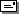 Rob Kremer
Rob Kremer

Object-oriented analysis, design and programming are being presented as major advances in software engineering. These notes address the reasons why OO programming is seen as important for software engineering.
The problems addressed by OO programming are not new, and neither are the solutions proposed. It is useful to go back to the very first Software Engineering conferences in the late 1960s and see the problems and proposed solutions from a viewpoint of 30 years ago.
Harr in 1968 enumerates problems of software development that still apply today. Hardware is orders of magnitude faster and available memory orders of magnitude larger, but our ability to make that hardware perform effectively, and to manage this on schedule and to budget, is still very poor.
"Why do we often fail to complete systems with large programs on schedule?"
Dijkstra in 1968 sarcastically emphasizes that we have to change. The hardare and tools have changed. The tasks have become more complex. But how much have thinking habits and organizations changed -- very little. We are now told to think in terms of OO and to manage software as a manufacturing process -- are these the necessary changes?
"What is actually happening, I am afraid, is that we all tell each other and ourselves that software engineering techniques should be improved considerably, because there is a crisis. But there are a few boundary conditions which apparently have to be satisfied. I will list them for you:
Naur in 1968 suugests a design discipline for software based on Alexander's approach to synthesizing forms in architecture.
"In the design of automobiles, the knowledge that you can design the motor more or less independently of the wheels is an important insight, an important part of an automobile designer's trade. In our field, if there are a few specific things to be produced, such as compilers, assemblers, monitors, and a few more, then it would be very important to decide what are their parts and what is the proper sequence of deciding on their parts. That is really the essential thing, what should you decide first.
The approach suggested by Christopher Alexander in his book: Notes on the Synthesis of Form, is to make a tree structure of the decisions, so that you start by considering together those decisions that hang most closely together, and develop components that are subsystems of your final design. Then you move up one step and combine them into larger units, always based on insight, of some kind, as to which design decisions are related to one another and which ones are not strongly related. I would consider this a very promising approach."
Gillette in 1968 also emphasizes modularity and the rigid specification of the modules.
"Three fundamental design concepts are essential to a maintainable system: modularity, specification, and generality. Modularity helps to isolate functional elements of the system. One module may be debugged, improved, or extended with minimal personnel interaction or system discontinuity. As important as modularity is specification. The key to production success of any modular construct is a rigid specification of the interfaces; the specification, as a side benefit, aids in the maintenance task by supplying the documentation necessary to train, understand, and provide maintenance. From this viewpoint, specification should encompass from the innermost primitive functions outward to the generalized functions such as a general file management system. Generality is essential to satisfy the requirement for extensibility."
McIlroy in 1968 suggests modular families of software components in words that could be those of OO proponents such as Brad Cox today.
"Software components (routines), to be widely applicable to different machines and users, should be available in families arranged according to precision, robustness, generality and time-space performance. Existing sources of components -- manufacturers, software houses, users' groups and algorithm collections -- lack the breadth or interest or coherence or purpose to assemble more than one or two members of such families, yet software production in the large would be enormously helped by the availability of spectra of high quality routines, quite as mechanicaI design is abetted by the existence of families of structural shapes, screws or resistors. The talk will examine the kinds of variability necessary in software components, ways of producing useful inventories, types of components that are ripe for such standardization, and methods of instituting pilot production."
Falkoff in 1969 states requirements for programming languages that address the richness necessary in a language that will allow human concepts to be expressed in computational terms.
"The criteria that are proposed for the choice of a formal design language are:
Kitchenham & Walker in 1986 enumerate the quality criteria for software, most of which are non-functional in that they do not relate to the input/output behavior but rather to some global property of that behavior.
Booch in 1991 captures the key features of the OO approach and the languages that support it. What he says links back to the issues raised over 20 years earlier. The OO approach is intended to provide modularity, encapsulation, specification, etc, and to provide a design language close to human conceptualization, and allow software manufacturing to be managed more effectively.
Object-oriented analysis is a method of analysis that examines requirements from the perspective of the classes and objects found in the vocabulary of the problem domain
Object-oriented design is a method of design encompassing the process of object-oriented decomposition and a notation for depicting both logical and physical as well as static and dynamic models of the system under design
A language is object-oriented if and only if it satisfies the following
requirements:
The properties of an OO language are:
Stroustrup designed C++ as a highly structured language that had the speed and space efficiency of C. The essence of C++ is that it allows the programmer to specify his or her intentions to the compiler so that many more logical errors in program implementation are reported at compile time. It does this by assigning a type to each data structure, requiring arguments to procedures to be typed, providing means for specifying accesibility of data and procedures, and many other similar mechanisms allowing the compiler to 'understand' the logic of the program.
Data and procedures may be protected through two mechanisms.
The C++ class extends the definition of a record structure to include the associated procedures that operate on that record structure. A class is a type definition for an abstract data type that includes both data and procedures. An object is an instance of that data type.
Thus, one can take the definition of a data type for a rectangle:
struct rectangle { int length, width; };
and extend it to include procedures that operate upon the rectangle:
class rectangle {
public:
int length, width;
rectangle(): length(0), width(0) {}
rectangle(int l, int w): length(l), width(l) {}
~rectangle();
virtual void MakeEqual(void) {width = length;}
virtual int GetArea(void) {return length *width;}
};
The two procedures with the same name as the class, "rectangle", are constructors that get called when an object of type rectangle is instantiated.
For uniformity, C++ also associates constructors with simple data types such as int:
int w(x);
initializes w to have the value x
(i.e. same as w = x;).
Constructors can call other constructors through a colon followed by a comma separated list:
rectangle(): length(0), width(0) {}
is a constructor that sets length
and width to zero, and
rectangle(int l, int w): length(l), width(l) {}
is a constructor that sets length to l and width to w.
These two constructors have the same name but the compiler can distinguish them by the number and types of their arguments, the "signature" of the argument.
The procedure with the name as the class prefixed by "~", "~rectangle()", is the destructor for the class. It gets called automatically when an object is deleted. In this example a destructor is unnecessary and the procedure does nothing. However, if the constructors allocated data structures in the heap then the destructor would deallocate them.
Constructors and destructors support a software engineering discipline for storage allocation, initialization and deallocation.
The procedures "MakeEqual" and "GetArea" are normal procedures associated with the rectangle data structure. They are declared to be virtual so that sub-classes can override them and replace them with other procedures having the same name and argument signature but performing a different computation more appropraite to the sub-class.
A new class can be defined as a sub-class of an existing one by placing the name of the existing one after a colon before the body of the definition. Thus, in the following example "square" is defined as a sub-class of "rectangle" and inherits all the properties of rectangle. It has a new constructor with one argument that sets the length and width to that argument.
class square: public rectangle
{
public:
square();
square(int edge): rectangle(edge,edge) {}
};
The class "cuboid" is defined as a sub-class of "rectangle" with one additional variable, "height". Its constructors initialize height also. The default constructor (with no arguments) for rectangle will be called automatically unless one of the other constructors for rectangle is specified. Hence, for "cuboid()" length and width are automatically initialized to zero.
The virtual procedure "MakeEqual(void)" is overridden by a new definition that sets the height as well as the width to the value of length. A new procedure "GetVolume(void)" is defined and the previous procedure "GetArea(void)" continues to be available since it is inherited from the definition of "rectangle".
class cuboid: public rectangle
{
public:
int height;
cuboid() : height(0) {}
cuboid(int l, int w, int h)
: rectangle(l,w), height(h) {}
virtual void MakeEqual(void)
{height = width = length;}
virtual int GetVolume(void)
{return GetArea()*height;}
};
The class definitions define data types that may be used to instantiate objects as normal variables. The following example illustrates this:
void main(void)
{
rectangle r1; rectangle r2(20,15);
square s1;
square s2(50);
cuboid c1;
cuboid c2(12,10,19);
int x;
x = r1.GetArea();
x = s1.GetArea();
x = c1.GetArea();
x = r1.GetVolume(); // Compile-time Error!
x = s1.GetVolume(); // Compile-time Error!
x = c1.GetVolume();
x = r1.length;
x = s1.length;
x = c1.length;
x = r1.height; // Compile-time Error!
x = s1.height; // Compile-time Error!
x = c1.height;
}
The compile-time errors arise because the procedures or variables do not exist in the objects declared. The compiler has sufficient information to catch such logical errors.
It may make it easier to understand class and inheritance if one looks at a typical implementation. An object with the rectangle struct is implemented in memory as a pair of integers as shown below:
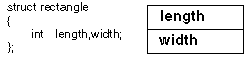
When the instance of a struct becomes the instance of a class an additional pointer is added which points to a table of procedure pointers for the associated procedures. This is how procedures become associated with data structures. A pointer to a table is used for efficiency since there will usually be many objects instantiating the same class.
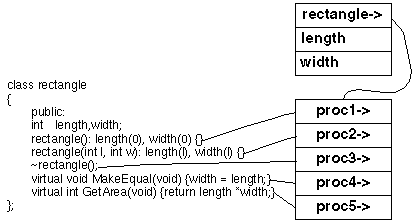
When one object is created from an inherited class it has the data structures from all the classes together with a pointer to a procedure table for the inherited class:
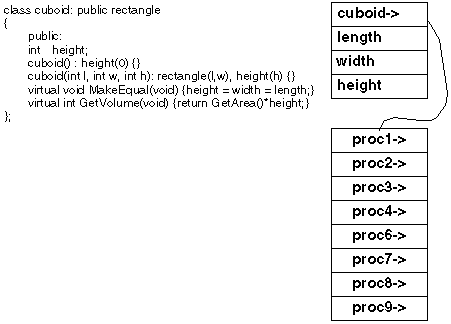
When additional procedures have been added the table is just increased in size. When a virtual procedure has been overriden the entry in the table is replaced with a pointer to the new procedure.
class rectangle {
public:
int length, width;
rectangle(): length(0), width(0) {}
rectangle(int l, int w): length(l), width(l) {}
~rectangle();
virtual void MakeEqual(void) {width = length;}
virtual int GetArea(void) {return length *width;}
};
That was bad. Why?
length and width publicly
declared reviels how the class is implemented.
length and width without being able to trap the
event.
ADisplayedRectangle.length = 5;which would not give us the chance to change the display.
Always hide data members:
class rectangle {
private:
int length, width;
public:
rectangle(): length(0), width(0) {}
rectangle(int l, int w): length(l), width(l) {}
~rectangle();
virtual void MakeEqual(void) {width = length;}
virtual int GetArea(void) {return length *width;}
};
What's the problem now?
There's no way to change the length and width of the rectangle.
What can we do about it?
Accessor functions!
class rectangle {
private:
int length, width;
public:
rectangle(): length(0), width(0) {}
rectangle(int l, int w): length(l), width(l) {}
~rectangle();
virtual int getLength() const {return length;}
virtual int getWidth () const {return width ;}
virtual void setLength(int l) {length = l;}
virtual void setWidth (int w) {width = w;}
virtual void MakeEqual(void) {width = length;}
virtual int GetArea(void) const {return length *width;}
};
Two types:
set accessor functions often return the old value. For example:
virtual int setLength(int l) {
int old = length;
length = l;
return old;
}
The inheritance structure whereby the classes square and cuboid inherit from the class rectangle can be represented in a diagram as:
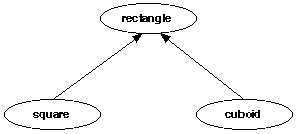
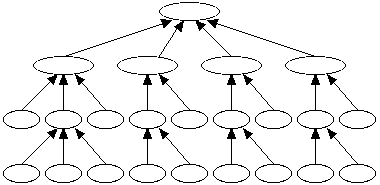
A class library is a set of classes designed to work together to provide the functionality of a graphics user interface, or a database, or a numerical library, and so on. Since common features such as cloning, object storage, and so on, need to be included in all classes, the structure of a class library using single inheritance is an inheritance tree like that shown below.
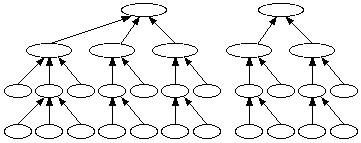
Early C++ libraries all have the structure shown above. However, this causes problems if one tries to mix class libraries from different vendors. The two libraries below do not combine well because the trees cannot be merged without changing the code.
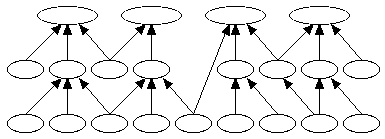
This led Stroustrup to introduce multiple inheritance in C++ whereby a class can be a sub-class of more than one other class. It then becomes possible to structure libraries like the one below, and to mix different libraries together more easily.
Templates allow data structures to be defined and programs to be written where the types of data involved are passed as parameters (parametric polymorphism).
For example consider various forms of classes of pairs of differing types:
class pair_int_char {
public:
int first;
char second;
pair_int_char(int x, char y) : first (x), second (y) {}
};
pair_int_char pair1(4, 'p');
class pair_bool_double {
public:
bool first;
double second;
pair_bool_double (bool x, double y) : first (x), second (y) {}
};
pair_bool_double pair2(false, 0.89);
The first class defines a pair of an int and a char with a constructor that initializes each. The second class defines a pair of a bool and a double with a constructor that initializes each.
Templates allow us to define all such pairs in a single definition where the types are given as parameters to the compiler, e.g.:-
template <class T1, class T2>
class pair {
public:
T1 first;
T2 second;
pair(const T1& x, const T2& y) : first (x), second (y) {}
};
pair<int, char> pair3(10, 'x');
pair<bool,double> pair4(true, 3.45);
pair<pair_int_char, float> pair5(pair1, 98.3);
Type parameters may also be used in function definitions:-
template <class T>
T max(T x, T y) {
return x < y ? y : x;
}
The standard template library provides a wide range of templated data structures together with generic algorithms for standard operations such as sorting.
STL data types include:
More information on STL is available at:
The paper Class Library Implementation of an Open Architecture Knowledge Support System provides a detailed discussion of a large-scale class library, its architecture and application to building a range of systems. It also comments on the value of C++ in software engineering.
Adapted from original notes by Dr. Brian Gaines.
Practical Software Engineering, Department of Computer Science
Rob Kremer