The principal components of project costs are:
This is the most difficult to estimate and control, and has the most significant effect on overall costs.
Software costing should be carried out objectively with the aim of accurately predicting the cost to the contractor of developing the software.
Software cost estimation is a continuing activity which starts at the proposal stage and continues throughout the lifetime of a project. Projects normally have a budget, and continual cost estimation is necessary to ensure that spending is in line with the budget.
Effort can be measured in staff-hours or staff-months (Used to be known as man-hours or man-months).
Boehm (1981) discusses seven techniques of software cost estimation:
(1) Algorithmic cost modeling
A model is developed using historical cost information which relates some software metric (usually its size) to the project cost. An estimate is made of that metric and the model predicts the effort required.
(2) Expert judgement
One or more experts on the software development techniques to be used and on the application domain are consulted. They each estimate the project cost and the final cost estimate is arrived at by consensus.
(3) Estimation by analogy
This technique is applicable when other projects in the same application domain have been completed. The cost of a new project is estimated by analogy with these completed projects.
(4) Parkinson's Law
Parkinson's Law states that work expands to fill the time available. In software costing, this means that the cost is determined by available resources rather than by objective assessment. If the software has to be delivered in 12 months and 5 people are available, the effort required is estimated to be 60 person-months.
(5) Pricing to win
The software cost is estimated to be whatever the customer has available to spend on the project. The estimated effort depends on the customer's budget and not on the software functionality.
(6) Top- down estimation
A cost estimate is established by considering the overall functionality of the product and how that functionality is provided by interacting sub-functions. Cost estimates are made on the basis of the logical function rather than the components implementing that function.
(7) Bottom- up estimation
The cost of each component is estimated. All these costs are added to produce a final cost estimate.
Each technique has advantages and disadvantages.
For large projects, several cost estimation techniques should be used in parallel and their results compared.
If these predict radically different costs, more information should be sought and the costing process repeated. The process should continue until the estimates converge.
Cost models are based on the fact that a firm set of requirements has been drawn up and costing is carried out using these requirements as a basis.
However, sometimes the requirements may be changed so that a fixed cost is not exceeded.
The most commonly used metric for cost estimation is the number of lines of source code in the finished system (which of course is not known).
Size estimation may involve estimation by analogy with other projects, estimation by ranking the sizes of system components and using a known reference component to estimate the component size or may simply be a question of engineering judgement.
Code size estimates are uncertain because they depend on hardware and software choices, use of a commercial database management system etc.
An alternative to using code size as the estimated product attribute is the use of `function- points', which are related to the functionality of the software rather than to its size.
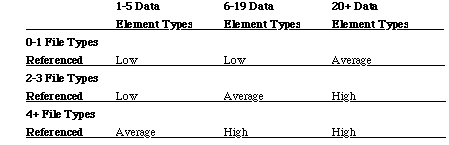
Function points are computed by counting the following software characteristics:
The function point count is computed by multiplying each raw count by the estimated weight and summing all values, then multiplied by the project complexity factors which consider the overall complexity of the project according to a range of factors such as the degree of distributed processing, the amount of reuse, the performance, and so on.
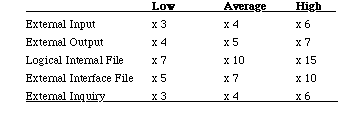
Function point counts can be used in conjunction with lines of code estimation techniques.
The number of function points is used to estimate the final code size.
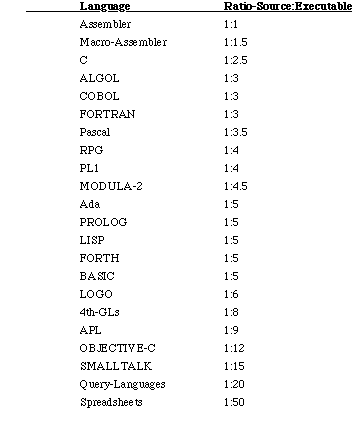
Based on historical data analysis, the average number of lines of code in a particular language required to implement a function point can be estimated (AVC). The estimated code size for a new application is computed as follows:
Code size = AVC x Number of function points
The advantage of this approach is that the number of function points can often be estimated from the requirements specification so an early code size prediction can be made.
Halstead's Effort Model
Technology constant, C, combines the effect of using tools, languages, methodology, quality assurance procedures. standards etc. It is determined on the basis of historical data (past projects). C is determined from project size, area under effort curve, and project duration.
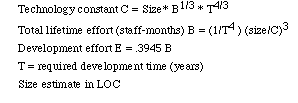
Rating: C = 2000 -- poor, C = 8000 -- good, C = 11000 it is excellent.

Effort and productivity change when development time varies between 2 and 3
years:
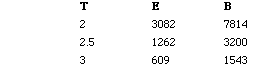
Considers a wide variety of factors.
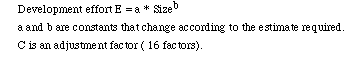
Projects fall into three categories: organic, semidetached, and embedded, characterized by their size.
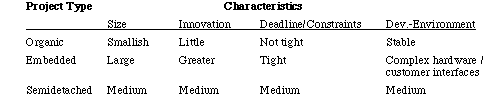
In the basic model which uses only source size:


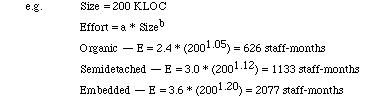
There is also an intermediate model which, as well as size, uses 15 other cost drivers.
Cost Drivers for the COCOMO Model.
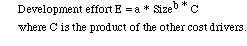

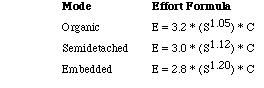

The intermediate model is more accurate than the basic model.

All have the same general characteristics and require:
BYL (Before You Leap) developed by the Gordon Group,
WICOMO (Wang Institute Cost Model) developed at the Wang Institute, and
DECPlan developed by Digital Equipment Corporation
are
automated estimation tools that are based on COCOMO.
Each of the tools requires the user to provide preliminary LOC estimates.
These estimates are categorized by programming language and type
(i.e.,
adapted code, reused code, new code).
The user also specifies values for the cost driver attributes.
Each of the tools produces estimated elapsed project duration (in months), effort in staff-months, average staffing per month, average productivity in LOC/pm, and cost per month.
This data can be developed for each phase in the software engineering process individually or for the entire project.
SLIM is an automated costing system based on the Rayleigh-Putnam Model.
SLIM applies the Putnam software model, linear programming, statistical simulation, and program evaluation and review technique, or PERT (a scheduling method) techniques to derive software project estimates.
The system enables a software planner to perform the following functions in an interactive session:
(1) calibrate the local software development environment by interpreting historical data supplied by the planner;
(2) create an information model of the software to be developed by eliciting basic software characteristics, personal attributes, and environmental considerations; and
(3) conduct software sizing--the approach used in SLIM is a more sophisticated, automated version of the LOC costing technique.
Once software size (i.e., LOC for each software function) has been established, SLIM computes size deviation (an indication of estimation uncertainty), a sensitivity profile that indicates potential deviation of cost and effort, and a consistency check with data collected for software systems of similar size.
The planner can invoke a linear programming analysis that considers development constraints on both cost and effort, and provides a month-by-month distribution of effort, and a consistency check with data collected for software systems of similar size.
ESTIMACS is a "macro- estimation model" that uses a function point estimation method enhanced to accommodate a variety of project and personnel factors.
The ESTIMACS tool contains a set of models that enable the planner to estimate
ESTIMACS can develop staffing and costs using a life cycle data base to provide work distribution and deployment information.
The target hardware configuration is sized (i.e., processor power and storage capacity are estimated) using answers to a series of questions that help the planner evaluate transaction volume, windows of application, and other data.
The level of risk associated with the successful implementation of the proposed system is determined based on responses to a questionnaire that examines project factors such as size, structure, and technology.
SPQR/20, developed by Software Productivity Research, Inc. has the user complete a simple set of multiple choice questions that address:
All these tools have been implemented on personal computers or engineering workstations.
Martin compared these tools by applying each to the same project.
A large variation in estimated results was encountered, and the predicted values sometimes were significantly different from actual values.
This reinforces the fact that the output of estimation tools should be used as one "data point" from which estimates are derived--not as the only source for an estimate.