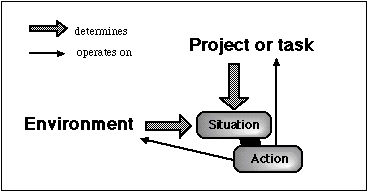
Figure 2. The Situation-Action model
An action is attached to each situation. The execution of an action return facts that define a new situation. We can say that the initial situation is refined at each step towards the final situation that precisely matches to the current task and the current state of the environment. It can also be said that the situation is different at each step because the new data discovered have changed the situation. In the two cases, the idea is to represent the achievement of a task as a chaining of situations. This model of reasoning is schematized in figure 3.
Figure 3. The incremental environment interpretation schema
Our purpose is not to define a psychological model (this one would be a very poor one) but the claim here is that this Situation-Action model can be useful to build KB because it is a prescriptive (or normative) model in the sense that it allows to represent precisely and explicitly what the agent or the system must do in the different situations.
Situation Nodules have been designed to represent situations - in the sense of the Situation-Action model - in Knowledge Based Systems.
According to the Situation-Action model, a situation is defined by three aspects:
Nodules form graphs which represent tasks. A nodule must belong to a single graph and each graph is identified by the name of his initial nodule. The initial nodule expresses an expectation (Lave, 1988) which is less precise than a goal . As a matter of fact, a goal means a desired state formally expressed. The word expectation allows to stress the fact that the situation solution features can not be known in advance.
The algorithm of the engine is very simple:
When a nodule is activated, each of its actions is executed. These actions can return more or less structured facts which are stored in a Working Memory (WM). From this WM, selection rules allow to choose the next nodule to trigger. If a next nodule is found, it is activated in turn. Otherwise the algorithm stops. Only one nodule is activated at any time.
An important aspect of this representation is the possibility to launch the execution of another graph from each nodule. The execution of the subtask (subgraph) is viewed as an action that returns information which is useful in the calling task. This characteristic is very interesting because it allows situation nodules graphs to be reused. A graph can indeed be called from any nodule. However let us remind that in our model the role of an action is basically to retrieve new information. The next nodule is activated by selection rules. The call of a subgraph from an action must be seen as a kind of interruption of this process.
This approach has been applied to the design of on-line customized dialogues for the French Railways (SNCF).The goal of the SNCF project is to provide customized information by the means of French Minitel to its employees in the domains of health insurance and old-age insurance.
We distinguish four actors in this project:
The application of the situation nodules framework to the Minitel project leads to define three types of actions according to the knowledge sources used:
For each action the designer defines a description of the returned facts that is called declaration of the action. This description is useful to know the kind of facts that the action is able to return and that can be stored in the WM.
An action can return objects, can set relations between objects, can set values to properties of objects. An example of returned fact is: the property age of the object agent has the value 53. The declaration of an action specifies the structure of the expected facts and requires the designer to give a type or a values domain for each property values. For example, the fact given above is declared as "agent.age INTEGER". As the properties are monovalued, these declarations allow to compute the "cover" of the nodules graph, as it will be detailed in section 8.4.
We have developed a tool in Smalltalk called EDINOS to build and test KB with situation nodules. With EDINOS the dialogue designer can create nodules graphs and simulate Minitel dialogues that are defined with these graphs.
The graph shown in figure 4 has for purpose to display the transport cards to which the different categories of beneficiaries can claim.
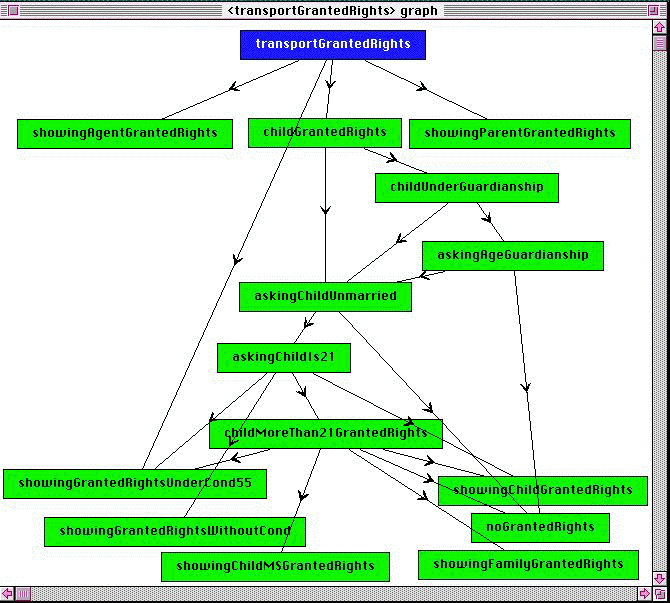
Figure 4. The "transportGrantedRights" graph
The nodule "childMoreThan21GrantedRights" represents the situation where the beneficiary is an unmarried child of the affiliated member and is more than 21 years old. This nodule holds a single "ask" action, named "caseChildMoreThan21", which consists in asking the minitelist to which of the following category his/her child belongs:
Selection rules of the nodule "childMoreThan21GrantedRights" appear in figure 5. The nodule has four possible next nodules. The rules of a nodule are independent. A priority level is set for each rule to force the choice of a nodule when several rules are activable at the same time. When a rule has no priority level the rule is set with the lowest priority. For instance, in figure 5, the case of a child of a common-law wife/husband who has a long illness activates the nodule "showingGrantedRightsUnderCond55". We can notice that several rules can conclude with the same nodule.
Figure 5. The selection rules of the nodule "childMoreThan21GrantedRights"
Situation nodules graphs have similarities with other representations. Figure 6 compares the representations.
| One node contains: | Potential children | Potential parents | Exclusive paths | Call of a subpart | |
|---|---|---|---|---|---|
| Decision Tree | simple test or conclusion | 2 | single | YES | NO |
| Ripple Down Rules | compound clauses or conclusion | 2 (multiple with MCRDR) | single | YES | NO |
| Exception Direct Acyclic Graph | - premise - conclusion | multiple | multiple | NO | NO |
| Augmented Transition Network | simple test plus test on buffers states | multiple | multiple | backtracking and parallelism can be used | YES (Recursive ATN) |
| Blocks | - preconditions - actions - abnormal conditions - goals | multiple | multiple | YES | YES |
| Situation Nodules | - actions - rules | multiple | multiple | YES | YES |
Figure 6. Comparisons of the knowledge representations
Decision trees, such as ID3 algorithm (Quinlan, 1986) builds them, can be seen as simplified nodules graphs, in which actions are simple attribute evaluation.
Ripple-Down Rules (RDR), introduced by (Compton and Jansen, 1990), differ from standard decision trees in that compound clauses are used to determine branching (Gaines and Compton, 1996). The RDR approach is very close to ours in the attempt to facilitate the improvement of the KB. With RDR, the addition of a new case in the KB is made easily and locally : there is no repercussion on the previous cases stored in the KB.
Exception Direct Acyclic Graphs (EDAG), introduced by (Gaines, 1996), are aimed to help the comprehensibility of the KB. They are "exception based" in that the maintenance can be simply made by adding new exceptions. The originality of EDAG with representations like RDR and situation nodules is that the paths in EDAG are not necessarily exclusive: every child of a node whose premise is verified, is activated.
Augmented Transition Networks (ATN) as proposed by (Bobrow and Fraser, 1969) are finite state automatons, augmented with local conditional transitions. The transitions depend on the values of parameters defined in global buffers. In recursive ATN the rules that activate nodes can be more complex since sub networks can be used as transition unites. ATN are used in grammatical parsing and natural language processing and therefore intensively backtrack or use parallel mechanisms.
Blocks from (Boy, 1990) and (Mathé and Kedar, 1992) are objects which are activated if their preconditions are fulfilled. A block contains actions (actions can be activation of others blocks) and two other fields: an "abnormal conditions" field and a "goals" field. These two fields define what to do according to the results of the actions and can therefore activate other blocks, e.g. if an abnormal condition occurs the relevant block is activated. They are equivalent to the selection rules : the block representation has been designed for complex dynamic systems control and the detection of abnormal results of actions are very important. The main difference between blocks and nodules is the "preconditions" field. The nodule representation requires that these "preconditions" fields are explicitly expressed in other nodule selection rules. The claim here is that the use of simple and homogeneous objects makes easier the correction of the KB.
In short, representation with nodules allows to attach complex actions (as call of subgraphs) to nodes and also allows to build complex rules to choose a next nodule. This way, nodules graphs show interesting characteristics of conciseness and legibility.
But especially, by requiring to explicitly represent situations, nodules set a meaning to the states (or nodes), and allow then to model knowledge at a certain "conceptual level". This makes easier the comprehensibility of the KB, especially if the nodules are well-documented.
During the incremental design of the KB, the designer has to make modeling choices in particular when he is creating new nodules. As the situation nodule is a representation of a situation, hence an abstract situation, a same situation nodule can model several different concrete situations. The designer generally chooses to differentiate concrete situations according to the actions that the situations require. There obviously can be several equivalent graphs to represent the same task.
In the modeling process, the names given to objects play an important part in the comprehensibility of the KB, since the name is always the first property that is viewed. Only after, one can access to a description or a contents of the object. For example, the contents of a Minitel screen is the text of the question and the possibly returned facts.
The meaning of a nodule depends on its location in the graph (which are its ancestors? which are its descendants?), and on its own contents (actions and selection rules). A nodule has three facets:
| NAME of the NODULE | FACET | EXAMPLE |
|---|---|---|
| past participle of the verb | RESULT | "retired before 55 years old" |
| gerund of the verb | ACTIVITY | "verifying rank" |
| infinitive of the verb | PLAN | "look for concerned department" |
Figure 7. A convention for nodule names
The EDINOS tool allow the user to simulate dialogues and to stop the execution at any time to "examine the situation". At that moment the user wants to "understand the situation", that is to say he wants to understand the reason of the execution of the current action. Notice that this user has the role of the designer of the KB, but does not have necessary designed this part of the KB.
The "object to understand" will be referred to as observation in the following because it can be viewed as an example observed. It is the conjunction of a nodule, the current state of the WM and a nodule path (the set of nodules which have been activated since the initial nodule). This "observation" object is a kind of "Situation Specific Model" (SSM) (Clancey, 1992), or a kind of "Conceptual Case Model" (Causse, 1994). As a matter of fact, a SSM contains the description of the process which led to the current solution (a nodule path in our framework) together with the "Case Model" in the sense of CommonKADS (Wielenga, Van de Velde, Schreiber and Akkermans, 1993), i.e. the current nodule plus the state of the WM in our framework .

Figure 8. Visualization of the current situation
To understand the observation, the user has to understand several objects (an example is given at figure 8):
When the user has finally understood these objects, he is in time to decide if he agrees with the system or not. Checking the meaning of each object is a prerequisite to revision.
In case the disagreement is confirmed, the user has two possibilities:
In the same way as interactive machine learning and revision tools such as MIS (Shapiro, 1983), APT (Nédellec and Causse, 1992) or KRT (Morik, Wrobel, Kietz and Emde, 1993), REVINOS is based on user-system cooperation in order to correct and/or complete the KB. This section describes the process of the revision session, and details the three main steps of the cooperation with REVINOS. The fourth step is optional.
Revision session starts with a given observation (see above) that is called current example and denoted by <curEx>.
The revision loop consists of three steps, as shown in figure 9.
Figure 9. Algorithm of the revision session
During each of these steps, the system resorts to the user for some tasks: the system can ask the user to create or modify KB objects. The system has generally initiative: the user is driven and just answers the system by exploring KB objects that the system shows him. In figure 10, the system is asking the user for the action that should replace the action "ask: grantUnderConditions".
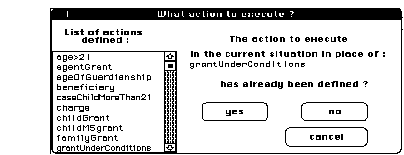
Figure 10. A dialogue excerpt during step 1
During the validation stage (step 3), the system submits to the user examples which fit with the different repercussions of the correction. If an example is not validated, the system goes back to step 1 with the new example, which becomes <curEx>. It does not mean that the correction is not relevant. Generally this new correction is required because a graph has not been sufficiently extended. For example, if an information <i1> is missing in WM to decide of the relevant action to do, the first correction changes the graph so that in the same context this information is known as the result of the execution of an action <a>. Now, the actions to do in situations where <i1> occurs, and in situations where <a> returns other facts <i2> and <i3>, have to be defined. Thus further corrections are hence necessary.
Once all examples have been validated, revision session can possibly be pursued if the system detects that the corrections performed can be generalized (step 4).
During the dialogue (figure 10 shows an extract), the system identifies the cause of the disagreement and the associated repair. Four causes of error are distinguished:
a) New situation: the data from the WM are correct and complete, but the action suggested is not relevant. This is a particular case, which had not been identified before. The relevant action and the nodule fitting with this situation can be created or even reused if existing objects can match.
b) Erroneous situation: the data from the WM are correct and complete but the action suggested is never relevant for the nodule. The action of the nodule must simply be changed.
c) Missing information: to be in position to decide of the final action to do, an information must be sought. The action that will return the missing information must be found or created.
d) erroneous information: a data of the WM is not correct. The action that has returned that information must be altered.
Causes b) and d) do not need a correction of the selection rules of a nodule. After repairing the action itself or the field "action" of the nodule, the system goes to step 3 (validation).
On the other hand, causes a) and c) requires either the joining of a new nodule to a graph, either the correction of a "mispoints" (step 2). The step 1 then outcomes to the identification of an objective of correction, that is to say a conjunction of the name of a current nodule and of the name of a target nodule, which must be chosen from the current nodule. The alteration of the selection rules of the current nodule (called <nodCur> afterwards) must be done in such a way that for <curEx> (at least), the target nodule <nodTarget> will be activated.
During this stage, the system has to choose and to apply an operator relevant to the objective defined before. In some cases the system submits examples to the user in order to choose between two revision operators. In contrast with a system like SEEK2 (Ginsberg, 1988) where a set of classified examples is known at the beginning and constrains the revision, REVINOS asks the user to classify relevant examples to delimit the right generalization level of the correction. This allows to revise the KB as precisely as desired.
The figure 11 details the algorithm used to choose the relevant operator. <oldNod> is the name of the nodule that has been chosen in the current context before revision. After the correction, <nodTarget> is activated in place of <oldNod> for the current context.
Figure 11. Algorithm for the choice of a revision operator
Figure 12 shows a "partial example" submitted to the user during this stage.
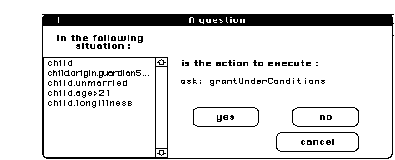
Figure 12. Submission of a partial example
The examples submitted to the user at this point of the session, are called "partial" examples in contrast with "complete" examples of step 3. The action proposed in a partial example is not final, and consequently the situation shown is transitional. However, the form and the abstraction level of partial and complete examples are the same and their computation from the graph and the actions declarations are strictly identical. This is made by exploring all possible paths from the initial nodule through the graph. An example of this computation will be detailed in the next section.
The submitted examples can be compared to "crucial objects" in MARVIN (Sammut and Banerji, 1986) and to discriminating examples in APT (Nédellec, 1992). Their roles are similar since they are shown to the user in order to determine the right "generalization level" for the revision. The <modifyRule> operator suggests to spread the current correction to the set of examples that uses the current rule. In concrete terms, it replaces <oldNod> by <nodTarget> in the current rule. The <replaceRule> operator is more specific and makes the current correction to the only subset of the examples concerned with the correction (see the annex for details on these operators). Similarly to APT, REVINOS uses those submitted examples to compute by differentiation the discriminating facts that direct either on <oldNod>, either on <nodTarget>. Then, these discriminating facts allow to modify appropriately the selection rules.
This process is similar to that of ENIGME (Thomas, Laublet and Ganascia, 1993), which uses the KADS inference structure to learn the operational knowledge of a given inference step in order to limit the learning subset.
Once the correction has been done, the system computes all the repercussions of this correction and submits them to the user as examples to validate. To calculate the repercussions of the correction, REVINOS build the cover of the graph. The cover of a graph is the set of all possible paths of the graph, expressed at a certain abstraction degree. Each path is an example. It is expressed by the list of abstracts facts returned by the actions executed along the path. When the graph is explored the domains of possible values are updated in accordance with the selection rules activated (see figure 13). Facts that are property values are computed in consequence. The computation of the graph covers is possible because:
| declared fact (what the action a can return) | property1 STRING |
| abstract fact (computed for the cover of the graph g) | property1 != 'Lyon' AND property1 != 'Marseille' |
| instanciated fact (stored in the WM during the execution) | property1 = 'Valence' |
Figure 13. The different abstraction degrees of the facts used in REVINOS
The modification repercussions are computed by stating the difference between
the cover of the graph before and after the correction of the graph. Two sets
are built:
E+ = new examples which were not covered before the correction.
E- = examples which are no longer covered.
The set E+ is useful to enrich the list L of the examples to validate. The set
E- is used to update L and to remove examples that would be now obsolete. A
list L' is also maintained which contains the examples that are already
validated. L' is useful during the step 2 to avoid submitting to the user
partial examples already validated.
Once all the examples have been validated, the system can suggest a generalization of the correction done if it finds one.
The generalization detailed in this section concerns the selection rules fields of nodules that have been corrected by a <replaceRule> or <modifyRule> operator. This generalization is possible only if other selection rules of corrected nodules can lead to <oldNod>. The principle is to submit to the user examples that use these other rules to state if correcting one of these rules would be relevant. If this is the case, the revision is spread to nearby situations that have not been considered before (see figure 14).
However there is another rule (see figure 3) which leads to
<showingGrantedRightsUnderCond55>:
"if: child.student thenGo: showingGrantedRightsUnderCond55 priority: 2;"
It appears to be relevant to ask the user if <showingGrantedRightsUnderCond75>
should not also be activated for the student children.
Figure 14. The possible generalization
In short, the generalization described here is driven by the selection rules just as the two <replaceRule> and <modifyRule> operators. The corrections suggested by REVINOS depends strongly on the manner the rules are expressed. Development of other generalization operators will also be useful.
We think the situation nodules framework must be validated by use. Up to now, REVINOS has been validated by a few users and we will extend this test. A key point is the way users appropriate the model.
An interesting and important question is how this model can provide reusable components. The adaptation of works in Derivational Analogy (Carbonell, 1986) to nodule graphs seems to be a promising direction to tackle this problem.
Finally, situation nodules allow to solve classification problems. The model can be extended to allow loops in nodule graphs. More complex control knowledge could by this way be expressed as the control knowledge used in synthesis tasks.
In this paper we have proposed a new method and knowledge representation to incrementally elicit knowledge. Knowledge representation with situation nodules has been designed having in mind the Situated Cognition critics to traditional Artificial Intelligence approach (Lave, 1988; Compton and Jansen, 1990; Clancey, 1991; Clancey, 1993; Menzies, 1996). What has been retained from these works is, in short:
The REVIN0S tool build on knowledge representation with situation nodules integrates a performance system and a learning system. This coupling characterizes learning apprentices (Mitchell, Mahadevan and Steinberg, 1990; Nédellec, 1992) which are able to learn new knowledge by observing the problem-solving steps during real executions or simulations. Together with this coupling, REVINOS uses Machine Learning techniques to provide interactive revision and generalization of concrete real examples. Thus, REVINOS is able to compute the family of examples that are concerned with the current revision operation. If the user accepts these examples, he validates the correction itself by validating the use of the revised knowledge.
We suggest to qualify "Situated Revision" the family of works which integrates learning apprentices and interactive revision approaches with the following goals:
This work benefits from the financial support of the ANRT. The author thanks the Division Technique des Caisses de Prévoyance et de Retraite de la SNCF, and the Machine Learning group at LRI, in particular Yves Kodratoff and Claire Nédellec, his Ph.D. advisor, for her helpful remarks on this paper. Thanks also to anonymous referees who gave profitable comments to this paper.
Agre, P. and Chapman, D. (1987). Pengi: An Implementation of A Theory of Activity, in Proceedings of the 6th National Conference on Artificial Intelligence (AAAI-87), 268-272.
Bobrow, D.G., and Fraser, B. (1969). An Augmented State Transition Network Analysis Procedure, in Proceedings of IJCAI'69, Walker D., Norton L. (Eds.), 557-567.
Boose, J., (1985). A Knowledge Acquisition Program For Expert Systems Based On Personal Construct Psychology, International Journal Of Man-Machines Studies 23, 495-525.
Boy, G. (1990). Acquiring and Refining Indices According To Context, in Proceedings of Banff Knowledge Acquisition For Knowledge-Based Systems Workshop..
Carbonell, J.G. (1986). Derivational Analogy: A Theory of Reconstruction Problem Solving and Expertise Acquisition, in R.S. Michalski, J.G. Carbonell, and T.M. Mitchell (Eds.), Machine Learning II: An Artificial Approach, 371-392, Morgan Kaufman, 1986.
Causse, K., (1994). A Model for Control Knowledge, in Proceedings of the 8th Banff Knowledge Acquisition For Knowledge-Based Systems Workshop.
Clancey, W.J., (1991). The Frame of Reference Problem in the Design of Intelligent Machines, in K. VanLehn K. (Ed.), Architectures for Intelligence, 357-423, Lawrence Erlbaum.
Clancey, W.J. (1992). Model construction operators, Artificial Intelligence 53, 1-115.
Clancey, W.J. (1993), Situated Action: A Neuropsychological Interpretation (Response to Vera and Simon), Cognitive Science 17, 87-116.
Compton, P., and Jansen, R. (1990). A Philosophical Basis For Knowledge Acquisition, Knowledge Acquisition 2 (3), 241-258.
Davis, R. (1979). Interactive Transfer of Expertise: Acquisition of New Inference Rules, Artificial Intelligence 12, 121-157.
Gaines, B.R. (1996). Transforming Rules and Trees into Comprehensible Knowledge Structures, in B.R. Gaines, U.M. Fayyad, G. Piatetsky-Shapiro, P. Smyth, and R. Uthurusamy (Eds.), Advances in Knowledge Discovery and Data Mining, 205-226, Cambridge: The MIT Press.
Gaines, B.R., and Compton, P. (1995). Induction of Ripple-Down Rules Applied to Modeling Large Databases, Journal for Intelligent Information Systems 5(3), 211-228.
Genesereth, M.R., and Nilsson, N.J. (1987) Logical Foundations of Artificial Intelligence, Morgan Kaufman.
Ginsberg, A. (1988). Automatic Refinement of Expert System Knowledge Bases, London: Pitman.
Lave, J. (1988). Cognition in Practice, Cambridge University Press, 1988.
MacCarthy, J., and Hayes, P.J. (1969). Some philosophical problems from the standpoint of Artificial IntelligenceÓ, Machine Intelligence 4, 463-502.
Mathé, N., and Kedar, S. (1992). Increasingly Automated Procedure Acquisition in Dynamic Systems, Technical Report FIA-92-23, NASA Ames Research Center, June 1992.
Menzies, T. (1996). Assessing Responses to Situated Cognition, in Proceedings of the 10th Banff Knowledge Acquisition For Knowledge-Based Systems Workshop.
Mitchell, T.M., Mahadevan, S., and Steinberg, L. (1990). LEAP: A Learning Apprentice For VLSI Design, in Y. Kodratoff, R.J. Michalski R. (Eds.), Machine Learning III: An Artificial Intelligence Approach, Morgan Kaufmann.
Morik, K., Wrobel, S., Kietz, J.U., and Emde, W. (1993). Knowledge Acquisition and Machine Learning, London: Academic Press.
Nédellec, C., and Causse, K. (1992). Knowledge Refinement using Knowledge Acquisition and Machine Learning Methods, in Proceedings of the 6th European Knowledge Acquisition For Knowledge-Based Systems Workshop (EKAW-92), 171-190, LNAI 599, Springer Verlag.
Nédellec, C. (1992). How to specialize by Theory Refinement, in Proceedings of the 1Oth European Conference on Artificial Intelligence (ECAI-92), 474-478, Neuman B. (Ed.), John Wiley & sons, Vienna, August 1992.
Quinlan, J.R. (1986). Induction of Decision Trees, in Machine Learning 1,1, 81-106.
Sammut, C., and Banerji, R.B. (1986). Learning Concepts By Asking Questions, in R.S. Michalski, J.G. Carbonell, and T.M. Mitchell (Eds.), Machine Learning II: An Artificial Approach, 167-192, Morgan Kaufman.
Shapiro, E.Y. (1986). Algorithmic Program Debugging, Cambridge: The MIT Press.
Thomas, J., Laublet, P., and Ganascia, J-G (1993). A Machine Learning Tool for a Model-Based Knowledge Acquisition Approach, in Proceedings of the 7th European Knowledge Acquisition For Knowledge-Based Systems Workshop (EKAWŐ93), 124-138, LNAI 723, Springer Verlag.
Wielenga, B.J., Schreiber, A.T., and Breuker J.A. (1992). KADS: a modelling approach to knowledge engineering, Knowledge Acquisition 4, 5-53.
Wielenga, B.J., Van de Velde, W., Schreiber, G., and Akkermans, H. (1993).
Towards an Unification of Knowledge Modelling Approaches, in J-M David,
J-P Krivine, R. Simmons (Eds.), Second Generation Expert Systems, 299-335,
Springer-Verlag.
replaceRule operator:
(<submitEx> is the partial example that has been submitted to the
user and has been accepted)
locate the discriminate fact <factD> by comparing WM of <submitEx>
and <curEx>
if <factD> was in <submitEx>,
nod1 := oldNod
alterNod := targetNod
endif
if <factD> was in <curEx>
nod1 := targetNod
alterNod := oldNod
endif
locate the activable rule and his <premise>
delete the activable rule from the selection rules of the nodule
add the rule 'if: <premise> AND <factD> thenGo: <nod1
>'
locate the alternative fact(*) <alterFact> of <factD>
if <alterFact> is empty
add the rule 'if: <premise> thenGo: <alterNod >' with the lower priority
else
add the rule 'if: <premise> AND <alterFact> thenGo:
<alterNod >'
endif
(*) The "alternative fact" of <factD> is computed from the declaration of
the action <a> that returned <factD>.
It is empty if <a> can return alternatively to <factD> more then
one fact. Its value is NOT(factD) if the only alternative to <factD> is
nil.
createRule operator :
locate <fact1>, the returned fact
if <fact1> is not empty
add the rule 'if: <fact1> thenGo: <targetNod>'
else
locate the alternative facts of <fact1>
if there is only one alternative fact <fact2>
add the rule 'if: NOT(<fact2>) thenGo: <targetNod>'
else
add the rule 'go: <targetNod>' with the lower priority
endif
endif